基于GA-BP神經網絡的雷竹林CO2濃度反演*
2022-05-11 11:53:48侯志康曾松偉莫路鋒周宇峰
林業科學 2022年2期
侯志康 曾松偉 莫路鋒 周宇峰
(1.浙江農林大學信息工程學院 杭州 311300; 2.浙江農林大學環境與資源學院 杭州 311300)
全球森林覆蓋率為32%,森林碳儲量占全球陸地生態系統碳總量的77%。森林生態系統通過同化作用吸收CO2,再以生物量的形式將CO2固定在植被和土壤中,使其成為陸地上最重要的碳匯或碳庫(Attrietal., 2018; 劉平奇等, 2020; 王興昌等, 2015)。森林生態系統通過物理化學的反應過程與大氣進行物質和能量交換,進而對全球氣候變化產生影響,開展森林碳循環監測研究有助于評價未來氣候變化趨勢(Leeetal., 2018; Sasaietal., 2007)。森林碳通量觀測研究已成為當前研究熱點(劉敏等, 2014; 李國棟等, 2013; 陳曉峰等, 2016)。
目前,森林碳通量的觀測方法主要包括微氣象學法、土壤碳儲量清單調查、衛星遙感、大氣CO2濃度反演和建立生態系統模型等(于貴瑞等, 2014; 韋志剛等, 2016; Wilsonetal., 2001)。微氣象學的代表方法是渦度相關法,渦度相關技術也是唯一能直接測定生態系統與大氣間物質能量交換的標準方法,已成為國際碳通量觀測(網絡)的主流技術(張鑫等, 2011)。Ishtiaq 等(2015)通過研究美國落葉林冠層CO2通量與氣候環境變量的相關性后,提出利用環境因素建立碳通量的數據模型,該模型省去了傳統搭建生態系統模型反演碳通量的復雜過程; 王海波等(2014)通過氣象觀測系統研究青藏高原草甸生態系統的碳通量變化特征及其影響因素,認為CO2的濃度與氣象因素具有相關性。搭建環境數據反演碳通量模型是目前最簡便、高效的碳通量研究方法,無需考慮生物量對試驗結果的影響,僅關注于環境數據與反演結果之間的相關性。因此,結合氣象因子和人工神經網絡對碳通量進行反演是可行的。王怡鷗等(2016)利用三元回聲狀態網絡算法對區域CO2濃度進行預測,提高了預測結果的精度,但其弊端在于模擬計算耗時較長; 汪雪等(2017)通過貝葉斯改進人工神經網絡對竹林碳通量進行估算,取得了較好效果。神經網絡的初始權值是隨機分配,因此收斂性能存在不穩定性,并且模型的參數選擇也會對反演結果產生影響(姚仲敏等, 2015; 張宏等, 2014; 王新普等, 2016)。本研究將相關氣象因子作為輸入,引入遺傳分類神經網絡(GA-BP)和參數試湊法對CO2濃度反演進行建模,以克服上述缺點。
本研究以浙江省杭州市臨安區太湖源鎮雷竹(Phyllostachyspraecox)林作為研究對象,研發基于嵌入式的竹林氣象因子實時采集系統,并分析竹林CO2濃度與溫濕度等氣象因子之間的關系,探討基于GA-BP神經網絡的雷竹林CO2濃度反演模型(簡稱GA-BP模型),以期為竹林碳儲量、竹林增匯、竹林固碳能力等研究提供基礎數據。
1 研究區概況
研究區位于浙江省杭州市臨安區太湖源鎮(119°34′104″E,30°18′169″N)國家級自然保護區天目山東麓,其地形為中低山丘陵。氣候類型屬亞熱帶季風氣候: 全年溫暖濕潤,雨熱同期,氣候溫和,雨量充沛。春季以陰雨天為主,夏季濕熱伴有梅雨期,秋季干爽,冬季干冷。全年降水量1 600 mm,年蒸散量800~850 mm,年均空氣相對濕度在80%以上,年均氣溫16 ℃,全年日照時長1 900 h。研究區土壤以紅壤為主,海拔185 m,坡度為東西方向2.5°、南北方向12.5°。
雷竹林群落高7~11 m,胸徑4~6 cm,以2、3年生竹為主,總覆蓋度達80%,立竹密度為22 500株·hm2,竹林林冠郁閉度>0.7,林下灌木草本少,有竹葉及竹筍保溫材料覆蓋,竹林地勢平坦。
2 研究方法
2.1 竹林氣象數據采集
采用渦度相關技術可直接測得生態系統的環境變量,有助于定量理解水、熱和CO2在生態系統中的交換過程,可更深層地理解氣候變化與生態系統之間的相互影響(劉晨峰等, 2009)。本研究基于渦度相關法設計了一套基于嵌入式的森林碳通量數據遠程實時監測系統,該系統主要由嵌入式主控模塊、CO2傳感器(B530)、三位超聲風速儀(Windmater)、大氣溫濕度傳感器(DHT11)、Zigbee通信模塊、GPRS(GTM-900)、數據存儲模塊(AT24C02)、太陽能充電模塊等組成。
監測點實時采集氣象因子數據,通過Zigbee無線傳輸經過無線分組業務,再通過GPRS模塊將數據無線傳輸至后臺服務器,服務器再將數據存儲在后臺數據庫,并在Web網頁上實時顯示,用戶通過平臺查詢和下載數據。碳通量數據監測系統框架如圖1所示。系統主要監測的數據有:CO2濃度、大氣溫濕度、風速和風向等。

圖1 氣象因子數據采集系統框架圖
2.2 數據處理
本研究所用的原始數據來自4個監測點(均布施在通量塔周圍,林冠層蓋度>0.7,監測點位于近地面1.5 m處,同時林地品種單一,下墊面覆蓋有凋零的竹葉及竹筍保溫材料,本試驗排除光照強度及其他植物種生物量等因素的影響),采集時間為2019年10—11月(此時當年生新竹已經成熟,光合速率和呼吸速率穩定)。因電源斷電及儀器短期故障等因素而導致的某個時間段內丟失的部分氣象數據,采用高斯模糊插值法恢復。試驗選取每5 min采集的CO2濃度及溫濕度等氣象數據平均值作為建模所用的數據集。試驗數據分為4組,每組1 200個數據樣本,其中80%作為訓練集, 20%作為測試集。
一般而言,確定某個事象概念需要訴諸邏輯學中演繹、歸納等方法。一個概念的完整界定分為內涵和外延。前者是指某個概念所含括的思維對象的特有屬性總和;后者是指該概念所含括的思維對象的數量或范圍。二者的關系為,內涵越大越豐富,相應的外延則越小,反之亦然。人們在對世界的認識中,將事物、事件或事實劃分成類和屬,并確定它們之間的包含關系和排斥關系。根據邏輯學中“類層級結構”思維:任何事物都是世界事物結構中某一層級某一類中的一個單體。人腦在按照內涵、外延的“親和性”層級歸屬進行分類建構的同時,還要依據它們之間歷史運動的關系。
森林生態系統碳通量表示生態系統中單位時間單位面積上碳增減的數量(PgC·a-1)。森林生態系統碳循環過程由兩部分組成: 光合作用將CO2固定進入生態系統;自養呼吸將CO2釋放進入大氣。在森林生態系統中,地面與大氣間的碳通量成分由空氣中的微量成分CO2和痕量成分CO、CH4等組成,在測量的過程中發現痕量成分CO、CH4等與CO2存在數量級上的差距,且大氣中痕量成分的含量是默認不變的。因此,本研究以CO2濃度作為碳通量的研究對象,將痕量成分忽略。
影響CO2濃度的環境因素很多。研究環境參數與CO2濃度的相關性有利于模型參數的選取分析。本研究首先對CO2濃度與各環境參數進行了相關性分析。
2.3 反演模型建立
本研究將基于傳統BP神經網絡和基于GA-BP神經網絡的CO2濃度反演方法進行對比分析。GA-BP模型克服了傳統基于BP神經網絡反演CO2濃度模型(簡稱BP模型)的一些不足,其通過種群初始化、計算適應度、選擇、交叉、變異、搜索等操作得到最優的初始化權值和閾值傳遞給BP神經網絡,從而糾正神經網絡易陷入局部極小值和網絡收斂速度慢的缺點,同時可以提高模型的精確度。
GA-BP神經網絡的結構分為輸入層、隱含層和輸出層。輸入層的節點數量取決于輸入參數的種類。隱含層的節點數量決定了神經網絡的訓練時間和預測精度,其節點數的選取首先根據公式(1)~(3)確定范圍,再利用試湊法進一步選擇,最后確定最佳的節點個數。
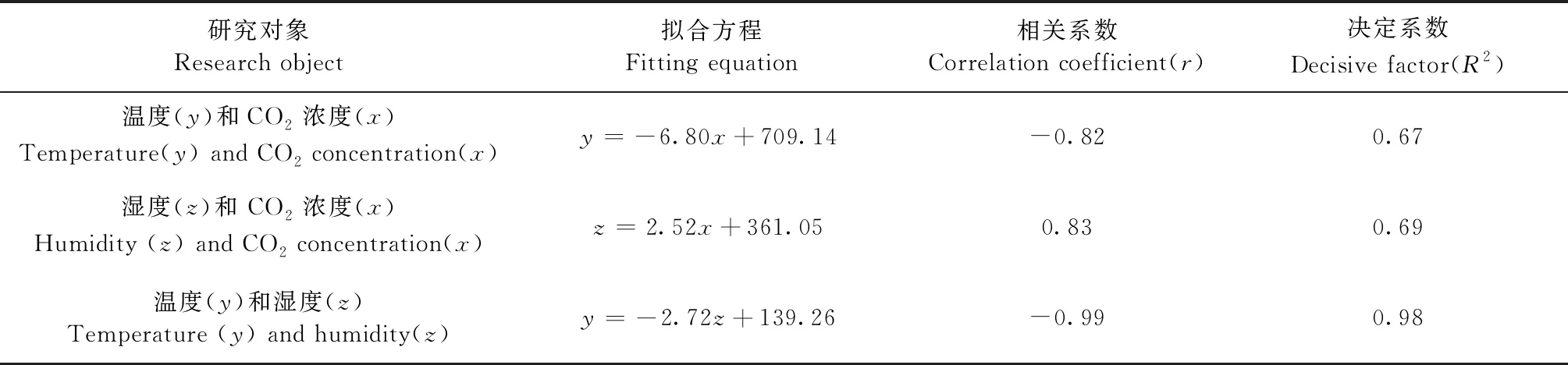
l (1) (2) l=log2n。 (3) 式中:n為輸入層節點數;l為隱含層節點數;m為輸出層節點數; a為0~10之間的常數。 通過遺傳算法的選擇、交叉和變異操作,在神經網絡的初始權值和閾值種群中進行全局搜索,找到適應度最優的權值和閾值傳遞給BP神經網絡,最終通過BP神經網絡算法局部尋優計算得到最優解。算法流程如下。 1) 種群初始化: 將輸入參數的原始數據轉換成二進制編碼,隨機組成初始種群。 2) 適應度尋優: 根據個體得到BP神經網絡的初始權值和閾值,傳遞進入BP神經網絡進行模型訓練,按誤差絕對值大小尋找最優適應度的函數值。 3) 訓練: 經過適應度尋優、選擇、交叉、變異的多次迭代,最終滿足程序終止條件,模型訓練完成。 4) 數據輸出: 將輸入參數帶入模型,輸出具有最大適應度的反演數據作為結果。 建模時,每組試驗在相同條件下重復10次,試驗結果取平均值。另外,由于影響碳通量的各環境參數之間的數值范圍和單位相差很大,這對模型訓練和預測效果會產生顯著影響。因此,在試驗前對數據進行歸一化處理。 為了驗證模型的穩定性和精度,本研究采用決定系數(R2)、平均絕對誤差(mean absolute error,MAE)、均方根誤差(root mean square error,RMSE)、平均百分比誤差(mean absolute percentage error,MAPE)和標準偏差(standard deviation,StdDev)這5個指標對模型進行評價。模型的決定系數R2越大,MAE、MAPE和RMSE值越小,模型StdDev與實測值的StdDev越接近,說明模型的反演準確度越高。相關公式如下: (4) (5) (6) (7) (8) 所采集的氣象因子中,溫度和濕度對CO2濃度具有明顯的強相關性,同時濕度與CO2濃度之間的相關性略強于溫度與CO2濃度之間的相關性。溫度、濕度與CO2濃度間的相關性分析結果見表1。 溫度與 CO2濃度之間呈負相關,相關系數r為-0.82,決定系數R2為0.67; 濕度與 CO2濃度之間呈正相關,r為0.83,R2為0.69; 溫度和濕度之間呈強負相關,r達到-0.99,R2為0.98。 表1 溫度、濕度和CO2濃度間的相關性 由圖2可知,BP模型能夠有效反演CO2濃度,BP模型的反演值與實測值變化趨勢基本相符,但兩者間的某些樣本數據存在明顯誤差。相較于前者,基于GA-BP模型的反演結果與實測數據的誤差明顯減小。 2種反演模型的比較結果見表2,實測值的標準偏差為26.99 mg·m-3,BP模型反演結果的標準偏差是24.71 mg·m-3,而GA-BP模型反演結果的標準偏差為26.51 mg·m-3,GA-BP模型反演結果的標準偏差與實測值的誤差更小。綜上所述,GA-BP模型反演結果與實測值的離散程度更接近。 圖2 2種模型反演值與實測值對比 對BP模型和GA-BP模型的反演結果進行交叉驗證,結果如圖3所示。BP模型的R2為0.79,表明BP模型對CO2濃度的反演結果可靠,反演結果能整體上表現出CO2濃度的變化趨勢。但是,其反演結果與實測值之間存在較大誤差,BP模型反演結果的不穩定。而GA-BP模型的R2相較于BP模型有顯著提高,R2從0.79上升到0.86,較優化前提高了6%。GA-BP模型的擬合效果更好,反演值與實測值的相關性更強,利用GA-BP模型對CO2濃度反演的結果更接近實測結果。 表2 CO2濃度實測值及BP模型和GA-BP模型反演結果 圖3 BP模型和GA-BP模型的交叉驗證結果 BP模型和GA-BP模型反演驗證結果如表3所示: GA-BP模型反演結果的MAE為8.12 mg·m-3,較BP模型反演結果的10.91 mg·m-3低2.79 mg·m-3; 前者的MEAP為0.84%,而后者的MAPE為1.17%; 同時,前者將RMSE從14.22 mg·m-3優化到10.82 mg·m-3,這表明GA-BP模型的反演值與實測值之間的偏差范圍小于BP模型,GA-BP模型反演結果的準確性更高。通過比較模型的5種評價指標發現,GA-BP模型相較BP模型在CO2濃度反演上具有更優的表現。 表3 BP模型和GA-BP模型反演結果驗證 影響CO2濃度反演結果的因素主要有2個: 一是算法本身導致的誤差,主要是建模時數據采集不完整或模型參數選擇不當產生的誤差(王曉輝等, 2021); 二是相關氣象因子選擇的遺漏導致的誤差(范德成等, 2021)。本研究提出基于GA-BP的CO2濃度反演模型首先通過GA優化得到最優的網絡初始權值和閾值,再利用試湊法確定最優的網絡節點數,有效提高了反演模型的精度,減少了誤差。在控制樣本選擇誤差方面,與王楷等(2014)利用草原環境因子對碳含量進行預測相比,本研究選取10—11月份的成熟雷竹林作為研究對象,充分利用了竹林生態環境的穩定性,滿足GA-BP模型需要穩定可靠的氣象因子作為輸入的建模條件,減少了可能存在的選擇誤差。本試驗結果表明,實測值與反演值的百分比誤差為0.84%,說明GA-BP模型的CO2濃度反演效果優良。 本研究提出GA-BP神經網絡反演算法不僅適用于CO2濃度的反演,根據其模型特點也可以推廣至生態環境監測領域其他環境參數的反演,這既可以簡化系統也可以降低相關監測系統的硬件成本。但本研究依然存在一些局限性,如受到試驗環境、儀器精度和時間等限制,也未考慮到其他碳匯相關因子的影響,在后續研究中,還需考慮時空、研究區內灌木和草本的生物量等因素的影響。 利用竹林氣象因子采集系統可獲取相關氣象數據;基于CO2濃度與溫濕度等氣象因子之間的相關性,本研究提出的基于GA-BP神經網絡的CO2濃度反演模型能夠有效反演該研究區的CO2濃度。
2.4 模型評價指標

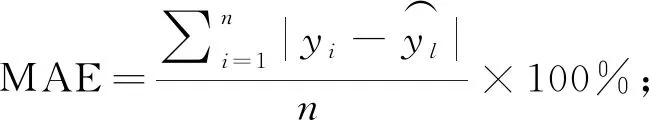

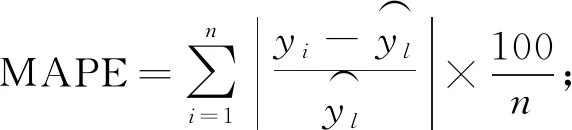
3 結果與分析
3.1 環境因子與CO2濃度相關性分析
3.2 GA-BP反演結果分析

3.3 模型評價分析



4 討論
5 結論
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
天津外國語大學學報(2021年3期)2021-08-13 08:32:18
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
科技傳播(2019年22期)2020-01-14 03:06:54
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
汽車工程學報(2017年2期)2017-07-05 08:13:02
光學精密工程(2016年6期)2016-11-07 09:07:19
