基于GCN 的配電網知識圖譜構建及應用
2022-04-20 07:24:08宋瑋瓊羨慧竹姚盛楠
電子設計工程 2022年7期
宋瑋瓊,韓 柳,羨慧竹,姚盛楠,郭 帥
(1.國網北京市電力公司電力科學研究院,北京 100161;2.華中科技大學,湖北武漢 430070)
近年來,我國電網規(guī)模的不斷提升以及線路復雜度的迅速增加,給電網帶來了巨大的挑戰(zhàn),強迫電網升級,提高電網的信息化、智能化成為了重要任務[1-3]。業(yè)擴計量規(guī)則庫是包括各類電力規(guī)范文件的數據庫,是計量配置方案確定的基礎[4]。傳統(tǒng)的關系型數據庫或者人工查找文檔的方式,雖有優(yōu)勢,但仍有較多局限。同時,方案出錯時會造成計量誤差、裝置故障、電量追回等影響和損失[5-6]。
知識圖譜技術是認知智能領域中的主要技術,其強大的語義處理和互聯(lián)組織能力,已被廣泛應用于智能搜索、智能問答、個性化推薦等領域[7]。但對非結構化數據構建知識圖譜時仍面臨著較大挑戰(zhàn),例如文檔嵌套實體、實體名稱過長、多元關系、表格關系處理等問題。
文中主要從兩個部分重點講解知識圖譜的構建過程:實體抽取和關系抽取。文中采用人工構建嵌套規(guī)則進行實體抽取,使用Multi-Self Attention 與圖卷積網絡結合的方法進行關系抽取。
1 知識圖譜及其關鍵技術
知識圖譜按使用范圍分為通用知識圖譜和領域知識圖譜,通用知識圖譜強調廣度,數據多來自于互聯(lián)網,常見的通用知識圖譜有CYC、WordNet、FreeBase等[8]。而領域知識圖譜應用于垂直領域,以領域或企業(yè)內部的數據為主要來源,知識結構復雜,通過對企業(yè)內部的結構化、非結構化數據進行聯(lián)合抽取并依靠人工進行審核校驗來保證質量。知識圖譜構建主要包括命名實體識別和關系抽取任務。
命名實體識別的主要任務是識別出文本中出現(xiàn)的專有名稱和有意義的數量短語并加以歸類。實體識別主要有以下幾種方法:1)基于規(guī)則。如NTU 系統(tǒng)、FACILE 系統(tǒng)、OKI 系統(tǒng);2)基于統(tǒng)計。如n 元模型、隱馬爾科夫模型(HMM)、條件馬爾科夫模型等;3)混合方法。借助規(guī)則知識及早剪枝,再用統(tǒng)計模型是比較好的方法[9-12]。
關系抽取(Relation Extraction)是信息抽取的關鍵內容,旨在發(fā)現(xiàn)現(xiàn)實世界實體(Entity)間的語義關系。該項技術被廣泛應用在自然語言處理任務中,包括知識圖譜(Knowledge Graph,KG)的構建及補全、問答系統(tǒng)等任務[13-14]。傳統(tǒng)的關系抽取研究通常采用監(jiān)督學習,可取得一定的分類效果,但是需要代價高昂的人工標注數據。為了解決該問題,研究人員基于假設提出遠程監(jiān)督(Distant Supervision)-自動生成標注數據方法,遠程監(jiān)督解決了標注數據不足的問題,但其假設并不總是正確,導致生成的標注數據中存在大量的錯誤標注數據,對關系抽取模型造成不利影響[15]。后續(xù)又有專家提出了使用圖卷積神經網絡的方法解決關系抽取問題并取得了不錯的效果[16]。
文中的知識圖譜構造被分為兩大步驟,分別是實體識別和關系抽取,并重點介紹關系抽取的方法。為獲得更加準確的實體,文中采用由專家制定實體規(guī)則模板匹配的方法,共計7 類實體。同時文中采用由attention 引導的圖卷積神經網絡進行關系抽取,把關系的類別定義成6 類,包括安裝位置、安裝方式、采用、限定、接線方式、其他。
2 配電網計量知識圖譜構建
2.1 計量知識圖譜構建及應用框架
文中提出的基于GCN 的配電網計量知識圖譜構建的算法模塊如圖1 所示。
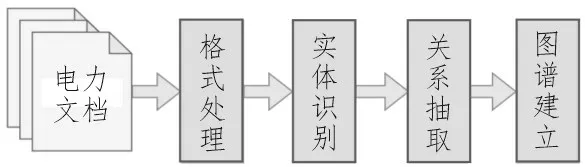
圖1 算法模塊
首先接收技術規(guī)則原始文檔,對其進行格式處理,包括格式對齊、數據清洗等。第二步采用人工制定模板匹配的方法完成實體識別;第三步采用基于GCN 和注意力機制結合的方法完成關系抽取任務;最終對抽取出的<實體-關系-實體>三元組構建配電網計量知識圖譜。文中將重點介紹關系抽取的具體方法與實驗。
2.2 計量本體抽取
文中考慮到使用以往的方法可能導致較多無關實體的出現(xiàn),因此文中采用人工制定規(guī)則進行匹配的方法進行實體抽取。首先由專家指定出電力文檔中的實體規(guī)則,然后按照字符串匹配的方式來匹配計量文檔的各類實體,共計7 類實體。
2.3 計量關系抽取
文中主要通過以下步驟講解關系抽取的具體步驟。
第一步:數據預處理與模型輸入,將數據的信息依存樹提取出來,構建鄰接矩陣作為句子的結構特征。同時利用GloVe 模型獲得句子的詞向量表達w1,并且實體之間的相對位置信息也具有很重要的作用,因此在詞向量中加入位置信息p1,表示兩個實體的相對距離,將詞向量和位置信息結合起來,作為句子的特征向量的嵌入表達:

第二步:LSTM 是一種長短期記憶網絡,能夠捕捉句子中長距離的依賴關系,而有時僅通過單向的LSTM 模型不能獲取足夠的依賴信息,模型需要獲得前文和后文的信息,來進行更優(yōu)的預測。因此為了獲得句子的上下文信息,文中選擇雙向LSTM 網絡進行訓練,得到帶有上下文信息的隱藏層表達X。
第三步:圖卷積網絡(GCN)是一種在圖結構上進行計算的多層神經網絡,這里的圖可以是知識圖譜之類的有向圖,也可以是一些無向圖結構。GCN 可以對輸入圖中的節(jié)點或邊進行編碼,并且同時包含其關聯(lián)節(jié)點的信息。在這里,將鄰居矩陣A和初始的句子的嵌入表達X 作為圖卷積網絡的輸入。通過圖卷積網絡,中心節(jié)點可以融合到鄰居節(jié)點的特征信息,相當于將句子的結構信息與特征信息融合。具體公式如下:
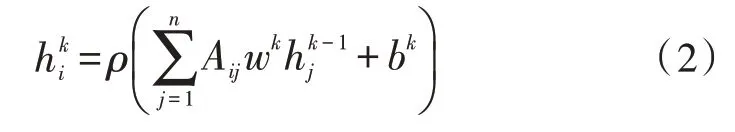
其中,Aij為鄰居矩陣,wk為參數矩陣,為上層GCN 的結果,初始時為,bk為偏置。
第四步:在GCN 的訓練過程中,不同節(jié)點的邊應具有不同的重要程度,例如越近的節(jié)點之間的邊相較于距離更遠的邊應該賦有更高的權重。為了解決不同節(jié)點之間權重初始化相同的問題,同時為了更好地得到節(jié)點之間的關聯(lián)特征信息,文中使用多頭注意力機制來學習獲取節(jié)點之間的重要程度并將其作為權重矩陣,送入第二層圖卷積中進行訓練。公式如下:

第五步:將句子的隱藏層表達送入池化層,同時由于句子中的實體也有非常重要的作用,因此將用同樣的池化方法得到實體的隱向量。f:Rd×n→Rd×1是一個最大池化函數,可將n個輸出向量映射到一個句子向量。

同樣,模型可以獲得實體表示。對于第i個實體,其計算可表示為:

將其進行拼接,送入前饋神經網絡,得到最終的隱藏層結果,即:
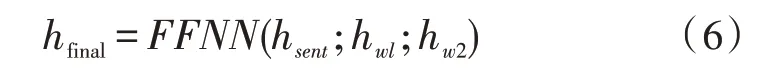
第六步:關系分類,將獲得的隱藏層表達(句子,實體1,實體2)送入softmax 分類器得到最終的分類結果:
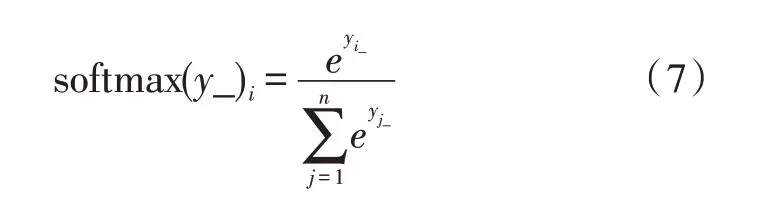
并使用交叉熵作為損失函數:

2.4 計量規(guī)則生成
圖數據庫使用的數據模型包括簡單圖、屬性圖、超圖及嵌套圖,文中依據屬性圖為基礎進行數據存儲。圖由頂點和邊組成,頂點與頂點之間由邊連接。屬性圖的頂點有標簽、頂點的屬性及屬性值;屬性圖的邊有類型、方向、屬性及屬性值。每個頂點都包含標簽和屬性,其中標簽代表頂點的分類,屬性用來描述頂點的特征,用一組鍵值對來存儲。例如一個名稱為發(fā)電企業(yè)的用戶,在圖數據庫中用一個頂點表示,頂點的標簽是“用戶”,屬性(name:發(fā)電企業(yè))則代表用戶的特征。邊包含類型和方向,其中類型代表關系的名字,方向則表示頂點之間邊的方向。例如名稱為用戶的節(jié)點包含發(fā)電企業(yè)節(jié)點時,用戶與發(fā)電企業(yè)之間存在一條邊,邊的方向是從用戶到發(fā)電企業(yè)。邊也可以包含屬性,采用鍵值對存儲。例如給邊增加權重、特性等信息時,即可以給邊增加屬性。如圖2 是一個簡單的圖數據庫例子。若用戶希望獲得“發(fā)電企業(yè)的貿易結算電能計量點的安裝位置”,針對這類查詢,結合圖2 中所示的數據,可將查詢表示為路徑:(發(fā)電企業(yè))→[限定]→(發(fā)電企業(yè)的貿易結算電能計量點)→[位置]→(位置信息xxx),其中()表示頂點,第一個頂點信息由查詢條件給定;[]表示關系;→表示方向。該查詢中涉及未知個數的頂點以及兩層關系,最后對最終的結果進行排序。

圖2 知識圖譜規(guī)則查詢簡單示例
3 實驗分析
3.1 評價指標
文中的關系抽取實驗采用精確率、召回率以及F1 值作為關系抽取的實驗指標,其中,精確率是針對預測結果而言的,表示預測為正的樣本中有多少是真正的正樣本,公式為:

召回率表示樣本中的正例有多少被預測正確,公式為:

為了能夠評價不同算法的優(yōu)劣,在精確率和召回率的基礎上使用F1 值的概念,對精確率和召回率進行整體評價。F1 的定義如下:

3.2 實驗數據集
文中的關系抽取數據集主要來自電力計量規(guī)則文檔,文中首先進行了格式處理、數據清洗等工作。其中數據樣例為“適用于發(fā)電企業(yè)的貿易結算電能計量點的安裝位置為并網線路側”。其中“發(fā)電企業(yè)的貿易結算電能計量點”為實體1,“并網線路側”為實體2。文中的數據總量為7 800 條,其中7 000 條為訓練集,800 條為測試集。關系類別共有6 種,分別為安裝位置、安裝方式、采用、限定、接線方式、其他。其他代表實體之間除上述5 類之外的關系。
3.3 結果與分析
3.3.1 實驗設置
文中為驗證構建的基于注意力機制的GCN 模型對于關系抽取的有效性,以精確率、召回率、F1 值3 個指標來觀測實驗效果。同時文中在不改變其他超參數的設置下,對是否使用注意力機制和是否加入上下文信息進行了測試和實驗,并對比二元實體關系與三元實體關系的抽取結果。
文中采用的硬件條件是單塊Tesla P4 的GPU,CentOS 7.8.2003 的操作系統(tǒng)。其中,所有模型均使用了隨機梯度下降的方法進行訓練。
3.3.2 電力數據集的注意力機制實驗
從表1 可以看出,在增加了注意力機制后,精確率、召回率和F1 值均優(yōu)于無注意力機制的模型效果,同時三元實體的關系抽取效果比二元實體的關系抽取效果好,因此可以看出注意力機制對圖卷積模型特征提取的有效性。

表1 電力數據集的注意力機制實驗精確率、召回率和F1值
3.3.3 電力數據集的上下文信息實驗
在模型中通過加入LSTM 模塊可以得到文本的上下文信息,如表2 所示,當模型中缺失了上下文信息,模型效果會有明顯的下降。因此可以看出文本的上下文信息對關系抽取模型的有不小的影響。

表2 電力數據集的上下文信息實驗精確率、召回率和F1值
3.3.4 知識圖譜建立與規(guī)則測試效果
當完成了關系抽取任務后,就獲得了<實體-關系-實體>三元組,在經過專家核驗后,并以此構建電力業(yè)擴計量知識圖譜。通過規(guī)則測試,精確率可以達到79.4%,查詢效果如圖3 所示。

圖3 查詢效果展示圖
4 結束語
目前知識圖譜已廣泛應用在各種通用領域,然而各行業(yè)數據結構復雜、不規(guī)范,導致在知識圖譜的構建過程中遇到了不少困難與挑戰(zhàn)。文中對于電力文檔構建知識圖譜提出了可行的辦法,通過圖神經網絡模型抽取文檔中的關系,結合抽取出的實體,構建實體關系三元組,并用此構建電力業(yè)擴計量知識圖譜,同時提出了基于知識圖譜遍歷的配電網計量裝置選型規(guī)則生成方法,其生成的規(guī)則更加精確,為電力裝置的選型奠定基礎。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中華手工(2017年2期)2017-06-06 23:00:31
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
中外會展(2014年4期)2014-11-27 07:46:46
中學數學雜志(初中版)(2006年1期)2006-12-29 00:00:00
建筑創(chuàng)作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
