基于多任務持續學習的樹種識別
2022-04-26 03:24:06王恩澤趙亞鳳
森林工程 2022年1期
王恩澤 趙亞鳳











摘 要:針對現有的深度學習方法在樹干或樹葉單一識別任務上需要大量樣本做標注和訓練的問題,且存在災難性遺忘現象,提出一種新的神經網絡模型用于多任務樹種識別。對于少量不同類型數據樣本,本文引入持續學習,將樹干識別和樹葉識別看作2個連續的學習,實現多任務識別。訓練模型分為2個階段:第1階段為樹干識別,保留參數重要性;第2階段引入正則化損失約束重要參數的變化,維持模型對于葉片的特征提取能力,而保持低重要性參數的改變,以學習不同樹種樣本中更多的特征信息。測試結果表明,該方法在樹干識別和樹葉識別時的準確率分別為91.75%和98.85%,較單任務的深度學習有18.03%和11.92%的提升。本研究所提出的模型更適用于在不同樣本中進行多任務分類識別,較好地避免災難性遺忘問題。
關鍵詞:樹種識別;多任務學習;持續學習;卷積神經網絡;混淆矩陣
中圖分類號:S718.49;TP391.4;TP181? 文獻標識碼:A? 文章編號:1006-8023(2022)01-0067-09
Identification of Tree Species Based on Multi-Task Continual Learning
WANG Enze, ZHAO Yafeng*
(College of Information and Computer Engineering, Northeast Forestry University, Harbin 150040, China)
Abstract:For the current problem that methods of deep learning need a large number of examples for labeling and training in solving single task such as trunk recognition or leaf recognition, and there is a phenomenon called catastrophic forgetting, this paper has proposed a new neural network model for multi-task tree species recognition. For a small number of different data samples, continual learning is introduced in this paper, and trunk recognition and leaf recognition are regarded as two continuous learning to accomplish multi-task recognition. The training model is divided into two stages: trunk recognition is settled in the first stage, which preserves the significance of parameters. In the second stage, regularization loss constraint is introduced to maintain the feature extraction ability of the model for leaves, while keeping the changes of low importance parameters, so as to learn more feature information from different tree species samples. The experiment shows that the accuracy in trunk recognition and leaf recognition are 91.75% and 98.85%, respectively, which are 18.03% and 11.92% higher than single-task deep learning. It indicates that the proposed model is more suitable for multi-task classification and recognition in different samples, and it effectively prevents catastrophic forgetting in deep learning.
Keywords:Tree species recognition; multi-task learning; continual learning; convolutional neural network; confusion matrix
0 引言
樹木的種類識別一直是林業研究的熱點內容[1]。由于葉片具有形狀特征豐富、數據采集方便等優點,識別率高,是樹種識別領域的常用數據源。由于樣本存在類間相似性,單獨利用樹葉進行樹種識別也會有圖像識別精確度不高的現象,傳統識別方法很難突破在不同類的樹種之間容易識別錯誤這一限制,特別是針葉類樹木[2]。
近年來,卷積神經網絡在圖像分類、語義分析和計算機視覺等領域具有優異的性能,其突出的特征學習和分類能力備受關注[3]。將基于深度學習理論的圖像識別與分類技術應用到樹種識別過程中,對提高林區的工作效率和質量具有十分重要的意義[4]。Sun等[5]利用改進的ResNet26模型對100種樹木自動識別和分類,在BJFU100數據集上識別率為91.78%;鄭一力等[6]以植物葉片為研究對象,提出了AlexNet與Inception v3相結合的遷移學習網絡模型,測試集上識別率分別達到95.31%和95.40%。然而,基于葉片圖像的識別對源數據要求較高,大大增加了人工標注的難度,且圖像數據有限,為此高旋等[7]結合樹葉及樹干2種器官進行多任務學習,提出了基于遷移學習的樹種識別,在少量樣本的識別中提高了識別精度。
由于樹干識別和樹葉識別存在一定的相似性,多任務樹種識別可以較好地應用于單獨進行樹葉或樹干識別,易于遷移特征信息;但不同樣本之間的遷移在神經網絡中仍會存留大量原有信息,在學習新信息方面存在局限性,即未能克服災難性遺忘問題。為解決這一問題,本文提出了利用持續學習的思想和算法,對樹干識別網絡和樹葉識別網絡的重要信息進行學習,保證原有任務順利完成且使得后續任務正常進行,最終完成樹種識別。
1 持續學習的網絡模型
1.1 災難性遺忘
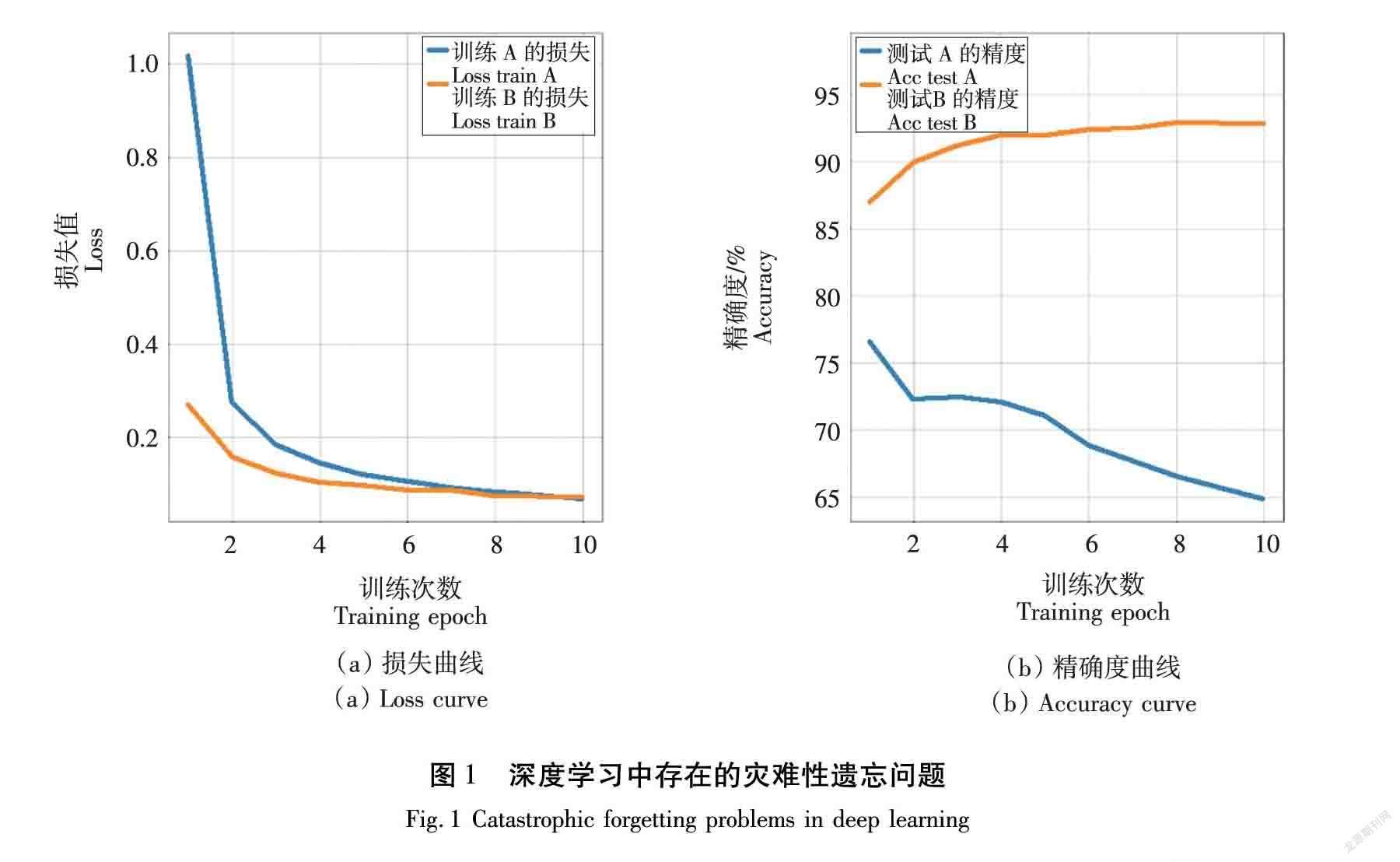
據近年相關報道,機器學習在圖像分類和目標檢測等單個任務中表現出超高的準確率[8]。盡管這些結果令人印象深刻,但這是通過靜態模型獲得的,不能隨時間調整其行為,每當有新數據時,訓練過程必須重新啟動。這種方法難以處理數據流,且由于存儲限制或隱私問題無法長期應用。在機器學習中,一旦學習到一個新模型,以前的模型都會被遺忘,這稱為災難性遺忘[9]。具體來說,當接受新的任務訓練時,標準的神經網絡會忘記與先前學習任務相關的大部分信息。當樣本隨時間推移逐漸可用時,傳統神經網絡模型的性能隨著新任務的學習而顯著降低[10],如圖1所示。
為克服災難性遺忘,一方面,學習系統應該在持續輸入的基礎上獲取新知識和精煉現有知識;另一方面,應防止新輸入對現有知識的顯著干擾。在現實世界中,人腦能夠適應和學習新知識,以適應不斷變化的環境,可以不斷地學習不同的任務,并不否認以前的知識或直接拒絕新的信息,而是保留之間學過的任務,并用新的信息來改進[11-12]。因此,按順序學習多個任務仍然是深度學習的主要挑戰。
1.2 持續學習的原理
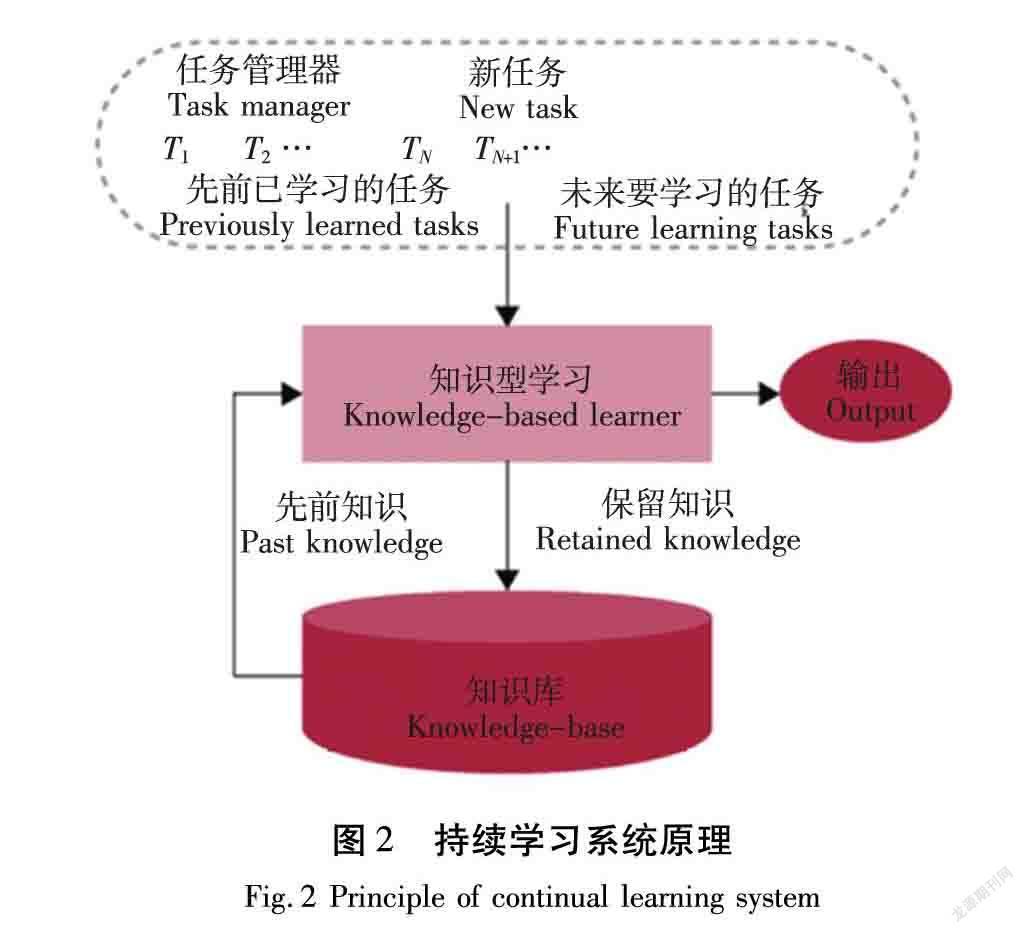
持續學習試圖從一段信息流中提取知識,然后建立知識記憶以改進未來預測[9],如圖2所示。其思想是建立一個系統來總結不同的預測任務和可能的數據模式,并為每個任務保留有效的特定于任務的知識,以后再遇到類似任務,可以調用并應用這些知識。
持續學習問題,即單個神經網絡模型需要連續學習一系列的任務。在訓練過程中,只有當前任務的數據是可用的,并且假設任務是明確分開的[13]。持續學習中有2種流行的模式:①任務增量學習(Task-IL),模型可以訪問任務分隔符(例如:任務ID)來劃分任務。此模型的配置通常是多頭的,每個任務都有一個單獨的分類層。②類增量學習(Class-incremental learning,Class-IL),模型不訪問任務分隔符,在推理過程中需要區分所有類和所有任務。因此,為該模式設計的模型通常是單頭模式。類增量學習更貼近真實場景,更具挑戰性。
在學習方法方面,主要有3種方法:基于重放的方法、基于正則化的方法以及參數隔離方法[11]。在基于正則化的方法中,Li 等[14]使用了知識蒸餾;Dhar等 [15]通過增加注意力損失來改善知識蒸餾;Kirkpatrick等 [16]和Zenke等 [17]估計網絡參數的重要性,并對重要參數的變化進行懲罰。參數隔離方法在計算上是昂貴的,并且需要訪問任務標識符;基于重放和正則化的方法都可以用于2種持續學習模式,但前者除了網絡參數之外,其內存需求與當前深度網絡的大小相當,而且在類增量分類問題上還未得到較好地解決[17]。故本文考慮以一般的深度學習、基于正則化的持續學習和支持向量機為基礎。
1.3 網絡架構
1.3.1 ResNet
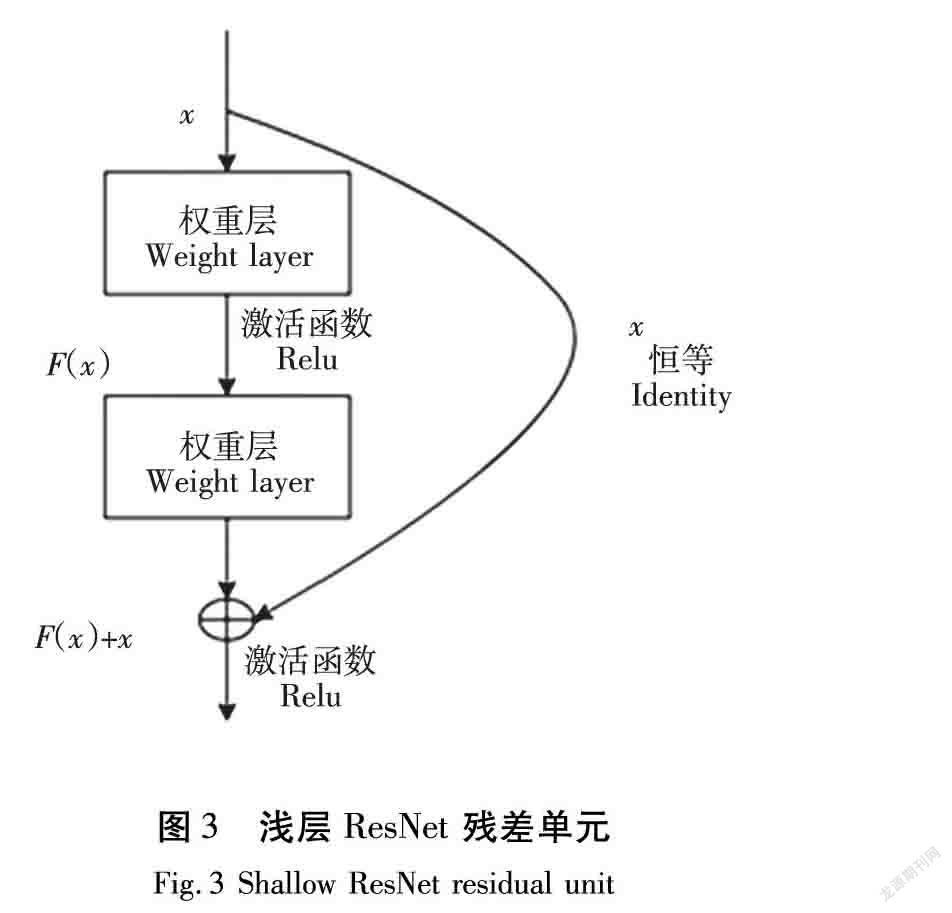
ResNet是在傳統卷積神經網絡的基礎上加入殘差單元,解決深度網絡中梯度擴散和精度降低的問題。ResNet在兩層之間添加了一個短路機制,以完成與普通網絡相比的更深層次的學習,不僅提高了精度,而且提高了系統的可靠性。ResNet的一個重要設計原則是,當特征映射的大小減少一半時,特征映射的數目增加一倍,從而保持了網絡層的復雜性[18]。以淺層ResNet為例,由殘差塊BasicBlock構建,殘差學習單元圖如圖3所示。
由圖2可知,每個輸入學習都是一個殘差函數,圖中殘差塊中有2個層,公式表示為:
F=ω2σ(ω1x)。(1)
式中:σ表示非線性函數ReLu(Rectified Linear Units)。再利用shortcut(跳遠連接)以及第二個ReLu函數,獲得輸出y
y=Fx,ωi+x。(2)
當輸入及輸出的維數需要變化,需要在shortcut的時候對x進行線性變換,表達式如下:
y=Fx,ωi+ωsx。(3)
1.3.2 持續學習的神經網絡結構
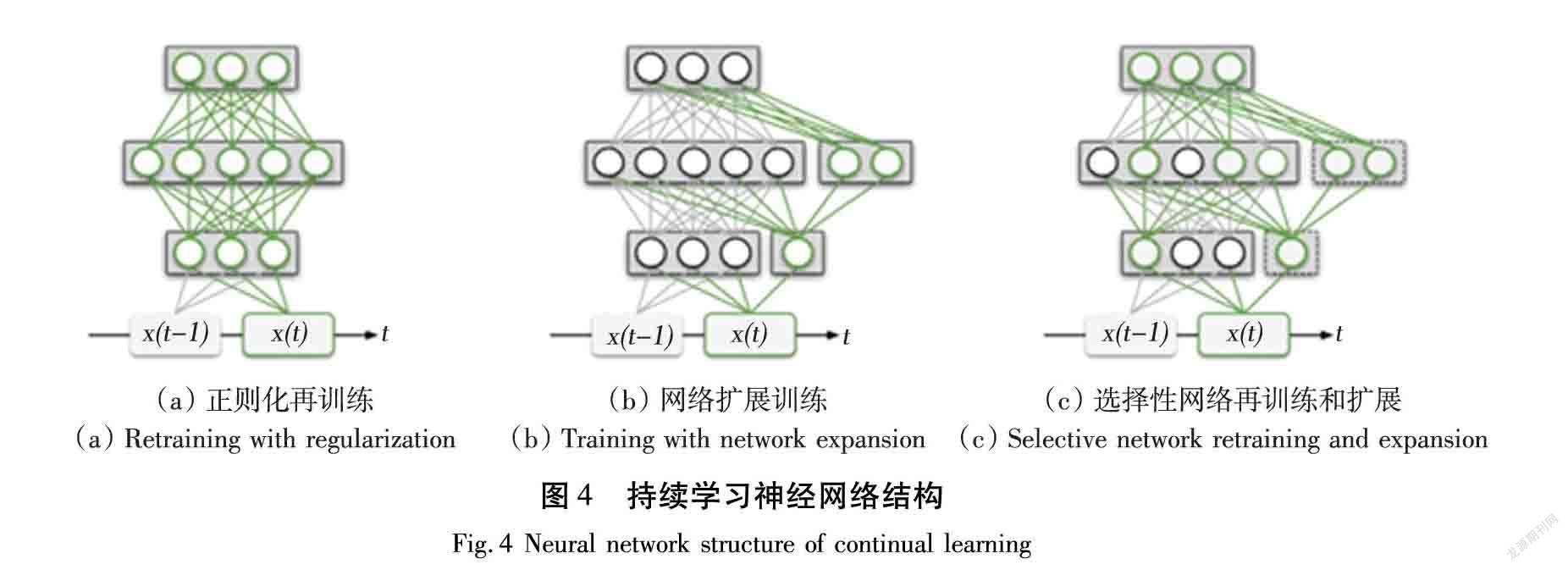
這些方法可以從概念上分為整個網絡的循環和學習任務的適應,以防止災難性遺忘。如圖4(a)所示,有選擇地訓練網絡并在必要時擴展網絡以表示新任務,如圖4(b)和(c)所示,以及構建用于記憶整合的互補學習系統模型的方法,例如用記憶重放來整合內部表示。
其中,正則化方法通過對神經網絡中的權值更新施加約束來減輕災難性遺忘。從計算的角度來看,這通常是通過額外的正則化項來建立模型的,這些正則化項會懲罰神經網絡映射函數的變化。如果θn表示對應于第n個任務Tn的模型參數,那么二次正則化下的總訓練損失為:
L=LTn+λ2∑kαkn-1(θkn-θ(k)n-1)2。(4)
式中:LTn為第n個任務的損失;λ為正則化常數;θn-1為第n-1個任務結束時的模型參數;αn-1為第0個任務到第n-1個任務參數的重要性。
對二次正則化函數機制的分析是基于參數更新的分解。具體來說,前面提到的計算公式的梯度,按公式(5)對參數θn進行更新:
θni+1-θni=-η(SymbolQC@θniLTn+
λαn-1⊙θni-θn-1)。(5)
當學習新任務時,模型參數可以被正則化,以確保參數的當前值和先前值之間的任意插值在新的和先前學習的任務上實現較低的損失。這種策略大大減輕了災難性遺忘。對公式(5)重新排列:
θni+1=1-ηλαn-1⊙θni+
ηλαn-1⊙θn-1-ηSymbolQC@θniLTn。(6)
公式(6)表明,二次正則化下的參數更新可分解為2個同時進行的操作:①利用模型參數當前值與前一任務結束時的值之間的插值來限制任何給定迭代中模型參數的變化;②模型參數移動沿著特定任務的梯度學習新任務。
與現有的一般深度學習的微調不同,微調指向相似樣本學習的遷移性,而本文則是增加了一個有效的正則化項來指導在樹葉和樹干不同樣本之間進行學習以完成樹種識別網絡的訓練。本研究中樹種識別方法的過程如圖5所示。由圖5可知,樹種識別方法包括2個階段,第1階段為特征學習階段,對樹干數據集進行特征提取,在此期間計算并記錄每個參數的重要性,并構建分類器,此階段最后一層僅有Softmax層;第2階段為新任務學習階段,在第1階段模型的基礎上,利用引入的正則化損失優化階段1的訓練網絡,對樹干識別任務的重要參數進行限制,以保持網絡提取葉片圖像特征的能力,避免樹種識別的過擬合;同時利用階段網絡作為特征提取器以共享參數,對新樣本進行特征提取后,產生一個分類權重向量,通過額外的全連接層將其擴展到階段1訓練的分類器權重中,以適應對新樣本的分類任務,獲取第1階段樹干數據和第2階段樹葉數據的特征,并將第2階段提取的特征用于對樹干和樹葉進行分類。
本研究分析了樹干識別和樹葉識別的區別和聯系,并將持續學習的思想應用到樹種識別中,避免了由于訓練數據不足致使模型擬合過度。通過正則化參數,保持了樹干識別模型強大的特征提取能力,減少了重要參數的變化,從而可以學習樹葉相關特征信息。
2 數據集
為保證數據集采集過程公平公正,作者依據不同距離、不同角度、不同光照、不同氣候的原則進行圖像采集,以確保外采集到的圖像盡可能多樣化。每個保存的圖像都有匹配的標簽來識別不同的樹種類別。另外,剔除由于運動模糊而無法清晰拍攝的圖片,然后手動將大小剪切為256×256,使圖像處理過程更加方便,去除每張圖片的背景(此過程相當于手動劃分數據集的感興趣區域(region of interest, ROI))。
2.1 樹干數據集
圖片數據采集來自東北林業大學校園內的樹木,在數據收集過程中,根據拍攝環境(鏡頭前的遮擋物或曝光嚴重程度),為每棵樹選擇合適的拍攝位置,距離在20~30 cm不等。共收集了10種植物2 000張樹干照片。樹干類型見表1。表1中第1行是10種樹木的名稱,第2行是實驗中使用的每種樹木的樹干圖片數。原始圖像如圖6所示(第1行和第2行),與之相應的去除背景的圖像如圖7所示(第1行和第2行)。
2.2 樹葉數據集
由于大部分樹葉易于采集,故保持與樹干數據集相同類別和相同數量,共采集10種類別2 000張樹葉圖像,見表2。表2中第1行第2行顯示的是10種樹種的類別名稱,第3行是樹葉采集圖片數目。原始圖像如圖6中所示(第3行和第4行),與之相應的去除背景的圖像如圖7所示(第3行和第4行)。
3 實驗與分析
3.1 網絡訓練
在實驗過程中,使用PyCharm軟件進行樹種識別分類研究,選用Python語言,利用PyCharm軟件中的Pytorch框架。實驗采用ubuntu16.04系統,服務器內存為16 GB,處理器為Inter-i7,顯卡為NVIDIA GeForce GTX 1080 Ti。
選擇ResNet作為卷積神經網絡(Convolutional Neural Networks, CNN)骨干網絡,CNN提取的特征維度為224×224像素。2個訓練階段均使用SGD(隨機梯度下降)優化器,動量設為0.5,權重衰減項設為0.000 5。
在第1階段,使用樹干數據集訓練樹干識別模型,選擇交叉熵損失作為損失函數,批量大小設為32,該階段僅使用Softmax層構建分類器;第2階段使用樹葉數據集,通過引入的正則化損失層對參數權重進行約束,全連接層也會用于該階段的訓練,以適應由舊樣本到新樣本的分類任務。網絡共訓練50個epoch(使用訓練樣本的次數),初始學習率為0.01,從第30個epoch開始,每10個epoch學習率下降到之前的1/10。第2階段批量大小設為16,初始學習率設為0.01,每10個的學習率下降到前一個時期的1/10,一共訓練20個epoch。基線的訓練超參數與之相同。
3種機器學習方式:首先是從零開始對訓練集進行訓練,即一般的深度學習;其次是持續學習網絡模型,2種方法的區別為是否對參數有所約束;最后是傳統的支持向量機分類器。本文對3種方式進行訓練1測試數據集上的性能分析。實驗見表3。
為了使測試結果公正可信,經過幾輪調試,統一超參數見表4。
3.2 研究方法
本文將2 000幅樹干圖像分為10個子集作為第1階段的數據輸入,分為4類訓練集和測試集,即80%訓練,20%測試;60%訓練,40%測試;40%訓練,60%測試;20%訓練,80%測試。第2階段的訓練是用2 200張樹葉圖片以相同的樹干識別模式進行的。
最后利用生成的混淆矩陣對持續學習進行解釋和分析。在本研究中,混淆矩陣的顯示僅使用80%的訓練-20%測試的原始圖像和去除背景圖像,即:樹干圖像總數為2 000張,1 600張為訓練圖像,400張為測試圖像;樹葉圖像與之相同。通過矩陣歸一化,可以直觀地看到每種樹木類別的分類得分。
3.3 結果分析
3.3.1樹干圖像識別結果與分析
在樹干識別任務中,普通深度學習、持續學習以及SVM分類器的識別精度見表5。
普通深度學習的識別精度在訓練集占比分別為80%、60%、40%、20%時的數值為70.43%、68.28%、64.78%、62.53%,持續學習的識別精度 81.54%、79.32%、76.48%、72.35%。識別精度隨著訓練圖片圖像數量的減少,而呈降低趨勢。
對原始圖像進行實驗結束以后,筆者對去除背景的樹干圖像進行實驗,實驗結果表明,經過去除復雜背景后的圖像識別準確率相比原始圖像識別準確率有所提升,具體結果見表5。從表5可以看出,4種不同訓練集/測試集比例的實驗結果中,利用普通深度學習得到的識別率分別是73.72%、70.56%、67.39%、65.47%,持續學習方式學習到的識別準確率為91.75%、87.97%、83.24%、79.86%。
3.3.2 樹葉圖像識別結果與分析
表6為在樹葉識別模型中普通深度學習、持續學習以及SVM分類器的識別率。從表6可以看出,本文方法在原始樹葉圖像和去除背景的樹葉圖像上分別達到了94.34%和98.85%的識別率。這表明通過正則化,模型可能具有更好的泛化性能。
實驗結果表明,在少量樣本的數據集上,盡管存在圖像類型的不同、訓練-測試比例不同以及源數據不同的條件,但是持續學習的識別效果很大程度上都好于其余學習方式。實驗結果顯示對圖像去除背景在一定程度上有助于提高識別準確率,這表明對于重要的區域,深度學習網絡會給予一個較大的權重值,而對于無關的區域,深度學習網絡給定的權重值就會越小,去除背景相當于將輸入圖像中的重要區域篩選出來。
3.4 混淆矩陣
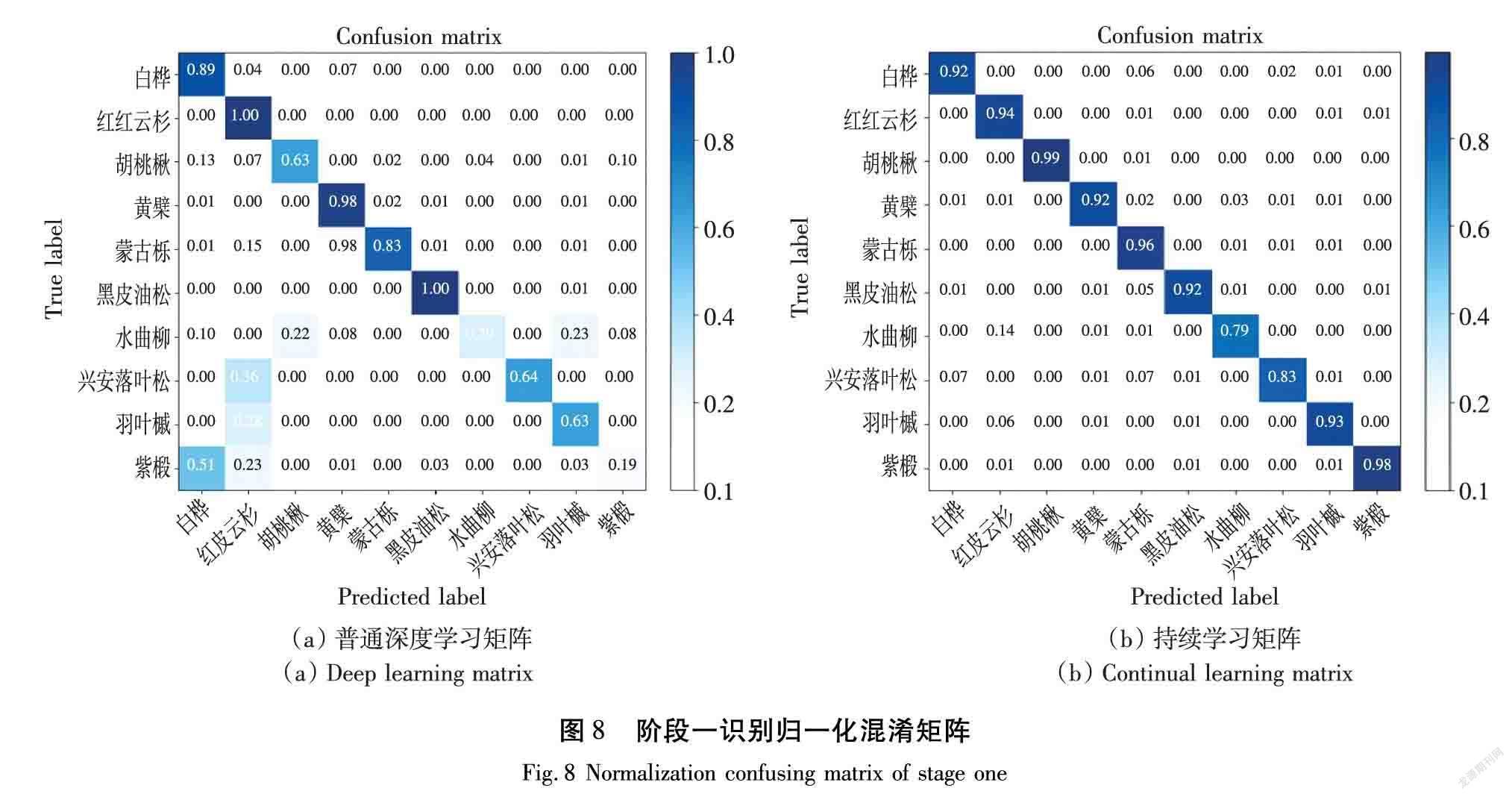
3.4.1 樹干圖像的混淆矩陣
作者分析了利用混淆矩陣進行持續學習的方法。在本實驗的混淆矩陣中,以藍色顯示識別的準確性:顏色越深,識別越精確。橫軸表示測試集,縱軸表示訓練集。持續學習方法的識別結果如圖8所示,可以看出在胡桃楸這一類別的圖像中識別率為0.99,在紫椴這一類別上也達到了0.98的識別率,最低識別率0.79是水曲柳。
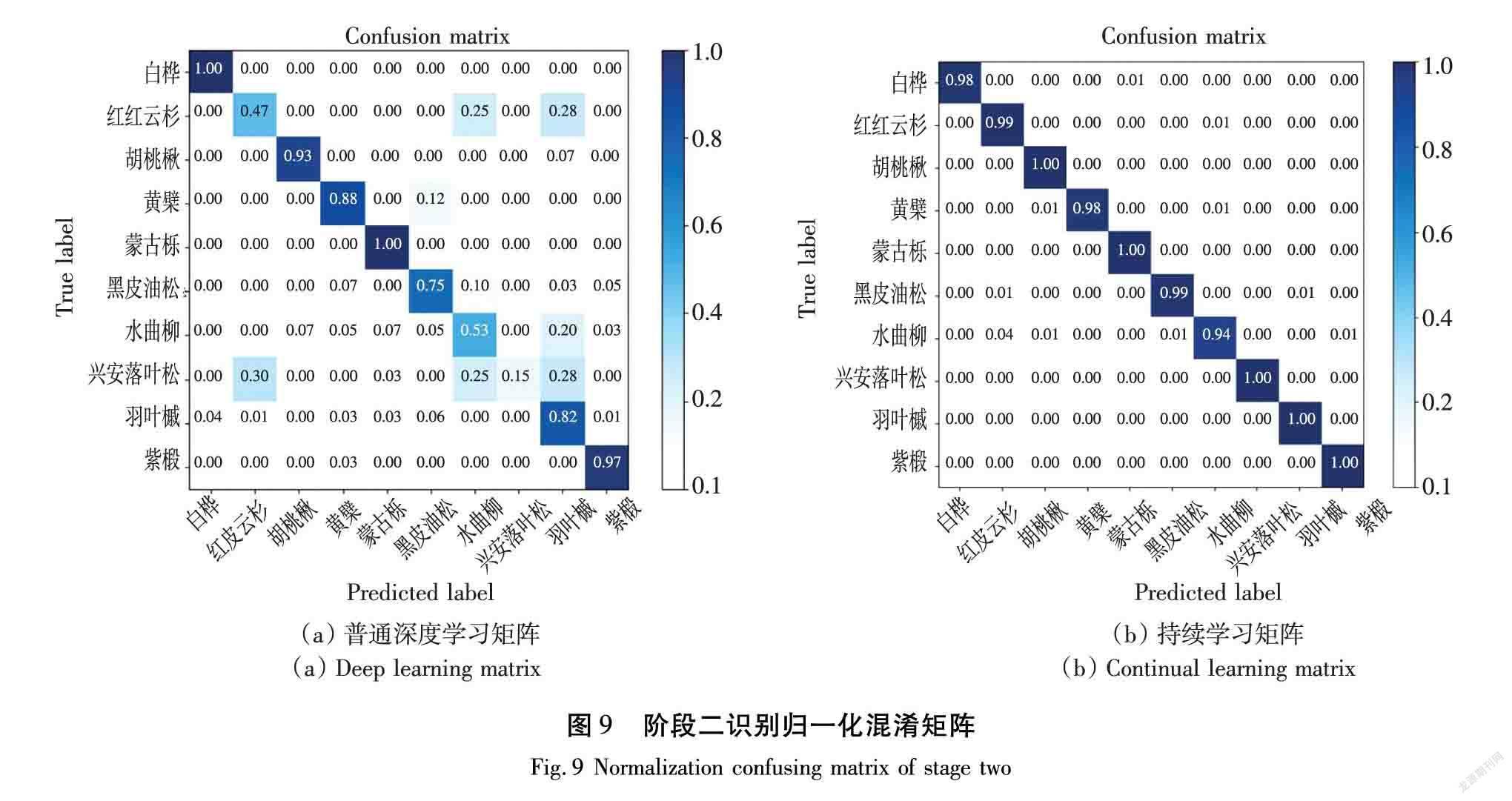
3.4.2 樹葉圖像的混淆矩陣
在混淆矩陣中,橫縱坐標顯示10種樹葉類別名稱。持續學習的方法如圖9所示。
持續學習在蒙古櫟、羽葉槭和紫椴樹種的識別上全部正確,在樹干識別最高的胡桃楸這一類別上也保持著全部識別正確的高識別率。另外,第2階段對水曲柳和興安落葉松的識別率也相較于第1階段有所提高。以上就是普通學習、持續學習和支持向量機(Support Vector Machine,SVM)在樹種識別的表現,從圖9中可以看出,持續學習得到的結果最優。雖然有些圖像被錯誤識別,但是大多數圖像都得到了正確地識別。這是由于不同樹干、樹葉在顏色、紋理和形狀等方面的相似性導致的。
4 結論
本文成功地將持續學習引入到少量不同樣本的樹種識別中,并與普通深度學習和傳統的支持向量機分類方法進行了比較,在訓練集-測試集比例為80%-20%的條件下,基于持續學習的樹葉和樹干最高識別率為91.75%、98.85%,比普通深度學習提高了18.03%和11.92%,比支持向量機提高了20.11%和25.57%,該方法較大程度地提升了識別準確率。
但也存在一些問題。首先,同一樹種類別之間存在差異,不同樹種之間存在相似性,這將影響識別的準確性,這些差異在構建的混淆矩陣中得到了呈現。其次,照片中紅皮云杉和興安落葉松的針葉類葉片形狀較小。當被識別樹種特征時,很難有效地提取特征,去除背景后的圖像仍然無法避開不相關的區域。目前,還沒有相關的研究成果。針對上述問題,作者將在后續實驗中引入恰當的處理方法,并選擇合適的網絡模型來攻克此類難題,也會在以后的工作中,關注在這些數據集上的識別性能。
【參 考 文 獻】
[1]張穎,潘靜.中國森林資源資產核算及負債表編制研究——基于森林資源清查數據[J].中國地質大學學報(社會科學版),2016,16(6):46-53.
ZHANG Y, PAN J. Study on accounting of forest resources assets and preparation of balance sheet in China – based on forest resources inventory data[J]. Journal of China University of Geosciences (Social Sciences Edition), 2016, 16(6): 46-53.
[2]牟鳳娟,胡秀,趙雪利,等.比較教學法在“樹木學”課程教學中的應用[J].中國林業教育,2019,37(3):40-43.
MOU F J, HU X, ZHAO X L, et al. Application of comparative teaching method in dendrology course[J]. Forestry Education in China, 2019, 37(3): 40-43.
[3]劉建偉,劉媛,羅雄麟.深度學習研究進展[J].計算機應用研究,2014,31(7):1921-1930,1942.
LIU J W, LIU Y, LUO X L. Research and development on deep learning[J]. Application Research of Computers, 2014, 31(7): 1921-1930, 1942.
[4]張國棟.基于深度學習的圖像特征學習和分類方法的研究及應用[J].網絡安全技術與應用,2018(7):52-53.
ZHANG G D. Research and application of image feature learning and classification based on deep learning[J]. Network Security Technology & Application, 2018(7): 52-53.
[5]SUN Y, LIU Y, WANG G, et al. Deep learning for plant identification in natural environment[J]. Computational Intelligence and Neuroscience, 2017, 2017: 7361042.
[6]鄭一力,張露.基于遷移學習的卷積神經網絡植物葉片圖像識別方法[J].農業機械學報,2018,49(S1):354-359.
ZHENG Y L, ZHANG L. Plant leaf image recognition method based on transfer learning with convolutional neural networks[J]. Transactions of the Chinese Society for Agricultural Machinery, 2018, 49(S1): 354-359.
[7]高旋,趙亞鳳,熊強,等.基于遷移學習的樹種識別[J].森林工程,2019,35(5):68-75.
GAO X, ZHAO Y F, XIONG Q, et al. Identification of tree species based on transfer learning[J]. Forest Engineering, 2019, 35(5): 68-75.
[8]DELANGE M, ALJUNDI R, MASANA M, et al. A continual learning survey: Defying forgetting in classification tasks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021, 5: 1.
[9]PHILPS D G. Continual learning: the next generation of artificial intelligence[J]. Foresight: The International Journal of Applied Forecasting, 2019, 55: 43-47.
[10]KEMKER R, MCCLURE M, ABITINO A, et al. Measuring catastrophic forgetting in neural networks[EB/OL]. 2017: arXiv: 1708.02072[cs.AI].
[11]ABDELSALAM M, FARAMARZI M, SODHANI S, et al. IIRC: incremental implicitly-refined classification[C]//2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). June 20-25, 2021, Nashville, TN, USA. IEEE, 2021: 11033-11042.
[12]劉嘉政,王雪峰,王甜,等. 基于深度學習的樹種圖像自動識別[J].南京林業大學學報(自然科學版),2020,44(1):138-144.
LIU Jiazheng, WANG Xuefeng, WANG Tian. Automatic identification of tree species based on deep learning[J].Journal of Nanjing Forestry University (Natural Science Edition), 2020, 44(1): 138-144.
[13]VEN G M V D, TOLIAS A S. Three scenarios for continual learning[EB/OL]. 2019: arXiv: 1904.07734[cs.LG].
[14]LI Z Z, HOIEM D. Learning without forgetting[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(12): 2935-2947.
[15]DHAR P, SINGH R V, PENG K C, et al. Learning without memorizing[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). June 15-20, 2019, Long Beach, CA, USA. IEEE, 2019: 5133-5141.
[16]KIRKPATRICK J, PASCANU R, RABINOWITZ N, et al. Overcoming catastrophic forgetting in neural networks[J]. PNAS, 2017, 114(13): 3521-3526.
[17]ZENKE F, POOLE B, GANGULI S. Continual learning through synaptic intelligence[EB/OL]. 2017: arXiv: 1703.04200[cs.LG].
[18]REBUFFI S A, KOLESNIKOV A, SPERL G, et al. iCaRL: incremental classifier and representation learning[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). July 21-26, 2017, Honolulu, HI, USA. IEEE, 2017: 5533-5542.
[19]HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). June 27-30, 2016, Las Vegas, NV, USA. IEEE, 2016: 770-778.
