基于GLSTM和Attention的中文事件要素提取
2022-03-22 03:36:10曹渝昆
計算機工程與應用 2022年6期
曹渝昆,孫 濤
上海電力大學 計算機科學與技術學院,上海 200090
事件抽取是信息抽取中的一項分支任務,旨在從文本中提取出可以描述事件的觸發(fā)詞和要素[1]。例如,給定一句話,則其指示詞與事件要素如圖1所示。
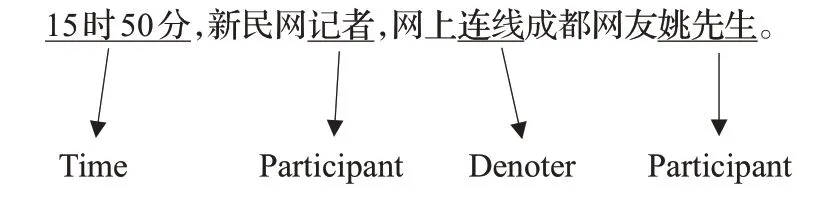
圖1 事件抽取示例Fig.1 Example of event extraction
事件信息抽取任務一般分為事件觸發(fā)詞的抽取和事件要素的抽取。相比觸發(fā)詞而言,事件要素更難識別和提取,主要的分析方法是通過神經(jīng)網(wǎng)絡來進行多元分類,主要分為兩個部分,特征選擇和分類模型。事件要素類似命名實體,而事件要素抽取類似命名實體識別,而且針對人名、地名和時間的識別技術已經(jīng)相對成熟。事件要素的定義會根據(jù)事件類型的不同而不同,要求和數(shù)量都有更高的要求。對中文事件要素抽取的研究,有利于擴大實體識別的范圍,同時也有利于相關方向如知識圖譜的研究。
特征選擇方面,主要分為詞法特征和句法特征。通常采用詞嵌入、位置信息作為詞法特征,從上下文中采集信息作為句法信息。現(xiàn)有的研究中選用了不同的方法來抽取特征,在特征的表示方式和不同特征的結合方式上也有不同。分類模型方面,通常采用Softmax、條件隨機場(conditional random fields,CRF)[2]和支持向量機(support vector machine,SVM)等方式對候選示例進行標記。現(xiàn)有的研究表明,詞法特征與句法特征的嵌入,能明顯提升事件要素抽取的效果。但是也存在一些問題,比如如何選擇詞法特征與句法特征,位置信息、距離特征等需要預訓練,實體信息和事件類型特征等需要人工標注,且并不同適用于中文事件抽取環(huán)境。
中文在句法和詞法的表達上與英文所有不同,在抽取詞法與句法特征上所用的方式也不同。英文事件抽取任務中,可以通過位置信息,相對距離特征來幫助事件要素的確定和抽取,但是在中文事件抽取任務中,這些特征的所取得的效果并不明顯。由于中文事件要素的抽取更類似于命名實體識別,在中文事件抽取任務中,往往依靠Bi-LSTM來捕獲語法特征,進而抽取事件要素,而Bi-LSTM與CRF結合的模型在實體識別上取得了非常好的效果。近年來,隨著transformer的興盛,Self-attention也被應用于中文事件抽取,從而提升了事件要素抽取的效果。但是Self-attention僅僅能捕獲詞與詞之間的相互關系,無法捕獲詞在整個句子中所表現(xiàn)出的特征。
本文采用Word2vec預訓練的詞向量作為詞法特征,并以數(shù)據(jù)集本身為語料訓練出句向量作為句法特征,通過Multi-head Attention[3]將每個詞都注意到句子上,得到一種兼具詞法特征和句法特征的融合特征,在獲得多樣性特征的同時,保證了特征的完整性。融合特征以詞嵌入的形式輸入到序列標注模塊中,本文采用雙向GLSTM來計算每個詞對應每個標簽的分數(shù),并通過Softmax轉(zhuǎn)換成置信度,最后通過CRF得到合理的標注結果。
本文的主要貢獻在于:
(1)采用Word2vec訓練的詞向量作為詞法特征,并以數(shù)據(jù)集本身為語料計算的句向量作為句法特征,以滿足中文文本的特征要求。
(2)采用Multi-head Attention將普適性詞法特征聚焦于具有事件特色的句法特征上,以滿足事件要素提取的特征要求。
(3)采用GLSTM捕獲上下文信息,從向量維度出發(fā),橫向分組提取要素特征,強化特征的效果,以提升事件要素抽取的準確率。
1 相關工作
事件要素抽取技術的研究中,主要可以分為特征選擇和分類方式兩個方面。
在特征的表示方式上,2015年Chen等[4]提出的DMCNN模型中,句法特征的輸入由三部分組成,表示上下文的詞向量特征、用于表示與候選詞相對位置的位置特征和用于表示事件類型的事件特征,將這三部分拼接并通過動態(tài)多池化卷積構成最終的句法特征,詞法特征則由預訓練的詞向量表示;2018年Bj?rne等[5]在TEES系統(tǒng)上進行的事件抽取研究中,采用了多種特征,包括Word2vec預訓練的詞向量、BLLIP解析器生成的詞性表示、實體特征、距離特征、相對位置特征、路徑嵌入和最短路徑嵌入等;2018年Liu等[6]提出的JMEE模型中,將Word2vec預訓練的詞向量、詞性表示、實體類型標簽和相對位置表示拼接到一起作為嵌入;2020年Shafieibavani等[7]提出的全方位事件抽取方法中采用Word2vec預訓練的詞向量為主體,拼接相對位置表示以及距離特征,作為詞嵌入表示。
可以看到,現(xiàn)有的研究中,特征選擇上主要采用位置特征、實體類型和詞性表示等,并且將這些特征拼接到詞向量上作為模型的輸入。這些特征或依賴大量的人工標注,如實體類型、詞性;或不適用于中文文本,如相對位置、距離特征。而在結合方式上,大多數(shù)模型采用簡單的拼接,以將特征體現(xiàn)在輸入向量表示中,然而簡單的拼接并不能讓特征足夠明顯,除非像DMCNN模型中那樣對每個部分單獨聚焦。
在分類標記方式方面,2017年Kusa等[8]總結了幾種經(jīng)典的分類模型,并進行了全面的對比,其中包括support vector machines(SVM)、decision tree(DT)、decision tree(RF)、multinomial Naive Bayes(MNNB)、multi-layer perceptron(MLP);DMCNN模型中采用了Softmax分類器進行最后的標記;Elaheh等采用了一層卷積加最大池化進行特征提取。
在分類標記方式上,現(xiàn)有的模型大多采用機器學習方法,而對于序列分析,本文提出的模型采用深度學習和機器學習相結合的方式,實驗證明,其效果比單純的機器學習方法要好。
在2018年Yang等[9]提出的DCFEE中,Bi-LSTMCRF模型來進行句子級事件要素的抽取,并將識別出的結果作為特征進行文檔級的事件抽取。在2019年Zheng等[10]提出的Doc2EDAG中,作者也贊同該模型在實體識別和句子級事件要素抽取方面的有效性。可以看出,神經(jīng)網(wǎng)絡可以有效提取中文句子中的語法信息。但是,僅僅靠Bi-LSTM提取出的信息顯然是不夠準確的,因此2018年Cao等[11]提出通過Self-attention來捕獲詞與詞之間的長期依賴關系,并與Bi-LSTM相結合來提高中文實體識別的效果。相應地,在事件要素抽取任務中,本文除了需要考慮詞與詞之間的相互關系,還考慮了解詞在句子中所表現(xiàn)的特征,才能更準確地識別詞所代表的角色。
2 模型介紹
2.1 模型框架
本文模型分為兩個部分,基于Attention機制的詞嵌入,將預訓練的詞向量和句向量相融合,保證了特征的多樣性和完整性;基于分組長短期記憶網(wǎng)絡(grouped long-short term memory,GLSTM)[12]和CRF的序列標注,將深度學習與機器學習相結合以提升序列標注的效果。模型框架如圖2所示。

圖2 模型框架圖Fig.2 Framework of model
詞嵌入部分采用Word2vec來訓練詞向量,取維基百科語料作為預訓練的語料庫,使詞向量本身具有普適性,并且詞與詞之間保持緊密的聯(lián)系;采用實驗數(shù)據(jù)集本身作為句向量的訓練語料,使句向量帶有上下文的信息之外,還包含更明顯的突發(fā)事件特征;采用Multihead attention將每個元素注意到其所處的句子上,使詞嵌入包含兩者的特征。
序列標注部分采用GLSTM來計算一個詞對應每個標簽的概率,通過Softmax函數(shù)轉(zhuǎn)化為得分并輸出;CRF接收GLSTM算得的概率,計算不同條件下序列組合的得分,將得分最高的一組序列作為最后的輸出。
模型中每一層的具體功能將在2.2~2.4節(jié)中詳細說明。
2.2 基于Attention機制的特征融合
特征融合部分采用Multi-head attention將句法特征融合到詞法特征中。
首先,采用N-gram模型來訓練詞向量,訓練語料為維基百科,訓練結果為包含普適性詞特征的輸入向量,則詞向量為:

式中,n為詞向量的維度。
文本可表示為:

式中,W表示詞向量構成的矩陣;m表示批次大小;i表示句子的長度。
然后,句向量的訓練采用文本本身為訓練語料,使句向量帶有上下文的信息之外,還包含更明顯的事件特征,句向量可表示為:

式中,S表示句向量構成的矩陣;m表示批次大小;i表示句子的長度。
最后,采用Multi-headed attention的方式融合詞向量與句向量。由于詞本身包含了普適性的詞特征,當其注意到帶有事件性質(zhì)的句子上時,兩種特征不會互相抵消或覆蓋,而會使詞向量的特征向突發(fā)事件聚焦,從而更符合事件提取的要求。
Multi-headed attention模型是由放縮點積注意力機制(Scaled dot-product attention)[13]模型演變而來,Scaled dot-product attention在相似度計算上表現(xiàn)非常出色,其表達式為:
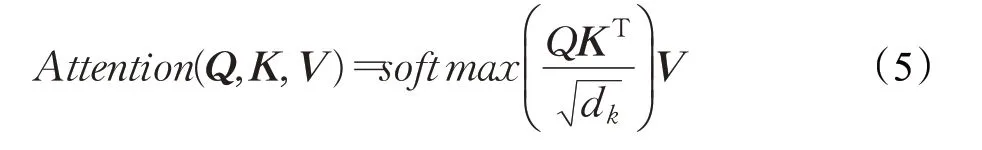
其中,Q表示由查詢向量組成的矩陣,K表示鍵向量組成的矩陣,V表示值向量組成的矩陣,dk為矩陣K的維度。將查詢向量乘上鍵向量,可以得到該查詢向量對每一個鍵向量的得分,將每個score經(jīng)Softmax處理成概率再乘上值向量,可以得到查詢向量對每一個鍵向量的相似度。
Multi-headed attention可以將整個句子分為多個部分,并允許模型在不同的句子部分中學習到相關的信息,對應于事件抽取任務中,可以讓詞關注到句子的不同部分,從而使不同的事件要素關注到其所處的句法位置。
將詞向量設置為查詢向量,句向量設置為鍵向量,為了使維度對應,將句向量復制,使句矩陣和詞矩陣大小相同。使用多個head以及不同的權重組合得到和相同數(shù)量但值不同的Query、Key和Value。其中,向量的維度為300,每個head的維度為100,相當于將詞分別對句子的三個部分進行注意,通過訓練權重來得到最合理的特征表示。
由得到的多個Query、Key和Value分別計算出對應詞做多次Attention的新特征矩陣Zi,則:

式中,W0為整個Multi-headed Attention的外部權重矩陣,ci表示經(jīng)過融合之后的詞向量表示,其維度為n;m表示批次大小;i表示句子長度。
2.3基于GLSTM的置信度評價
LSTM(long short term memory,長短期記憶網(wǎng)絡)可以有效處理序列信息。將詞向量的序列(c1,c2,…,ci)作為輸入,并得到一個輸出序列(h1,h2,…,hn),輸出序列捕獲的是輸入序列在當前時間的信息。一個GLSTM(Group-LSTM)單元每組由一個LSTM子單元組成,其中每個子單元在輸入的均勻大小的子向量上操作,并產(chǎn)生輸出的均勻大小的子向量,其作用在于減少訓練參數(shù)同時可以加快訓練速度。
GLSTM單元可表示為:

采用雙向GLSTM計算得出句子中第t個詞左側(cè)的信息hlt,以及它右側(cè)信息hrt,將左右側(cè)的輸出拼接起來得到最終的輸出結果。
通過多頭注意力機制融合了句子特征的詞嵌入依舊無法滿足事件要素抽取的需求,因此,考慮加入上下文信息來提高事件要素的識別效果。
將詞嵌入輸入到雙向GLSTM中得到每個詞對應每個標簽的分數(shù),將分數(shù)輸入Softmax層中可以得到詞獲得每個標簽的置信度,即當前的詞獲得每個標簽的概率。
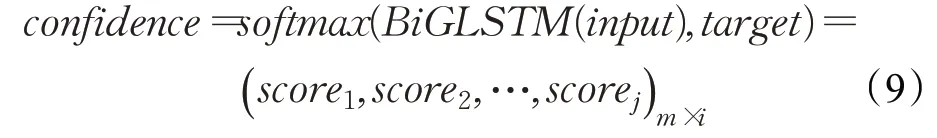
式中,j表示標簽的數(shù)量;m表示批次大小;i表示句子的長度。
GLSTM部分輸出的是一個得分,用于表示每個元素被標記為各種角色的可能性,CRF部分重新將詞構成不同的序列,通過確認標簽之間的關系來重新評分,最后輸出得分最高的標簽序列進而確認元素對應的角色。
2.4 標簽體系定義
在標簽體系方面,由于BIO(B-begin,I-inside,O-outside)標簽體系的精度能達到要求,而且訓練復雜度相對較低,因此選擇該體系來序列標注。在中文中,每個元素是由一個詞組來表示的,BIO標簽體系將一個元素中的字標記為“B-X”“I-X”或“O-X”。其中,“B-X”表示當前的字所在的詞組屬于X類型并且這個字在當前詞組的開頭,“I-X”表示當前的字所在的詞組屬于X類型并且這個字在當前詞組的中間位置,O表示這個字不屬于任何類型的元素。
在本模型的標簽定義中,數(shù)據(jù)集內(nèi)凡是帶有Event、Denoter、Time、Location、Participant和Object標記的詞,詞中第一個字重新標記為B-Event、B-Denoter、B-Time、B-Location、B-Participant和B-Object,詞中剩余的字重新標記為I-Event、I-Denoter、I-Time、I-Location、I-Participant和I-Object,兩位以上連續(xù)的數(shù)字合并到一起標記,其他沒有標記的詞一律標記為O,包括標點符號。
3 實驗與結果分析
3.1 數(shù)據(jù)集及實驗環(huán)境
中文突發(fā)事件語料庫是由上海大學(語義智能實驗室)所構建[14]。該語料庫根據(jù)《國家突發(fā)公共事件總體應急預案》所提出的分類體系,通過網(wǎng)上廣泛搜索,收集了5類突發(fā)事件,事件以新聞報道的方式表達,分別為地震、火災、交通事故、恐怖襲擊和食物中毒。通過對生語料文本進行處理、分析、標注等,最后形成標準的標注語料存入語料庫中,共計332篇。該語料庫包含了六種標記:Event、Denoter、Time、Location、Participant和Object。其中,Event表示事件的開始;Denoter為事件的觸發(fā)詞;Time、Location、Participant和Object為事件的4個要素,并且每個要素也有更細致的分類。語料庫以XML文件構建,形式類似ACE2005數(shù)據(jù)集,但是更針對中文的語法習慣和結構,也更詳細。
本文在Tensorflow平臺上構建了模型,將數(shù)據(jù)進行預處理,共整理出2 027句話,共91 221個標記字符(包括標點符號),其中90%作為訓練集,10%作為測試集,批次大小設定為16,并采用Adam優(yōu)化器,最終的結果取F1分最高時的測試結果。
實驗共分為兩組,分別為采用不同LSTM單元的實驗效果比較和與基線模型的比較。比較分為兩個方面,評估標準上的比較用以說明模型的事件抽取能力,訓練過程的對比圖用以說明模型的性能。
3.2 采用不同的LSTM單元效果比較
如表1所示,在嵌入層相同的情況下,比較不同LSTM單元的實驗效果。
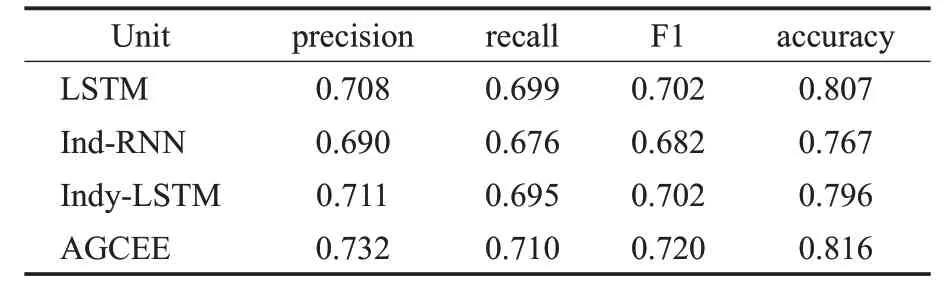
表1 采用不同LSTM單元對比分析結果Table 1 Comparison of different LSTM units
獨立循環(huán)神經(jīng)網(wǎng)絡(independently RNN,Ind-RNN)[15]和獨立循環(huán)長短記憶網(wǎng)絡(independently recurrent LSTMs,Indy-LSTM)[16]是LSTM的兩種最新的改進算法,其作用都是通過降低過擬合以獲得更好的效果。傳統(tǒng)LSTM單元的抽取效果僅次于本模型采用的GLSTM,由此可以看出,事件要素之間的相互關聯(lián)很緊密,獨立性質(zhì)的算法不適合用于事件抽取任務。從實驗結果可以看出,AGCEE采用的GLSTM取得的效果最好。
實驗記錄了每個模型在四個評估指標上的訓練過程,并按四個評估標準分開制圖,以對比模型性能,對比結果如圖3~圖5所示。

圖3 不同LSTM單元的準確率訓練結果Fig.3 Precision training results of different LSTM units
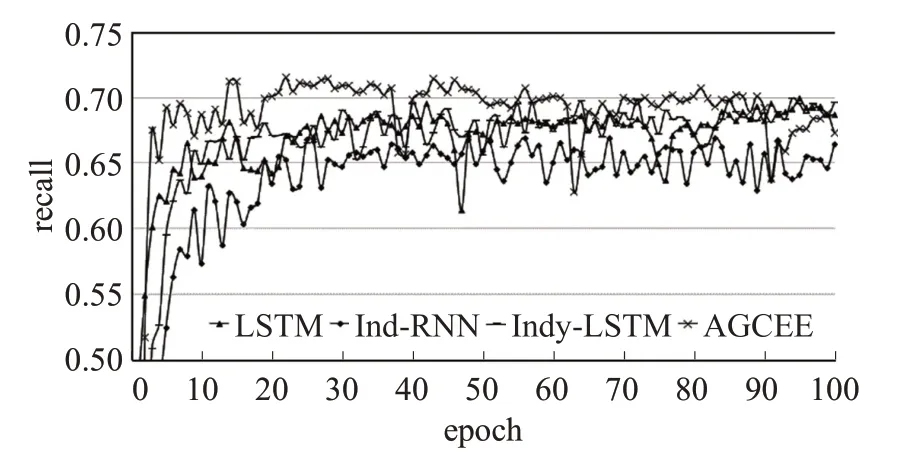
圖4 不同LSTM單元的召回率訓練結果Fig.4 Recall training results of different LSTM units

圖5 不同LSTM單元的F1分訓練結果Fig.5 F1 score training results of different LSTM units
如圖6所示,神經(jīng)網(wǎng)絡單元在準確率上的訓練效果差不多,但是在召回率上的差異比較大,特別是Ind-RNN單元,整個過程震蕩較大,說明該單元對數(shù)據(jù)特征的把握不夠精確,雖然在準確率上與其他幾種單元相差不多,但是在覆蓋程度上的表現(xiàn)來看,容易顧此失彼。相比較而言,傳統(tǒng)的LSTM和Indy-LSTM的訓練過程都比較平緩,各項指標都在穩(wěn)步上升。AGCEE采用的GLSTM,在各項指標上都優(yōu)于另外三種單元,訓練過程平穩(wěn)且規(guī)律。
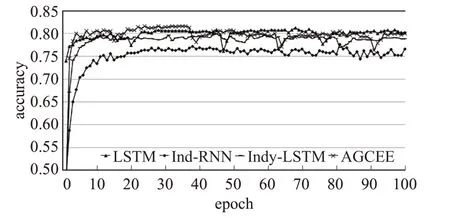
圖6 不同LSTM單元的正確率訓練結果Fig.6 Accuracy training results of different LSTM units
3.3 與基線模型比較
如表2所示,基線模型采用預訓練的詞向量為輸入,通過Bi-LSTM和CRF結合的方式進行標注[17],后面三種模型都采用了Bi-GLSTM和CRF結合的方式進行分類標注,不同的是,第二種模型將句向量與詞向量拼接作為輸入,第三種模型在詞句拼接之后通過Selfattention對詞嵌入進行特征的優(yōu)化,最后一種模型是本文提出的AGCEE。

表2 與基線模型對比分析結果Table 2 Comparison result with baseline model
從實驗可以看出,僅將句向量作為句法特征拼接到詞向量后面,模型的整體評估結果有所提升,但提升非常有限,在精確度方面甚至有所下降。
Self-attention可以有效捕獲詞與詞之間的依賴關系,對事件抽取而言,除了可以提高詞語的完整性,可以捕獲事件要素之間的依賴關系,實驗表明在詞句向量拼接的基礎上,增加Self-attention可以有效提升事件抽取的效果,特別是在召回率上提升明顯,說明Attention機制可以有效提升事件要素抽取的覆蓋率。
AGCEE基于Multi-head attention構建了包含詞法和句法的融合特征,并采用Bi-GLSTM和CRF向結合的方式進行分類標注,從實驗結果中可以看出,本模型取得了最好的事件要素抽取效果,準確率、召回率、F1分和精確度都有提升。
實驗記錄了每個模型在四個評估標準上的訓練過程,并按四個評估標準分開制圖,以對比模型性能,對比結果如圖7~圖9所示。
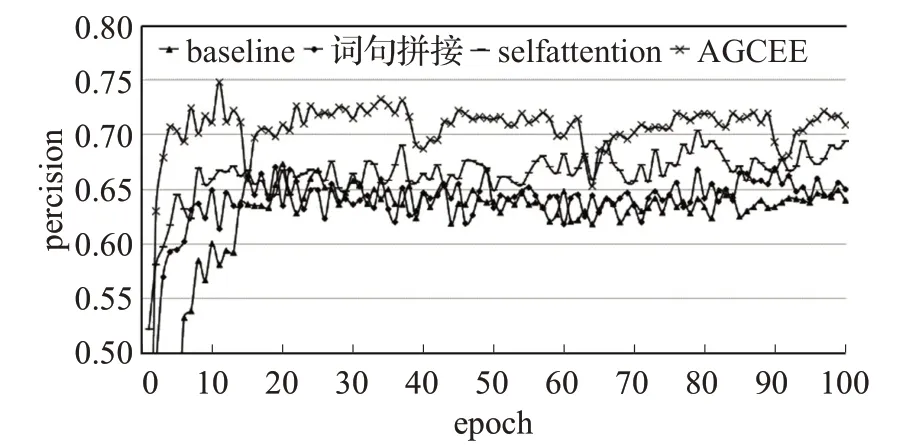
圖7 不同模型的準確率訓練結果對比Fig.7 Precision training results of different models
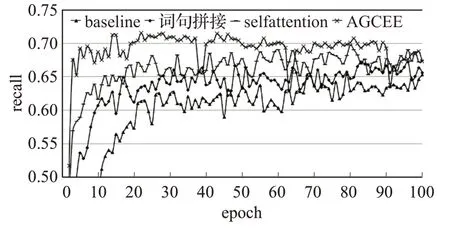
圖8 不同模型的召回率訓練結果對比Fig.8 Recall training results of different models
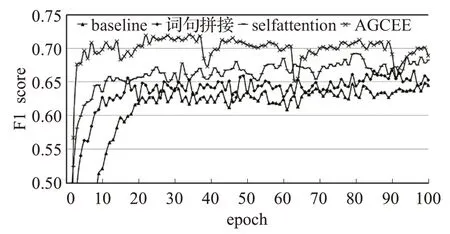
圖9 不同模型的F1分訓練結果對比Fig.9 F1 score training results of different models
如圖10所示,將整個訓練過程分為上升階段與平穩(wěn)階段,可以明顯區(qū)分兩個階段的點稱為轉(zhuǎn)折點。可以看到,基線模型在第20個epoch時出現(xiàn)轉(zhuǎn)折點,之后的測試結果圍繞這個值上下浮動,并趨于平穩(wěn)。在增加了句法特征之后,模型在第15個epoch出現(xiàn)轉(zhuǎn)折點,并且在第80個epoch后有一段小幅提升。增加self-attention之后,模型在第10個epoch出現(xiàn)轉(zhuǎn)折點,在第50個epoch后有一段幅度較大的提升,然后趨于平穩(wěn)。AGCEE在第15個epoch時出現(xiàn)轉(zhuǎn)折點,此外,從圖中還可以明顯看出15~40、40~65、65~90三段提升過程。
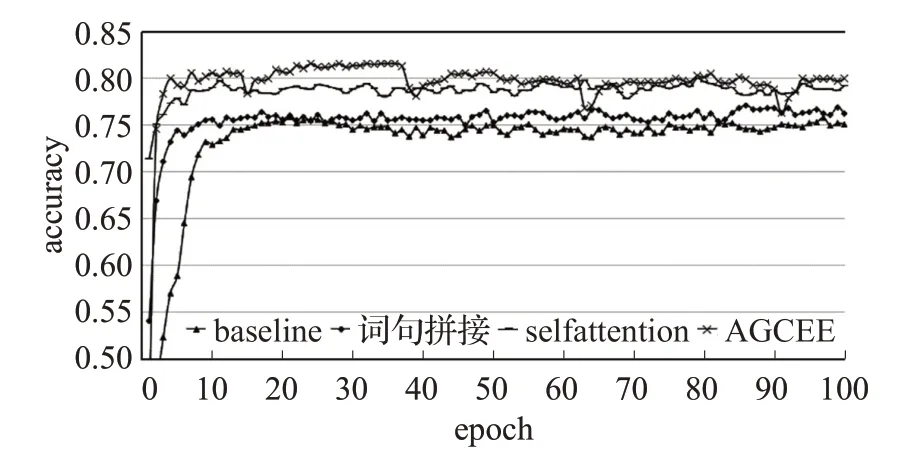
圖10 不同模型的正確率訓練結果對比Fig.10 Accuracy training results of different models
通過對比可以看出:
(1)詞法特征與句法特征的結合可以有效提升模型的準確率,并且使模型更快地得到一個較好的結果。
(2)訓練的過程是一個螺旋上升的過程,測試結果按一定的規(guī)律波動,Attention機制在提升訓練效果的同時,還可以縮短波動的周期。
(3)AGCEE通過Multi-head attention將詞法特征與句法特征融合,得到了最好的效果,并且大幅縮短了波動的周期。
3.4 與現(xiàn)有模型比較
表3中模型采用相同的訓練方式,即數(shù)據(jù)集90%作為訓練集,數(shù)據(jù)集10%作為測試集,批次大小設定為16,并采用Adam優(yōu)化器,最終的結果取F1分最高時的測試結果。可以看出,DMCNN在正例準確率以及全要素識別正確率上具有一定優(yōu)勢,驗證了在中文事件要素抽取任務中,對句子不同部分進行聚焦是有效的;JMEE采用了多種特征表達,彌補了DMCNN在一句多事件情況下事件要素抽取的效果,有效提升了召回率;AGCEE針對中文文本設計特征組合,并通過分組的方式對句子不同部分進行特征的進一步聚焦,在準確率、召回率和F1分數(shù)三個方面都有提升。在訓練時間方面,AGCEE采用Attention機制提取特征,所需要的時間成本相對多一些。
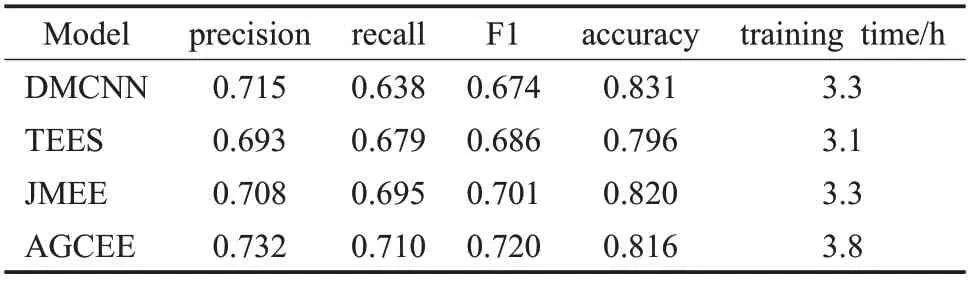
表3 與現(xiàn)有模型比較Table 3 Compared with existing models
4 結語
中文事件要素抽取的難點在于構建特征工程,由于中文的詞法與句法難以通過一個或幾個表達來定義,而詞向量和句向量包含了大量的詞法和句法信息,通過處理詞向量和句向量是捕獲中文語法的有效途徑。
本文提出了一種新的事件要素抽取模型AGCEE,針對中文表達的特點,通過Attention機制構造包含詞法特征與句法特征的融合特征,并采用GLSTM與CRF結合的方式進行分類標記,在加快訓練速度的同時提高標注的精度。實驗表明,相比基線模型,該模型在準確率上提升了6%,在召回率上提升了6.2%,在F1分上提升了6.1%,在正確率上提升了3.3%。
在未來的工作中,會將研究重點放在改善Attention機制所帶來的運算時間成本問題。此外,AGCEE可應用于繼續(xù)提升整個事件抽取系統(tǒng)的效果,會繼續(xù)探究該模型在知識圖譜中的應用。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中華詩詞(2021年3期)2021-12-31 08:07:22
大連民族大學學報(2021年2期)2021-07-16 05:41:42
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中華詩詞(2018年3期)2018-08-01 06:40:40
中華詩詞(2018年11期)2018-03-26 06:41:32
數(shù)學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
