隱私數據庫多關鍵詞秘密同態檢索方法研究
2022-05-14 10:28:04姜姍,曹莉
計算機仿真 2022年4期
姜 姍,曹 莉
(河南中醫藥大學信息技術學院,河南 鄭州 450046)
1 引言
在網絡數據安全威脅指數不斷上升的態勢下,隱私數據庫作為大部分用戶選擇承載隱私數據的安全平臺,它的主要用處是針對數據儲存以及訪問數據進行一定的管控[1]。其中可以將管控分為兩個方面,其一是隱私數據庫在被訪問過程中,必須要保證庫中數據絕對安全性;其二是在未經授權的訪問者想要訪問數據時,系統必須拒絕訪問數據的要求,這樣才能夠保證有效性,即可從根本上確保隱私數據庫中數據的安全性[2]。
目前,越來越多的人將關鍵數據和個人信息提供給云數據庫進行存儲,外包前的數據加密是數據保護基本方法,從加密云中檢索所需文件,可搜索加密技術在保證用戶數據隱私的同時,實現數據檢索服務,同時使用戶能夠也能夠使用關鍵字正確有效地定位加密文件[3]。
楊旸[4]等人提議出一種基于隱私數據庫的多關鍵詞檢索方法,首先根據該領域中加權評分的基本理念代入到需要檢索的文檔中,對需要檢索數據進行輸入題目關鍵詞等處理,并在此基礎上計算求解出不同類別關鍵詞的本身權重數值;其次針對需要檢索的關鍵詞做對應的語義擴展處理,并且計算出關鍵詞語義之間相似程度。最后,在對文檔向量進行加密時進行分段,使每個分段乘以相應維數的矩陣完成檢索。
周藝華[5]等人為保證云存儲數據的安全性,提出一種f-mOPE數據庫密文檢索方案,該方法首先根據f-mOPE方法以及二值排序樹的數據結構理論,形成檢索明文以及對應的保序編碼,并且在AES加密方法的基礎上,將檢索出來的隱私數據明文轉換成為密文并將其加密處理,最后運用秘密同態技術獲取出檢索的數據。
上述兩種方法雖然都可以有效保護用戶數據的安全性,但實際上并不能保證檢索的時效性。基于此本文將提出一種隱私數據庫多關鍵詞秘密同態檢索方法。
2 模擬隱私數據系統模型
首先構建出一個模擬隱私數據庫系統,將組成系統的參與者分為三個主要個體,分別是需要存儲數據個體、根據關鍵詞檢索數據的用戶個體以及存儲數據的服務器。系統構成結構如圖1所示。
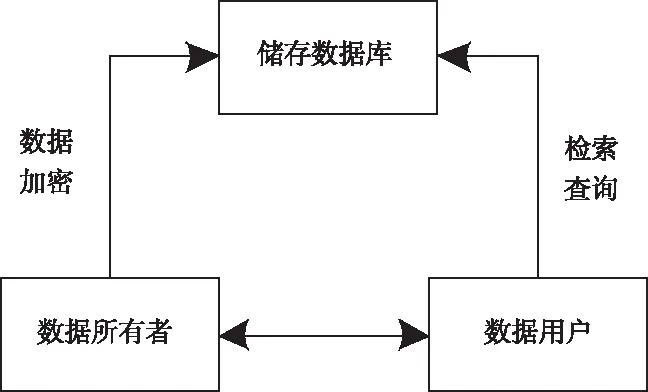
圖1 系統模型圖
假設存儲數據的服務器既能保證數據隱私安全性又可以讓不明身份的用戶停止訪問數據,那么當數據所有者將數據文件F=(f1,f2,…,fm)上傳到存儲器之前,就需要針對上傳文件F進行加密處理。為了能夠從根本上符合數據檢索的分級條件,將對數據文件集F進行提取相對關鍵詞W=(w1,w2,…,wp),在此基礎上根據關鍵詞的模糊集合構建出與關鍵詞語義對應的陷門Tw以及數據加密檢索索引,最后再將關鍵詞檢索索引傳至加密隱私數庫。這樣當需要檢索的用戶在進行關鍵詞檢索的過程中,即可向數據所有者發送檢索請求,在所有者同意的情況下檢索用戶獲取對應陷門的函數密鑰,這樣在存儲數據的服務器在接收到陷門的放行指令時,就可以完成根據數據文件關鍵詞進行檢索。
3 秘密同態技術
本研究使用秘密同態技術對統計數據進行加密,在不泄露的情況下處理敏感數據,秘密同態技術源于代數理論,其基本思想如下:
假設將Ek和Dk2分別描述為加密與解密函數,并且令明文數據空間中的元素是一個有限集合{M1,M2,…,Mn},而α和β分別表示為加密和解謎運算。如果α(Ek1(M1),Ek1(M2),…,Ek(Mn))=Ek1β(M1,M2,…,Mn)是一個相對成立的運算,且Dk2(α(Ek1)(M1),Ek1(M2),…,Ek1(Mn))=β(M1,M2,…,Mn)也是一個成立條件,那么就會將函數(Ek1,Dk2,α,β)族稱之為秘密同態。
3.1 加密解密算法
在對數據進行加密解密處理的過程中,首先需要選擇出兩個相對應的安全素數p和q,然后讓m=pq,其中m是隱私數據,再根據隱私數據選取出數據空間T=Zm以及隱私數據空間這樣就有T′=(Zp*Zq)n,這里的n為數據庫中較為安全的數據參數值,這樣數據空間中計算集合F就可以由m加、m減、m乘、m除構建而成,并且隱私數據庫中的運算集合也是由其構成,這樣分別選取出rp∈Zp、rq∈Zq生成乘法子群Zp-{0}和Zq-{0},加密密鑰為K=(p,q,rp,rq)。
加密過程:針對明文x∈Zm,任意地將x等同劃分成為x1,x2,…,xn,xi∈Zm,i=1,2,…,n,使滿足x=modm,其中對x的機密運算為
Ek(x)=([x1rpmodp,x1rqmodq],
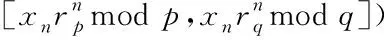
(1)
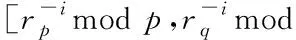
3.2 定理運算
根據上述加密解密結算結果,如果令文件數據x、y的加密運算為Ek(x)和Ek(y),并且其中包括了最高次指數冪運算n1和n2,那么乘積Ek(z)=Ek(x)Ek(y)就是由包括1≤j≤n(n=n1+n2)在內的次指數冪運算的項目Ek·j(z)構成的,這里將Ek(z)描述為向量形式便有
(Ek·1(z),Ek·2(z),…,Ek·n(z))
(2)
如果假設r=(rp,rq),那么Ek(z)就可以描述為多項式的形式
Ek(z)[r]=t1r+t1r2+….+tnrn
(3)
根據上式計算結果可得知加減乘除運算定義為
加法和減法
Ek(x±y)=Ek(x)±Ek(y)
(4)
其結果為Zm上的向量加減法或者是Zm上的多項式加減法。
于是便有
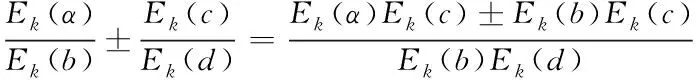
(5)
乘法
Ek(xy)=Ek(x)Ek(y)
(6)
其結果為Zm上的向量乘積或者是系數在Zm上的多項式乘積。
則有
Ek(xy)=Ek(∑xiyj)
=Ek((x1+x2+…+xn1)(y1+y2+…+yn2))
(7)
Ek(xy)可以被表示為多項式形式,便有
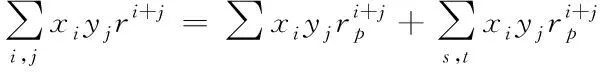
(8)
其中1≤i,s≤n1,1≤j,t≤n2,1≤i+j≤n。
除法:
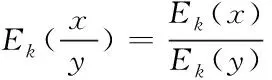
(9)
其結果為Zm上向量相除或者是系數在Zm上的多項式相除。
那么根據上述加減乘除運算便可進一步得出
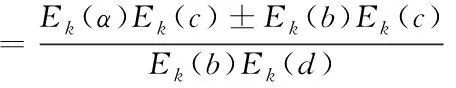
(10)
根據計算結果便可得知,這些運算保證可以直接對隱私數據進行運算操作。
4 多關鍵詞下秘密同態檢索方法
根據上述秘密同態技術運算定理,本研究將在同態加密基礎上提出一種多關鍵詞檢索方法[6],其中檢索模塊將由以下五種模塊構成:
1)Init():當隱私數據庫在被不明身份者進行訪問的過程中,DO會在存儲隱私數據庫中根據加密計算的參數λ形成同態加密前提下的公鑰Pk以及私鑰Sk;
2)Encrypt():DO根據數據文件集合形成的向量空間模型中文檔向量D,將其采用公鑰Pk加密的方式獲取出對應的{D}Pk,并且把文檔集合運用私鑰加密方式進行加密進一步得出{DS}Ek,最后通過調試系統應用接口層中API接口上傳加密數據文件;
3)Query():在數據庫中檢索用戶向DO申請訪問,如果數據所有者同意該檢索方的申請,將會給出對應的公鑰Pk密鑰Sk以及隱私數據空間Ek,當檢索方進行多關鍵詞檢索時,首先需要將初始檢索向量擴展為目前標準檢索向量Q,并且需要運用公鑰Pk對其進行加密處理獲取出{Q}Pk,這樣即可調試應用接口層提交檢索請求;
4)Score():當隱私數據庫接收到檢索方的申請之后,就會在隱私數據庫中對向量Q和文檔D之間的相關性分數進行計算,并且將每個不相同的計算結果反饋給到存儲客戶端中;
5)TopK():根據上述計算出的相關性分數結果,然后將其結果進行解密計算,此處根據TopK算法進行計算,最后獲取出相關度最高的第K個文檔數據編碼,這樣服務器接收請求就可以從存儲層讀取加密文檔返回給客戶端。
4.1 關鍵詞權重
在信息獲取領域有很多評價文檔的權重模型,根據相關系數計算的基本原理,當一個關鍵字在文檔中出現多次時,即單詞頻率系數越大,如果一個關鍵字出現在更多的文檔中,使用這個關鍵字來區分文檔的作用就更小,應該減少它的含義[7]。增加了關鍵字的個數,減少了每個關鍵字對文檔的區分效果,這些關鍵字的含義應該是平衡的[8]。本文選擇的權重公式如下
ωij=tfij×lnidf
(11)
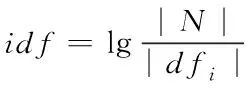
(12)
其中,將ωij描述為多關鍵詞i在隱私數據庫j中的權重取值,tfij表述為多個關鍵詞i出現在文檔中j的次數,而|dfi|則代表了文件結合中包括了關鍵詞 的數據文件數量。
4.2 相關性分數
在對隱私數據進行訪問的過程中,為了能夠讓檢索用戶不費時的收集眾多含有對應關鍵詞的數據文件,本文將采用以下兩方面讓檢索用戶得到更精簡的檢索結果,一方面是根據分級檢索的方法過濾到部分不精準的檢索結果,另一方面是通過添加關鍵字的數量來管控檢索錯誤結果的大概范圍,檢索結果的點數越高,與其對應的檢索結果相關性就會越高。基于此本文將采用了word-frequency逆文件頻率模型,讓數據文件中特殊關鍵字的word-frequency和整個文件集合中關鍵字的反作用頻率來估測文件之間的相關性,這樣便有
(13)
4.3 向量空間模型
由于已給定數據文件中多關鍵詞的權重取值較高[9],因此,本研究將采用向量空間模型來對數據文件中多個關鍵字的權重進行度量,這樣向量模型中與其維度對應的每一個關鍵詞的取值,都將成為該關鍵詞在數據文件中的權重去噪后,如圖2所示。
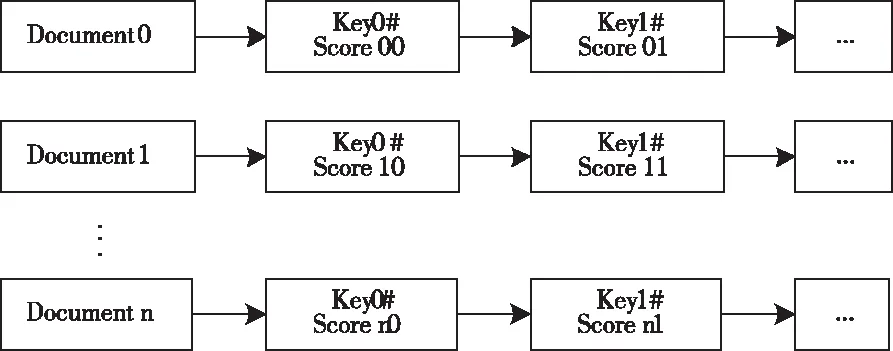
圖2 向量空間模型
根據圖2即可得知,在一般情況下向量空間模型是可以完全符合多關鍵詞檢索條件的,并且可以提供出一個對數據種類沒有實質性要求的系統框架,所以此處本文將運用費布爾量化值來對其權重取值點數進行描述[10],如圖3所示。

圖3 向量空間模型計算諾請求向量
Score=vf·q
(14)
該評分計算方法考慮了文件中檢索關鍵字的總數,即檢索關鍵字越多,相關得分越高。
5 仿真與結果分析
為驗證隱私數據庫多關鍵詞秘密同態檢索方法研究的有效性與適用性,設計如下仿真檢驗過程。將實驗搭建于Microsoft Visual Studio平臺上,隱私數據流大小為1000byte,中心頻率為5 GHz,噪聲增益為-12dB,均衡系數為2.15。
根據上述設定的仿真環境,利用本文方法完成隱私數據庫檢索。終端數據頻譜圖如圖4所示。
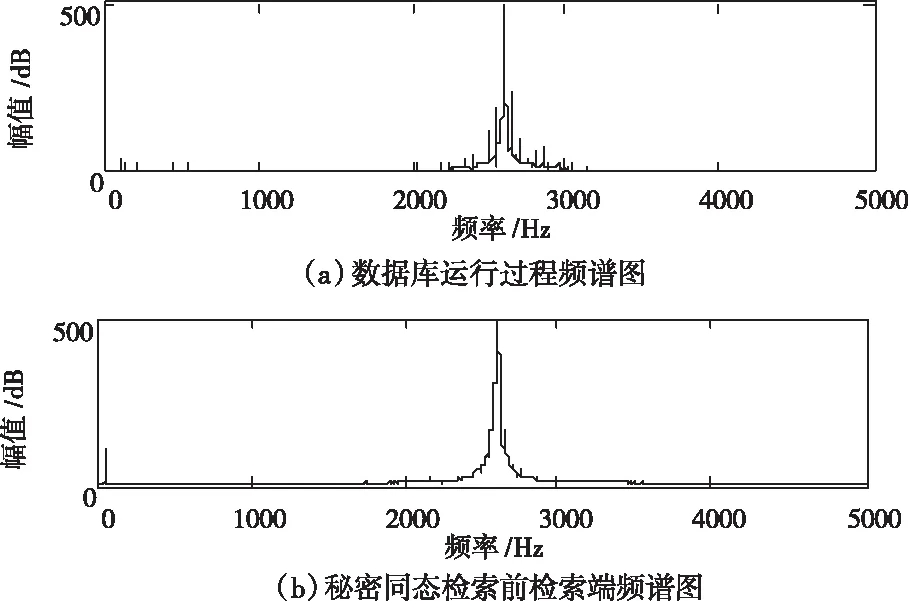
圖4 終端數據頻譜圖
根據圖4所示的終端數據頻譜圖進行多關鍵詞秘密同態檢索,在秘密同態技術的基礎上,將數據庫關鍵詞分為五大模塊,通過相關性分數以及向量空間模型完成索引,得到檢索后的數據頻譜圖如圖5所示。
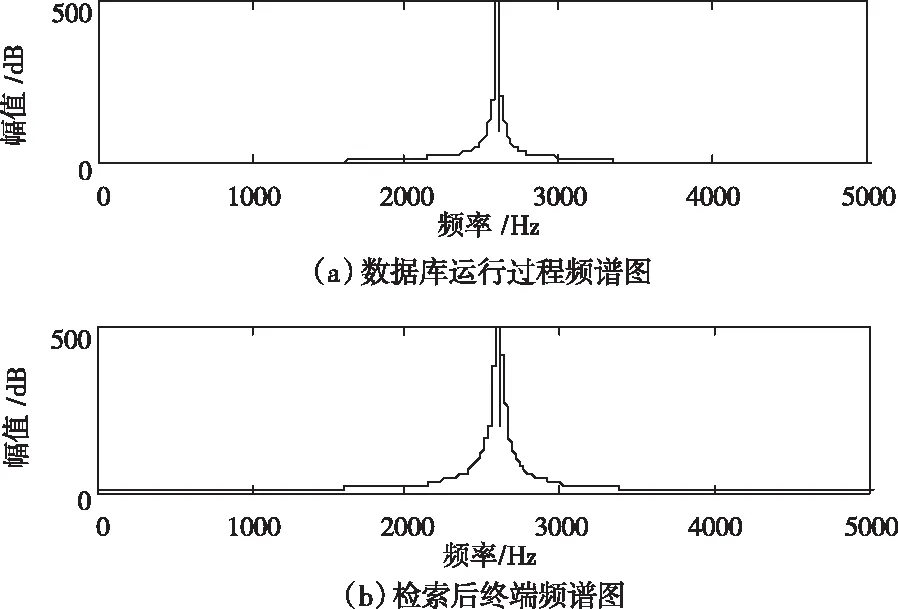
圖5 檢索后終端數據頻譜圖
分析圖5所示結果可知,采用本文方法對 隱私數據庫進行檢索后,檢索結果的輸出性較好,輸出狀態較為平穩,初步證明了本文方法的有效性。
為突出本文方法的應用性能,從檢索時間和穩定性兩個角度,將本文方法與文獻[4]中的基于隱私數據庫的多關鍵詞語義排序檢索方法和文獻[5]中的基于f-mOPE的數據庫密文檢索方法進行性能對比。
實現對比不同方法的檢索過程耗時,結果如圖6所示。
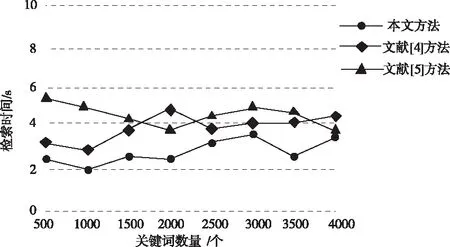
圖6 不同方法檢索過程耗時對比圖
根據圖6所示結果可知,隨著檢索關鍵詞數量的增加,不同方法的檢索過程耗時也在隨之變化,且這種變化沒有規律性。但是,本文方法的檢索過程耗時始終保持較少狀態,最少僅需2s,明顯優于另外2種對比方法。
在此基礎上,指定的初始密鑰集大小為1000byte,不斷增加密鑰集大小,直到其大小達到3500byte,測試該過程中,不同方法的檢索過程耗時,從而判斷不同方法的穩定性。結果如圖7所示。
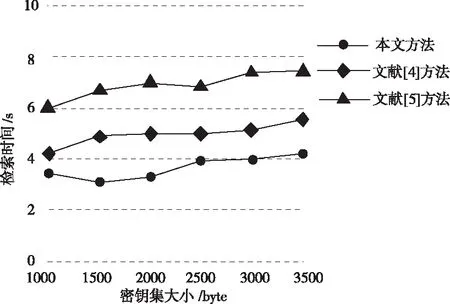
圖7 不同方法檢索過程用時對比
根據圖7所示結果可知,隨著密鑰集大小的增加,不同方法的檢索過程用時也在隨之變化,整體均呈上升趨勢。但本文方法的檢索過程用時始終保持最小狀態,最大的檢索過程用時也僅為4.1s,明顯少于另外2種對比方法。這一結果表明,盡管運行環境在不斷變化,但本文方法穩定性較強,檢索過程始終較快。
6 結論
本研究針對隱私數據庫設計了一種多關鍵詞秘密同態檢索方法,在保證了數據安全性能的同時,根據相關性分數以及向量空間模型構建可搜索索引,從根本上避免了服務器端返回相關度不大的文件。同時,經過仿真結果證明了該方法具有實用性高、計算過程耗時少且穩定性較高的優點,表明該方法具有較好的應用前景。
猜你喜歡
兒童故事畫報(2019年5期)2019-05-26 14:26:14
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
Coco薇(2016年2期)2016-03-22 02:42:52
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
