近20年計算機與信息科學領域研究進展
2022-03-21 04:06:20李涵霄杜杏葉
知識管理論壇 2022年1期
李涵霄 杜杏葉



關鍵詞:《信息處理與管理》 ? ?IPM ? ?計算機與信息科學 ? ?主題分析
分類號:G201
引用格式:李涵霄, 杜杏葉. 近20年計算機與信息科學領域研究進展: IPM期刊主題分析[J/OL]. 知識管理論壇, 2022, 7(2): 24-36[引用日期]. http://www.kmf.ac.cn/p/272/.
1 ?引言
數字化、網絡化與智能化時代的到來,為計算機與信息科學領域的發展帶來了巨大沖擊,也使得相關研究迅速增多,研究主題發生變化。作為科研成果的主要載體和傳播平臺,科技期刊在學術交流中承擔著重要的使命[1]。對科技期刊載文進行主題分析,能夠更好地了解該學科領域的研究進展與演進特征。《信息處理與管理》(Information Processing and Management,IPM)于1963年創刊,其最初名為《信息存儲與檢索》(Information Storage and Retrieval,ISR),自1975年正式更名為IPM,并延續至今。根據SCI-JCR數據,該刊2020年的引用評分(CiteScore)為8.6,影響因子為6.222,在計算機科學與信息系統(COMPUTER SCIENCE,INFORMATION SYSTEMS)以及情報學與圖書館學(INFORMATION SCIENCE & LIBRARY SCIENCE)類別中均位列一區。IPM致力于發表計算機與信息科學交叉領域的前沿研究成果,在國內外計算機與信息系統界乃至圖書情報界均具有高影響力與高知名度,為推動領域進步做出了重要貢獻。因此,對IPM期刊的發文主題進行系統梳理,能夠在一定程度上反映計算機與信息科學領域的研究進展,展現IPM為領域發展所做出的學術貢獻。
已有學者針對IPM進行了主題分析。F. E. DeHart對IPM、JASIS(Journal of the American Society for Information Science)和JD(Journal of Documentation)3個期刊1987-1990年所發表論文的參考文獻進行分析,著重比較了引用專著的比例,發現IPM在1989-1990年引用專著最多的3個主題分別為信息存儲和檢索系統、人工智能、話語分析[2];M. Y. Tsay對1998-2008年JASIST(Journal of the American Society for Information Science and Technology)、IPM和JD 3個期刊進行文獻計量分析與比較,發現IPM引用期刊論文最多的3個主題分別為搜索、在線信息檢索、信息工作,引用書籍最多的3個主題分別為信息存儲和檢索系統、信息檢索、計算機算法[3];王曰芬等對2006-2015年《現代圖書情報技術》及IPM等國內外相似期刊的發文特征進行比較分析,發現信息檢索是IPM期刊最大的研究熱點,其他熱點還有用戶行為分析、文本挖掘算法、文本分類、語義分析等[4]。可以看出,此前研究均是將IPM與其他期刊進行比較分析,且大多是定量分析,而較少關注各個研究主題的內涵演變。因此,筆者對IPM近20年(2000-2020年)的發文主題進行系統梳理,以了解IPM期刊發文的主題側重與演進趨勢,為計算機與信息科學領域發展及相關研究提供參考,也為圖書情報領域提供有益借鑒。
2 ?數據與方法
2000-2020年間,IPM共刊發1 852篇研究論文。利用ScienceDirect全文數據庫將論文數據導出,形成可供統計分析的數據源。首先,對論文關鍵詞詞頻進行統計,繪制關鍵詞詞云圖(見圖1),發現研究熱點主要涉及信息檢索(information retrieval)、機器學習(machine learning)、自然語言處理(natural language processing)、查詢擴展(query expansion)、社交媒體(social media)、情感分析(sentiment analysis)、文本分類(text classification)、信息搜尋(information seeking)等主題。其次,提取論文標題與摘要,利用VOSviewer進行共現分析,得出共現網絡圖(見圖2),從圖2中可以明顯看出,研究主題主要分為三大類:信息檢索(information retrieval)、文本分析(text analysis)和用戶研究(user research)。最后,基于1 852篇研究論文,從信息檢索、文本分析和用戶研究三大類別出發,對IPM近20年的研究主題進行梳理,并比較不同時期的研究重點,得出主題演進趨勢。
3.1 ?第一大主題:信息檢索
信息檢索是20世紀50年代在國外興起的一門新興學科,主要研究的是信息的表示、存儲、組織與訪問[5]。在過去20年中,信息檢索一直是IPM期刊關注的重點,涉及的主題包括信息檢索模型(information retrieval model)、搜索引擎(search engine)、圖像檢索(image retrieval)等方面。
3.1.1 ?信息檢索模型
信息檢索模型指描述信息檢索中的文檔、查詢和它們之間關系(匹配函數)的數學模型[6],常用的檢索模型有布爾檢索模型、概率模型、向量空間模型、語言模型、排序模型等類型。IPM相關研究基本圍繞概率模型展開,如K. Sparck Jones等開發了信息檢索概率模型[7-8],該模型是對其團隊于1976年提出的概率模型的改進[9],也是目前最廣受認可的檢索模型,許多研究在該模型的基礎上進行改動,形成了較為普遍的應用形式,見公式(1)[10]:
公式(1)
其中,fi指檢索文檔中詞項i出現的次數,qfi指查詢中詞項i出現的次數,N指整個檢索文檔數據集合的大小,ri指包含詞項i的相關文檔的數量,ni指包含詞項i的文檔的數量,R指和查詢相關的文檔集合的大小,K、k1、k2均為根據經驗設定的超參數[10]。
其他學者也從多個角度出發構建了信息檢索概率模型,并進行了實驗測試。Z. B. Xu等開發了一種基于狄利克雷復合多項式(Dirichlet Compound Multinomial,DCM)分布的信息檢索概率模型,能夠實現高效檢索和準確排名[11];F. Dahak等針對XML信息檢索,建立了一個利用用戶期望來估計上下文重要性的概率模型,并通過實驗證明了其有效性[12]。此外,向量空間模型與排序模型也受到了廣泛討論,如X. Y. Tai等提出一種基于向量空間模型(VSM)的信息檢索模型,能夠利用用戶提供的相關信息來提高檢索性能[13];J. F. Guo等分析比較了神經排序模型的基本假設、設計原則和學習策略,并討論了學習索引、利用外部知識學習、利用可視化技術學習、利用語境學習、神經排序模型理解等未來發展趨勢[14]。整體而言,相關研究主要關注檢索模型的構建、測試、比較與改進,目的是提升信息檢索系統性能,實現更高精度的信息檢索。
3.1.2 ?搜索引擎
在搜索引擎方面,相關研究集中在搜索引擎的檢索性能評估、查詢擴展和相關反饋以及網頁排名算法等方面。關于檢索性能評估,L. Vaughan基于查準率和查全率的概念,提出一組測量方法,用于評估搜索引擎性能與穩定性,實驗結果表明該測量方法能夠有效區分搜索引擎性能[15];F. Can等認為人為評估搜索引擎檢索性能成本較高,因此引入一種自動搜索引擎評估方法,并通過實驗證明其評估結果與人為評估一致[16]。作為查詢優化的重要分支,查詢擴展主要通過用戶查詢日志與用戶相關反饋等來源中的信息,對用戶的查詢進行擴展,如H. Kim等提出了一種基于用戶查詢日志聚類的方法,能夠在一定程度上彌補用戶查詢和檢索系統間的詞匯鴻溝[17];S. Jung等以搜索引擎用戶的點擊數據作為隱式相關反饋的信息來源,討論了相關反饋的可靠性及其變化[18]。此外,查詢擴展還更加關注基于語義的相關反饋技術,以應對查詢和文檔間的語義鴻溝,如J. M. Wang等提出了一種結合相關匹配和語義匹配的偽相關反饋,以提高反饋文檔質量[19]。在網頁排名算法方面,在PageRank、HITS和OPIC等主流算法的基礎上,眾多學者開發了更高效的排名算法,如A. M. Z. Bidoki等提出了一種基于強化學習的DistanceRank算法,將兩個網頁間的“平均點擊次數”定義為距離,距離較小的頁面能夠具有更高的排名,實驗結果表明該算法在網頁排名和抓取調度方面優于其他算法[20]。
3.1.3 ?圖像檢索
在文本檢索的基礎上,以圖像、音頻、視頻作為檢索對象的多媒體檢索技術逐漸發展起來,IPM相關研究則主要集中在圖像檢索領域。2000年后,圖像檢索從基于文本的圖像檢索(Text-based Image Retrieval,TBIR)向基于內容的圖像檢索(Content-based Image Retrieval,CBIR)發展。CBIR的基礎即是對圖像的顏色、紋理、形狀等內容特征進行選擇、提取和表示[21],相關研究也基本從該角度出發。如P. W. Huang等基于紋理相似度,提出了兩種紋理特征表示方法(CSG-vector和EDP-string),并據此設計了高效的圖像檢索系統[22];T. C. Lu等針對圖像的顏色特征,以顏色分布、平均值和標準差表示圖像的全局特征,以圖像位圖表示圖像的局部特征,以提高圖像檢索的準確性[23]。然而,基于內容的圖像檢索也存在難以跨越的語義鴻溝[24],為此,基于語義的圖像檢索技術逐漸發展起來,S. Pandey等便提出了一種用于語義分類分層圖像數據庫的語義和圖像檢索系統,使得圖像被映射到多維特征空間的同時,圖像語義也能夠通過聚類和索引被表示出來,最終實現所需語義和對應圖像的高效檢索[25]。
3.2 ?第二大主題:文本分析
文本分析即對文本內容進行表示和特征提取,使得文本能夠被計算機識別與處理,從而判斷文本主題以及文本提供者的態度和情緒。IPM中有關文本分析的研究主要集中在文本挖掘(text mining)、情感分析(sentiment analysis)、知識圖譜(knowledge graph)等方面。
3.2.1 ?文本挖掘
針對潛藏于電子形式中的大量文本數據,文本挖掘能夠從中抽取事先未知的、可理解的、最終可用的知識,并運用這些知識更好地組織信息以支持參考利用[26-27]。IPM相關研究基本圍繞文本分類與文本聚類展開。其中,文本分類指將文檔組織為預先定義好的類別,通常使用機器學習算法[28],如A. Elnagar等比較了常用的阿拉伯語文本分類深度學習模型,并提出了一個完全基于深度學習模型的分類方法[29]。同時,文本分類針對的文本特征也從簡單的詞、短語和句子發展為語法和語義特征,如A. Mohasseb等針對問答系統中的問題分類,提出了一種基于語法的分類框架,能夠有效區分不同的問題類型[30];Z. Kastrati等提出了一種語義豐富的文檔表示模型,能夠對金融文檔進行自動分類[31]。在文本聚類方面,眾多學者提出了各種聚類算法以優化聚類性能,如G. B. Hu等開發了一種基于K-Means聚類算法的半監督聚類方法,能夠對聚類過程進行約束[32];C. L. Chen等提出了一種基于頻繁模糊項集的分層聚類方法,旨在提高分層聚類精度[33];還有學者提出了用于文檔聚類的概率模型與算法,并通過實驗證明其性能優于此前廣泛使用的模型與算法[34-35]。此外,也有研究從應用場景出發,探討了文本挖掘在信息檢索[36]、用戶服務[37]、專利分析[38]、話題識別[39]等領域的應用方法與實踐效果。
3.2.2 ?情感分析
論壇、博客等各類社交媒體的發展以及以大眾點評為代表的點評網站的出現,為大眾提供了情緒交流與消費點評的開放式平臺[40],也因此產生了大量的針對產品、服務、事件、話題等實體的觀點、情感、評價、態度與情緒[41]。情感分析,或稱觀點挖掘,便是利用自然語言處理和文本挖掘技術,對這些帶有情感色彩的主觀性文本進行分析、處理和抽取的過程[42]。IPM中的情感分析研究主要以社交媒體為依托平臺,從用戶發布內容或評論中分析其觀點和情緒,如A. Balahur等與S. M. Mohammad等以Twitter為例,分析了推文中的情感、情緒、目的、風格以及相應的情感分析系統[43-44];A. Severyn等針對YouTube上大量的用戶生成內容,構建了能夠應對新領域或新語言的觀點挖掘模型,并通過實驗進行了驗證[45]。還有學者分析了用戶對產品或服務的評價,以挖掘其中的態度與情緒,如M. Al-Smadi等提出了一種基于監督機器學習的方法,能夠對酒店評論進行情緒分析[46]。在情感分析的過程中,研究者構建了許多用于不同場景的情感分析模型,如A. Kumar等提出了一種用于文本和視覺社交數據中細粒度情感分析的深度學習模型[47];Z. Mahmood等則開發了羅馬烏爾都語語料庫,并以此為依據開發了一種用于挖掘情緒和態度的深度學習模型[48]。
3.2.3 ?知識圖譜
知識圖譜本質上是揭示實體/概念之間語義關系的語義網絡[49]。IPM相關研究主要涉及知識圖譜技術、知識圖譜構建與知識圖譜應用3個方面。在知識圖譜技術方面,眾多學者以知識實體的抽取為主,探討了知識圖譜中的知識抽取與知識表示,如H. C. Cho等研究了多段表示的命名實體識別[50];L. Derczynski等描述了一個Twitter實體消歧數據集,并對推文中的命名實體識別和消歧進行了實證分析[51];X. Tang等提出了一種多源知識表示學習的模型,以結合實體描述、層次類型和文本關系,提高知識表示有效性[52]。在知識圖譜構建方面,相關研究主要以語料庫為基礎,構建基于語義關系的知識圖譜,如I. Bounhas等從阿拉伯語的有聲語料庫中構建了一個形態語義知識圖譜,利用上下文知識來推斷實體之間的語義依賴關系,并評估了文檔索引和查詢擴展的集中使用場景[53]。在應用方面,知識圖譜可以應用至檢索系統、問答系統、大數據分析等領域,如D. F. Li等提出了一種級聯模型,能夠同時考慮語義特征和圖譜特征,并設計了不同的級聯結構,以用于知識推理和檢索[54];S. Shin等針對問答系統中咨詢問題的含義,設計了一種謂詞約束詞典,并提出了基于該種謂詞約束的問答系統,能夠提高搜索準確性[55];F. Janssens等選擇了圖書情報領域的5本期刊,對其2002-2004年間刊載的近千篇文獻進行了計量分析,利用知識圖譜繪制了可視化術語網絡[56]。
3.3 ?第三大主題:用戶研究
對用戶的信息獲取、查尋、利用等行為進行研究,有助于信息服務機構更具針對性地改進信息服務系統性能,提升服務質量[57]。信息搜尋行為(information seeking behavior)、用戶生成內容(user generated content)、個性化服務與人機交互(personalized service & human-computer interaction)是用戶研究主要關注的主題。
3.3.1 ?信息搜尋行為
信息搜尋行為指個體為滿足某些目標需求而有目的地搜尋信息,除包括普遍意義上的信息搜索外,信息搜尋更側重于滿足整個信息需求的完整過程,探索用戶搜尋行為背后的原因、影響因素、用戶特征和個人差異等方面[58]。許多學者針對不同類型的用戶,分析了其信息搜尋行為的特征,如S. Makri等通過對27位律師的信息搜尋行為進行分析,提出了對Ellis信息搜尋行為模型的改進[59];H. R. Jamali等對物理和天文學研究人員的信息搜尋行為進行了調查,揭示了不同學科在信息搜尋行為上的差異,并發現跨學科領域更有可能使用通用搜索工具來獲取信息[60];M. Lykke等調查了醫生的信息搜尋行為,發生多數醫生能夠利用系統特征和搜索策略生成結構良好的查詢[61]。此外,隨著社會水平的不斷提高,人們對健康信息的需求也逐漸增多,健康信息行為受到了更加廣泛關注,相關研究從不同角度著手分析了健康信息行為。如針對健康信息需求,W. J. Pian等系統梳理了消費者健康信息需求理論,指出未來應關注的社會和情感維度[62];針對健康信息提供方,X. F. Zhang等探討了醫生在網絡平臺分享健康信息的動機,發現除物質動機外,職業動機起著主要作用[63];針對健康信息獲取方,I. Huvila等研究了中老年人的健康信息行為偏好和動機,并將其與年輕人和老年人的健康信息行為進行了比較[64]。還有研究對健康信息規避行為進行了分析[65],以促進人們對健康信息的搜尋。
3.3.2 ?用戶生成內容
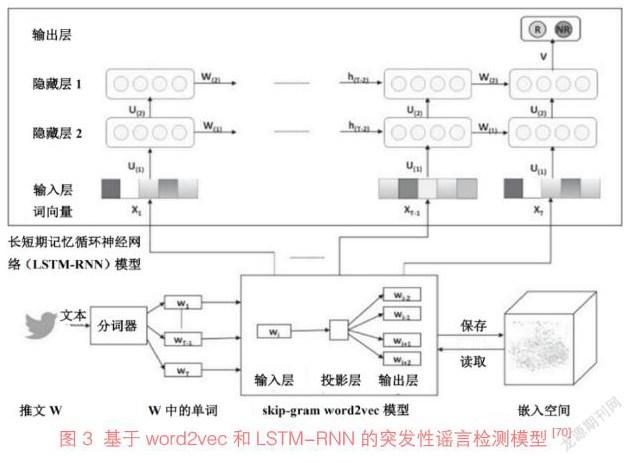
用戶生成內容是隨著Web 2.0興起而發展起來的一種網絡信息資源創作與組織模式,指用戶以各種形式在網絡上創作的文字、圖片、視頻等內容[66]。IPM相關研究較少直接討論用戶生成內容的理論基礎,而是將其作為觀點挖掘、情感分析、輿情管理等領域研究的數據來源來進行分析。如A. Severyn等對YouTube上的用戶生成內容進行了觀點挖掘[45];Y. D. Ge等探討了用戶生成內容中的情緒對股市的影響[67];L. F. Li等研究了自然災害發生后社交媒體上公眾的負面情緒,以及具有大量追隨者的用戶的發言對轉發數量的影響[68]。此外,社交媒體上的用戶生成內容還可能會造成謠言和虛假新聞的傳播,學者們對謠言的識別和檢測進行了研究。Y. H. Liu等提出了一種基于長短期記憶網絡(Long Short-Term Memory,LSTM)和最大池化(max pooling)的模型,通過捕獲轉發內容、傳播者和傳播結構的動態變化來識別謠言傳播過程,并利用新浪微博數據進行了驗證[69];S. A. Alkhodair等則提出了一種基于word2vec和長短期記憶循環神經網絡(LSTM-RNN)的突發性謠言檢測模型(見圖3),并利用Twitter中的數據進行了實驗,證明該模型在查準率、查全率及F1值等方面的性能優于其他模型[70]。
3.3.3 ?個性化服務與人機交互
在個性化服務方面,相關研究主要圍繞推薦系統的個性化展開。J. Wang等提出了社交媒體個性化框架,并構建了一個排名模型,能夠在標簽和內容推薦中集成用戶的標記歷史,使得系統建議與用戶偏好保持一致[71];F. M. Belem等以對象和用戶為中心,對個性化標簽推薦進行了改進,并將其與以對象為中心的推薦方法進行了比較[72];S. Renjith等討論了旅游推薦系統的發展,梳理了從通用搜索引擎到個性化推薦系統再到基于情境感知的個性化推薦系統的演變[73]。在人機交互方面,除討論用戶和互聯網資源[74]、信息檢索系統[75]的交互,以及人機交互中的情感[76]等方面外,眼動跟蹤技術也是廣受關注的主題。如M. J. Cole等利用眼動跟蹤技術,對用戶的交互式信息獲取過程進行了建模,以預測用戶的知識水平[77];M. Clark等基于眼動跟蹤數據,分析了用戶對電子郵件文本的交互方式[78];B. Hilberink-Schulpen等通過眼動跟蹤方法調查了招聘廣告中外語的使用是否會影響用戶的注意力和觀看方式[79]。
4 ?IPM主題演進趨勢
在不同的時間段內,IPM的研究主題有著不同的側重。為了解不同時期的研究重點,并從整體上分析論文主題的演進趨勢,筆者將2000-2020年的論文劃分為4個時間段,對每個時間段內的關鍵詞詞頻進行統計與可視化,制作不同時期的詞云圖(見圖4)。在4個時間段內,信息檢索(information retrieval)始終是最主要的研究主題,這與IPM期刊的定位密切相關。然而,隨著時間的推移,在2016-2020年間,信息檢索的研究熱度下降,社交媒體(social media)、情感分析(sentiment analysis)、深度學習(deep learning)、機器學習(machine learning)、自然語言處理(natural language processing)、文本挖掘(text mining)等主題詞的頻率增高,其中社交媒體以33次的詞頻,超過了信息檢索(31次),成為研究熱度最高的主題詞。
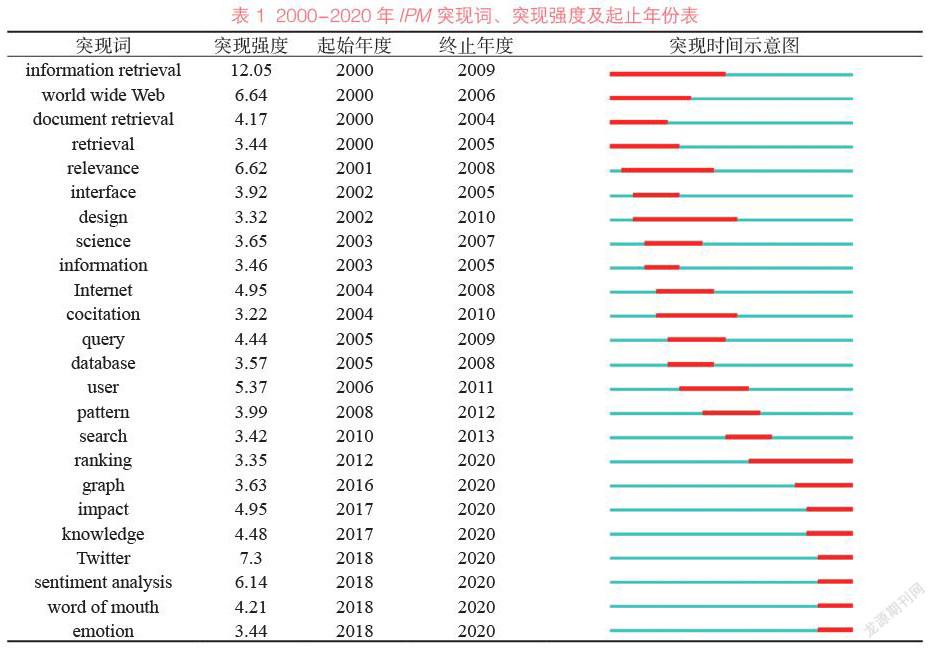
利用CiteSpace軟件進行突現詞探測(burst detection),以展現研究主題的發展脈絡和演進趨勢,并預測未來的研究方向。2000-2020年IPM突現詞、突現強度及起止年份見表1,從表1中可以看出,在近20年的時間中,共有24個突現詞,其中“信息檢索”(information retrieval)的研究熱度從2000年開始,持續到2009年;“排名”(ranking)的研究熱度從2012年開始,持續到2020年。其他持續時間較長(5年以上)的突現詞還有:萬維網(world wide Web)、檢索(retrieval)、相關性(relevance)、設計(design)、共引(cocitation)、用戶(user)等。目前的研究熱點及前沿包括:排名(ranking)、圖像(graph)、影響(impact)、知識(knowledge)、Twitter、情感分析(sentiment analysis)、口頭語言(word of mouth)、情緒(emotion)等。這與此前的分析結果大致吻合,即信息檢索在很長時間內一直是IPM主要關注的內容,同時由于搜索引擎的發展離不開網頁排名算法的更新與優化,因此排名算法在持續較長時間的研究熱度后,仍然是目前的研究前沿。此外,研究主題的演變還呈現出從文本到圖像、從信息到知識的特征。從表現形式來看,信息檢索的對象逐漸脫離文本的限制,而開始關注具有更豐富信息的圖像、音頻與視頻,這些多媒體載體除包含基本的文本信息外,還能夠傳達出更多內容特征,從而便于對其進行識別、檢索與挖掘。從組織方式來看,相比于信息而言,知識更加結構化,也更具利用價值。我國《新一代人工智能發展規劃》也提到要重點突破知識加工、深度搜索和可視交互核心技術[80],意味著基于知識的分析、挖掘及知識圖譜構建將成為計算機與人工智能領域未來的重點發展方向。社交媒體與情感分析也是重要趨勢之一,社交媒體上用戶生成的海量文本信息與行為數據,為情感分析與用戶行為研究提供了必要的數據基礎,使得相關研究在計算機與人工智能技術的應用下得到了飛速發展。
從期刊專輯也可以看出IPM關注的重點主題及其變化。在2010年以前,專輯主題基本圍繞信息檢索展開,例如在2000年的“基于網絡的信息檢索研究”(Web-based information retrieval research)專輯中,期刊編輯提到,互聯網的發展擴大了信息檢索的研究范圍,研究人員開始逐漸關注網絡信息檢索以及信息檢索系統的交互[81]。同時,在2000-2004年間,國際計算機學會信息檢索領域會議(ACM Special Interest Group on Information Retrieval,ACM SIGIR)連續舉辦了五屆信息檢索中的數學/形式化方法研討會,證明了在信息檢索中使用數學和形式化方法的重要性,IPM也因此選編了相關論文,形成“信息檢索中的數學模型設計、公式化和解釋”(Model design, formulation and explanation in information retrieval using mathematics)專輯。步入新世紀后,互聯網的迅猛發展、信息技術的更新迭代,以及數學統計方法的引進,為信息檢索研究提供了源源不斷的新動力,推動了研究內容向更加深入化發展,研究方法向更加技術化轉變。
互聯網的迅猛發展還帶來了爆炸式增長的信息資源,而繁雜的文檔信息中則可能包含許多具有重要價值的潛在知識,在傳統的文本處理技術與工具不能滿足新的用戶需求的情況下,基于人工智能的文本挖掘方法應運而生,能夠對浩瀚的文本資源進行有效的挖掘與利用[82]。同時,隨著Facebook與Twitter分別于2004年與2006年成立,社交媒體一躍成為便捷的交流工具和強大的自媒體平臺,用戶生成內容也因此成為網絡信息資源的主要產生方式。由用戶生成的信息資源難免摻雜許多個人的觀點和情緒,這些主觀性的言論大多會涉及社會熱點事件或對產品/服務的消費評價,對此,情感分析迅速發展起來,并在輿情監測與商業營銷等領域得到了廣泛應用。針對文本挖掘和情感分析,IPM也制作了相關的專輯,如“管理和挖掘多語言文檔”(Managing and mining multilingual documents)、“社交和表達媒體中的情緒和情感”(Emotion and sentiment in social and expressive media)、“文本中的敘事提取”(Narrative extraction from texts)、“從社交網絡中挖掘有價值的情報”(Mining actionable insights from social networks)等。總的來說,IPM各個研究主題之間是互相聯系的,主題的演進也與網絡技術的發展、社交媒體的興起有著密不可分的關系,同時,人工智能等新興技術的出現也為計算機與信息科學領域帶來了新的機遇。
5 ?結語
筆者通過詞云圖與共現網絡圖的繪制,將IPM近20年的研究主題劃分為信息檢索、文本分析、用戶研究三大類。在信息檢索方面,相關研究從信息檢索模型的構建到搜索引擎與排名算法,全方位地討論了信息檢索的理論與方法,同時推進了圖像檢索技術的語義化發展。在文本分析方面,文本挖掘是主要的研究方向,在此基礎上,社交媒體中的情感分析成為近期的研究熱點,以知識圖譜為依托的知識研究與分析也得到了持續的發展和應用。在用戶研究方面,新型冠狀病毒肺炎疫情發生后,健康信息搜尋、謠言識別與傳播的相關研究受到更多關注,服務系統的個性化與人機交互的研究則凸顯了以用戶為中心的信息服務理念。
IPM的主題演進主要呈現出3種特征: ? ?①始終以信息檢索為核心主題。信息檢索及以信息檢索為基礎的內容檢索始終是IPM重點關注的主題。②從文本與信息分析向多媒體與知識分析轉變。一方面,研究對象從文本信息向包含更多內容的多媒體信息拓展;另一方面,人工智能等新興技術的發展,推動了信息分析向知識分析升級。③對用戶情感的深入分析與挖掘。社交媒體上的用戶生成內容催生了用戶情感分析,使得用戶研究向更深層次發展。
從主題分析結果來看,IPM刊載論文關注的是計算機與信息科學領域的重點問題,使用的也是前沿的計算機技術與數學統計方法,能夠從側面展現出該領域在國際上的學術研究與實踐現狀。然而,以單個期刊來反映整個學科領域的進展仍然具有局限性,后續研究可以對更多高影響力期刊進行計量研究與主題分析,以更全面地把握該學科領域的演化規律。
參考文獻:
初景利.高端交流平臺建設需要創新學術交流模式[J].智庫理論與實踐, 2021, 6(1): 7-9.
DEHART F E. Monographic references and information science journal literature[J]. Information processing & management, 1992, 28(5): 629-635.
TSAY M Y. A bibliometric analysis and comparison on three information science journals: JASIST, IPM, JOD, 1998–2008[J]. Scientometrics, 2011, 89(2): 591-606.
王曰芬, 靳嘉林.比較分析《現代圖書情報技術》近10年發文特征與發展趨勢[J].現代圖書情報技術, 2016(9): 1-16.
焦麗.我國信息檢索研究綜述[J].情報探索, 2007(6): 11-14.
王斌.信息檢索導論[M].北京: 人民郵電出版社, 2010.
SPARCK JONES K, WALKER S, ROBERTSON S E. A probabilistic model of information retrieval: development and comparative experiments Part 1[J]. Information processing & management, 2000, 36(6): 779-808.
SPARCK JONES K, WALKER S, ROBERTSON S E. A probabilistic model of information retrieval: development and comparative experiments Part 2[J]. Information processing & management, 2000, 36(6): 809-840.
ROBERTSON S E, SPARCK JONES K. Relevance weighting of search terms[J]. Journal of the American Society for Information Science, 1976, 27(3): 129-146.
龔慶雄. 基于實體的信息檢索模型研究[D].武漢: 華中師范大學, 2020.
XU Z B, AKELLA R. Improving probabilistic information retrieval by modeling burstiness of words[J]. Information processing & management, 2010, 46(2): 143-158.
DAHAK F, BOUGHANEM M, BALLA A. A probabilistic model to exploit user expectations in XML information retrieval[J]. Information processing & management, 2017, 53(1): 87-105.
TAI X Y, REN F, KITA K. An information retrieval model based on vector space method by supervised learning[J]. Information processing & management, 2002, 38(6): 749-764.
GUO J F, FAN Y X, PANG L, et al. A Deep Look into neural ranking models for information retrieval[J]. Information processing & management, 2020, 57(6): 102067.
VAUGHAN L. New measurements for search engine evaluation proposed and tested[J]. Information processing & management, 2004, 40(4): 677-691.
CAN F, NURAY R, SEVDIK A B. Automatic performance evaluation of Web search engines[J]. Information processing & management, 2004, 40(3): 495-514.
KIM H, SEO J Y. High-performance FAQ retrieval using an automatic clustering method of query logs[J]. Information processing & management, 2006, 42(3): 650-661.
JUNG S, HERLOCKER J L, WEBSTER J. Click data as implicit relevance feedback in Web search[J]. Information processing & management, 2007, 43(3): 791-807.
WANG J M, PAN M, HE T T, et al. A Pseudo-relevance feedback framework combining relevance matching and semantic matching for information retrieval[J]. Information processing & management, 2020, 57(6): 102342.
BIDOKI A M Z, YAZDANI N. DistanceRank: an intelligent ranking algorithm for Web pages[J]. Information processing & management, 2008, 44(2): 877-892.
孫君頂, 原芳.基于內容的圖像檢索技術[J].計算機系統應用, 2011, 20(8): 240-244.
HUANG P W, DAI S K. Design of a two-stage content-based image retrieval system using texture similarity[J]. Information processing & management, 2004, 40(1): 81-96.
LU T C, CHANG C C. Color image retrieval technique based on color features and image bitmap[J]. Information processing & management, 2007, 43(2): 461-472.
圖像檢索:基于內容的圖像檢索技術[EB/OL].[2021-09-17].https: //www.cnblogs.com/king-lps/p/11407206.html.
PANDEY S, KHANNA P, YOKOTA H. A semantics and image retrieval system for hierarchical image databases[J]. Information processing & management, 2016, 52(4): 571-591.
袁軍鵬, 朱東華, 李毅, 等.文本挖掘技術研究進展[J].計算機應用研究, 2006(2): 1-4.
肖建國.試論文本挖掘及其應用[J].圖書館學研究, 2008(4): 22-24.
ALTINEL B, GANIZ M C. Semantic text classification: a survey of past and recent advances[J]. Information processing & management, 2018, 54(6): 1129-1153.
ELNAGAR A, AL-DEBSI R, EINEA O. Arabic text classification using deep learning models[J]. Information processing & management, 2020, 57(1): 102121.?
MOHASSEB A, BADER-EL-DEN M, COCEA M. Question categorization and classification using grammar based approach[J]. Information processing & management, 2018, 54(6): 1228-1243.
KASTRATI Z, IMRAN A S, YAYILGAN S Y. The impact of deep learning on document classification using semantically rich representations[J]. Information processing & management, 2019, 56(5): 1618-1632.
HU G B, ZHOU S G, GUAN J H, et al. Towards effective document clustering: a constrained K-means based approach[J]. Information processing & management, 2008, 44(4): 1397-1409.
CHEN C L, TSENG F S C, LIANG T. Mining fuzzy frequent item sets for hierarchical document clustering[J]. Information processing & management, 2010, 46(2): 193-211.
ZHU S F, TAKIGAWA I, ZENG J. Field independent probabilistic model for clustering multi-field documents[J]. Information processing & management, 2009, 45(5): 555-570.
FERSINI E, MESSINA E, ARCHETTI F. A probabilistic relational approach for Web document clustering[J]. Information processing & management, 2010, 46(2): 117-130.
SOULIER L, TAMINE L, SHAH C. MineRank: leveraging users’ latent roles for unsupervised collaborative information retrieval[J]. Information processing & management, 2016, 52(6): 1122-1141.
KUCUKYILMAZ T, CAMBAZOGLU B B, AYKANAT C, et al. Chat mining: predicting user and message attributes in computer-mediated communication[J]. Information processing & management, 2008, 44(4): 1448-1466.
TSENG Y H, LIN C J, LIN Y I. Text mining techniques for patent analysis[J]. Information processing & management, 2007, 43(5): 1216-1247.
PONS-PORRATA A, BERLANGA-LLAVORI R, RUIZ-SHULCLOPER J. Topic discovery based on text mining techniques[J]. Information processing & management, 2007, 43(3): 752-768.
洪江濤, 陳榴寅, 黃沛.第三方點評網站對餐飲企業品牌形象與消費者行為的影響研究——以大眾點評網為例[J].財貿經濟, 2013(10): 108-117.
LIU B. Sentiment analysis and opinion mining[M]. San Rafael: Morgan & Claypool Publishers, 2012.
馬力, 宮玉龍.文本情感分析研究綜述[J].電子科技, 2014, 27(11): 180-184.
MOHAMMAD S M, ZHU X D, KIRITCHENKO S, et al. Sentiment, emotion, purpose, and style in electoral tweets[J]. Information processing & management, 2015, 51(4): 480-499.
BALAHUR A, PEREA-ORTEGA J M. Sentiment analysis system adaptation for multilingual processing: the case of tweets[J]. Information processing & management, 2015, 51(4): 547-556.
SEVERYN A, MOSCHITTI A, URYUPINA O, et al. Multi-lingual opinion mining on YouTube[J]. Information processing & management, 2016, 52(1): 46-60.
AL-SMADI M, AL-AYYOUB M, JARARWEH Y, et al. Enhancing aspect-based sentiment analysis of Arabic Hotels’ reviews using morphological, syntactic and semantic features[J]. Information processing & management, 2019, 56(2): 308-319.
KUMAR A, SRINIVASAN K, CHENG W H. Hybrid context enriched deep learning model for fine-grained sentiment analysis in textual and visual semiotic modality social data[J]. Information processing & management, 2020, 57(1): 102141.
MAHMOOD Z, SAFDER I, NAWAB R M A, et al. Deep sentiments in Roman Urdu text using recurrent convolutional neural network model[J]. Information processing & management, 2020, 57(4): 102233.
漆桂林, 高桓, 吳天星.知識圖譜研究進展[J].情報工程, 2017, 3(1): 4-25.
CHO H C, OKAZAKI N, MIWA M, et al. Named entity recognition with multiple segment representations[J]. Information processing & management, 2013, 49(4): 954-965.
DERZYNSKI L, MAYNARD D, RIZZO G, et al. Analysis of named entity recognition and linking for tweets[J]. Information processing & management, 2015, 51(2): 32-49.
TANG X, CHEN L, CUI J, et al. Knowledge representation learning with entity descriptions, hierarchical types, and textual relations[J]. Information processing & management, 2019, 56(3): 809-822.
BOUNHAS I, SOUDANI N, SLIMANI Y. Building a morpho-semantic knowledge graph for Arabic information retrieval[J]. Information processing & management, 2020, 57(6): 102124.
LI D F, MADDEN A. Cascade embedding model for knowledge graph inference and retrieval[J]. Information processing & management, 2019, 56(6): 102093.
SHIN S, JIN X, JUNG J, et al. Predicate constraints based question answering over knowledge graph[J]. Information processing & management, 2019, 56(3): 445-462.
JANSSENS F, LETA J, GLANZEL W, et al. Towards mapping library and information science[J]. Information processing & management, 2006, 42(6): 1614-1642.
張一涵, 袁勤儉.我國用戶信息行為研究進展[J].國家圖書館學刊, 2014, 23(6): 91-98.
靳榮林. 大學生自主學習情境下的信息搜尋行為影響因素探究[D].保定: 河北大學, 2019.
MAKRI S, BLANDFORD A, COX A L. Investigating the information-seeking behaviour of academic lawyers: from Ellis’s model to design[J]. Information processing & management, 2008, 44(2): 613-634.
JAMALI H R, NICHOLAS D. Interdisciplinarity and the information-seeking behavior of scientists[J]. Information processing & management, 2010, 46(2): 233-243.
LYKKE M, PRICE S, DELCAMBRE L. How doctors search: a study of query behaviour and the impact on search results[J]. Information processing & management, 2012, 48(6): 1151-1170.
PIAN W J, SONG S J, ZHANG Y. Consumer health information needs: a systematic review of measures[J]. Information processing & management, 2020, 57(2): 102077.
ZHANG X F, GUO F, XU T X, et al. What motivates physicians to share free health information on online health platforms?[J]. Information processing & management, 2020, 57(2): 102166.
HUVILA I, ENWALD H, ERIKSSON-BACKA K, et al. Anticipating ageing: older adults reading their medical records[J]. Information processing & management, 2018, 54(3): 394-407.
JOHNSON J D. Health-related information seeking: is it worth it?[J]. Information processing & management, 2014, 50(5): 708-717.
趙宇翔, 范哲, 朱慶華.用戶生成內容(UGC)概念解析及研究進展[J].中國圖書館學報, 2012, 38(5): 68-81.
GE Y D, QIU J N, LIU Z Y, et al. Beyond negative and positive: exploring the effects of emotions in social media during the stock market crash[J]. Information processing & management, 2020, 57(4): 102218.
LI L F, WANG Z Q, ZHANG Q P, et al. Effect of anger, anxiety, and sadness on the propagation scale of social media posts after natural disasters[J]. Information processing & management, 2020, 57(6): 102313.
LIU Y H, JIN X L, SHEN H W. Towards early identification of online rumors based on long short-term memory networks[J]. Information processing & management, 2019, 56(4): 1457-1467.
ALKHODAIR S A, DING S H H, FUNG B C M, et al. Detecting breaking news rumors of emerging topics in social media[J]. Information processing & management, 2020, 57(2): 102018.
WANG J, CLEMENTS M, YANG J, et al. Personalization of tagging systems[J]. Information processing & management, 2010, 46(1): 58-70.
BELEM F M, MARTINS E F, ALMEIDA J M, et al. Personalized and object-centered tag recommendation methods for Web 2.0 applications[J]. Information processing & management, 2014, 50(4): 524-553.
RENJITH S, SREEKUMAR A, JATHAVEDAN M. An extensive study on the evolution of context-aware personalized travel recommender systems[J]. Information processing & management, 2020, 57(1): 102078.
WANG P L, HAWK W B, TENOPIR C. Users’ interaction with World Wide Web resources: an exploratory study using a holistic approach[J]. Information processing & management, 2000, 36(2): 229-251.
KUMARAN G, ALLAN J. Adapting information retrieval systems to user queries[J]. Information processing & management, 2008, 44(6): 1838-1862.
LOPATOVSKA I, ARAPAKIS I. Theories, methods and current research on emotions in library and information science, information retrieval and human-computer interaction[J]. Information processing & management, 2011, 47(4): 575-592.
COLE M J, GWIZDKA J, LIU C, et al. Inferring user knowledge level from eye movement patterns[J]. Information processing & management, 2013, 49(5): 1075-1091.
CLARK M, RUTHVEN I, HOLT P O, et al. You have e-mail, what happens next? tracking the eyes for genre[J]. Information processing & management, 2014, 50(1): 175-198.
HILBERINK-SCHULPEN B, NEDERSTIGT U, VAN MEURS F, et al. Does the use of a foreign language influence attention and genre-specific viewing patterns for job advertisements? an eye-tracking study[J]. Information processing & management, 2016, 52(6): 1018-1030.
中華人民共和國國務院.國務院關于印發新一代人工智能發展規劃的通知[EB/OL].[2021-10-26].http: //www.gov.cn/zhengce/content/2017-07/20/content_5211996.htm.
SPINK A, QIN J. Introduction to the special issue on Web-based information retrieval research[J]. Information processing & management, 2000, 36(2): 205-206.
郭飛. 文本挖掘方法探討及應用[D]. 成都: 成都理工大學, 2006.
作者貢獻說明:
李涵霄:數據調研,撰寫論文初稿;
杜杏葉:提出選題,修改論文及定稿。
Abstract: [Purpose/significance] This paper analyzes the themes of papers published in Information Processing and Management from 2000 to 2020, in order to know the thematic focus and evolution trends of IPM, and provide references for the development and related research of computer and information science. [Method/process] Firstly, based on 1852 research papers in the full-text database of ScienceDirect, this paper counted and visualized the titles, abstracts and keywords of the papers to classify the thematic categories. Then, this paper analyzed the research themes of each category systematically. At last, it compared the thematic focus in different periods and analyzed thematic evolution trends. [Result/conclusion] IPM mainly focuses on three themes of information retrieval, text analysis and user research, and presented evolution characteristics in general: information retrieval as the core theme, transform from text and information analysis to multimedia and knowledge analysis, and in-depth analysis and mining of user sentiments.
Keywords: Information Processing and Management ? ?IPM ? ?computer and information science ? ? thematic analysis
3900500589273
