基于卷積孿生神經(jīng)網(wǎng)絡的滾動軸承故障定位方法*
2022-03-23 09:16:44常東潤孫習習
機電工程 2022年3期
劉 岱,常東潤,孫習習,陳 斌
(1.中國民航大學 安全科學與工程學院,天津 300300;2.中國民航大學 電子信息與自動化學院,天津 300300)
0 引 言
作為大型機械設備的旋轉部件,滾動軸承被廣泛應用在風力發(fā)電、航空航天、鐵路運輸?shù)阮I域。當軸承發(fā)生故障時,可能會引起機械設備失效,造成經(jīng)濟損失,引發(fā)安全事故。因此,對軸承的故障進行診斷和狀態(tài)監(jiān)測極為重要。
傳統(tǒng)的故障診斷包括3個步驟[1]:信號采集處理、特征信息提取和故障類型辨識。近年來,深度學習算法憑借優(yōu)秀的特征提取和模式辨識能力,在滾動軸承故障診斷領域得到了快速發(fā)展。其中,最為常見的深度學習模型[2]包括卷積神經(jīng)網(wǎng)絡(convolution neural network, CNN)、自編碼器(auto-encoder, AE)和循環(huán)神經(jīng)網(wǎng)絡(recurrent neural network, RNN)等。
近年來,CNN被引入到故障診斷領域,且可以很好地提取出順序數(shù)據(jù)中的有效特征。LECUN Y等人[3]在CNN[4]的基礎上,構建了基于深度學習的LeNet-5模型。LI Chun-lin等人[5]建立了基于時間編碼序列和CNN的故障診斷方法。
自編碼器是由RUMELHART D E[6]提出的一種嘗試將輸入復制到輸出的無監(jiān)督網(wǎng)絡模型。通過改進編碼和解碼兩部分的網(wǎng)絡結構,自編碼器又被發(fā)展為:稀疏自編碼器(sparse auto-encoder, SAE)、堆疊自編碼器(stacked auto-encoder, SDAE)和降噪自編碼器(denoising auto-encoder, DAE)等網(wǎng)絡。
曹浩等人[7]采用堆棧系數(shù)自編碼器,對基于奇異值分解和時域分析方法提取的故障特征進行了優(yōu)化,通過SoftMax分類器實現(xiàn)了對非平穩(wěn)振動信號的特征分類。MAO Wen-tao等人[8]融合了極限學習機高訓練效率和堆疊自編碼器高分類準確率的優(yōu)點,提出了一種基于極限學習機和堆疊自編碼器的軸承故障診斷模型。
1990年Pollack[8]首次提出了循環(huán)神經(jīng)網(wǎng)絡(RNN)。RNN主要利用時間序列之間的關聯(lián)性來提取樣本的特征信息。LIU Han等人[9]提出了一種基于RNN的自動編碼器(auto-encoder,AE)診斷滾動軸承故障。但是,RNN始終存在一個缺陷,即在網(wǎng)絡訓練的反向傳播過程中,RNN容易發(fā)生梯度消失或梯度爆炸[10]。
為了改善RNN的梯度消失問題,研究人員提出了長短期記憶網(wǎng)絡(long short-term memory networks, LSTM)和門控循環(huán)單元網(wǎng)絡(gated recurrent unit networks, GRU)[11]。劉春曉等人[12]基于CNN和RNN的優(yōu)點,搭建了一種時空神經(jīng)網(wǎng)絡,采用深度殘差網(wǎng)絡的并聯(lián)思想,將卷積層和LSTM層并聯(lián)起來,以此作為模型的復合卷積層;同時,選取振動信號的時域和空間域特性作為輸入特征,以提升模型的特征表達能力。
在使用時,上述基于傳統(tǒng)深度神經(jīng)網(wǎng)絡的故障定位方法需要滿足數(shù)據(jù)同分布的要求,一旦負載、轉速或工作設備發(fā)生變化,原有的網(wǎng)絡模型就要重新調整結構和參數(shù)。因此,反復地訓練軸承的數(shù)據(jù)集,必然無法滿足工業(yè)故障診斷便捷性、快速性及準確性的需求。
因此,筆者針對同一設備不同工況及不同設備不同工況下數(shù)據(jù)分布不一致的情況,選用擅長處理樣本相似性度量的孿生網(wǎng)絡[13](Siamese neural network, SNN)作為診斷框架,提出一種基于隨機池化-ELU-孿生卷積神經(jīng)網(wǎng)絡(stochastic pooling ELU-Siamese convolutional neural network, SE-SCNN)的有監(jiān)督學習模型。
1 基于孿生網(wǎng)絡的特征模型
孿生網(wǎng)絡是一種基于權值共享的深度學習算法,在1993年提出后被廣泛用于解決樣本相似性度量的問題。基于孿生網(wǎng)絡的特征度量模型將一對樣本輸入至兩個結構相同、權值共享的子網(wǎng)絡中,通過同一個特征映射函數(shù)得到兩個特征向量,利用歐式距離計算特征向量之間的相關性,從而輸出樣本之間的相似程度。
此處采用孿生網(wǎng)絡作為軸承故障定位的基本框架,即將美國辛辛那提大學智能維護系統(tǒng)中心(IMS center)提供的航空軸承運行數(shù)據(jù),經(jīng)過預處理,與未知工況的其他設備數(shù)據(jù)組成樣本對作為網(wǎng)絡輸入,將提取到的故障信息對映射到低維特征空間中,通過比較特征信息之間的距離確定故障類型,然后借助分類器實現(xiàn)軸承故障定位。
為了避免特征相近的樣本被映射到特征空間的不同位置,孿生網(wǎng)絡的子網(wǎng)之間采用共享權值和損失函數(shù)來減少模型誤差。
基于孿生網(wǎng)絡的特征度量框架如圖1所示。
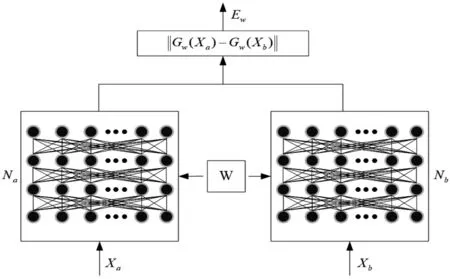
圖1 孿生網(wǎng)絡結構圖
Xa和Xb分別為一對輸入樣本,Na和Nb為兩個完全相同的子網(wǎng)絡,共享權重W;輸入樣本對通過兩個子網(wǎng)絡映射到同一特征空間,分別得到特征向量Gw(Xa)和Gw(Xb);通過計算每一個特征向量對之間的歐氏距離判斷輸入樣本之間的相似度。
具體公式如下:
Ew=‖Gw(Xa)-Gw(Xa)‖
(1)
式中:Ew—特征向量對之間的歐氏距離。
Ew值越小,表示在特征空間中的距離越近,樣本類型相同的概率越大。同時,對于n個訓練樣本來說,基于孿生網(wǎng)絡的深度學習框架可以構建n(n-1)個樣本組合,能夠有效擴充樣本的數(shù)據(jù)量,提高模型的訓練次數(shù),具有很強的魯棒性。
2 基于SE-SCNN的軸承故障定位模型
2.1 SE-CNN模型
滾動軸承的振動信號是非平穩(wěn)非線性的一維時間序列信號,而傳統(tǒng)的CNN具有平移性、縮放不變性,在信號處理方面具有不可比擬的優(yōu)越性。
筆者選取一維CNN作為孿生網(wǎng)絡的子網(wǎng)結構。由于多工況軸承數(shù)據(jù)集具有海量性、復雜性等特點,傳統(tǒng)CNN存在因輸入數(shù)據(jù)分布不一致導致網(wǎng)絡收斂性能不佳的問題;筆者在池化策略和激活函數(shù)方面對一維CNN進行改進,得到改進卷積神經(jīng)網(wǎng)絡:隨機池化-ELU-CNN(stochastic pooling ELU-CNN, SE-CNN)。
在池化策略上,最大池化和平均池化是CNN中最常用的兩種池化方法:(1)最大池化在對特征信息進行運算時,僅考慮池化區(qū)域中最大的元素,忽略了潛在的特征信息;(2)平均池化雖然統(tǒng)籌考慮了所有元素的信息,但過度削弱了核心元素在全局中的作用,特征表達能力有限。
除此之外,對于小樣本的訓練數(shù)據(jù)而言,這兩種池化方法更容易增加網(wǎng)絡過度擬合的風險。因此,為克服最大池化和平均池化的不足,筆者綜合考慮特征元素的全局信息和局部信息,選擇基于正則化算法的Stochastic池化策略,融合池化區(qū)域內每個元素的概率值進行隨機采樣。
(1)首先,對區(qū)域內的所有元素進行標準化處理,計算概率矩陣,具體公式如下:
(2)
式中:pi—激活元素ai的采樣概率;Rj—池化核的位置。
(2)然后,基于概率分布進行采樣,獲得新的特征元素值:
(3)
ReLU是目前深度神經(jīng)網(wǎng)絡中最常用的非負激活函數(shù),有效解決了傳統(tǒng)激活函數(shù)Sigmoid、Tanh等的梯度消失問題,但ReLU函數(shù)自身帶來的均值偏移和神經(jīng)元死亡現(xiàn)象,嚴重影響了深度神經(jīng)網(wǎng)絡的收斂性能。
針對以上問題,筆者選擇ReLU的改進變種函數(shù)ELU作為激活函數(shù)。ELU具有軟飽和性,能夠減輕噪聲對網(wǎng)絡的影響,其具體定義為:
(4)
式中:α—大于0的超參數(shù),負責控制輸入小于零的部分飽和值的大小。
2.2 軸承故障定位模型
針對原始孿生網(wǎng)絡子網(wǎng)結構簡單,導致特征提取性能不佳的問題,筆者在孿生網(wǎng)絡的基礎上,引入SE-CNN作為子網(wǎng)部分,構成一維隨機池化-ELU-孿生卷積神經(jīng)網(wǎng)絡(SE-SCNN)軸承故障定位模型。
變工況下軸承數(shù)據(jù)集分布不同,會導致模型訓練效率不高,因此,筆者將SE-SCNN模型分為兩個階段,即預訓練階段和模型訓練階段;根據(jù)具體性能的不同,每一階段的模型又分為特征提取器和分類器兩部分。
其中,特征提取器為SE-CNN結構,主要利用改進后的CNN提升模型的特征提取性能;分類器部分則采用SoftMax分類,用于對軸承特征距離進行進一步的分類,以實現(xiàn)對軸承故障進行定位。
預訓練網(wǎng)絡作為SE-SCNN模型的子網(wǎng)部分,采用單輸入的SE-CNN網(wǎng)絡,具體結構如圖2所示。
圖2中,網(wǎng)絡主要對模型的特征提取器進行初始的參數(shù)優(yōu)化,以便于后續(xù)SE-SCNN網(wǎng)絡的訓練。
在預訓練階段,已標記的軸承樣本經(jīng)特征提取器映射到特征空間,然后由分類器利用損失函數(shù)將特征信息映射到類別空間,利用最小化預訓練網(wǎng)絡的損失函數(shù)得到SE-SCNN模型的初始化參數(shù),提高了模型的故障定位性能。
SE-SCNN故障定位模型的整體結構如圖3所示。
圖3中,子網(wǎng)部分采用與預訓練網(wǎng)絡相同的結構,均由特征提取器和分類器組成。針對單一損失函數(shù)難以同時滿足模型的特征度量性能和故障定位性能的問題,SE-SCNN模型的關鍵在于采用基于對比損失和分類損失的聯(lián)合損失函數(shù)作為目標函數(shù),各子網(wǎng)之間保持權值共享,分別從變工況軸承數(shù)據(jù)集中接收一對不同的樣本作為模型輸入,通過特征提取器將樣本對中的故障信息映射到特征空間,利用對比損失函數(shù)計算故障特征對之間的相似度。同時,每一個子網(wǎng)又連接至一個獨立的分類器得到輸出類別,通過分類損失函數(shù)衡量模型的分類效果。

圖2 基于SE-SCNN故障定位模型的預訓練網(wǎng)絡
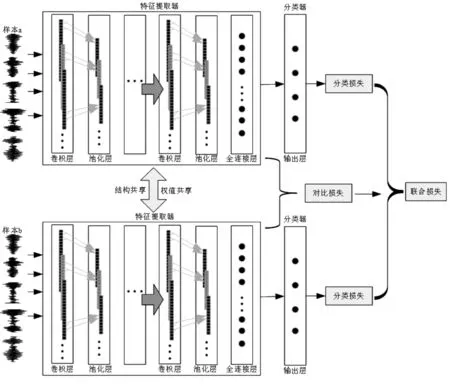
圖3 基于SE-SCNN的故障定位模型
在SE-SCNN故障定位模型的子網(wǎng)結構中,特征提取由輸入層、4個連續(xù)的卷積層和池化層、2個全連接層和1個Batch Normalization層組成,而后把特征向量經(jīng)分類器SoftMax層輸出。
具體SE-SCNN網(wǎng)絡結構參數(shù)如表1所示。
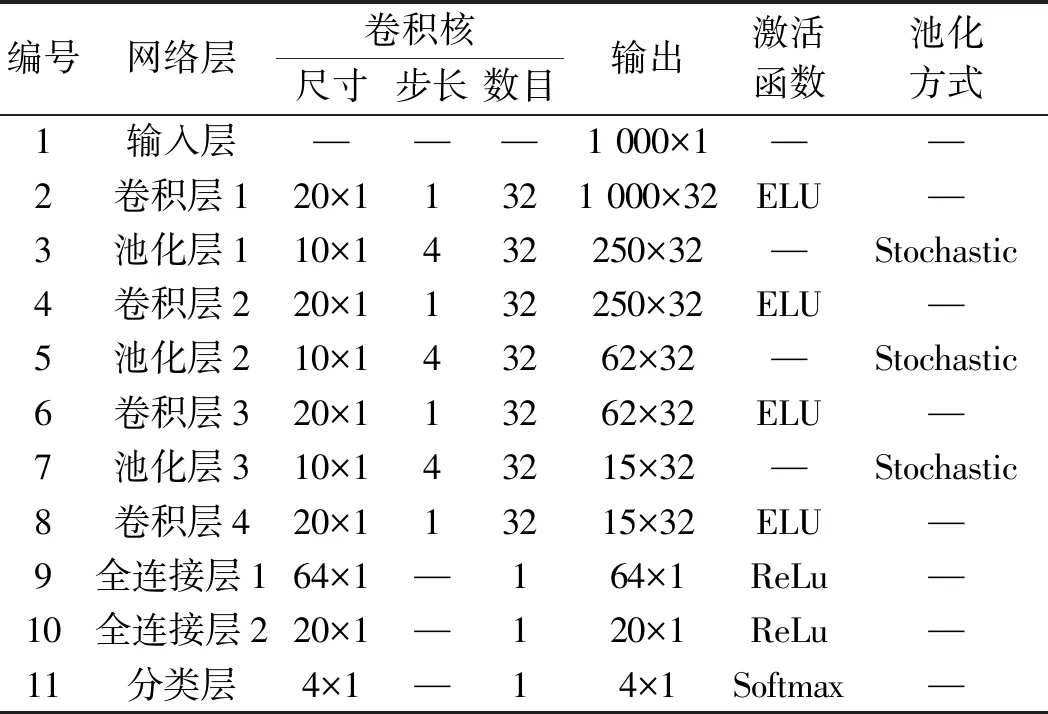
表1 SE-SCNN網(wǎng)絡結構參數(shù)設置
網(wǎng)絡結構中,卷積層和池化層的填充方式均為padding=“same”,以保證輸入輸出之間特征大小不變。
2.3 基于SE-SCNN的軸承故障定位流程
基于SE-SCNN的軸承故障定位方法的整體流程如圖4所示。
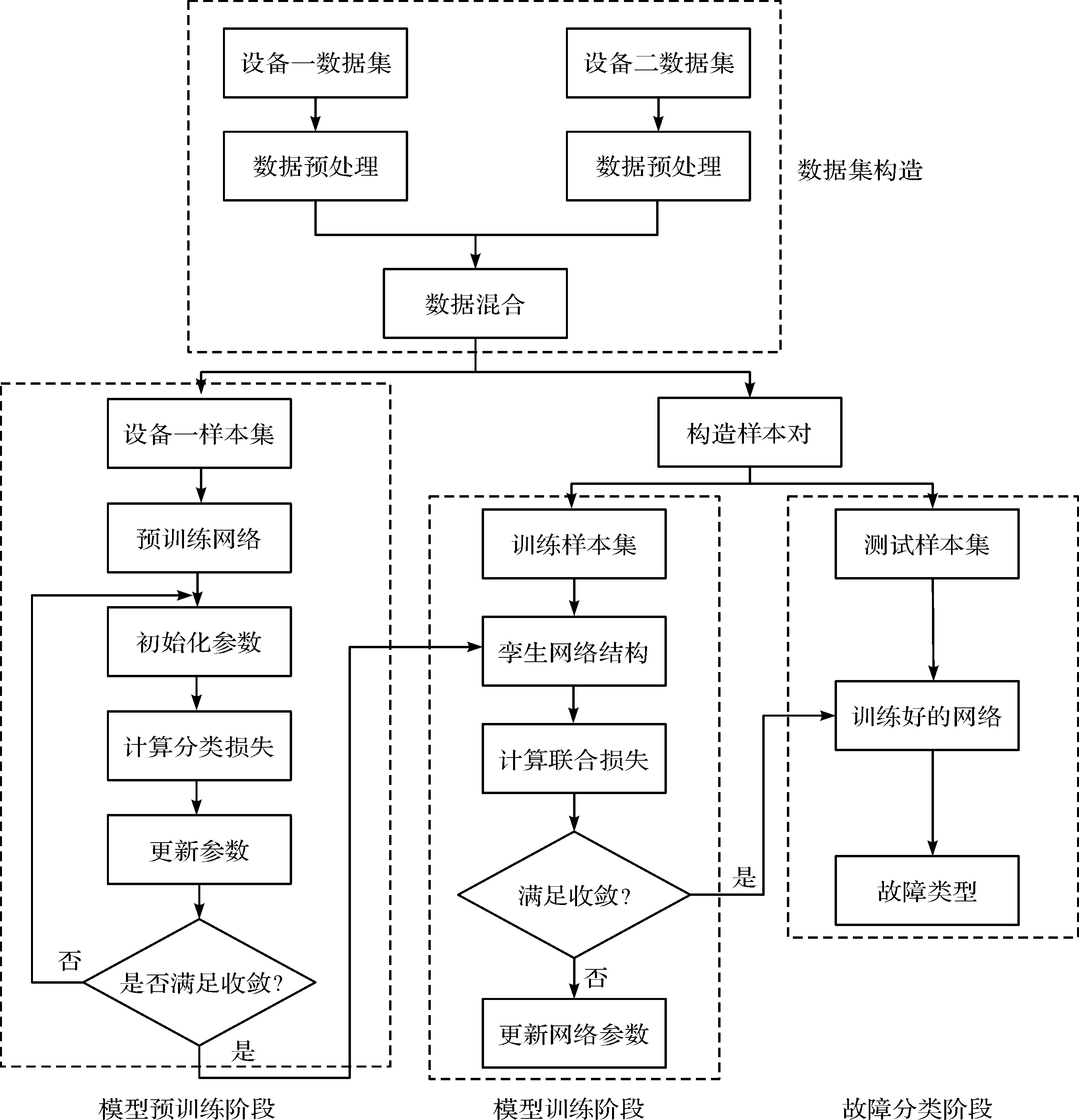
圖4 基于SE-SCNN的軸承故障定位流程圖
圖4中,定位流程總共分為4個階段,即數(shù)據(jù)集構造、模型預訓練、模型訓練和故障分類。
(1)數(shù)據(jù)集構造。將IMS數(shù)據(jù)集作為設備一數(shù)據(jù),根據(jù)故障起始時間選取健康數(shù)據(jù)和故障數(shù)據(jù),組成預訓練樣本集;將德國Paderborn大學的變工況軸承數(shù)據(jù)集作為設備二數(shù)據(jù),對其分別進行降采樣、滑窗、歸一化等數(shù)據(jù)預處理操作,得到2個數(shù)據(jù)集各自的訓練集和測試集,對應拼接,并隨機打亂,最終獲得混合工況下的SE-SCNN孿生模型基準樣本集;
(2)模型預訓練。構建基于特征提取器和SoftMax層分類器的預訓練模型;初始化網(wǎng)絡參數(shù)將由設備一得到的訓練樣本集輸入模型中進行訓練,通過最小化分類損失函數(shù)優(yōu)化模型的性能,優(yōu)化結束后保存其網(wǎng)絡參數(shù),以提升模型訓練的效率;
(3)模型訓練。利用(2)中預訓練后的模型作為孿生網(wǎng)絡的子網(wǎng)部分,搭建SE-SCNN網(wǎng)絡模型,從混合基準樣本集中隨機抽取構造成對的輸入樣本,通過前向傳播計算網(wǎng)絡的聯(lián)合損失函數(shù),使用反向傳播算法反復迭代更新模型參數(shù),充分提升模型的特征提取性能和分類性能;
(4)故障分類。利用混合樣本集的測試集樣本,成對輸入到已經(jīng)訓練好的網(wǎng)絡模型中,經(jīng)分類器獲得故障定位結果。
3 實驗與結果分析
3.1 數(shù)據(jù)集描述
3.1.1 設備一數(shù)據(jù)集描述
筆者采用美國辛辛那提大學智能維護系統(tǒng)中心(IMS Center)提供的軸承數(shù)據(jù)集1中的軸承3、軸承4振動數(shù)據(jù)和數(shù)據(jù)集2中的軸承1振動數(shù)據(jù)。
實驗軸承轉速均為2 000 r/min,僅3號軸承受徑向載荷為26.6 kN[14]。為了平衡故障數(shù)據(jù)集和健康數(shù)據(jù)集的比例關系,這里以軸承各自的故障起始點為坐標點,分別對3個軸承數(shù)據(jù)向左隨機選取70個正常數(shù)據(jù)樣本[15],構成設備一的健康數(shù)據(jù)集;向右取固定數(shù)目的故障數(shù)據(jù)構成內圈故障樣本、外圈故障樣本和滾動體故障樣本。
設備一原始數(shù)據(jù)集信息如表2所示。

表2 設備一原始數(shù)據(jù)集信息
3.1.2 設備二數(shù)據(jù)集描述
設備二數(shù)據(jù)集來自德國Paderborn大學提供的旋轉軸承數(shù)據(jù)集[16]。實驗平臺如圖5所示。

圖5 帕德伯恩軸承實驗平臺
該平臺包含多個模塊,其中,軸承測試臺用于產(chǎn)生不同損傷類型的實驗數(shù)據(jù),徑向力為1 000 N,電機轉速和負載轉矩均為工況變量,數(shù)據(jù)采樣頻率為64 kHz。
此處所用軸承型號參數(shù)如表3所示。

表3 設備二軸承型號參數(shù)
該數(shù)據(jù)集包含人工故障數(shù)據(jù)和軸承真實損傷數(shù)據(jù),有3種狀態(tài)類型:健康、內圈故障和外圈故障。
為了驗證該方法具有較強的泛化性,筆者保持負載轉矩為0.7 N·m不變,在僅僅改變電機轉速的情況下,得到了設備二的原始變工況數(shù)據(jù)集,如表4所示。
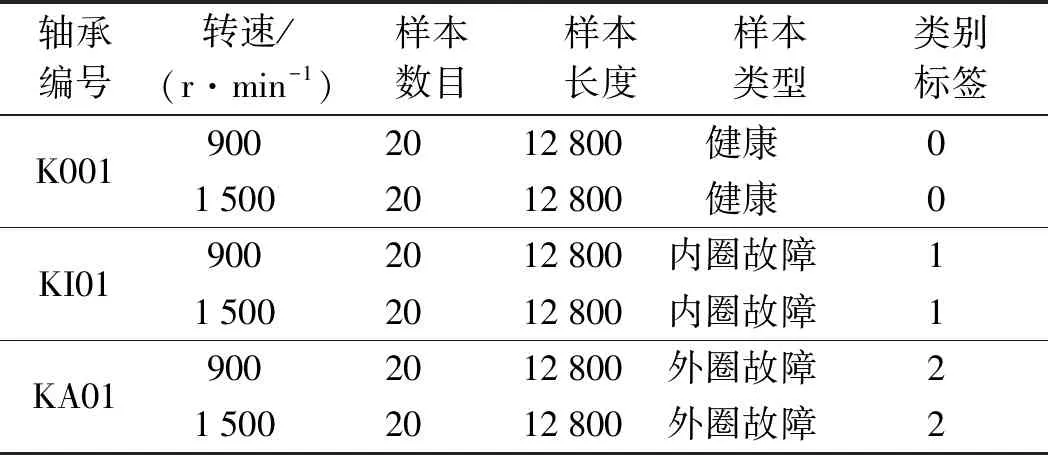
表4 設備二原始數(shù)據(jù)集信息
筆者選取設備二較少的數(shù)據(jù)樣本,以滿足實際多工況下的小樣本數(shù)據(jù)集特點。
3.2 混合數(shù)據(jù)集構造
由于預訓練網(wǎng)絡和SE-SCNN的子網(wǎng)均采用相同的結構,為了便于模型的統(tǒng)一輸入,同時減少計算資源,筆者分別對設備一和設備二的數(shù)據(jù)集進行相同的數(shù)據(jù)預處理操作。
考慮到實際工業(yè)采集系統(tǒng),為方便存儲大量歷史數(shù)據(jù),此處普遍采用間隔采樣的方式。
為了模擬實際信號的采樣數(shù)據(jù)量,筆者首先將原始信號采樣頻率降至工業(yè)常用的5 000 Hz,縮短數(shù)據(jù)長度至5 000;然后對數(shù)據(jù)進行無重疊的滑窗處理,設置截斷長度為1 000(在進一步縮短數(shù)據(jù)長度的同時,有利于擴充樣本集,避免訓練過程中的過擬合現(xiàn)象);最后,為了加快卷積網(wǎng)絡的訓練,將輸入數(shù)據(jù)處理成具有相同量級的規(guī)范數(shù)據(jù),對所有樣本進行歸一化處理。
在上述實驗中,筆者預訓練網(wǎng)絡的數(shù)據(jù)集來自設備一預處理后的數(shù)據(jù),按照7 ∶3隨機抽取組成預訓練模型的訓練集。
為了模擬實際工程中變工況、跨設備的復雜采集環(huán)境,筆者打亂兩個數(shù)據(jù)集分別按照同樣比例劃分訓練集和測試集,對應拼接訓練集的數(shù)據(jù)和標簽以及測試集的數(shù)據(jù)和標簽,再從中隨機抽取一定比例的訓練集和測試集作為SE-SCNN孿生模型的混合樣本集。
其中,混合樣本信息如表5所示。
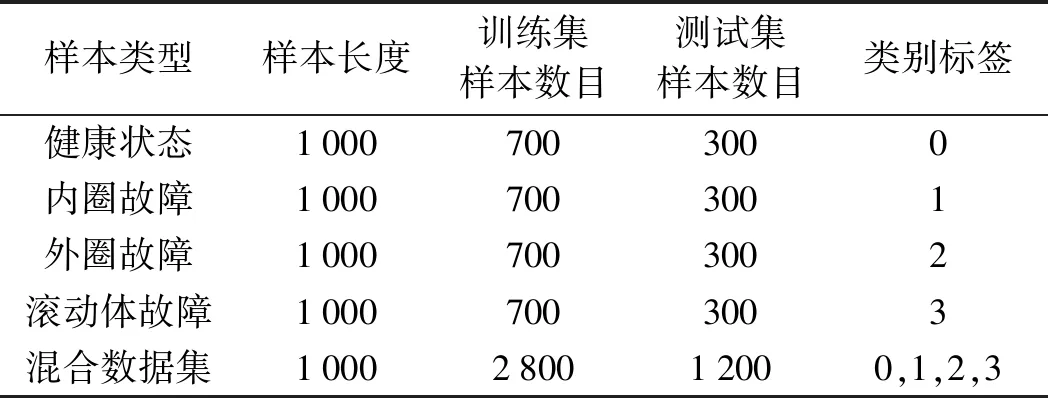
表5 混合樣本集信息
3.3 結果與分析
為了驗證筆者提出的SE-SCNN模型的有效性,針對網(wǎng)絡有無孿生結構,以及是否改進池化策略和激活函數(shù),筆者構建CNN、SE-CNN、SCNN、SE-SCNN等4種模型,從特征提取性能、故障定位準確程度、收斂速度3個方面,比較模型對混合數(shù)據(jù)集的故障定位性能。
基于單輸入的預訓練網(wǎng)絡,CNN、SE-CNN模型參數(shù)設置與SCNN、SE-SCNN相同,即均采用“特征提取器+分類器”的結構;其中,CNN、SCNN池化策略設置為常用的最大值池化,激活函數(shù)為ReLU。
4種模型的訓練過程參數(shù)設置如下:epochs=150,batch_size=64,初始學習率lr=0.001。
3.3.1 故障定位性能綜合評價指標
由于單一的指標不能很好地評估模型的性能,因此,筆者將常用的準確率Acc,精確率Pre,召回率Re和F1值(F1-score)作為模型故障定位準確程度的評價指標。
其中,每個指標的計算公式如下:
(5)
(6)
(7)
(8)
式中:TP—正確分類的正樣本數(shù);TN—正確分類的負樣本數(shù);FP—正樣本的誤分類樣本數(shù);FN—負樣本的誤分類樣本數(shù)。
3.3.2 故障定位性能對比與分析
考慮到單次實驗結果往往誤差較大,為了說明各模型的故障定位性能,筆者從混合數(shù)據(jù)集中隨機抽取10次測試集進行實驗,取不同指標的平均值作為最終實驗結果,如表6所示。
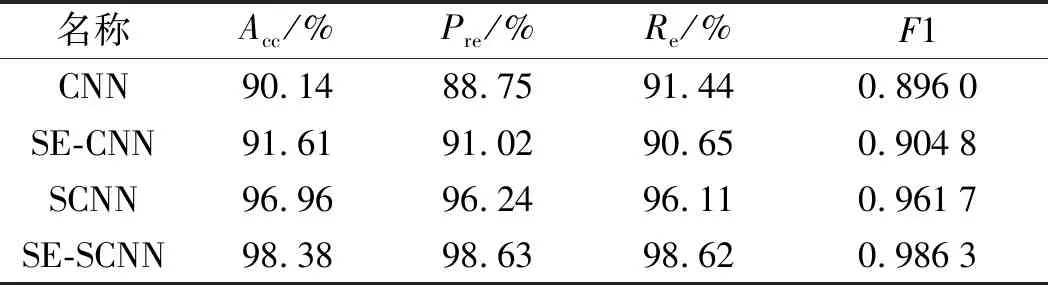
表6 不同模型的定位準確程度
從表6中可知:相對于CNN來說,在各類性能指標上,基于孿生結構的SCNN和SE-SCNN模型都具有很大的優(yōu)越性,其準確率均達到了95%以上;
其綜合數(shù)據(jù)指標F1也充分表明,在不同的工況下,筆者所提的SE-SCNN模型都有著較好的分類效果;特別是在跨設備的情況下,與同結構的SCNN相比,該模型故障定位準確程度有明顯提高。
3.3.3 模型收斂性能對比與分析
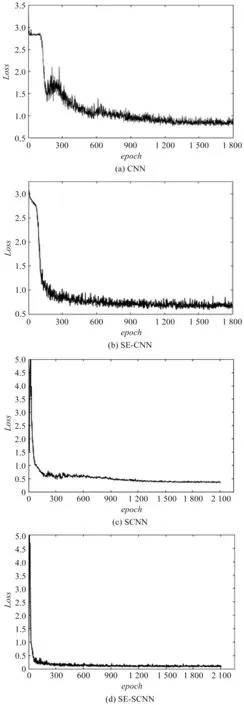
圖6 不同模型的Loss收斂曲線圖
筆者通過訓練過程的損失函數(shù)-迭代次數(shù)曲線,證明SE-SCNN模型的快速收斂性,如圖6所示。圖6分別展示了4組模型的損失函數(shù)下降曲線。首先,從收斂速度來看,在同一迭代次數(shù)下,采用Stochastic池化策略和ELU激活函數(shù)的SE-CNN、SE-SCNN下降速度明顯高于另外兩種模型,且收斂曲線更加平滑,具有較強的穩(wěn)定性;
其次,比較SE-CNN和SE-SCNN可以發(fā)現(xiàn),后者的損失函數(shù)到達平穩(wěn)狀態(tài)時,損失函數(shù)值更小,具有更好的分類性能。
4 結束語
由于不同設備及不同工況下,滾動軸承振動數(shù)據(jù)分布存在差異,傳統(tǒng)深度學習模型難以適應數(shù)據(jù)集分布的不一致,為此,筆者提出了一種基于卷積孿生神經(jīng)網(wǎng)絡SE-SCNN的軸承故障定位方法,即利用基于樣本相似性度量的孿生結構,通過特征提取器,將一對不同設備、不同工況的樣本數(shù)據(jù)映射到特征空間中,進行距離計算;結合分類器得到特征向量在類別空間的映射結果,實現(xiàn)混合數(shù)據(jù)集下的故障定位。
筆者通過集合兩種數(shù)據(jù)集的混合數(shù)據(jù)集進行了實驗,結果表明:
(1)與其他方法相比,基于SE-SCNN的故障定位方法的3項性能指標準確率均為最高,且都在95%以上,綜合評價指標比其他先進方法提高了0.024 6,在模型的定位準確度方面具有明顯優(yōu)勢;
(2)在收斂性方面,采用Stochastic池化策略和ELU激活函數(shù)的SE-SCNN模型,收斂曲線更平滑的同時,損失函數(shù)值也更小,在穩(wěn)定性和分類性能具有明顯優(yōu)勢。
除了軸承采集裝置本身的多工況設定外,傳感器采集的振動信號會混入背景噪聲,淹沒故障特征信息,導致軸承故障診斷開展困難。因此,在未來的研究工作中,筆者可嘗試對信號進行有效去噪處理,以提高工業(yè)場景下軸承設備的智能故障診斷性能。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
汽車維修與保養(yǎng)(2019年7期)2020-01-06 03:30:42
光學精密工程(2016年6期)2016-11-07 09:07:19
汽車維護與修理(2016年10期)2016-07-10 08:17:41
核科學與工程(2015年4期)2015-09-26 11:59:03
汽車維修與保養(yǎng)(2015年12期)2015-04-18 07:51:49
汽車維修與保養(yǎng)(2015年6期)2015-04-17 03:31:50
汽車維修與保養(yǎng)(2015年2期)2015-04-17 01:30:34
