農業類大數據分類預測算法研究*
2022-04-07 03:42:28葉煜李敏文燕
計算機與數字工程 2022年3期
葉 煜 李 敏 文 燕
(成都農業科技職業學院信息技術分院 成都 611130)
1 引言
我國是一個傳統農業大國。隨著科技的發展,我國農業進入了一個新時期。一系列的農業生產、管理和經營,產生大量的農業數據。農業從業者與農業相關部門需要各種有意義的農業信息指導農業決策。如何很好地利用這些數據,引導農業生產、管理和經營,需要對數據進行深度分析。數據分類是大數據分析的關鍵內容。這些農業數據往往帶有大量不確定性的、不完整的、有噪聲的以及冗雜的信息[1],從這些冗雜的數據信息中發現有價值的信息,找到它們的內在規律,建立能盡可能反映事物實際特征的模型,使數據分類更易與先驗知識融合以適應大數據處理要求,是近年來數據分類預測算法研究的熱點。目前,基于神經網絡的分類算法應用于對農業數據進行自動分類是一個行之有效的方法。例如,BP 神經網絡、支持向量機、廣義神經網絡等[2~10]。但神經網絡往往存在收斂速度慢、訓練時間長、對冗雜的農業數據分類精度低等問題[11~12]。因此,找到一種訓練時間短、快速且準確獲得最優解的分類算法是研究的重點。本文在分析了極限學習機及遺傳算法基礎之上提出了基于遺傳算法的極限學習機,能較好地提高數據分類精度且具有良好的泛化性能。
2 極限學習機
極限學習機(Extreme Learning Machine,ELM)是一類基于前饋神經網絡構建的機器學習系統或方法[13]。在訓練階段,與單隱層前饋神經網絡基于梯度算法不同的是,極限學習機采用隨機或人為設定輸入層權重和偏差,之后不需要更新,學習過程僅計算輸出權重。當所有節點都得到相應的權重和偏差,就完成極限學習機的訓練。單隱層前饋神經網絡由輸入層、隱含層和輸出層組成,如圖1 所示:
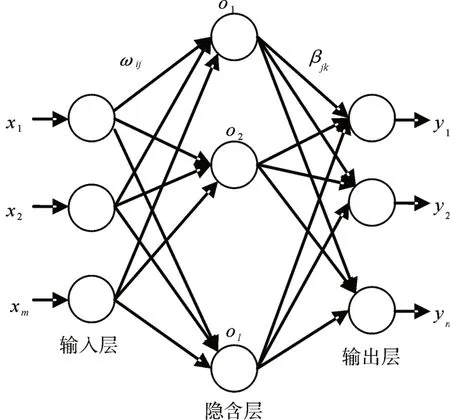
圖1 單隱層前饋神經網絡
對于單隱層神經網絡,ELM可以隨機初始化輸入權重和偏差并得到相應的輸出權重。假設單隱層神經網絡有N 個任意的樣本{Xi,ti|Xi=[xi1,xi2,…,xin]T∈Rn,ti=[ti1,ti2,…,tim]T∈Rm}。若隱含層有n 個節點,激活函數為g(x),輸入權重Wi=[wi,1,wi,2,…,wi,n]T,輸出權重βi,設bi為第i 個隱層單元的偏置。那么有l個隱層節點的單隱層神經網絡可以表示為
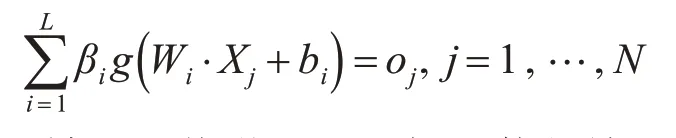
單隱層神經網絡學習的目標是使得輸出的誤差最小,則存在βi,Wi和bi,使得
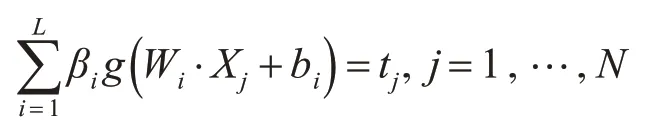
隱層節點的輸出為H:
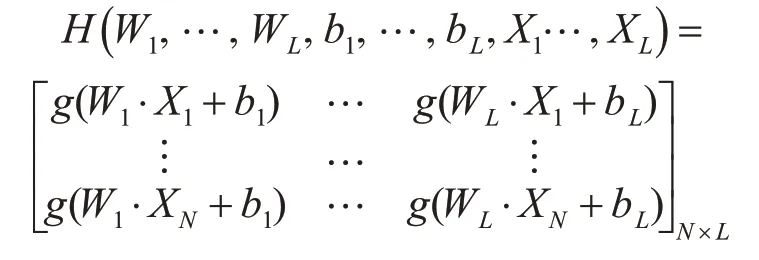
隱層1個節點與輸出層之的輸出權重為β:
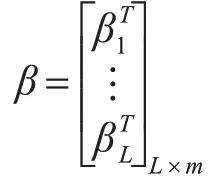
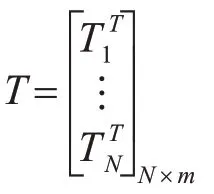
訓練集的目標矩陣T:
上述可以矩陣表示為Hβ=T。ELM 算法的輸入權重Wi和隱層偏差bi確定了,隱層的輸出矩陣H也就唯一確定。訓練單隱層神經網絡可以轉化為求解一個線性系統Hβ=T。于是輸出權重β可以被確定:β?=H+T(H+是矩陣H 的Moore-Penrose 廣義逆)。
3 遺傳算法
遺傳算法是模擬達爾文生物進化論的自然選擇和遺傳學機理的生物進化過程的計算模型,是一種基于“適者生存”的高度并行、隨機和自適應的優化算法,通過復制、交叉、變異將問題解編碼表示的“染色體”群一代一代不斷進化,最終收斂到最適應的群體,從而求得問題最優解的方法[14~15]。遺傳算法的工作過程如下:
1)初始化。首先隨機生成一組可行解,即第一代染色體。
2)適應度函數。然后適應度函數計算每一條染色體的適應程度,根據適應程度進一步計算每一條染色體在下一次進化中選中的概率。
3)遺傳算子。遺傳算法有三類遺傳算子:選擇、交叉、變異。選擇算子負責選擇出交叉時所要使用的父母染色體,將它們傳到下一代群體中。常用選擇算子有輪盤選擇、錦標賽選擇和排名選擇。交叉算子對兩個相互配對的染色體依據交叉概率按某種方式相互交換其部分基因,從而形成兩個新的個體。基本的遺傳算法采用單點交叉。變異算子模仿自然界變異現象,依據變異概率改變個體編碼串中的某些基因值,從而形成一個新的個體,以保持個體多樣性。
遺傳算法工作流程圖如圖2。
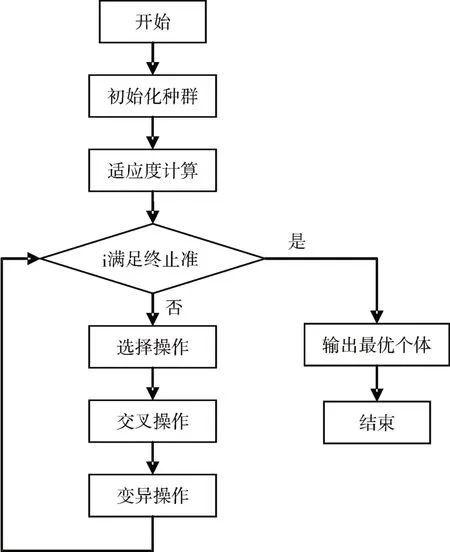
圖2 遺傳算法工作流程
4 極限學習機的優化
極限學習機(ELM)隨機生成輸入層權值和隱含層閾值,致使網絡不穩定。為提高極限學習機在農業數據上的分類精度,利用遺傳算法(GA)對極限學習機進行優化,將遺傳算法的全局最優搜索能力和極限學習機的強學習能力結合起來。算法將極限學習機輸入層權值和隱含層閾值映射為遺傳算法種群中每個染色體上的基因,染色體適應度對應于極限學習機的分類精度。在遺傳算法每次迭代過程中,從通過了選擇、交叉、變異的子代種群里,選擇最優染色體從而獲得優化的極限學習機輸入權值和閾值。提高網絡穩定性,降低分類的誤差。
基于遺傳算法的極限學習機(GA-ELM)工作過程如下:
1)種群初始化。設輸入層的神經元m,隱含層的神經元n,初始化種群為X,染色體數量為N,每個染色體xi,都包括m.n 個輸入權值和n 個閾值。初代種群可以表示為

其中,aij為輸入層權值;bhk為隱含層閾值。
2)適應度函數。利用極限學習機對學習樣本的分類預測輸出誤差作為適應度函數,計算初代種群中個體的適應度參數。
3)選擇染色體。在對初代種群進行選擇、交叉、變異等操作之后,選擇適應度大的個體形成新和種群。循環往復、依次迭代,每進化一次,計算適應度,保留適應度最好的染色體,當達到預先設定的遺傳代數,選擇出適應度最高的染色體,并以此作為極限機最優輸入權值和隱層閾值,從而獲得最佳網絡結構。
5 結語
算法采用UCI 中的Iris 和Wine 數據集進行測試,選擇的Iris 數據集包含4 個特征,3 個類別,150個樣本,Wine 數據集包含13 個特征,3 個類別,178個樣本。遺傳算法進化迭代次數設為50,交叉概率0.4,變異概率0.1,種群規模為40。經過10 次測試取平均值,ELM 在Iris 數據集上的分類精度為93.43%;GA-ELM 在Iris 數據集上的分類精度為95.62%;ELM 在Wine 數據集上的分類精度為60.15%;GA-ELM 在Wine 數據集上的分類精度為81.38%。可以看到,基于遺傳算法的極限學習機在樣本特征較少時分類精度提升較小,但在樣本特征較多時,分類精度提高幅度很大,非常適合于特征點較多的農業類數據的分類預測。基于遺傳算法的極限學習機可以很好地提高農業數據分類性能,有利于促進農業信息化的發展。
猜你喜歡
今日農業(2022年1期)2022-11-16 21:20:05
今日農業(2022年3期)2022-11-16 13:13:50
今日農業(2022年2期)2022-11-16 12:29:47
今日農業(2021年14期)2021-11-25 23:57:29
今日農業(2021年13期)2021-08-14 01:38:18
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
今日農業(2020年15期)2020-12-15 10:16:11
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
