基于改進LDA-CNN-BiLSTM模型的社交媒體情感分析研究
2022-04-14 03:26:34楊秀璋劉建義任天舒宋籍文姜婧怡陳登建周既松
現代計算機 2022年2期
楊秀璋,劉建義,任天舒,宋籍文,武 帥,3,姜婧怡,陳登建,周既松,李 娜
(1.貴州財經大學信息學院,貴陽 550025;2.貴州高速公路集團有限公司,貴陽 550027;3.漣水縣財政局,淮安 223400;4.中國船舶工業系統工程研究院,北京 100094)
0 引言
隨著Web2.0和社交媒體的迅速發展,互聯網產生了海量的評論信息,它們包含了用戶對輿情事件、人物觀點和風景事物等所產生的價值傾向和情感色彩信息,表達了大眾對萬事萬物的情感色彩和立場態度,包括喜悅、憤怒、哀傷、贊同、批評等。如何自動化快速地從非結構化評論中挖掘出用戶的情感傾向,動態監測輿情事件的情感態勢變得至關重要,情感分析(sentiment analysis)技術應運而生。情感分析又稱為意見挖掘、傾向性分析,旨在對帶有情感色彩的主觀性文本進行分析、處理和推理及預測的過程,重點關注文本中的不同情感色彩的特征,比如積極或消極。文本情感分析被廣泛應用于輿情分析、內容推薦、文本挖掘等領域,已經成為了近年的研究熱點。
社交媒體的發展,便捷了用戶信息的往來,用戶對事件抒發個人真實感受和親身體驗,對于政府、企業來說都是重要的信息。然而社交媒體由于用戶量龐大,產生的意見信息層次不齊,大多信息簡短而緊湊,夾雜大量個人感受和評論,存在較為嚴重的文本噪聲,一定程度增加了文本挖掘研究的難度。傳統情感分析方法僅從文本信息特進行征提取實現情感分類,并未有效考慮上下文間的語義關聯,不能較好反應社交媒體真實的情感,結果存在一定的片面性。
1 相關研究
1.1 社交媒體情感分析
依托社交媒體的存在,用戶對輿情事件、人物觀點和風景事物等產生了大量意見,為理解、深層次挖掘用戶信息行為提供了可能。其核心研究為分析用戶在社交媒體平臺上表達的情感,即情感分析(sentiment analysis)。情感分析主要包括:傾向性分類、情緒分析、情感時序分析、主觀檢測、意見摘要、意見檢索、意見持有者提取、諷刺和反語檢測、跨領域情感分析以及多模態情感分析。最為常見的情感分析為情感分類和情緒分析。
情感分類基于假定一個實體或實體的方面和屬性能夠簡單劃分在兩個相反情感極性的一個,分為積極、消極和中立。情緒分析是在情感分析的基礎上結合心理學的情緒狀態量表(profile of mood states)進行六維度劃分。
1.2 基于機器學習的情感分析
基于機器學習的情感分析方法可分為兩類:監督學習技術和非監督學習技術,都依賴于特征集。基于監督機器學習方法以支持向量機(SVM)、樸素貝葉斯、決策樹算法等,需要充足的語料庫作支撐。基于非監督學習方法以無監督學習和半監督學習為主,一定程度能夠解決缺乏完整標注的語料庫帶來的分析局限性。
針對機器學習算法的局限性,學者在算法基礎上進行一定程度優化,提升其識別效果。馬捷等人在現有情感極性值的基礎上,融入方差加權信息熵,計算不同話題解讀傾向所映射出的信息嬌虎毒,一定程度量化了熱點話題的信息價值。車思琪等在傳統機器學習算法基礎上融入情感詞典,提升識別效果。王珠美等在傳統LDA模型基礎上結合直覺模糊TOPSIS方法對農產品在線評論進行綜合評價值計算,有效發現綜合評價值與積極情感值之間的正相關性。
由于社交媒體的語料內容存在大量個人情感,語料信息噪聲大,機器學習方法進行情感特征提取時,無法進行準確預測。
1.3 基于深度學習的情感分析
相比于機器學習方法,深度學習模型不再依賴于特征提取,而是進行自主學習。隨著深度學習的研究深度加深,基于深度學習的情感分析方法的準確率逐步超過傳統方法。雖然深度學習模型進行情感分析能夠有效解決語料標注問題,且準確率較高,但模型訓練花費時間較大,無法解釋最終語義。
針對深度學習模型現階段的局限性,學者在框架模型上進行一定程度改進。楊秀璋等人在傳統TextCNN模型基礎之上融入Attention機制組合,有效完成微博輿情事件的情感分類。夏輝麗等人針對推文情感分類復雜且準確率低的問題,提出一種利用自注意力雙向分層語義模型進行網絡文檔情感分析,提高了深度學習模型的求解速度和準確度。張衛等人針對古詩文本采用“冷啟動”自動標引進行語料學習,并運用深度學習模型BERT-BiLSTM-CRF進行長篇幅詩文情感分析,有效提升準確率,拓寬了對非遺文本的語義解析。
由于社交媒體的信息文本簡短而緊湊,前后文語義關聯度大,深度學習方法在進行語料學習后,應考慮前后文本語義關聯性,再進行情感分析。
針對社交媒體情感分析忽略情感特征的長距離語義關系,無法精準捕獲文本信息中帶有情感色彩的特征詞,需要進行大量人工標注提升實驗結果的問題。本文提出一種改進LDACNN-BiLSTM的深度學習模型,有效感知輿情事件的情感態勢,一定程度上實現對微博輿情事件的情感分析,具有一定的研究意義。
2 本文工作
為更好地對社交媒體輿情事件的評論實現情感分析,本文提出一種改進LDA-CNNBiLSTM模型,通過融合LDA模型和情感詞典實現特征提取,再構建CNN-BiLSTM模型完成情感分類,預測輿情事件的情感態勢。
2.1 模型總體框架
本文提出一種改進LDA和CNN-BiLSTM的情感分類模型,其總體框架如圖1所示。具體實現過程如下:
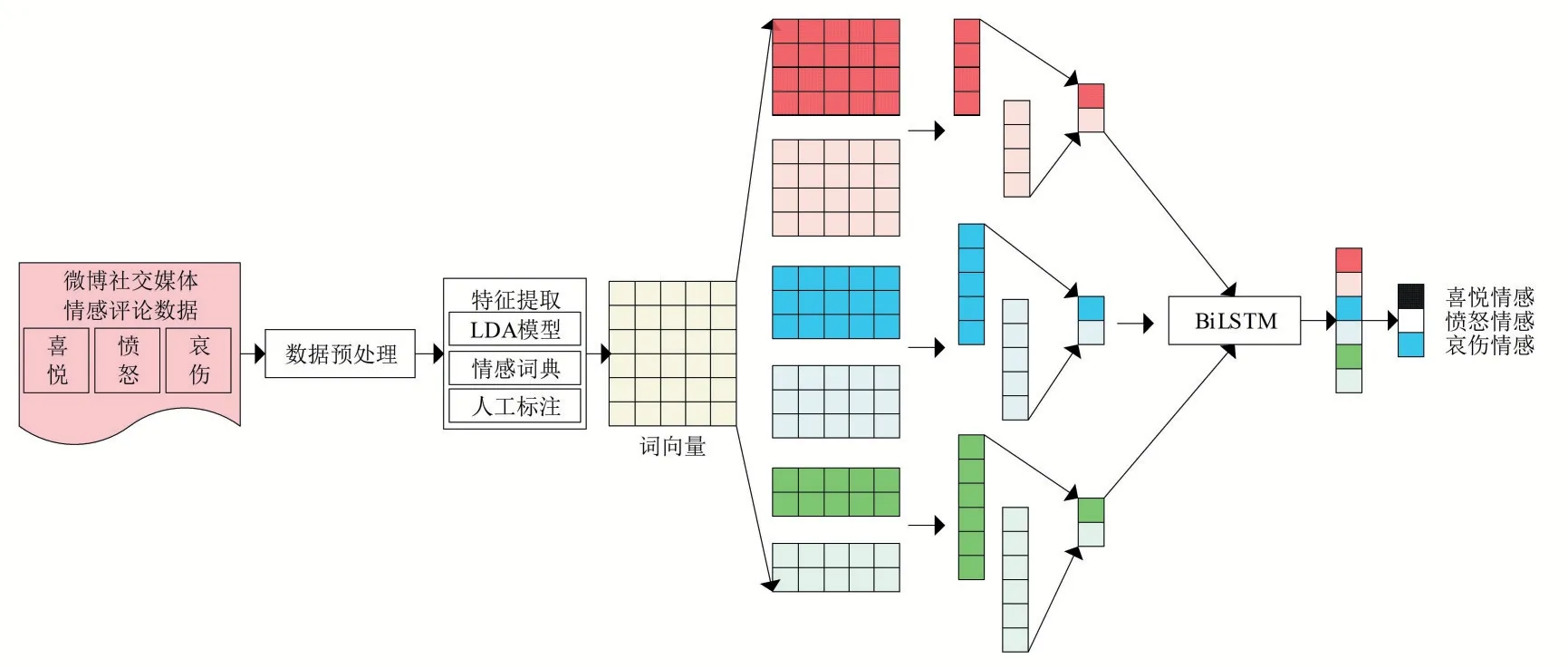
圖1 改進LDA-CNN-BiLSTM模型框架
(1)通過Python和Xpath技術自定義網絡爬蟲,采集微博社交媒體輿情事件的評論信息,包括“喜悅”“憤怒”和“哀傷”三種類別的情感,并存儲至本地CSV文件中。
(2)對評論文本進行數據預處理,包括Jieba中文分詞、停用詞過濾、特殊字符刪除、重復評論刪除、評論標注等。
(3)構建融合LDA模型、情感詞典和人工標注的模型并用于情感特征詞提取,使用Word2Vec將經過特征提取后的情感文本轉換為詞向量,并用作后續深度學習模型的輸入層。
(4)構建CNN-BiLSTM模型,利用卷積神經網絡提取文本的關鍵特征,長短時記憶網絡捕獲長距離語義特征,最終經過Softmax分類器計算社交媒體輿情事件評論的情感傾向,完成情感分類任務。輸出結果分別對應“喜悅”“憤怒”和“哀傷”三種情感。
2.2 特征提取
本文提出一種融合LDA模型和情感詞典的特征提取方法。其具體的實現過程如下:
(1)通過LDA模型提取不同評論文本的情感特征詞。LDA模型是2003年由Blei等提出的主題模型,常用于文本分類和文本挖掘任務,它可以將文檔集的主題以概率分布的形式給出,從而抽取出不同主題的分布情況,更好地完成融合主題的分類或聚類任務。本文將微博社交媒體不同輿情事件的評論劃分為三類主題,分別對應“喜悅”“憤怒”和“哀傷”三個類別,并利用LDA模型提取對應的主題特征詞。
(2)利用大連理工大學情感詞匯本體庫進行特征提取,將其劃分為7個大類和21個小類,即“樂”“好”“怒”“懼”“哀”“惡”“驚”。同時,結合情感特征詞的詞頻統計和人工標注構建針對微博社交媒體的情感詞庫。
(3)由該情感詞庫完成特征提取任務。該操作能抽取出不同評論帶有情感色彩的高質量特征詞,為后續深度學習模型實現情感分類任務提供支撐。
2.3 CNN模型
卷積神經網絡(Convolutional Neural Network,CNN)主要由卷積層和池化層組成,本文構建三層卷積神經網絡提取輿情事件評論文本的關鍵特征。其中,卷積層將接收n×d的情感特征詞矩陣,卷積過程如公式(1)所示。
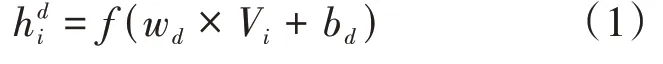
式中,f表示激活函數,通常采用ReLu(rectified linear units)函數加快訓練收斂速度;hi表示微博社交媒體評論詞向量卷積處理后的特征;w表示大小為d的卷積核;V表示輸入層的詞向量;b表示偏置項。通過該卷積操作能有效生成局部特征集合,如公式(2)所示。

池化層可以壓縮文本特征向量和模型參數的大小,并且最大化保留情感特征特性,其計算公式如(3)所示。

本文通過構建卷積核分別為2、3、4的過濾器來提取微博評論文本的關鍵特征,接著將其輸出向量輸入至BiLSTM模型。
2.4 Bi LSTM模型
雙向長短時記憶網絡(Bi-directional long short-term memory,BiLSTM)模型是循環神經網絡的變體,它從前后兩個方向提取特征,從而捕獲長距離依賴關系及上下文語義特征,本文用來提取輿情事件評論的情感特征。
BiLSTM模型的網絡結構如圖2所示,通過狀態的傳遞來增強主體信息,從而有效捕獲如“喜歡”與“哈哈”、“難受”與“祈禱”等情感特征詞,其計算公式如(4)—(6)所示。
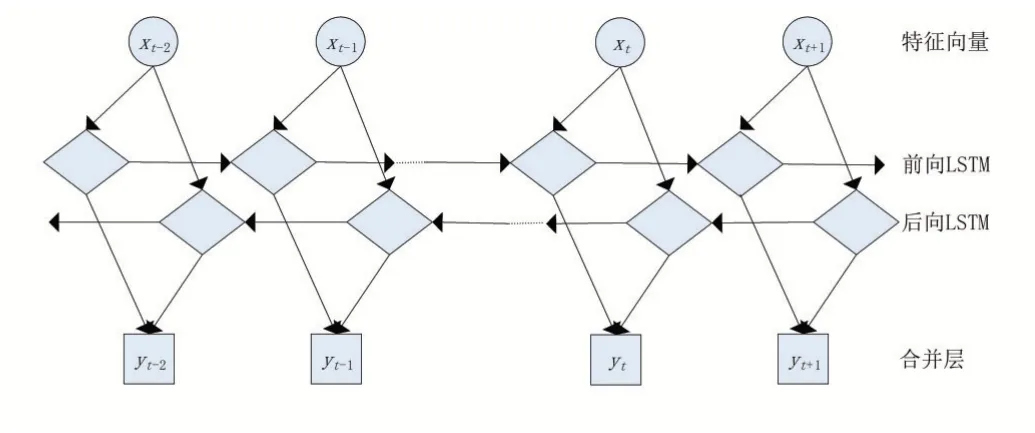
圖2 BiLSTM模型網絡結構

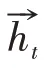
3 實驗分析
本文實驗在Windows環境下完成,利用Python和Xpath技術采集微博社交媒體評論數據集,并按照“喜悅”“憤怒”和“哀傷”三種情感進行標注。接著通過TensorFlow和Keras構建深度學習模型,其GPU為GTX 1080Ti,處理器為Inter(R)Core i7-8700K,編程環境為Anaconda,編程語言為Python 3.6。
3.1 實驗數據和評價指標
本文實驗數據是通過Python和Xpath技術構建網絡爬蟲采集微博各輿情事件的評論數據,經過數據清洗和預處理后形成20萬條帶有情感色彩的數據集,數據集包括“喜悅”“憤怒”和“哀傷”三種情感,并隨機劃分為訓練集、測試集和驗證集,其數據分布情況如表1所示。
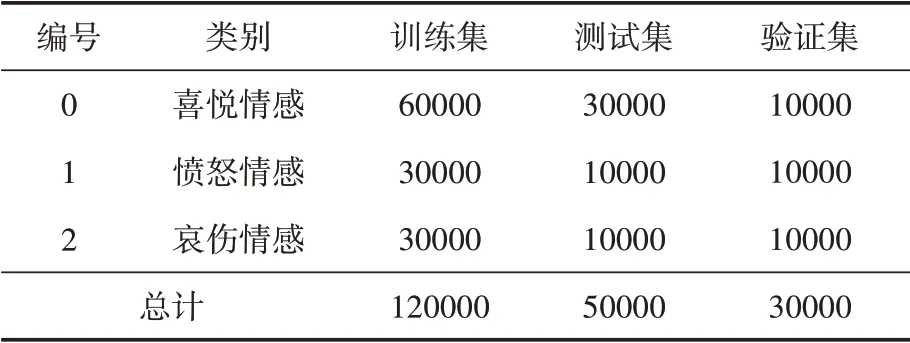
表1 社交媒體評論數據集
針對微博社交媒體評論的情感分析,本文采用精確率(Precision)、召回率(Recall)、F值(F-score)和準確率(Accuracy)進行實驗評價,其計算過程如公式(7)—(10)所示。

其中,精確率用于評估情感分類被正確預測為指定類別占所預測類別評論數量的百分比,召回率用于評估情感分類被正確預測占該類別情感評論數量的百分比,F值綜合了精確率和召回率,是兩者的加權調和平均值,常與準確率用于評估模型的質量。
3.2 基于LDA模型和情感詞典的特征提取實驗
本文利用LDA模型和情感詞典對微博社交媒體的輿情事件評論進行特征提取,其LDA主題模型的n_topic設置為3,分別對應“喜悅”“憤怒”和“哀傷”三類情感,情感詞典選擇大連理工大學情感詞匯本體庫。通過該操作能有效過濾不必要的噪聲特征詞干擾,同時經過處理后特征詞將更具有情感色彩,為后續CNNBiLSTM模型的情感分類提供良好的支撐。具體過程如下:
(1)通過中文分詞和數據清洗(含停用詞過濾和特殊字符清洗)提取只保留具有語義價值信息的特征詞。
(2)利用LDA模型提取“喜悅”“憤怒”和“哀傷”三類主題的情感特征詞,并結合大連理工大學情感詞匯本體庫和人工標注將不同評論的情感特征詞進行權重加成。
(3)經過上述步驟生成對應的微博社交媒體情感詞庫,其中“喜悅”情感特征詞的詞云分布如圖3所示,“憤怒”情感特征詞的詞云分布如圖4所示,“哀傷”情感特征詞的詞云分布如圖5所示。

圖3 經特征提取的“喜悅”類別情感特征詞

圖4 經特征提取的“憤怒”類別情感特征詞

圖5 經特征提取的“哀傷”類別情感特征詞
(4)經過情感特征提取,將其輸入CNNBiLSTM模型,并完成最終的情感分類實驗。
本文通過構建改進的LDA-CNN-BiLSTM模型,完成社交媒體情感分析任務。其中,圖3顯示了“喜悅”類別的關鍵情感特征詞,包括“哈哈”“喜歡”“可愛”“快樂”“開心”“完美”等。
圖4顯示了“憤怒”類別的關鍵情感特征詞,包括“沒有”“問題”“死亡”“真實”“可憐”“嚴重”“憤怒”等,同時包括網絡術語,比如“TMD”“呵呵”“受不了”等,這些特征詞有效體現了大眾對輿情事件的憤怒情緒,并且經過基于LDA模型和情感詞典的特征提取能有效增強情感分類的結果。
圖5顯示了“哀傷”類別的關鍵情感特征詞,包括“可憐”“祈禱”“遇難”“默哀”“祝福”“可惜”等。
3.3 社交媒體情感分析實驗分析
經過基于LDA模型和情感詞典的特征提取后,本文構建CNN-BiLSTM模型并實現社交媒體情感分析實驗。該模型的超參數如表2所示,并且增加Dropout層防止出現過擬合現象。為避免某次異常實驗結果的影響,整個實驗結果為十次實驗結果的平均值。

表2 模型超參數設置
本文提出一種改進LDA-CNN-BiLSTM的方法,并進行了詳細的對比實驗,其實驗結果如表3所示,分別與經典的機器學習模型(包括邏輯回歸、SVM、隨機森林、KNN、樸素貝葉斯、AdaBoost)和深度學習模型(包括LSTM、BiLSTM、GRU、BiGRU、CNN、TextCNN)進行對比。
由表3可知,本文方法的精確率為0.8946,召回率為0.8841,F1值為0.8893,準確率為0.8778,整個實驗結果均優于現有的機器學習和深度學習模型。通過對比本文方法與其他方法的F值(F-score)變化趨勢,可以發現本文方法比邏輯回歸、SVM、隨機森林、KNN、樸素貝葉 斯、AdaBoost分 別 提 高0.1878、0.1939、0.1902、0.2671、0.1419和0.2194,比LSTM、BiLSTM、GRU、BiGRU、CNN、TextCNN分 別 提 高0.0795、0.0489、0.0858、0.0572、0.0491和0.0394。通過對比本文方法與其他方法的準確率(Accuracy)變化趨勢,可以看到本文的方法比邏輯回歸、SVM、隨機森林、KNN、樸素貝葉斯、AdaBoost分 別 提 高0.1747、0.1789、0.1937、0.2597、0.1477和0.2092,比LSTM、BiLSTM、GRU、Bi-GRU、CNN、TextCNN分別提高0.0769、0.0382、0.0855、0.0564、0.0530和0.0459。
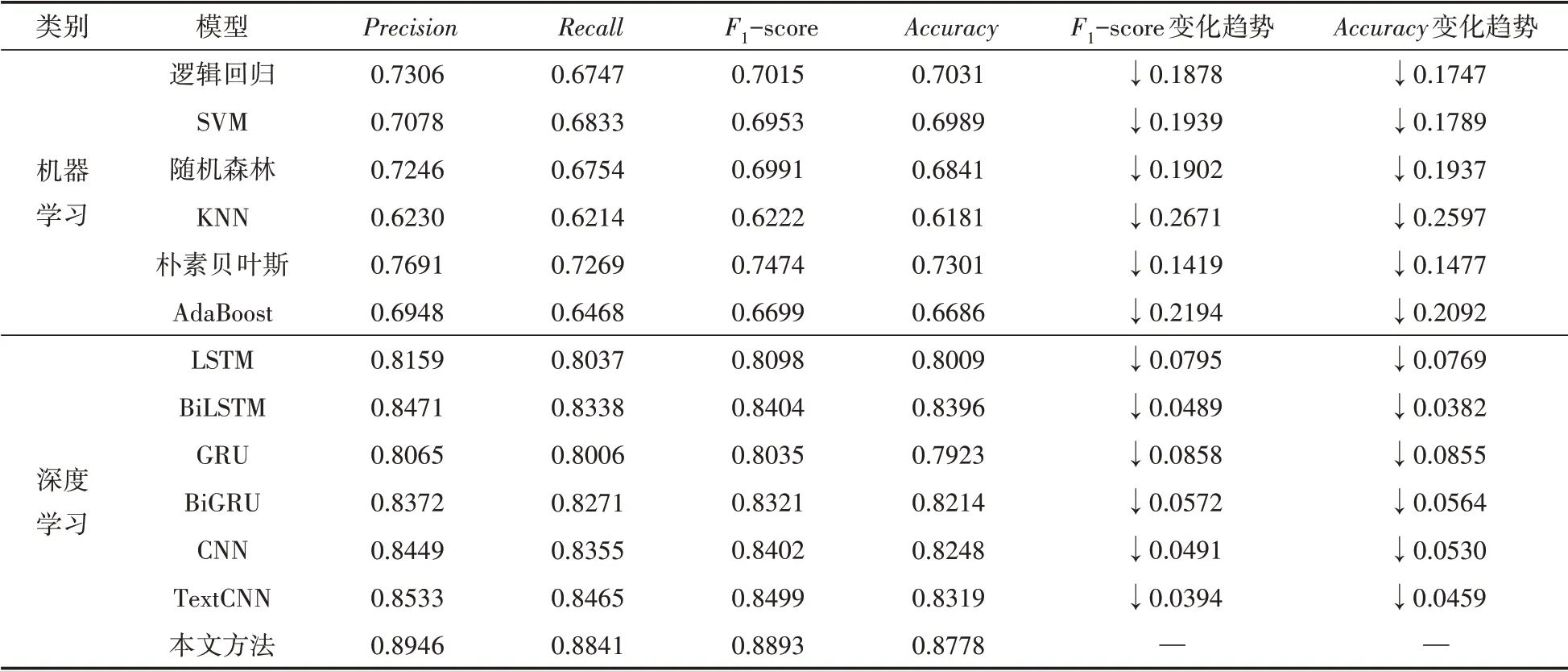
表3 各模型情感分類實驗結果對比
同時,本文對三種情感進行了對比分析,得出如表4所示的實驗結果。
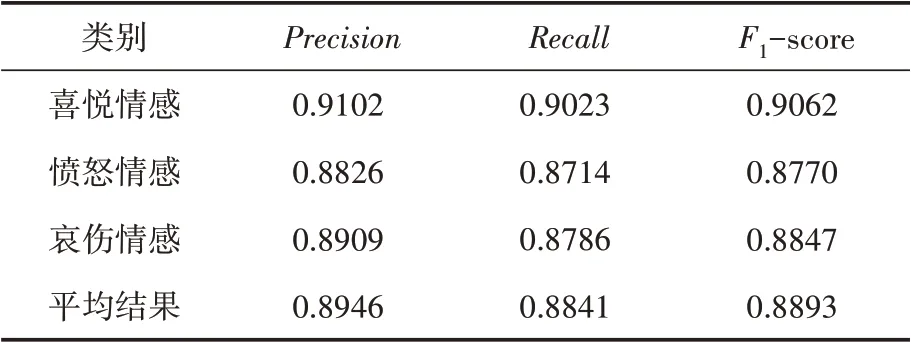
表4 三大類別情感分析實驗結果
由表4可知,“喜悅”情感的精確率、召回率和F值最高,分別為0.9102、0.9023和0.9062,接著是“哀傷”情感和“憤怒”情感。這一方面是因為“喜悅”類型的樣本數量較多,另一方面是“憤怒”和“哀傷”情感特征詞存在部分融合的現象,但該實驗結果仍然有效證明了本文方法的有效性,能高質量對社交媒體的評論信息進行情感趨勢分析,自動化區分出“喜悅”“憤怒”和“哀傷”不同類型的情感。
最后,本文分別對比了不同方法是否使用LDA模型和情感詞典融合的F1值,其機器學習實驗結果如圖6所示,深度學習實驗結果如圖7所示。
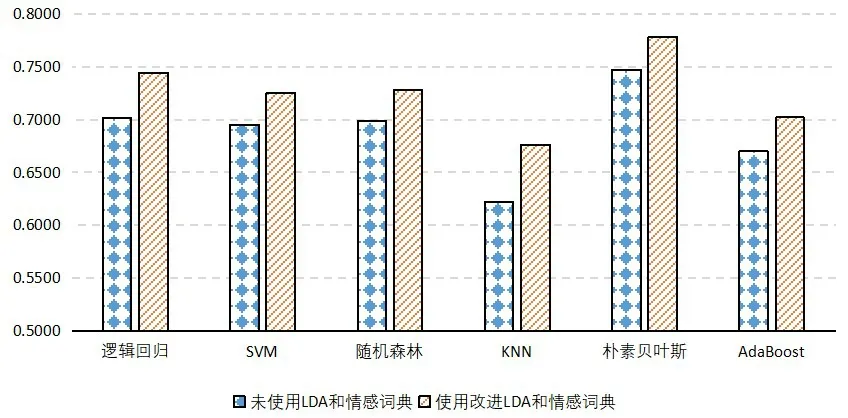
圖6 機器學習使用LDA和情感詞典前后的F1值對比
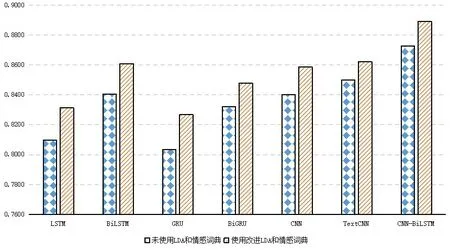
圖7 深度學習使用LDA和情感詞典前后的F1值對比
由圖6和圖7可知,融合改進LDA模型和情感詞典后的方法在社交媒體評論情感分析實驗中的效果更好,六種機器學習模型的F值平均提升3.66%,七種深度學習模型的F值平均提升1.84%。通過該部分實驗充分說明情感特征詞的有效提取能在一定程度上提升分類模型的效果,并能夠充分實現對微博等社交媒體輿情事件的評論進行情感分析,較好地感知大眾情緒,預測情感趨勢。
4 結語
本文針對社交媒體情感分析忽略情感特征的長距離語義關系,無法精確捕獲帶有情感色彩的特征詞,過度依賴人工標注等問題,本文提出一種改進LDA-CNN-BiLSTM模型,旨在實現對微博輿情事件的情感分析研究。實驗通過對微博輿情事件評論文本進行數據采集和數據預處理,獲取“喜悅”“憤怒”和“哀傷”三種類別情感文本。其次,構建融合LDA模型、情感詞典和人工標注的算法并用于情感特征詞提取,使用Word2Vec將經過特征提取后的情感文本轉換為詞向量。最后,構建CNN-BiLSTM模型,利用卷積神經網絡提取文本的關鍵特征,長短時記憶網絡捕獲長距離語義特征,從而完成情感分類任務。
實驗結果表明,本文方法的精確率、召回率、F1值和準確率分別為0.8946、0.8841、0.8893和0.8778,整體實驗結果均優于現有的機器學習和深度學習模型,并且融合LDA模型和情感詞典的實驗結果均有明顯提升,其F1值比實驗中的六種機器學習模型平均提升3.66%,比七種深度學習模型平均提升1.84%。綜上,本文方法能夠應用于社交媒體的情感分析任務,并有效感知輿情事件的情感態勢,具有一定的研究價值。
猜你喜歡
中國生殖健康(2020年5期)2021-01-18 02:59:48
北極光(2019年12期)2020-01-18 06:22:10
小太陽畫報(2019年10期)2019-11-04 02:57:59
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2019年15期)2019-08-27 01:12:00
電子制作(2018年18期)2018-11-14 01:48:06
中國生殖健康(2018年5期)2018-11-06 07:15:40
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
小學教學參考(2015年20期)2016-01-15 08:44:38
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
