改進(jìn)相位補償結(jié)合諧波重構(gòu)的語音增強方法
2022-04-21 08:01:16馬建芬張朝霞
計算機工程與設(shè)計 2022年4期
關(guān)鍵詞:方法
崔 磊,馬建芬+,張朝霞
(1.太原理工大學(xué) 信息與計算機學(xué)院,山西 晉中 030600;2.太原理工大學(xué) 物理與光電工程學(xué)院,山西 晉中 030600)
0 引 言
語音增強的目的就是從含噪語音中去除背景噪聲。但是多數(shù)語音增強方法僅關(guān)注幅度譜的優(yōu)化,卻忽視了相位信息對于語音的重要性。已有學(xué)者對相位信息的優(yōu)化[1-5]進(jìn)行了研究,其中最具代表性的就是Anthony P.Stark等提出的相位譜補償函數(shù),它將含噪語音幅度譜與優(yōu)化過的相位譜重新結(jié)合來產(chǎn)生增強語音。但是這種方法有一個較大缺陷就是其補償因子是一個固定值無法適應(yīng)非平穩(wěn)噪聲的變化情況,這會對相位優(yōu)化產(chǎn)生一定的影響。此外多數(shù)語音增強方法在降噪過程中由于語音的諧波結(jié)構(gòu)遭到破壞會出現(xiàn)一定程度的語音失真。
針對傳統(tǒng)相位改進(jìn)方法中補償因子無法改變以及降噪過程中出現(xiàn)的語音失真等問題,提出改進(jìn)相位補償結(jié)合諧波重構(gòu)的語音增強方法。該方法利用先驗信噪比來動態(tài)調(diào)整補償因子。因目前大多數(shù)使用的先驗信噪比估計算法[6-8]如直接判決算法、兩步噪聲消除算法、改進(jìn)型直接判決算法等都存在一定的缺陷[9],而這些缺陷會導(dǎo)致先驗信噪比的估計值較真實值存在較大誤差,為解決這一問題本文采用深度學(xué)習(xí)模型[10,11]來估計先驗信噪比。在此基礎(chǔ)上針對在降噪過程中出現(xiàn)的語音失真采用諧波重構(gòu)的方式對語音的諧波結(jié)構(gòu)進(jìn)行恢復(fù),最終實現(xiàn)語音增強。通過實驗對比,進(jìn)一步探討本文方法的性能。
1 傳統(tǒng)相位譜補償函數(shù)
假定x(t)表示純凈語音,z(t)表示噪聲,x(t)和z(t)相互獨立,t表示離散時間變量,則含噪語音y(t)可表示為
y(t)=x(t)+z(t)
(1)
對式(1)兩邊同時做短時傅里葉變換即可得含噪語音頻譜Y(n,k),純凈語音頻譜X(n,k),噪聲頻譜Z(n,k),Y(n,k)的極坐標(biāo)形式表示如下
Y(n,k)=|Y(n,k)|exp(j∠Y(n,k))
(2)
其中,|Y(n,k)|表示含噪語音第n幀第k個頻點的幅度信息,∠Y(n,k)表示含噪語音第n幀第k個頻點的相位信息。
雖然相位信息可以有效提升語音質(zhì)量,但是由于相位譜的高度非結(jié)構(gòu)化特性,很難對相位進(jìn)行直接估計,鑒于此Paliwal等提出了相位譜補償方法,該方法可以利用噪聲特性對含噪語音相位信息進(jìn)行優(yōu)化,相位譜補償函數(shù)如下
(3)
其中,λ為補償因子,φ(k)為如下所示判決函數(shù)
(4)
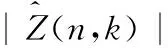
Y∧(n,k)=Y(n,k)+Λ(n,k)
(5)
其中,Y∧(n,k)表示補償后的第n幀第k個頻點的含噪語音頻譜,對Y∧(n,k)取相位即可得到補償后的相位譜
∠Y∧(n,k)=arg[Y∧(n,k)]
(6)
將補償后的相位譜與含噪語音幅度譜結(jié)合即可得到增強語音頻譜S∧(n,k)
S∧(n,k)=|Y(n,k)|exp(j∠Y∧(n,k))
(7)
傳統(tǒng)的相位譜補償函數(shù)中λ是一個固定值,一般取3.74。但是由于λ的固定性它無法反應(yīng)噪聲的實時變化情況,現(xiàn)實生活中大多數(shù)噪聲都是非平穩(wěn)噪聲,簡單的通過一個經(jīng)驗值無法很好的根據(jù)噪聲的變化情況來確定該對相位譜進(jìn)行何種補償。
分析語譜圖,圖1(a)中的Clean是純凈語音,圖1(b)中的Mixture是含噪語音,圖1(c)中的PSC是使用傳統(tǒng)相位譜補償方法結(jié)合含噪語音幅度譜得到的增強語音。從語譜圖中可以看出傳統(tǒng)的相位譜補償方法可以在一定程度上抑制噪聲,但是整體效果并不理想而且失真現(xiàn)象較為嚴(yán)重,這一定程度上是由于結(jié)合了含噪語音幅度譜導(dǎo)致的,但是也能反應(yīng)出傳統(tǒng)相位譜補償方法對于語音質(zhì)量提高的局限性。
2 相位改進(jìn)結(jié)合諧波重構(gòu)的語音增強方法
相位改進(jìn)結(jié)合諧波重構(gòu)的語音增強方法主要分為3部分,第一部分是對相位譜補償函數(shù)進(jìn)行改進(jìn),第二部分是通過深度學(xué)習(xí)模型估計先驗信噪比,第三部分是對增強后的語音進(jìn)行諧波重構(gòu)。
2.1 改進(jìn)的相位譜補償函數(shù)
傳統(tǒng)相位譜補償方法的關(guān)鍵在于補償函數(shù)Λ(n,k),而補償因子λ又是補償函數(shù)中較為關(guān)鍵的一環(huán)。傳統(tǒng)相位譜補償方法中補償因子是一個固定值,這會帶來一個問題就是不能很好地根據(jù)噪聲能量的變化情況對補償因子做出動態(tài)調(diào)整,因此傳統(tǒng)相位譜補償方法會存在一定的不足。針對傳統(tǒng)相位譜補償方法中出現(xiàn)的問題,本文提出一種改進(jìn)的相位譜補償方法,該方法利用含噪語音先驗信噪比這一參數(shù)對補償因子進(jìn)行優(yōu)化,先驗信噪比可以很好反應(yīng)純凈語音和噪聲的能量變化情況。將含噪語音先驗信噪比與相位譜補償函數(shù)相結(jié)合可以很好地通過信噪比變化情況動態(tài)調(diào)整相位譜補償函數(shù),所提出的改進(jìn)的相位譜補償函數(shù)中補償因子如下
(8)
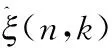
此外,補償因子λnew中c的取值也會影響到增強語音的質(zhì)量,經(jīng)多次實驗取c=7.5。將式(8)帶入式(3)中得到新的相位譜補償函數(shù)
(9)
結(jié)合式(9)和式(6)可以得到新的相位譜
∠Y∧new(n,k)=arg[Y∧new(n,k)]=
arg[Y(n,k)+Λnew(n,k)]
(10)
2.2 先驗信噪比估計
傳統(tǒng)的先驗信噪比估計算法大多存在一定的不足,而改進(jìn)的相位譜補償方法對于相位譜的優(yōu)化主要依賴于對先驗信噪比的準(zhǔn)確估計,為了更好地解決這一問題本文將采用Deep XI深度學(xué)習(xí)模型,其中Deep代表深度學(xué)習(xí)而XI代表先驗信噪比。Deep XI模型是一種結(jié)合了殘差網(wǎng)絡(luò)[12]和時域卷積網(wǎng)絡(luò)[13]可以有效針對先驗信噪比估計的深度學(xué)習(xí)框架。Deep XI模型對于先驗信噪比的估計主要包括兩個階段,第一階段是從含噪語音幅度譜中估計先驗信噪比的映射值,第二階段是通過映射得到的先驗信噪比計算先驗信噪比估計值。Deep XI模型估計先驗信噪比的語音增強方法實驗框架如圖2所示,它包括訓(xùn)練和增強兩個部分,本文主要對訓(xùn)練部分的網(wǎng)絡(luò)配置、特征提取、代價函數(shù)以及增強部分的語音合成進(jìn)行簡要介紹。

圖2 Deep XI估計先驗信噪比實驗框架
2.2.1 網(wǎng)絡(luò)配置
Deep XI模型的搭建參考了文獻(xiàn)[10,11],模型首先是一個大小為256維的全連接層,該全連接層包含歸一化層以及整流線性單元(ReLU)激活函數(shù)。全連接層后面跟40層殘差結(jié)構(gòu),每層殘差結(jié)構(gòu)包含3個一維因果膨脹卷積層,每個卷積層通過層歸一化和ReLU激活函數(shù)進(jìn)行預(yù)激活,其中第一層卷積核為1,輸出大小為64維,膨脹率為1;第二層卷積核為3,輸出大小為64維,膨脹率隨殘差塊指數(shù)增加2的冪次,若超過最大膨脹率,則再次循環(huán);第三層卷積核為1,輸出為256維,膨脹率為1。最后一個殘差結(jié)構(gòu)后面跟一個帶有sigmoid單元的全連接層作為輸出層,用來獲得模型的輸出。模型訓(xùn)練過程中使用的梯度下降參數(shù)優(yōu)化算法為Adam,初始學(xué)習(xí)率為0.001。
2.2.2 特征提取
將純凈語音和噪聲逐幀相加得到含噪語音,提取分幀后的含噪語音幅度譜|Y(n,k)|作為網(wǎng)絡(luò)的輸入。
2.2.3 代價函數(shù)
Deep XI模型使用的代價函數(shù)為sigmoid交叉熵函數(shù),具體定義為
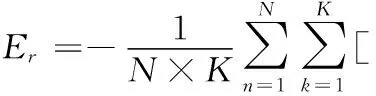
(1-ξ(n,k))ln(1-ξp(n,k))]
(11)
其中,N表示總幀數(shù),K表示每一幀包含的樣本點數(shù),ξp(n,k)如下式所示
(12)
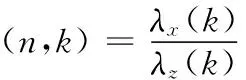
(13)
其中,λz(k)代表噪聲方差,λx(k)代表純凈語音方差。
2.2.4 語音合成
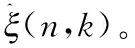
(14)
將含噪語音頻譜Y(n,k)與維納濾波增益函數(shù)G(n,k)相乘,即可得到增強語音頻譜S(n,k),公式如下
S(n,k)=Y(n,k)×G(n,k)
(15)
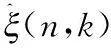
(16)
其中,|S(n,k)|表示增強語音頻譜S(n,k)的幅度譜,最后通過傅里葉逆變換得到時域上的增強語音。
2.3 諧波重構(gòu)
目前通過單聲道語音增強方法得到的增強語音中都會存在一定的語音失真,這是因為語音的濁音中包含了與語音相關(guān)的大部分信息,而濁音的功率是隨著頻率的增加而減小,由于濁音的功率小,它的組成部分會被視為噪聲而被抑制,特別是在高頻下這種情況尤為嚴(yán)重[14],為了解決這一問題,本文采用諧波重構(gòu)的方法,而諧波重構(gòu)的目的就是為了將被抑制的諧波分量重新恢復(fù)。
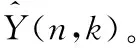
(17)
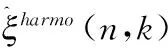
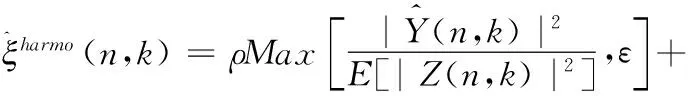
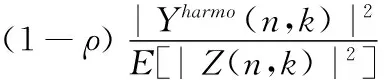
(18)
其中,ρ(0≤ρ≤1)是權(quán)重因子,ε是偏置值取0.8,E[|Z(n,k)|2]代表噪聲的功率譜。因為維納濾波增益函數(shù)G(n,k)的取值范圍也是0到1,而且增益函數(shù)G(n,k)是由先驗信噪比計算得到的,可以較好地反應(yīng)噪聲能量的變化情況,因此本文使用增益函數(shù)G(n,k)來代替權(quán)重因子ρ。則式(18)可以改寫為如下形式
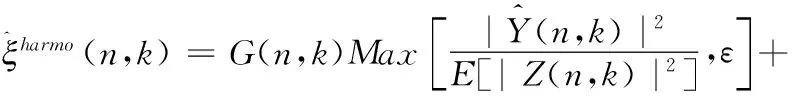
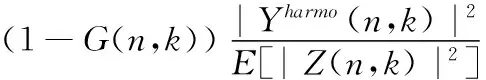
(19)
其中,維納濾波增益函數(shù)G(n,k)是通過第一步基于相位改進(jìn)的語音增強方法計算得到的,此外權(quán)重因子ρ的取值越小計算得到的先驗信噪比估計值越精確,如果直接使用增益函數(shù)G(n,k),當(dāng)信噪比值較高也就是在非噪聲段的時候增益函數(shù)G(n,k)的取值會逼近1,這會影響到最終求得的先驗信噪比估計值的精確度,因此對式(19)進(jìn)行改進(jìn)得到最終的先驗信噪比求解公式
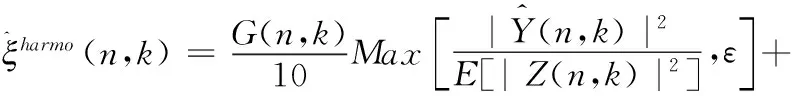
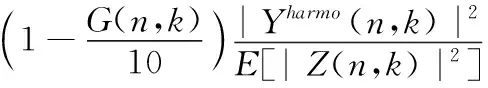
(20)
將增益函數(shù)G(n,k)的取值范圍縮小至0到0.1之間,這樣就可以保證不管信噪比是如何取值,最終得到先驗信噪比估計值的精確度都不會有較大幅度的波動。
(21)
得到增強語音頻譜后通過傅里葉逆變換即可得到最終的增強語音。
3 實驗和結(jié)果分析
3.1 實驗配置
實驗中訓(xùn)練集和測試集的純凈語音均來自TIMIT語料庫,其中TIMIT語料庫中的訓(xùn)練集共有4620條純凈語音,測試集中共有1680條純凈語音,一共有6300條純凈語音。訓(xùn)練集和測試集的噪聲均來自NOISEX-92語料庫,NOISEX-92語料庫中共有15種噪聲。在4種信噪比(-5 dB,0 dB,5 dB,10 dB)條件下,通過將TIMIT語料庫訓(xùn)練集中選取的3000條純凈語音與NOISEX-92語料庫中選取的4種噪聲(Pink,F(xiàn)16,Volvo,F(xiàn)actory1)相結(jié)合,可以得到包含48 000(3000×4×4)條含噪語音的訓(xùn)練集,將其中的2400條含噪語音設(shè)置為交叉驗證集。為了使實驗更符合真實情況,在上述4種信噪比條件下,選取在訓(xùn)練集中不匹配的噪聲類型,即NOISEX-92語料庫中的3種噪聲(Factory2,White,Babble),同時選取TIMIT語料庫中測試集的400條純凈語音結(jié)合得到一個包含4800(400×3×4)條含噪語音的測試集。實驗中所有的純凈語音和噪聲的采樣率均為16 KHz。對信號分幀,加窗,其中幀長為32 ms(512個采樣點),幀移為16 ms(256個采樣點),并對分幀后的信號進(jìn)行短時傅里葉變換,可將信號從時域轉(zhuǎn)換到頻域。
3.2 評價方法
語音增強性能評價指標(biāo)采用語音質(zhì)量感知評價(perce-ptual evaluation of speech quality,PESQ)和語音可懂度評價(short-time objective intelligibility,STOI)。語音質(zhì)量感知評價代表人在聽語音時的舒適程度,語音可懂度評價代表人對于語音的可理解程度,其中PESQ得分在-0.5~4.5之間,得分越高代表增強語音的質(zhì)量越好。STOI得分在0~1之間,得分越高代表語音的可懂度越好。
3.3 評價結(jié)果
為了驗證本文所提出的改進(jìn)相位補償結(jié)合諧波重構(gòu)的方法可以進(jìn)一步提高語音增強性能,將本文所提方法與3種對比方法進(jìn)行比較,含噪語音表示為Mixture,3種對比方法分別為不對相位進(jìn)行處理的Deep XI語音增強方法簡稱為Method_A,該方法通過Deep XI模型直接估計先驗信噪比,并將估計得到的先驗信噪比用于維納濾波增益函數(shù)并對含噪語音進(jìn)行增強;傳統(tǒng)的相位譜補償方法簡稱為Method_B;sigmoid型相位譜補償方法[15]簡稱為Method_C;本文提出的改進(jìn)相位補償結(jié)合諧波重構(gòu)的語音增強方法簡稱為Method_D。其中傳統(tǒng)的相位譜補償方法和sigmoid型相位譜補償方法結(jié)合的增強語音幅度譜均是通過Deep XI模型獲取到先驗信噪比估計值后構(gòu)建維納濾波增益函數(shù),將維納濾波增益函數(shù)與含噪語音幅度譜相乘得到的。
表1列出了在3種噪聲(Factory2,White,Babble)以及每種噪聲對應(yīng)的4種信噪比(-5 dB,0 dB,5 dB,10 dB)下,本文所提方法與3種對比方法的PESQ得分情況。從表1中可以看出在Factory2噪聲下Method_D比Method_A的PESQ得分提升了13%,比Method_B提升了9%,比Method_C提升了4%;在White噪聲下Method_D比Method_A提升了11%,比Method_B提升了8%,比Method_C提升了3%;同樣在Babble噪聲下Method_D比Method_A提升了11%,比Method_B提升了8%,比Method_C提升了4%。從數(shù)據(jù)中分析可知所提方法在不同的噪聲環(huán)境,不同的信噪比情況下均取得了較其它3種對比方法更好的PESQ得分,這是因為本文所提方法不僅僅只針對含噪語音幅度譜進(jìn)行處理,容易被忽視的相位信息在本文中也得到了相應(yīng)的處理,同時得益于Deep XI模型強大的學(xué)習(xí)能力能夠更準(zhǔn)確地估計先驗信噪比,本文所提方法對相位的優(yōu)化要好于對比方法。
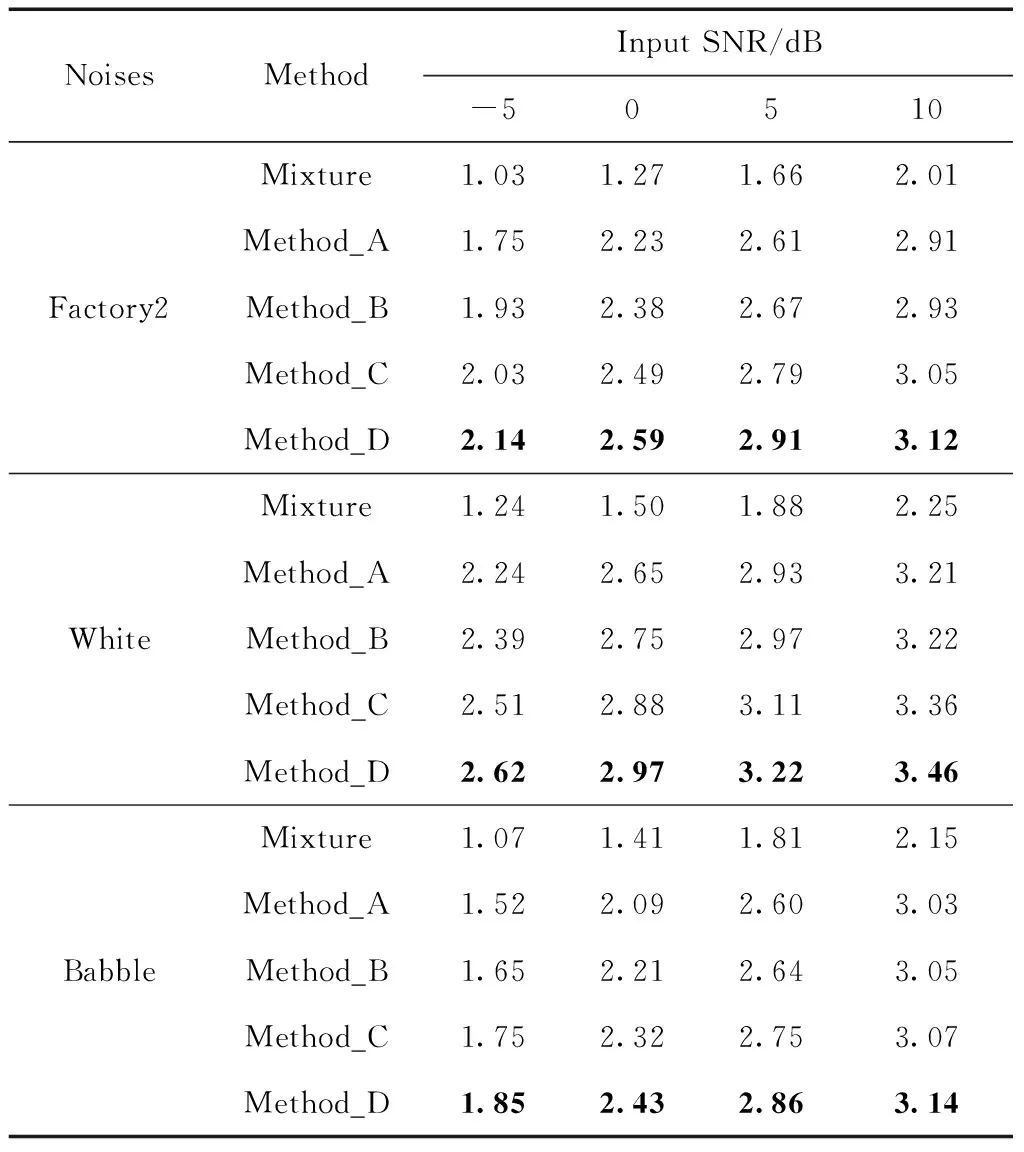
表1 4種方法在不同噪聲不同信噪比情況下的PESQ得分
表2給出了本文所提方法與3種對比方法的STOI得分情況,分析表2數(shù)據(jù)可知Method_A,Method_B和Method_C的STOI得分相差不大,在某些情況下數(shù)據(jù)甚至相等,這是因為在幅度譜保持一致的情況下,增強相位信息并不會對可懂度的提升有較大影響,相位信息更多的是在影響語音的質(zhì)量,但是Method_D不僅考慮對相位進(jìn)行改進(jìn),同時對增強后的語音進(jìn)行諧波重構(gòu),盡可能地恢復(fù)在增強過程中被抑制的諧波分量,有效減少了語音失真,對語音可懂度的提升有一定幫助。
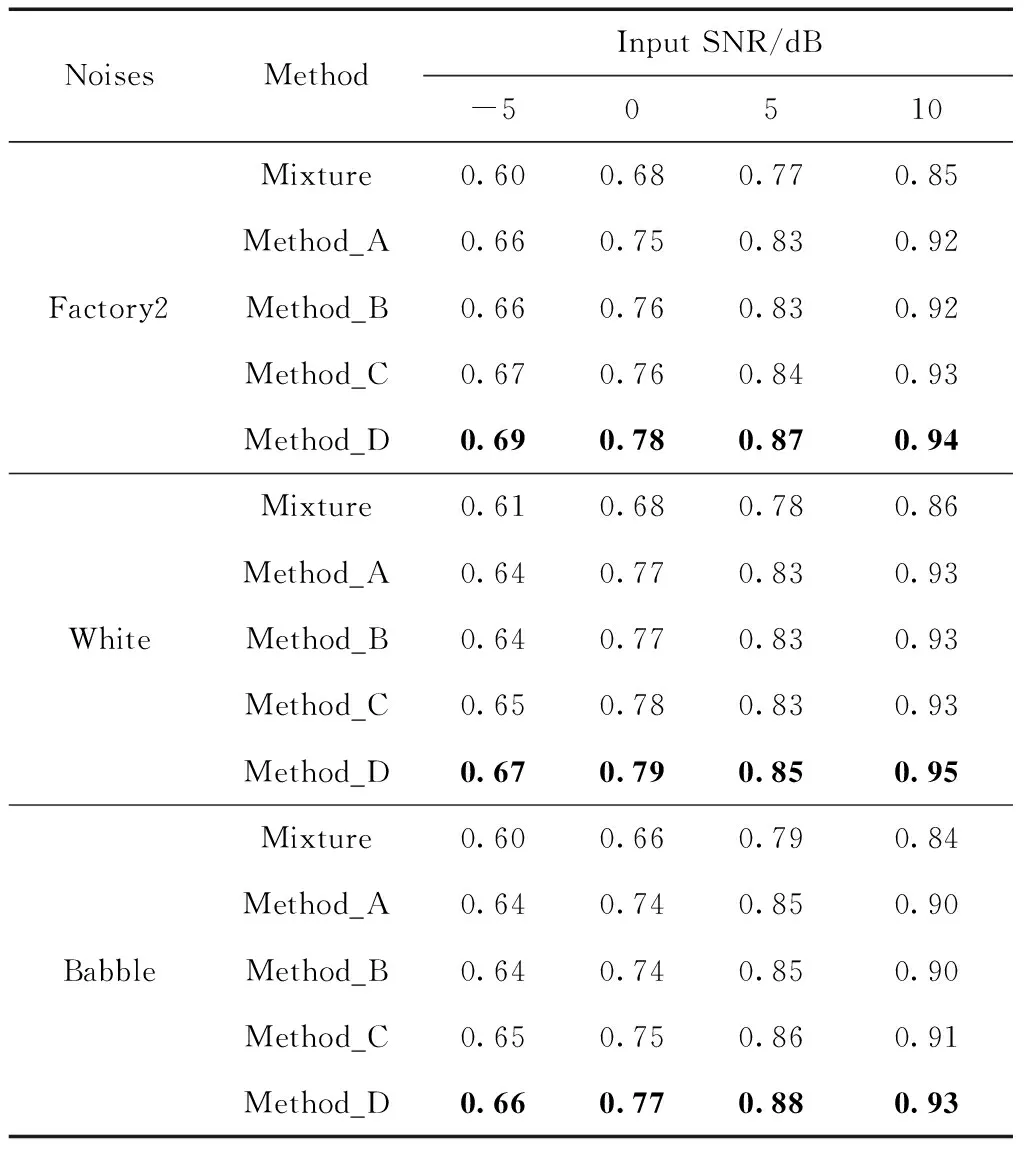
表2 4種方法在不同噪聲不同信噪比情況下的STOI得分
圖3以柱狀圖的形式更直觀地展示了Method_A,Method_B,Method_C和Method_D的PESQ均值。從圖3中可以明顯看出,Method_D與3種對比方法相比取得了明顯的提升。結(jié)合表1數(shù)據(jù)可知這種提升在低信噪比下尤為明顯,當(dāng)信噪比較高時由于相位信息對語音質(zhì)量的影響較小,對相位的改進(jìn)不會帶來明顯的語音質(zhì)量的提升,但是本文提出的方法在高信噪比下也取得了不錯的增強效果。
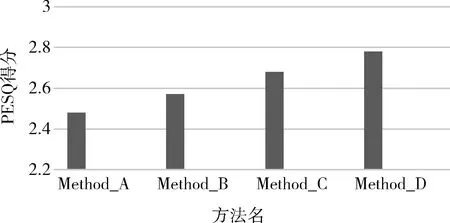
圖3 各方法PESQ均值
圖4表示TIMIT語料庫中的一條純凈語音Clean,SNR=5dB的含噪語音Mixture,以及Method_A,Method_B,Method_C和Method_D這4種不同方法得到的增強語音的語譜圖。從圖4的語譜圖中可以看出,相比圖4(a)中的純凈語音,圖4(c)、圖4(d)、圖4(e)中的增強語音雖然殘留噪聲較少,但是語音的諧波結(jié)構(gòu)較圖4(a)有一定差距,同時可以看到圖4(f)中增強語音的諧波結(jié)構(gòu)較3種對比方法更接近于圖4(a)。這表明所提方法確實可以更好地恢復(fù)諧波結(jié)構(gòu)進(jìn)而提高增強語音的可懂度。
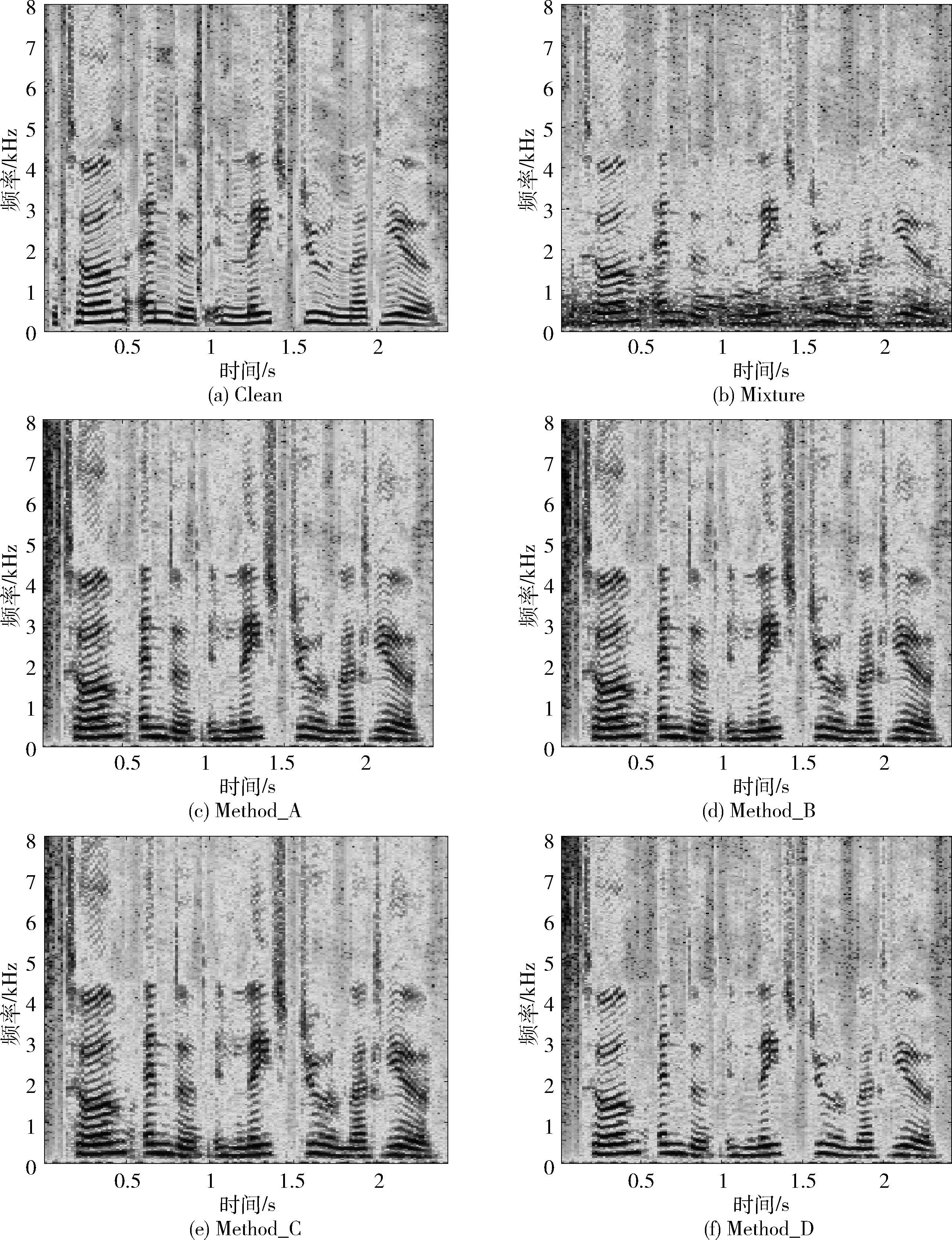
圖4 不同增強方法語譜圖對比
4 結(jié)束語
本文提出一種改進(jìn)相位補償結(jié)合諧波重構(gòu)的語音增強方法。實驗結(jié)果表明,所提出的語音增強方法相比于不對相位進(jìn)行處理的方法以及其它對于傳統(tǒng)相位譜補償函數(shù)進(jìn)行改進(jìn)的方法在語音質(zhì)量和可懂度方面有明顯提升。同時本文所提方法具有普適性,可與任何幅度譜估計方法相結(jié)合,最終得到的增強語音在質(zhì)量和可懂度方面均會優(yōu)于單獨使用幅度譜估計方法得到的增強語音。
但是本文所提方法也存在一定不足,先驗信噪比估計精確度的提升是通過深度學(xué)習(xí)模型以大量的訓(xùn)練時間為代價。未來將繼續(xù)尋找一種輕量級模型,在不降低精確度的前提下縮短訓(xùn)練時間。
猜你喜歡
中老年保健(2021年9期)2021-08-24 03:52:04
河北畫報(2021年2期)2021-05-25 02:07:46
中學(xué)生數(shù)理化(高中版.高考理化)(2020年2期)2020-04-21 05:33:04
兒童繪本(2020年5期)2020-04-07 17:46:30
兒童故事畫報(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
山東青年(2016年1期)2016-02-28 14:25:23
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
