基于改進Faster RCNN的小尺度鐵路侵限算法
2022-04-21 07:23:32余志強
計算機工程與設計 2022年4期
余志強,張 明
(石家莊鐵道大學 電氣與電子工程學院,河北 石家莊 050000)
0 引 言
由行人、動物、車輛等異物侵入鐵道沿線極大的威脅了列車的安全運行,因此為避免異物侵限所造成的安全隱患,利用機器視覺[1]的異物檢測方法有著安裝維護便捷等優點,但是往往受外界的干擾較大,導致檢測結果出現偏差。
目前在異物目標檢測方面的研究大多是采用特征提取結合機器學習的方法。覃劍等[2]采用在線高斯模型對目標候選框快速生成。陳麗楓等[3]采用HOG特征和機器學習對行人進行檢測。
上述研究都是基于人工手動提取特征來實現對目標的檢測,而且特征的適應性較差,在調節過程的時候費時費力、泛化性較差。
近年來,隨著深度學習的快速發展,以及其自動提取特征來進行訓練學習,其高度的智能化成為目標檢測最優的選擇。鄒逸群等[4]提出一種基于anchor-free損失函數的行人檢測算法,解決行人平移問題和緩解行人尺度變化問題。李佐龍等[5]提出利用多尺度特征融合來提高對行人檢測的精確度。付云霞[6]提出基于YOLO算法的行人檢測。徐喆等[7]提出基于候選區域和并行卷積神經網絡的行人檢測。邵麗萍等[8]提出利用Faster RCNN對行人及車輛進行檢測。
然而,對于傳統的Faster RCNN網絡模型存在對于小物體目標漏檢等問題,因此本文提出了一種改進的Faster RCNN鐵路異物檢測方法來提高小尺度識別的精確度。由于傳統算法設置的錨點框尺寸以及數量比例較少,不能很好覆蓋圖像的缺陷信息。因此本文通過調整錨點框數量來提高對于小尺度目標檢測的精確度,同時根據FPN[9]的思想,使主干提取網絡的深淺層特征相融合;并對NMS算法進行改進,提出一種基于衰減得分的NMS算法,在訓練中使用在線難例挖掘方案對模型進行訓練;引入遷移學習[10]的思想,降低了在訓練網絡時所需的大量數據信息的需求。
1 Faster RCNN算法
1.1 Faster RCNN原理
原始圖像首先經過Reshape得到主干特征提取網絡所需要的輸入尺寸,然后進入主干特征提取網絡(Backbone)進行特征提取,本文選取的Backbone為VGG16模型。結構如圖1所示。
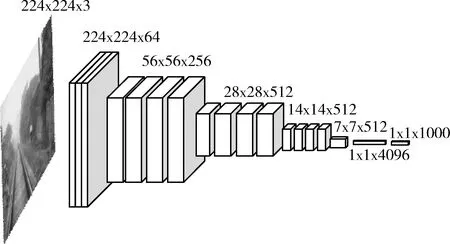
圖1 VGG16結構
隨后由主干網絡提取的特征圖作為共享特征圖分別送到RPN層和RoI Pooling層[11],其中一部分共享特征圖經過RPN層得到多個建議框,之后將建議框映射到另一部分的特征圖上共同輸入RoI Pooling層進行Max Pooling操作,由于輸出為全連接層,因此經過Max Pooling的輸出為固定大小的尺寸。最后進行分類、回歸,然后根據非極大值抑制(NMS)算法篩選Bounding box,找到最優的目標位置以及對應的分類概率。Faster RCNN原理流程如圖2所示。
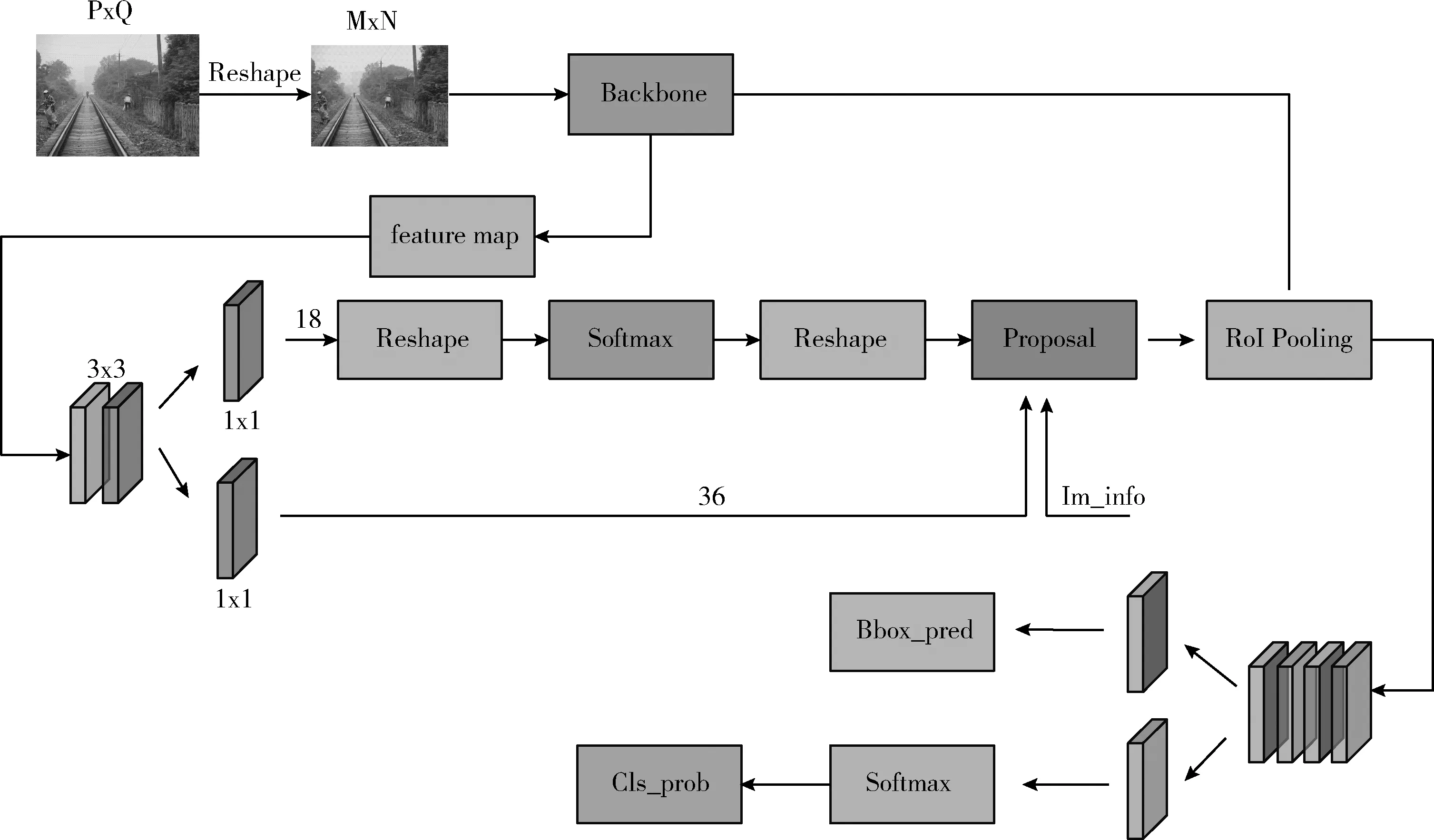
圖2 Faster RCNN流程
1.2 RPN網絡結構
RPN是一個基于全卷積的網絡,可以通過卷積操作同時預測輸入特征圖的每個位置目標候選區域框的坐標信息以及目標得分。RPN的結構如圖3所示。
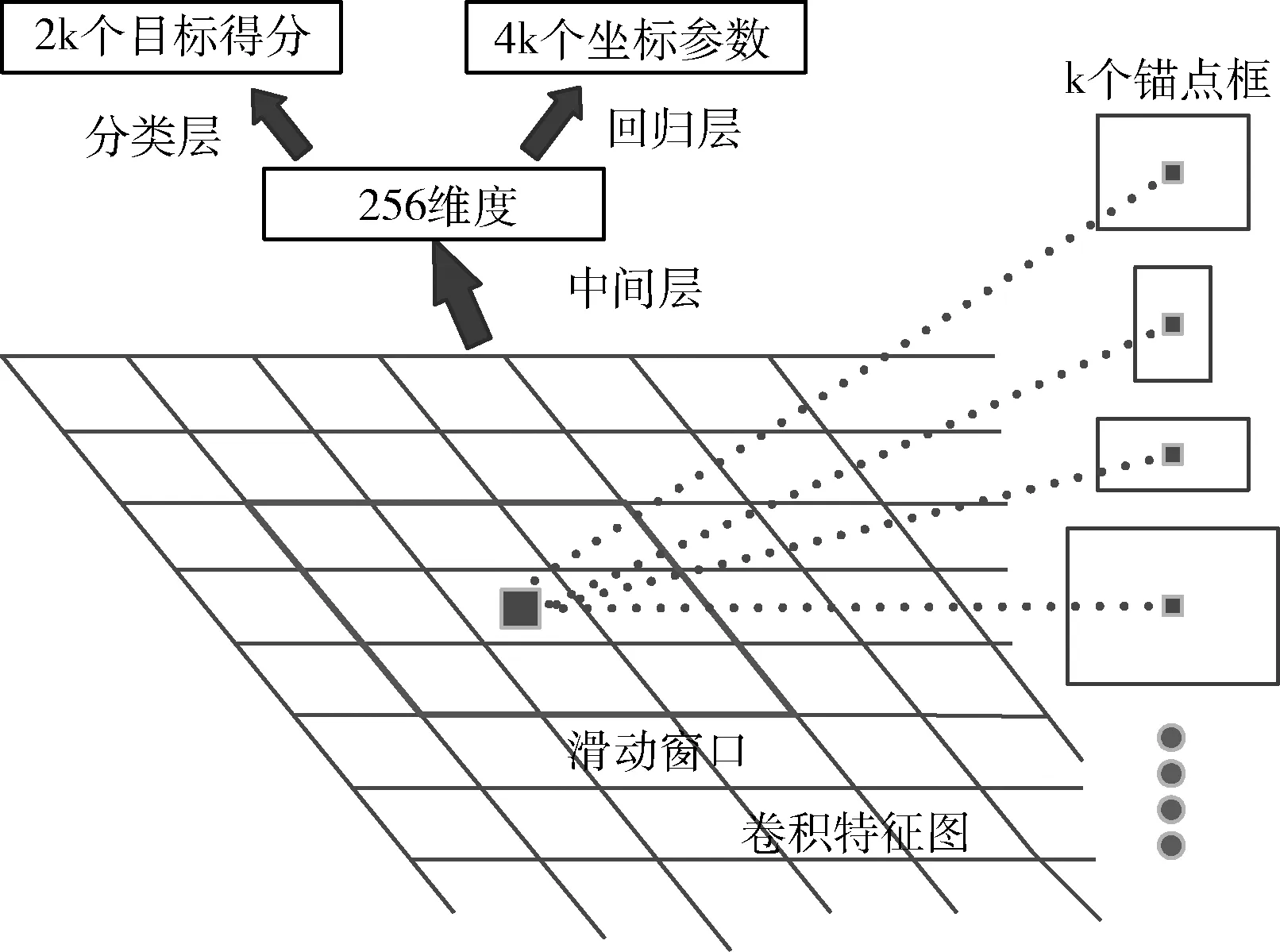
圖3 區域建議網絡RPN結構
首先在主干網絡提取的特征圖上的每一個錨點(anchor point),生成具有不同尺度和寬高比的k個錨點框。然后采用滑動窗口機制,對每個位置的錨點都產生一個對應短的向量來輸入到全連接層中進行位置和種類的判斷。其中一個網絡rpn_bbox_pred用來輸出4個位置坐標,為(x,y,w,h), 其中(x,y)為建議框中心位置坐標,w,h分別為建議框的寬和高。
另一個網絡rpn_cls_score用來做分類,判斷該錨點框中的特征圖是屬于前景(foreground)還是背景(background)。對于每個錨點處有產生k個錨點框,因此,rpn_bbox_pred層產生4k個參數用來編碼k個框的4個坐標。rpn_cls_score則產生2k個參數,用來預測每個特征區域所對應的目標是前景的概率還是所屬背景的概率。
1.3 NMS算法
基于RPN網絡得出每個默認框的得分(score),RPN網絡會將所有得分超過閾值的錨點框全部保留,因此對于一個目標物體可能存在多個選擇框,若要去掉多余的選擇框則需要采用非極大值抑制算法(non-maximum suppression,NMS)。
對于檢測出某一個物體的所有錨點框(bounding box)記為列表B,對應的置信度記為Si。首先選擇檢測框M的重疊區域面積比例(IOU)大于閾值Nt的檢測框,將其從列表B中移除并加入到最終的檢測結果D中。重復該過程,直到B為空集為止。其中閾值Nt一般選取0.3~0.5。具體如式(1)所示
(1)
2 基于改進的Faster RCNN鐵路異物侵限算法
2.1 軌道區域劃定算法
由于在拍攝時,圖像所呈現的距離很遠,范圍很廣。因此對于一些并不會對列車產生威脅的物體也被檢測進取,會使得網絡存在誤檢的情況,而且還會浪費檢測時間,影響運算速率。
因此本文考慮在圖像輸入神經網絡時先對待測圖像進行預處理,根據軌道區域進行區域分割。這樣就達到了只對潛在危險區域進行檢測,間接的提高了整體網絡的運算速度。
對于危險區域的劃分本文根據鐵軌的位置作為參考物,向左右延伸作為確定入侵的檢測區域。軌道區域劃分算法流程如圖4所示。

圖4 軌道區域劃分算法流程
在劃定侵限區域最關鍵的就是找到鐵軌沿線。因為鐵軌檢測的實質其實就是直線檢測。因此本文采用霍夫變換算法(hough transform)來對軌道進行檢測。
霍夫直線檢測算法具有空間變換對偶性,因此每一個點都可以對應某一條直線。相當于在霍夫直線變換時,原像素空間設為x、y坐標系。因此對于任意像素(x0,y0)都可以用表達式y=kx+b來表示。那么對應的參數空間k、b坐標系中用一條對應直線來代表原像素空間中的直線,即:b=-kx0+y0。空間變換如圖5所示。
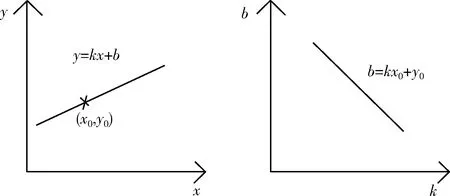
圖5 從(x,y)空間轉換為(k,b)空間
霍夫直線檢測的檢測過程如圖5所示,對每個像素點均求過該點的N條直線的坐標參數(r,theta),采用投票的方式選出擁有最多相同的(r,theta)坐標。當坐標數量超過某一閾值時則確定出一條對應的直線。
若使用霍夫檢測算法進行直線檢測,則參數空間不能選擇直角坐標系,因為在使用直角坐標系的時候,無法表達對于斜率為無窮大時的直線,即垂直直線。在這種情況時直角坐標系對于直線的表達就受到了限制。因此采用極坐標系。
本文使用OpenCV測試仿真如圖6所示。

圖6 軌道侵限區域劃分
由仿真圖可知,若要得到軌道侵限區域首先需要到鐵軌的位置信息如圖6所示中實線部分,通常將檢測出的軌道位置向左右延伸一定距離得到易侵限區域。如圖6中虛線線段表示區域所示,最后將該區域的圖像進行裁剪,作為最終輸入神經網絡的輸入圖像。
2.2 深淺層特征融合算法
對于深層的特征圖,往往會有更小的像素值,表達著更強的語義,若想與淺層的特征值相融合則需要將低層特征和高層特征通過橫向連接和top-down網絡進行融合,這樣操作充分利用了卷積層計算出來的特征信息。橫向連接就是利用1x1的卷積核進行卷積操作,該操作只會改變特征圖的維度不會改變特征圖像的尺寸大小。
自頂向下網絡(top-down)就是一個上采樣的過程,采用雙線性插值算法來對其像素進行擴充。
將上采樣的結果與尺寸相匹配的深層特征相融合,融合之后采用尺寸為3x3的卷積核對融合后的feature map進行卷積計算,該操作可以消除上采樣造成的混疊效應(aliasing effect)。結構如圖7所示。
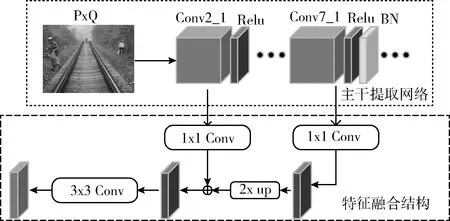
圖7 特征融合結構
2.3 調整錨點數量
在區域建議網絡RPN中有兩個層,一個是坐標回歸層(rpn_bbox_pred)用于對邊框進行回歸;另一個是目標判斷層(rpn_cls_score)用來對目標物體和背景進行分類判別。

2.4 采用遷移學習訓練網絡
針對鐵路異物侵限數據集搜集困難,資料匱乏的問題,如果在訓練過程中直接隨機化初始權重,同時使用收集到的數據進行訓練會導致權重更替緩慢,不利于網絡模型的收斂。因此采用遷移學習的思想對網絡模型進行預訓練。
在預訓練時使用Pascal VOC 2007數據集、INRIA Person Dataset數據集和KITTI數據集中的相似數據整合為訓練集,對網絡模型進行預訓練,得到預權重。通過這種方式就有效的防止了數據量過少造成的過擬合的問題,同時加快了網絡模型的收斂速度。
2.5 在線難例挖掘(OHEM)
首先通過主干神經網絡提取出feature map,將feature map和所有RoI輸入到RoI網絡中進行前向傳播,根據損失函數計算出損失值,并將其進行排序,取損失值(loss)最大的B/N(實際中一般N取2,B取128)個樣本進行反向傳播,因此在反向傳播是只選擇loss值較大的RoI用于更新模型,所以使得參數量大幅度減少,運算速度增加。在一張圖像中,若每個RoI之間的交疊區域越大,那么兩者的loss值也就越相似,由于在經過多層卷積之后得到的feature map,其分辨率不高,交疊區域較大的RoI投射到feature map上可能為同一個區域,會導致loss重復計算。為防止該問題的產生,本文采用非極大值抑制(NMS)對RoI進行去重復,過濾掉交疊區域較大的RoI。最后再令篩選之后的RoI進行反向傳播。經實驗驗證,非極大值抑制的閾值選取0.7為最佳。
如圖8所示,在Faster RCNN的RoI Pooling層之后設計兩個具有同樣架構的RoI網絡,不同的是將其區分為只讀層和可讀-寫層。對于只讀層,只對所有RoI做前向運算,而可讀-寫層既要對可讀層篩選出的難例RoI做前向運算也要進行反向傳播。這一個整體作為一次迭代。
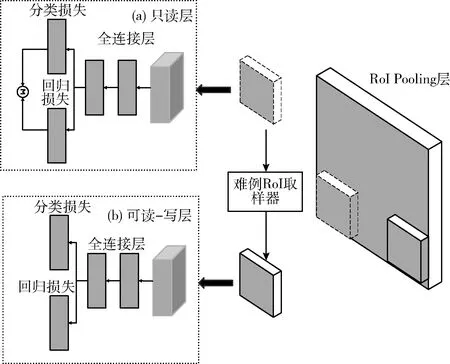
圖8 在線難例挖掘原理
2.6 基于衰減得分的NMS算法
由于NMS的計算方法是當IOU大于閾值時直接把其置信度設置為0。如果將兩個相近的預測框之間進行非極大值抑制時就會出現高得分的預測框直接將較低得分的預測框抑制的問題,這樣就刪除了原本正確分類的預測框。因此本文采用基于衰減得分的非極大值抑制算法,即在NMS的基礎上用一個與IOU值成反比的函數來衰減得分,具體如式(2)所示
(2)
這樣就避免了傳統算法直接置為0,這樣以來即便兩個檢測框的IOU值較大,得分也不會直接置為0,避免了漏檢的現象。
2.7 基于改進的Faster RCNN鐵路異物侵限算法框架
將原始圖經過主干特征提取網絡(Backbone)輸出共享特征圖。本文的主干提取網絡采用的改進的VGG16網絡模型。主要改進措施是將卷積層的高低特征層進行融合,用第二層卷積之后的特征圖Conv2_1,其輸出維度為512x38x38。第7層卷積后的Conv7_2將其經過雙線性插值上采樣得到特征維度為512x38x38的特征圖,使兩者相拼接得到Conv_merge,融合后的特征層(Conv_merge)作為輸入區域建議網絡(RPN)和感興趣區域池化的輸入圖像,最后經過分類、回歸輸出檢測的目標圖像。異物侵限算法的模型整體結構如圖9所示。
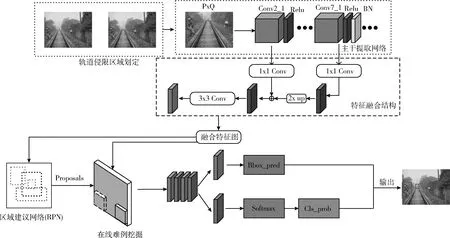
圖9 基于改進Faster RCNN鐵路異物侵限算法框架
3 實驗設計及結果分析
3.1 實驗平臺環境
基于Faster RCNN鐵路異物侵限算法的訓練測試硬件環境見表1。
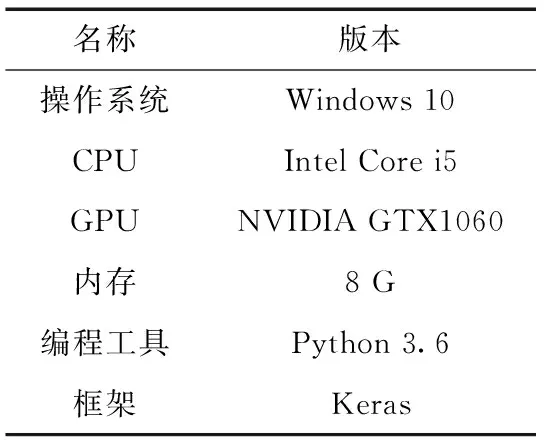
表1 網絡模型訓練及測試環境
3.2 網絡訓練
3.2.1 數據集制作
在進行網絡模型訓練時需要大量的數據集,然而針對鐵路異物侵限的相關數據數量較少,因此若使用的數據量較少就有可能存在在訓練網絡有著較好的訓練效果但是在測試集上泛化性較差的問題。
因此為了避免過擬合現象,文本使用遷移學習的方式對網絡模型進行訓練,即使用一些公開的數據集中與異物侵限內容相近的數據進行預訓練,然后再使本文的數據集參與到訓練之中。
本文使用的公開數據集主要包括VOC 2007數據集中的人像、車輛、動物的內容數據、INRIA Person Dataset數據集、KITTI數據集,以及使用labellmg工具安裝VOC2007格式人工標注的鐵路異物侵限數據集。
3.2.2 損失函數
Faster RCNN的損失函數主要是由RPN網絡的損失函數和Fast RCNN的損失函數組成,并且兩部分都包含分類損失(cls_loss)和回歸損失(bbox regression loss),形式皆如式(3)所示
LFrcnn=LRPN({pi},{ti})+LFcnn({pi},{ti})
(3)
由RPN結構可知,RPN層分為兩個網絡,一個是判斷RPN網格產生的候選框里面的目標是前景還是背景;另一部分則是對該候選框進行回歸的回歸任務。因此對應RPN網絡的總體損失函數如式(4)所示
(4)
其中,Lcls為分類的損失函數,Ncls為mini-batch大小,Lreg為回歸的損失函數,λ為回歸損失函數的權重。
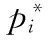
(5)
分類的loss函數使用的是交叉熵,如式(6)所示
(6)
對于Fast RCNN的分類損失因為所檢測的目標大于2,故使用的是多分類交叉熵損失函數。而對于RPN只需分類出背景與前景因此使用的是二分類交叉熵損失函數。
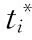
(7)
其中,R為smoothL1函數
(8)
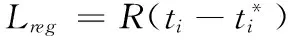
3.2.3 訓練步驟
本文由于數據集匱乏的限制,因此采用了遷移學習的思想,首先基于參數遷移的思想,在GitHub上下載已經訓練好的Faster RCNN模型。然后使用預訓練之后的權重對RPN網絡進行初始化,并使用均值為0,方差為0.01的高斯分布對新增的網絡層進行隨機初始化,最終完成RPN網絡的初始化設置,同理根據參數遷移將Fast RCNN進行初始化。最后基于實例遷移的思想使用異物侵限數據集對RPN網絡和Faster RCNN網絡進行參數權重的細微調整,最后完成對于整個網絡模型的訓練。
在RPN網絡和Fast RCNN網絡訓練時采用隨機梯度下降(stochastic gradient descent,SGD),對網絡進行50次迭代訓練,計算公式如式(9)所示
(9)
其中,α為模型所設置的學習率,m為整體數據樣本總量,hθ(x)為參數的函數,x(j)為第j組的x,y(j)為第j組的y。
其中每一批訓練的數據包含60張訓練樣本,初始化學習率設置為0.01,在此之外還采取圖像旋轉,高度、寬度自由裁剪、增加對比度等數據增強的方式來對原始的數據集進行擴增,防止過擬合并且加快模型的收斂速度。具體操作見表2。
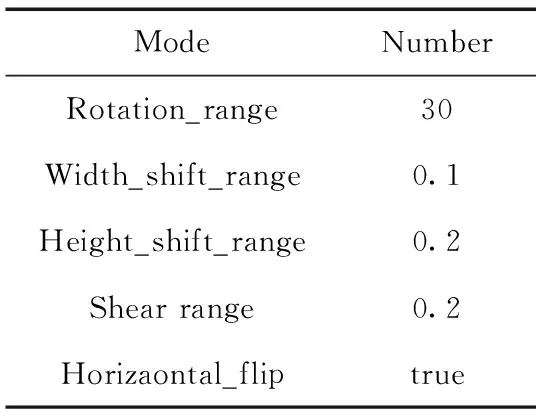
表2 數據集擴展方式
對于網絡模型的評價指標,利用AP(average precision)對檢測網絡中的各類目標進行評價。其計算公式
(10)
其中,Ji為在所有類別中第i類物體的AP值,M為所有數據樣本中正樣本(positive)的數量,P為在不同正樣本數量下對不同的召回率(recall)中最大精確率(precision)。
對于精確率以及召回率的公式如式(11)、式(12)所示
(11)
(12)
mAP則是對每一個類別都計算出AP,然后再計算AP平均值。
3.2.4 基于改進Faster RCNN檢測效果
本文所提出的鐵路異物侵限算法是基于Faster RCNN網絡模型,對其主干特征提取網絡選用VGG16,并對其進行深淺層特征融合,增加了對細小物體特征的學習能力。在RPN網絡中改變了默認的錨點框尺寸,使之更好適應小物體目標的檢測。
為驗證本文模型的效果,從VOCdevkit數據集中選取包括行人、動物、車輛3種類別的數據總共2000張,鐵路異物侵限數據集中數據1000張。總共3000張圖像作為訓練集對模型進行訓練。此外總計1000張異物侵限圖像作為測試集用來對模型的性能進行檢測。如圖10(a)、圖10(b)所示,為50次迭代后模型的準確率和損失率。圖10(c)為5種不同檢測對象各自的準確率。驗證了本文算法有著較高的準確率。
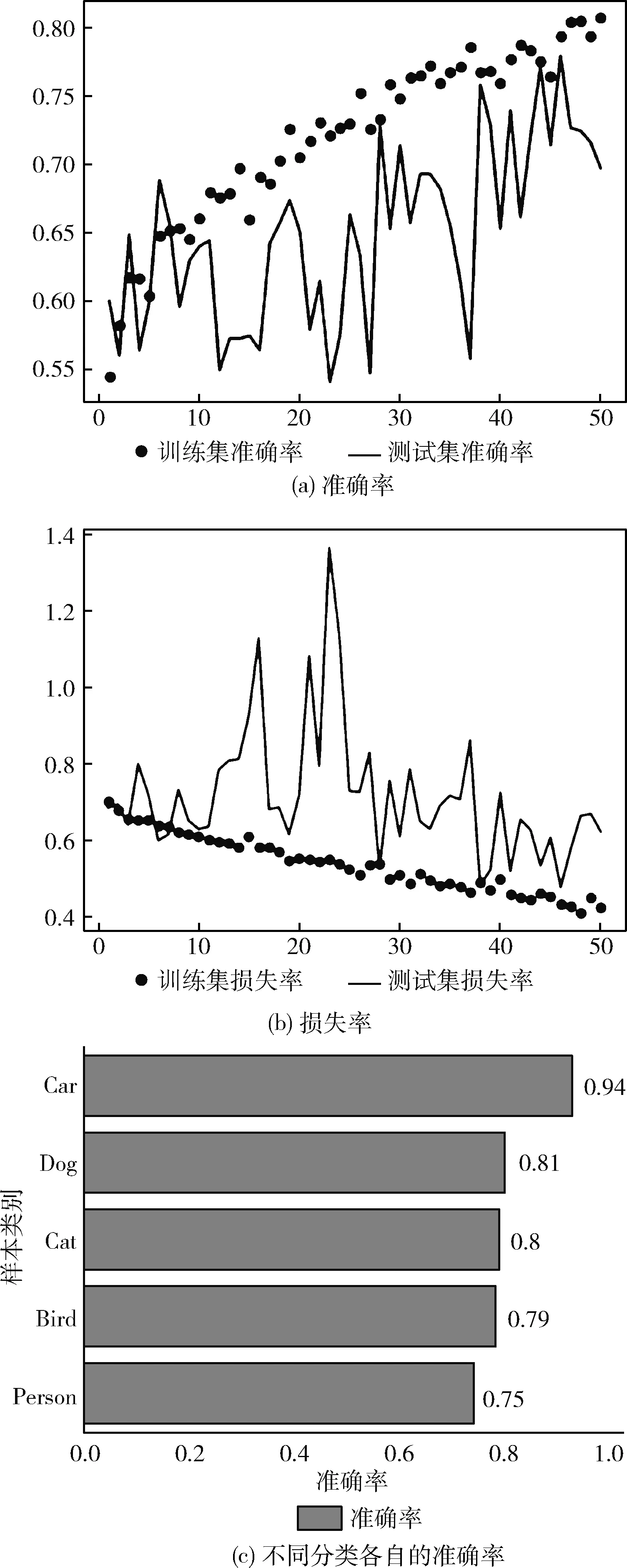
圖10 實驗數據分析結果
3.2.5 不同錨點框尺寸的檢測效果比較
根據上述對于設置默認錨點框尺寸的分析可知不同尺寸的錨點框對于檢測不同大小物體的精確度有所影響。考慮到文獻[12]對于原始的Faster RCNN中使用的是人工預設定的錨點框尺寸(anchor scales)大小為 {128×128,256×256,512×512}, 但是該尺寸對于本文研究內容來說并不能很好覆蓋數據集中較小尺度的目標物體。因此本文在原有改進的基礎上進一步研究對比了不同尺寸的錨點框在鐵路異物侵限數據集上的檢測效果。文本一共選取3組不同尺寸的錨點框在同樣的主干網絡—VGG16下測試對于車輛、動物、行人的準確率以及整體網絡的mAP值。其中,錨點框的尺寸分別為Anchor Scales A{128×128,256×256,512×512},Anchor Scales B{64×64,128×128,256×256},Anchor Scales C{32×32,64×64,128×128}。實驗結果見表3。
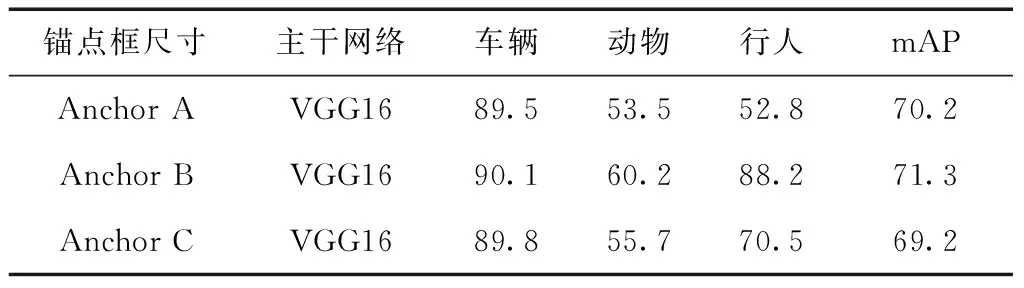
表3 不同尺寸錨點框的檢測結果比較
表3可知,Anchor B的綜合比分更高,因此通過將錨點框尺寸調整為 {64×64,128×128,256×256} 時,其尺寸分布更適應于特征圖感受野同時能夠更好地覆蓋數據集中的大部分目標區域,包括小目標區域。如果繼續將錨點框的尺寸縮小到Anchor C規格,雖然與原尺寸Anchor A相比提高了準確度,但是提高幅度并不大,因此對于本文的研究來說錨點框規格選取Anchor B最為適合。
同時通過Anchor A、Anchor B、Anchor C這3組不同規格的錨點框的對比也驗證本文所提到的較小的預定義錨點框能有效提升小目標的檢測結果。
3.2.6 本文算法性能改進對比
根據表4可知在4種改進方法中增加特征融合和改進錨點框的尺寸可以使整體網絡的性能大幅增加。在保證都加入錨點框時,增加特征融合層,使mAP增加5.1%,驗證特征融合能夠有效地提取小目標特征,對于本文的檢測有極大的提升。在對錨點框的尺寸進行調整之后mAP提升了5.6%,而在訓練中利用在線難例挖掘進行訓練以及基于衰減得分的NMS對mAP也有較大的提升。最后,將4種有效提升小目標檢測效果的方法結合起來,mAP達到77.3,驗證了本文算法的有效性。
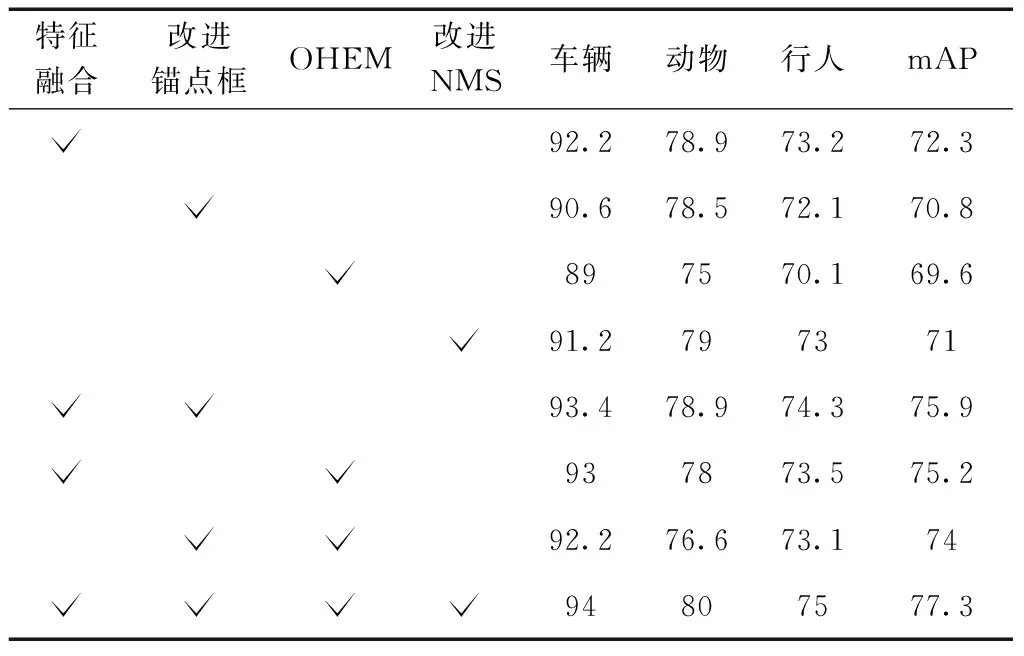
表4 本文算法性能改進對比
3.2.7 本文算法與當前主流目標檢測算法對比
將本文算法與當前主流目標檢測算法進行對比,比較結果見表5。
由表5可知通過本文的改進,使Faster RCNN的mAP相比傳統的Faster RCNN提高了2.1%,同時與目前主流的目標檢測算法相比都有著較高的準確率,該結果驗證了本文算法的可靠性。
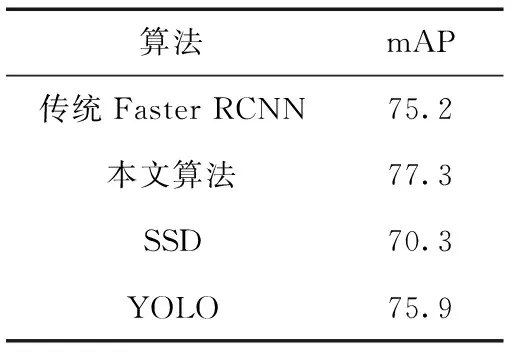
表5 主流目標檢測算法對比
最后,圖11展示了本文算法對鐵路異物侵限的預測效果圖。

圖11 預測效果
4 結束語
本文針對鐵路異物侵限的小目標物體檢測困難問題,提出了一種改進的Faster RCNN算法。
(1)本文采用深層特征與淺層特征相融合的方法,這樣既可以保留高層特征的高語義的特點又能保證低層特征高分辨率的位置細節信息。經實驗驗證,該融合方法能夠有效彌補小目標識別問題,從而提升對于小尺度物體的檢測效果。
(2)通過分析鐵路異物侵限數據集,將原預定的錨點框尺寸進一步精細化,縮小其尺寸,并設計3組不同的錨點框尺寸進行了對比實驗,選取了最適合本文的Anchor Scales。
(3)基于衰減得分的NMS算法經實驗驗證相比NMS算法對mAP有著較好的表現。
(4)由于網絡訓練所需的訓練數據較少,因此本文采用了基于參數和基于實例的遷移學習方式。實現了對本文模型的訓練,實驗結果也有著較高的準確度,具有現實應用的價值。
(5)訓練采用在線難例挖掘的方案,加快網絡的收斂速度,增加了網絡模型對小物體檢測的魯棒性。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
