基于卷積LSTM模型的航空器軌跡預測
2022-04-21 07:24:20劉龍庚翟俐民韓云祥
計算機工程與設計 2022年4期
劉龍庚,翟俐民,韓云祥+
(1.中國軟件評測中心,北京 100089;2.四川大學 視覺合成圖形圖像技術國防重點學科實驗室,四川 成都 610041)
0 引 言
隨著計算機技術不斷發展,各行業的信息量急劇增長,一般將規模巨大且無法通過常規軟件工具在合理時間內管理和處理的信息稱為大數據,目前業界普遍認為大數據的特征可以歸納為4個“V“-Volume(大量)、Velocity(高速)、Variety(多樣)、Value(價值低)[1]。傳感器數據是大數據的主要來源之一,對傳感器網絡的大數據分析和應用,是信息技術的發展趨勢和重點研究方向[2],Liu L等深入研究了大數據環境下傳感器網絡基礎技術[3-5]。空中交通管理過程中需要不斷收集航空器相關傳感器數據,天然具有大數據的特點,除了傳統的大數據特征之外,還具有以下特點[6]:①體量巨大,空管一年產生的數據在PB級別以上;②種類繁多,在空管過程中涉及到多種數據,包含靜態數據、動態數據、結構化數據、非結構化數據;③來源真實,空管數據直接采集自空管一線,來源真實可靠。
在空管大數據開發方面,美國處于領先地位[7]。國內在空管大數據開發方面也做出了一些探索。空管大數據可實現空管運行過程智能化精細化,空管大數據可用于空管流程優化和空管風險管理與評估,空管大數據可直接用于空管仿真模型的構建,并據此實現航空器運行過程預測,準確、可靠的空中交通軌跡預測模型(TBO)可以有效提高空中交通運行效率并進一步保障運行安全。
目前關于航跡預測的方法主要有基于航空器性能參數、運動學模型的傳統方法以及基于數據挖掘和混合機器學習的研究方法。石慶研等[8]提出了一種在線更新LSTM網絡的短期航跡預測算法;李旭娟等[9]提出了一種自動生成的條件變分自動編碼器,以編碼-解碼的形式直接對未來一段時間的航跡進行預測;Xu等[10]提出了一種新的Social-LSTM模型,為空域內的每個航空器建立LSTM網絡,并通過一個池化層整合關聯航空器的狀態,從而編碼了航空器之間的相互作用;馬蘭等[11]基于ADS-B數據挖掘和統計分析,并使用CURE聚類分析;Shi等[12]提出了一種基于LSTM的軌跡預測模型,該模型解決長期依賴問題,避免了相鄰序列狀態的動態依賴性,有助于提高精度;Gallego等[13]針對目前的航跡預測方法缺少對于空中交通中不確定因素的理解,提出了融入航空器周圍交通狀況的航跡預測方法;Liu等[14]提出了一種基于樹的高效匹配算法從氣象數據中構建特征圖,并構建了一個端到端的卷積神經網絡,該網絡包含一個LSTM編碼網絡和混合密度的LSTM解碼網絡,進一步從歷史飛行軌跡中學習時空相關性;Shi等[15]提出了一種4D航跡預測模型,該模型長短期記憶網絡結合滑動窗口來維持長期特征并預測軌跡,并將環境信息作為輸入特征;Zeng等[16]針對目前的空域狀態軌跡方法在終端區這樣復雜的空域中效果不好的問題,提出了一種seq2seq的深度長短期記憶網絡預測模型,可以有效地捕獲長期和短期的時間依賴;Giuliari等[17]將自然語言處理領域的熱門模型Transformer應用在軌跡預測中,并分別實現了原始的Transformer網絡和BERT,實驗結果表明Transformer在數據存在缺失的情況下表現更好;本文基于空管大數據分析挖掘,利用聚類算法萃取航跡數據,并構建LSTM網絡航空器軌跡,使用航跡信息進行仿真驗證,實現對航空器軌跡的準確預測。
1 數據處理
根據數據的來源的組織形式,可將空管大數據初步劃分為靜態數據、動態數據、結構化數據、非結構化數據[6],其中靜態數據是在一定時間段內保持穩定的數據,動態數據與靜態數據相反,主要包含了航空器運行時數據。本文采集了動態的航空器軌跡數據、機場天氣數據和靜態的進場標準儀表進港程序用于構建航空器軌跡預測模型。通過一定渠道獲取雙流國際機場2019年6月至2020年12月每天進離崗航班相關數據[18],包含解析標準ADS-B航跡數據以及二次雷達數據,編寫爬蟲收集雙流機場對應日期的METAR天氣數據報。對于從多種渠道獲取的原始航跡數據及氣象數據不能直接作為訓練數據集,需經過以下處理流程:數據清洗、多源數據融合、離散特征編碼、模型數據集構建。數據清洗是剔除航跡點缺失過多的航跡。多源數據融合是指將來自不同數據源的軌跡數據及氣象數據進行整合,使得航跡數據特征更加豐富。數據編碼是指將特征中離散數據通過特征規則化,使其滿足神經網絡模型輸入格式,讓機器讀懂該特征的含義。數據預處理過程如圖1所示。

圖1 數據預處理過程[19]
ADS-B以及二次雷達中的坐標數據為經緯度,為減少后續計算量,將航跡中的經緯度(B,L)通過墨卡托投影,轉換為以雙流國際機場為坐標原點的坐標系(X,Y)。坐標系轉換關系如式(1)~式(3)所示
(1)
Y=K×(L-L0)
(2)
(3)
其中,標準緯度B0,標準經度L0,e為第一偏心率,e′為第二偏心率,a為長半軸長,b為短半軸長。使用一定對應規則將采集的ADS-B航跡數據、二次雷達數據、機場METAR數據進行融合,作為完整的訓練集。ADS-B航跡數據與二次雷達數據通過飛行日期date和航空器呼號ID匹配,在確定為同一航班之后,使用時間戳插值的方法構造數據集,對于過程中差異較大的數據使用均值操作,如式(4)所示
(4)
上式中,(xradar,yradar)為航跡點p(i,j)記錄的二次雷達位置坐標,(xabs-b,yabs-b)為航跡點p(i,j)記錄的ADS-B坐標,(xi,j,yi,j)為融合后的航跡坐標。最后為了消除不同特征之間量綱不同導致模型訓練困難的問題,使用歸一化和標準化對數值型特征進行處理,方法如式(5)~式(6)所示
(5)
(6)
其中,X為特征數據集,x為原始特征數據,x′為歸一化后的特征數據,max(X)、min(X)分別為該特征中的最大特征值與最小特征值,μ(X)、σ(X)分別為該特征中的期望與方差。
2 航跡聚類
作為一種無監督的機器學習方法,聚類在諸多領域應用廣泛。聚類將具有類似特征的對象使用劃分標準分為不同類別,目前常用的劃分標準有歐式距離、馬氏距離、曼哈頓距離等。在航跡聚類中,需要將類似的飛行軌跡劃分為同一類,從最初選定的航跡簇開始,通過距離度量選定相近的航跡簇,不斷合并航跡簇后重新計算航跡簇間距離,最終獲得聚類結果。在計算的過程中,需要使用航跡間距離衡量航跡相似性,以判斷是否將航跡簇合并。由于設備誤差等現實原因,每條航跡長度通常不等,故無法使用常規的距離度量算法。動態時間規整(dynamic time warping,DTW)通過計算航跡點之間的最短距離,能夠計算出航跡間的距離。針對兩條航跡,其計算過程是將其航跡點分別作為行列,排列為一個二維表,并使用DTW公式計算航跡點間距離,從二維表的左上角到右下角尋找一條距離最短的路徑,將這條路徑上的距離和作為兩條航跡間的相似度量。將訓練樣本中的所有航跡,兩兩計算航跡間的相似性,得到一個二維航跡矩陣,其大小為航跡數量,對于航跡集合T,通過DTW算法計算得到的航跡距離矩陣如式(7)所示
(7)
其中,d(Tj,TJ)為第j條航跡與第J條航跡之間的相似度。在計算距離矩陣時,使用快速DTW,其使用約束搜索空間的策略,可以降低時間復雜度,加速計算過程。
使用航跡聚類,將航跡分類并在此基礎上建立不同預測模型,可以有效提高軌跡預測的精度。本文構建基于快速動態時間規整距離度量的并行剪枝層次聚類算法。在計算航跡相似度中,使用DTW算法;使用批次運算更新距離矩陣;及時剪枝遠離聚類中心的離群航跡。具體流程:①計算航跡距離矩陣。對于訓練集中的所有航跡,數量為nt,計算兩兩之間的相似度,得到nt×nt的距離矩陣,相似度計算使用DTW算法;②計算航跡簇之間的相似度;③遍歷相似性矩陣中的航跡,獲取其中距離最近的航跡,形成航跡簇對;④計算航跡簇對之間的簇間距離,比較與設定的簇間距離,小于預設則剔除,大于預設則為一個類別并重新計算所有航跡簇的距離矩陣,進行下一步迭代。使用預先設定的航跡數目閾值來判定航跡簇是否為離群航跡簇,當其中航跡數量大于閾值時,當前航跡簇成為一個航跡類別,否則該航跡簇為離群航跡簇,將被剔除。上訴過程為一次聚類算法的迭代過程,重新計算航跡簇的距離矩陣進入下一輪迭代。計算過程前需要設定兩個關鍵參數,分別是離群航跡距離和離群航跡數目。
3 模型構建
航跡序列是一種時間序列,目前常用LSTM處理時間序列問題,相對于RNN而言,LSTM解決了其存在的長期依賴問題,能夠學習長期依賴關系。LSTM的網絡單元中每個重復模塊由3個門組成,分別是遺忘門、輸入門和輸出門,每個門可以選擇性地決定前一層的信息以什么樣的方式傳遞給當前層,LSTM網絡單元結構如圖2所示。
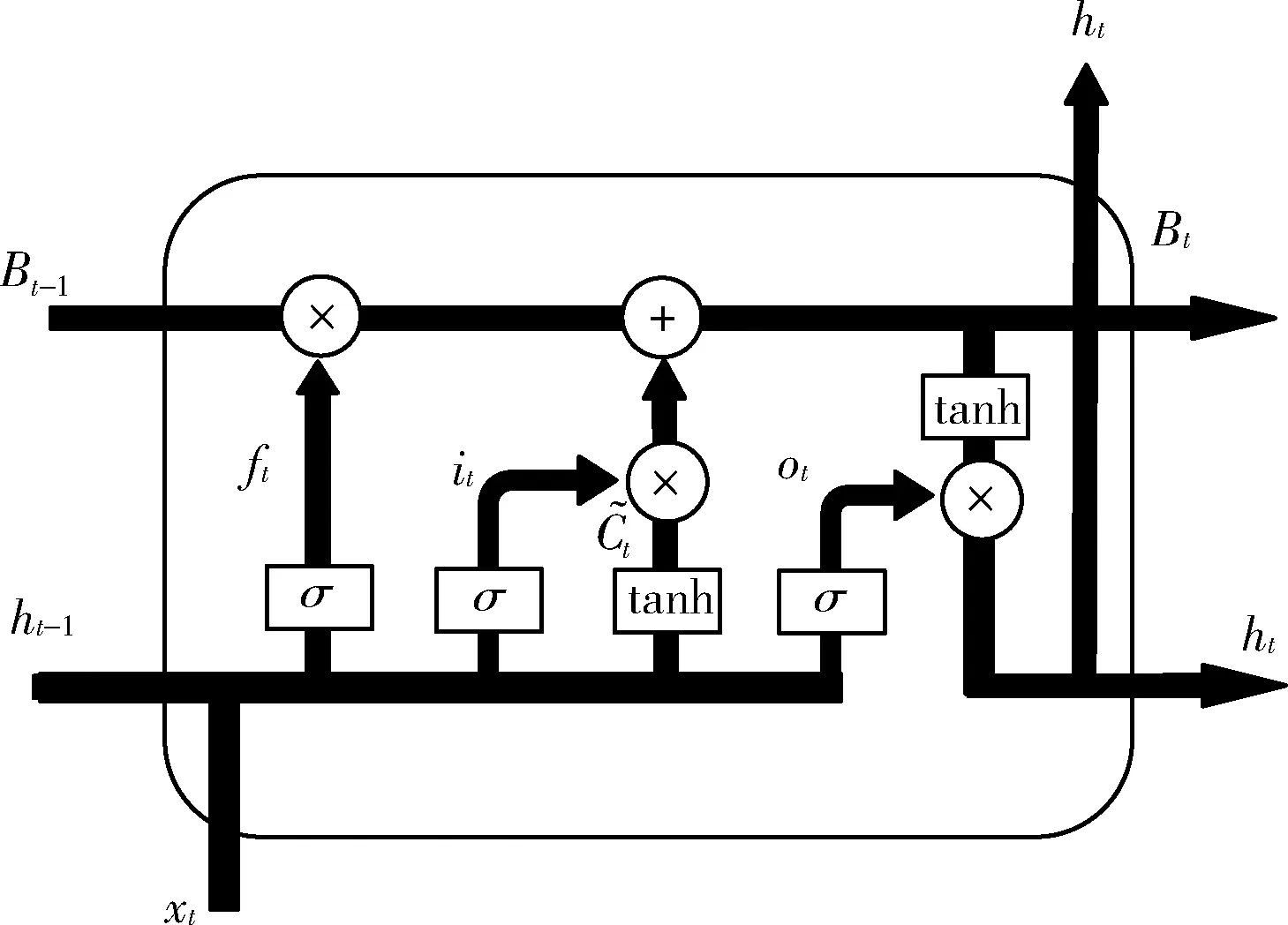
圖2 LSTM網絡單元結構
其中,σ和tanh分別是sigmoid激活函數和tanh激活函數,xt為t時刻的輸入,ht為t時刻的狀態,it為t時刻輸入門輸出,ft為t時刻的遺忘門輸出,ot為t時刻輸出門輸出,結合圖2,對于上述定義如式
ft=sigmoid(αf·[ht-1,xt]+βf)
(8)
it=sigmoid(αi·[ht-1,xt]+βi)
(9)
ot=sigmoid(αo·[ht-1,xt]+βo)
(10)
(11)
(12)
ht=ot*tanh(Bt)
(13)
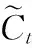
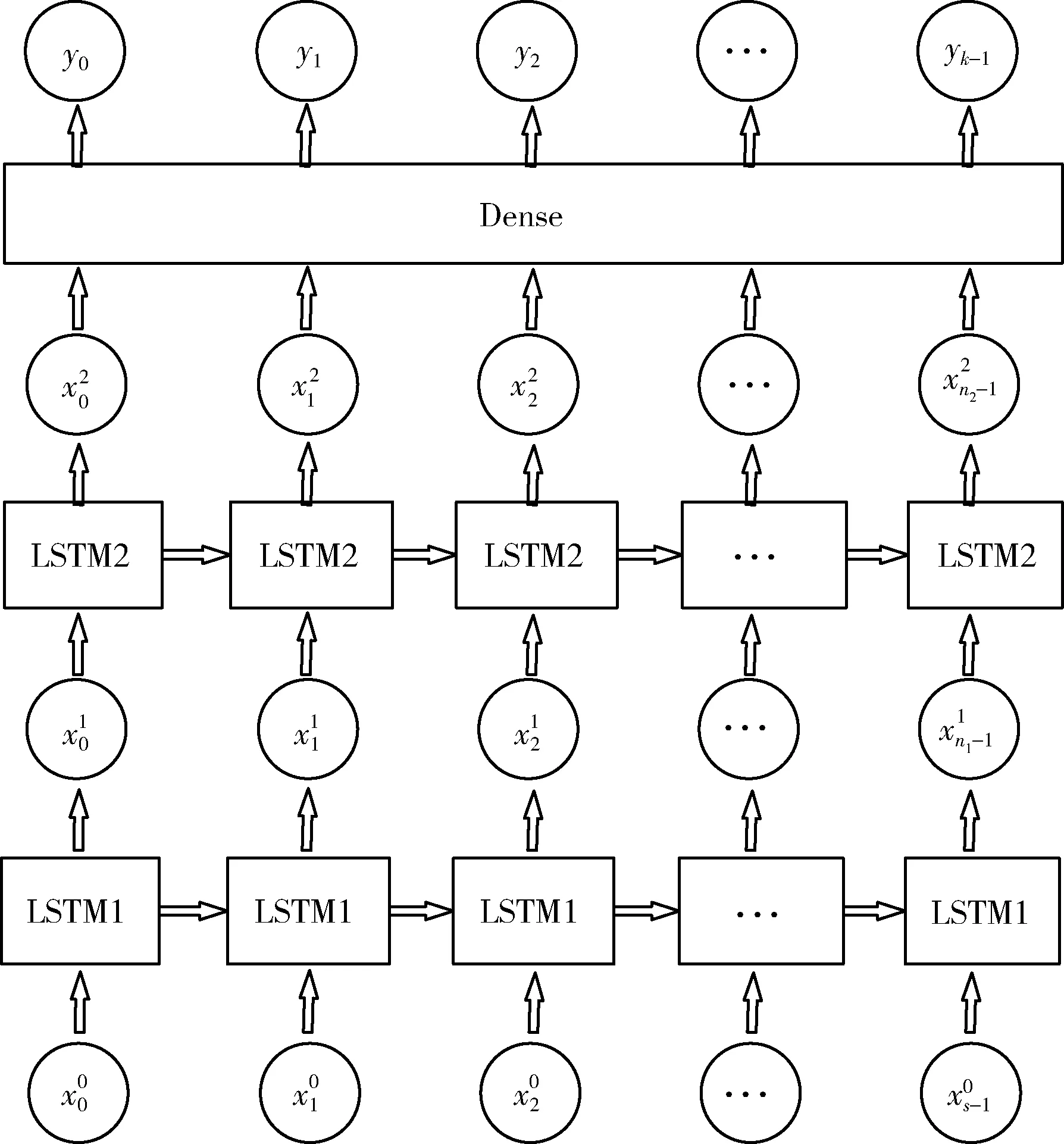
圖3 基于StackedLSTM航跡預測模型架構
根據不同數據類型,LSTM具有多種變體,ConvLSTM是其中的一種,與原始LSTM的區別在于其使用卷積計算來代替權值計算,使用卷積提取多維數據中隱含的關聯信息,在LSTM單元的遺忘門、輸入門和輸出門之前都添加一次卷積操作,這樣做的目的是通過卷積在多維數據中提取特征,使其更加適合空間序列。ConvLSTM網絡單元結構如圖4所示。

圖4 ConvLSTM網絡單元結構
相應的,網絡單元中的每個門對應的計算公式也發生了變化,ConvLSTM的單元計算公式如下所示
ft=σ(Wxf*Xt+Whf*Ht-1+Wcf⊙Ct-1+bf)
(14)
it=σ(Wxi*Xt+Whi*Ht-1+Wci⊙Ct-1+bi)
(15)
Bt=ft⊙Bt-1+it⊙tanh(Wxc*Xt+Whc*Ht-1+bc)
(16)
ot=σ(Wx0*Xt+Wh0*Ht-1+WC0⊙Ct+bo)
(17)
Ht=ot⊙tanh(Bt)
(18)
式中:σ為Sigmoid激活函數;W為權重值;X為輸入數據;H為輸出數據;B為狀態信息;b為偏差量;tanh為tanh激活函數。
ConvLSTM最早被應用于降雨問題預測,用于處理時空序列預測問題,后來也被應用在時間序列問題中。針對4D航跡預測問題,本文基于ConvLSTM單元構建了航跡預測模型,與Stack LSTM預測模型相比,ConvLSTM雖然包含了相同數量的隱藏層,但是將原始的LSTM單元替換成了包含CNN卷積操作的ConvLSTM單元;在模型輸入層中,輸入的數據為三維張量而不是一維數據;與原始的LSTM模型中大小為s的時間窗口序列對應,ConvLSTM模型的輸入數據被劃分為3個子序列;在模型的最后,仍然通過全連接層輸出模型的最終結果。基于ConvLSTM航跡預測模型構架如圖5所示。
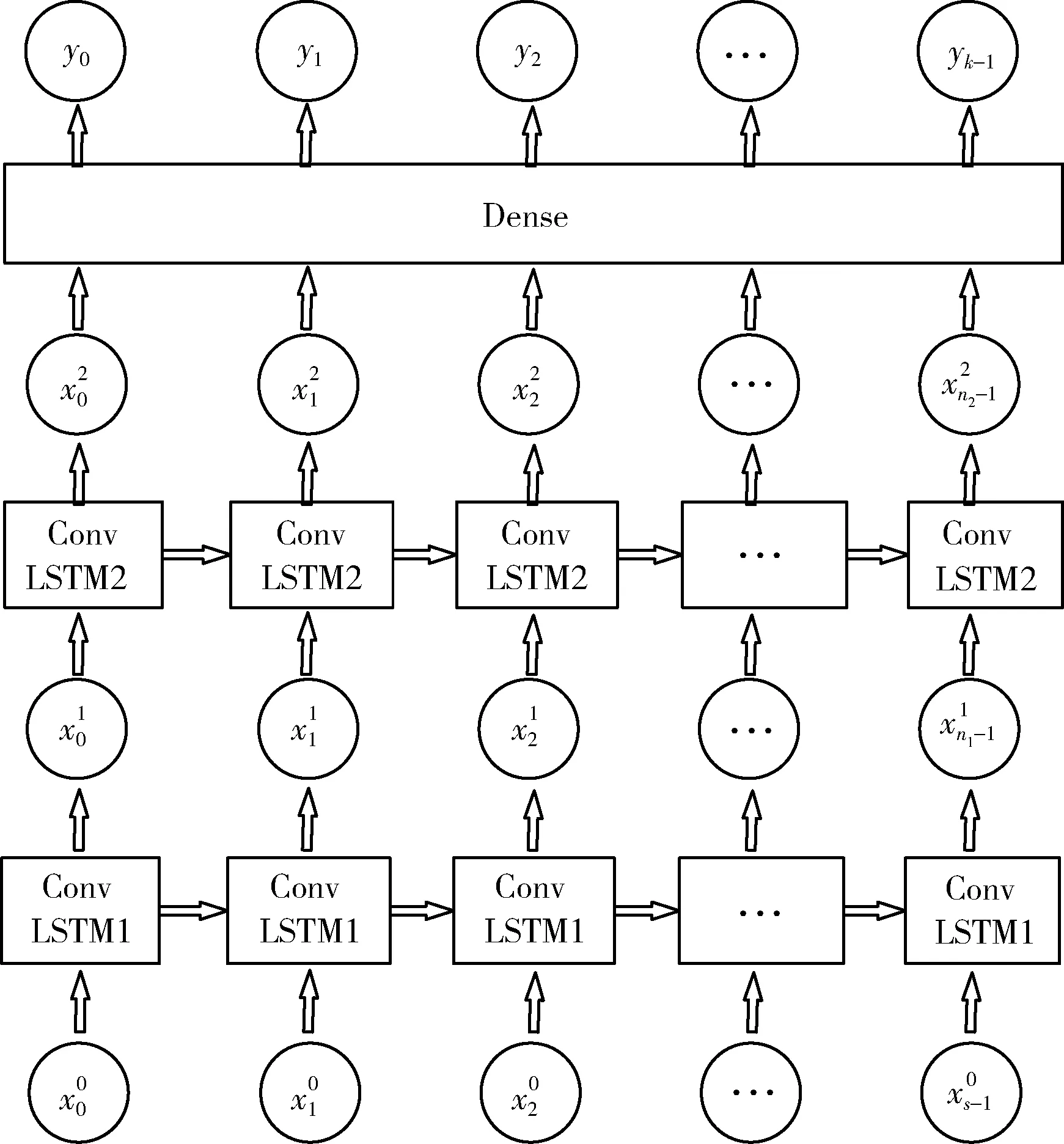
圖5 基于ConvLSTM航跡預測模型架構
4 實驗及結果分析
將獲取的原始雷達報文數據解析,并通過數據分析等方法剔除不合理數據后得到航跡數據集。再對航跡進行航跡聚類,將數據集轉換為聚類后數據。最后使用歸一化和標準化將數據轉換為標準模型輸入。使用航跡中的三維位置坐標進行軌跡聚類,將航跡數據中不同航路的航跡分類。使用墨卡托投影將原始航跡中的經緯度坐標轉換為以機場坐標為中心的二維平面坐標值以便后續計算,并對數據進行歸一化處理以避免特征間量綱不同帶來的影響。最終獲得維度為9405*3的數據集。對于樣本集中機型和分類結果是非數值類型,對其使用One-Hot編碼。訓練樣本的特征包含時間戳、飛行器三維坐標、航向、速度、垂直速度、機型和聚類結果。訓練時使用滑動窗口移動數據,將初始滑動窗口大小設置為9,即將航跡中前9個航跡點作為訓練樣本,模型輸出下一個航跡點后窗口向后滑動,不斷輸出航跡點直到輸出最后一個航跡點。使用水平誤差、垂直誤差和時間誤差評估模型,水平誤差為預測航跡點C和真實航跡點T在二維平面下的歐式距離,垂直誤差是垂直方向上航空器的實際飛行高度和預測高度之前的距離差,時間誤差是指兩條航跡中對應航跡點的時間差值,計算公式如下所示
(19)
evert=|hT-hC|
(20)
etime=|tT-tC|
(21)
其中,水平誤差以海里為單位(nm),垂直誤差以英尺為單位(ft)。使用平均絕對誤差(mean absolute error,MAE)和均方根誤差(root mean squared error,RMSE)衡量預測航跡和實際航跡之間的誤差大小,其計算公式如式(22)~式(23)所示
(22)
(23)
其中,Pi為第i個航跡點某個特征的預測值,Ri為第i個航跡點某個特征實際值。使用雙流機場航班進港航跡作為測試數據集,分析了DTW、快速DTW(FastDTW)、傳統層次聚類(HC),以及加入剪枝的改進層次聚類(IHC)在不同航跡點數下的實驗結果,在時間開銷上進行評價,結果見表1,聚類結果可視圖如圖6、圖7所示。
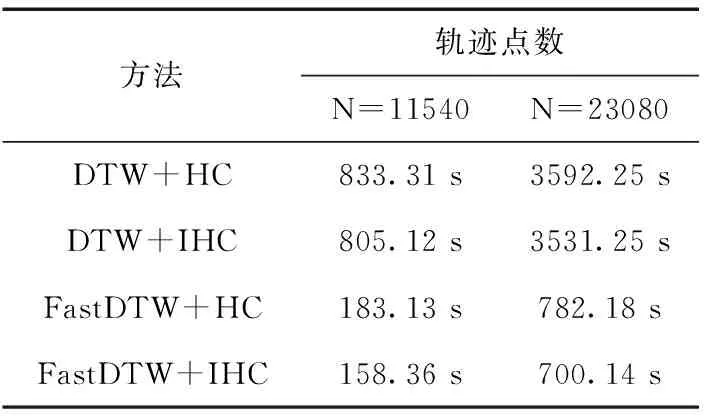
表1 聚類算法時間對比
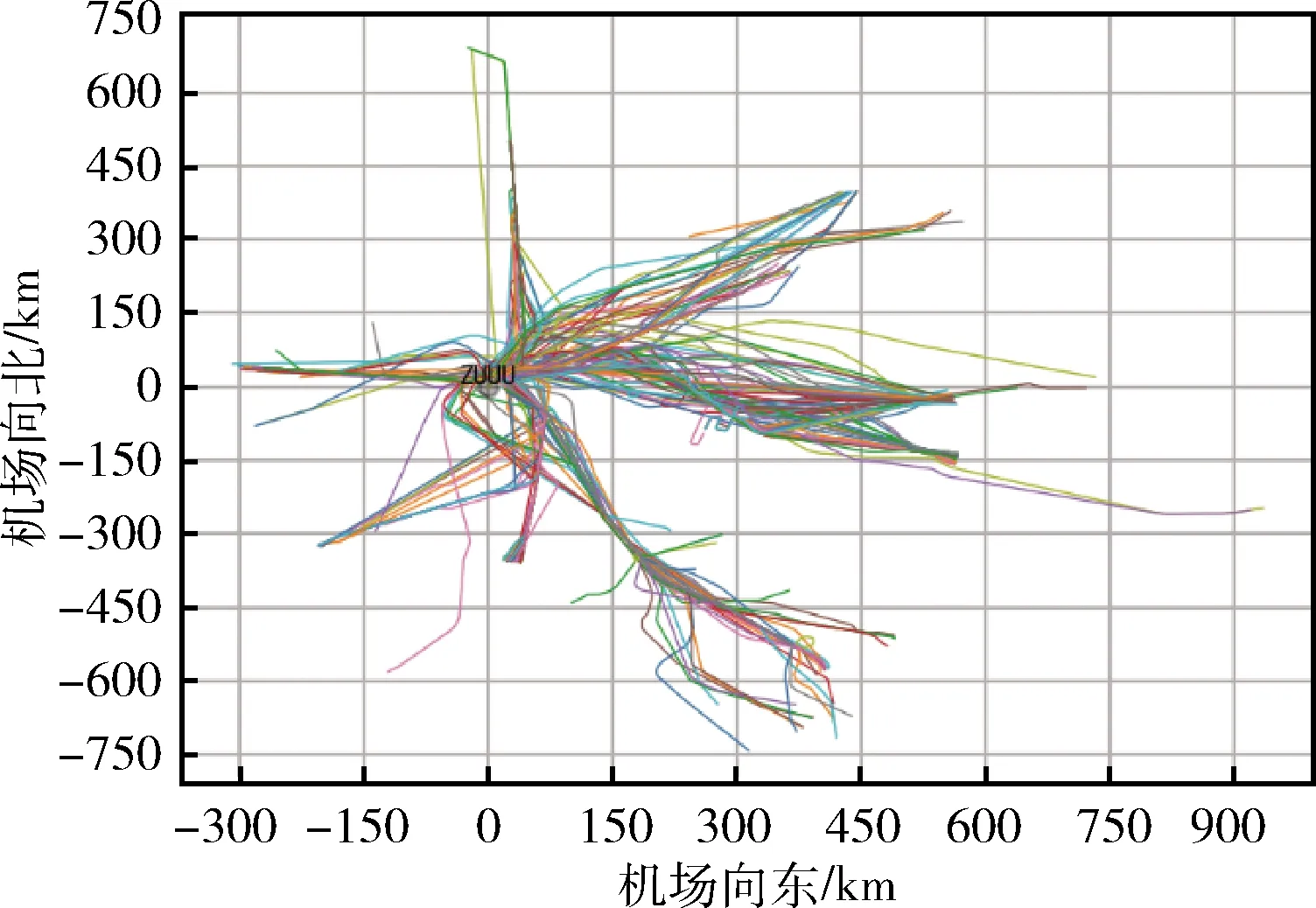
圖6 原始航跡二維平面
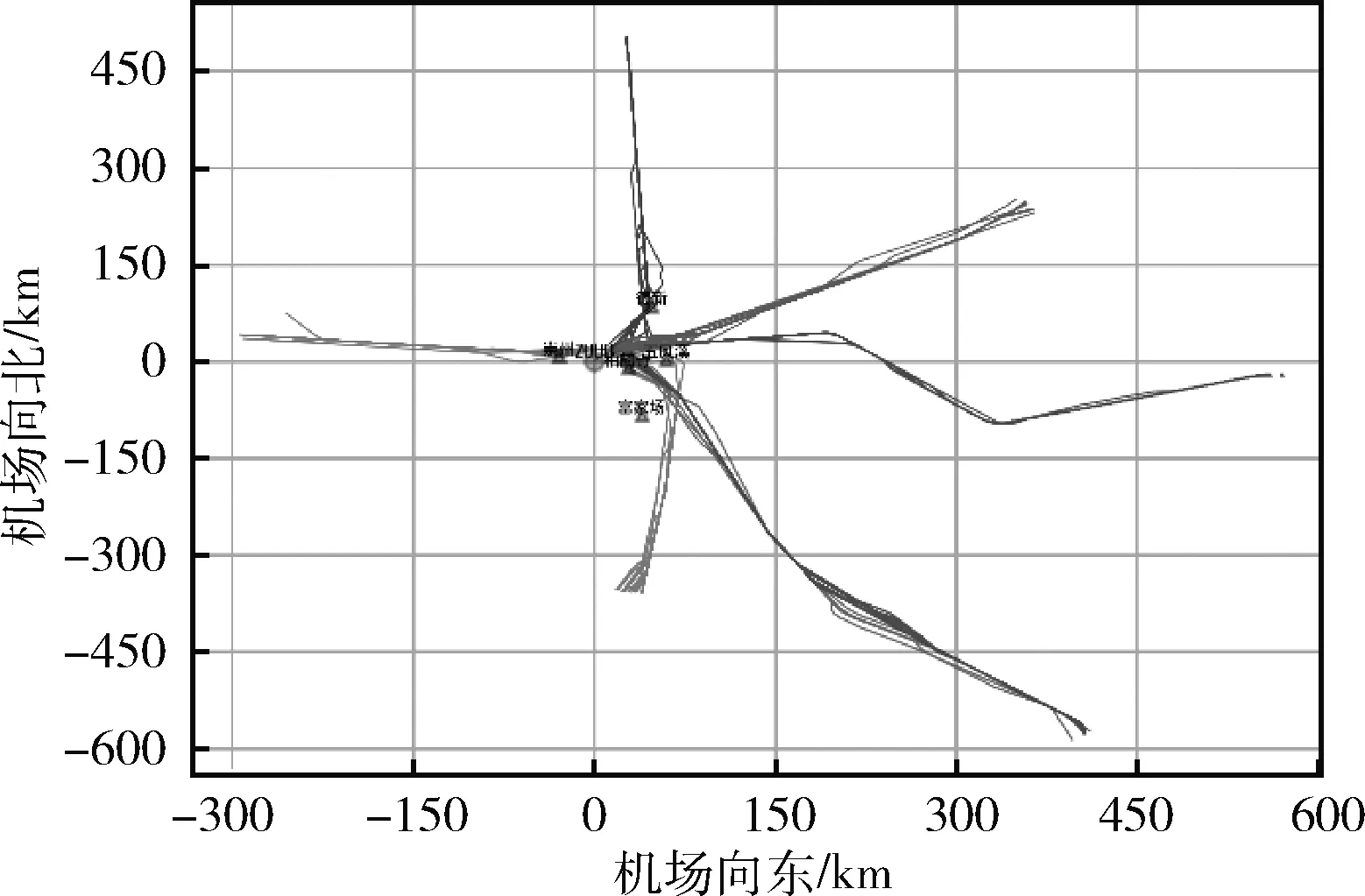
圖7 聚類后二維平面
通過實際結果可知,該聚類方法將原始航跡分為6類,可以有效分離數據,將各類數據分別作為測試樣本對航跡預測模型進行對比實驗。在基于LSTM的預測模型中,包含兩層LSTM隱藏層,單元個數均為300,為防止模型過擬合,在LSTM隱藏層后使用比例大小為0.2的Dropout,滑動窗口大小設置為9。基于ConvLSTM的預測模型中,將滑動窗口大小拆分為3、1、3,在輸入層之后,包含兩個ConvLSTM的隱藏層,每一層設置卷積核大小為(1,3),通道數個數為256。隨機選取60條航跡作為測試集,數據集剩余部分作為訓練集。以測試集中一條航跡為例,預測模型的評價指標計算過程如下:①通過模型不斷迭代計算預測點,獲得一條預測航跡;②通過航跡點之間最短歐式距離的方式匹配樣本標簽航跡中的航跡點,計算預測點與實際點之間的各項誤差值;③得到單條航跡的各項誤差后,使用MAE和RMSE計算所有測試集誤差。實驗結果見表2。
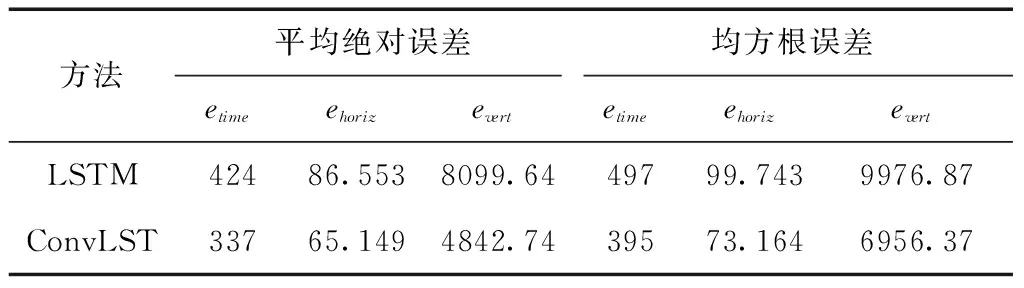
表2 誤差分析對比
可以看出ConvLSTM預測模型的各項誤差值均低于LSTM模型,其中,時間誤差減少了87 s,垂直誤差減少了21.404,水平誤差減少了3256.9,由此看出ConvLSTM模型預測效果更佳。
5 結束語
本文從空管大數據出發,使用數據挖掘聚類算法構建數據集,在聚類算法中使用DTW算法和剪枝加速聚類,實驗結果顯示聚類時間開銷從3592.25 s下降到700.14 s,構建LSTM預測模型和ConvLSTM預測模型,通過計算模型的MAE和RMSE,結果顯示ConvLSTM預測模型的各項誤差值均低于LSTM模型,時間誤差減少了87 s,垂直誤差減少了21.404,水平誤差減少了3256.9。本文借助數據挖掘和神經網絡等技術對4D航跡預測開展了研究工作,但仍然存在較多有待改進的不足之處,其主要包含:①目前數據源較為單一,隨著民航大數據技術不斷發展,可以從不同設備中獲取航跡數據以供后續研究,后續工作可以獲取多源航跡,利用大數據技術對數據進行融合,提供更加完備的數據集;②在預測中僅考慮歷史航跡,并未將氣象因素和空域態勢融入模型,下一步可以將空域氣象和空域態勢輸入模型,提高預測模型的魯棒性和精確性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
