基于相似性的CITCP強化學習獎勵策略①
2022-05-10 02:29:42潘超月曹天歌
計算機系統應用 2022年2期
楊 羊,潘超月,曹天歌,李 征
(北京化工大學 信息科學與技術學院,北京 100029)
1 引言
持續集成環境允許代碼頻繁地集成到主干上以進行軟件的更改[1].持續集成測試用例優先排序針對每次集成連續地進行測試用例執行序列的調整,以保障持續集成的每次修改沒有引入新的錯誤[2].基于強化學習的持續集成測試用例優先排序技術[3],通過歷史經驗的學習自適應地進行測試用例優先排序策略的調整,以適應持續集成環境的變化,其框架被定義為reinforced test case selection (RETECS).
強化學習與持續集成測試用例優先排序的交互如圖1所示.強化學習主要包括環境、智能體、動作和獎勵4 個元素[4].針對持續集成測試用例優先排序,環境是持續集成周期,環境中的狀態是在每一集成周期提交的測試用例的元數據,包括測試用例預計運行時間和測試用例歷史執行結果等;智能體是依據歷史經驗進行測試用例優先排序決策的中樞;動作是智能體根據歷史學習的策略進行當前持續集成周期測試用例優先級排序結果的返回;獎勵是對當前測試用例優先排序策略的反饋,通過評價當前集成周期測試用例執行結果以實現獎勵.
強化學習是一種基于獎勵機制的機器學習方法,核心是通過獎勵函數對當前行為進行有效的評估,并反饋給智能體選擇合適的后續行為,以實現期望的最大化.基于強化學習的持續集成測試用例優先排序技術,通過對測試用例實施獎勵以實現測試用例優先排序策略的調整,從而最終提高持續集成測試用例優先排序的質量.測試用例的獎勵包括獎勵函數設計方法和獎勵對象選擇策略.Yang 等人[5]系統化研究了獎勵函數設計方法,提出了基于歷史信息的獎勵函數,通過提取測試用例歷史信息序列的特征以實現測試用例檢錯能力的度量,可以實現測試用例優先排序效果的優化.
獎勵對象選擇策略通常選擇執行失效測試用例作為獎勵對象實施獎勵.然而,實際工業軟件持續集成測試具有集成高頻繁和測試低失效的特點.例如,在Google開源數據集GSDTSR 中,共集成336 個周期,其中284個周期存在執行失效,涉及5 555 個測試用例的1 260 618次測試執行,其中失效執行只占0.25%.在基于執行失效的獎勵對象選擇策略下,持續集成測試的低失效會引發獎勵對象稀少,從而導致強化學習獎勵稀疏問題,減緩了強化學習速度,甚至可能導致智能體生成高隨機的策略[6],難以真正應用于實際工業生產環境中.如何解決基于強化學習的持續集成測試用例優先排序技術在實際工業環境中產生的獎勵稀疏問題,是本文的研究重點.
獎勵稀疏問題的核心是獎勵對象稀少,可以通過增加獎勵對象來解決獎勵稀疏問題.測試用例優先排序旨在優先執行潛在失效測試用例.當前執行失效的測試用例,基于失效測試與測試失效的相關性[7],在后續測試執行中具有較大的失效可能性,該理論不適用于執行通過的測試用例.在測試用例優先排序中考慮測試用例之間的依賴關系,理論上會使排序結果更優,但依賴性分析特別是大規模程序的依賴性分析是一個非常耗時的過程,難以滿足持續集成測試的快速反饋需求.在測試用例優先排序中考慮測試用例之間的相似關系,即基于相似性的測試用例優先排序[8],通過測試用例間的相似性度量,優先執行有相同特征的測試用例,可以有效提高測試序列的檢錯能力.因此,本文基于相似測試用例的假設,提出一種測試用例相似性的度量方法,并選擇與失效測試用例集相似的通過測試用例實施獎勵,以解決獎勵對象稀少導致的強化學習獎勵稀疏問題.
根據集成測試的快速反饋需求,Bagherzadeh 等人[9]認為持續集成測試用例優先排序的最優序列為檢錯能力高并且執行時間短的序列,即優先執行檢錯能力高的測試用例,在相同的檢錯能力下優先執行運行時間短的測試用例.因此,本文針對測試用例相似性度量考慮以下兩個因素.首先,測試用例的歷史執行信息序列相似的測試用例具有相似的檢錯能力,即兩個測試用例在歷史執行過程中執行結果相似,在后續測試中執行結果可能相同.所以選擇與失效測試用例歷史執行信息序列相似的執行通過測試用例實施獎勵,有助于在后續測試中提升高檢錯能力測試用例的執行順序.其次,在第一個條件的基礎上,具有相似執行時間的測試用例有利于優化測試執行時間,從而提升反饋速度.
本文通過歷史信息序列特征和執行時間設計了一個多維度相似性度量方法,通過增加獎勵與執行失效測試用例相似的執行通過測試用例,解決強化學習獎勵稀疏問題,從而實現基于強化學習的持續集成測試用例優先排序技術在實際工業界的應用.最終,在大規模工業數據集上驗證了基于強化學習的持續集成測試用例優先排序在基于相似性的獎勵對象選擇策略下的有效性.
2 基于相似性的獎勵對象選擇策略
基于強化學習的持續集成測試用例優先排序通過歷史經驗的學習,盡可能多地獎勵潛在失效測試用例,通過測試用例優先排序策略的調整以實現在后續測試中優先執行失效測試用例.基于失效測試與測試失效的相關性[7],當前執行失效測試用例在后續測試中具有更大的潛在失效可能性,智能體對其實施獎勵有助于提高測試用例優先排序效果.然而實際工業程序中低失效的持續集成測試導致基于強化學習的持續集成測試用例優先排序獎勵對象稀少,即獎勵稀疏,減緩了強化學習的速度,甚至形成難以收斂的高隨機策略.
為了解決強化學習的獎勵稀疏問題,在獎勵失效測試用例的基礎上,基于測試用例相似性假設[8],本文針對執行通過測試用例與執行失效測試用例進行相似性分析,從而實現對執行通過測試用例實施獎勵,并提出基于相似性的獎勵對象選擇策略.
2.1 持續集成測試用例特征分析
基于相似性的測試用例優先排序技術在回歸測試中證明了存在相似性的測試用例擁有相似的錯誤檢測率[8],并且具有潛在失效可能的測試用例傾向于聚集在連續的區域[10].
相似性度量的概念是許多研究領域的研究主題.兩個物體共有特征的程度被稱為相似性,它們不同的程度被稱為距離.許多軟件測試文獻量化了測試用例之間的相似性,例如在基于覆蓋的測試優化中,使用覆蓋信息進行測試用例之間相似性的度量[11].測試用例的相似性度量因素還涉及測試路徑[12,13]、測試用例相關源代碼[14]、測試輸入和輸出[15]、從測試腳本中提取的主題模型[16]、測試用例的歷史失效信息[17]等.
在基于強化學習的持續集成測試用例優先排序中,智能體根據歷史學習的策略針對測試用例元數據進行識別以產生測試用例優先排序結果.測試用例元數據通過持續集成測試日志的提取,包括Cycle、ID、Duration、LastRun、LastResults和Verdict,這些屬性及其解釋如表1所示.

表1 測試用例元數據
針對在同一周期的測試用例,根據當前執行結果的不同,即Verdict的不同,可以有效地識別失效測試用例對被測系統的失效影響.對于執行通過測試用例,基于Verdict 無法度量其失效影響,然而其歷史執行結果LastResults 可以描述其在歷史執行過程中的失效情況.針對歷史執行過程相似的測試用例,其在未來執行中可能有相同的測試結果.因此,可以基于測試用例的歷史執行過程進行測試用例的相似性度量.
持續集成測試是一種黑盒測試方法,在快速反饋需求下,基于黑盒測試的測試用例執行時間,在相近測試內容下其執行時間非常接近.測試用例優先排序旨在優先執行潛在失效測試用例.在實際工業程序中,潛在失效的測試用例可能與執行失效測試用例不完全相同,但是非常相似,例如,當新測試用例是舊失效測試用例的修改版本時,新測試用例可以捕捉未檢測到的系統故障,但是當前執行通過.新測試用例與舊測試用例的執行時間Duration 非常接近或者相同.因此新測試用例由于與舊測試用例相似,并且具有類似的執行時間,具有相似的失效影響,在后續測試中應該被優先執行.
基于測試失效的假設,失效測試用例對被測系統具有失效影響,智能體對其實施獎勵.本文通過提取測試用例的歷史執行信息序列LastResults 與測試執行時間Duration 進行執行通過測試用例與執行失效測試用例集的相似性度量,以識別執行通過測試用例集中具有失效影響的測試用例,從而實現獎勵的實施.
2.2 測試用例相似性度量方法
測試用例的相似性度量,通過提取測試用例的特征以實現測試用例間的相似性計算.本文針對持續集成測試用例使用歷史執行信息序列LastResults和執行時間Duration 信息,進行測試用例的特征向量定義,如定義1 所示.
定義1.測試用例的特征向量(feature vector of test case).
其中,totalTimei表示持續集成i周期的計劃執行時間,t.durationi表示測試用例t在i周期的執行時間,是測試用例t在i周期執行時間的歸一化,t.lastresultsi表示測試用例t在i周期測試執行后的歷史執行信息序列.
測試用例的特征向量通過測試用例的特征提取以實現測試用例間的相似性度量.本文通過測試用例的歷史執行信息序列和執行時間的屬性,進行測試用例的特征提取,定義了測試用例的特征向量,并進一步根據特征向量進行兩兩測試用例間的特征距離計算以實現相似性計算.
相似性函數通過兩兩測試用例間的特征距離計算以度量測試用例相似程度.相似性距離計算的常用方法包括杰卡德距離[11]、Gower-Legendre[18]、Sokal-Sneath[19]、歐氏距離[20–22]、余弦相似性[23]和比例二進制距離[21,24,25]等.Wang 等人[26]通過深入研究了這6 種常用相似性計算公式對基于相似性的測試用例優先排序效果的影響,研究表明歐氏距離比其他相似性距離計算公式更有助于進行測試用例優先排序,從而更有效地發現程序錯誤.因此,本文采用歐氏距離進行持續集成測試的測試用例相似性函數計算,通過特征向量的逐一比較實現測試用例的相似性度量,其相似性計算函數如定義2 所示.
定義2.測試用例相似性函數(test case similarity,TCS).
其中,t1表示執行通過測試用例,t2表示執行失效測試用例,Featurei(t1j)表示測試用例t1在第i集成周期的特征向量的第j個特征,n是測試用例t1和t2的最短有效歷史執行序列長度.由于在持續集成測試中測試用例出現的頻率不同,導致測試用例的歷史執行信息序列長度不同.為了有效地進行特征向量的比較,基于失效測試與測試失效的相關性[7],本文依據測試用例中歷史信息序列較短的序列長度,選擇臨近歷史信息序列進行相似性的計算,從而實現全面測試用例相似性比較.
測試用例相似性函數通過兩兩測試用例的特征向量距離計算,以實現測試用例的相似性度量.距離越小,即相似性值越低,表明這兩個測試用例越相似.
2.3 基于相似性的獎勵對象選擇方法
基于失效測試與測試失效的相關性[7],失效測試用例具有較高的檢錯能力,在后續測試中需要進行優先級的提升,因此智能體優先對失效測試用例實施獎勵以實現測試用例優先排序策略的調整,使其適應后續持續測試.然而,持續集成測試的低失效特征,即失效測試執行稀少,導致基于強化學習的持續集成測試用例優先排序獎勵對象稀少,導致獎勵稀疏問題,影響了強化學習的學習速度和學習質量.
在持續集成測試中,對于當前執行通過測試用例,一方面存在頻繁失效、偶然通過的測試用例,另一方面存在測試用例是舊測試用例的修復版本.這些測試用例在后續測試中存在失效可能性,因此具有一定的失效影響,然而無法基于當前執行結果進行有效的度量.為了有效度量執行通過測試用例的失效影響,本文通過與執行失效測試用例的相似性分析,以選擇執行通過測試用例集中與執行失效測試用例相似的測試用例實施獎勵,進一步提出基于相似性的獎勵對象選擇策略.智能體針對執行通過測試用例,使用與執行失效測試用例的相似性分析方法,實現執行通過測試用例的失效影響分析,從而增加獎勵與執行失效測試用例相似的執行通過測試用例.
針對在某一集成周期的測試用例集,在測試執行后,智能體首先對失效測試用例進行獎勵,進一步將執行通過測試用例逐一與失效測試用例集進行相似性分析以尋找具有失效影響的執行通過測試用例.若執行通過測試用例與執行失效測試用例存在相似性,則該執行通過測試用例具有失效影響,智能體應該獎勵該測試用例,否則執行通過測試用例不被獎勵.其執行流程如圖2所示.根據其執行過程,本文進一步定義了基于相似性的獎勵對象選擇策略如定義3 所示.
定義3.基于相似性的獎勵對象選擇策略(similaritybased reward object selection strategy).
對于第i個周期的測試套件Ti={t1,t2,…,tj,…,tn},如果測試用例tj執行失效,則獎勵測試用例tj;若測試用例tj執行通過,但測試用例tj與Ti中的失效測試用例t′存在相似性,即則獎勵測試用例tj;其他情況智能體不獎勵測試用例.
基于相似性的獎勵對象選擇策略的獎勵方式,如式(3)所示.
其中,rewardvalue是基于任意獎勵函數計算的測試用例的獎勵值,t.verdict表示測試用例t的執行結果,1 表示執行失效,0 表示執行通過,t′是該周期中任意執行失效測試用例.
本文通過持續集成測試用例的特征分析,提出考慮測試用例歷史執行信息序列和執行時間的多維度測試用例特征向量表示方法,并進一步基于特征向量進行測試用例間的相似性度量.基于測試用例的相似性特征,本文提出基于相似性的獎勵對象選擇策略,在獎勵失效測試用例的基礎上,通過相似性的判斷,自適應地選擇執行通過測試用例進行獎勵以解決在實際工業程序中的獎勵稀疏問題.
3 實驗設計及結果分析
基于強化學習的持續集成測試用例優先排序過程如圖3所示,其中虛線部分存在于持續集成環境中,實線部分存在于強化學習框架中.對于每個集成周期中提交的測試用例集,強化學習的智能體根據歷史學習的測試用例優先排序策略定義測試用例的優先級,進一步根據快速反饋的時間約束選擇測試用例以進行測試排序從而實現測試執行,最后根據執行結果進行評價并反饋給開發人員和強化學習的智能體.智能體根據反饋的結果選擇測試用例實施獎勵,即獎勵對象選擇策略,并進一步根據獎勵的結果為后續集成測試調整測試用例優先排序策略,使其適應于持續集成系統的連續變化.
3.1 研究問題
本文針對在實際工業程序存在集成高頻繁但是測試低失效的特征,在基于強化學習的持續集成測試用例優先排序中研究獎勵對象稀少導致強化學習的獎勵稀疏問題,提出基于相似性的獎勵對象選擇策略.本文從以下3 個研究問題進行實驗的分析和驗證.
問題1.在基于相似性的獎勵對象選擇策略中,如何進行相似性閾值的選取,從而實現持續集成測試用例優先排序?
問題2.基于相似性的獎勵對象選擇策略對基于強化學習的持續集成測試用例優先排序質量的影響如何?
問題3.基于相似性的獎勵對象選擇策略對基于強化學習的持續集成測試用例優先排序框架的時間開銷影響如何?
問題1 通過不同閾值下基于相似性獎勵對象選擇策略對測試用例優先排序效果的影響研究,選擇適合目標程序的最佳閾值.問題2 通過基于相似性的獎勵對象選擇策略與基于執行失效的獎勵對象選擇策略進行測試用例優先排序質量的對比,驗證基于相似性的獎勵對象選擇策略的有效性.問題3 是對不同獎勵對象選擇策略下的框架時間開銷進行對比.
3.2 評價指標
本文為了比較不同獎勵對象選擇策略,在基于強化學習的持續集成測試用例優先排序下對持續集成測試用例優先排序效果通過NAPFD (normalized average percentage of faults detected),TTF (test to fail),Recall和時間開銷4 個評價指標進行度量.
(1)NAPFD
平均歷史檢測率(APFD,average percentage of faults detected)[27]作為測試用例優先排序效果評價的有效方法,在檢測到序列中所有錯誤的假設下,根據測試序列中失效位置的索引進行測試序列的評價.然而,基于強化學習的持續集成測試用例優先排序,使用測試用例選擇的快速反饋機制模擬,使得只有占一半執行時間的測試用例被執行,即存在失效的測試用例不被執行.由于APFD 只適用于可以檢測到所有錯誤的測試用例序列,即不存在測試用例選擇.因此,Qu 等人[28]于2007年提出APFD的擴展NAPFD,根據實際檢測錯誤率來進行失效分布的計算,適用于存在測試用例選擇的測試用例優先排序序列.
NAPFD 作為測試用例優先排序的評價標準[28],其定義為:
根據NAPFD的定義,在持續集成測試中,如果所有的錯誤均被檢測到,則p=1,NAPFD 與APFD 等同;如果存在錯誤未被檢測到,則p<1,基于NAPFD的評價更符合實際情況.
(2)TTF
TTF 根據測試執行中首次執行失效的測試用例在測試序列中的位置進行評價.測試用例優先排序的目標是優先執行失效測試用例.失效位置越靠前,測試用例優先排序效果越好.因此,TTF 可以有效地評價測試用例優先排序的效果.TTF 值越小,即執行失效測試用例在執行序列中位置越靠前,則測試用例優先排序的效果越好.
(3)Recall
為了有效地評價持續集成測試用例優先排序的質量,引入Recall 來評價每一周期實際檢測到錯誤的比例.Recall 根據測試執行序列中實際檢測錯誤與集成周期內實際存在錯誤的比重進行度量.Recall 在測試選擇的基礎上,計算占總執行時間一半的測試用例集檢測到的錯誤占該周期實際總錯誤的比例.Recall 值越高,則執行序列檢測的錯誤越多,相應的測試用例優先排序效果越好.
(4)時間開銷
時間開銷作為測試用例優先排序技術的重要評價指標,對算法的執行效率進行評價.針對基于強化學習的持續集成測試用例優先排序技術,其時間開銷包括獎勵計算的時間、智能體的學習時間、測試用例執行信息的更新時間和測試用例優先排序的時間等.
3.3 實驗對象及設計
本文針對個6 工業數據集進行相關實驗,其中IOF/ROL、Paint Control和GSDTSR為Spieker 等人[3]研究中所使用的數據集,Rails為開源工業數據集(http://gihub.com/elbum/CI?Datasets.git),其他2 個數據集為研究者共享的持續集成測試日志(https://travistorrent.testroots.org/buildlogs/20-12-2016/).測試用例是唯一識別碼,在持續集成的不同周期中測試不同的組件,并記錄了相關的測試執行結果.表2列出了6 個工業數據集的持續集成測試的詳細信息,包括測試用例數、持續集成周期數、持續集成測試執行結果數、持續集成失效率和頻率.集成周期不僅給出了持續集成的周期數,并標注了實際測試過程中失效周期數,執行結果數強調的是在整個持續集成過程中測試執行總數,失效率表示持續集成測試過程中測試失效占總測試執行的比例,頻率統計了測試用例在每一周期進行測試的概率.
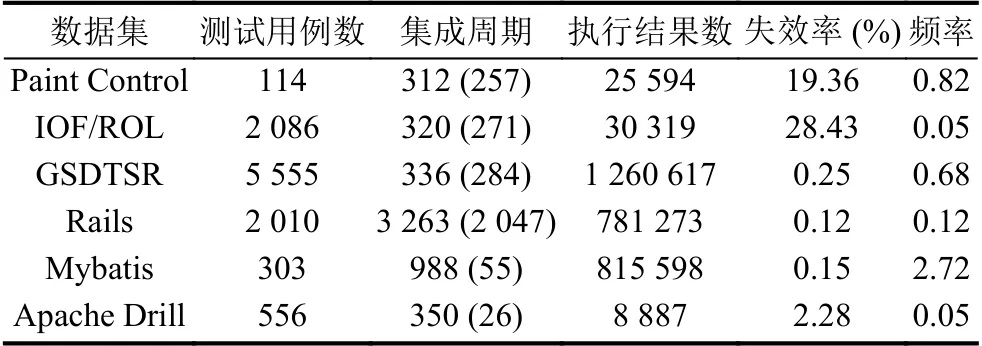
表2 工業數據集信息
在基于強化學習的持續集成測試用例優先排序中,獎勵函數設計方法采用目前最優的基于歷史信息的獎勵函數[5],即基于平均歷史失效分布的獎勵函數APHF(average percentage of historical failure).在實際工業數據集中,針對龐大歷史信息,本文使用滑動窗進行臨近歷史信息的特征選取[29],即通過提取臨近歷史信息的特征以實現獎勵計算效率的提升.本文基于持續集成測試的連續變化,采用基于動態滑動窗的臨近歷史信息選擇方法,即滑動窗尺寸隨著持續集成測試進程動態變化,以實現自適應的獎勵計算[30].
3.4 實驗結果及分析
本小節分別針對3 個研究問題進行實驗結果的展示及分析.
3.4.1 測試用例相似性閾值選取分析
本小節針對問題1 進行實驗分析.測試用例相似性通過測試用例之間的特征匹配以實現相似性度量.在基于相似性的獎勵對象選擇策略中,使用執行通過測試用例與執行失效測試用例進行相似性對比,從測試歷史執行信息序列和測試執行時間角度進行多維度特征匹配,從而確定智能體是否對執行通過測試用例進行獎勵.由于工業數據集存在不同的失效率、測試頻率等特征,在具體數據集中相似性閾值的不同,會導致不同的獎勵對象數量,從而產生不同的測試用例優先排序效果.因此需要針對不同的數據集進行相似性閾值的選取分析.
首先對工業數據集進行相似性特征分析,即基于相似性度量方法進行測試用例相似性指標值的分析,圖4統計了在6 個數據集上進行測試用例相似性值分析的具體分布情況,針對具體數據集,縱坐標表示基于相似性計算獲得的相似性值.由于在不同數據集上測試用例的執行過程和結果不同,導致相似性值的范圍不同,并且相似性值存在較多的異常數據,因此為了更好地確定適用于不同數據集的相似性閾值,本文首先依據相似性值的分布針對具體數據集選取相似性值分布的下四分位數、中位數和上四分位數作為基于測試用例相似性的獎勵對象選擇策略閾值,其統計結果如表3所示.
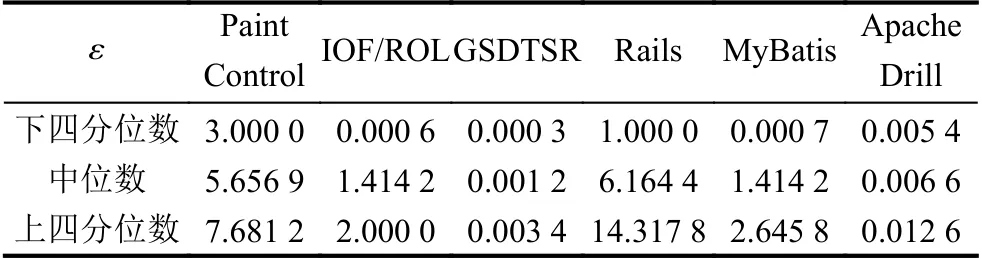
表3 針對工業數據集的測試用例相似性閾值ε 選取
進一步在基于強化學習的持續集成測試用例優先排序中依據基于相似性的獎勵對象選擇策略,使用不同的相似性閾值進行基于強化學習的持續集成測試用例優先排序,并使用NAPFD 指標進行持續集成測試用例優先排序質量的評價,并實現不同閾值的測試用例優先排序效果的對比,其結果如表4所示,其中加粗字體標注了在該閾值下可以取得最好的NAPFD 值.
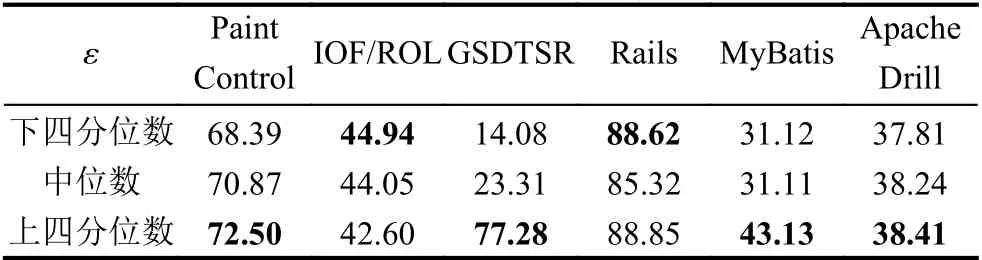
表4 基于不同相似性閾值選取的持續集成測試用例優先排序NAPFD 值(%)
相似性閾值的選取,決定了在基于強化學習的持續集成測試用例優先排序中增加獎勵的執行通過測試用例的數量.增加獎勵的數量過多,反而會降低失效影響大的執行通過測試用例的優先級;而增加獎勵的數量過少,導致部分失效影響大的執行通過測試用例無法獲得有效的獎勵,從而降低測試用例優先排序效果.
因此針對6 個數據集,本文根據NAPFD的結果對比分別選取Paint Control的7.681 2、IOF/ROL的0.000 6、GSDTSR的0.003 4、Rails的1.000 0、MyBatis的2.645 8和Apache Drill的0.012 6 作為基于相似性的獎勵對象選擇策略的相似性閾值,以實現在有效的獎勵數量增加下獲得測試用例優先排序效果優化,為后續實驗及分析奠定基礎.
3.4.2 基于相似性的獎勵對象選擇策略有效性分析
本小節針對問題2 進行實驗分析.基于相似性的獎勵對象選擇策略,在獎勵失效測試用例的基礎上,通過相似性分析自適應地選擇執行通過測試用例實施獎勵,從而實現獎勵對象數量的增加以解決獎勵稀疏問題.在基于強化學習的持續集成測試用例優先排序中,本文采用相同的獎勵函數設計方法APHF,通過不同獎勵對象選擇策略,即基于執行失效的獎勵對象選擇策略(APHF_P)和基于相似性的獎勵對象選擇策略(APHF_S),在NAPFD、Recall和TTF 三個指標下進行測試用例優先排序質量的對比.實驗結果如表5所示,其中加粗數據部分標注了在基于相似性的獎勵對象選擇策略下,測試用例優先排序評價指標值優于基于執行失效的獎勵對象選擇策略的情況.
根據表5所示的實驗結果,從整體平均上來看,基于相似性的獎勵對象選擇策略在不同的評價指標上均可以有效地進行指標值的提升,NAPFD 可以獲得5.94%的提升,Recall 可以有效地改進5.51%的錯誤檢測率,并且在TTF 上可以有效地提升57.42 個失效測試用例在測試序列中首次執行失效的位置.針對具體數據集的分析可以看出,在6 個數據集上,基于相似性的獎勵對象選擇策略可以有效改進4 個數據集的測試用例優先排序質量,尤其在GSDTSR 中可以明顯提升34.51%的NAPFD 值、34.13%的Recall 值和293.15位的TTF.
在基于相似性的獎勵對象選擇策略下,通過相似性閾值的判斷來增加獎勵執行通過測試用例.相比于基于執行失效的獎勵對象獎勵策略,基于相似性的獎勵對象選擇策略增加了強化學習的獎勵數量,緩解了面向持續集成測試用例優先排序的強化學習獎勵對象稀少問題.獎勵對象的增加,使得強化學習的智能體可以接收到更多環境的反饋,從而更好地進行測試用例優先排序策略的調整,最終實現測試用例優先排序質量的提升.
綜上所述,基于相似性的獎勵對象選擇策略通過增加獎勵與執行失效測試用例存在相似的執行通過測試用例,有效地增加了面向持續集成測試用例優先排序的強化學習獎勵對象,解決了強化學習的獎勵稀疏問題,并進一步有效地提升了測試用例優先排序效果.
3.4.3 基于相似性的獎勵對象選擇策略的時間開銷分析
本小節針對問題3 進行實驗分析.基于相似性的獎勵對象選擇策略在基于強化學習的持續集成測試用例優先排序中,通過相似性分析以實現測試用例優先排序質量的提升,在一定程度上是以時間開銷為代價進行測試用例優先排序質量的提升,理論上增加了基于強化學習的持續集成測試優先排序框架的時間開銷.本文進一步在基于強化學習的持續集成測試用例優先排序中使用基于執行失效的獎勵對象選擇策略和基于相似性的獎勵對象選擇策略進行時間開銷的對比分析,其時間開銷展示如表6所示.

表6 基于不同獎勵對象選擇策略的持續集成測試用例優先排序時間開銷(s)
基于強化學習的持續集成測試用例優先排序框架的時間開銷,不僅包括了獎勵計算的時間、智能體的學習時間和測試用例優先排序的時間,還考慮了獎勵對象選擇的時間,以及相似性分析的時間.根據表6所示的時間開銷結果,明顯看出基于相似性的獎勵對象選擇策略在大部分數據集上均明顯增加了時間開銷,這是由于在每一周期進行相似性分析增加了相應的時間開銷,然而基于相似性的獎勵對象選擇策略通過解決強化學習的獎勵稀疏問題,加速了強化學習的學習速度,因此對于框架整體來說,其平均時間開銷的增加均是秒級,是可以接受的時間開銷增加.
綜上所述,基于相似性的獎勵對象選擇策略在有限的時間開銷增加下,不僅通過獎勵對象的增加有效地解決了基于強化學習的持續集成測試用例優先排序獎勵稀疏問題,還有效了提升了持續集成測試用例優先排序質量.
4 結論與展望
本文針對工業程序的持續集成測試存在頻繁迭代和測試失效低導致獎勵稀疏的問題,在基于強化學習的持續集成測試用例優先排序中,依據測試用例的歷史執行過程和執行時間提出了基于相似性的獎勵對象選擇策略,在獎勵失效測試用例的基礎上,通過選擇與失效測試用例存在相似的通過測試用例作為額外獎勵對象,有效解決了獎勵稀疏問題.提出的方法在有限時間開銷增長下,有效地提升了測試用例優先排序效果.
未來進一步研究構建基于強化學習的持續集成測試用例優先排序策略網絡.通過自適應學習測試用例的新特征以實現測試用例優先排序策略的調整,從而生成適合后續的測試用例優先排序策略.
猜你喜歡
兒童時代·幸福寶寶(2022年12期)2022-12-09 11:24:14
中學生數理化·七年級數學人教版(2022年11期)2022-02-14 07:14:12
教學考試(高考化學)(2021年2期)2021-05-30 06:15:52
科普童話·學霸日記(2020年1期)2020-05-08 16:45:11
中學生數理化·高一版(2020年3期)2020-04-21 08:03:20
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
小天使·一年級語數英綜合(2019年2期)2019-01-10 11:57:30
兒童繪本(2018年5期)2018-04-12 16:45:32
數學大世界(2018年1期)2018-04-12 05:39:14
