基于深度學習的3維點云處理綜述
2022-05-09 07:39:56李嬌嬌孫紅巖張若晗孫曉鵬
計算機研究與發展 2022年5期
李嬌嬌 孫紅巖 董 雨 張若晗 孫曉鵬,2
1(遼寧師范大學計算機與信息技術學院計算機系統研究所 遼寧大連 116029) 2(智能通信軟件與多媒體北京市重點實驗室(北京郵電大學) 北京 100876)
隨著3維傳感器的迅速發展,3維數據變得無處不在,利用深度學習方法對這類數據進行語義理解和分析變得越來越重要.
不同3維數據(體素、網格等)表示下,深度學習的方法不盡相同,但這些方法應用于點云中都有一定的局限性,具體表現為:體素化方法會受到分辨率的限制;轉換為2維圖像的方法在形狀分類和檢索任務上取得了優越性能,但將其擴展到場景理解或其他3維任務(如姿態估計)有一定的困難;光譜卷積神經網絡限制在流形網格;基于特征的深度神經網絡會受到所提取特征表示能力的限制[1].
點云本身具有的無序性與不規則性為利用深度學習方法直接處理該類數據帶來一定挑戰性:1)規模局限性.現有研究方法一般針對小規模點云,而能處理大型點云的方法也需要切割處理,即將其分為小塊后再處理.但切割可能會造成點云整體信息的丟失.2)遮擋.當被掃描對象被遮擋時,將直接導致信息的丟失,這為后續任務的處理帶來嚴重影響.3)噪聲.由于點云數據本身就是3維空間內的點集,噪聲的存在直接影響點云模型的正確表示,在形狀識別等任務中會造成精度的降低.4)旋轉不變.對于同一模型,旋轉不同角度仍表示同一對象,網絡識別結果不應由于角度不同而產生差異.
隨著近年來激光雷達等傳感設備及相關技術的發展,3維點云的掃描與獲取更為便捷,其處理技術在機器人、自動駕駛及其他領域的實際應用中已取得一定進展.基于深度學習的蓬勃發展,研究者提出了許多方法來解決相關領域的不同問題.本文對基于深度學習的點云處理任務進行詳細闡述.
本文的主要貢獻有4個方面:
1) 從機器人、自動駕駛、虛擬和增強現實以及醫學4個領域介紹點云處理技術的應用情況;
2) 探討點云拓撲結構與形狀分析在應用于點云處理任務中的必要性,并總結對比多種算法;
3) 歸納基于點云數據處理相關任務的方法,主要包括模型重建與變換、分類分割、檢測跟蹤與姿態估計,著重討論基于深度學習的方法,并給出各種方法的優劣比較;
4) 總結多個公開點云數據集,并分析各數據集中不同方法能處理的不同任務.
1 基本概念及應用情況
1.1 深度學習
機器學習推動現代科技手段的進步.網絡的內容過濾及推薦、語音文本的轉換及醫學影像分析等應用程序越來越多地使用深度學習技術.
1) 基礎概念
深度學習善于發現高維數據中的復雜結構,因此可應用于科學、商業和醫學等諸多領域.
深度學習利用多處理層組成的計算模型學習具有抽象層次的數據表示,關鍵在于其目標特征不是人類指定的,而是從大量數據中學習獲取的,深度神經網絡已經成為人工智能的基礎.多層感知機或全連接網絡堆疊線性層和非線性激活層,是神經網絡的經典類型.卷積網絡引入卷積層和池化層,在處理圖像、視頻和音頻方面取得了突破性進展.遞歸網絡可有效處理文本語音等具有連續性的數據.Trans-former利用self-attention機制提取特征,最早用于處理自然語言[2-3].
2) 框架平臺
為了實現更復雜的模型,若從頭開始編寫代碼,效率非常低,因此深度學習框架應運而生.本節介紹常用的深度學習框架,并將其匯總于表1中.
目前常用于點云處理的框架更多為TensorFlow與PyTorch,其他框架如Caffe與Jittor等也可用于處理點云,但應用較少.
1.2 點云處理任務
3維幾何模型中,點云已經成為主要表達方式之一,其應用于深度學習中的處理技術已取得一定成果.在不同任務驅動下,本文以構建神經網絡為主要方法,通過分類與整理相關文獻,將點云處理任務分為模型重建與變換、分類分割、檢測跟蹤與姿態估計幾大類.本節總結其基本概念.
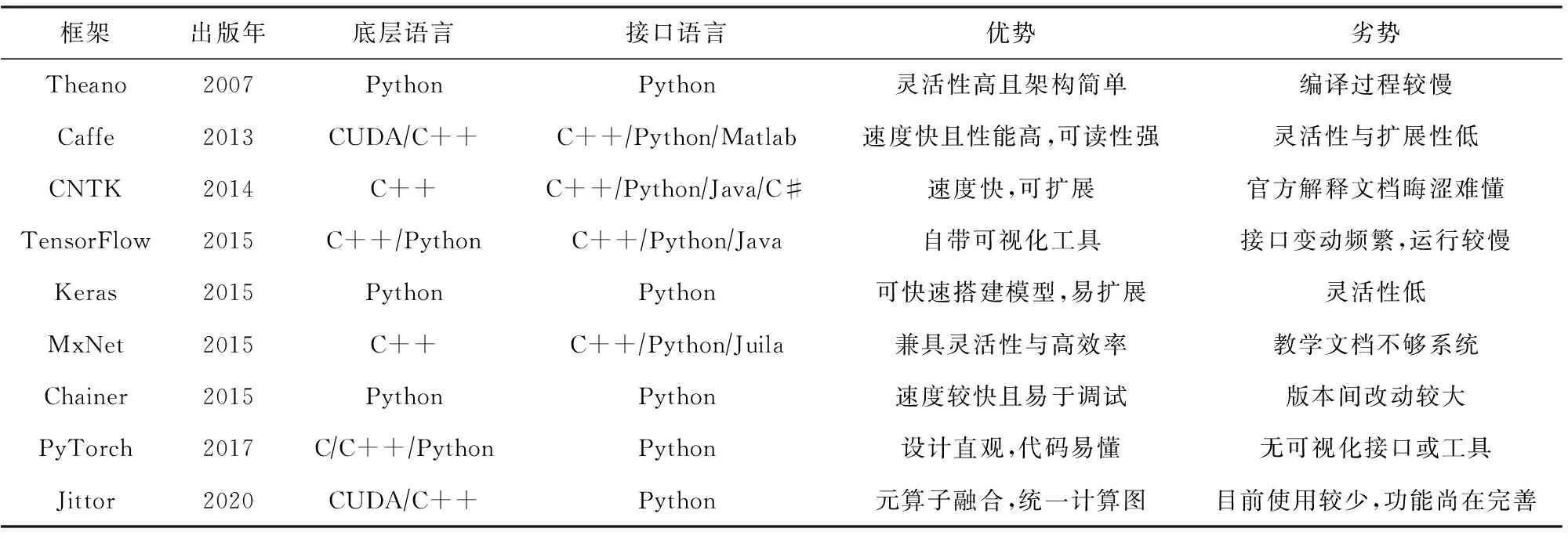
Table 1 Deep Learning Framework 表1 深度學習框架
模型重建與變換包括形狀修復、模型補全與變形.掃描獲取到的數據并不能完美表征原物體的特性,很可能存在缺漏或誤差,造成模型不完整、扭曲,故而需要對該模型進行處理,使其盡可能貼合原物體模型或目標模型,處理手段即為重建與變換.
分類分割主要包括分類、部件分割、語義分割與實例分割.在諸如機器人抓取等需求中,必須明確所抓取對象的分類,即需要判斷其信息,判斷即為對場景中對象語義信息標記與分類.
檢測跟蹤主要包括3維對象檢測、場景流估計與目標跟蹤.在諸如自動駕駛等應用中,需要明確路徑與方向,確定追蹤對象,并能依據當前狀態自動調節或人為干預使其后續運動符合預期目標.
姿態估計主要包括位姿估計與手部姿態估計.前者需要確定對象的位置與方向,如工廠噴漆中,噴槍需要依據目標不斷改變其位置與指向.后者則是為了理解人類肢體語言,如在體感游戲中,根據肢體變換執行相應游戲操作.
1.3 應用情況
3維點云處理目前在實際應用中已經取得了一定的進展.本節以應用為導向,從機器人領域、自動駕駛領域及虛擬、增強現實領域及醫學領域4個角度介紹點云處理技術的應用情況.
1.3.1 機器人領域
機器人抓取技術的核心在于目標識別和定位.2019年Lin等人[4]利用深度神經網絡學習物體外在形狀,并訓練網絡在獲取物體局部表面時也能成功抓取目標.
在機器人室內定位及導航技術方面,2020年Khanh等人[5]設計了新的云端導航系統.云端導航下機器人能更準確地移動到目標位置.該技術可應用于位置服務需求,如盲人導航.
針對噴漆機器人的自動化操作,2019年Lin等人[6]利用迭代最近點(iterative closest point, ICP)算法進行姿態估計,計算物體部件的位置誤差,并重新調整機器人的方向,以完成所需的噴漆任務.2020年Parra等人[7]設計了能夠在地板下的空隙中進行隔熱噴涂以提高建筑的強度及使用年限的機器人.他們針對地形不均勻等情況,提出定位模塊.機器人依據傳感器獲取連續點云的信息.Yang等人[8]基于點云模型表示的家具表面路徑規劃和邊緣提取技術提出邊緣噴涂,獲取噴涂槍路徑點序列和對應姿態.在家具等工件的生產流程中,該方法能夠根據噴涂系統坐標系與家具姿態的不同,自適應地調整二者的坐標關系,以實現正確噴涂的目的.
1.3.2 自動駕駛領域
自動駕駛系統的性能受環境感知的影響.車輛對其環境的感知為系統的自動響應提供了基礎.2017年Hanke等人[9]提出采用光線追蹤的汽車激光雷達傳感器實現實時模型測量方法.使用由真實世界場景的測量構建的虛擬環境,能夠在真實世界和虛擬世界傳感器數據之間建立直接聯系.2019年Josyula等人[10]提出了利用機器人操作系統(robot operating system, ROS)和點云庫(point cloud library, PCL)對點云進行分割的方法.它是為自動駕駛車輛和無人機的避障而開發的,具體涉及障礙物檢測與跟蹤.
激光雷達(light detection and ranging, LIDAR)和視覺感知是高水平(L4-L5)飛行員成功自動避障的關鍵因素.為了對大量數據進行點云標記,2020年Li等人[11]提出針對3維點云的標注工具,實現了點云3維包圍盒坐標信息到相機與LIDAR聯合標定后獲得的2維圖像包圍盒的轉換.
基于圖的同步定位與建圖(simultaneous locali-zation and mapping, SLAM)在自動駕駛中應用廣泛.實際駕駛環境中包含大量的運動目標,降低了掃描匹配性能.2020年Lee等人[12]利用加權無損檢測(掃描匹配算法)進行圖的構造,在動態環境下也具有魯棒性.
1.3.3 虛擬、增強現實領域
為了更好地了解室內空間信息,2015年Tredinnick等人[13]創建了能夠在沉浸式虛擬現實(virtual reality, VR)顯示系統中以較快的交互速率可視化大規模LIDAR點云的應用程序,能夠產生準確的室內環境渲染效果.2016年Bonatto等人[14]探討了在頭戴式顯示設備中渲染自然場景的可能性.實時渲染是使用優化的子采樣等技術來降低場景的復雜度實現的,這些技術為虛擬現實帶來了良好的沉浸感.2018年Feichter等人[15]提出了在真實室內點云場景中抽取冗余信息的算法.其核心思想是從點云中識別出平面線段,并通過對邊界進行三角剖分來獲取內點,從而描述形狀.
生成可用于訓練新模型的標注已成為機器學習中獨立的研究領域,它的目標是高效和高精度.標注3維點云的方法包括可視化,但這種方法是十分耗時的.2019年Wirth等人[16]提出了新的虛擬現實標注技術,它大大加快了數據標注的過程.
LTDAR為增強現實(augmented reality, AR)提供了基本的3維信息支持.2020年Liu等人[17]提出學習圖像和LIDAR點云的局部特征表示,并進行匹配以建立2維與3維空間的關系.
使用手勢自然用戶界面(natural user interface, NUI)對于頭戴式顯示器和增強及虛擬現實等可穿戴設備中虛擬對象的交互至關重要.然而,它在GPU上的實現存在高延遲,會造成不自然的響應.2020年Im等人[18]提出基于點云的神經網絡處理器.該處理器采用異構內核結構以加速卷積層和采樣層,實現了使用NUI所必需的低延遲.
1.3.4 醫學領域
醫學原位可視化能夠顯示患者特定位置的成像數據,其目的是將特定病人的數據與3維模型相結合,如將手術模擬過程直接投影到患者的身體上,從而在實際位置顯示解剖結構.2011年Placitelli等人[19]采用采樣一致性初始配準算法(sample consensus initial alignment, SAC-IA),通過快速配準三元組計算相應的匹配變換,實現點云快速配準.
模擬醫學圖像如X射線是物理學和放射學的重要研究領域.2020年Haiderbhai等人[20]提出基于條件生成式對抗網絡(conditional generative adversarial network, CGAN)的點云X射線圖像估計法.通過訓練CGAN結構并利用合成數據生成器中創建的數據集,可將點云轉換成X射線圖像.
2 模型形狀結構
了解并確定高層形狀結構及其關系能夠使得模型感知局部和全局的結構,并能通過部件之間的排列和關系描繪形狀,這是研究形狀結構分析的核心課題.隨著真實世界的掃描和信息的挖掘,以及設計模型規模的增大,在大量信息中進行3維幾何模型的識別和分析變得越來越重要.
2.1 結構信息
對于3維物體,僅明確局部信息遠遠不夠,更重要的是結構關系,它是理解整體3維結構的關鍵,利用結構關系可以更好地把握物體的語義信息.
2.1.1 拓撲結構
3維物體在局部結構之間有內在聯系,而這些聯系是智能推理的基本能力.明確部件之間的對稱性、表面的連續性及主軀干和其他部位間的聯系,即明確物體本身拓撲結構對3維物體的理解起重要作用.
現有的大多數方法都是對圖像的空間或時間關系進行建模,為了捕捉點云局部區域之間的結構交互作用,2019年Duan等人[21]提出結構關系網絡(structural relation network, SRN)解釋點云中局部區域的結構依賴性.該方法通過計算局部結構之間的相互作用,解釋它們之間的關系,從而使學習到的局部特征不僅編碼3維結構,而且編碼與其他局部區域的關系.相較于對局部信息的利用,2018年Deng等人[22]提出點對特征網絡(point pair feature network, PPFNet),學習全局信息的局部特征描述符,以在無組織的點云中到對應點.
相鄰點往往具有相似的幾何結構,因此通過鄰域圖傳播特征有助于學習更穩健的局部模式.2018年Shen等人[23]提出了2種新的操作來改進PointNet,使之更有效利用局部結構.第1種方法是定義局部3維幾何結構,它類似于處理圖像的卷積核.第2種方法利用局部高維特征結構,從3維位置生成的近鄰圖上重復進行特征聚合.
為了學習點云內的空間拓撲結構,2019年He等人[24]提出GeoNet,針對不同任務,采用不同融合方法.具體來說,選擇PU-Net用于點云上采樣,PointNet++[25]則用于其他任務(重建、分類等).
2.1.2 算法性能對比分析
具體來說,文獻[21]的SRN模塊證明了結構關系推理在點云數據分析中的有效性.它具有很強的泛化能力,可以很容易地與現有網絡相融合.它不需要特定的標簽也能捕捉到高度相關的局部結構和常見的結構關系.對于具有復雜局部結構的點云數據,其效果更為顯著.文獻[22]學習純幾何上的局部描述符,并高度感知全局上下文,在精度、速度、對點密度以及對3維姿態變化的魯棒性方面達到了較高的性能.其主要限制是內存占用.文獻[23]能夠有效地捕捉局部信息,直接利用局部幾何結構.2種新的操作能夠顯著提高點云語義學習的性能.但是,這種方法需要盡量避免在頂層改變鄰域圖結構.文獻[24]學習對局部和全局結構信息都進行編碼的特征,可用于與其他網絡架構融合以提高其性能,但數據集中像火箭這樣的棒狀物體只占小部分,所以GeoNet會在推理這類樣例時出錯.
2.2 形狀信息
形狀分析與識別中長期存在的問題是如何使得模型具有多樣且逼真的3維形狀,并具有相關語義和結構特點的能力.
2.2.1 形狀分析
形狀分析的目的往往不是幾何意義上的,而是功能的或語義級別的.局部描述符是各種3維形狀分析問題的核心,它應該對形狀的結構變化保持不變,并且對丟失的數據、異常值和噪聲具有魯棒性.
2017年Huang等人[26]采用能夠自動學習3維形狀局部描述符的方法,不需要輸入部件分割,通過學習多個形狀類別,可直接生成通用的描述符.網絡將幾何和語義上相似的點嵌入描述符空間中,其產生的描述符可以用于各種形狀分析應用.
借助多種數據格式,2017年Shafiq等人[27]提出點云到2維網格的表示方法和體系結構.現有的大多數方法在低層中使用較少的濾波器,在高層中逐漸增加其數量,但這可能丟失重要特征信息.Shafiq等人主張在低分辨率的輸入層也使用大量濾波器,這不會顯著影響參數的總數,還能實現更高精度.
基于層次化的思想,2017年Klokov等人[28]提出的Kd-network、2018年Xie等人[29]提出的注意力形狀上下文網絡(attentional shape context net, attentional SCN)以及2019年Liu等人[30]提出的RS-Conv(relation-shape convolutional neural network)和Mo等人[31]提出的StructureNet分別以不同方法實現分析模型形狀信息的目的.
具體來說,Kd-network[28]在多方面模仿Conv-Nets[32]但使用kd-tree形成計算圖、共享可學習參數,并以自下而上的方式計算層次表示.attentional SCN[29]不會刪除點之間的空間關系,它通過構建形狀上下文的層次結構,以解釋端到端過程學習的局部和全局上下文信息.RS-Conv[30]可以將規則網格使用的卷積神經網絡(convolutional neural network, CNN)擴展到不規則配置,實現點云的上下文形狀感知學習.StructureNet[31]引入n元層次結構編碼,從根本上避免了二值化引起的不必要的數據變化,從而大大簡化了學習任務.
2.2.2 算法性能與對比分析
文獻[26]在對象類別未知時也能產生有效的局部描述符.但它對局部信息和上下文都很敏感,且在生成局部描述符過程中,只依靠透視投影來獲取局部表面信息,而投影得到的信息可能不夠全面.此外,對于形狀和拓撲結構變化顯著的部件,它使用的非剛性對齊方法易于生成不精確的訓練對應,而太多錯誤的訓練對應將影響描述符的區分性能.文獻[27]結合了體素表示和2維圖像的優點.文獻[28]內存占用小且計算效率高.但在形狀分類中,對于較小的模型,每個epoch的學習時間短,達到收斂的周期數會增加.對于較大的模型,kd-tree構造的時間較長.文獻[29]通過層次結構傳遞信息,以獲取豐富的局部和全局形狀信息,并據此來表示目標點的內在屬性.文獻[30]在法線估計任務中,可能對一些棘手的形狀(如旋轉樓梯)不太有效.文獻[31]允許對具有多種幾何和結構變化的包圍盒和點云進行形狀合成,可用于不同的分析任務中.然而,StructureNet是基于數據驅動的方法,它繼承了數據集中數據的采樣偏差.對于包含具有分離部分或非對稱部分的模型,其生成效果不盡如人意.
3 模型重建與變換
由于遮擋等多種因素的限制,利用激光雷達等點云獲取設備得到的數據存在幾何信息和語義信息的丟失以及拓撲結構的不確定,這直接導致了數據的質量問題.為后續任務的處理帶來極大挑戰.
3.1 形狀修復與重建
點云的不完整給后續處理任務帶來了一定的困難和挑戰,這突顯出點云補全作為點云預處理方法的重要性.
直接對原始點云進行形狀補全與修復的方法是2019年Sarmad等人[33]提出的RL-GAN-NET及Wang等人[34]提出的漸進上采樣網絡、2020年Huang等人[35]提出的PF-Net及繆永偉等人[36]提出的基于生成對抗網絡的方法.PF-Net,RL-GAN-NET與基于生成對抗網絡的方法是對殘缺點云的補全:PF-Net只輸出缺失部分;RL-GAN-NET輸出修復后的完整模型;基于生成對抗網絡的方法生成缺失部分并與原輸入數據合并得到完整模型.漸進上采樣網絡則是將稀疏點云變密集.
RL-GAN-NET[33]基于數據驅動填充缺失區域,通過控制生成對抗網絡(generative adversarial network, GAN)將含噪聲的部分點云轉換成更具真實性的完整點云.基于片元的點集漸進上采樣網絡[34]由具有相同結構的上采樣單元組成,但每個單元對應不同級別的細節,可以成功地將稀疏的輸入點集逐步上采樣到具有豐富幾何細節的密集點集.PF-Net[35]能夠從部分點云及其低分辨率特征點中提取多尺度特征,增強了網絡提取語義和幾何信息的能力.文獻[36]為了修復補全模型形狀,以生成對抗網絡為基礎,利用Wasserstein距離優化模型,補全形狀的同時保持精細結構信息.
在不直接對原始點云進行操作的情況下,廣泛使用的方法是基于圖像進行的重建.2019年Nguyen等人[37]、Choi等人[38]都提出了由單一2維圖像重建物體3維點云表示的方法.2種方法都能夠根據輸入圖像對隨機點集變形以生成目標對象,并具有可伸縮性,即輸出點云的大小可以是任意的.
Nguyen等人[37]提出的點云變形網絡(point cloud deformation network, PCDNet)基于局部特征,利用高層語義進行預測.它的整體形狀特征是由AdaIN提取出來的.提取操作是對稱映射,因此網絡對無序點云具有不變性.Choi等人[38]利用CNN從輸入圖像中提取形狀特征,然后利用提取的形狀信息將隨機初始化的點云變形為給定對象的形狀.
文獻[33-36]都可以完成補全點云,文獻[34-35]直接對原始點云進行處理,不需要進行其余步驟,但文獻[33]需要對原始點云進行降維.文獻[37-38]從目標圖像提取點的形狀信息并根據提取的信息進行模型重建.
3.2 模型變形
點云變形過程中,缺乏有效語義的局部結構監督可能會在學習過程中積累誤差,這將嚴重限制學習特征的可分辨性,進而影響網絡在3維點云理解中的能力.本節根據不同方式,將變形問題分為直接變形與借助圖像信息變形2種方式展開介紹.
直接變形原點云數據的方法中,研究思路是多樣的,可以根據成對形狀[39]、多角度分析[40]等多種方法實現.
一般的變形方法是單方向的.2018年Yin等人[39]提出的P2P-Net可以實現雙方向的變形.變換前后的2點集可以是同一形狀在不同視角或不同時間下的采樣,也可以是不同形狀中的采樣.2019年Han等人[40]提出的多角度點云變分自編碼器MAP-VAE(multi-angle point cloud variational auto-encoder)將有效的局部監督與變分約束下的全局監督相結合.
與直接基于點的變形不同,2019年Wang等人[41]提出了基于目標2維圖像、3維網格或3維點云來變形網格的3維變形網絡(3-dimensional deformation network, 3DN),Zhou等人[42]提出了基于圖像信息的點云變形監測方法.前者通過保持原網格拓撲結構不變和對稱性等性質,可以生成合理的變形,能夠適應原模型和目標模型中不同密度的變化.后者利用點云顏色信息和反射強度信息的特點,將小波變換模極大值技術引入點云強度圖像的特征提取中.
在變形中,文獻[39]不需要成對的點以及點的對應關系,只需成對的形狀即可實現變形.文獻[40]通過多角度分析并分割點云,利用變分約束來促進新形狀的生成.文獻[41]更改3維網格曲面頂點位置并變形為目標模型.文獻[42]需要將點云轉換為2維強度圖像再變形.
3.3 算法性能對比分析
在形狀補全修復及模型重建任務中,文獻[33]能夠在缺失大量區域的情況下實現補全,其形狀完成框架在具有噪聲前提下,解決了點云數據的低可用性.文獻[34]主要解決不同細節級別和點云密度的上采樣問題,能夠自適應地確定感受野.這種基于自適應的網絡結構能夠以端到端的方式在高分辨率點集上訓練,從具有稀疏性和噪聲的點集得到高精度的點云幾何結構.文獻[35]能夠以部分點云作為輸入并直接輸出缺失部分,但它對數據集的要求較高.文獻[36]能有效保證網絡的收斂性和訓練穩定性.但是對于局部點較為稀疏且具有精細結構的模型,其修補效果并不理想.
文獻[37-38]都是根據輸入圖像對隨機點集進行變形,并生成任意大小點云表示的模型.前者能夠簡單有效地生成高質量的形狀模型.然而,其輸出坐標的預測不受語義形狀信息和局部一致性的約束,這會降低性能.后者可訓練參數的數量與點云大小無關,因此不需要額外開銷,其效率較高.
在變形任務中,文獻[39]可以在沒有明確點與點之間對應關系的情況下實現雙向性的幾何變化,但它無法學習并保存輸入形狀的內在屬性.文獻[40]聯合利用局部和全局自監督學習更具鑒別力的點云特征,并能夠從不同角度捕捉局部區域的幾何和結構信息.文獻[41]可以使用現有的高質量網格模型來生成新模型,但當原模型或目標模型缺失區域較大時,變形還需要更改原模型的拓撲結構,否則會產生錯誤的對應點.文獻[42]能夠明確點云中各點之間的拓撲關系.
4 形狀分類與分割
基于檢索或劃分的目的,對具有相似特征或相同屬性的點云數據進行區域的分割或屬性的分類是極其重要的.
4.1 基于體素的網絡
使用體素這種規則的數據結構可以保留和表達空間分布.通常,每個體素僅包含布爾占用狀態而不是其他詳細的點分布.
2016年Qi等人[43]對體素CNN和多視角CNN進行了改進并介紹了2種不同的體素CNN網絡結構.第1種網絡有利于對對象的細節進行研究,第2種網絡有利于捕捉對象的全局結構.
2017年Tchapmi等人[44]提出SEGCloud,Wang等人[45]提出O-CNN.SEGCloud聯合基于體素的3維全卷積神經網絡(3-dimensional fully convolutional neural networks, 3D-FCNN)和基于點的條件隨機場(conditional random fields, CRF),從而在原始3維點空間中實現分割.O-CNN的核心思想是用八叉樹表示3維形狀并離散化其表面,僅對3維形狀邊界所占據的稀疏八叉樹進行CNN運算.其特殊之處在于八叉樹的葉子節點存儲的是法向量信息.
與SEGCloud類似,同樣使用稀疏卷積的是2018年Graham等人[46]介紹的子流形稀疏卷積網絡(submanifold sparse convolutional networks, SSCN).他們引入子流形稀疏卷積(submanifold sparse con-volution, SSC)算子,并將其作為SSCN的基礎,以稀疏體素作為輸入,能夠處理高維空間中的數據,并可用3維點云語義分割.
為了有效地編碼體素中點的分布,2019年Meng等人[47]提出新的體素變分自編碼器(variational auto-encoder, VAE)網絡VV-NET.每個體素內的點分布由自編碼器捕捉,該編碼器利用徑向基函數(radial basis functions, RBF),既提供了規則結構,又能獲取詳細的數據分布.
2020年Shao等人[48]提出基于空間散列的數據結構,設計了hash2col和col2hash,使得卷積和池化等CNN操作[49]能夠有效地并行化,使用完美空間散列(perfect spatial hashing, PSH)整合3維形狀.
文獻[43]的2種體素CNN網絡結構輸出結果的精度值較高,但高分辨率會限制該網絡的性能.文獻[44]結合了神經網絡(neural networks, NNs)、三線性插值(trilinear interpolation, TI)和全連接條件隨機場(fully connected conditional random fields, FC-CRF)的優點,表現出相當高的性能.與“暴力”體素化方案相比,文獻[45]使用的八叉樹結構有效減少了占用的內存,但是也生成了許多冗余的空葉八叉樹.特別是對于高分辨率模型,其內存開銷相當大.文獻[46]在識別大場景中的對象表現出高效率、高精度的優勢.文獻[47]占用內存較小且效率較高,但與其他方法相比,其精度不顯優勢且處理某些特定形狀時可能會出錯.文獻[48]利用3維形狀邊界稀疏性,建立不同分辨率下模型的層次散列表,顯著減少了CNN訓練過程中占用的內存.
4.2 基于視圖的網絡
在基于視圖的方法中,通常將點云投影到2維圖像中,并利用2維CNN提取及融合圖像特征,進而應用于后續具體任務中.
受現有深度學習網絡的限制,基于多視角的方法只能從特定角度識別點云模型.因此,選擇角度提取點云的所有信息是難點.2017年Lawin等人[50]與2019年Zhou等人[51]分別提出不同的視角選擇方法來應對挑戰.為了完全覆蓋渲染視圖中的點云,Lawin等人[50]控制等距角,生成具有不同俯仰角和平移距離的圖像.Zhou等人[51]提出了MVPointNet,其視圖是利用變換網絡(transformer network, T-Net)[1]生成的變換矩陣來確定多個相同的旋轉角度獲取的,這保證了網絡對幾何變換的不變性.
點云包含了豐富的3維信息,不同的視圖包含不同的2維信息.不同于以上只利用不同視角圖像的方法,2017年Guerry等人[52]提出的SnapNet-R可同時利用2維圖像和3維空間結構中的信息,2019年Jaritz等人[53]提出的MVPNet將2維圖像特征聚合到3維中,2019年Yang等人[54]提出的Relation Network綜合考慮了不同視圖之間區域到區域和視圖到視圖的關系.
對于單個圖像,SnapNet-R[52]生成多個視圖,所有視圖都對應于從不同的角度看到的場景.MVPNet[53]采用貪心算法動態選擇RGB-D幀,并獲取不同幀上的2維圖像特征,然后將這些特征提升到3維,并將它們聚集到原始點云中以進行語義分割.對于給定視圖中的某區域,Relation Network[54]從其他視圖中找到匹配或相關區域,并利用來自匹配或相關區域的線索來重新增強該區域的信息.此外,其還采用注意選擇機制生成各視圖的重要性分數,該分數反映視圖的相對辨別能力.
文獻[50]僅使用顏色值或法線作為輸入也能取得較高的性能.文獻[51]提取中心點與鄰域點之間的信息,在3維形狀分類中精度較高.文獻[52]證明了3維結構重建與2維語義標記是互利的.文獻[53]計算了2維圖像特征,這可以從高分辨率的圖像中收集額外的信息,提升到3維中的2維特征包含上下文信息.文獻[54]的網絡結構考慮了區域到區域的關系和視圖到視圖的關系,對3維對象的學習能力較強.
4.3 基于點的網絡
CNN處理點云的研究中,大多數方法需要對點云進行體素化或將其轉化為視圖等其他操作,這會帶來一定的局限性.直接對點云進行處理即相當于直接處理原始數據,其優勢十分顯著.
基于點云數據不規則的特點,針對采樣密度不確定的情況,2018年Atzmon等人[55]提出點卷積神經網絡(point convolutional neural networks, PCNN),對圖像CNN進行了泛化,允許調整網絡結構,利用擴展算子和約束算子生成適應點云的卷積.Hermosilla等人[56]提出Monte Carlo卷積,使用Monte Carlo積分做卷積計算,利用這一概念可以組合處理來自不同層的多個采樣信息.2020年Zhai等人[57]提出雙輸入網絡(dual-input network, DINet)框架和適用于該框架的正則化方法,可以減少噪聲和背景對分類任務的干擾.
對于局部信息丟失問題,2019年白靜等人[58]提出的MSP-Net與2020年Hu等人[59]提出的RandLA-Net都能在網絡訓練過程中有效改變感受野范圍.2021年杜靜等人[60]引入局部殘差塊能夠提取更多局部細節信息.
只使用最高層特征將會丟失較多底層細節信息,在滿足點云覆蓋的完備、空間分布的自適應性及區域之間的重疊性的要求下,文獻[58]提出多尺度局部區域劃分及多尺度局部特征融合算法.
昂貴的采樣技術或計算繁重的預/后處理使得大多數方法只能處理小規模點云.RandLA-Net[59]使用隨機采樣解決規模局限性,引入局部空間編碼(local spatial encoding, LocSE)模塊逐步增大感受野來學習復雜的局部結構,能有效保留幾何特征.文獻[60]融合幾何結構特征及語義特征,改進殘差模塊以實現點云數據復雜幾何結構的提取.
基于點云本身無序性的特點,為了滿足置換不變性與順序不變性,2019年Wu等人[61]提出PointConv、Wang等人[62]提出DGCNN、Komarichev等人[63]提出環狀卷積、Zhang等人[64]提出ShellNet,2020年Zhao等人[65]提出Point Transformer,2021年Guo等人[66]提出PCT.
PointConv[61]擴展到反卷積PointDeconv可以獲得更好的分割結果,這是大多數現有算法不能實現的操作.DGCNN[62]顯式地構造局部圖并學習邊的嵌入,因此能夠在語義空間中對點進行分組.點云中普遍存在法向翻轉,環形保護策略下,無論相鄰點如何排列,其結果不變.Komarichev等人[63]將搜索區域限制在局部環形區域中.這使得相鄰點序列的首尾相連,因此,可以基于任意起始位置排序.卷積運算ShellConv使用同心球的統計信息來定義代表性特征并解決點序模糊性.ShellNet[64]是在ShellConv的基礎上進一步建立的.
Point Transformer[65]與PCT[66]的相同之處在于都以transformer為基礎.文獻[65]設計了適合于處理點云的point transformer layer,并構造以其為核心的residual point transformer block,它有助于局部特征向量之間的信息交換,為所有數據點生成新的特征向量.文獻[66]的PCT編碼器將輸入坐標嵌入到特征空間中生成特征,繼而輸入注意模塊中獲取具有區分性的表示并學習點的語義信息.
針對點云密度不同的問題,文獻[55]計算效率高,對點云中點的階數不變,對采樣密度變化魯棒性強,但其計算量較大.文獻[56]參數數量較少,但在不同規模的點云中,效率與質量方面的高性能不能兼得.文獻[57]在處理包含大量噪聲和復雜背景信息的真實數據時也能表現出較高精度.文獻[58]所提的MSP-Net是多尺度分類網絡,隨著神經網絡深度的增加及感受野的擴大,其特征抽象程度也越高.文獻[59-60]可直接處理大規模點云,前者能夠很好地權衡效率和質量問題,后者注意力機制的引入及殘差模塊的改進,提高了網絡獲取更具區分性語義特征的提取能力.
針對順序與置換不變的特點,文獻[61]能夠完全逼近任意3維點上的連續卷積,特定的反卷積操作可以獲得更好的分割結果.文獻[62]使用有向圖表示點云的局部結構,能夠更好地捕捉結構信息,但該方法的某些細節設計影響了其效率.文獻[63]可以在局部環形區域上定義任意大小的卷積核,更好地捕獲鄰域結構,且捕獲到的信息不重疊.文獻[64]在不增加網絡層數的情況下允許感受野更大,且解決了卷積階數問題.文獻[65]中residual point transformer block集成self-attention與線性投影,可以減少維數并加速處理過程.文獻[66]用注意模塊的輸入和注意特征之間的偏移量來代替注意特征,提出隱式拉普拉斯算子和歸一化改進,偏移注意優化過程可以近似理解為拉普拉斯過程.
4.4 算法性能對比分析
本節將從評估指標與算法詳細對比分析2部分進行介紹.
4.4.1 評估指標
目前廣泛使用的指標為準確率(accuracy,Acc)、精確率(precision,P)、召回率(recall,R)以及交并比(intersection over union,IoU).
指標計算公式中,TP(true positives)表示正類判定為正類,FP(false positives)表示負類判定為正類,FN(false negatives)表示正類判定為負類,TN(true negatives)表示負類判定為負類.
N類對象中,第i類的準確率為
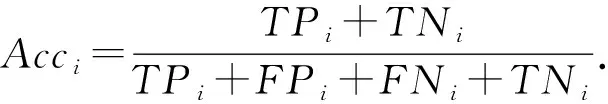
(1)
N類對象的類間平均準確率為
(2)
精確率指的是所有被判定為正類(TP+FP)中,真實的正類(TP)所占的比例.N類對象中,第i類的精確率為
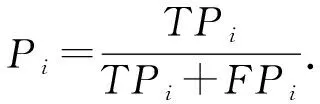
(3)
N類對象的總體精度為
(4)
N類對象中,第i類的交并比為
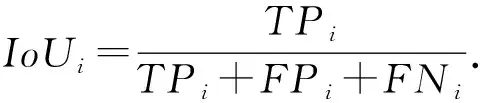
(5)
所有類的平均交并比為
(6)
召回率指所有真實為正類(TP+FN)中被判定為正類(TP)占的比例,其計算方式為
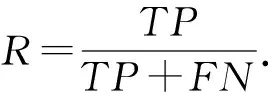
(7)
除了這些指標外,還有一個重要指標為平均精準度(average precision,AP).基于精確率和召回率即可得到PR(precision-recall)曲線(R值為橫軸,P值為縱軸),則PR曲線的線下面積即為AP值.注:mAP為所有類別下AP的均值.
4.4.2 算法對比
文獻[43-48]都是基于體素的方法.具體來說,文獻[43]提出的2種體素CNN網絡結構在結合數據擴充和多方向池化后,性能有顯著的提升.該方法顯著地改善了體素CNN在3維形狀分類方面的研究現狀,但更高的3維分辨率會限制該網絡的性能.文獻[44]使用了基于標準體素的3D-FCNN,并且仍然可以使用稀疏卷積來適應體素的稀疏性.文獻[45]利用了八叉樹表示的稀疏性和形狀的局部方向性,實現了緊湊的存儲和快速的計算.但其存儲和計算開銷隨著八叉樹深度的增加呈2次增長,且該算法沒有考慮形狀的幾何變化.文獻[46]在識別單個模型部件或大場景中的對象時,都表現出高效率高精度的優勢.文獻[47]進一步使用RBF來計算每個體素內的局部連續表示.此外,對對稱性進行了編碼,并在不增加參數數量的情況下提高了網絡的表達能力,獲得更穩健的分割結果.VV-Net對包含噪聲的數據具有一定的魯棒性.但對某些特定形狀的輸入,它得到的效果并不好.文獻[48]中PSH的運用使得散列表的大小與輸入3維模型的大小相同.2種GPU算法使得基于散列的模型實現了CNN操作的并行計算,其內存開銷比現有的基于八叉樹的方法(如O-CNN)小得多,運行速度較快.但所有PSH都是使用CPU生成的,使用GPU可進一步加速該過程.
文獻[50-54]都是基于視圖的方法.只利用不同視角圖像的算法中,文獻[50]從點云中提取不同信息(如顏色、深度值和法線)并組合多種信息作為輸入,判斷其對分割結果的影響.該方法證明多種信息的融合能顯著提高分割性能.該方法得益于大量現成的用于圖像分割和分類的數據集,這大大減少甚至消除了訓練3維數據的需要.此外,該方法提高了空間分辨率和分割結果的質量.文獻[51]引入了豐富的局部結構特征,這些特征包含了中心點及其鄰域點之間的信息,能夠更好地表示和捕捉模型的上下文結構.多個視圖的融合包含了更多的點云信息,使網絡在3維目標分類任務中具有更強的魯棒性和準確性.
除了不同視角圖像外,還考慮其他信息(點云信息、不同視圖的聯系等)的算法中,與僅使用RGB-D單幅圖像相比,文獻[52]利用了點云中的信息,具有更高的完備性,能夠快速生成與原始相機位置不同的視點.文獻[53]有效融合2維視角圖像和3維點云,在將2維信息提升到3維之前,先計算了2維圖像特征,證明了從多視角圖像中計算圖像特征的優越性.其網絡訓練速度較快,對密度變化的點云具有更高的魯棒性,在遮擋情況下也能實現良好的分割.文獻[54]從不同的角度有效地連接相應的區域,從而增強了單個視圖圖像的信息,利用視圖之間的相互關系,并對這些視圖進行集成以獲得有區別的3維對象表示.
文獻[55-66]都是基于點的處理方法.主要針對點云密度問題的算法中,文獻[55]的框架由擴展算子和約束算子組成,其核心思想得到適應任意點云的卷積.文獻[56]能在相鄰點數目可變的感受野中直接工作.特定的結構可以在2個不同采樣密度之間進行卷積,實現從較低采樣到較高采樣的映射,也可以降低采樣分辨率.該方法在均勻與非均勻采樣中都表現出優越性能.但是,它存在效率與質量的權衡:小規模點云或較小的感受野中,其計算速度很快但結果不精確;大規模點云或較大的感受野中,其結果精度較高但計算速度慢.文獻[57]提出適用于DINet框架的正則化方法能有效減少點云噪聲和遮擋對原始信息的干擾.文獻[58]建立不同尺度的局部感受野,能隨著感受野的擴大獲得抽象程度更高的多尺度局部語義重要特征,其多尺度局部空間劃分貼合點云空間分布,但該算法未考慮單一尺度局部區域的關系.文獻[59-60]都采用隨機采樣解決點云規模過大的問題,但隨機采樣在快速采樣的同時很可能會丟失關鍵特征.二者為彌補該問題所采取的方法也有一定的相似之處:前者引入LocSE,后者設計多特征提取模塊.它們都對中心點、鄰域點的3維坐標、中心點與鄰域點間的歐氏距離和相對坐標進行編碼,用于后續特征處理.
主要針對順序與置換不變的算法中,文獻[61]可以實現與2維卷積網絡中相同的平移不變性以及點云中點的順序不變性.此外,它可以在保證高效利用內存的同時實現改變求和順序技術.文獻[62]動態更新圖的同時聚合點,它描述的是相鄰點之間的邊特征.文獻[63]可以在具有相同大小卷積核且不增加參數的情況下覆蓋較大的區域.基于環的方法可以聚集更多具有區分性的特征,能夠更好地捕獲形狀的幾何細節.文獻[64]定義從內到外的卷積順序,允許高效的鄰域點查詢.ShellNet具有快速的局部特征學習能力,同時能以較快的速度訓練網絡.文獻[65]引入了可訓練的、參數化的位置編碼,這對后續特征轉換非常重要.文獻[66]采用鄰域嵌入策略來改進點嵌入,增強局部上下文信息獲取能力.其注意機制在獲取全局特征方面是有效的,但是它可能忽略了點云學習所必需的局部幾何信息.
表2與表3分別給出各算法在處理分類與分割任務的性能比較.其中,由于文獻[45,48]受分辨率影響,表中給出分辨率為643的結果.
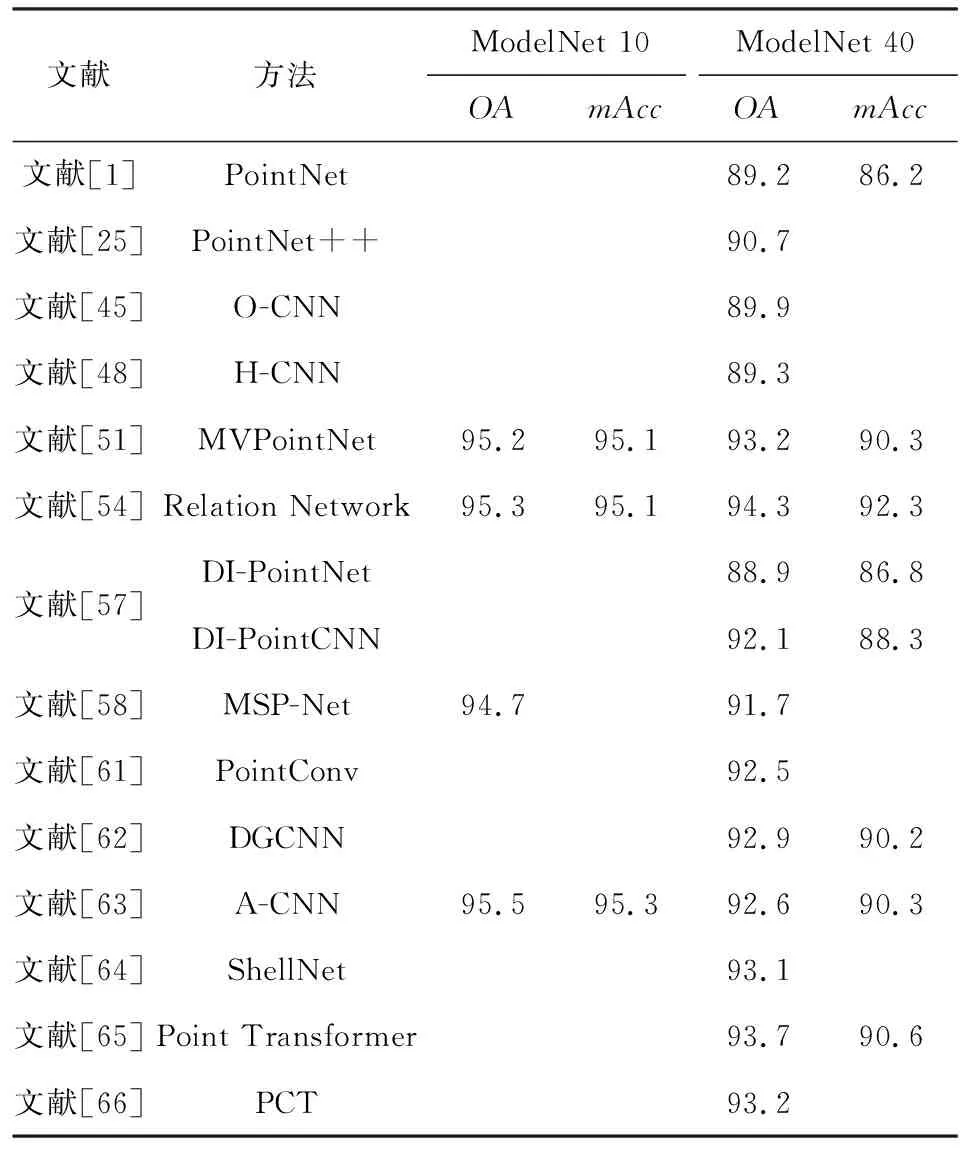
Table 2 Performance Comparison of Classified Tasks 表2 分類任務性能比較 %
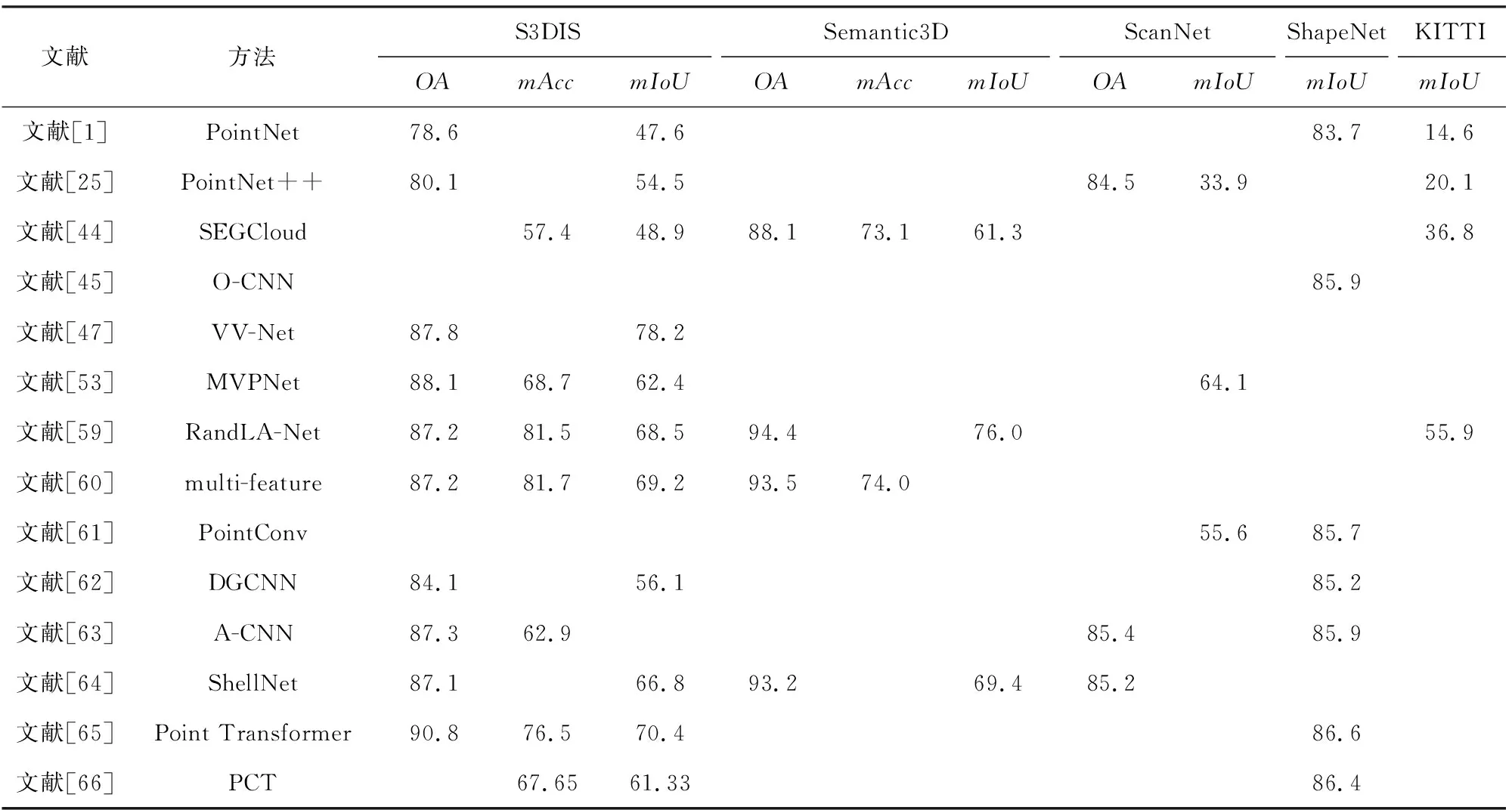
Table 3 Performance Comparison of Segmentation Tasks 表3 分割任務性能比較 %
5 目標檢測與跟蹤
自動駕駛、機器人設計等領域中,3維目標檢測與跟蹤至關重要.自動駕駛車輛和無人機的避障等實際應用中,涉及障礙物檢測與跟蹤.
5.1 3維目標跟蹤
目標跟蹤是推測幀的屬性并預測變化,即推斷對象的運動情況,可以利用預測對象的運動信息進行干預使之實際運動符合預期目標或用戶要求.
為了從點云中推斷出目標對象的可移動部件以及移動信息,2019年Yan等人[67]提出RPM-Net.其特定的體系結構夠預測對象多個運動部件在后續幀中的運動,同時自主決定運動何時停止.
2020年Wang等人[68]提出PointTrackNet.網絡中提出了新的數據關聯模塊,用于合并2幀的點特征,并關聯同一對象的相應特征.首次使用3維 Siamese跟蹤器并應用于點云的是Giancola等人[69].基于Achlioptas等人[70]提出的形狀完成網絡,2019年Giancola等人[69]通過使用給定對象的語義幾何信息豐富重編碼后的表示來提高跟蹤性能.
2019年Burnett等人[71]提出aUToTrack,使用貪婪算法進行數據關聯和擴展卡爾曼濾波(extended Kalman filter, EKF)跟蹤目標的位置和速度.Simon等人[72]融合2維語義信息及LIDAR數據,還引入了縮放旋轉平移分數(scale-rotation-translation score, SRTs),該方法可更好地利用時間信息并提高多目標跟蹤的精度.
文獻[67]可以從開始幀和結束幀的移動部分導出變化范圍,故參數中不含變換范圍,減少了參數個數.文獻[68]提供的跟蹤關聯信息有助于減少目標短期消失的影響,其性能比較穩定,但是當汽車被嚴重遮擋時,結果會出現問題.文獻[69]解決了相似性度量、模型更新以及遮擋處理3方面的問題,但該方法直接利用對稱性來完善汽車整體形狀會導致更多噪聲.文獻[71]實際需要計算被檢測物體的質心,這種方法能有效檢測行人,但對于汽車來說,其結果并不準確.文獻[72]提出的SRTs可用于快速檢測目標,提高了準確性和魯棒性.
5.2 3維場景流估計
機器人和人機交互中的應用可以從了解動態環境中點的3維運動,即場景流中受益.以往對場景流的研究方法主要集中于立體圖像和RGB-D圖像作為輸入,很少有人嘗試從點云中直接估計.
2019年Behl等人[73]提出PointFlowNet,網絡聯合預測3維場景流以及物體的3維包圍盒和剛體運動.Gu等人[74]提出HPLFlowNet,可以有效地處理非結構化數據,也可以從點云中恢復結構化信息.能在不犧牲性能的前提下節省計算成本.Liu等人[75]提出FlowNet3D.由于每個點都不是“獨立”的,相鄰點會形成有意義的信息,故而FlowNet3D網絡嵌入層會學習點的幾何相似性和空間關系.
文獻[73]先檢測出object并計算出ego motion和scene flow,再去回歸各個object的motion,它從非結構化點云中直接估計3維場景流.文獻[74-75]的整體結構類似,都是下采樣-融合-上采樣,直接擬合出scene flow.
5.3 3維目標檢測與識別
在城市環境中部署自動型車輛是一項艱巨的技術挑戰,需要實時檢測移動物體,如車輛和行人.為了在大規模點云中實現實時檢測,研究者針對不同需求提出多種方法.
2019年Shi等人[76]提出PointRCNN,將場景中的點云基于包圍盒生成真實分割掩模,分割前景點的同時生成少量高質量的包圍盒預選結果.在標準坐標中優化預選結果來獲得最終檢測結果.
2019年Lang等人[77]提出編碼器PointPillars.它學習在pillars中組織的點云表示,通過操作pillar,無需手動調整垂直方向的組合.由于所有的關鍵操作都可以表示為2維卷積,所以僅使用2維卷積就能實現端到端的3維點云學習.
考慮到模型的通用性,2019年Yang等人[78]提出STD,利用球形錨生成精確的預測,保留足夠的上下文信息.PointPool生成的規范化坐標使模型在幾何變化下具有魯棒性.box預測網絡模塊消除定位精度與分類得分之間的差異,有效提高性能.
2019年Liu等人[79]提出大規模場景描述網絡(large-scale place description network, LPD-Net).該網絡采用自適應局部特征提取方法得到點云的局部特征.此外,特征空間和笛卡兒空間的融合能夠進一步揭示局部特征的空間分布,歸納學習整個點云的結構信息.
為了克服一般網絡中點云規模較小的局限性,2019年Paigwar等人[80]提出Attentional PointNet.利用Attentional機制進行檢測能夠在大規模且雜亂無章的環境下重點關注感興趣的對象.
2020年Shi等人[81]提出PV-RCNN.它執行2步策略:第1步采用體素CNN進行體素特征學習和精確的位置生成,以節省后續計算并對具有代表性的場景特征進行編碼;第2步提取特征,聚集特征可以聯合用于后續的置信度預測和進一步細化.
文獻[76]生成的預選結果數量少且質量高.文獻[77]能夠利用點云的全部信息,其計算速度較快.文獻[78]能夠將點特征從稀疏表示轉換為緊湊表示,且用時較短.文獻[79]充分考慮點云的局部結構,自適應地將局部特征作為輸入,在不同天氣條件下仍能體現出健壯性.文獻[80]不必處理全部點云,但預處理步驟使得計算成本較大.文獻[81]結合基于體素的與基于PointNet的優勢,能夠學習更具鑒別力的點云特征.
5.4 算法性能對比分析
跟蹤算法中,文獻[67]主要關注的是物體部件的跟蹤,文獻[68]與文獻[69]則主要檢測同一物體在不同時間的狀態.文獻[67]的優勢在于可以同時預測多個運動部件及其各自的運動信息,進而產生基于運動的分割.該方法實現高精度的前提是輸入對象的幾何結構明確,否則很有可能會生成不完美的運動序列.文獻[68]在快速變化的情況下,如突然剎車或轉彎,其結果仍可靠.但是當目標被嚴重遮擋時,其結果并不可靠.由于大多數模型(如汽車模型)只能從單側看到,文獻[69]利用對稱性完善汽車形狀的方法未必是有效的.文獻[71]的處理方法較簡單且用時較短,在CPU上運行時間不超過75 ms.它能在檢測行人時達到較高性能.但用于擁擠道路的自動駕駛時,其采用的質心估計對于汽車并不準確.文獻[72]同時利用2維信息與3維 LIDAR數據,且使用的SRTs指標可縮短訓練時間.
場景流估計算法中,文獻[73]聯合3維場景流和剛性運動進行預測,其效率較高且處理不同運動時具有魯棒性.文獻[74]與文獻[75]都以端到端的方式從點云中學習場景流.前者從非結構化的點云中恢復結構化,在生成的網格上進行計算,后者則是在點云的連續幀中計算.
檢測算法中,文獻[76]不會在量化過程中丟失信息,也不需要依賴2維檢測來估計3維包圍盒,故而可以充分利用3維信息.文獻[77]的處理速度較快,計算效率較高.文獻[78]具有較高的計算效率和較少的計算量,能夠同時集成基于點和基于體素的優點.文獻[79]引入局部特征作為網絡輸入,有助于充分了解輸入點云的局部結構.文獻[80]能夠有效地獲取數據的3維幾何信息.但是,將點云裁剪成較小區域等預處理步驟增加了計算成本.文獻[81]結合了基于體素與基于PointNet的優點,不僅保留了精確的位置,而且編碼了豐富的場景上下文信息.
表4給出KITTI數據集下不同算法處理跟蹤任務的性能對比.指標為多目標跟蹤準確度(multi-object tracking accurancy, MOTA)、多目標跟蹤精確度(multi-object tracking precision, MOTP)、目標大部分被跟蹤到的軌跡占比(mostly tracked, MT)、目標大部分跟丟的軌跡占比(mostly lost, ML)、ID改變總數量(ID switches, IDS)、跟蹤過程中被打斷的次數(fragmentation, FRAG)及每秒幀數(frames per second, FPS).

Table 4 Performance Comparison of Tracking Tasks 表4 處理跟蹤任務性能對比
表5給出在KITTI數據集下3維檢測框(3-dimensional detection benchmark, 3D)、BEV視圖下檢測框(bird eye view detection benchmark, BEV)與檢測目標旋轉角度(average orientation similarity detection benchmark, AOS)的檢測結果.其中,評估指標為AP,IoU閾值為:汽車0.7,行人和自行車0.5.
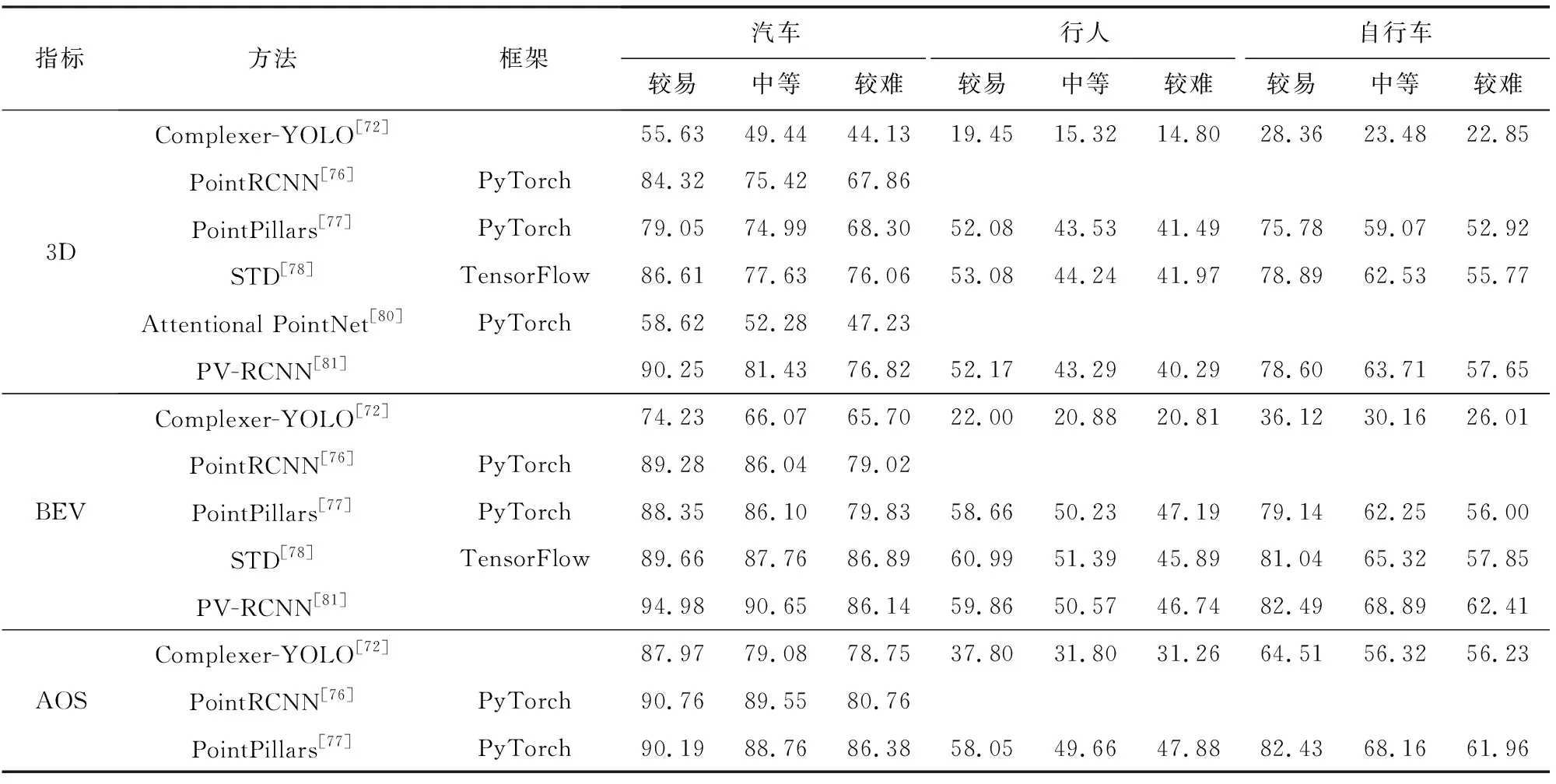
Table 5 Performance Comparison of Detecting Tasks 表5 處理檢測任務性能對比 %
6 姿態估計
3維姿態估計即確定目標物體的方位指向問題,在機器人、動作跟蹤和相機定標等領域都有應用.
6.1 位姿估計
解決3維可視化問題的中間步驟一般是確定3維局部特征,位姿估計是其中最突出的問題.
2017年Elbaz等人[82]提出的LORAX采用了可以處理不同大小點云的設置,并設計了對大規模掃描數據有效的算法.2019年Speciale等人[83]將原始3維點提升到隨機方向的3維線上,僅存儲3維線和3維點的關聯特征描述符,這類映射被稱為3維線云.2019年Zhang等人[84]從目標點云中自動提取關鍵點,生成對剛性變換不變的逐點特征,利用層次式神經網絡預測參考姿態對應的關鍵點坐標.最后計算出當前姿態與參考姿態之間的相對變換.
2018年Deng等人[85]提出了PPF-FoldNet,通過點對特征(point pair feature, PPF)對局部3維幾何編碼,建立了理論上的旋轉不變性,同時兼顧點的稀疏性和置換不變性,能很好地處理密度變化.
考慮到成對配準描述符也應該為局部旋轉的計算提供線索,2019年Deng等人[86]提出端到端的配準方法.這種算法在PPF-FoldNet[85]的工作基礎上,通過學習位姿變換將3維結構與6自由度運動解耦.該方法基于數據驅動來解決2點云配準問題.
2020年Kurobe等人[87]提出CorsNet,連接局部特征與全局特征,不直接聚集特征,而是回歸點云之間的對應關系,比傳統方法集成更多信息.
文獻[82]解決了2點云之間點數相差數倍的問題,它簡單、快速,并且具備擴展性,但在極端情況下,其結果會出錯.文獻[83]只使用了一個幾何約束,其準確性與召回率可以與傳統方法媲美,但這種方法的速度較慢.文獻[84]需要較少的訓練數據,因此對于沒有紋理的對象,它更快、更精確.文獻[85]繼承了多個網絡框架的優點,且充分利用點云稀疏性,能夠快速提取描述符.文獻[86]提高了成對配準的技術水平且減少了運行時間.文獻[87]結合了局部與全局特征,從平移和旋轉的角度而言準確性較高.表6上半部分給出位姿估計算法的核心方法及優勢對比分析.
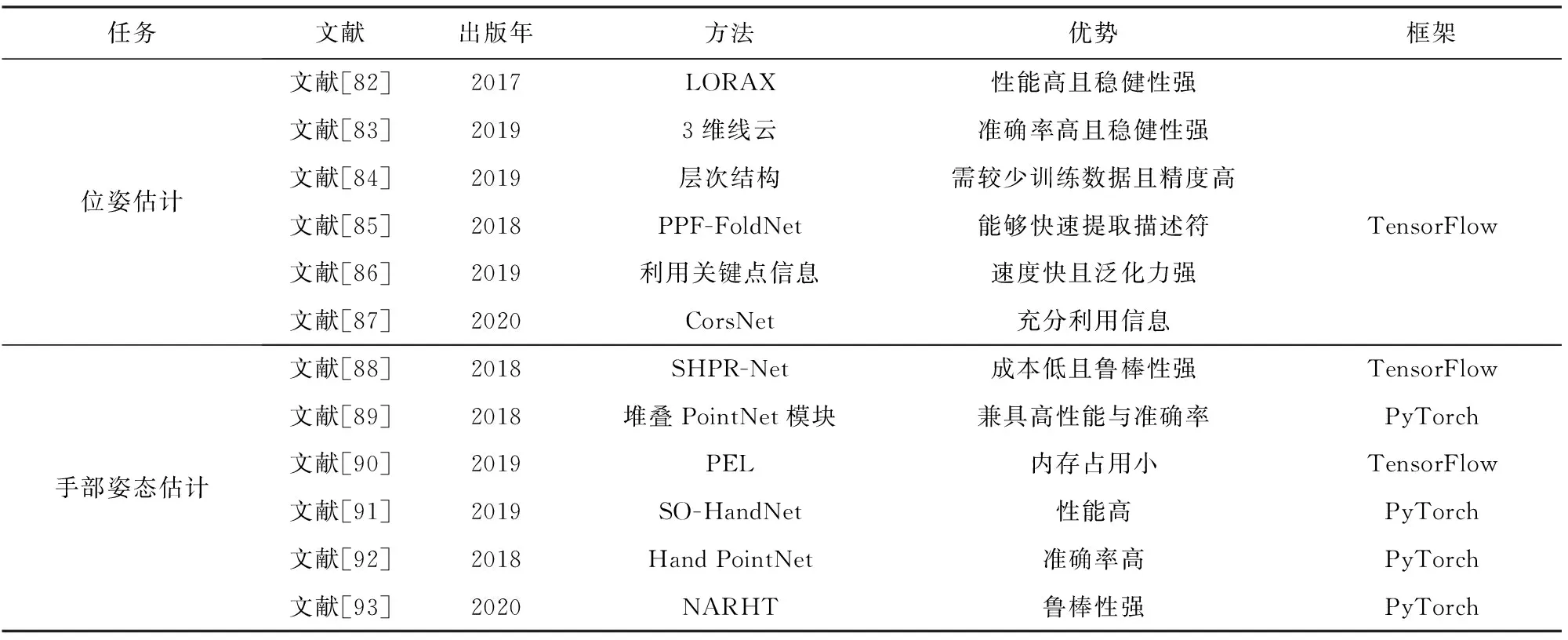
Table 6 Comparison of Pose Estimation Methods 表6 姿勢估計方法對比
6.2 手部姿態估計
點云作為更簡單有效的數據表示方法,其輸入的點集和輸出的手部姿態共享相同表示域,有利于學習如何將輸入數據映射到輸出姿態上.
為了直接從點云中估計手部姿態,同樣以手部3維點云為輸入,2018年Chen等人[88]提出語義手部姿態回歸網絡(semantic hand pose regression network, SHPR-Net),通過學習輸入數據的變換矩陣和輸出姿態的逆矩陣應對幾何變換的挑戰.Ge等人[89]提出的方法輸出反映手部關節的每點貼近度和方向的heat-maps和單位向量場,并利用加權融合從估計的heat-maps和單位向量場中推斷出手部關節位置.2019年Li等人[90]提出的方法以置換等變層(permutation equivariant layer, PEL)為基本單元,構建了基于PEL的殘差網絡模型.且手部姿態是利用點對姿勢的投票方案來獲得的,這避免了使用最大池化層提取特征而導致的信息丟失.
現有的手部姿態估計方法大多依賴于訓練集,而在訓練數據上標注手部3維姿態費時費力.2019年Chen等人[91]提出的SO-HandNet旨在利用未注記數據以半監督的方式獲得精確的3維手部姿態估計.通過自組織映射(self-organizing map, SOM)模擬點的空間分布,然后對單個點和SOM節點進行層次化特征提取,最終生成輸入點云的判別特征.
2018年Ge等人[92]提出Hand PointNet,提出的精細化網絡可以進一步挖掘原始點云中更精細的細節,能夠回歸出更精確的指尖位置.Huang等人[93]認為學習算法不僅要研究數據的內在相關性,而且要充分利用手部關節之間的結構相關性及其與輸入數據的相關性.基于此,2020年他們提出非自回歸手部transformer(non-autoregressive hand transformer, NARHT),以關節特征的形式提供參考手部姿態,利用其固有的相關性來逼近輸出姿態.
文獻[88]對點云的幾何變換具有魯棒性.文獻[89]能夠很好地捕捉空間中點云的結構信息.文獻[90]較利用體素的方法占用內存更少,但其效率不如基于深度圖像的方法.文獻[91]的特征編碼器能夠揭示輸入點云的空間分布.文獻[92]能夠捕捉復雜的手部結構,并精確地回歸出手部姿態的低維表示.文獻[93]采用新的non-autoregressive結構學習機制來代替transformer的自回歸分解,在解碼過程中提供必要的姿態信息.表6下半部分給出手部姿態估計算法的核心方法及優勢對比分析.
6.3 算法性能對比分析
位姿估計方法中,核心問題是找到旋轉矩陣與平移矩陣.文獻[83,85-86]都利用了RANSAC迭代算法.其中,文獻[83]實現了魯棒、準確的6自由度姿態估計.文獻[85]是無監督、高精度、6自由度變換不變的網絡.文獻[86]在挑戰成對配準的真實數據集方面優于現有技術,具有更好的泛化能力且速度更快.文獻[82]的LORAX能夠并行實現,效率較高,適合實時應用.它對隨機噪聲、密度變化不敏感,并且其魯棒性僅在極端水平下才會惡化.文獻[84]使用較少的訓練圖像實現了較高的準確性.文獻[87]提出的CorsNet回歸的是對應關系,而不是直接姿態變化.
手部姿態估計方法中,文獻[88]可獲得更具代表性的特征.SHPR-Net可以在不改變網絡結構的前提下擴展到多視點的手部姿態估計,這需要將多視點的深度數據融合到點云上.然而,融合后的點云也會受到噪聲的影響.文獻[89]可以更好地利用深度圖像中的3維空間信息,捕捉3維點云的局部結構,并且能夠集中學習手部點云的有效特征,從而進行精確的3維手部姿態估計.文獻[90]與基于體素化的方法相比,需要更少的內存.但與基于深度圖像的方法相比,需要更多的計算時間和內存.文獻[91]使用半監督的方式對網絡進行訓練,其性能可與全監督的方法相媲美.文獻[92]有效利用深度圖中的信息,以較少的網絡參數捕獲更多的手部細節及結構,并準確地估計其3維姿態.文獻[93]首次結合結構化手部姿勢估計與基于transformer的自然語言處理領域的轉換框架.引入參考手部姿勢為輸出關節提供等效依賴關系.文獻[89]的模型大小為17.2 MB.其中11.1 MB用于點對點回歸網絡,它是分層PointNet;6.1 MB用于附加的回歸模塊,它由3個全連層組成.文獻[90]有2種版本,回歸版本為38 MB,檢測版本為44 MB.文獻[91]中,手部特征編碼器(hand feature encoder, HFE)、手部特征解碼器(hand feature decoder, HFD)和手部特征估計器(hand pose estimator, HPE)的大小分別為8.1 MB,74 MB,8.5 MB.由于只在測試階段使用HFE和HPE,所以其網絡模型大小為16.6 MB.文獻[92]的模型大小為10.3 MB,其中回歸網絡為9.2 MB,指尖精細網絡為1.1 MB.不同方法在3個數據集上的性能對比分析如圖1所示:
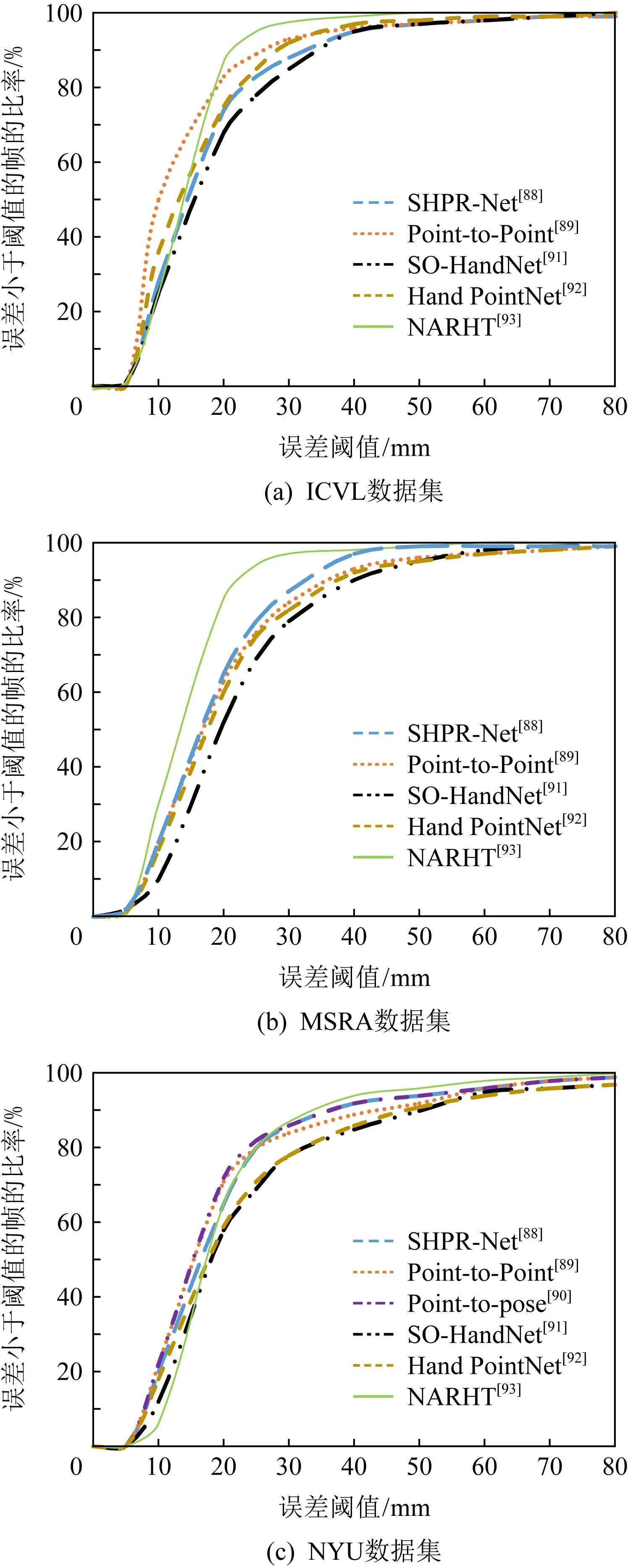
Fig. 1 Performance comparison of hand pose estimation methods圖1 手部姿態估計方法的性能對比
7 總 結
本文總結了近年來多種點云處理任務的方法,特別側重于基于深度學習的工作,為讀者提供了最新的研究進展.
大多數關于點云的綜述類文章都集中于討論點云分類分割處理任務.如文獻[94-95]只討論了語義分割任務;文獻[96-97]增加了目標檢測和分類任務的研究分析.其中,文獻[97]只用1節內容簡要介紹分類、分割及目標檢測三大任務,更關注于處理點云數據的深度學習方法,而不依據處理任務對其進行劃分討論.本文則考慮多種點云處理任務,包括模型重建與變換、分類分割、檢測跟蹤與姿態估計等.在模型分割分類中,由于大部分算法有用于實現點云分類與分割的功能,不同于文獻[96-97]將分類與分割作為2種類別分開討論,本文將它們統一考慮,并根據基于體素、基于視圖與基于點三大主流方法對其劃分并展開討論,明確給出各算法可處理的任務.
目前,已經有大量學者對點云處理任務進行研究并依據任務的不同提出多種方法,但這些方法或多或少都有一定的局限性.本文基于這些算法的不足總結點云處理任務所面臨的挑戰與發展趨勢.
1) 數據方面
大部分方法只在現有的數據集上進行實驗,而對于新獲取的數據并不適用.這很大程度上是由于新獲取的數據無法實現多角度、全方位的完美匹配,而且不同平臺獲得的數據難以融合,無法達到統一的標準.對于融合后的點云,具有魯棒性和區分性特征的提取有一定的難度,未來的研究可以從特征提取方面入手.
數據集尺度不均衡是由于真實復雜場景中檢測及識別小目標較為困難.未來研究工作可人工生成小目標樣本,增大數據集中小目標所占比例,進而在網絡訓練中提高其識別檢測能力.
數據質量對網絡(如transformers)的泛化性和魯棒性的影響較大[2].點云的幾何位置存在誤差時,可以通過已知控制點對其進行幾何矯正.當使用激光掃描獲取數據時,除了考慮掃描距離和入射角度的問題,還可以進行強度矯正,通過不同方法改善點云的質量.
隨著3維掃描技術的發展,大規模點云的獲取已不是難點,挑戰性在于如何對其進行處理.此外,算法精度依賴大批量的數據集[98],目前還沒有比較好的解決手段.
2) 性質方面
點云是3維空間內點的集合,它沒有提供鄰域信息,故而大部分方法需要依據不同的鄰域查詢方法確定點的鄰域,這將導致算法增加額外的計算成本.點云不能顯式地表達目標結構以及空間拓撲關系.此外,當目標被遮擋或重疊時,不能依據幾何關系確定拓撲結構,給后續處理任務帶來一定難度.
針對點云的不規則性及無序性,將其應用于深度神經網絡中進行相關任務的處理需要做數據形式的轉換,如體素化[40].但這些轉換操作不但增加了計算量,而且很可能在轉換的過程中丟失信息,所以直接的點云處理方法是重要的研究方向.
3) 網絡結構方面
① 基于快速和輕量級的模型.為了達到理想效果,目前的算法傾向于使用含大量參數的較大的神經網絡結構,導致計算復雜度高、內存占用大、速度慢等問題.因此,設計快速且輕量級的網絡架構具有較大的應用價值[99-100].
② 網絡結構的改良.優化網絡結構可使同一網絡處理多種任務,能夠很大程度地降低復雜度[2].還可以考慮與其他網絡結構結合[45]來實現優化目的.
4) 應用方面
室外場景信息較多、結構復雜,所以目前大多數方法著重于相對簡單的室內場景的分析.然而自動駕駛[12]等技術的研究無法在室內場景中完成,所以未來的研究方向可側重于構建適用于室外場景的網絡模型.
現有分割方法大都用于單個物體的部件分割[1]或場景中同類對象的語義分割[25].而真實場景中目標類別眾多、結構復雜,對同類對象的不同個體分割是3維形態檢測(文物、古建監測)的重要手段.
現有的大多數算法主要利用靜態場景中獲取的數據,在地震檢測等實際應用中,設計能夠應對變化場景的算法具有重要應用價值.利用時序上下文信息可作為其研究方向[99].
計算機視覺中的有效性通常與效率相關,它決定模型是否可用于實際應用中[100],因此在二者之間實現更好的平衡是未來研究中有意義的課題.
作者貢獻聲明: 李嬌嬌負責調研文獻、撰寫并修改全文;孫紅巖負責檢查論文并提出指導意見;董雨和張若晗負責檢索、歸納、整理相關文獻;孫曉鵬負責確定論文思路、設計文章框架.
猜你喜歡
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中華手工(2017年2期)2017-06-06 23:00:31
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
中外會展(2014年4期)2014-11-27 07:46:46
河南科技(2014年23期)2014-02-27 14:19:15
祝您健康(1987年3期)1987-12-30 09:52:32
