手機游戲消費潛在現象的預測
2022-03-25 16:27:01朱文瑞
中國市場 2022年5期




摘 要:文章利用了人工神經網絡模型,通過被調查者的基本信息、手游時長、消費態度等方面,預測被調查者是否存在長期消費的現象,以期更容易辨認出氪金玩家與平民玩家,使得開發者的宣傳以及策劃更具有目的性和有效性。
關鍵詞:長期消費行為;手機游戲消費;人工網絡模型
中圖分類號:F49 文獻標識碼:A 文章編號:1005-6432(2022)05-0123-02
DOI:10.13939/j.cnki.zgsc.2022.05.123
1 引言
如今的社會中,科技迅速發展,手機也變成人手一個的生活必需品,網上支付的便捷性和安全性也使手機從20年前的聯系工具,變成了人們移動的錢包。對于公司而言,能從龐大的玩家群體尋找出未來可能存在長期消費行為的人群,會使其策劃、宣傳的過程中的對象更加集中,對于手游公司來說百利而無一害。宋子健等[1]通過構建二元Logistic回歸模型消費者的游戲意愿和消費意愿進行實證分析得到“年齡”“平均每天游戲時長”“接觸手機游戲時間”對消費者的消費意愿均起到正向作用這一結論。洪晶[2]考慮通過神經網絡算法預測出每一位客戶最終所屬的消費模式類別,能夠幫助客戶服務人員按照每一類客戶群體消費行為的特點提供相應的服務和采取針對性的營銷策略。本文采取人工神經網絡模型,通過玩家的基本信息、游戲時長等方面對玩家是否存在長期消費行為進行預測,使得游戲開發商能夠針對不同的玩家采取不同的策劃宣傳方式。
2 理論概述
人工神經網絡,就是人們利用計算機模仿生物的神經網絡,解決信息分類處理的模型[2]。神經元大致可以分為樹突、突觸、細胞體和軸突。神經元在神經系統中,起著接收信息、傳遞信息、處理信息的作用。而人工神經網絡,將輸入數據看成是接收信息,而激活函數則是神經元處理信息的能力,輸出數據則是經過神經元多層處理傳出的信息。經過一層層神經元的處理之后,便可以由原始的輸入數據得到對應的輸出數據。由于迭代的次數,神經元的層數比較多,相比于大多回歸模型,預測精度可能會更高,擬合效果會更好。
本文經過多層神經元處理所得到的神經網絡模型:
其中的g(i),i=1,2,3,…,n指的是每一層的激活函數,在每一層中神經元處理數據所遵循的函數。而b(i),i=1,2,3,…,n代表了每一層的閾值,在生物神經元中,只有足量的信息輸入神經元后,達到一定的閾值之后,神經元才會向下一層神經元傳遞信息,這里用bi表示第i層的閾值。W(i),i=1,2,3,…,n指的是每一層神經元中的權重,用來說明每一層對應分量的影響程度。上述模型,就是模擬了輸入數據經過一層層神經元激活函數的作用后,輸出對應y的過程。
3 變量選取
本文中所研究的問題存在12個自變量,所以設X=(x1,x2,…,x12)為輸入數據,而調查中所得到的數據中存在缺失的問題,倘若學生并沒有進行過手機游戲的消費行為,那么手機的消費體驗以及更傾向的消費模式的數據就會缺失,設計問卷時,有意將y=0看作是玩家無消費行為。因此,筆者將缺失的部分數據用0進行對應的補齊。輸入數據X包括性別、收入、游戲時間、手機內游戲數量、最近所玩游戲的游戲時長,以及對于游戲品質、社交系統等屬性偏好,共12方面,通過被調查者的選擇,預測被調查者是否大概率存在消費狀況。
y為問題中的輸出數據,由于筆者感興趣的是消費玩家的是否存在長期穩定的消費行為,所以如果玩家存在氪金的情況,筆者設y=1,若玩家不氪金,設y=0,相當于筆者將其看成了一個二分類的問題。由于數據本身并非如上的表示方法,所以筆者對數據y進行了一定的處理,方便后續模型的建立。
4 模型的建立
由于解釋變量X存在12個分量,所以在設計第一層神經元時,遵從規律,設計約為變量個數的百分之七十五,第一層的神經元個數設置約為8個。在構建模型之時,所選用的激活函數是“relu”函數:
相比于其他函數,經過測試發現,“relu”函數的迭代次數更少,并且更快地達到了所需要的精度。由于問題最后的輸出數據為二分類型,為了能更好地映射到0,1上面,輸出層的激活函數使用“sigmoid”,公式如下所示:
通過以上兩種形式激活函數,便可以將輸入數據進行有效的分類,使得最后的輸出數據對應想得到的0,1。
為了驗證模型的準確性,將數據集分為三個部分,從理論上說,訓練集、測試集、驗證集的比例為8∶1∶1,根據所得到的數據數量共792組,將其分為訓練集634組,測試集79組,驗證集79組。首先,利用634組訓練集的數據,對神經網絡模型進行訓練構建好模型,利用測試集的數據,對模型的擬合度等進行測試。
在本文中,筆者利用loss函數,以及模型的精度,對模型進行檢驗。所采取的loss函數是可以度量預測值與實際值之間的差異的二分類交叉熵公式:
筆者先分別在訓練集、測試集中計算其loss函數。訓練集中損失函數的值越大,說明訓練集中預測的差異與真實情況越大,驗證集中的損失函數同理。
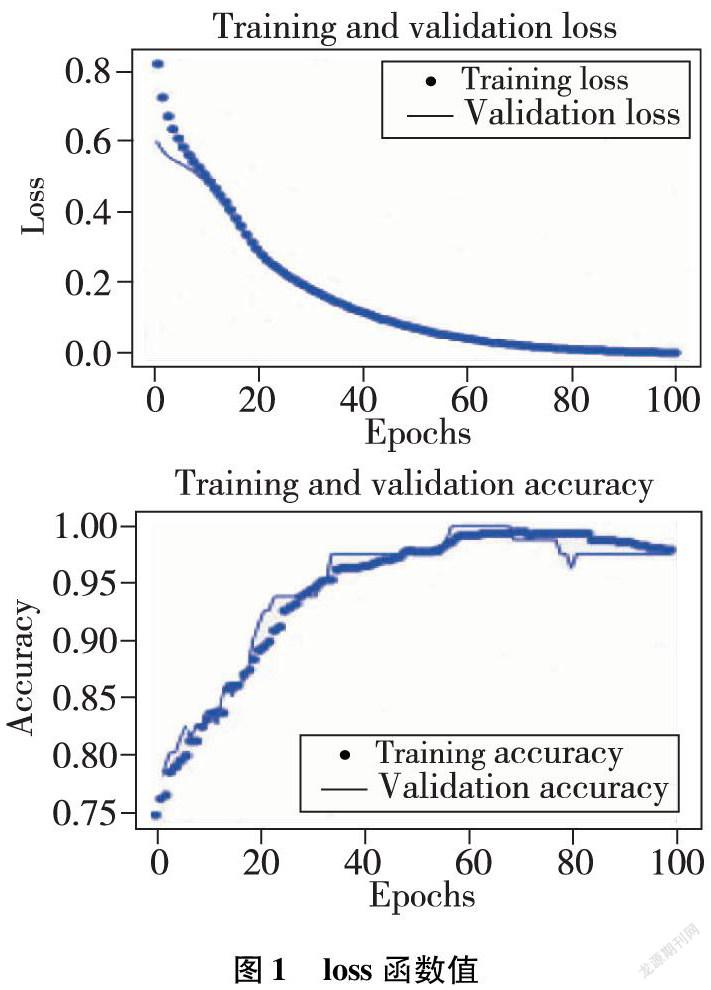
如圖1的上方圖所示,點集代表訓練集的loss函數值,線條代表驗證集的loss函數值。隨著迭代次數的增加,兩者都在逐步減小,可見迭代的次數增加,模型的預測效果會更好。當訓練集和測試集的loss函數值在迭代了20次時,兩者接近重合,可見其擬合的效果。最為重要的是,隨著迭代的次數增加到80次后時,訓練集和驗證集的loss函數值已經無限的趨近于0,可見在兩者中,模型的預測值與真實值的差異逐步減少,甚至是消失。如圖1的下方圖所示,就算是迭代的次數不超過20,訓練集所訓練的模型的精度也高達0.6,而隨著迭代的次數逐步增加,在迭代次數達到40時,不管是訓練集,還是驗證集,產生的模型精度都高達0.9以上。筆者為了測試模型的精度,繪制訓練集與測試集的精度圖。為了確保模型的準確性,利用測試集對模型進行了同樣的測試,結果如圖2所示。
如圖2所示,當迭代次數足夠時,測試集的loss函數足夠小,精度也同樣足夠高,所以可以說本文所提到的模型通過了檢驗。也可以根據測試集的數量,將數據分為10組,每組79份,每組都進行精度的計算,得出精度分別為0.9744、0.9465、0.9487、0.8077、0.8846、0.8846、0.9872、0.9615、0.6538、0.6538,算出其平均值約為0.8703,在多次訓練的模型精度的平均水平達到了0.8703,可見相比于logistic回歸模型,神經網絡的模型預測的能力之強,結果之準確。除已有的數據外,又收取了10份問卷,將其數據處理之后,代入到已經訓練好的模型中,發現在迭代多次后,最多只會出現一次錯誤,大多數情況甚至沒有出現預測錯誤的情況。
5 結論
倘若對數據使用Logistic回歸模型,預測的正確率只有60%左右,神經網絡的精度高達90%,其預測的效果有著極大差距。神經網絡模型所訓練出的模型,其精度較高,預測出錯的概率在迭代次數較高時,非常低,利用神經網絡構建的模型,可以通過玩家的一些基本信息,平時游戲的時長,還有其對于游戲內一些消費內容的偏好性,很好地預測玩家是否存在消費行為。玩家如果經過神經網絡的檢測之后,輸出的數據為1時,可以認定玩家存在著長期的、穩定的手機游戲消費行為,是未來游戲盈利的主要對象,可以針對其游戲偏好設置一些更新內容,道具,促使消費;當輸出結果為0時,玩家被認定為平民玩家,消費的潛在可能性較低,在策劃運營過程可以不用太過于迎合其心理需求。綜上而言,本文所得出的神經網絡模型,可以有效且高精度地判斷學生是否為一個有著長期穩定消費行為的群體,可以方便游戲開發商針對這些長期穩定的消費群體做出合理的游戲運營策略。
參考文獻:
[1]宋子健,陳家樂,趙家悅.手機游戲廣告對消費者游戲意愿和消費意愿的影響因素:基于Logistics回歸和SEM模型[J].現代經濟信息,2019(13):129-131.
[2]洪晶. 聚類和神經網絡算法研究及其在電信業客戶消費模式中的應用[D].景德鎮:景德鎮陶瓷學院,2007.
[作者簡介]朱文瑞,男,漢族,江西南昌人,研究生學歷,研究方向:數理統計。
