基于YOLOv3改進的輕量化人臉檢測方法
2022-03-22 03:35:04史夢安蔡慧敏陸振宇
計算機工程與設計 2022年3期
史夢安,蔡慧敏,陸振宇
(1.蘇州大學應用技術學院 工學院,江蘇 蘇州 215325;2.南京信息工程大學 人工智能學院, 江蘇 南京 210044;3.南京信息工程大學 江蘇省大氣環境與裝備技術協同創新中心,江蘇 南京 210044)
0 引 言
如今的人臉檢測技術大致可分為兩類:人工設計特征的傳統方法和特征自動提取的深度學習方法。人工設計一般從人臉的膚色、結構、紋理、輪廓等特征入手。Mollah等[1]將Harr-like特征與膚色特征相結合,降低了人臉樣本假陽性的概率。Zheng等[2]先后選取膚色特征與紋理特征,使用局部二進制模型進一步減少誤檢率。Sudhaker團隊[3]使用Gabor濾波器進行人臉的檢測,通過濾波生成不同角度和方向的人臉圖像通過匹配算法與數據庫中的人臉輪廓進行比對。人工設計特征的檢測算法,由于特征表達能力有限,容易受外界環境變化的影響,所以在復雜場景下檢測性能難有提升。
基于深度學習的人臉檢測算法大致分為兩類:以Faster R-CNN[4]為代表的兩步法(Two-Stage):這類方法首先提取候選區域,再基于候選區域做二次修正,特點是速度較慢,但精度很高;以SSD[5]為代表的一步法(One-Stage):這類方法通過直接對預設在圖像上的邊界框做修正來獲得檢測結果,特點是速度與精度相均衡。
目前人臉檢測技術的難點是如何在有限的資源上完成實時檢測并兼顧準確性,究其原因是現在通用的目標檢測模型往往本身復雜度高,神經網絡模型參數多,計算量大,而它們的簡化版本(tiny)雖然速度有所提高,但是檢測精度卻大打折扣,不能滿足現實生活中的需要。
為解決上述不足,本文認為關鍵點是輕量化模型設計,并增加一系列的trick提高網絡的檢測精度,提出了以YOLOv3[6]為基礎的一種基于MobileNet[7-9]中深度可分卷積替換傳統卷積的輕量化模型,主要貢獻可總結為:
(1)針對人臉檢測不能滿足實時性的問題,采用MobileNet中的深度可分卷積輕量化YOLOv3模型,降低計算量,加快檢測速度。
(2)針對人臉檢測因人臉尺寸不一容易出現漏檢的情況,增加了SPP結構,尺度不變的同時可提取不同尺寸的空間特征信息,提升模型的魯棒性。
(3)針對人臉檢測易受環境影響召回率不高的問題,基于YOLOv3中的FPN[10]結構,增加Self-attention[11]機制,加強不同尺度預測特征層上語義信息與位置信息的融合,提高檢測精度,降低環境對人臉檢測的影響。
1 相關理論基礎
1.1 MobileNet網絡
MobileNet是google團隊于2017年發表的專門針對移動端或者小型設備開發的輕量級CNN網絡,提出了深度可分卷積這一結構。相比傳統的卷積神經網絡,在略微降低準確率的前提下大幅減少了模型參數與運算量,與同樣是通過堆疊卷積層構建的VGG16網絡相比準確率僅降低了0.9個百分點但是模型參數只有VGG大小的1/32。
深度可分卷積(depthwise separable convolution)的定義請參見文獻[7]。圖1中的depthwise convolution就是深度卷積,在深度卷積中,每一個卷積核的深度都為1,也就是說每一個卷積都只對應輸入特征矩陣中的一個通道,也只提取一個通道的特征,所以得到的輸出特征矩陣的深度等于輸入特征矩陣的深度。逐點卷積則對應圖1中的pointwise convolution,其實逐點卷積就是卷積核大小為1的普通卷積,它對深度卷積計算出來的結果進行1×1的卷積運算,并將得到的特征圖再串聯起來,維持特征的完整性。標準的卷積運算是一步中就包含了深度計算和合并計算,然后直接將輸入變成一個新的尺寸的輸出。深度可分卷積是將這個一步的操作分成了兩層,一層做深度計算,一層做合并計算。這種分解的方式極大地減少了計算量和模型的大小。深度卷積和逐點卷積如圖1所示。

圖1 深度可分卷積
1.2 YOLOv3網絡
2018年Redmon發布的YOLOv3(you olny look once)可謂是前兩代YOLO[12,13]的集大成者,在原有YOLO算法的基礎上修改主干特征提取網絡,改變對邊界框的預測方式并引入一些新的結構來增加mAP,使其成為當時最受歡迎的one-stage目標檢測網絡之一。
YOLOv3的主干特征提取網絡較之于YOLOv2[13]的Darknet-19,采用重新訓練的Darknet-53,Top-1達到了77.2個百分點,對比原來的Darknet-19有非常明顯的提升。和Darknet-19一樣,Darknet-53中有53個卷積層,所以稱為Darknet-53。具體網絡結構如圖2所示。

圖2 YOLOv3網絡結構
YOLOv3引入了FPN結構,會在3個預測特征層上進行預測,每個預測特征層上使用3種尺度的預測邊界框。這3種尺度也是通過k-means聚類算法得到的,一共9組尺度。在YOLOv3中稱這些預設的目標邊界框作bounding box priors,與SSD中的anchor類似。每一個預測特征層上的一個網格會預測3種尺度,所以在每個預測特征層上會預測N×N×[3×(4+1+80)] (N是指特征矩陣的高和寬),也就是說一個bounding box priors需要預測85個參數(4個偏移參數,1個confidence,80個classes score(因為是在coco數據集上))。
2 網絡模型
2.1 主干特征提取網絡的替換
對于YOLOv3而言,其網絡結構可以大致分為以下兩個部分:①主干特征提取網絡Darknet-53;②預測網絡YOLO-head。第一部分的主干特征提取網絡進行圖像特征的初步提取,提取后可以獲得3個初步的有效特征層,預測網絡則根據第一步獲取的有效特征層進行目標的預測。
MobileNet網絡雖然用于圖像分類任務,但它的主干網絡(backbone)的作用也是初步的特征提取,可以使用MobileNet替換YOLOv3中的Darknet-53進行特征的提取。
基于上述想法,要想用MobileNetV1模型替換Darknet-53模型,只需將經過Darknet-53后得到的3個初步有效特征層替換成MobileNetV1中shape相同的特征層即可。如表1所示,輸入圖片的大小控制為320×320,第一次卷積為普通的卷積,其它卷積為DW卷積,DW的普遍使用提高了模型的計算速度,表中有3處加粗的Output分別為:40×40×256,20×20×512和10×10×1024,這3個 Output是為后面的特征金字塔(FPN)提供的input即替代3個有效特征層的特征層的shape值。

表1 MobilenetV1架構
2.2 增加空間金字塔池化
He等提出卷積神經網絡是由卷積層和全連接層組成,卷積層對輸入圖像的大小并沒有要求,但是第一個全連接層的輸入必須是大小固定的特征向量。人臉圖像由于圖像者本身,具體拍攝情況等一系列原因不可能達到固定的大小,如果直接對圖像進行拉伸、縮放、裁剪等操作必然要損失信息從而影響到檢測的精度和算法的魯棒性。SPP(空間金字塔池化)也正是He等提出來的解決辦法。
考慮到與本文改進模型的適配性,參考SPP結構對其做出了改良,添加到第一個YOLO-head前的第5和第6層卷積之間。改良的SPP結構如圖3所示。
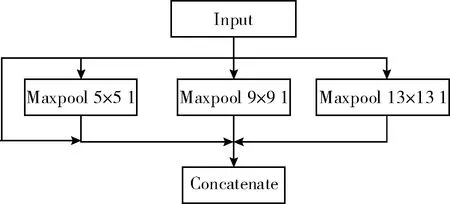
圖3 改良的SPP結構
選取池化核大小分別為13×13、9×9、5×5的池化核。首先從輸入直接接到輸出,這是第一個分支;第二個分支是池化核為5的最大池化下采樣;第三個是池化核大小為9的最大池化下采樣;第四個分支是池化核大小為13的最大池化下采樣。注意這里的步距都是1,意味著在池化之前會對特征矩陣進行padding填充,填充之后進行最大池化下采樣之后所得到的特征層的高度和寬度是沒有發生變化的。最后在深度上進行一個Concatenate拼接就完成了。通過改良的SPP結構實現了不同尺度的特征融合,并且使特征層的表達能力增強,有利于對不同尺寸的人臉圖像進行檢測。
2.3 Self-attention與FPN融合
由2.1節可知,改進的模型(以下簡稱改進的模型為SMYOLO)中FPN(特征金字塔)是基于MobileNetV1的第6層、第12層、第14層輸出來實現的,圖4為融合后的整體架構,第一行Conv1、DWConv12、DWConv14為MobileNetV1的架構。第二行以下模塊屬于FPN,圖4中紅色模塊與黃色模塊為Self-attention。黃色的Self-attention接收的是DWConv14輸出的特征圖(10×10×1024),紅色右接收DWConv12與DWConv14上采樣的特征圖,紅色左接收DWConv6與DWConv12上采樣的特征圖。

圖4 SMYOLO框架
在介紹Self-attention與FPN融合前,首先介紹下Self-attention機制。Self-attention的流程如圖5所示。

圖5 Self-attention[11]
f(x),g(x) 和h(x) 都是普通的1×1卷積,差別只在于輸出通道大小不同也就是每個權重的規格是不一樣的,規格見式(1)。將f(x) 的輸出轉置,并和g(x) 的輸出相乘,再經過Softmax歸一化得到一個Attention map。將得到的Attention map和h(x) 逐像素點相乘,就能得到自適應注意力的feature maps
(1)
圖5中輸入的feature map(x)就是經過隱藏層后得到的特征圖,對應圖4中3個Self-attention接收的特征圖,對于x來說它的維度是C×N,C表示通道數,N表示圖片的寬度×高度,換句話來說就是這個feature map中一共有多少個像素點。f(x)、g(x)、h(x) 的計算公式見式(2)
f(x)=Wf·xg(x)=Wg·xh(x)=Wh·x
(2)

(3)
式中:βj,i代表生成第j個Attention map矩陣區域時,模型對第i個位置的關注程度。
如何將Self-attention與FPN融合來降低環境對人臉檢測的干擾。第一部分是Self-attention機制一,如圖6所示,對應圖4中SMYOLO框架黃色的Self-attention機制。將MobilenetV1的DWConv14輸出特征圖(10×10×1024)作為Self-attention機制一的輸入,然后通過Self-attention輸出特征圖(10×10×256)。

圖6 Self-attention機制一
第二部分是Self-attention機制二,如圖7所示,Self-attention機制二的輸入是兩部分,第一部分是MobileNetV1中DWConv12的輸出特征圖(20×20×512),第二部分是Self-attention機制一模塊的輸出特征圖(10×10×256)。將特征圖(10×10×512)進行f(x) 和g(x) 的計算,并計算出Attention map,如圖7綠色部分。
Attention map是采用DWConv12輸出的特征圖計算出來的,相對于DWConv11輸出的特征圖語義信息強,本文用Attention map來聚焦人臉的特征,Attention集中在人臉,減小環境對人臉的影響。為了使Attention map發揮作用,將DWConv11的特征圖與經過h(x) 處理后的特征圖進行融合(*)(對應像素相加)。如圖7的黃色部分
(4)
式(4)是計算Attention map層的輸出,得到Self-attention feature maps的計算公式。其中,o代表最終的輸出,維度是C×N即C×N大小的一個自適應注意力的矩陣。h(xi)+X是上文中的步驟*。v(xi) 表示一個1×1大小的矩陣,維度是C×C。

圖7 Self-attention機制二(模塊一)
圖8是Self-attention機制二的第二模塊,原理與第一模塊一樣,不同的是輸入不同,模塊二的輸入分為兩個部分,第一部分是Self-attention第一模塊的輸出特性圖(20×20×128),第二部分是MobileNetv1的DWConv5的輸出特征圖(40×40×256)。

圖8 Self-attention機制二(模塊二)
2.4 DIoU損失函數
YOLOv3在計算置信度損失時使用的是IoU[14]損失函數,IoU表示預測目標邊界框和真實目標邊界框之間的重合程度,計算公式見式(5)
(5)
式中:A為預測邊界框的面積,B為真實邊界框的面積,IoU(A,B)表示A與B的交并比,即A與B面積的交集和A與B面積的并集的比值。可以發現IoU能夠很好反應預測邊界框和目標邊界框的重合程度,但是當二者相交時損失直接就變成0,這是我們不想看到的結果。為了避免在改進的模型中計算置信度損失時出現這種無法優化的情況,本文采用DIoU[15]作為邊界框回歸損失函數,公式見式(6)
(6)
式中:b是指預測目標邊界框的中心坐標,bgt是指真實目標邊界框的中心坐標,ρ代表兩個中心之間的歐氏距離的平方,即圖9中d的平方,c是指預測邊界框和真實邊界框的最小外接矩形的對角線的長度。由此可見DIoU損失對預測邊界框和真實邊界框之間的歸一化距離進行了建模,如圖9所示,在考率重合度的同時還考慮到兩者之間的中心距離和尺度,可以更快更穩定地進行回歸。因為考慮到了中心距離,即使在預測邊界框和真實邊界框不重合的情況下也能為回歸移動提供方向,這樣就避免了IoU為0時訓練發散,回歸收斂慢的問題。

圖9 DIoU計算參數
同時DIoU損失能夠直接最小化兩個邊界框之間的距離,因此收斂速度也更快,且對邊界框的尺度具有不變性,使預測邊界框回歸真實邊界框時定位更加準確。
從表2可知,DIoU在mAP上優于IoU,因此選擇DIoU作為邊界框回歸損失函數對模型的檢測性能是有很大提升的。

表2 IoU與DIoU損失函數對比
3 實驗與結果分析
3.1 實驗數據
本文用于模型訓練的人臉圖片來自大型人臉公開數據集WIDER FACE,由香港中文大學資訊工程學系多媒體實驗室制作,包含32 203張圖像共40多萬張人臉,涵蓋不同尺度、光照、表情、遮擋等不同類型的人臉數據,大部分數據環境復雜,人臉和小人臉眾多,是訓練和檢驗人臉檢測模型較為官方有效的數據集之一。本文在一開始訓練模型時還采用了LFW人臉數據集,LFW人臉數據集圖像尺寸固定,大部分圖像中只包含一張人臉且人臉特征十分明顯,相對于WIDER FACE而言識別簡單,用于一開始初步訓練模型非常合適。圖10為LFW和WIDER FACE數據集中的示例圖片。

圖10 LFW和WIDER FACE數據集中的示例
最終選取WIDER FACE和LFW數據集中15 494張圖像進行模型的訓練,訓練集和驗證集和測試集的比例按照7∶2∶1的比例在總圖像中隨機抽取,保證各類人臉圖像的平衡。
3.2 實驗環境及訓練參數
實驗訓練所采用的設備為NVIDIA GeForce RTX 2080Ti,CPU i7 9700 K,內存16 GB,操作系統為Ubuntu 18.04 64位,編譯環境/語言Pycharm2019.2/Python 3.7,使用Pytorch1.6框架進行深度學習,cuda版本10.1。
根據事先寫入用于訓練的.yaml超參數文件進行模型的訓練,初始學習率0.001,衰減系數0.0005,最小批量32。
3.3 評價標準
本實驗針對人臉檢測效率、準確度兩個方面,選取速度、召回率(Recall)、精度均值(average precision,AP)3個指標來評估各模型的人臉檢測表現。
召回率(Recall)是所有真實目標中,模型預測正確的目標比例,公式為
(7)
平均精度(AP)是P-R曲線下面積,P-R曲線即Precision-Recall曲線,Precision為查準率,表示模型預測的所有目標中,預測正確的比例。求解Precision的公式為
(8)
其中,TP表示IoU>0.5時檢測框的數量,同一個真實目標框只計算一次;FP表示IoU≤0.5的檢測框或者是檢測到同一個真實目標框的多余的檢測框的數量;FN表示沒有檢測到的真實目標框的數量。
檢測速度表示為每秒鐘處理圖像的數量,單位FPS。
3.4 實驗結果與分析
考慮到本文提出的改進網絡模型是用于人臉實時檢測的,在減少參數和計算量的同時要保留較高的檢測精度,故選擇YOLOv3-tiny、YOLOv3、Faster R-CNN、SSD-Lite作為對比模型。所有算法均在WIDER FACE和LFW共同構建的數據集上進行測試,測試對比結果見表3。

表3 不同算法結果對比
由表3可知,像Faster R-CNN這一two stage的大型網絡,在人臉檢測任務中雖然檢測速率低但是檢測精度非常高,YOLOv3作為平衡速度和精度的one stage模型代表,在人臉檢測任務中雖不落下風,但和本文改進的方法相比無論是精度還是速度都沒有任何優勢。剩下的兩個輕量級網絡,在檢測速度方面依然無人能敵,但是削減了網絡層數,模型整體結構簡單檢測效果方面達不到實際中的要求。本文的方法雖然檢測精度略低于Faster R-CNN,但是速度是它的兩倍多。與原方法相比在YOLOv3的基礎上替換了主干特征提取網絡,減少模型參數以及計算量更能滿足實際應用中檢測速度的需求,同時增加了SPP結構尺度不變的同時可提取不同尺寸的空間特征信息,提升模型的魯棒性,檢測速度低于兩個輕量級網絡也是因為在訓練后期mAP上升的同時能檢測出更多的人臉圖像。綜上所述,本文提出的方法更適合運用在人臉檢測的任務當中。
為了更明顯表示我們的方法更適合運用在人臉檢測任務中,選取了測試中的一些圖片進行檢測效果的分析,從上到下依次是原圖、YOLOv3-tiny的檢測結果、YOLOv3的檢測結果、本文的檢測結果。
從圖11看出,在小人臉眾多的場景下YOLOv3-tiny漏檢嚴重,且人臉置信度也是最低的,YOLOv3效果比YOLOv3-tiny較優,在右上方還是有3張人臉漏檢的情況,人臉置信度也有相應的提升,本文的算法只有最后一張小人臉漏檢,檢測效果非常強勁,因此可見本文改進的方法更適合用于人臉檢測任務當中。

圖11 各種方法的效果對比
4 結束語
本文提出了一種改進YOLOv3的輕量化人臉檢測方法。用MobileNetV1替代YOLOv3的主干特征提取網絡Drrknet-53,引入深度可分卷積,大幅減少網絡參數和計算量。增加了SPP結構,尺度不變的同時可提取不同尺寸圖像的空間特征信息,實現不同尺度的特征融合,并且使特征層的表達能力增強。Self-attention機制與FPN結構的融合,減少環境對檢測的干擾,使用DIoU損失函數加速模型收斂。實驗結果表明,相較于原算法YOLOv3,在公開人臉數據集WIDER FACE上mAP提高了9.0個百分點,檢測速度達到了61 FPS,滿足人臉檢測任務中的準確率和實時性。在今后的研究中,會從其它方面進一步優化我們的模型,使其速度更快精度更高,并且適應多種場景下的人臉檢測任務。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
