基于GAICNet的垃圾識別分類檢測網絡
2022-04-28 14:09:26張濤
智能計算機與應用 2022年4期
張 濤
(上海工程技術大學 機械與汽車工程學院,上海 201620)
0 引 言
隨著科技革新的不斷推進和城市化規模的逐漸擴大,人們越來越重視周邊環境衛生及可持續發展。但是,有價值垃圾的接管利用和對人類身心健康有威脅的垃圾的利用已經成為一個亟待解決的問題,所以垃圾的分類處理問題也成為人們越來越關注的熱點話題之一。許多國家已經出臺了對垃圾分類的嚴格政策要求,這對全球環境保護和各國家推行的可持續發展計劃有著重要的促進作用。目前的垃圾回收大部分依靠人工挑選那些機器無法準確識別的破碎目標,這種方式不僅效率低下、勞動強度大、并且可能會對工作人員健康造成傷害。所以徹底解決這個問題就要從科技創新上來著手,利用深度學習方法進行自動化分揀,實現垃圾的合理分類及回收。
當前,許多能用于實際的檢測模型處于測試階段,普遍存在著模型適應性差、精準率低、魯棒性差等問題。2014年Lukka等人成功開發出了第一臺可用于垃圾分類的機器人Zen Robotics,該機器人問世后,將其應用到了實際工作中,但由于其智能化水平低,故障率高,只能輔助垃圾分類。吳健等人針對國內的計算機實驗室場景提出了一套實驗室垃圾分類的解決方案。然而,由于垃圾、背景復雜交錯,光照昏暗不明,手工粗略提取相應數據時,模型適應性差,處理相應數據過程十分復雜,所以無法滿足實時檢測要求。
當前在深度學習研究中獲得迅猛發展的圖像檢測是計算視覺的未來發展趨勢,現已運用到各個領域,如自然語言處理、無人駕駛等,并取得優異成果。其中,Song等人提出基于Inceptionv4的垃圾自動分類DSCR網絡,使得模型在多尺度特征上獲得更多的信息,準確率達94.38%。Dong等人提出一種注意力機制模型,通過完成局部、全局的特征提取和特征融合機制等方法建立了垃圾圖像分類模型,該模型有效利用豐富的特征信息進而避免梯度消失的現象。Yang等人設計了一個新的增量學習框架GarbageNet以解決垃圾分類中缺乏足夠數據、高成本的類別增量等問題,通過AFM(Attentive Feature Mixup)消除噪聲標簽的影響,但這些模型通常只針對通用物體檢測,深度學習在垃圾分類領域依舊面臨運算復雜、時效性差、魯棒性欠佳的問題。
綜上所述,本文研究了以ResNet18為骨干的淺層特征提取網絡,設計了一個全局感知特征聚合模塊的垃圾識別分類網絡(Garbage identification and classificationNet,GAICNet)。并在整體網絡建構中引入一種具有普適性的非線性曲線映射圖像增強方法,有助于算法更有效地對目標進行檢測,增強網絡模型對于不同拍攝環境、不用視覺效果的垃圾的測試魯棒性。
1 算法基礎
1.1 非線性曲線映射圖像增強
對數據做變換,增加基礎數據集容量的方法叫做數據增強,避免因為數據集太少導致新對象的細粒度特征就很容易被忽略,也可以讓網絡能學到某一類別真正的特征,而不是此類別中個別圖片的非本質個性特征。
本次研究提出了一種具有普適性的非線性曲線映射圖像增強方法,該方法給定輸入弱光圖像的情況下估計一組最佳擬合的光增強曲線。然后,該框架通過迭代非線性曲線來映射輸入的RGB通道中所有像素到其增強版本,以獲得最終的增強圖像。研究得到的模型結構如圖1所示。
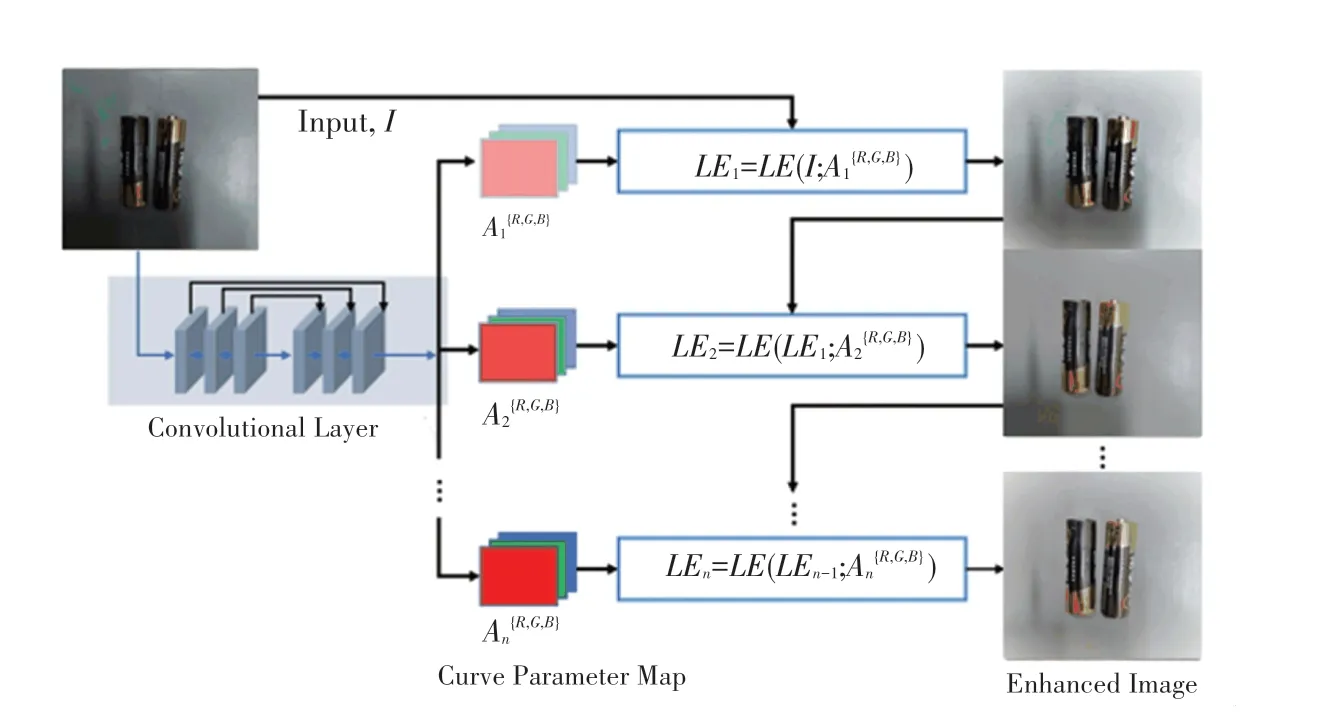
圖1 非線性曲線映射圖像增強模型Fig.1 Non-linear curve mapping image enhancement model
首先,輸入尺寸為256×256×3的弱光圖像。然后使用一個由7個卷積層組成的卷積神經網絡層,這些卷積層是對稱連接的。每個卷積層由32個卷積核組成,各卷積核的大小為3×3,1,后跟激活函數。此方法丟棄了破壞相鄰像素關系的下采樣和BN層。最后一個卷積層后是激活函數。研究過程中,為了能夠在更寬的動態范圍內調整圖像,本文設計了一種可自動將弱光圖像映射到其增強版本的高階曲線。由此推得的數學定義公式如下:
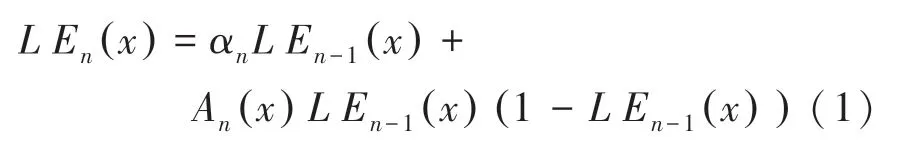
其中,表示像素坐標;LE()是給定輸入的最終增強迭代版本;∈(-1,1)是可訓練的曲線參數且調整曲線的幅度,也控制曝光水平;是迭代次數,控制曲率;是與給定圖像大小相同的參數圖。該框架將像素歸一化為[0,1],以避免溢出截斷引起的信息丟失。再通過迭代應用曲線來映射輸入的RGB通道的所有像素,并降低過飽和的風險,以獲得最終的增強圖像。受益于簡單的曲線映射形式和輕量級的網絡結構,則能夠改善高級視覺任務,計算效率高。圖像增強結果見圖1。
1.2 總體架構
基于傳統的深度學習圖像檢測方法需要大量手工標注的邊界框注釋用于訓練,這對于獲得高分辨且易分類的注釋數據來說是十分困難的。在這項工作中,為了充分利用帶注釋的新對象的特征并捕獲查詢對象豐富的細粒度特征,文中提出了帶有上下文感知聚合的密集關系蒸餾來解決帶有弱光和復雜背景圖像的識別分類問題。首先,將原始圖像輸入基于ResNet18構建的主干網共享特征提取器用于提取低分辨率特征。這里,本文的簡化ResNet18將輸出通道切割為“16、32、64、128”以避免過擬合,并將下采樣因子設置為8以減少通道結構細節的損失。同時將獲得的特征信息通過專用的深度編碼器編碼成和,接著饋送到DRD模塊測量和值圖的權重之間像素的相似性。然后使用新設計的CAFA模塊將DRD模塊中所映射的有效特征聚合起來。最后執行一種核心自注意力關注機制,以解決尺度變化大和獲取詳細的局部上下文信息的問題,最終輸出是聚集特征之后的3個特征的加權和。整體框架如圖2所示。
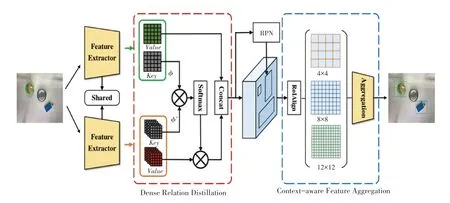
圖2 整體模型架構Fig.2 Overall model architecture
1.3 密集關系蒸餾(DRD)模塊
因為在某些垃圾分類數據集中個別同類別垃圾之間大小不一、復雜背景環境,顏色五花八門,這會影響模型的檢測精度。針對這些問題,本文構建了密集關系提取模塊,支持從特征中提取像素相關視覺語義信息,從像素級區分目標對象。由圖2可知,深度編碼器以一個或多個特征作為輸入,查詢特征來自前一個解碼器層,并為每個輸入特征輸出2個特征映射:和,這2個值圖是并行的3×3卷積層,用于壓縮輸入特征的通道維數,以節省計算成本。圖用于支持特征之間的相似性,這不僅能夠確定在哪里檢索相關支持值,而且也有助于匹配編碼視覺語義信息。用于存儲識別的詳細信息。之后所生成的值和值被進一步饋送到關系提取部分。
DRD在獲得值和值的映射之后執行關系提煉,以非局部方式執行像素相似性,公式為:
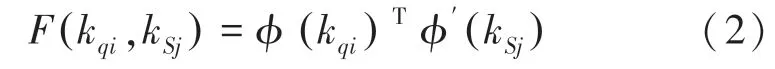
其中,和是支持位置的索引;和φ表示2個不同的線性變換;k和k分別表示查詢特征的值和值的輸出映射。計算像素特征的相似度后,輸出最終權重w:
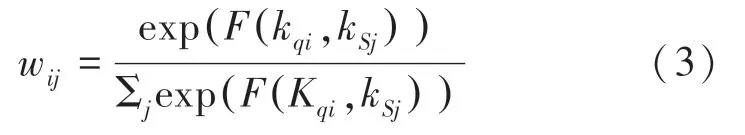
在此基礎上,通過產生的權的加權求和來檢索支持特征的值,此后將其與查詢特征的值圖連接。
1.4 上下文感知特征聚合(CAFA)模塊
執行密集關系蒸餾后,DRD模塊完成了指定任務。細化的查詢特征隨后被饋送到區域建議輸出的區域規劃網。RoIAlign模塊以建議和特征為輸入,進行特征提取,用于最終的類預測和包圍盒回歸。此外,由于尺寸、顏色差異被放大,模型趨向于失去對新類的泛化能力,而新類對不同尺度具有足夠的魯棒性。為此,研究提出了上下文感知特征聚合模塊。根據經驗選擇4、8和12三種分辨率,繼而執行并行池化操作,以獲得更全面的特征表示。較大的分辨率傾向于專注局部詳細的上下文信息,而較小的分辨率目標是捕捉整體的信息。因為每個生成的特征包含不同級別的語義信息,因此這種簡單靈活的方式可用來解決了尺度變化問題。為了有效地聚合特征,研究中進一步提出了一種核心自注意力關注機制。如圖3所示。
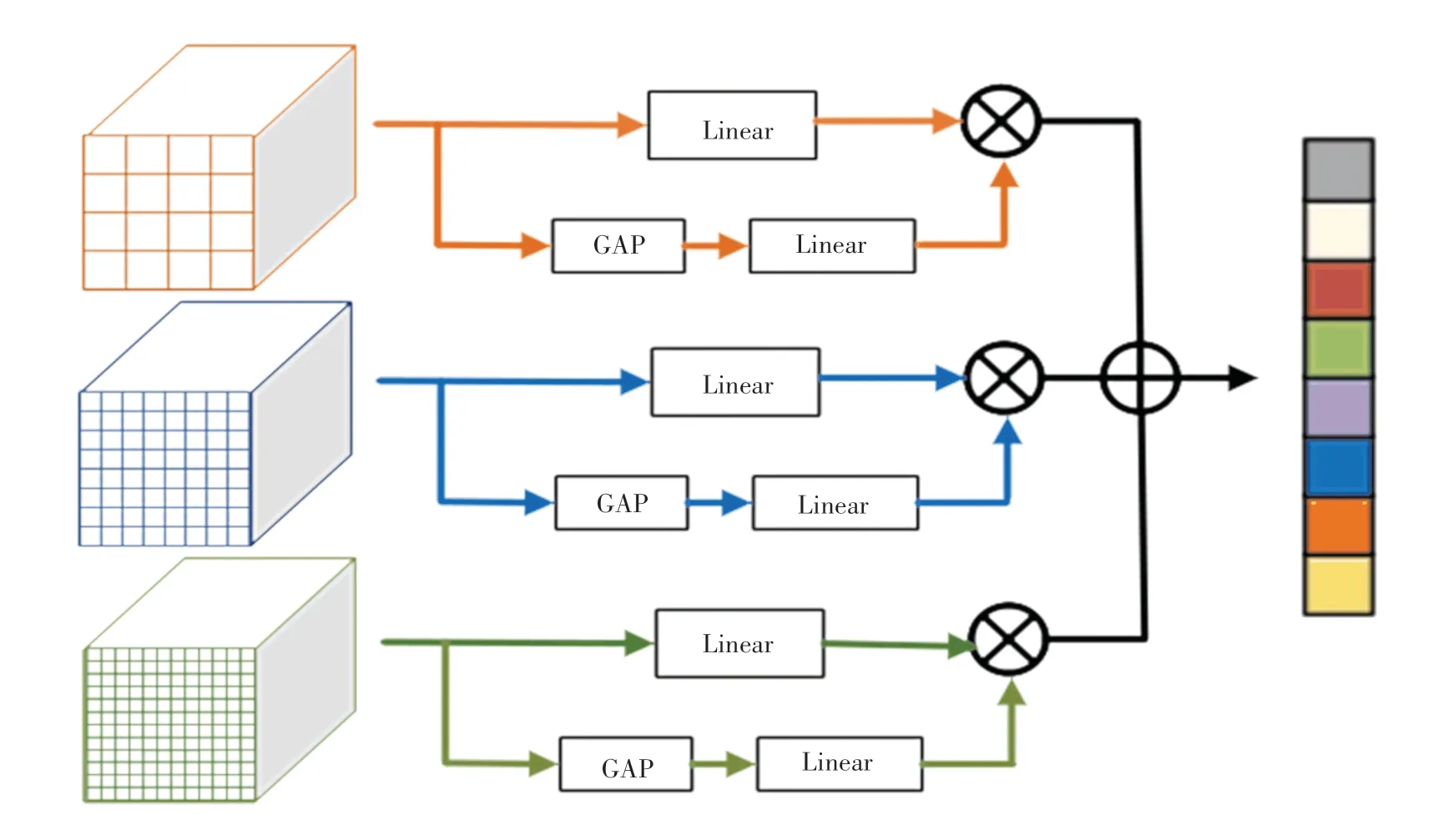
圖3 核心自注意力關注機制Fig.3 Focused self-attention mechanism
研究中,為每2個塊組成的特征添加一個注意分支。第一個塊包含一個全局平均池,第二個包含2個連續的FC層。研究中,向生成的權重添加最大值歸一化,以平衡每個特征的貢獻。此后可得到,聚合特征的最終輸出是3個特征的加權總和。最終輸出公式為:

其中,“*”表示矩陣內積,v和v分別表示支持特征的值和值的輸出映射。
至此,模型通過ResNet18融合密集關系蒸餾(DRD)模塊和上下文感知特征聚合(CAFA)模塊獲取了豐富的、不同級別的特征信息,同時再利用獲取到的不同層次特征生成密集的類和范圍框的預測,最后對范圍框采用NMS輸出最終結果。
2 實驗結果與分析
2.1 實驗平臺
目標檢測模型訓練對計算機的配置和算力都有著較高的要求,本實驗模型訓練采用ubuntu18.04,由于ubuntu占用了大量計算機內存,故選擇minconda搭建TensorFlow-GPU環境,并下載安裝相應版本的cuda,cudnn來支持GPU計算,最后是使用一塊型號為Tesla P100-PCIE-16 GB的GPU進行模型訓練。
2.2 樣本數據集
本文采用的基礎實驗數據是華為云人工智能大賽提供的生活中常見的40種垃圾圖片數據集,圖片數量合計14 802張。該數據集均為真實、高質量的數據資源。將生活中的垃圾分為4大類,分別為:廚余垃圾、有害垃圾、可回收垃圾,除以上垃圾以外的歸為“其他垃圾”。具體分類及每種垃圾數量見圖4。其中,訓練樣本數量占比70%,有10 361張;測試樣本數量占比20%,有2 960張;檢測樣本數量占比10%,有1 480張。
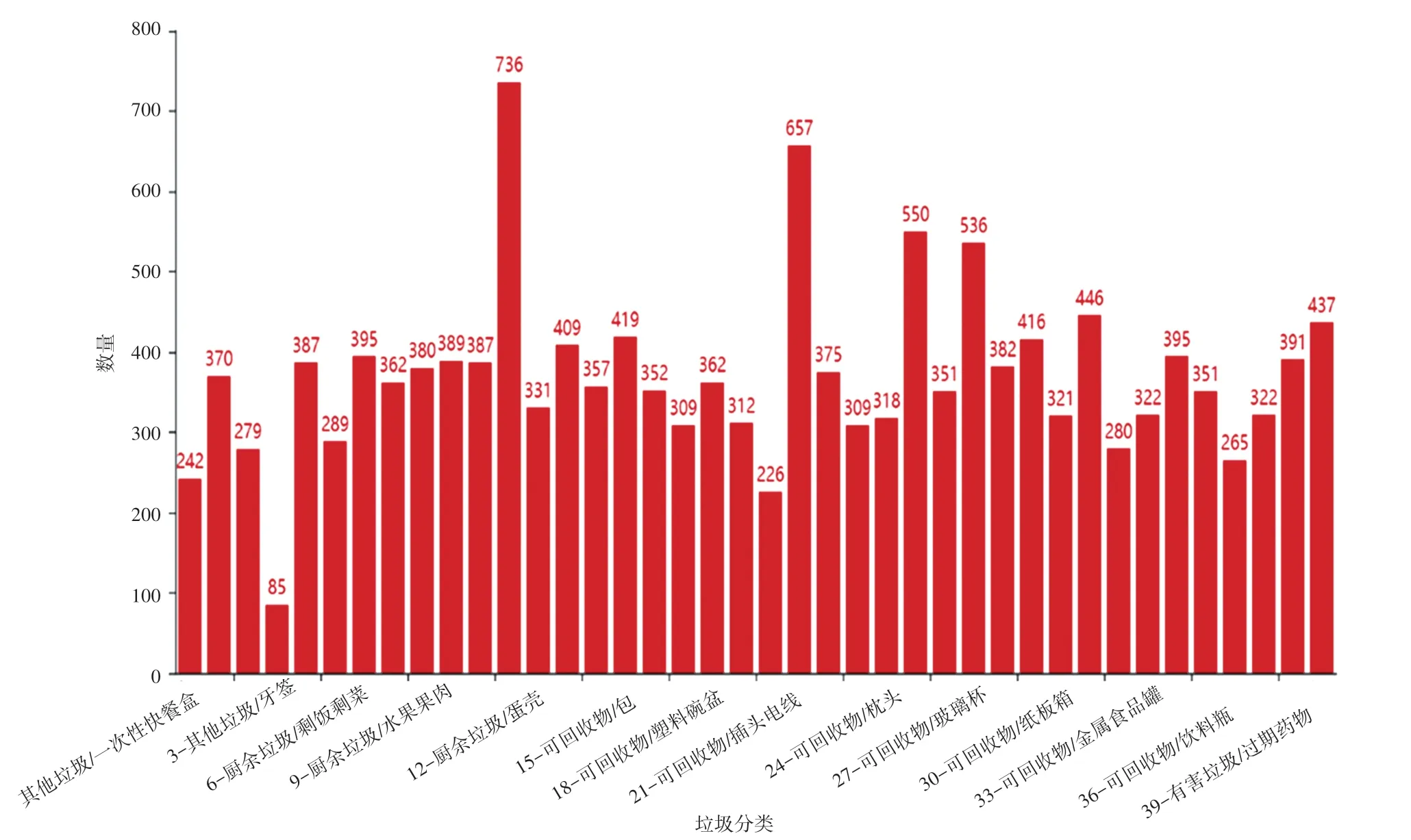
圖4 不同類別數據分布Fig.4 Data distribution of different categories
另外,為了減少數據集中因為拍攝設備、拍攝環境造成的噪聲與異常值帶來的干擾,系統使用濾波器去噪對數據集圖像進行處理。線性均值濾波去噪是在圖像上對目標像素的中心以的像素為一個模板,通過均值計算以全體像素的平均值賦值給原有的模板中心像素,其數學表達式為:
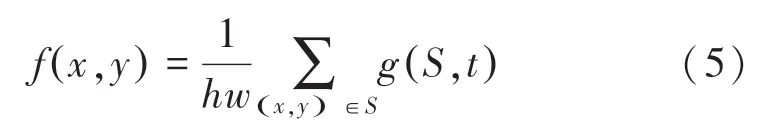
其中,(,)為濾波后的圖像;(,)為原始圖像;為以(,)為中心,以為尺寸的模板。圖像通過均值濾波器能夠過濾掉由于受到角度、光源以及分辨率產生的影響,避免產生噪聲,使圖像平滑,突出圖片局部以及全局豐富的細粒度特征。
2.3 實驗設置
本實驗參數方面設置為:使用SGD優化算法進行模型練習,12,動量系數為0.99,共設置50個迭代周期,基礎學習率為0.01,設置10并且為了加快模型收斂速度,將COCO數據及上部分已經預訓練好的參數遷移至模型訓練。由于加入遷移學習和聚類分組歸一化模型訓練速度加快,將模型在9 000次時停止,訓練結束時保存正確率值最高和效果最好的模型參數。
2.4 結果分析
對GAICNet模型訓練過程中的準確率()和損失()進行分析與記錄,并與當前主流的幾種方法進行結果對比。圖5展示了此算法所構建的GAICNet網絡模型以及目前多種主流的圖像識別分類模型在華為云數據集上進行10次迭代練習之后的結果對比曲線,包括DenseNet、YOLOv3、LSSD等。圖6顯示了此算法所構建的GAICNet網絡模型以及目前多種主流的圖像識別分類模型在阿里云天池進行的垃圾分類大賽中的數據集進行10次迭代訓練之后的損失值結果對比曲線。
從圖5、圖6中可以得出結論,GAICNet的準確率比DenseNet、YOLOv3、LSSD高,并且收斂速度快。值則要大大低于其他3種方法。當迭代18 000次左右時,GAICNet的精度已經達到了97.3%,說明本文構建的密集關系蒸餾(DRD)模塊和上下文感知特征聚合(CAFA)模塊均能夠有效提升算法的。通過和圖的詳細比較,可以得出結論是GAICNet魯棒性好且分類準確度很高。
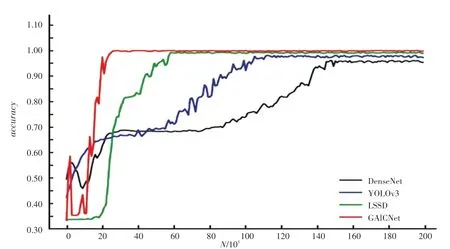
圖5 GAICNet的精確度對比圖Fig.5 Accuracy comparison chart of GAICNet
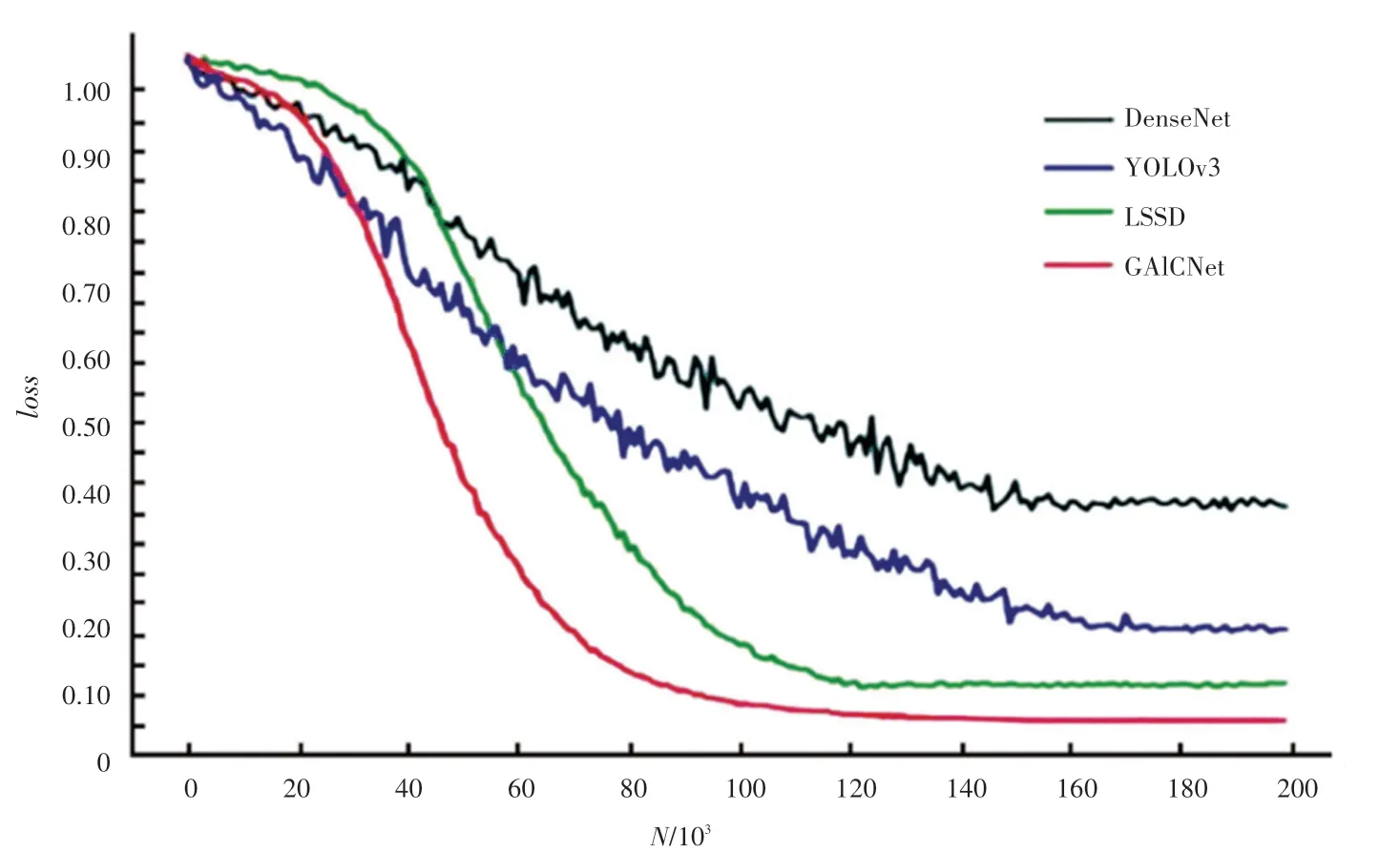
圖6 GAICNet的loss對比圖Fig.6 GAICNet′s loss comparison chart
在與優秀的圖像檢測算法進行比較后,圖7給出了GAICNet在測試集上的部分識別結果的詳細展示。仔細分析后發現,GAICNet在各個差異較大類別的圖像樣例檢測中,都取得了令人滿意的結果。

圖7 GAICNet數據測試結果Fig.7 GAICNet data test results
3 結束語
本文主要對人工智能算法在垃圾智能識別分類應用上展開研究,構建了一種基于GAICNet的智能垃圾分類模型。該算法創新性地設計了利用非線性曲線映射的變光圖像增強方法,提高了模型的泛化能力,有效地擴充了樣本數據集,提升了算法的魯棒性。同時,添加的密集關系蒸餾(DRD)模塊采用查詢和支持特征的稠密匹配策略,充分挖掘支持信息,可以顯著提高性能。上下文感知特征聚合(CAFA)模塊,使模型能夠自適應地聚合來自不同尺度的圖像特征,以獲得更全面的特征表示。本文所構建的基于深度學習的垃圾識別分類算法能夠減少同類垃圾所帶來的差異性的影響,使模型在復雜場景上取得了97.3%的準確率,符合現有場景垃圾分類的實際使用需求。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
