基于模糊K線的FCLSTM-vSVR模型的股票價格預測
2022-04-28 14:09:28劉茜陽張亞萌
智能計算機與應用 2022年4期
關鍵詞:模型
劉茜陽,宋 燕,張亞萌
(1上海理工大學 理學院,上海 200093;2上海理工大學 光電信息與計算機工程學院,上海 200093)
0 引 言
金融數據是現代經濟學不可分割的一部分。在金融市場中,由于具有較高的回報率,股票市場成為最熱門的投資領域。股票價格反映了公司的經營狀況,為投資者提供了重要的投資參考。為了使利益最大化,降低投資風險,投資者有必要對股票價格進行預測。然而,由于股票市場受到國外市場行情、時事生態和投資者行為及心理等多方面因素的影響,其數據呈現非線性和非平穩特征,這使得預測更具挑戰性。因此,長期以來,股票價格預測一直是金融學者研究的重點。
目前,股票預測方法主要包括基本分析法、技術分析法、組合分析法、時間序列分析法、機器學習和神經網絡等幾大類。傳統的股票市場預測技術主要是基于歷史股票數據的統計分析,如自回歸綜合移動平均模型(ARIMA)、自回歸條件異方差模型(ARCH)和廣義自回歸條件異方差模型(GARCH)模型,已被廣泛用于金融市場的預測中。但由于股票自身的非平穩與非線性特征,這些統計方法并不能在預測時達到較好的效果。
近幾年,隨著人工智能領域的發展,機器學習方法在股票市場預測中被廣泛應用,并取得了一定的研究成果。其中,人工神經網絡(ANN)和支持向量回歸(SVR)是預測金融時間序列流行的技術,因為不需要做任何的統計假設條件,可以直接提取數據間的非線性關系。同時,在小樣本預測方面,與ANN方法相比,SVR不容易陷入局部最優,因此有較大的優越性。但這些方法在處理輸入數據時并不能捕獲序列數據的順序信息,對時間序列問題沒有優秀的泛化能力,所以預測效果仍然受到了一些限制。
循環神經網絡(RNN)解決了這一問題,因其具備了時序概念,對股票的預測性能更好,但RNN在訓練時往往會出現梯度消失或梯度爆炸的問題,這導致時間序列的長期依賴關系很難學習。1997年,Hochreiter等人在論文《Long Short-Term Memory》中,針對RNN不能解決數據的長序依賴的問題進行研究并提出了LSTM模型。但是此LSTM的記憶存儲會隨序列長度的延伸而增長,最終可能會導致網絡崩潰,因此,在2000年針對該問題,Felix等人在LSTM神經元內部增加了遺忘門,使數據在傳輸時可以保持長時記憶。因此LSTM神經網絡被越來越多地應用到金融時間序列的預測中。
此外,基于LSTM神經網絡的混合方法也被廣泛應用于金融時間序列分析中,并通過與單一模型方法相比獲得更高精度的預測結果。然而,大多數混合方法雖然在一定程度上提高了預測精度,但這些方法都是通過對LSTM預測模型的輸入進行分析,而沒有對于LSTM模型產生的殘差進行分析預測。
基于上述問題,本文提出了一種將遺傳算法、LSTM網絡、模糊K線和改進的支持向量回歸算法(vSVR)相結合的混合股價預測模型。第一階段,該模型首先利用遺傳算法對LSTM神經網絡的參數進行優化,然后用訓練好的LSTM網絡產生預測輸出。第二階段,基于模糊K線模型提取到的模糊信息,采用vSVR模型預測誤差。最后,將兩階段的預測值之和作為最終的股票價格預測值。本文的貢獻主要如下:
(1)對于LSTM網絡的部分參數、如時間窗口大小和結構參數的估計,以往通常采用試錯法,但效率較低,本文利用遺傳算法優化LSTM網絡,以選擇最佳的窗口大小、神經元數目。
(2)由于股票價格序列可以由K線表示,而且會受到多方面因素的影響,本文利用模糊理論將股票價格數據轉換為模糊數據,采用vSVR模型建立預測誤差與股票模糊信息之間的映射關系,減小了模型的固有誤差。
(3)實驗結果顯示本文提出模型的預測效果更好,擬合程度更優。
1 背景知識
1.1 LSTM神經網絡
近年來,LSTM神經網絡已陸續應用于時間序列預測、文本分類等領域中,具有較高的精度。LSTM單元結構如圖1所示。由圖1可知,LSTM單元控制門結構主要包含遺忘門、輸入門與輸出門。遺忘門f控制細胞在1時刻的狀態有多少信息會被遺忘,輸入門i決定有多少新信息將被保存到時刻的細胞狀態,輸出門o決定輸出新細胞狀態的信息。其計算過程如下:
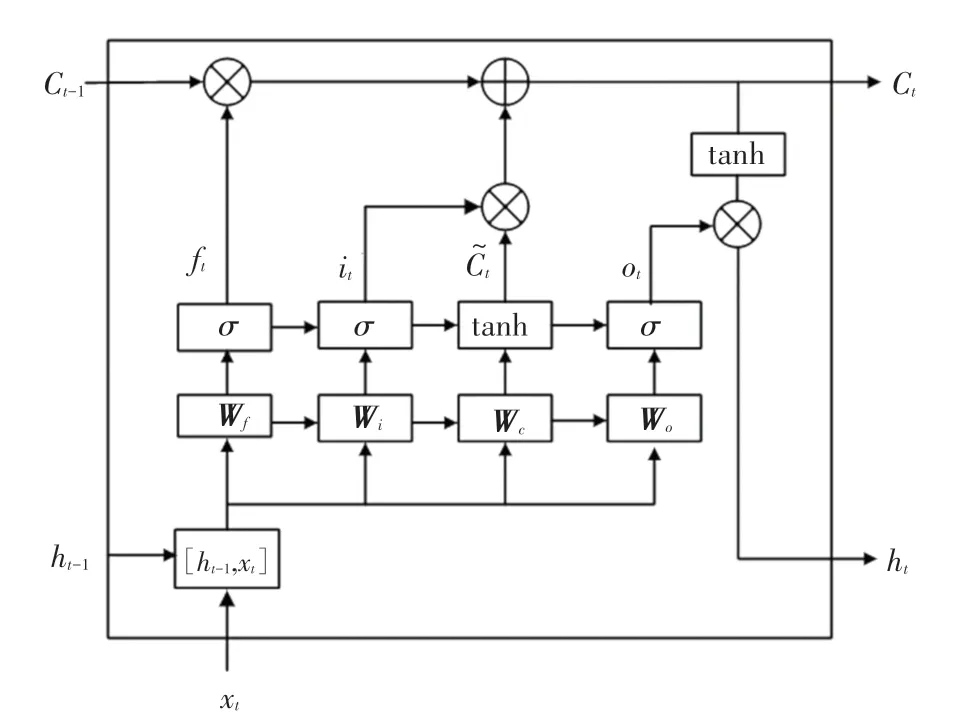
圖1 LSTM單元結構Fig.1 The LSTM cell structure
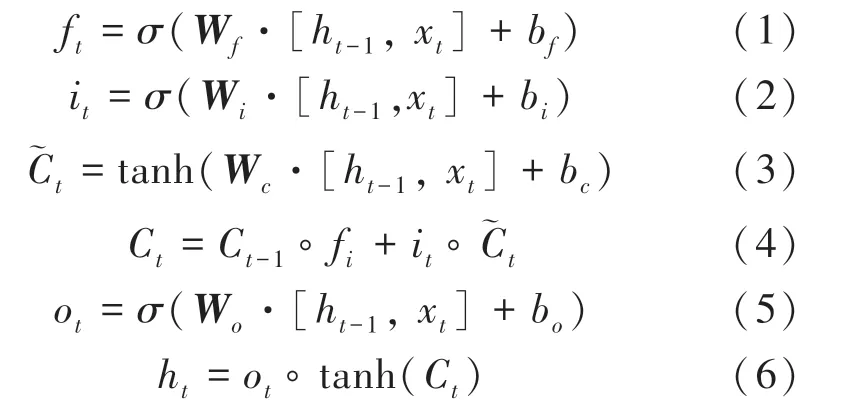
當使用LSTM網絡進行股票價格預測時,前期多個時刻的收盤價將作為輸入,當前時刻的收盤價作為輸出。對于LSTM模型預測而言,時間窗口起著較為重要的作用,每層神經元數也是LSTM模型優化的重要參數。本文利用遺傳算法對LSTM模型進行優化,得到時間窗口和隱藏層神經元數的最佳值或接近最佳值。
1.2 vSVR模型
SVR是支持向量機(SVM)在回歸問題領域的推廣,其中vSVR模型是一種改進的SVR,新參數控制誤差分數的上界和支持向量分數的下界,并自動最小化誤差參數,這使得更容易通過手動校準來調整參數。對于給定的一組數據點{(,),(,),…,(x,y)},其中x∈R是輸入,y∈是目標輸出,vSVR模型使用核函數將不可分割的輸入數據x映射到高維空間,從而使得目標值與訓練數據得到的回歸函數()(,())的距離最小,即極小化目標函數:

其中,常數表示錯誤樣本個數占總樣本個數份額的上界或支持向量與總樣本數比值的下界;()為核函數;和分別表示權重和偏置;表示誤差;ξ和為松弛變量;為懲罰參數。
其對偶問題為:
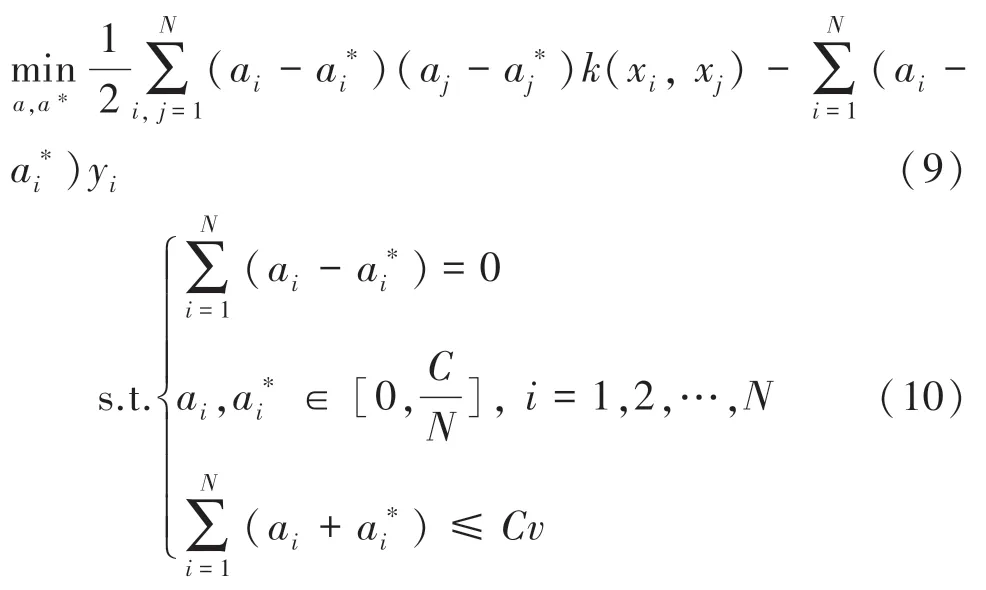
其中,和為拉格朗日乘子,且其值都不為0,(x,x)為核函數。決策函數變為:
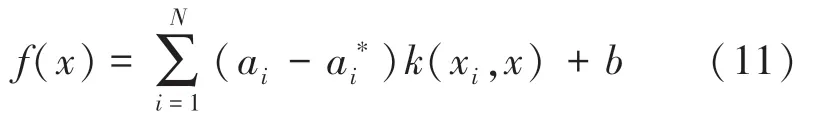
相對于傳統的經濟學模型和基本的機器學習方法,單一的LSTM神經網絡的預測精度雖然有所提高,但這并不能滿足人們的需求。針對這個問題,本文利用vSVR模型進行殘差分析來提高LSTM神經網絡的預測精度。
2 基于模糊K線和遺傳算法的FCLSTMvSVR股票價格預測方法
2.1 模糊K線
研究可知,經過不斷演變,K線圖現已形成了擁有完整形式和分析理論的技術分析方法。在K線圖中,影線長度和實體長度在識別K線模式上發揮了重要作用。但是,在日常生活中,人們對于K線的描述往往難以做到精確,甚至是模糊的,例如長的、中等的或者是短的。因此,本文將引入Naranjo等人在股票預測中所提到的模糊變量法,即運用模糊集合理論將本文的股票時間序列數據轉化為模糊化的數據,并作為vSVR模型的輸入,LSTM神經網絡的殘差作為輸出構建vSVR模型。
首先,將K線的3個變量包括上影線、下影線和實體的長度(L、L和L)作為輸入數據,R和R作為模糊輸出數據,分別表示實體與燭臺整體之間的相對大小和相對位置。交易時間中的3個模糊輸入可以定義如下:

其中,(),(),(),()分別表示時刻的開盤價、收盤價、最高價和最低價。然后利用式(15)將這3個變量縮放到[0,100]之間,數學公式具體如下:
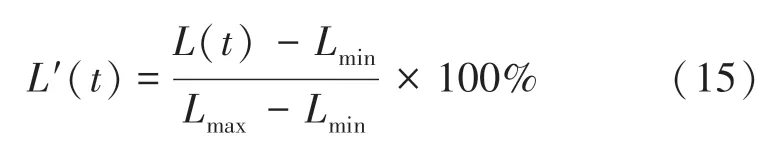
其次,用定義的4個模糊語言變量來描述3個輸入變量:NULL、SHORT、MIDDLE、LONG,如圖2所示。用5個模糊子集來描述R:DOWN、CENTER_DOWN、CENTER、CENTER_UP、UP,如圖3所示。用5個模糊子集來描述輸出變量R:LOW、MEDIUM_LOW、MEDIUM、MEDIUM_EQUAL、EQUAL,如圖4所示。
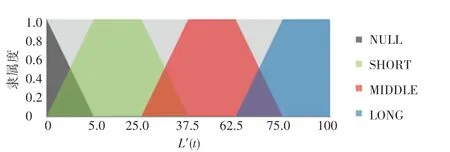
圖2 Lu、Ll和Lb的隸屬度函數Fig.2 Membership function for Lu、Ll and Lb
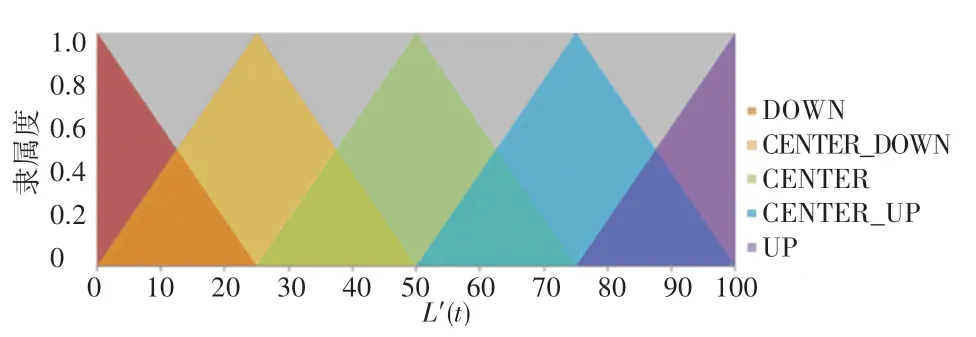
圖3 Rp的隸屬度函數Fig.3 Membership function for Rp
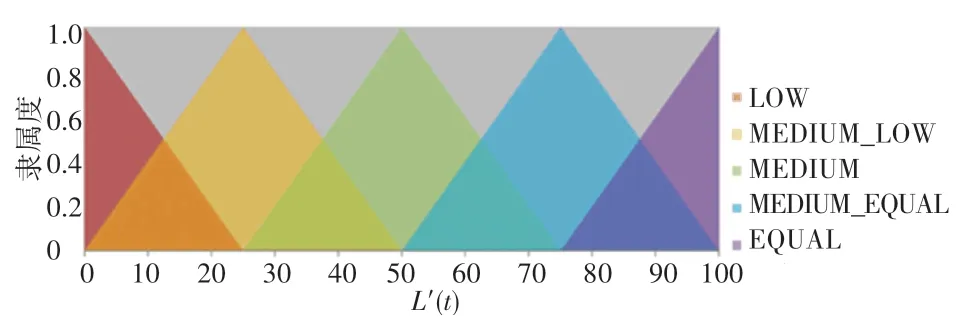
圖4 Rs的隸屬度函數Fig.4 Membership function for Rs
最后,基于128條IF-THEN模糊規則,詳見表1中的部分模糊規則,并用質心法去模糊化得到輸出數據。
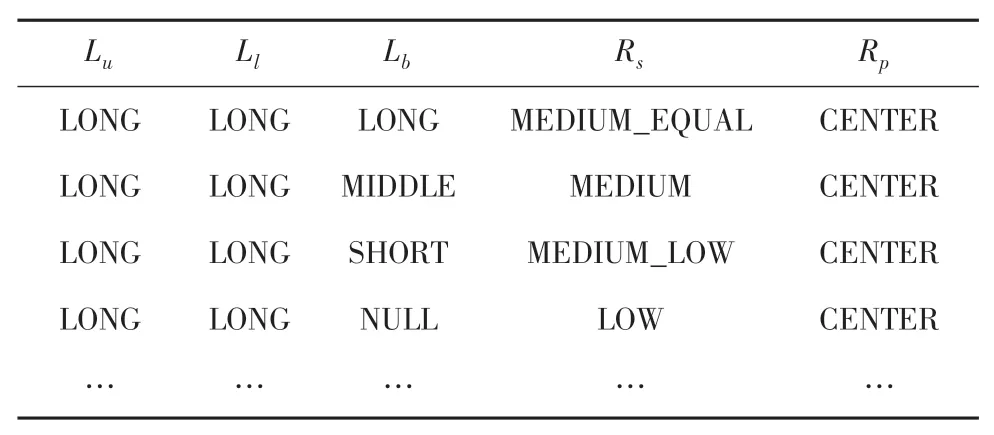
表1 模糊規則Tab.1 Fuzzy rules
2.2 GLSTM模型
由于LSTM網絡在學習過程中使用過去的信息,不同的時間窗口會對模型學習性能的提高起不同的作用。窗口過小,模型會忽略重要信息;窗口過大,模型會對訓練數據過度擬合。所以將遺傳算法用于優化LSTM模型,以選擇最佳的窗口大小、神經元數目,即GLSTM模型。圖5給出了GLSTM模型的流程圖。
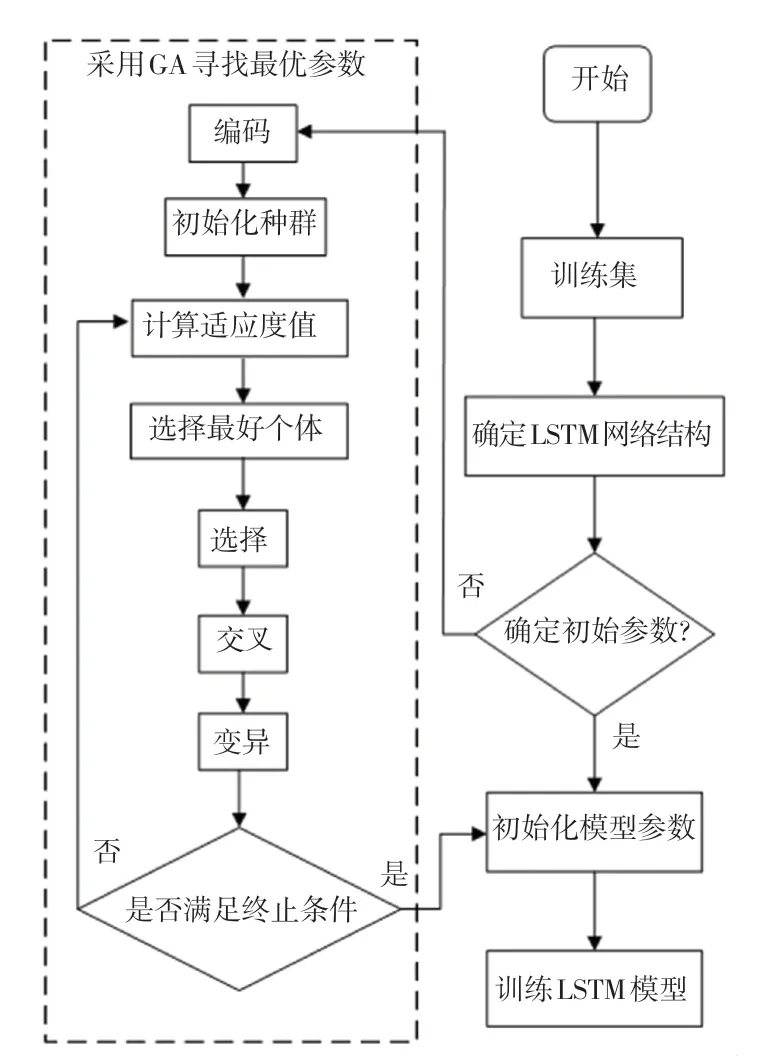
圖5 GLSTM模型流程圖Fig.5 The flowchart of the GLSTM model
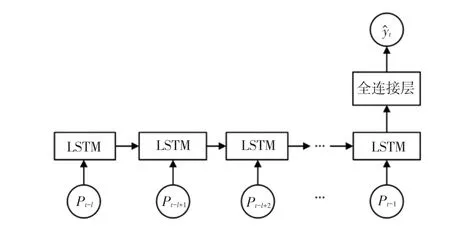
圖6 LSTM模型結構Fig.6 The structure of the LSTM model
2.3 FCLSTM-vSVR模型
由于GLSTM網絡模型較為單一,本文提出了一種基于模糊K線的FCLSTM-vSVR模型的股票價格預測方法。其中,主模型是基于遺傳算法的LSTM網絡模型,次模型是vSVR模型。
對于主模型,基于不同的參數設置,LSTM網絡模型的預測結果和性能會有所不同。所以本文首先通過遺傳算法進行參數尋優,找到模型的最佳時間窗口大小和隱藏層單元數,如2.2節所示。
對于次模型,vSVR模型是一種不依賴于任何先驗知識的機器學習非線性回歸方法,該模型參數具有明確意義,更利于得到精確的回歸解,因此在小樣本預測方面具有顯著優勢。圖7描述了FCLSTMvSVR模型的流程圖。
圖7中,FCLSTM-vSVR殘差修正模型的處理流程如下:
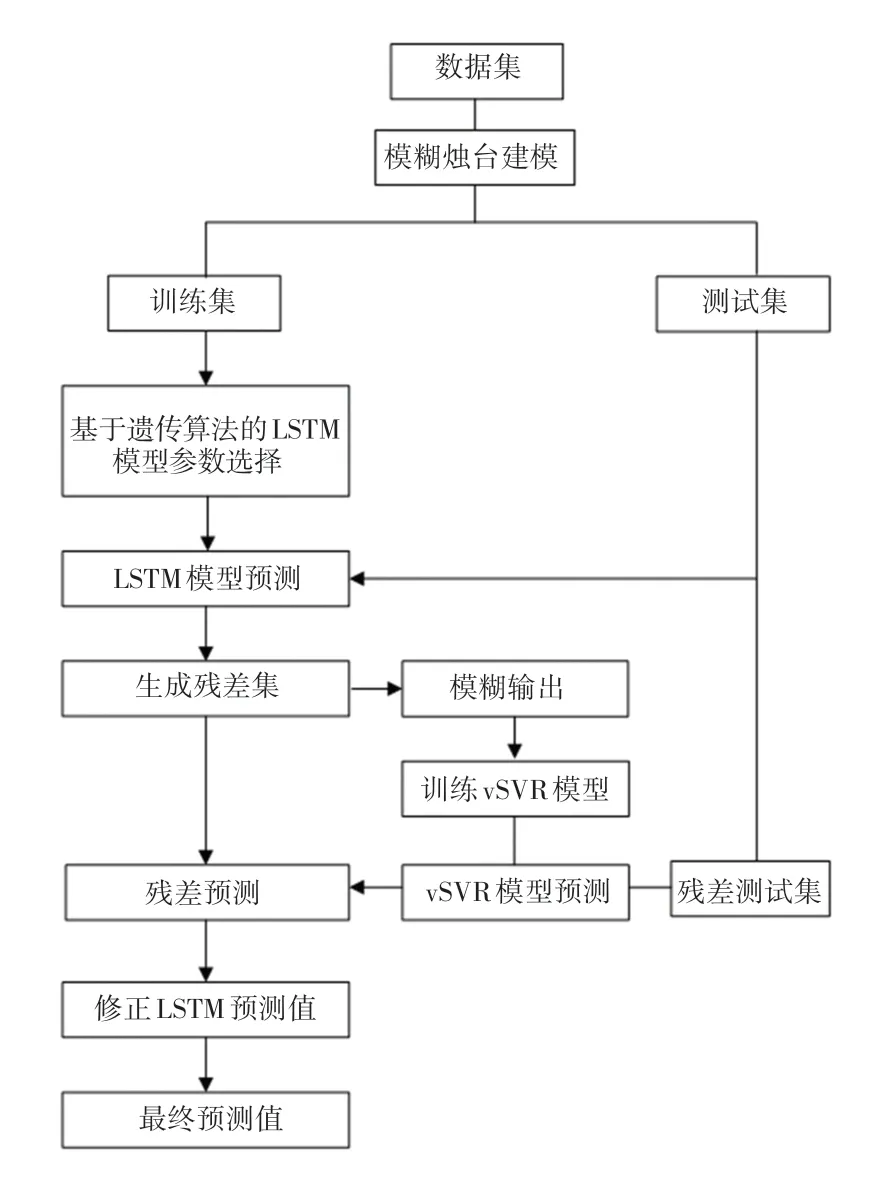
圖7 FCLSTM-vSVR模型流程圖Fig.7 The flowchart of the FCLSTM-vSVR model
(1)利用數據集原始價格數據建立模糊燭臺模型,得到2個模糊輸出數據R和R。然后將數據集拆分為訓練集和測試集,并利用最大-最小標準化公式進行歸一化處理。
(2)將訓練集部分劃分為驗證集,利用訓練集建立GLSTM預測模型:
①使用二進制位編碼表示時間窗的大小和LSTM神經單元數。
②隨機生成初始種群,根據適應度函數和選擇進行評估,然后進行交叉和變異,使用賭輪盤選擇。在本文中使用均方誤差()來計算每個染色體的適應度,輸入LSTM模型,在驗證集上計算,并返回該值將其作為當前遺傳算法解決方案的適應度值,得出最優時間窗口大小及最優神經網絡隱藏層單元數。
③重復該過程直至滿足終止條件。
(3)將經過良好訓練的GLSTM預測模型應用于整個訓練集的股票價格預測中,得到不同時刻的預測殘差值e,形成歷史殘差,稱為殘差集。
3 實驗
為了驗證實驗結果,本文將設置GLSTM模型、vSVR模型、BPNN模型、ARIMA模型、GLSTM-BPNN模型作為對照,其中GLSTM模型的輸入為收盤價歷史數據,并對ARIMA模型使用網格搜索法確定最優參數。本節通過股票歷史數據驗證了FCLSTM-vSVR模型的優越性和穩健性,也對FCLSTM-vSVR模型和其他模型進行了性能比較。所有模型都由Python3.6和TensorFlow實現,電腦的操作系統Windows 10,處理器是英特爾i7-7820HQ(2.90千兆赫)。模型的主要最佳參數是通過在驗證集上不斷試驗和參考相關文獻確定的,見表2。

表2 模型的部分參數設置Tab.2 Parameters setting of the model
3.1 數據來源
本文使用從雅虎財經網站獲得的5只股票數據集:AAPL、ADI、WTI、GSPC、IXIC。每只股票數據集的時間跨度為2015年1月4日至2020年10月22日。數據集劃分為訓練集和測試集,其中訓練集為80%,測試集為20%。這里,訓練集中選擇20%數據作為驗證集來確定超參數。
3.2 評價指標
為了量化模型的性能,引入了5個指標:平均絕對誤差()、平均絕對百分比誤差()、均方誤差()、均方根誤差()、決定系數(),這些指標可以定義如下:
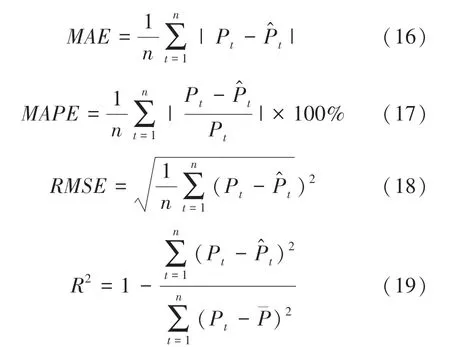
3.3 結果分析
首先通過遺傳算法,本文得到LSTM網絡的最優結構因素,包括LSTM網絡的時間窗口大小和隱藏層的單元數。其中,時間窗口大小取值范圍為[5,30],隱藏層單元數取值范圍為[10,100]。表3顯示了GLSTM模型在各個數據集上的訓練得到的參數結果。例如股票AAPL預測的最佳時間窗口大小為6,最佳LSTM隱藏層單元數為80。也就是說,對于股票AAPL,利用過去6個交易日的信息來分析預測是最有效的。
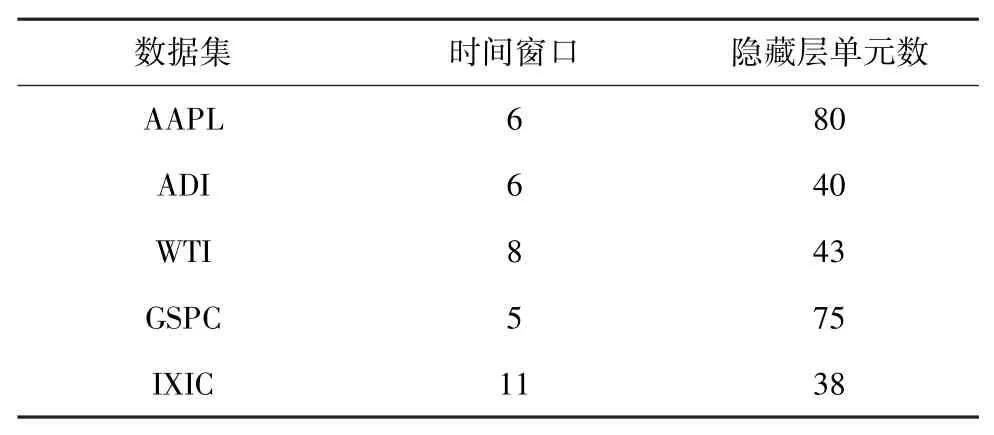
表3 GLSTM模型的時間窗口大小和隱藏層單元數Tab.3 Time window size and hidden layer units of GLSTM model
在得到模型最佳參數基礎上,利用提出FCLSTMvSVR預測模型對各個股票數據集進行股價預測,并與其他模型進行對比。表4~表8給出了不同模型在各個數據集上的平均預測誤差。對于單一模型,傳統的時間序列模型ARIMA的預測效果最差。機器學習vSVR模型的預測效果與BPNN模型的效果相近,而GLSTM模型的預測效果最好。這表明GLSTM模型在具有相同的輸入變量下可以獲得相比于普通機器學習的模型vSVR和BPNN更好的性能。所以在股票預測中,GLSTM網絡模型是一種較好的預測方法。
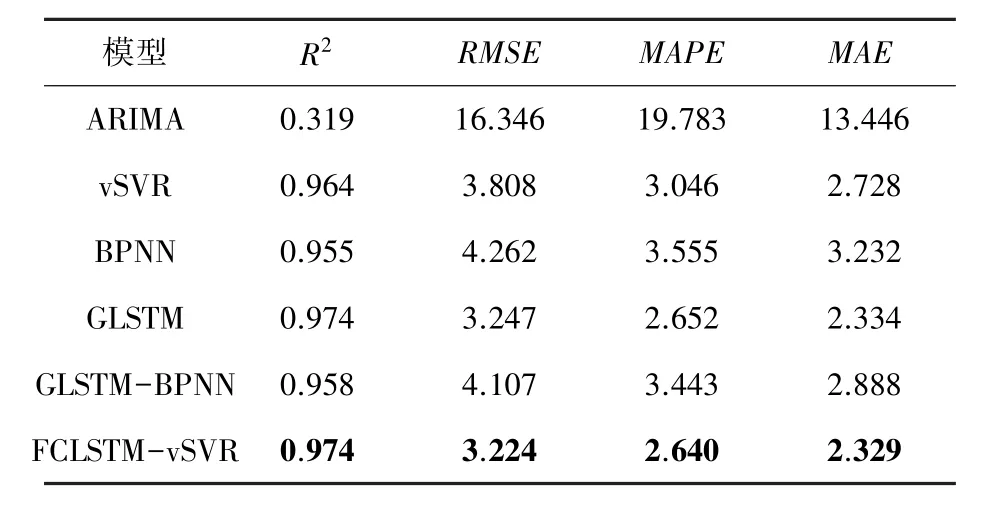
表4 AAPL上各模型比較結果Tab.4 The evaluation results of different models on AAPL
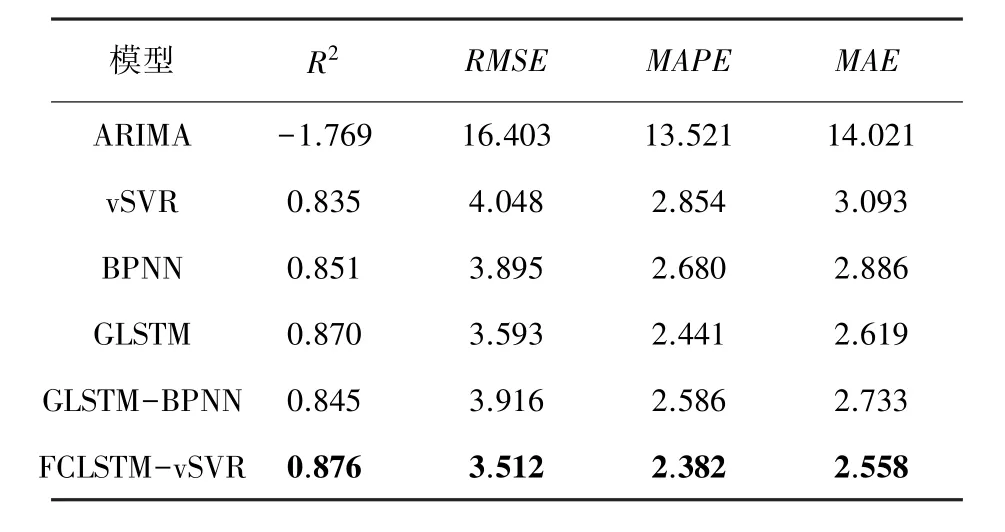
表5 ADI上各模型比較結果Tab.5 The evaluation results of different models on ADI
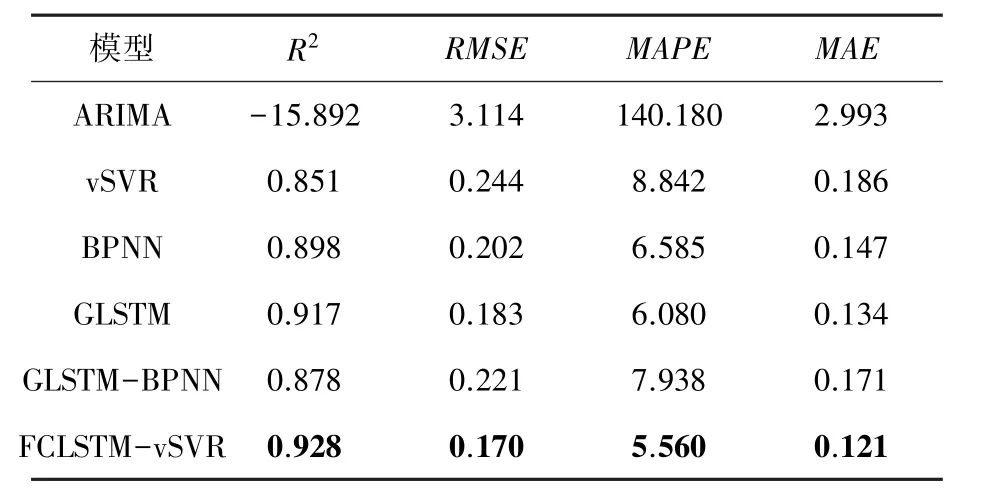
表6 WTI上各模型比較結果Tab.6 The evaluation results of different models on WTI
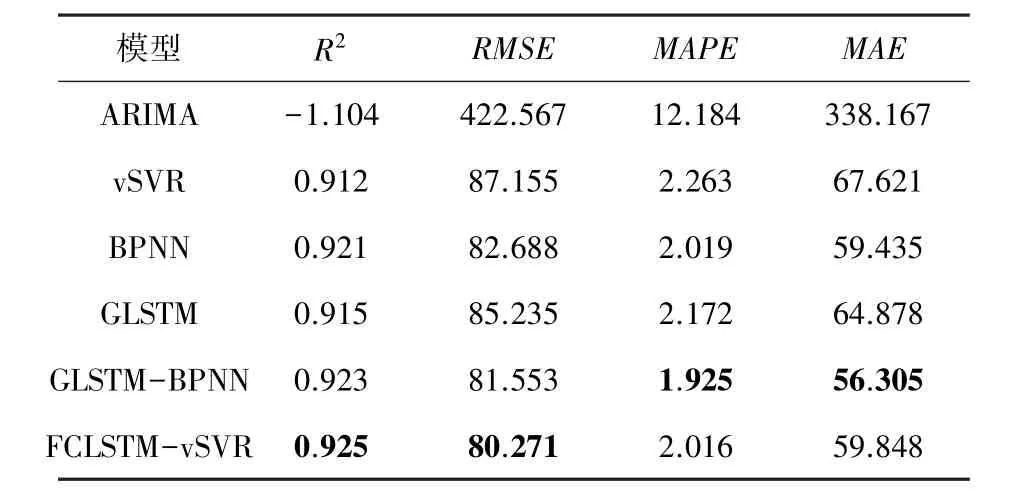
表7 GSPC上各模型比較結果Tab.7 The evaluation results of different models on GSPC
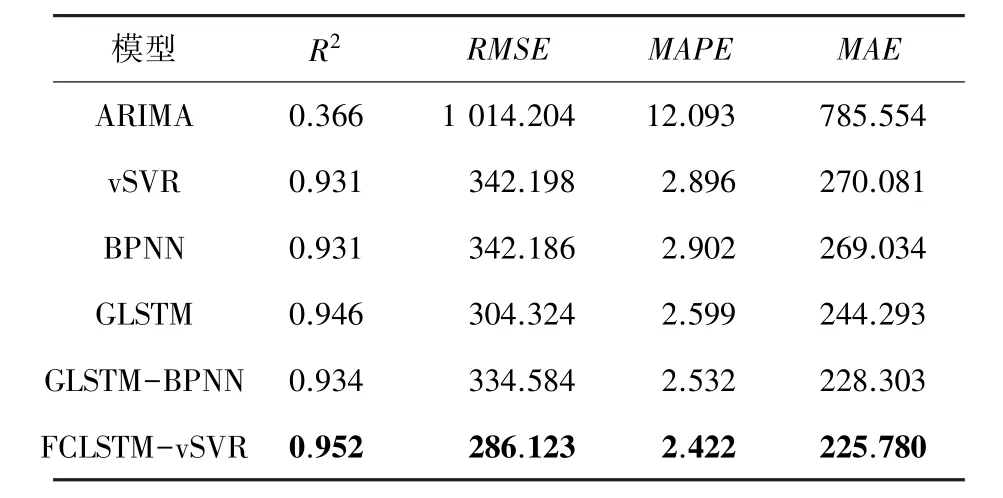
表8 IXIC上各模型比較結果Tab.8 The evaluation results of different models on IXIC
對于混合模型GLSTM-BPNN,在股票GSPC上的結果比其他單一模型的預測效果好,、、、分別為0.923 23、81.552 46、1.924 91、56.304 93,與GLSTM模型相比,精度分別提高了0.86%、4.32%、11.39%、13.21%。但在其他數據集上,模型GLSTM-BPNN結果并不理想,這可能與神經網絡參數設置不合理有關。
所有數據集中,與GLSTM模型相比,FCLSTMvSVR的誤差指標均保持較低值,也更接近于1,擬合效果更好。這一結果的主要原因是增加了殘差分析。結果表明,殘差分析是一種能顯著提高股價預測精度的方法,殘差中具有重要的信息價值,值得進行深入研究。基于模糊燭臺建模,2個模糊輸出變量(R和R)在殘差模型中成功應用,這一結果表明,在數據中的模糊信息對于殘差序列也具有影響。與GLSTM-BPNN模型相比,FCLSTM-vSVR的所有指標結果都較好,這表明vSVR模型與BPNN相比,對于小樣本具有更精確的回歸解。所以,對于股票價格預測,FCLSTM-vSVR模型與其他模型相比具有更好的預測效果。
為了更好地觀察模型GLATM-vSVR的性能,在測試集上實際值對于模型預測值的擬合效果如圖8所示。
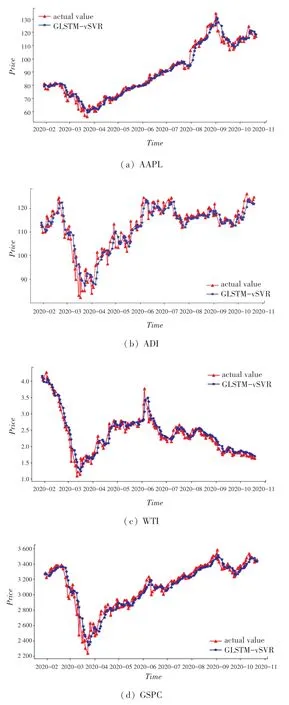
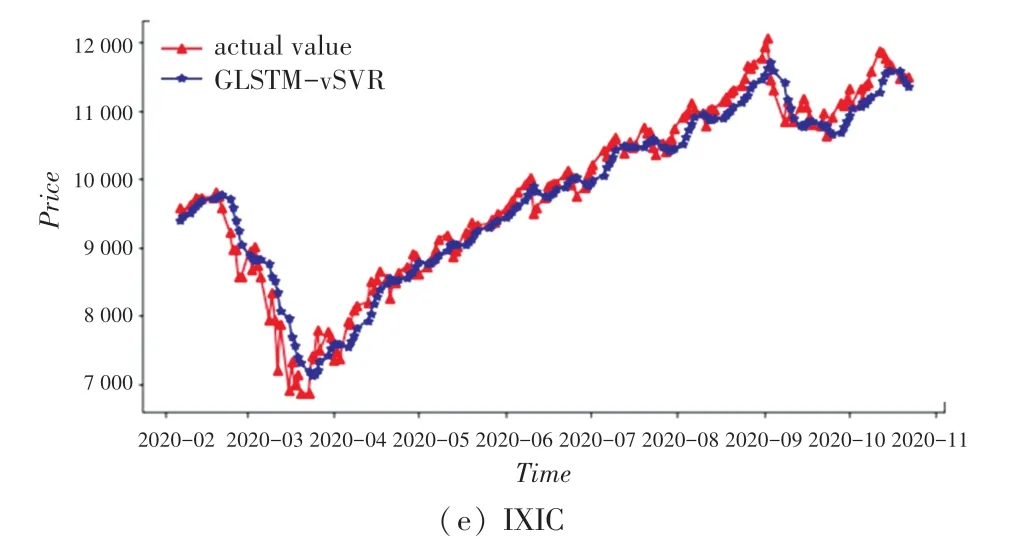
圖8 收盤價真實值與FCLSTM-vSVR模型的預測值對比Fig.8 The comparison of the actual closing price values with the predicted value of FCLSTM-vSVR model
由圖8可知,提出FCLSTM-vSVR模型得到的預測值與真實值較為接近。但由于市場環境和投資人行為等因素的存在,所以零誤差的預測無法實現。但本文提出模型與其他對照模型相比,取得了較為理想的預測效果。
4 結束語
對股票市場的預測可以產生實際的盈利或虧損,因此提高模型的可預測性對投資者來說是非常重要的。在本文中,提出了一種新的基于模糊K線的混合股票價格預測模型,即FCLSTM-vSVR模型。具體來說,首先本文將遺傳算法和LSTM網絡結合起來考慮股票市場的時間特性和模型的自定義結構因素。利用遺傳算法搜索時間窗口大小和神經網絡隱藏層單元數的最優或接近最優值。然后,提出了一種降低預測誤差的方法來提高GLSTM模型的預測精度。該方法采用模糊K線模型來表示原始價格序列中的模糊信息,vSVR模型建立預測誤差與模糊輸出因素之間的映射關系。本文選取5個股票數據集,通過對比試驗,驗證了該模型的可行性。實驗結果表明,與基線模型相比,所提出的模型具有更高的預測精度。但使用遺傳算法尋找LSTM神經網絡模型參數所需時間與計算資源較大。因此,尋找一種更簡單的方法來優化LSTM網絡參數將是下一步研究的方向。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
