基于數據增強的侵徹引信準確層識別神經網絡方法
2022-03-21 11:37:22房安琪
探測與控制學報 2022年1期
房安琪,李 蓉
(西安機電信息技術研究所,陜西 西安 710065)
0 引言
現代戰爭中,大規模殺傷武器庫、地下指揮中心、多層建筑物、導彈發射井、飛機掩體等高價值目標的防護能力大幅增強,建筑物內部結構變化多樣[1],作為打擊這類硬目標的侵徹彈藥動能也在不斷提高,在高速侵徹多層硬目標時,侵徹彈內部的加速度傳感器獲取的過載中疊加了大量高頻振蕩信號,導致層與層之間彼此粘連,計層算法準確率下降甚至失效[2]。如何對多層粘連過載信號實現準確計層一直是國內外研究的熱點,目前的層識別研究主要集中在信號處理方面。如基于幅值識別的計層方法,該算法簡單易實現,但對高速侵徹和復雜結構多層目標及寬速度范圍的適應性不足。利用小波變換提取過載信號的小波系數[3],匹配濾波提取過載信號的包絡等方法相較于幅值識別算法進一步提高了計層的準確性,但需要計算多個中間過程,且在一定程度上依賴先驗參數,需針對不同戰斗部、不同靶板、不同工況設置不同閾值。文獻[4]采用時頻分析法研究彈體主軸方向加速度信號的Choi-Williams能量分布特征,提出以侵徹過程加速度信號的能量分布為依據的層識別方法。文獻[5]利用短時傅里葉變換對過載信號進行處理,通過分析頻率成分及梯度提取完成層識別。這兩種方法對復雜信號的識別能力較為精準,但均為事后分析非實時處理,難以應用到硬件電路。
本文針對此問題,提出基于數據增強的侵徹引信準確層識別神經網絡方法。與信號處理方法不同的是,深度學習具備自己獲取知識的能力,即從原始數據中提取模式識別的能力,能夠自主分析決策,解決涉及現實世界知識的問題。將神經網絡引入目標層識別算法,通過對侵徹多層粘連過載信號進行學習與訓練,自主認知戰斗部侵徹多層硬目標的過程,自適應調整模型參數,可以有效提升層識別算法的準確性,使引信獲得精確計層起爆控制能力。
1 數據增強
大量研究和實驗表明,神經網絡在擁有足量數據的情況下具有極其強大的非線性映射能力,但當數據量較少時,識別效果不理想,因此獲取大量數據是神經網絡工作的關鍵。然而由于侵徹試驗成本高昂,無法收集足夠多的過載信號來訓練神經網絡模型,而利用數據增強方法對已有樣本進行處理,可以顯著緩解訓練數據缺乏的問題。
本文將抗高過載電子數據傳感記錄器置入戰斗部,通過侵徹多層試驗方法獲取戰斗部侵徹多層硬目標的加速度信號,采用線性抽取與插值、添加自適應噪聲的方式將實測小樣本數據進行擴展。
1.1 線性抽取與插值
線性抽取與插值是豐富離散數據的有效方法,也是神經網絡數據增強的常用手段。過載信號作為隨機振動信號無法使用確定性的插值函數來擬合曲線,因此本文采取連續均勻插值法,計算相鄰兩點的均值進行數據填充,實現對實測過載信號的等倍數壓縮和擴展,例如將6 000點的數據插值為12 000點或者將6 000點的數據抽取為3 000點,將每條實測信號擴展為原數量的兩倍,實測信號與經過抽取和插值后的樣本對比如圖1所示。
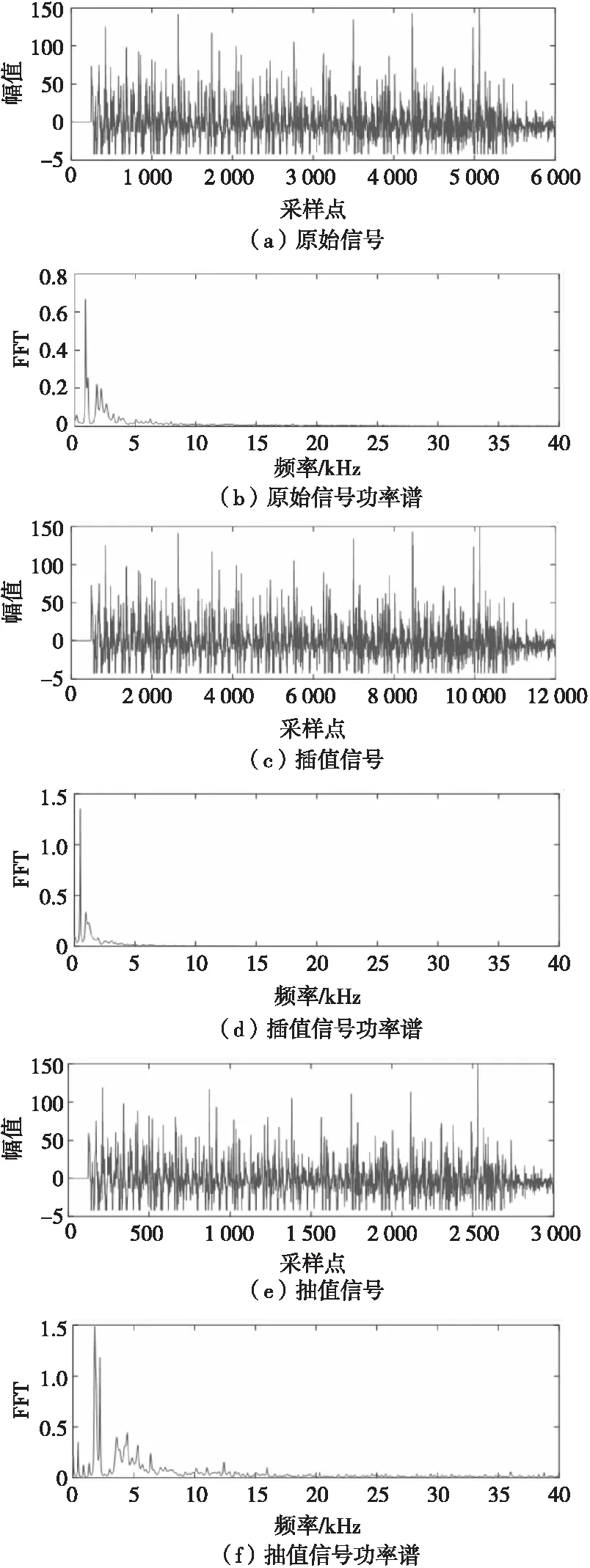
圖1 實測信號與經過抽取和插值后的樣本對比Fig.1 Samples of the measured overload signal after extraction and interpolation
從圖1可以看出過載數據在抽取和插值前后沒有顯著變化,在時域內保持了波形的一致性,信號功率隨頻率的變化趨勢相同,具有相似的頻譜特征,在擴展樣本的同時增加了數據多樣性。
1.2 添加自適應噪聲
文獻[6]發現神經網絡非常容易受到對抗樣本的攻擊,對抗樣本是指對原樣本產生一些人眼可能無法察覺的微小擾動,分類器卻會輸出完全不同的預測結果,甚至以高置信度錯誤分類。為提高神經網絡正確處理對抗樣本的能力,最近的一些工作在模型訓練階段向輸入的數據集中添加隨機噪聲[7],實現網絡正則化,從而增強模型的魯棒性;然而這些方法所添加的噪聲均服從同一分布,具有相同的均值和標準差,沒有考慮到神經網絡對不同數據的敏感度不同。因此,本文使用添加自適應噪聲的數據集訓練神經網絡,首先對每個過載信號樣本進行功率譜分析,在功率集中的地方添加較多噪聲,有效降低模型對序列變化的敏感性,提高神經網絡對抗擾動的能力,在敏感性較小即功率分散的地方添加較少噪聲,提高模型的識別精度。
圖2顯示了過載信號與添加普通隨機噪聲和自適應噪聲的不同。其中(a)為普通隨機噪聲,(b)為該隨機噪聲的功率譜估計,(c)為根據過載信號不同敏感度產生的自適應噪聲,(d)為該自適應噪聲的功率譜估計,(e)為原始過載信號,(f)為該原始信號的功率譜估計,(g)為將普通隨機噪聲添加到過載信號的樣本,(h)為添加隨機噪聲的功率譜估計,(i)為將自適應噪聲添加到過載信號的樣本,(j)為添加自適應噪聲的功率譜估計。
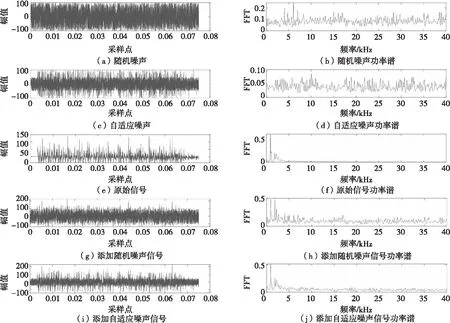
圖2 原始信號與添加普通隨機噪聲和自適應噪聲對比Fig.2 Comparison of the original signal with the addition of random noise and adaptive noise
從圖2可以看出,原始信號的中心頻率分布在1 kHz左右,其他諧波主要分布在(1.5, 2.5)kHz區間內,而添加隨機噪聲的信號中心頻率變為1 kHz和2 kHz兩個波峰,其他諧波分布區間變為(2.2, 10)kHz區間內,完全喪失了原始信號的頻譜特征,而添加自適應噪聲的信號中心頻率依然分布在1 kHz左右,其他諧波也分布在(1.5, 2.5) kHz區間內,在提高網絡對抗能力的前提下仍然保留了原始信號的特征,因此本文采用的自適應噪聲能夠更好地增強神經網絡的抗干擾能力,與此同時將每條實測信號擴展為原數量的5倍,實現數據擴充。
2 基于數據增強的侵徹引信準確層識別神經網絡方法
神經網絡是由具有適應性簡單單元組成的廣泛并行互連網絡,它的組織能夠模擬生物神經系統對真實世界物體作出的交互反應。神經網絡最基本的組成成分是神經元模型,如圖3所示,即上述的“簡單單元”[8]。
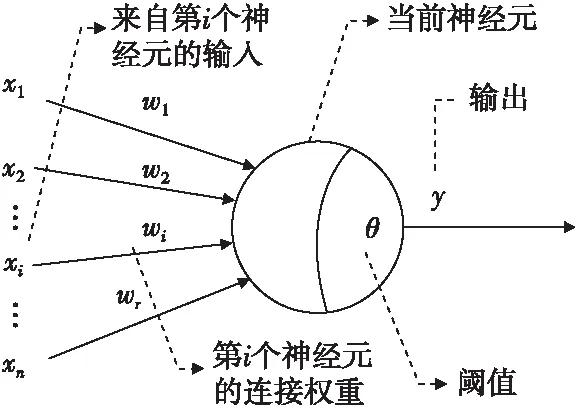
圖3 神經元模型Fig.3 Neuron model
神經元接收來自其他神經元傳遞的輸入信號x1,x2,…,xi,…,xn,這些輸入信號通過帶權重的連接w1,w2,…,wi,…,wn進行傳遞,然后將其與神經元閾值θ比較,通過激活函數處理產生輸出y:
(1)
其中,Relu函數是目前最常用的激活函數之一[9],表達式如下:
f(x)=max(0,x)
(2)
由式(2)可以看出,神經元在輸入負值的情況下不被激活,這意味著同一時間內只有部分神經元被激活,這種單側抑制的性質使神經網絡變得稀疏,極大提高了模型的計算效率。
將神經元的每個結點都與下一層所有結點相連就得到了神經網絡的全連接層,如圖4所示。
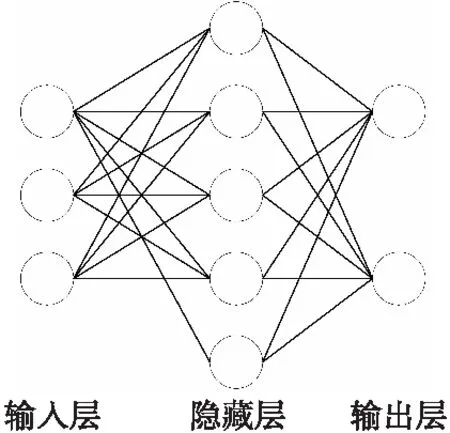
圖4 全連接層Fig.4 Fully connected layer
2.1 數據集
在深度學習中,數據集一般分為獨立的三部分:訓練集、驗證集、測試集,其中訓練集用于學習樣本數據,學習完畢后驗證集對模型進行準確率評估,測試集作為模型在學習與訓練過程中從未出現的數據,用于檢驗模型的泛化能力,也就是模型在全新數據上的識別能力。
本文從實測侵徹多層過載信號庫中抽取試驗數據187條,通過分析剔除不完整數據后用于建模的實測數據為162條,實驗室仿真數據412條,采用數據增強生成的數據1 031條,總數據集為1 605條,其中1 120條作為訓練集,485作為驗證集。
模型的輸入是經過歸一化后的序列數據,標簽為人工標記的層識別信號,具體而言,通過分析每條過載信號的包絡同時結合侵徹試驗信息在侵徹體穿出靶板至穿入下一層靶板的間隔內標記一個幅值為200的識別信號,其余時刻幅值均為0,如圖5所示。

圖5 訓練集中的樣本數據Fig.5 Data from training set
2.2 超參數選取
超參數是神經網絡訓練開始前人為設置的參數,而非模型經過訓練習得的參數。通常情況下需要對超參數進行不斷調試與優化,確定一組最優值以提高網絡的學習的能力和效率。超參數包括學習速率、優化器、網絡深度、隱藏單元數、Epoch等。
學習速率被認為是最重要的超參數,它決定了參數每次更新的幅度,如果學習速率太小,會使收斂過慢;如果學習速率太大,則會導致損失函數振蕩甚至使梯度下降法越過最低點進而發散。
通過選取不同學習速率,對比各學習速率的識別準確率后使用指數衰減式學習速率,曲線變化如圖6所示。初始學習速率α0=10-7,衰減步長T=1.0,衰減速率β=0.98,即:
(3)
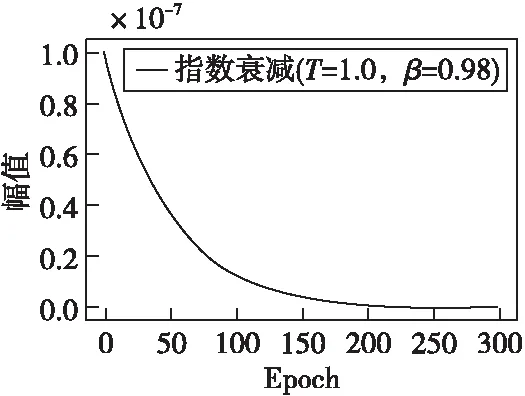
圖6 指數衰減學習速率曲線Fig.6 Exponential decay learning rate curve
神經網絡學習的目標是尋找合適的參數使損失函數盡可能小,解決這個問題的過程稱為最優化,解決這個問題使用的算法叫做優化器,一個好的優化器總能夠快速可靠地找到最小值,而不會陷入局部極小值、鞍點或高原區域。本文采用Adam優化器,它同時兼顧了Momentum優化器和RMSProp優化器的優點,使用跟蹤梯度平方和的方式在不同方向調整梯度,實踐效果非常好,是深度學習的常用選擇。
深度學習另一個重要的概念是Epoch,每學習一遍數據集,就稱為1個Epoch。神經網絡只運行一個Epoch是遠遠不夠的,而運行過多Epoch又會導致模型陷入過擬合問題,也就是模型只能在訓練數據中達到滿意效果而無法適應新數據。經過不同的嘗試后,Epoch=2 000時模型的學習效果最好。
2.3 層識別神經網絡模型
針對侵徹多層粘連過載信號特征建立神經網絡模型,網絡深度共六層,第一層是Flatten層,將輸入一維化;第二層到第五層為全連接(Dense)層,使用Relu函數激活,用于擬合層識別信號;最后一層為300個神經元的Dense層,即每300個點輸出一次預測結果,完整的層識別神經網絡模型如圖7所示。
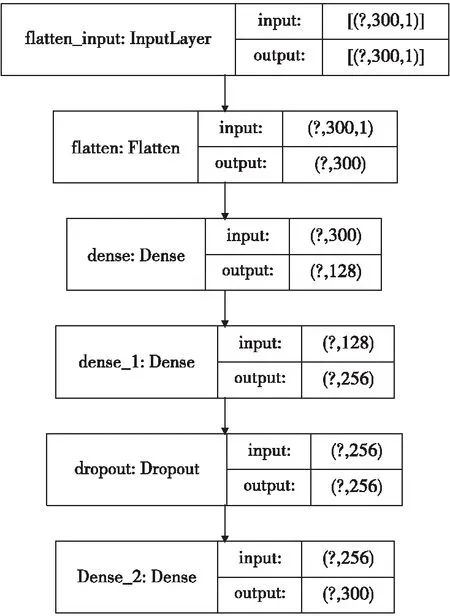
圖7 層識別神經網絡模型Fig.7 Layer recognition neural network model
2.4 識別實時性
假設神經網絡的可訓練參數為M,那么完成線下訓練后由Dense層構成的模型進行層識別需要運行的乘法指令為M個,加法指令為M-1個。本文構建的層識別模型參數數量如圖8所示,可訓練參數為148 652,因此運行的乘法指令為148 652個,加法指令為148 651個。若選用STM32F7系列芯片每次預測時間約為2.1 ms,能夠滿足層識別的實時性要求。
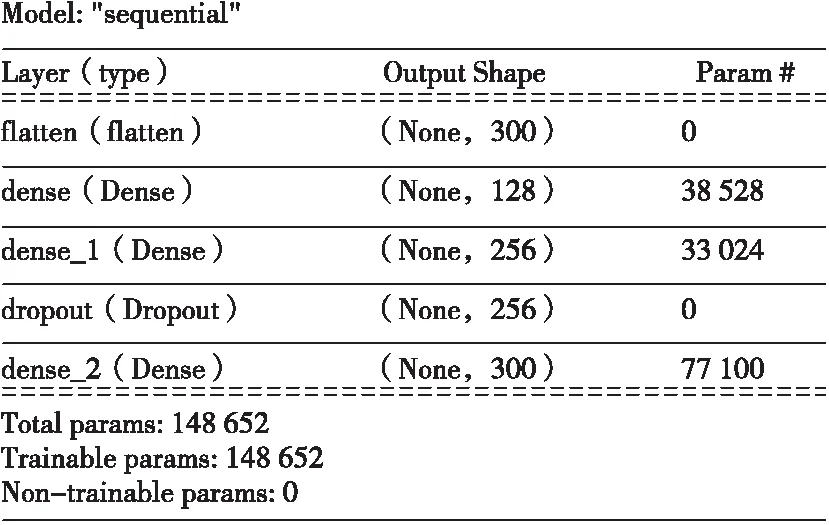
圖8 層識別神經網絡的參數量Fig.8 The number of parameters for layer recognition neural network
3 仿真驗證
在Anaconda科學計算平臺使用TensorFlow 2.0深度學習框架進行層識別神經網絡的訓練與驗證,選用MSE均方誤差作為損失函數評估模型的識別效果,其變化曲線如圖9所示,經過2 000個Epoch后,訓練集的損失約在18.452 2~19.058 3,驗證集的損失可達3以下,其中由幅值帶來的誤差占總損失的98.4%,而幅值誤差對計層準確度不產生影響,因此層識別誤差僅有1.6%。
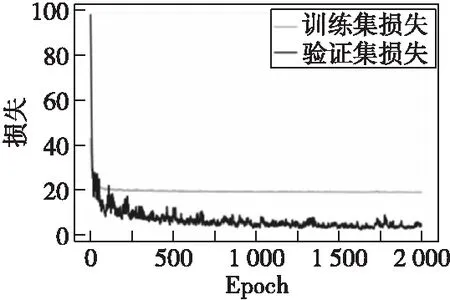
圖9 訓練集和驗證集的損失函數Fig.9 Loss function of training set and validation set
使用多組未曾在學習與訓練過程中出現的靶場實測過載信號組成測試集,模型輸出的層識別信號符合標簽信息,可以實現精確計層,其中一組復雜粘連過載層識別模型預測結果如圖10所示。
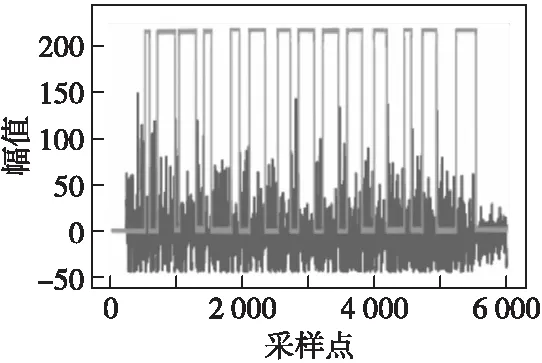
圖10 層識別神經網絡模型的預測結果Fig.10 Prediction results of layer recognition neural network model
4 結論
本文提出基于數據增強的侵徹引信準確層識別神經網絡方法,該方法針對粘連過載特征構建全連接神經網絡模型,通過對過載信號進行抽取、插值及添加自適應噪聲將實測小樣本數據擴展為較大樣本,實現數據增強,層識別神經網絡模型使用數據增強后的數據集進行學習與訓練,自主認知戰斗部侵徹多層硬目標的過程,自適應調整模型參數。仿真驗證結果表明,該方法不依賴先驗參數,能夠對不同靶板、不同戰斗部、不同工況下的侵徹多層過載信號實現準確計層。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
鴨綠江(2021年35期)2021-04-19 12:24:18
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
數學物理學報(2020年2期)2020-06-02 11:29:24
中國生殖健康(2019年3期)2019-02-01 06:12:26
光學精密工程(2016年6期)2016-11-07 09:07:19
鑿巖機械氣動工具(2016年3期)2016-03-01 04:00:25
海軍航空大學學報(2015年3期)2015-11-11 17:20:00
核科學與工程(2015年4期)2015-09-26 11:59:03
