基于YOLOv3算法的盲道識別研究
2022-04-22 06:53:54袁揚馬浩文葉云飛管慶勒周琳泰馬高輝
河南科技 2022年6期
關(guān)鍵詞:深度學習
袁揚 馬浩文 葉云飛 管慶勒 周琳泰 馬高輝



摘 要:世界衛(wèi)生組織統(tǒng)計的數(shù)據(jù)顯示,全球失明人數(shù)超過3 600萬,且有逐年遞增的趨勢。對于視障人群而言,其出行十分不便,并且現(xiàn)有的盲道識別算法大多是基于顏色和紋理,檢測速度較慢,不能很好地解決盲人出行難的問題。為此,本研究提出一種基于YOLOv3網(wǎng)絡(luò)模型的盲道識別算法。筆者使用LabelImg工具對收集到的數(shù)據(jù)進行標注,再將標注后的圖片送入模型中進行訓練,并調(diào)整參數(shù),得到最佳的檢測模型。試驗結(jié)果表明,YOLOv3算法的識別準確率達到98%,為優(yōu)化盲道識別算法提供了新思路。
關(guān)鍵詞:YOLOv3;目標檢測算法;盲道識別;深度學習
中圖分類號:TP212 ? 文獻標志碼:A ? ? 文章編號:1003-5168(2022)6-0020-04
DOI:10.19968/j.cnki.hnkj.1003-5168.2022.06.004
Research on Blind Track Recognition Based on YOLOv3
YUAN Yang ? ?MA Haowen ? ?YE Yunfei ? ?GUAN Qingle ? ?ZHOU Lintai ? ?MA Gaohui
(Tiangong University,Tianjin 300387,China)
Abstract: According to the statistics of the WHO,the number of blind people worldwide is more than 36 million,and the trend is increasing year by year.For the visually impaired people,their travel is very inconvenient,and most of the existing blind track recognition algorithms are based on color and texture,and the detection speed is slow,which cannot well solve the problem of difficult travel for blind people.To this end,this paper proposes a blind track recognition algorithm based on YOLOv3 network model.The author use the LabelImg tool to label the collected data,and then feed the labeled images into the model training and adjust the parameters to get the best detection model.The experimental results show that the accuracy of YOLOv3 reaches 98%,which provides a new idea for blind track recognition algorithm.
Keywords:YOLOv3;target detection algorithm;blind track recognition;deep learning
0 引言
眼睛是人體的重要器官。人們通過雙眼能夠獲取外界的信息,看到各種各樣的物體。但對于患有視力障礙的人群來說,其無法獲取周圍的環(huán)境信息,并且很難預(yù)測和自主處理環(huán)境中存在的各種狀況,在日常生活中很難做到安全出行、快樂出行。為了解決盲人出行難的問題,社會組織及個人都在積極尋找為盲人群體出行提供幫助的方法[1-2]。其中,導(dǎo)盲杖因設(shè)計簡單、便攜實用、成本較低,在一段時間內(nèi)被廣泛使用,但因其感知距離較近,給盲人用戶提供的幫助較為有限;導(dǎo)盲犬因訓練周期長、價格昂貴、社會接納度不高,加之其壽命與人類壽命相比要短得多,所以很少有盲人選用導(dǎo)盲犬作為導(dǎo)盲手段[3]。結(jié)合上述盲人輔助器材的優(yōu)點和不足,本研究使用基于YOLOv3[4]模型來識別盲道,從而可以快速準確地識別道路中的盲道。
1 基于深度學習的目標檢測算法
1.1 目標檢測算法介紹
傳統(tǒng)的目標檢測算法只適用于特征明顯且背景簡單的場景,但是在實際應(yīng)用中,背景復(fù)雜多變,物體特征多樣,大大降低了算法識別的準確度。2014年,Girshick等人提出了R-CNN網(wǎng)絡(luò)[5],R-CNN網(wǎng)絡(luò)是將Region Proposal與卷積神經(jīng)網(wǎng)絡(luò)結(jié)合起來,其在VOC07測試集上有明顯的性能提升,平均精準度(mean Average Precision,mAP)從33.7%(DPM-V5,傳統(tǒng)檢測的SOTA算法)提升至58.5%。從此,基于深度學習的目標檢測算法迅速發(fā)展起來。
1.2 算法類別
目標檢測一直都是計算機視覺領(lǐng)域的核心問題之一[6]。總的來說,基于深度學習的目標檢測算法最主要的任務(wù)是圖像中目標(物體)的識別和物體的定位(即確認位置和大小)。
目前,目標檢測算法大致可以分為兩類:one-stage(單階段檢測)和two-stage(雙階段檢測)。兩者的區(qū)別在于是否產(chǎn)生候選框。見圖1。
two-stage是先生成候選框,再通過卷積神經(jīng)網(wǎng)絡(luò)進行分類。因此,two-stage目標檢測算法的識別準確率高,但是速度較慢,不能滿足實時檢測的要求,代表算法有Fast R-CNN、MT-CNN、R-CNN等[7-8]。而one-stage則是直接提取特征來預(yù)測物體的類別和位置,擁有比two-stage更快的檢測速度,但在檢測精度和準確率方面,與two-stage相比要差一些,代表算法有YOLO系列算法、SSD、RetinaNet等。
1.3 YOLOv3算法介紹
1.3.1 網(wǎng)絡(luò)結(jié)構(gòu)。YOLOv3網(wǎng)絡(luò)結(jié)構(gòu)中的三個基本組件是CBL、Res unit、ResX(見圖2)。CBL由Conv、BN和Leaky Rule激活函數(shù)組成;Res unit仿照了ResNet的殘差塊結(jié)構(gòu),由兩層CBL組成,其中add的作用是張量相加,并不擴充維度。ResX由一個CBL和n個Res unit組成,在該模塊中,CBL層的作用是下采樣,因此經(jīng)過5次Res模塊后,得到的特征圖是608→304→152→76→38→19。Concat的作用是張量拼接,擴充維度。
表1為Darknet-53的網(wǎng)絡(luò)模型,YOLOv3拋棄了FC層(圖中沒有畫出),因此共有52層。
另外,在整個YOLOv3網(wǎng)絡(luò)結(jié)構(gòu)中,并沒有使用任何池化層。這是為了降低池化產(chǎn)生的梯度負面效果,YOLO系列算法直接拋棄了池化層,使用了stride為2的卷積核進行下采樣(見圖3)。
YOLOv3算法生成了三個feature map:y1、y2、y3。其仿照了Feature Pyramid Network算法的思想,當前層的feature map會對下一層的feature map進行上采樣,再進行張量拼接,也就是YOLOv3網(wǎng)絡(luò)結(jié)構(gòu)圖中的Concat函數(shù)。以y2為例,從圖2可以看到,Res4生成的feature map在經(jīng)過5層CBL、1層CBL和1層Conv后,會與第二個Res8所生成的feature map進行上采樣后再進行組合,再經(jīng)過5層CBL、1層CBL和1層Conv最終生成y2。
在這三個feature map中,每個feature map會采用三個先驗框,因此YOLOv3算法中一共有9個先驗框。值得一提的是,由于輸出的feature map尺寸發(fā)生變化,先驗框的尺寸也需要進行調(diào)整。對于這種調(diào)整,YOLOv3算法采用K-means聚類方法。在y1、y2、y3三個feature map中,feature map尺寸越小則感受野越大。因此,y1的感受野最大,適合檢測較大的目標,而y2適合檢測一般體積的目標,由于y3的感受野最小,適合檢測個體比較小的目標。
1.3.2 邊框預(yù)測公式。由圖4可以得到預(yù)測框在feature map上的中心坐標和寬高大小。為了方便將預(yù)測框還原到原圖尺寸,還需要進行歸一化處理,公式如式(1)到式(4)所示。
[bx=[σtx+cx]/W] ? ?(1)
[by=[σty+cy]/H] ? ?(2)
[bw=pwetw/W] ? ? ?(3)
[bh=pheth/H] ? ? ?(4)
其中,[W]和[H]分別表示feature map的寬和高;[cx]、[cy]分別是grid cell的長和寬;[pw]和[ph]分別是預(yù)設(shè)的anchor box映射到feature map中的寬和高;[σ ]為sigmoid函數(shù);[tx]、[ty]是預(yù)測的坐標偏移值;[tw]、[t?]是縮放的尺度;最終得到的bx、by、bw、bh四個量分別代表圖4中粗實線預(yù)測框的左上角坐標、預(yù)測框的寬和高。
2 模型訓練與測試
2.1 數(shù)據(jù)集準備與模型訓練
本次訓練模型的數(shù)據(jù)集是通過網(wǎng)絡(luò)爬蟲、人工拍攝等多種途徑獲得的,然后使用LabelImg圖片標注工具對獲得的圖像進行人工標注。將該數(shù)據(jù)集中的圖像分為typhlosolis-strigt、typhlosolis-turn兩類(見圖5)。
因為大多數(shù)圖片都是人工標注的,因此數(shù)量較少。然后將數(shù)據(jù)集按照9∶1的比例劃分為訓練集和測試集。使用Pytorch框架搭建YOLOv3模型進行訓練,將標注后的數(shù)據(jù)集生成的xml格式的文件轉(zhuǎn)換成txt格式的文件,放入訓練模型中,修改相關(guān)參數(shù)后進行訓練,訓練完成后對數(shù)據(jù)集進行測試。
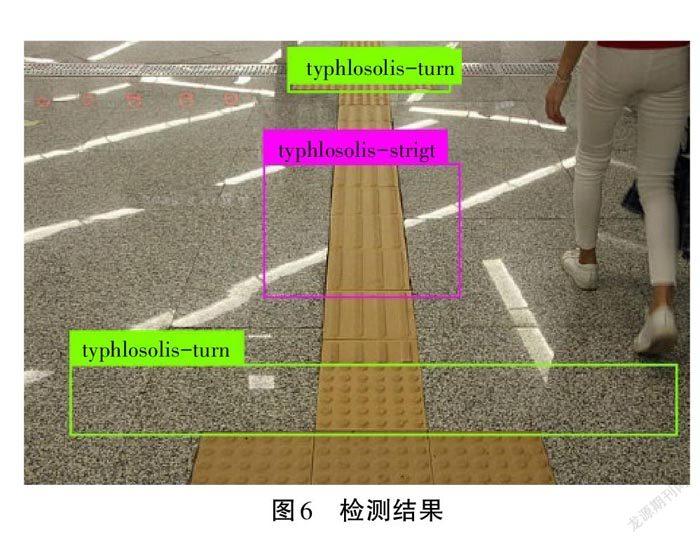
2.2 模型測試
模型測試的檢測結(jié)果如圖6所示,可以看出無論是單個盲道圖片的識別還是多個數(shù)量的盲道識別,匹配率都非常高。在單個盲道識別中對typhlosolis-turn的判斷率高達98%。并且在多數(shù)量盲道的識別中,匹配率也非常高。
3 結(jié)語
本研究采用YOLOv3目標檢測算法,實現(xiàn)了盲道識別,旨在幫助盲人解決出行困難的問題。通過對數(shù)據(jù)集的標注、模型的多次訓練,在單個盲道的識別準確率達到了98%。不同于以往基于顏色和紋理的識別算法,YOLOv3算法能夠更快速、準確地識別盲道。另外,YOLOv3算法的可移植性也更強,可以較為簡單地植入各類嵌入式設(shè)備中。目前YOLOv3算法已經(jīng)較為成熟,相信其能夠為盲道識別提供更多的新思路。
參考文獻:
[1] 謝敬仁,彭霞光.中國盲人定向行走訓練的現(xiàn)狀與發(fā)展對策[J].中國特殊教育,2008(12):53-56,40.
[2] 諶小猛,魯明輝.盲人定向行走輔具的發(fā)展現(xiàn)狀[J].中國特殊教育,2017(9):15-20.
[3] 崔逸飛.我國導(dǎo)盲犬應(yīng)用現(xiàn)狀[J].中國工作犬業(yè),2016(11):54-56.
[4] REDMON J,F(xiàn)ARHADI A.YOLOv3:An Incremental Improvement[J].arXiv e-prints,2018.
[5] GIRSHICK R,DONAHUE J,DARRELL T,et al.Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation[J].IEEE Computer Society,2013.
[6] 方路平,何杭江,周國民.目標檢測算法研究綜述[J].計算機工程與應(yīng)用,2018(13):11-18,33.
[7] ZHANG K P,ZHANG Z P,LI Z F,et al.Joint Face Detection and Alignment Using Multitask Cascaded Convolutional Networks[J].IEEE Signal Process Lett,2016(10):1499-1503.
[8] REN S Q,HE K M,GIRSHICK R,et al.Faster R-CNN:Towards Real-Time Object Detection with Region Proposal Networks[J].IEEE Transactions on Pattern Analysis & Machine Intelligence,2017(6):1137-1149.
猜你喜歡
中國教育技術(shù)裝備(2016年19期)2016-12-27 19:23:52
中國遠程教育(2016年11期)2016-12-27 18:07:31
現(xiàn)代商貿(mào)工業(yè)(2016年25期)2016-12-26 09:58:02
江蘇教育·中學教學版(2016年11期)2016-12-21 11:45:08
江蘇教育·中學教學版(2016年11期)2016-12-21 11:36:29
現(xiàn)代情報(2016年10期)2016-12-15 11:50:53
考試周刊(2016年94期)2016-12-12 12:15:04
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
軟件導(dǎo)刊(2016年9期)2016-11-07 22:20:49
