基于特征選擇的工業互聯網入侵檢測分類方法
2022-05-09 05:03:40任家東張亞飛李尚洋
計算機研究與發展 2022年5期
任家東 張亞飛 張 炳 李尚洋
(燕山大學信息科學與工程學院 河北秦皇島 066004) (河北省軟件工程重點實驗室(燕山大學) 河北秦皇島 066004)
互聯網行業的發展使得“工業互聯網”這個名詞也開始走進了大眾的生活,給電子裝備、鋼鐵、采礦、電力等工業制造業帶來了便捷.所謂的工業互聯網就是把工業制造與互聯網融合起來,將工業系統中的設備、車間、工廠、員工與客戶等利用互聯網這個平臺作為樞紐連接起來的網絡,從而推動工業的智能化,實現行業間的互通、資源間的共享.
然而,由于各種移動終端、工廠車間的接入,使得工業互聯網群體日益強大,安全問題愈加突出.研究發現,2020年上半年,通過國家工業互聯網的安全態勢感知平臺,檢測到了各種惡意攻擊1 356.3萬次,其中流量異常、非法外聯、僵尸網絡占惡意攻擊總數的80%以上[1].隨著工業互聯網的發展與應用,其遭受的惡意攻擊與日俱增,給工業互聯網帶來各種安全隱患,更嚴重的可能會導致工廠車間的癱瘓,生態系統失衡[2].
針對工業互聯網的安全現狀,網絡入侵檢測系統(intrusion detection system, IDS)可以有效識別網絡中的攻擊行為,實時監測網絡狀況,一旦發現入侵就會立即、主動地做出響應.入侵檢測系統的關鍵在于對攻擊行為的識別,傳統的入侵檢測系統從最初的利用審計信息來追蹤用戶的可疑行為,到提出了第一個實時的入侵檢測專家系統模型[3],再到利用狀態轉換分析來進行完善,對攻擊的識別始終是網絡安全領域的熱點問題.然而,隨著工業互聯網環境的日益復雜,傳統入侵檢測系統的問題便突顯了出來,如較多地占用網絡資源、網絡流量分析能力不足、對各種攻擊的監測能力較差[4]、誤報率較高等.
隨著機器學習和深度學習模型的普及,大量學者開始將機器學習和深度學習模型運用到工業互聯網的入侵檢測系統中[5-10],有效緩解了傳統入侵檢測系統的瓶頸問題.在傳統入侵檢測系統中引入機器學習和深度學習,就可以把入侵檢測問題簡化為識別與分類問題來處理,智能化地實現網絡安全維護.研究表明,機器學習和深度學習模型能夠有效識別正常與異常行為.但是,針對異常攻擊中的具體攻擊類別如DOS,Generic,Exploits等,研究成果較少.
為了實現具體攻擊類別的識別,幫助入侵檢測系統快速、準確地做出響應,還需要對工業互聯網網絡流量數據進行特征選擇,以此減小冗余特征對分類效果的影響.常見的特征選擇方法有相關系數法、卡方檢驗、信息增益[11]、遞歸特征消除[12]等,通過這些方法,能夠減少特征的數量和降低數據維度.其中,相關系數法最為簡單高效,通過計算皮爾遜相關系數,能夠快速準確地判斷特征之間的相關性,避免不相關特征未被篩選或相關特征過度篩選的情況,提高模型精度.
為了去除無關特征并更好地提高分類性能,本文提出了一種基于皮爾遜特征選擇的入侵檢測分類方法,主要貢獻包含3個方面:
1) 對原始數據集進行分析,利用獨熱編碼、歸一化等進行預處理,利用皮爾遜相關系數進行特征選擇,提高模型識別的準確率.
2) 從機器學習和深度學習2個角度,通過8種模型對入侵檢測攻擊進行分類評估和比較分析,確定了性能最佳的二分類和多分類模型.
3) 在公共數據集和工業互聯網真實流量數據集上,驗證了本文評估方法對入侵檢測二分類和多分類的有效性.
1 相關工作
工業互聯網網絡流量數據復雜多變,特征冗余度高,使得其產生的安全問題難以被發現.目前,用于驗證入侵檢測方法的經典數據集主要有KDD99,NSL-KDD99等,但是這些傳統的數據集數據陳舊、更新緩慢,只能識別Normal,DOS,R2L,U2L和Probe這5種攻擊類型,對于現在網絡中出現的其他攻擊無法實現精準識別.Kilincer等人[13]詳細介紹了網絡入侵檢測系統中常用的6種數據集,并對其進行對比分析,表明了UNSW-NB15數據集更適用于現在的各種研究.Almomani等人[14]基于UNSW-NB15數據集,利用機器學習中的邏輯回歸、貝葉斯、決策樹、隨機森林等分類器進行了二分類的實驗,實驗結果顯示隨機森林的分類效果最好,準確率為87%.Zhang等人[15]基于UNSW-NB15和MSU數據集,采用MRMR算法和支持向量機方法對特征進行選擇,實驗結果表明有的特征之間具有強耦合性,而有的特征冗余.Kumar等人[16-17]基于UNSW-NB15數據集提出了一種新型統一的入侵檢測算法,通過計算信息增益進行特征選擇,其結果僅識別了4~5種攻擊類型,成功識別的種類較少.Agarwal等人[18]利用樸素貝葉斯、支持向量機、K近鄰3種機器學習模型進行了分類,其中支持向量機的準確率最高,達到97.77%.
上述大多研究中,沒有充分利用各種機器學習和深度學習模型分別進行二分類和多分類實驗.其中涉及特征選擇的研究,雖然有效識別出了網絡流量中的異常行為,但是識別出的具體攻擊類型最多為5種.本文通過計算皮爾遜相關系數,選擇合適的特征,分別結合機器學習和深度學習模型進行二分類和多分類實驗,對工業互聯網入侵檢測情況進行詳細的分析.
2 基于特征選擇的入侵檢測分類方法設計
本節首先給出了基于特征選擇的入侵檢測分類方法的整體框架;其次,對特征選擇和分類模型分別進行具體闡述.
2.1 研究框架
本文的結構框架分為工業互聯網流量數據預處理、特征選擇、訓練并驗證模型、評估分析、特征分析5個部分,如圖1所示.
1) 數據預處理.從不同維度分析UNSW-NB15數據集的數據特征,對數據進行統一的清理與歸一化,并根據特征屬性的類型,將其轉化成模型可識別的數據.
2) 特征選擇.對原始數據集進行預處理后,計算特征的皮爾遜相關系數,判斷每種特征相關程度強弱,通過實驗選擇最優閾值,實現特征選擇.
3) 訓練并驗證模型.利用支持向量機、邏輯回歸、K近鄰、決策樹、隨機森林等傳統機器學習模型和多層感知機、卷積神經網絡、時空網絡等深度學習模型進行訓練和驗證.
4) 評估分析.對工業互聯網網絡流量分別進行二分類和多分類研究,二分類指的是能夠識別正常行為與攻擊行為,多分類能夠識別出具體的攻擊類型,根據準確率等評價參數,確定哪種模型二分類效果最佳,哪種模型多分類效果最佳.
5) 特征分析.根據分類結果,分析不同特征和特征相關性對分類結果的影響.
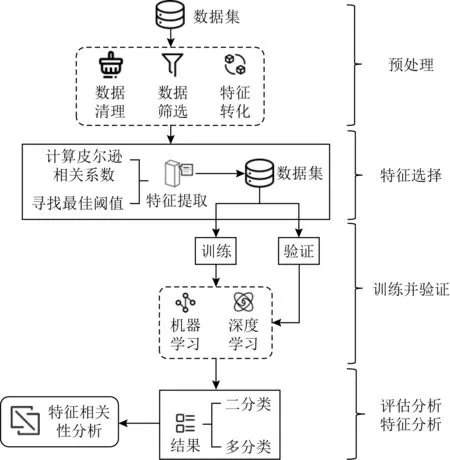
Fig. 1 Schematic diagram of the research structure圖1 研究結構框架示意圖
2.2 預處理
工業互聯網需要收集來自各種工業場景的數據并形成數據集,但收集的過程會由于設備、網絡、人工等導致一些數據出現錯誤或偏差,也會因為一些數據的屬性特點,無法對這些數據做進一步分析處理.因此,在得到原始數據之后,首先要對其進行預處理,以此來降低后續實驗的難度,提升實驗效果.工業互聯網流量數據的特征屬性主要分為連續型和離散型,本文針對離散型特征,利用獨熱編碼實現特征的映射;針對連續型特征,利用歸一化將連續型特征數據縮放至[0,1]區間.
2.2.1 獨熱編碼
獨熱編碼的定義為:用N位狀態寄存器來實現對N種狀態的編碼[19],充分保證了每種狀態都能夠保存在寄存器中,不會發生特征丟失現象,并且只有一位的編碼有效.
工業互聯網流量數據中的離散型特征定義為Di,其取值為Di={Di1,Di2,…,Din},n表示該離散型特征取值數量.經過獨熱編碼后,用有n位的二進制編碼分別代表每種取值,Di取值變為{1000…, 0100…, 0010…, …, …0001},其中當第j位為1時,代表了Di中的某項取值Dij.
利用獨熱編碼進行特征映射,能夠有效處理分類器難以處理的特征問題,從而提高模型的運行效率.但是獨熱編碼并不適用于特征類別較多的屬性,當類別較多時,會導致特征向量空間較大,進而形成高維的稀疏矩陣,使運算效率大大降低.
2.2.2 數據歸一化
歸一化的定義是把所有的數據映射到區間[0,1]上,從而加快模型收斂的速度,提高分類結果的精度.歸一化的方法有很多,其中最常用的就是Min-Max標準化,也稱離差標準化.工業互聯網流量中的連續型特征記為X,特征的最小值和最大值分別為Min和Max,通過式(1)將數據進行歸一化處理,設X′是歸一化后的結果,則:
(1)
2.3 特征選擇
入侵檢測數據中大多包含一些冗余無關的數據特征,需要進行特征的提取,挑選出滿足實驗要求的特征.常見的特征選擇方法有過濾法、包裝法和嵌入法.過濾法是通過對每種屬性相關性的評價,設置閾值來進行特征的篩選;包裝法在過濾法的基礎上,實現了多種特征之間交互關系的檢測,并結合機器學習算法來對子集進行評估;嵌入法結合了過濾法和包裝法的優點,實現了特征選擇和算法訓練的并行操作.
在特征選擇過程中,根據網絡流量的特征,需要用評價函數來衡量特征子集的性能,常見的評價函數有距離度量、信息度量和依賴性度量等.距離度量通過計算樣本之間的距離來實現對樣本的分類,距離越小,越可能屬于同一種類別;信息度量通過計算信息增益、信息熵等,將特征信息量化,計算所得值越大,越說明了分類器的性能較優;依賴性度量用來評價特征之間或類別與特征之間的相關性,與類別相關性大的特征被認為是好的特征.前2種評價方式無法判斷特征對分類結果的影響,也忽略了網絡流量特征之間的關聯性對分類結果的影響情況,鑒于網絡流量特征數據的復雜性和異構性,前2種評價方式較少用于評估生成特征子集的好壞.依賴性度量的評價方法能夠很好地實現網絡流量特征對類別影響的評估.依賴性度量中的皮爾遜相關系數具有易于理解、簡潔高效且計算復雜度較低等優點,因此,本文選擇皮爾遜相關系數來衡量類別與特征之間的相關程度,計算方法為
(2)

皮爾遜相關系數的取值范圍為-1~1,其絕對值越大,說明2個變量間的相關程度越強,一般通過表1來判斷相關程度的強弱.

Table 1 Strength of Correlation Table
2.4 分類模型
工業互聯網入侵檢測系統利用機器學習和深度學習中的各種模型對流量數據進行二分類和多分類,識別出攻擊類型并正確分類.
在機器學習模型中,邏輯回歸經常被用于解決二分類問題,也可用來解決多分類問題,通過Logistics函數來歸一化預測值;支持向量機通過超平面來對數據進行分類,在訓練數據的同時學習攻擊模型進而實現分類,主要適用于線性分類且特征量大的數據集[18];K近鄰是分類模型中最簡單的分類器之一,通過判斷與未知樣本最近的K個樣本的類別,將其分類為K個樣本點中大多數樣本所屬類別;在決策樹中,通過樣本的特征值進行分類,樹的節點代表數據集的特征,分支表示劃分的決策規則[20];隨機森林是基于多個決策樹來構建的,以此可以有效預防過擬合問題,通過對每一棵樹進行預測,最終獲得最優解,大多用于多分類問題,具體構建過程如圖2所示.
1) 對樣本進行隨機有放回的采樣(Bagging采樣),訓練決策樹.
2) 在包含M個特征的樣本中,選取m個特征(m?M),根據Gini Impurity選擇作為分裂節點的特征,計算方法為

Fig. 2 Modeling process of random forest model圖2 隨機森林模型建模過程示意圖

(3)
其中C表示分類的數量,某一條數據是第i類的概率為p(i).
3) 對每個節點重復步驟2),直到不能分裂為止,生成決策樹.
4) 重復步驟1)~3),建立大量的決策樹,生成隨機森林,并根據“少數服從多數原則”,做出決策.
深度學習模型中,多層感知機在單層神經網絡的輸入層和輸出層之間引入了隱藏層,并利用非線性激活函數relu(x)=max(x,0)進行標簽劃分,實現模型分類;卷積神經網絡是用卷積運算代替矩陣乘法運算的神經網絡[21],卷積層和池化層的加入能夠有效利用工業互聯網網絡流量特征進行異常檢測.時空網絡將CNN處理后的一維數據,作為LSTM的輸入,對經過處理后的流量數據特征進行正常和異常行為的分類.
2.5 評價指標
準確率(accuracy)、精確率(precision)、召回率(recall)和F1分數(F1-score)用來對機器學習和深度學習模型進行評價.
1) 準確率(accuracy).可以直接用來衡量模型的好壞,其結果指的是對整體樣本的預測準確度,accuracy的值越大,說明模型越好,計算為
(4)
其中,TP指攻擊類型被正確分類的數量,TN指正常行為被正常分類的數量,FP指正常行為被分類為攻擊行為的數量,FN指未將此攻擊類型正確分類的數量.
2) 精確率(precision).針對預測結果,在樣本不均衡的情況下提出的,由式(5)可看出,其含義為在所有的被預測為正的樣本里,實際結果為正樣本的概率,計算為
(5)
3) 召回率(recall).針對實際原樣本的,在實際結果為正的樣本,被預測也為正的概率,計算為
(6)
4)F1分數(F1-score).在希望精確率和召回率都很高,但又不能同時滿足時,就需要尋找二者的一個平衡點,平衡點定義為F1-score,同時考慮到精準率和召回率,使得二者結果能夠達到最優,計算為
(7)
5) 加權準確率(ωaccuracy).在多分類的情況中,要綜合考慮每種行為類型的準確率,因此利用加權準確率來評價模型的整體分類效果,計算為
(8)
其中,i為某種行為類型,共有k種行為類型,accuracyi為某種行為類型的準確率,ni為某種行為類型的數量,n為k種行為類型數量之和.
3 實驗與結果
3.1 實驗環境
本文所有的實驗均在Windows 10 PC,Intel?CoreTMi5-10210U CPU @ 1.60 GHz,16.00 GB RAM環境中實現.采用Python中的Sklearn庫等實現算法.
3.2 數據集
本文選取了UNSW-NB15數據集進行實驗,數據集基于IXIA PerfectStorm創建,并最終以CSV文件的形式生成.數據集中包含49種特征,根據這些特征的數據類型,將其劃分成5種:Object,Integer,Float,Timestamp,Binary,如表2所示.經過對這些特征的分析,最終可以識別Analysis,Backdoor,DoS,Exploits,Fuzzers,Generic,Shellcode,Reconnaissance,Worms,Normal共10種行為類別,其中Normal屬于正常行為,其余為異常攻擊行為.

Table 2 Feature Classification
3.3 預處理
3.3.1 數據清理
對工業互聯網流量數據集“service”列的值進行轉化.該列代表使用的通信服務類型,常見的通信服務包括HTTP,FTP,SMTP,SSH,DNS,FTP-data,IRC協議,但數據集中有的結果是“-”,代表了不常用的協議,模型無法識別,導致結果產生錯誤.因此,將“-”用“None”來代替,便于模型的識別,同時也不會對結果造成較大的影響.
數據集中某些屬性列的取值錯誤將對分類結果產生影響,需對其進行篩選.“ct_flw_http_mthd”列和“is_ftp_login”列的結果屬于Binary列,其結果非0即1.以“is_ftp_login”列為例,該屬性的含義是:FTP會話是否被用戶和密碼訪問,如果是,結果為0,反之即為1.根據表3中處理前的特征值可知,該屬性共有4個取值0,1,4,2,違背了“非0即1”的原則,說明2和4屬于錯誤值,將包含錯誤值的數據應
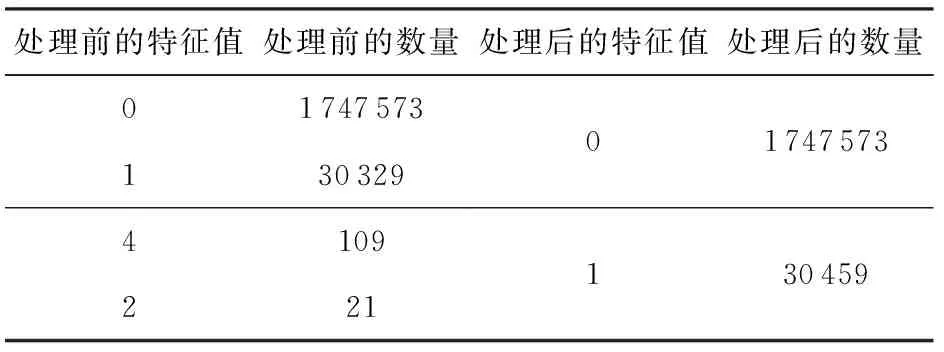
Table 3 Comparison of “is_ftp_login” Attribute Data Processing Before and After
用于分類中,會對結果產生較大影響,因此,要對這些數據進行處理.正常處理方法是進行替代,將該列所有取值為2或4的數據,都用1進行替代,如表3中處理后的特征值所示.
3.3.2 特征映射
UNSW-NB15數據集中,屬于“Object”類型的特征都是string字符串,模型無法識別.因此,利用獨熱編碼(one-hot encoding)實現特征映射.如“proto”列代表了傳輸協議,其取值包含TCP,UDP這2種,則映射的編碼為01和10,“state”列的取值有5種,分別是CON,FIN,INT,REQ和RST,則映射的特征編碼分別為10000,01000,00100,00010,00001.
3.4 特征選擇
特征的選擇,直接影響了分類的結果,因此,特征選擇是入侵檢測的關鍵.通過計算每種屬性的皮爾遜相關系數,可以達到選擇特征的目的,但是往往去掉或留下哪些特征難以確定.本文根據特征相關程度強弱對應表,直接摒棄了無相關程度和相關程度極弱的特征,之后在弱相關強度閾值0.2~0.4范圍內,進行分類實驗.
經過實驗分析,表4列出了在隨機森林模型下不同皮爾遜系數對應的二分類實驗結果,經對比可以看出,皮爾遜系數的值為0.3時,實驗效果最佳.因此,二分類實驗下,以皮爾遜系數等于0.3作為閾值,進行特征選擇.
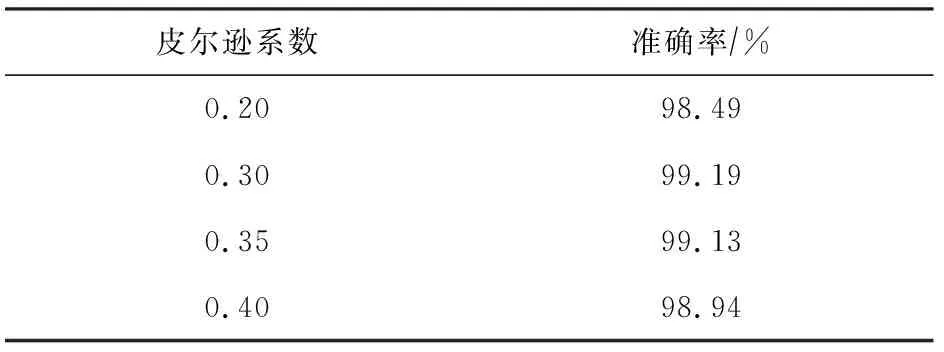
Table 4 Binary-Classification Experimental Results of Different Pearson Coefficients in Random Forest Model
在多分類實驗中,仍以隨機森林模型為例,尋找閾值,實驗結果如表5所示.
從表5中可以看出,當皮爾遜系數為0.20時,可以識別7種類型的攻擊;當皮爾遜系數為0.30時,識別5種;當皮爾遜系數為0.35和0.40時,僅能識別4種,且隨著皮爾遜系數的變大,多分類的實驗效果反而越差,因此,本文選取0.20作為多分類實驗的閾值,進行特征選擇.

Table 5 Multi-Classification Accuracy Results of Different Pearson Coefficients in Random Forest Model
3.5 二分類
從不同的機器學習和深度學習模型入手,對工業互聯網流量數據中的正常和異常行為進行檢測和分類.
3.5.1 機器學習模型
表6列出了在相同的實驗環境下,支持向量機、邏輯回歸、K近鄰、決策樹、隨機森林5種機器學習模型的實驗結果.為了防止過擬合現象,保證結果的可靠性,本文實驗使用5倍交叉驗證的方法,實驗結果的準確率為5次交叉驗證的平均值.

Table 6 Binary-Classification Results of Machine Learning Model
從表6中可以看出隨機森林模型的準確率為99.20%,比其他模型的準確率都高,決策樹的準確率次之,相對而言另外3種模型的分類效果略差.精確率代表了分類結果“找得對”,召回率代表了分類結果“找得全”,二者值越高,說明分類效果越好.
綜合各種評價指標可以看出,基于機器學習模型的二分類實驗中,隨機森林模型的分類效果最優.
3.5.2 深度學習模型
在深度學習模型中,本文分別使用了多層感知機、卷積神經網絡和時空網絡3種模型進行二分類實驗,實驗結果如表7所示.多層感知機模型的準確率為99.06%,識別效果最佳.多層感知機模型,包含了一個隱藏層和100個神經元,激活函數為relu,默認使用“adam”來對權重進行優化,鑒于本文數據集的數據量較大,使用“adam”優化效果更好;beta_1一階矩向量的指數衰減速率為90%,二階矩向量的衰減速率為99.9%,這樣能夠保證數據傳輸的質量,不會對結果有較大的影響;學習率learn_rate代表了每一次參數更新幅度的大小,若設置的值過大會導致結果不收斂,若過小會導致收斂過于緩慢,本文的學習率設置為了恒定值,即learn_rate_init=0.001,此時的訓練結果是最優的.
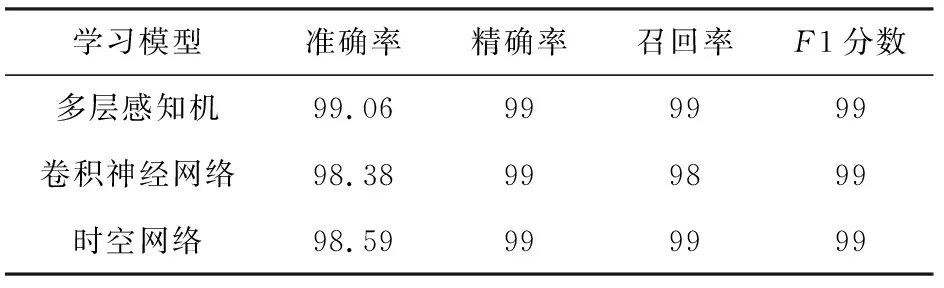
Table 7 Binary-Classification Results of Deep Learning Model
3.6 多分類
本節繼續從機器學習和深度學習模型的角度,進行多分類實驗,檢測具體攻擊的類別.
3.6.1 機器學習模型
表8總結了機器學習中每種模型識別10種攻擊類別的準確率.結果顯示,不同的機器學習模型對某種攻擊類別的識別效果不同,比如對于“Analysis”攻擊來說,決策樹和隨機森林的識別率達到了45%和53%,K近鄰模型對該攻擊的識別率為5%,而另外2種模型未識別出此類攻擊;每種模型對“Generic”和“Normal”這2種類別的識別效果都最好,說明了當前的分類模型對這2種類型的識別效果較好.
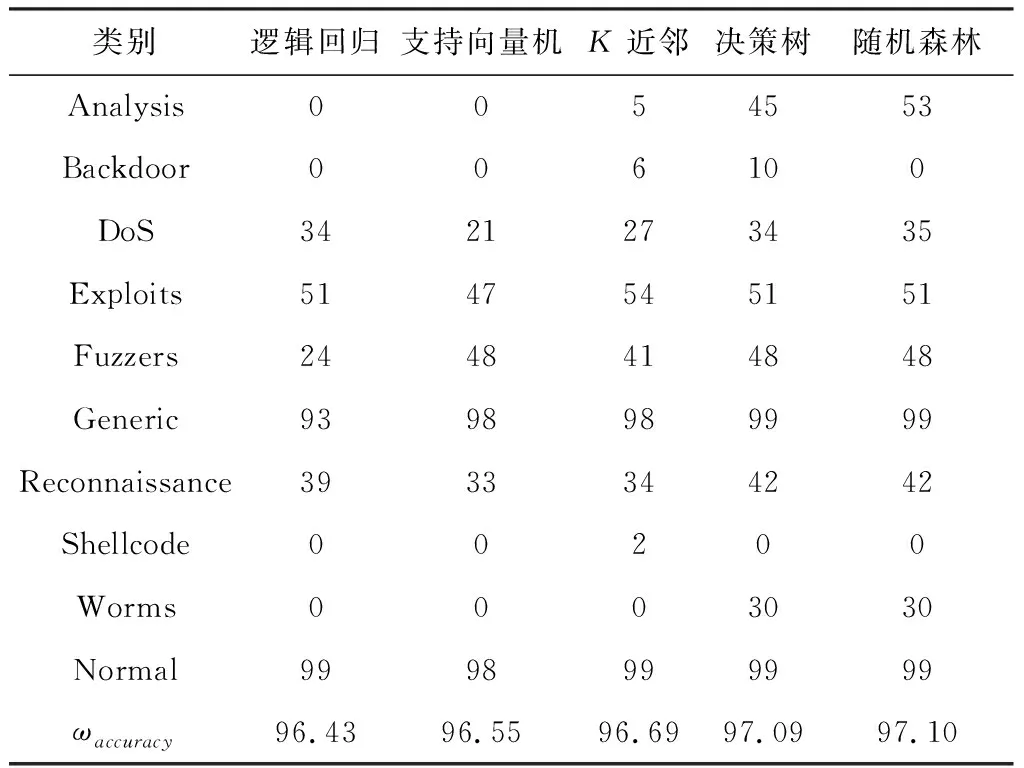
Table 8 Multi-Classification Accuracy Results of Machine Learning Model
決策樹和隨機森林模型的加權準確率分別為97.09%,97.10%,二者對10種類別的分類結果接近,但是決策樹能夠識別出9種類別,隨機森林只識別出8種,沒能識別出“Backdoor”攻擊;K近鄰模型同樣識別出9種類別,但其加權準確率相對較低.綜合分類效果分析,識別出的種類較多的模型,分類效果最優;分類效果相同時,加權準確率高者,實驗效果最佳.因此,多分類實驗中,決策樹的模型的分類效果最佳.
3.6.2 深度學習模型
表9總結了深度學習模型進行多分類的結果,多層感知機能夠識別6種類別,另外2種模型能夠識別5種,3種模型對“Generic”和“Normal”這2種類別的識別效果也是最好的.
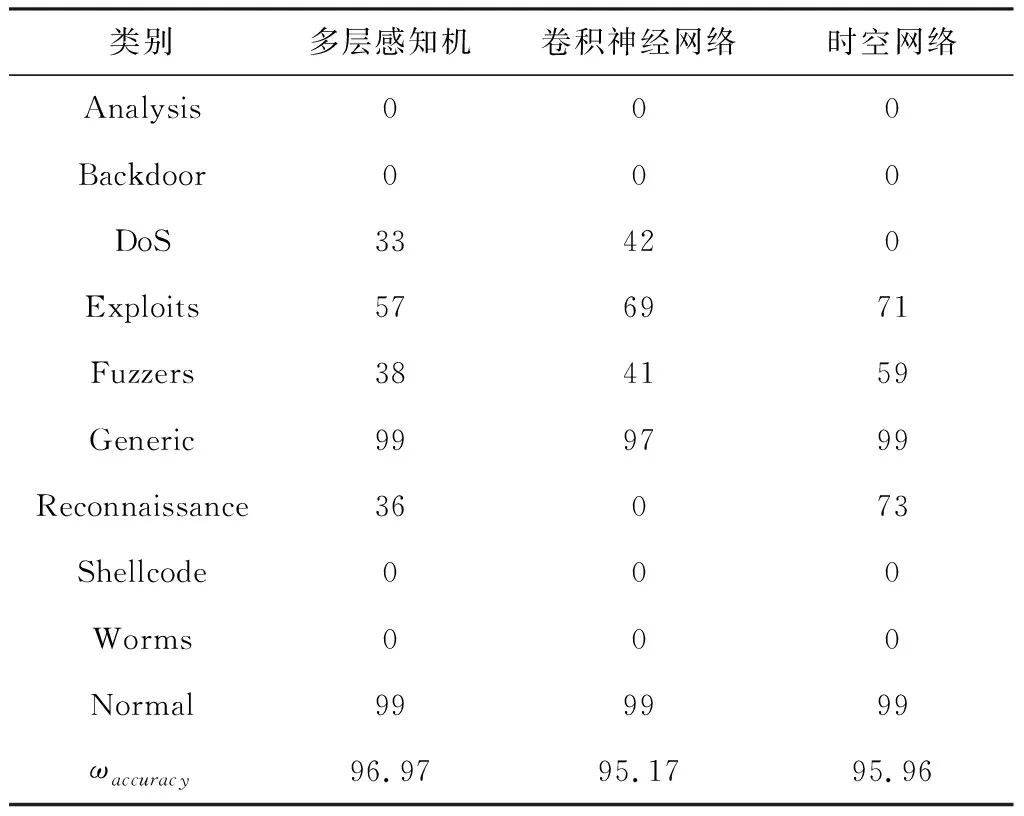
Table 9 Multi-Classification Accuracy Results of Deep Learning Model
從綜合機器學習和深度學習的模型來看,在多分類的實驗中,機器學習模型的識別效果優于深度學習模型,能夠識別更多種類別.
3.7 特征相關性分析
工業互聯網流量數據集UNSW-NB15中一共包含49種特征,在不同的分類模型下,特征本身及其之間的依賴關系對分類預測的結果都會產生不同的影響.
本文基于邏輯回歸模型的二分類實驗結果,來探究特征對分類結果的影響.經過預處理和特征選擇后,數據集中剩余21種特征,通過得到的部分依賴圖,并計算隨特征值改變而改變的預測結果的方差,得到了特征對預測結果的影響程度排序,如表10所示.表10對每種特征的方差進行了排序,方差越小,特征對預測結果的影響越小;方差越大,特征對預測結果的影響越大.本文以“ct_srv_src”(10-4級)為界限得到,“ct_src_ltm” ,“sttl”,“ct_srv_dst”,“ct_dst_ltm”,“ct_srv_src”等特征方差較小,說明對分類預測的結果不會產生較大的影響;“swin”,“dwin”和“ct_state_ttl”,“ct_dst_sport_ltm”等特征屬性對分類結果有一定的影響.
相同屬性在不同的分類模型中對預測結果的影響也不一樣.以“sttl”和“swin”為例,如圖3所示,展示了2個特征分別在邏輯回歸和隨機森林模型下對預測結果的影響.從圖3可以看出,不同的模型中,屬性的相關程度對實驗結果的影響較大.在邏輯回歸模型中,預測結果較好的情況占預測總數的1/3,預測準確率為89%;在隨機森林模型中,預測準確率最高為85%,且邏輯回歸模型預測結果的劃分層次較多,結果逐漸變化,而隨機森林模型預測結果的變化較少,大多處于76%的預測結果范圍內.

Fig. 3 Comparison of the effects of “sttl” and “swin” features on different models圖3 “sttl”和“swin”特征對不同模型的影響效果對比圖
綜上所述,每種特征對實驗結果的影響程度不同,且在不同的分類模型中,相同的特征也會對結果產生不同的影響.
3.8 實驗驗證
為了驗證本文所提方法的實驗結果的準確性與高效性,我們將本文所用方法與其他研究做了對比,如表11所示.與其他研究相比,本文提出的方法達到了99.20%的準確率,且精確率和召回率都達到了99%,表明本文提出的方法相較于其他方法能夠更好地實現對網絡異常流量的檢測.此外,在工業互聯網網絡流量數據集中,我們選擇了CSE-CIC-IDS2018數據集進行驗證.
CSE-CIC-IDS2018數據集中包含83種統計特征,但其中包含很多無關或者相關性很小的冗余特征[28].本文以隨機森林模型為例,選取部分數據集分別進行二分類和多分類的實驗驗證,實驗結果如表12和表13所示.為了防止出現過擬合現象,進行了交叉驗證.

Table 11 Comparison of Detection Performance of Different Studies
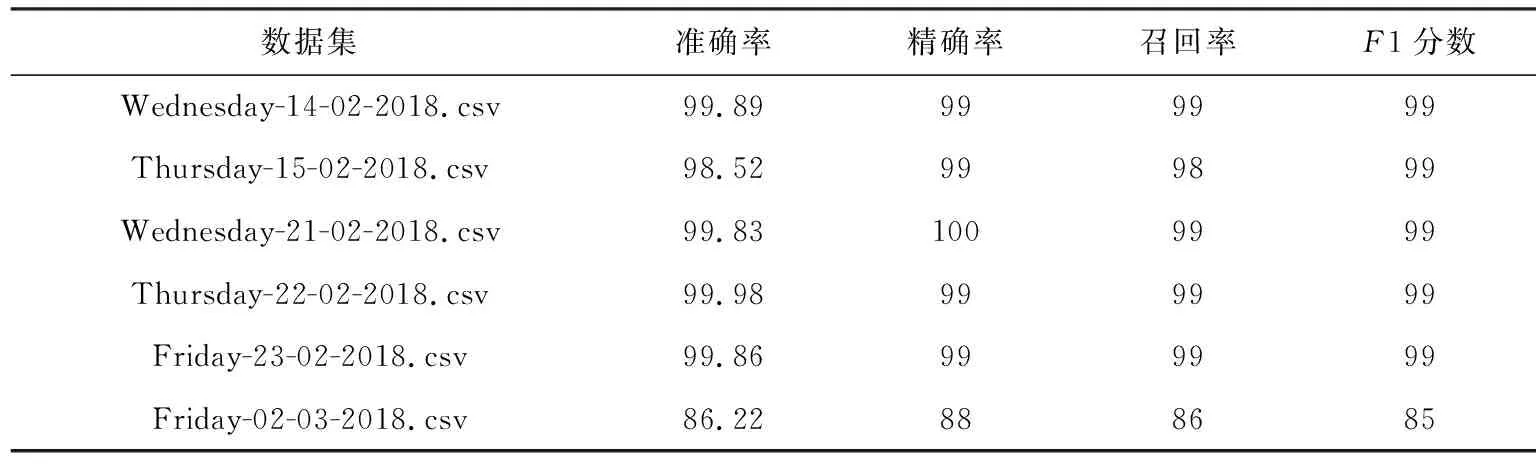
Table 12 Binary-Classification Results in CSE-CIC-IDS2018 Dataset

Table 13 Multi-Classification Accuracy Results in CSE-CIC-IDS2018 Dataset
實驗結果表明,本文提出的基于特征選擇的入侵檢測分類算法在CSE-CIC-IDS2018工業互聯網流量數據集中有較好的分類效果,驗證了本文所提方法的有效性和可遷移性.
4 討 論
在工業互聯網中,不同的應用場景下會產生不同的網絡流量數據,流量數據特征的選擇直接影響工業互聯網入侵檢測分類的結果.本文通過計算皮爾遜相關系數,選擇出了與分類結果顯著相關的特征,達到了提高模型精度的效果.但是該方法未考慮特征之間的相互作用對分類效果的影響,主要度量特征之間的線性關系,未來的工作將對特征間非線性關系的度量效果進行分析研究[29],針對不同的攻擊類別,判斷哪些特征對此類攻擊的影響程度較大.此外,將入侵檢測系統智能化,使其自動識別環境變化并做出響應;優化網絡流量攻擊的多分類算法,提高每種攻擊的識別率;運用可視化技術,更直觀、生動、立體地體現檢測結果.
5 結 論
本文提出了基于特征選擇的工業互聯網入侵檢測分類方法.首先,通過數據預處理,篩選異常或錯誤數據;在此基礎上,計算特征的皮爾遜相關系數,判斷特征的相關程度強弱,通過實驗找到合適的閾值,并根據閾值進行特征選擇;然后使用5種機器學習模型——支持向量機、邏輯回歸、K近鄰、決策樹和隨機森林,3種深度學習模型——多層感知機、卷積神經網絡和時空網絡,進行二分類和多分類的實驗.在二分類實驗中,隨機森林的準確率為99.20%,二分類效果最好;在多分類實驗中,決策樹的加權準確率為97.09%,多分類效果最好.最后,分析了工業互聯網流量數據集中特征對分類結果的影響,并在真實工業互聯網的實踐中,驗證了本文所提方法的有效性.
作者貢獻聲明:任家東負責論文研究思路和方案設計工作;張亞飛負責實驗設計和論文撰寫工作;張炳負責論文思路設計和實驗指導以及論文修訂工作;李尚洋負責論文實驗分析和語言文字把關工作.
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
發明與創新(2016年38期)2016-08-22 03:02:52
