云邊協同的調控云數據質量優化
2022-03-17 03:27:00李大鵬李立新楊清波劉金波
電力系統及其自動化學報 2022年3期
關鍵詞:服務
李大鵬,李立新,楊清波,劉金波,張 杰,劉 東
(1.電力調度自動化技術研究與系統評價北京市重點實驗室(中國電力科學研究院有限公司),北京 100192;2.國家電網有限公司國家電力調度控制中心,北京 100031;3.國網天津市電力公司,天津 300010)
近年來,以高可靠、易擴展、資源共享等為特點的云計算技術,在越來越多的領域得以應用。為此,國家電網公司電力調控中心規劃建設了物理分布、邏輯統一的調控云平臺,構建了跨調度機構的“1個國(分)主導節點+N個省(地)協同節點”的兩級部署調控云體系[1-3],目標是實現調控云平臺資源靈活調配、服務高效集成、應用便捷開發、數據智能利用,推動調度自動化系統由“分析型”向“智能型”轉變。
然而,在調控云建設過程中,接入的數據種類和數據量呈爆發式增長,為云中心數據處理帶來了巨大的壓力。針對云中心面臨的困境,邊緣計算作為一種新型計算范式被提出[4-5],并逐漸成為適應物互聯應用需求的新興計算模式。云邊協同計算模型中的邊緣設備具有計算和分析的能力,通過在網絡的邊緣執行計算,在實現整體計算能力擴展的同時,又能夠有效地降低網絡帶寬和云中心計算、存儲資源的占用。因此,越來越多的科研工作者開始研究云邊協同技術在電網領域的應用[6-8]。文獻[9]利用云邊協同數據處理結構的電力物聯網架構,建立了一種新的集中—分布聯合控制式電力信息物理系統CPPS(cyber power physical system)模型,提高了控制結構的優越性。文獻[10]通過云邊交互協議、規則引擎等模塊的設計,在邊緣側實現了統一智慧物聯體系“多元感知、多態接入、統一模型、統一物聯”的目標。文獻[11]針對傳統的傳感信息獲取處理方式存在數據良莠不齊、數據缺失、格式不統一的問題,通過引入云邊協同技術,就地實現數據的處理與判決,提高了獲取數據的質量。但云邊協同技術在調控領域的研究尚未完全成熟。
本文基于調控云平臺,在深入分析調控數據管理及質量優化應用需求的基礎上,研究了云邊協同關鍵技術,設計了應用于電網調控領域的調控云廣域云邊協同總體架構,實現了云邊協同的數據管理和質量優化。實際應用結果表明,云邊協同技術的應用解決了網絡帶寬占用過大、數據時效性不強的問題,緩解了調控云中心的計算、存儲壓力,同時調控云協同節點的數據質量也得以有效提升。
1 調控數據管理及質量提升應用需求
隨著國網調控云建設的深入推進,調控云平臺上已積累了大量的模型數據、運行數據、管理數據、外部數據等,數據類型多樣化加劇,數據量呈指數級增長,數據處理時效性要求增強。以某省級協同節點為例,每天全電壓等級的量測數據量約6億條,約32 GB,1年所需的存儲空間約12 TB。按照傳統云中心集中存儲模式,目前13個省級協同節點一年所需的云中心存儲空間約為150 TB。后期協同節點數量擴充至全網27個省調,則一年所需的云中心存儲空間約320 TB。另外,對于主配網模型信息融合已有相關研究[12],部分省級協同節點也在試點主配網一體化融合應用,對于主配網數據質量提升[13]提出了更高的要求。
面對如此海量的數據,在資源有限的情況下,所有的終端數據都傳輸到云中心會使得網絡帶寬負載急劇增加,復雜的網絡環境和較長的傳輸路徑也會造成很長的處理時延,數據消息堆積情況嚴重,從長遠角度考慮,云中心數據存儲壓力和數據服務壓力過大。這就導致了無法實時地為云中心傳輸數據,難以支撐云中心快速決策。
在電網調控領域,云計算適用于非實時、長周期數據、全局業務決策場景,而邊緣計算在實時性、短周期數據、本地業務決策等場景有不可替代的作用。其技術應用的對比分析如表1所示。

表1 云計算與邊緣計算適用場景對比Tab.1 Comparison of applicable scenarios between cloud computing and edge computing
邊緣計算模式作為云計算的拓展和延伸,是云中心所需高價值數據的采集和初步處理單元,可以更好地支撐云端應用[14-16];反之,云計算通過大數據分析優化輸出的業務規則或模型可以下發到邊緣側,邊緣計算基于新的業務規則或模型運行。如何將兩者更好地結合起來,搭建一個高效率、智能化的云邊協同計算平臺,解決廣域管理和協同等問題,提升廣域范圍內數據、服務、資源狀態的協調感知和協同共享能力,已經成為該研究領域主要關注的熱點。
基于調控云廣域分布式部署的特點,借鑒廣域面向服務(wide area SOA)技術[17],深入研究全網調控云及新一代調控系統廣域資源及信息協同交互需求,建立調控云廣域協同平臺支撐技術體系,突破傳統自動化系統局域控制技術,實現資源全方位安全共享、集中管控和彈性解耦,滿足電網運行的整體性對系統的一體化協調控制的需求[18-19]。
2 關鍵支撐技術
結合調控業務生產組織模式,調控云遵循與“統一調度、分級管理”原則相適應的分級部署模式,構建跨調度機構的兩級部署體系,通過廣域綜合數據網進行連接,在模型數據和業務層面存在大量的消息、服務和任務交互,因此需要借鑒互聯網技術,結合調控網絡特點,構建底層支撐技術,打通兩級之間的消息和服務通道。
2.1 廣域服務交互技術
調控云通過服務總線及廣域服務代理機制進行主導節點和協同節點間的各類服務協同交互。內部服務的請求、響應在本節點內部完成;廣域服務請求統一由廣域服務代理集群進行轉發,如圖1所示,具體流程包括:主導節點廣域服務客戶端先向本地出口代理發送服務請求,出口服務代理接收到請求后向協同節點入口服務代理發起請求,協同節點入口服務代理接收到請求后通過服務總線調用相應的廣域服務并將服務結果返回給入口服務代理,入口服務代理再將服務結果返回主導節點的出口服務代理,出口服務代理最后將服務結果返回給主導節點廣域服務客戶端。
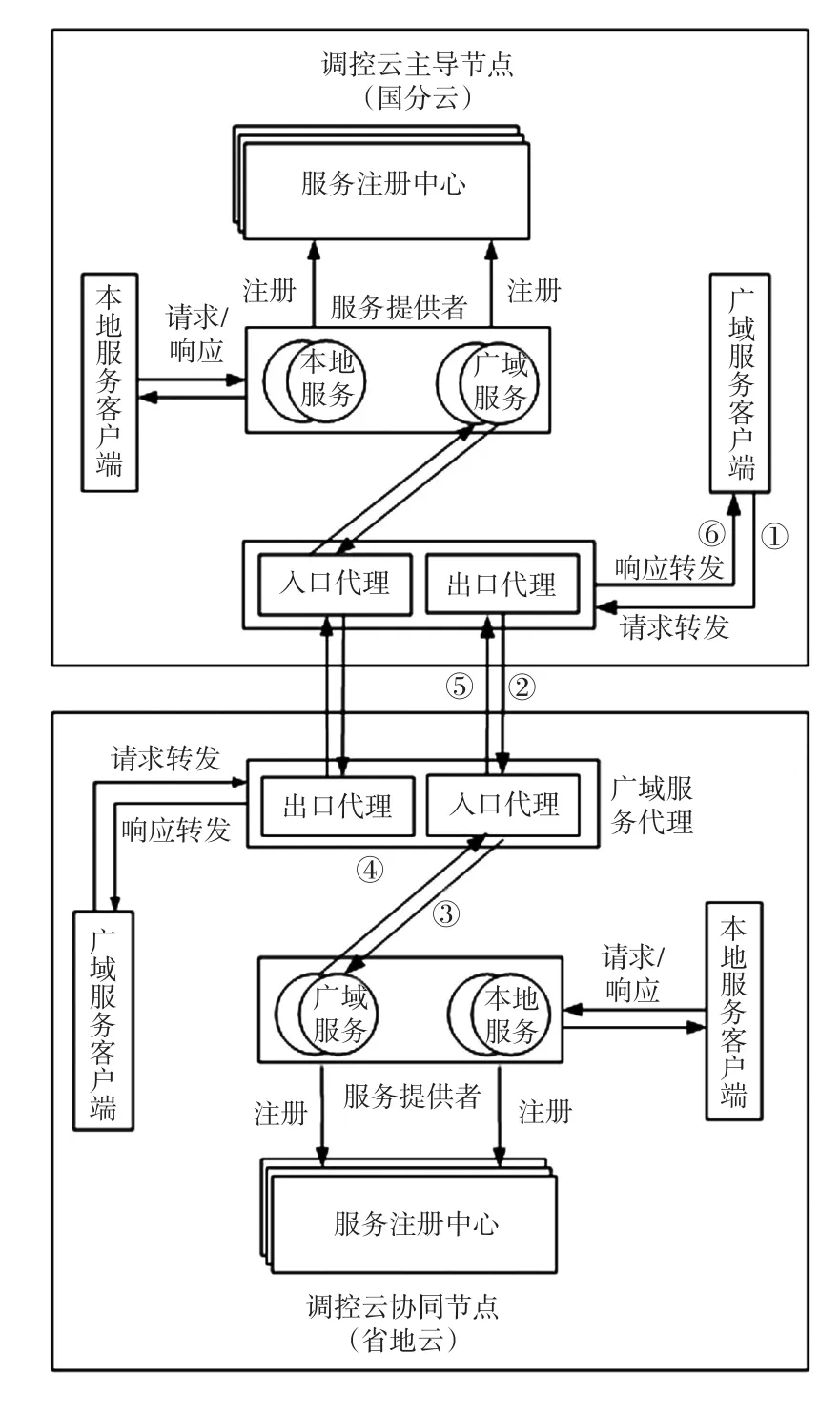
圖1 廣域服務交互架構Fig.1 Interaction architecture of wide area service
2.2 廣域消息交互技術
調控云通過消息總線進行消息的即時通信。廣域消息傳輸通過廣域消息代理來實現,消息代理以主備模式部署在調控云各節點邊界的通信代理服務器上,負責廣域范圍的消息轉發,完成消息跨節點的實時推送。如圖2所示,本文以主導節點某應用向協同節點某應用發送消息為例,說明消息傳輸流程:協同節點應用向消息管理中心訂閱消息主題;主導節點應用將廣域消息發送給本端廣域消息代理;廣域消息代理根據各協同節點與消息主題的訂閱關系,將其加入到對應節點的發送隊列中,發送給對端廣域消息代理;協同節點消息代理收到消息后,將消息發送給本節點內的應用,從而完成消息跨廣域網的即時傳輸。
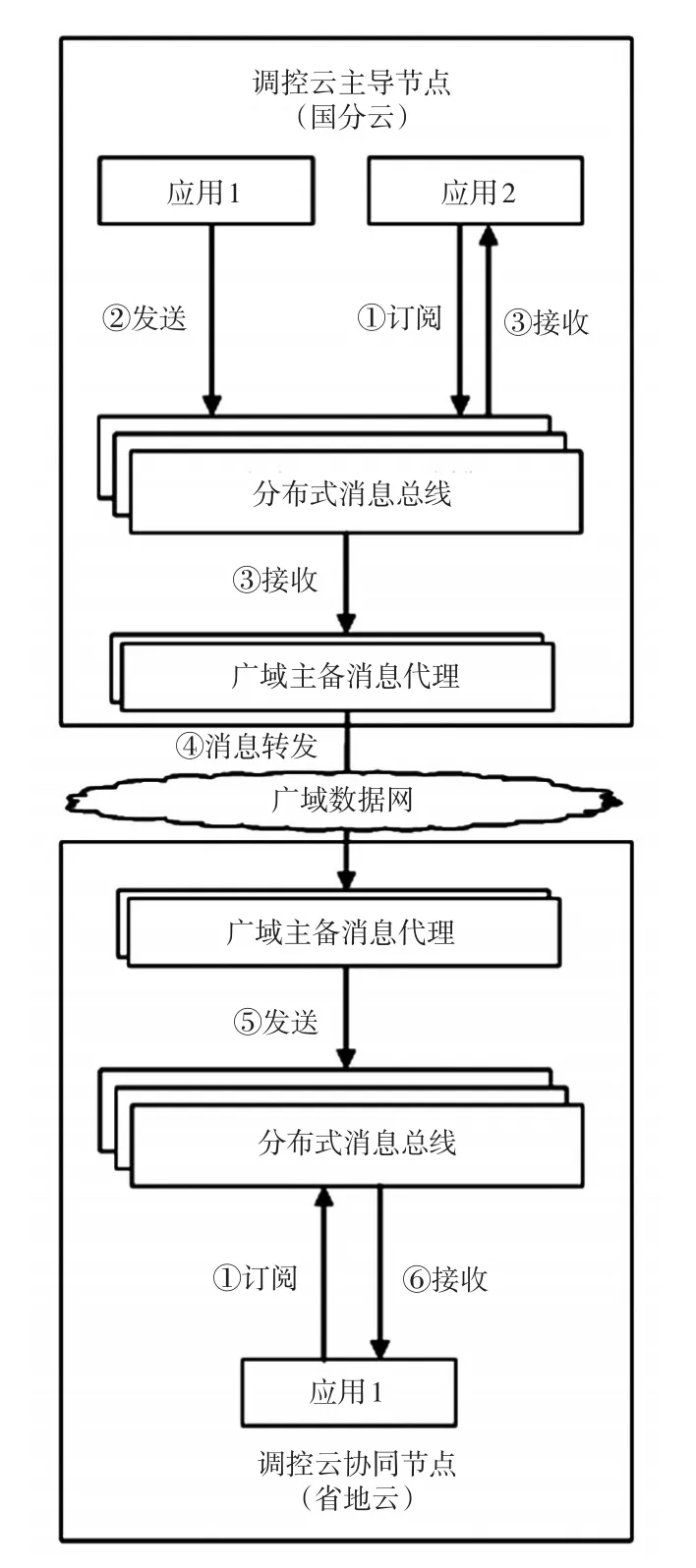
圖2 廣域消息交互架構Fig.2 Interaction architecture of wide area message
2.3 廣域任務調度技術
基于廣域云邊協同架構,調控云的數據質量優化功能被拆分為多個子任務,可借助服務編排工具對子任務進行組合并實現協同調度。廣域任務調度采用微服務化、廣域服務編排、標準模型構建等技術,實現兩級任務之間的便捷協作,進而快速、靈活組裝成數據質量優化的業務場景,降低應用實現復雜度,提升服務的復用度。廣域任務調度由服務注冊中心、服務編排頁面、服務編排文件、流程文件編譯、流程執行引擎等功能組成,如圖3所示。主導節點和協同節點間的任務調度、注冊中心數據同步通過廣域消息總線和廣域服務總線進行交互。
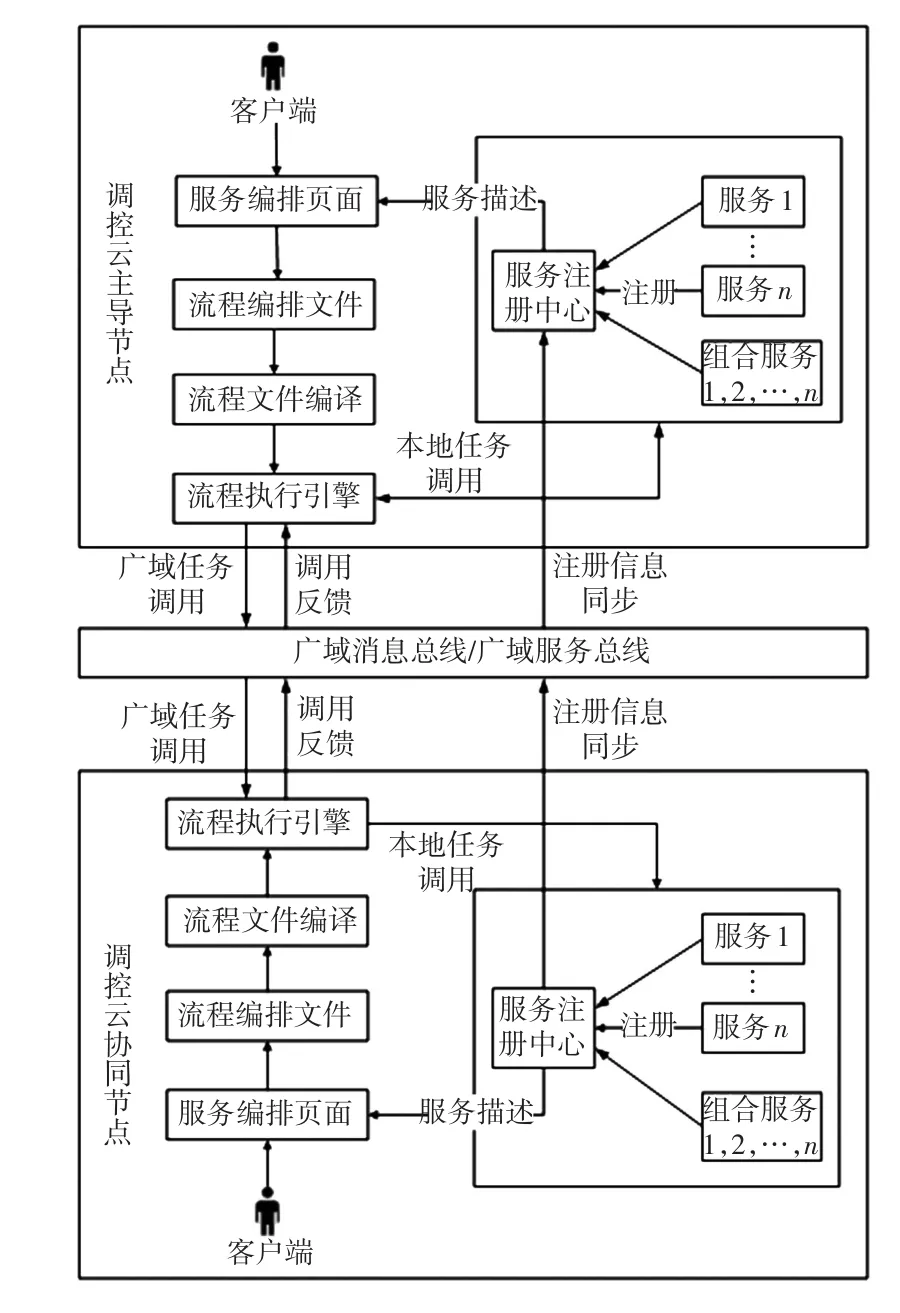
圖3 廣域任務調度架構Fig.3 Architecture of wide area task scheduling
3 廣域云邊協同架構設計
3.1 調控云架構
調控云是面向電網調度業務的云服務平臺,基于虛擬化、分布式及服務化等云技術理念,形成資源虛擬化、數據標準化、應用服務化的調控技術支撐體系,其架構如圖4所示。
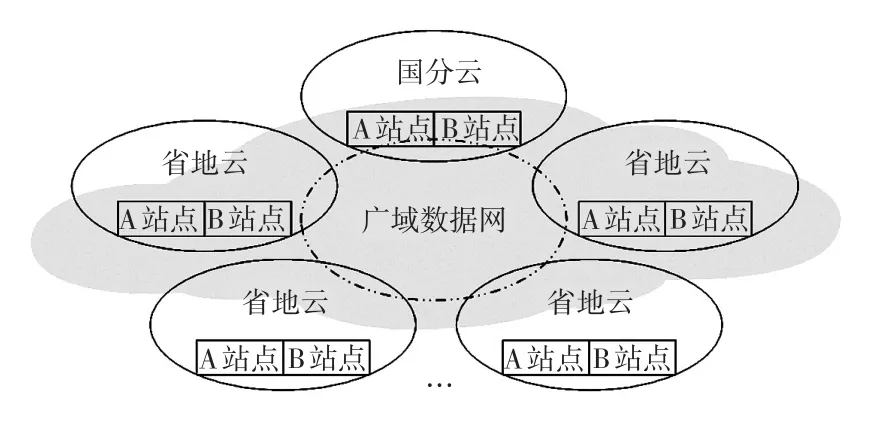
圖4 調控云體系架構Fig.4 Architecture of dispatching and control cloud
國分云作為主導節點,負責管理、控制各協同節點的運行,并實現與各協同節點的互聯和信息交換;省地云作為協同節點,配合主導節點進行數據歸集和匯聚。
3.2 廣域云邊協同架構
調控云按主導節點、協同節點、源數據端三層架構設計。基于調控云的總體架構和邊緣計算的理念,本文設計了基于調控云的廣域云邊協同架構,如圖5所示,該架構包含調控云主導節點(云)、協同節點(邊)和源數據端(端)三層,其中調控云主導節點(云)和協同節點(邊)通過廣域數據網相連,源數據端(端)和電網采集設備通過本地局域網相連。該架構充分利用了調控云協同節點(邊)的計算資源和存儲資源,緩解了調控云中心的計算壓力、存儲壓力和廣域數據網的帶寬壓力,實現了廣域云邊協同計算。
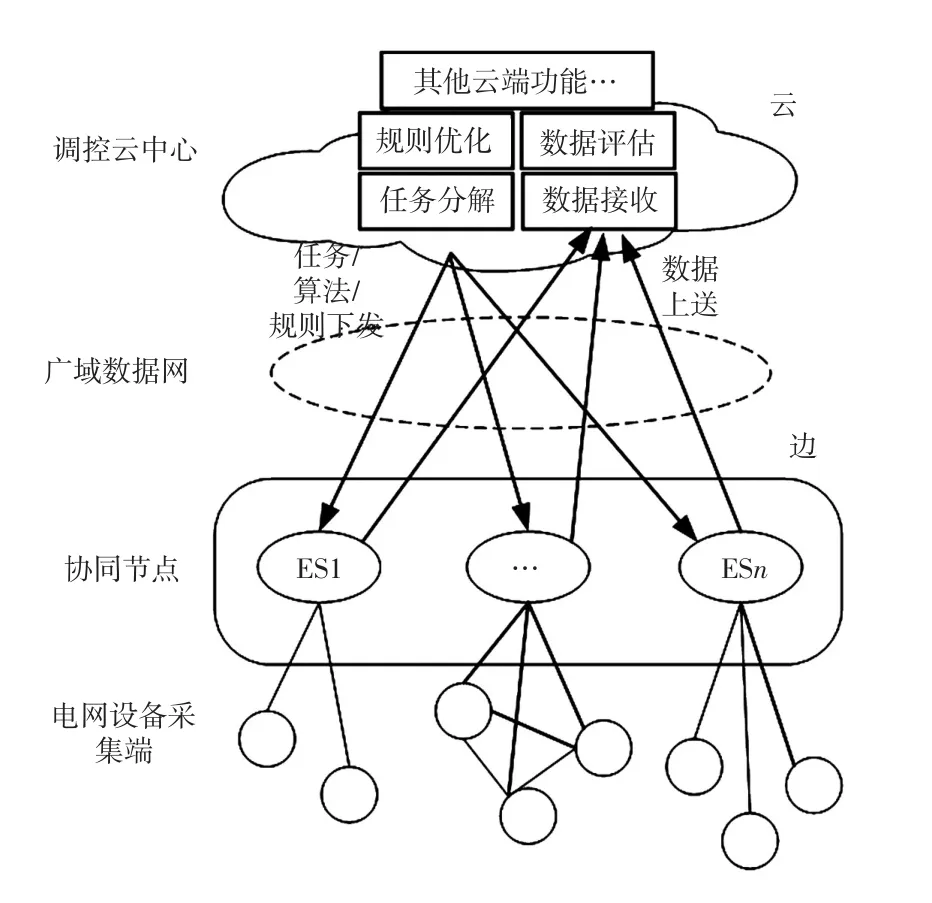
圖5 基于調控云的廣域云邊協同架構Fig.5 Wide area cloud-edge collaborative architecture based on dispatching and control cloud
基于廣域云邊協同架構,以電網采集數據的清洗、上送任務分解及協同為例進行分析,綜合考慮任務分解策略、單任務數據量、計算時間、網絡帶寬占用等性能指標,云中心將任務拆分為n個子任務,子任務間不存在耦合關系,任務定義為X={xi},任務在邊緣處理時間定義為Te={tei},任務在云中心處理時間定義為Tc={tci},單任務處理前數據量D0={D0i},處 理 后 數 據 量D1={D1i},其 中i={1 ,2,…,n}。
以協同處理的任務處理時間最優、占用網絡資源最小定義目標函數,具體如下。
(1)首先初始化任務分解策略。
α=[α1,α2,…,αn],αj=(0 ,1),表示任務在邊緣執行;β=[β1,β2,…,βn],βj=(0 ,1),表示任務在云中心執行;其中α⊕β=1,代表任務xi要么在邊緣節點執行,要么在云中心執行,且任務必須執行。
(2)根據任務分解策略定義優化函數。
(3)綜上優化目標。
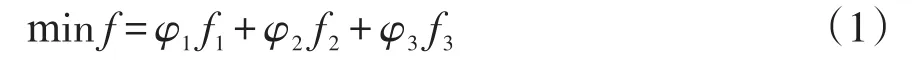
式中,φ1+φ2+φ3=1,代表處理時間和占用網絡資源的權重分配。
基于上述優化目標,采用基于啟發式規則的模擬退火算法,通過迭代優化的方式,得到任務分配的近似全局最優解,其算法實現流程如圖6所示。
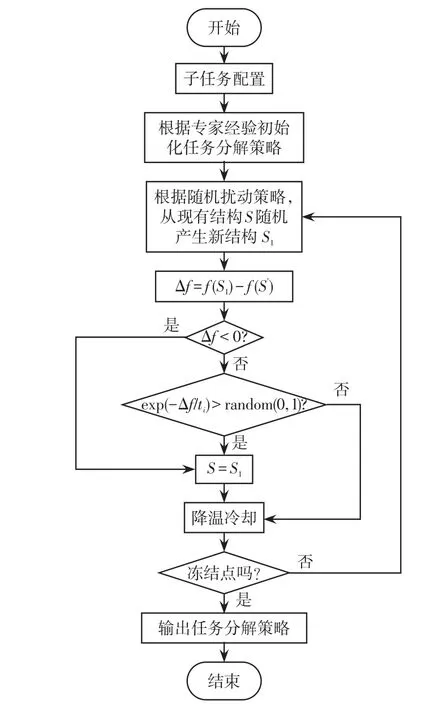
圖6 基于模擬退火算法的任務分配策略優化Fig.6 Optimization of task allocation strategy based on the Simulated Annealing algorithm
該架構應用到廣域數據質量迭代優化問題中,通過協同節點的計算資源進行部分采集數據的清洗、篩選和上送,調控云中心采用廣域任務調度技術,協調所有協同節點的計算任務和數據處理規則,實現任務、規則向協同節點的下發和反饋。
4 數據質量優化應用
調控云主導節點負責廣域云邊協同數據管理,其底層基于調控云基礎平臺提供的各種支撐,通過廣域數據網與協同節點進行任務、規則、數據的廣域交互,進一步支撐調控云上層的業務應用,如圖7所示。
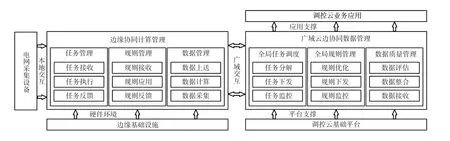
圖7 調控云廣域云邊協同數據管理Fig.7 Wide area cloud-edge collaborative data management in the dispatching and control cloud
調控云協同節點負責邊緣協同計算管理,其底層基于邊緣基礎設施提供的硬件環境,通過局域網匯集其管轄范圍內的所有電網采集設備采集的數據,通過廣域數據網與主導節點進行任務、規則、數據的廣域交互。
4.1 廣域云邊協同數據管理
廣域云邊協同數據管理具備全局任務調度、全局規則管理和數據質量管理3項功能。
(1)全局任務調度模塊負責廣域云邊協同任務的統一管理。面向具體的數據采集、清洗、校驗、評估等需求,將任務進行分解,并將數據采集、清洗等需要各邊緣節點具體執行的任務下發給對應的協同節點,并對協同節點的任務執行情況進行監控,確保任務能夠在協同節點有效執行。同時,主導節點作為調控云任務的全局協調中心,根據各協同節點的數據采集范圍、資源使用情況及任務執行情況等,進行全局統一協調,充分發揮協同節點計算能力的同時,保證數據采集質量和效率。
(2)全局規則管理模塊負責對各協同節點的數據采集范圍、數據處理規則進行統一管理。該模塊是數據質量迭代優化的核心。初始狀態時,根據調控云數據采集需求,由系統管理員通過手工配置各協同節點的數據采集范圍(如按管轄范圍、電壓等級、數據類別等)和初始的數據處理規則(如補全缺失點、平滑突變點、處理非法值等),并將該規則下發到各協同節點,同時對各協同節點規則的執行情況進行監控。在系統正常運行后,根據數據質量管理模塊匯集的各協同節點的數據評估情況,對數據處理的規則和算法進行在線優化,并將優化后的規則、算法下發到各協同節點,如此反復進行優化迭代,提升協同節點上送的數據質量。
(3)數據質量管理模塊負責對各協同節點上送的數據進行統一管理。該模塊接收各協同節點上送的數據,通過多源異構數據融合技術實現數據的匯總整合。之后通過多源數據質量智能綜合評估功能,對整合后的數據質量進行分析評估,確定每個協同節點上送的數據質量。最后將數據質量校驗、評估結果提供給全局規則管理模塊。
4.2 邊緣協同計算
邊緣協同計算管理具備任務管理、規則管理和數據管理3項功能,具體流程如圖8所示。

圖8 邊緣協同計算流程Fig.8 Flow chart of edge collaborative computing
(1)任務管理模塊負責接收調控云主導節點下發的任務,在本地執行任務,并將任務執行情況等信息反饋給調控云主導節點,具備任務接收、任務執行和任務反饋功能。
(2)規則管理模塊負責接收調控云主導節點下發的規則、算法,將其裝載到本地數據計算處理模塊內,并將規則執行情況等信息反饋給調控云主導節點,具備規則接收、規則應用和規則反饋功能。
(3)數據管理模塊負責協同節點管轄范圍內的數據采集,基于調控云主導節點下發的數據處理規則,進行批量處理或流式處理,將處理后的數據按約定的數據格式上送到調控云主導節點,具備數據采集、數據計算和數據上送功能。
4.3 數據流
調控云廣域云邊協同的數據流包含兩部分:從調控云協同節點到主導節點的電網數據,即業務數據流;調控云主導節點和協同節點交互的任務、規則等數據,即管理數據流。其數據流如圖9所示。
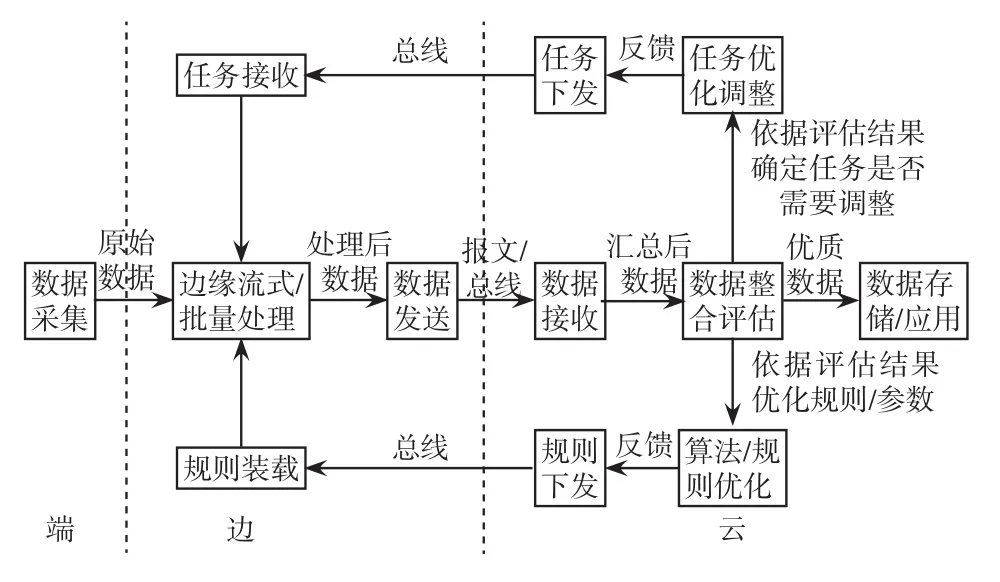
圖9 調控云廣域云邊協同數據流Fig.9 Wide area cloud-edge collaborative data flow based on dispatching and control cloud
1)業務數據流
業務數據流涉及的電網數據來源于電網采集設備,通過本地局域網將原始數據上送到協同節點。協同節點部署流式處理和批量處理功能(數據計算模塊內),根據調控云主導節點下發的數據采集范圍和數據處理規則,分別針對實時數據(流式處理)和歷史數據(批量處理)進行清洗、校驗等處理。協同節點處理后的優質數據,通過數據上送模塊,轉換為數據報文,通過總線或者協議的方式發送到調控云主導節點。
調控云主導節點的數據接收模塊接收到各協同節點發送的電網數據后,通過報文轉換和數據整合功能,進行數據緩存。對整合后的數據,通過多源數據質量智能綜合評估功能(數據評估模塊內),進行數據質量分析評估,確定每個協同節點上送的數據質量。之后對于優質的數據,存儲到調控云主導節點的數據庫中,為調控云業務應用提供數據服務。
2)管理數據流
管理數據流涉及調控云主導節點和協同節點之間的任務和規則交互。在上述業務數據流中,全局規則管理模塊和全局任務調度模塊獲取數據質量校驗、評估結果,確定算法規則和任務是否需要調整。如果需要調整,將調整后的規則和任務通過總線反饋給相應的協同節點,協同節點進行規則和任務接收,并在協同節點進行規則應用和任務執行。
5 應用結果分析
調控云目前已有13家省級協同節點接入國分云主導節點,基于調控云架構的廣域云邊協同技術已應用到調控云的數據質量管理中,實現了電網模型、運行數據的高效匯集和處理,應用成效顯著。
5.1 時延、帶寬性能分析
調控云的邊緣服務與云服務對比,最直接的優勢就是低延遲和高帶寬,邊緣節點內的應用同處一個局域網,可以保證足夠低的延時和足夠高的帶寬。而云中心在空間上一般偏離用戶,如果將數據從源端采集后直接上送至云中心處理,延時會相對較高,同時云中心整體的帶寬占用很大。表2展示了一般情況下的邊緣節點相對于云中心在延時、帶寬上的優點。這種優勢對于實時性要求較高的應用,采用邊緣協同計算效果更明顯。

表2 延時與帶寬對比Tab.2 Comparison of delay and bandwidth
5.2 單任務處理性能分析
對邊緣協同的單任務性能進行測試,本文選擇2個協同節點作為邊緣節點,以主導節點作為云中心,通過模型校驗(包含合規性校驗、冗余性校驗、統計值校驗、合理性校驗、規范性校驗、完整性校驗、圖形和拓撲校驗)、量測數據同步、數理分析3類計算任務,分別進行由云中心單獨處理和由各邊緣節點云邊協同處理的性能進行分析。
采用實際調控云系統中主導節點和選取的2個協同節點某一天的數據進行分析,計算任務的模型對象按發電廠、變電站、發電機、交流線路、母線、變壓器、繞組、斷路器、隔離開關、接地刀閘、并聯電容器、并聯電抗器12類一次設備及其拓撲連接關系、量測數據進行統計。其中,模型校驗分別按云中心和邊緣節點存儲的全電壓等級模型數據量進行計算;量測數據同步按邊緣節點匯集全電壓等級量測數據,云中心匯集220 kV及以上量測數據進行計算;數理分析按母線的電量(積分電量、采集電量)相關性進行分析。具體計算任務的數據量如表3所示。
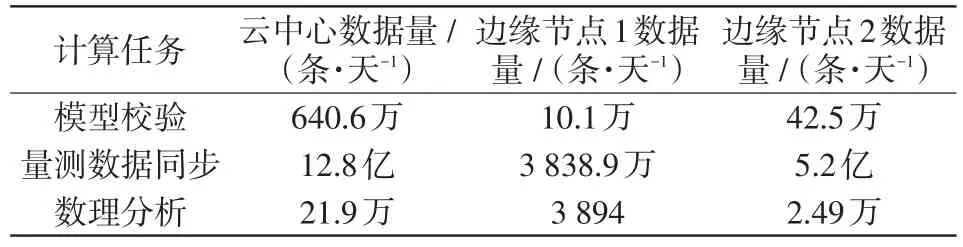
表3 計算任務數據量Tab.3 Data volume of computing tasks
圖10表明對于不同的任務,結果有很大的差異。數理分析應用在邊緣節點處理的耗時較云中心略長,而模型校驗、量測數據同步在邊緣節點進行云邊協同處理的性能優于云中心單獨處理。原因是不同的應用所需的資源不同,云中心相對于邊緣節點有更多的計算資源,計算能力更強大;而邊緣節點具有更高的帶寬和較低的網絡延遲。對于同一種應用而言,不同資源配置的邊緣節點在任務處理結果上也會略有差異。總體來說,通過適當的邊緣計算服務,在應用對于硬件資源需求不高、而對于低延時高帶寬需求較高的情況下,邊緣節點相對于云中心單獨處理具有明顯優勢,可以滿足應用需求。
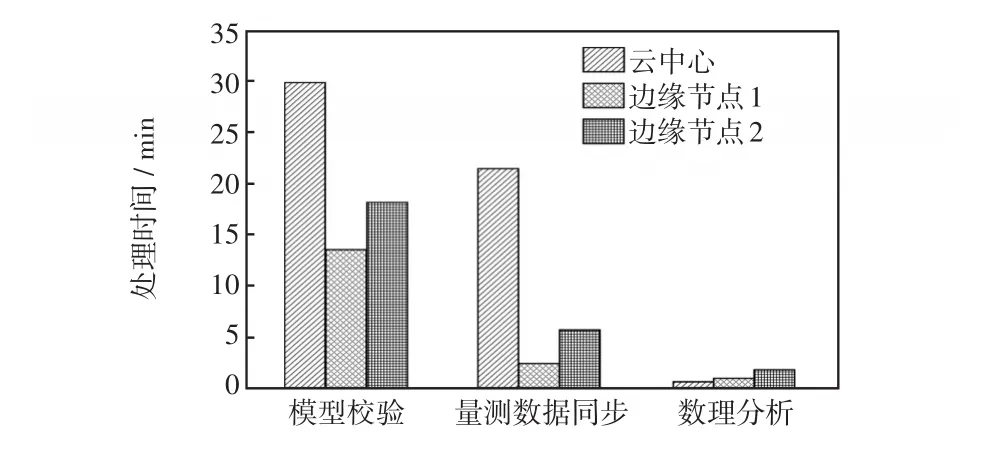
圖10 單任務處理時間對比Fig.10 Comparison of single-task processing time
5.3 任務分解策略分析
以云中心和某省協同節點的數據清洗、上送任務協同為例,進行任務分解策略分析。首先將調控云匯集的數據分為量測、電量、告警、事件、計劃、預測、氣象七大類,進一步根據實際數據發現的問題及應用對于數據的需求,將每類數據的清洗任務分解為數據多源清洗、冗余性清洗、完整性清洗、合規性清洗、規范性清洗、合理性清洗和時效性校驗7個方面,因此,共分解為49個子任務。
綜合考慮每類數據的數據量(以原始數據量為基準進行歸一化)和每個清洗任務的計算時間(以云中心計算時間為基準進行歸一化),采用公式(1)的 優 化 目 標 ,取φ1=0.4,φ2=0.1,φ3=0.5 ,因α⊕β=1,故只需求解α即可。α計算結果如表4所示。
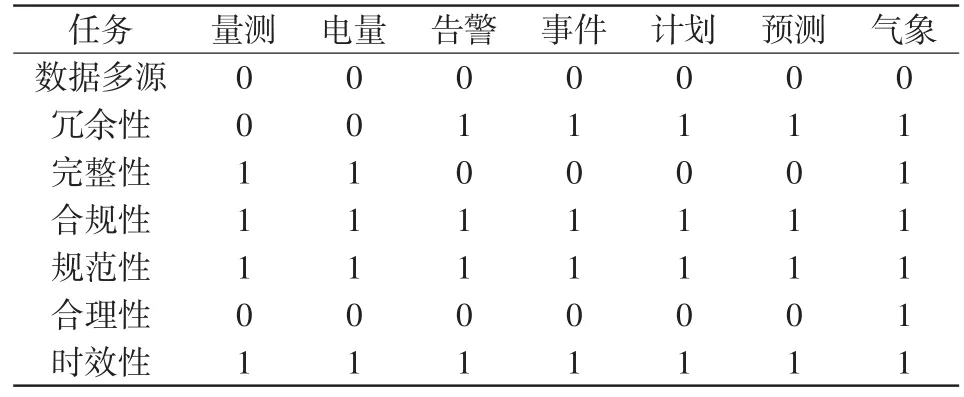
表4 數據清洗任務分解策略Tab.4 Decomposition strategy for data clean task
5.4 云中心存儲性能分析
以某省協同節點的量測數據為例,進行數據量分析,如表5所示。

表5 量測數據量對比Tab.5 Comparison of measurement data volume
廣域云邊協同架構將云中心所需的數據在邊緣節點直接進行計算,然后將處理后的高價值數據傳送到云中心,供云中心作分析決策,有效節約了云中心的存儲空間,減輕了存儲壓力。基于廣域云邊協同技術,調控云220 kV以下的電網量測數據存儲在邊緣節點,邊緣節點通過廣域服務總線對云中心提供這些量測數據的廣域數據訪問服務,實現在不占用云中心存儲空間的同時,滿足云中心業務應用對220 kV以下電壓等級量測數據訪問的需求。根據實際運行經驗表明,云中心對于220 kV以下電壓等級量測數據的訪問頻度和廣域服務響應時間滿足業務應用需求。
以一個協同節點為例,將220 kV以下量測數據存儲在邊緣節點,進行計算后將高價值數據傳入云中心,對比將全電壓等級數據都傳入云中心后計算,云中心在存儲容量方面的對比分析結果如圖11所示,可以看出,一個邊緣節點每天產生數據量約32 GB,通過云邊協同存儲方式,可節約云中心存儲空間約30 GB,1年可以節約云中心存儲空間約10 TB。隨著后期更多邊緣協同節點的接入,云中心可節約更多的存儲空間。
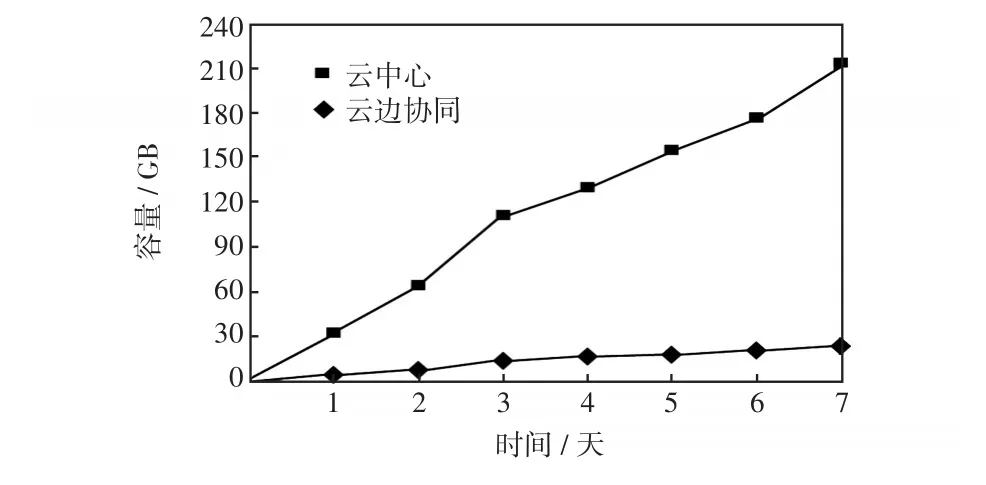
圖11 不同方式下云中心存儲容量對比Fig.11 Comparison of storage capacity of cloud center in different ways
6 結語
本文基于云邊協同技術,利用調控云主導節點和協同節點的體系架構和實際應用,設計了調控云廣域云邊協同總體架構,并以電網調控數據質量優化應用為例,研究了廣域云邊協同數據管理和邊緣協同計算的功能及計算流程,分析了廣域云邊協同的數據交互流程。結合目前調控云建設情況,從網絡帶寬及時延、數據協同處理性能、任務分解策略優化、云中心存儲性能等指標進行了對比分析,實際應用結果表明,云邊協同技術的應用解決了集中計算帶來的調控云網絡帶寬占用過大、數據時效性不強的問題,緩解了調控云中心的計算、存儲壓力,同時調控云協同節點的數據質量也得以有效提升。
猜你喜歡
杭州金融研修學院學報(2022年5期)2022-06-15 11:41:48
今日農業(2019年14期)2019-09-18 01:21:54
今日農業(2019年12期)2019-08-15 00:56:32
今日農業(2019年11期)2019-08-13 00:49:08
今日農業(2019年13期)2019-08-12 07:59:04
今日農業(2019年10期)2019-01-04 04:28:15
今日農業(2019年15期)2019-01-03 12:11:33
今日農業(2019年16期)2019-01-03 11:39:20
銅仁學院學報(2018年4期)2018-06-13 03:21:34
商周刊(2017年9期)2017-08-22 02:57:56
