GAN-TM:一種基于生成對抗網(wǎng)絡的流量矩陣推斷機制
2022-03-16 03:58:30章樂貴邢長友
計算機技術(shù)與發(fā)展 2022年2期
關(guān)鍵詞:模型
章樂貴,邢長友,余 航,鄭 鵬
(陸軍工程大學 指揮控制工程學院,江蘇 南京 210007)
0 引 言
流量矩陣(traffic matrix,TM)是網(wǎng)絡內(nèi)源(origin)節(jié)點和目的(destination)節(jié)點對之間流量的具體描述,矩陣中的每個元素都表示某一源和目的對之間的流量大小。作為網(wǎng)絡態(tài)勢的一種重要表現(xiàn)形式,流量矩陣能夠給網(wǎng)絡管理員提供許多關(guān)于當前網(wǎng)絡狀態(tài)有價值的全局信息,是解決網(wǎng)絡中很多問題不可或缺的組成部分,如網(wǎng)絡規(guī)劃、流量計費、流量工程、負載均衡、異常檢測和網(wǎng)絡性能分析等。由于流量矩陣在解決網(wǎng)絡問題中的極端重要性,近二十年來,關(guān)于流量矩陣的研究受到了國內(nèi)外學者的高度關(guān)注,各類流量矩陣測量與推斷技術(shù)不斷發(fā)展。
雖然準確獲取流量矩陣對網(wǎng)絡運營者來說至關(guān)重要,各類研究人員也對如何準確獲取流量矩陣提出了許多不同的方法,包括統(tǒng)計方法、最優(yōu)化方法和時間序列方法等,但現(xiàn)實條件下想要準確獲取流量矩陣始終存在困難。現(xiàn)有的流量矩陣測量方法主要可分為直接測量法和估計推斷法。由于當前計算機網(wǎng)絡快速發(fā)展,網(wǎng)絡規(guī)模不斷擴張,網(wǎng)絡結(jié)構(gòu)日趨復雜,通過部署大量節(jié)點直接進行測量的方法既受限于缺乏有效的測量框架,又因測量耗費無法承受逐漸失去了其現(xiàn)實意義。而對于現(xiàn)有的利用流量矩陣其內(nèi)在聯(lián)系進行分析計算的推斷法而言,又因流量矩陣推斷問題在線性求解上固有的高度病態(tài)特性難以有效解決而時常陷入困難。
1 背 景
目前在相關(guān)領(lǐng)域已經(jīng)有學者做出了相當有創(chuàng)新性的一些工作,如Luong等人提出了一種基于監(jiān)控鏈路流量吞吐量的解決方案和一種針對控制平面的新轉(zhuǎn)發(fā)算法。它基于SDN控制器的兩個模塊,吞吐量監(jiān)控器模塊著重于穿過交換機的數(shù)據(jù)包和字節(jié)數(shù),分組轉(zhuǎn)發(fā)模塊實現(xiàn)轉(zhuǎn)發(fā)算法, 吞吐量監(jiān)控器模塊提供的統(tǒng)計信息可供任何監(jiān)控應用程序使用。Silv等人提出了OFQuality,一種基于OVSDB協(xié)議的QoS配置模塊,該模塊得益于TM的生成來管理OF交換機上的QoS策略。Y. Tian等提出了一個新的基于SDN的IP網(wǎng)絡中TM估計的框架。該項工作表明,如果流量的流量可以從網(wǎng)絡中的其他流量中獲取,則為此流量添加新條目以進行流量測量不會提供有關(guān)TM的新信息。除此之外,胡煜雪也同樣基于SDN網(wǎng)絡進行了相關(guān)研究,提出了基于壓縮感知的流量估計算法,該算法的有效實現(xiàn)需要滿足RIP原則以及稀疏信號的前提條件。同樣使用壓縮感知方法的還有M. Malboubi等人,通過建立iStamp機制,使用壓縮好的聚集流量測量結(jié)果和K
個最有用的流量來推斷TM。其中,iStamp將流表分為兩部分:第一部分用于匯總測量,第二部分用于對選定流進行逐流監(jiān)視。使用這兩個不同的部分,iStamp可以估算流量矩陣。同時,D Jiang等人開發(fā)了一種算法,可以從采樣的流量跟蹤中以細粒度的時間估計和恢復網(wǎng)絡流量矩陣。他們的算法基于分形插值,三次樣條插值和加權(quán)幾何平均算法。王昌鈺從矩陣本身出發(fā),使用歐氏距離作為最優(yōu)化度量,解決了流量矩陣中的病態(tài)性問題,但并未考慮網(wǎng)絡流量矩陣本身的時間性和空間性。此外,Azzouni和Pujolle提出了NeuTM,它是基于長期短期記憶遞歸神經(jīng)網(wǎng)絡的TM預測框架。實驗證明,NeuTM可以使用歷史數(shù)據(jù)來訓練神經(jīng)網(wǎng)絡以預測未來的TM。在機器學習領(lǐng)域,Choudhury等人描述了機器學習在SDN賦能的IP /光網(wǎng)絡中用于TM預測的應用。在他們的工作中,使用機器學習來對流量矩陣的所有元素進行短期和長期預測是一未來的趨勢。2014年Ian Goodfellow等人提出了生成對抗網(wǎng)絡(generative adversarial networks,GAN),給出了生成對抗網(wǎng)絡的框架及理論收斂性分析。生成對抗網(wǎng)絡是一種無監(jiān)督機器學習的人工智能算法,通過兩個神經(jīng)網(wǎng)絡在二人零和博弈中相互競爭實現(xiàn)。生成對抗網(wǎng)絡包括兩個子網(wǎng)絡模型,一個是生成網(wǎng)絡,也叫生成器(generator,G
),它的作用是使生成的數(shù)據(jù)盡可能與真實數(shù)據(jù)的分布盡可能一致;另一個是判別網(wǎng)絡,也叫判別器(discriminator,D
),它的作用是在生成的數(shù)據(jù)與真實的樣本數(shù)據(jù)之間能夠做出正確判斷,可以理解為一個二分類器。GAN的訓練過程可以理解為一個極小極大化博弈過程,生成器的模仿能力與判別器的鑒別能力二者相互促進、共同進步,最終達到一個納什均衡,使得生成器對原數(shù)據(jù)分布的模擬近乎逼真。根據(jù)GAN網(wǎng)絡對于數(shù)據(jù)分布強大的學習能力,已經(jīng)有許多基于GAN進行數(shù)據(jù)恢復的研究取得了重大進展,因此該文針對如何將GAN用于流量矩陣推斷進行了研究。
考慮到流量矩陣的低秩性,其內(nèi)部存在大量的冗余,一些研究將流量矩陣估計推斷問題轉(zhuǎn)化成壓縮感知問題來進行解決。除了這些技術(shù)之外,基于張量的方法,在多維空間的矩陣推斷中,已被證明是一種用來估算缺失數(shù)據(jù)更有效的工具。但是,這些完成方法并未明確說明異常值,并且可能在數(shù)據(jù)嚴重損壞的情況下導致性能顯著下降。另一方面,由于流量矩陣內(nèi)部各元素之間存在強相關(guān)性,為了盡可能地挖掘、利用流量矩陣內(nèi)部這一空間特性,該文使用了卷積神經(jīng)網(wǎng)絡對生成器、判別器兩大神經(jīng)網(wǎng)絡進行了改進。根據(jù)相關(guān)研究表明,理論上深度神經(jīng)網(wǎng)絡能夠?qū)崿F(xiàn)任意功能的函數(shù)。為了使模型具有更強的學習能力,盡可能模擬出真實數(shù)據(jù)的分布,該文使用深度卷積網(wǎng)絡作為GAN結(jié)構(gòu)中生成器和判別器的架構(gòu)。通過設(shè)置大小不同的卷積核,獲取不同大小范圍感受野的特征,可以更好地學習到數(shù)據(jù)分布。使用深度卷積神經(jīng)網(wǎng)絡的另一個優(yōu)勢在于能有效利用流量矩陣的低秩特性,減少中間變量和參數(shù)的設(shè)置,進一步優(yōu)化網(wǎng)絡結(jié)構(gòu)。
盡管GAN有著許多優(yōu)秀的特性,但是與此同時也陷入了和其他機器學習方法相同的問題——完整數(shù)據(jù)依賴性。原生GAN在訓練過程中需要包含完整數(shù)據(jù)的數(shù)據(jù)集進行輔助,這意味著需要預先獲取大量整個目標流量矩陣——包括矩陣中每個位置上元素的歷史數(shù)據(jù),以此完成對損失函數(shù)的構(gòu)建,而構(gòu)建合理的損失函數(shù)是對模型參數(shù)進行訓練優(yōu)化的基礎(chǔ),這樣一來,就使得GAN一旦離開了完整的數(shù)據(jù)集將無法工作。事實上,對于現(xiàn)代大型網(wǎng)絡而言,想要獲取完整的流量矩陣數(shù)據(jù)是一件幾乎不可能的事情,包括該文所研究的流量矩陣推斷問題,同樣也是為了更好地獲得流量矩陣數(shù)據(jù)。完整流量矩陣數(shù)據(jù)的缺乏,成為了研究推進的瓶頸。為了消除模型的完整數(shù)據(jù)依賴,該文引入了掩碼矩陣作為構(gòu)建損失函數(shù)的依據(jù),并以此為依據(jù)獲得了優(yōu)化函數(shù)。這種做法有效地避開了完整數(shù)據(jù)依賴問題,使得模型可以在沒有任何完整數(shù)據(jù)的前提下解決流量矩陣推斷的機器學習解法,降低了問題解決的門檻和耗費。
2 方法建模
生成對抗網(wǎng)絡(GAN)的數(shù)學模型描述如下:
V
(G
,D
)=E
~[logD
(x
)]+E
~[log(1-D
(x
))](1)
其中,x
表示輸入判別器的向量,E
表示期望值,P
表示真實數(shù)據(jù)的分布,P
表示G
生成數(shù)據(jù)的分布。這個式子的好處在于,固定生成器(G
)之后,maxV
(G
,D
)就表示P
和P
之間的差異,只需要找到一個參數(shù)最“完美”的G
,使得它的最大值最小化,也就是P
和P
兩個分布之間差異最小,即收斂在: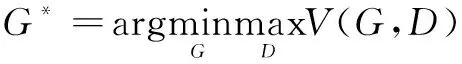
(2)
假設(shè)目標網(wǎng)絡有m
個節(jié)點,則該網(wǎng)絡中共有m
個OD流,它的流量矩陣應該是一個m
×m
的方陣,因此假設(shè)A
是該網(wǎng)絡中第i
個節(jié)點到第j
個節(jié)點之間的OD流,目標網(wǎng)絡的流量矩陣就可以表示為:=(A
)×(3)
接下來引入掩碼矩陣(mask matrix,MM)的概念。文中掩碼矩陣的作用是標明矩陣中各個位置元素是否有真實值的一個01矩陣,掩碼矩陣的規(guī)模與對應的流量矩陣一致,文中掩碼矩陣同樣也是一個m
×m
的方陣。其中,如果A
的數(shù)據(jù)是真實測得的數(shù)據(jù),那么對應的M
=1;否則如果A
的數(shù)據(jù)是缺失的,那么相應的M
=0,即:
(4)
模型的基本架構(gòu)如圖1所示。

圖1 模型基本架構(gòu)
在圖1所示的模型中,G
和D
分別是生成器和判別器。為只含有部分測量數(shù)據(jù)信息的缺失矩陣,根據(jù)矩陣,由公式(4)可以獲得該流量矩陣對應的掩碼矩陣,二者共同作為生成器的輸入。生成器G
利用已知的和作為輸入,輸出作為對原矩陣的一個推斷結(jié)果。是一個提示矩陣,由生成,含有部分信息。作為一個輔助輸入,用于輔助判別器D
判別其主輸入中各個元素是否是原始數(shù)據(jù),是原始輸入的打個標記“1”,不是的打個標記“0”,從而獲得一個對的估計。G
的能力越強,生成的就越接近于真實情況,D
的判別結(jié)果就越容易判為全真(即M
為全1矩陣),這顯然是在相對條件下弱化了D
,因此與D
努力判別出M
真實情況構(gòu)成博弈,在訓練過程中正是利用了這一點使得兩者的能力都不斷得到強化,最終到達平衡時獲得一個強大的生成器G
,G
能夠?qū)υ瓟?shù)據(jù)中缺失的部分以較高的準確率推斷出來。圖1中的G_loss和D_loss分別是生成器和判別器的損失函數(shù),通常被用于優(yōu)化模型參數(shù),同時也被用于檢驗生成器/判別器能力強弱。
通過訓練D
來最大化正確預測的概率,訓練G
來最小化D
預測的概率。定義要量化的V
(D
,G
)為:V
(D
,G
)=E
,,[logD
(,)+(1-)log(1-D
(,))](5)
根據(jù)Goodfellow在原始GAN中的推導,目標函數(shù)可以寫成:

(6)
2.1 生成器
生成器的作用是利用所有已知的信息,學習含有缺失的流量矩陣的數(shù)據(jù)分布,根據(jù)學習成果對原矩陣缺失的數(shù)據(jù)進行填充,使得輸出的流量矩陣接近于真實網(wǎng)絡中的情況。在該文所構(gòu)建的模型中,生成器的輸入為原流量矩陣及其對應的掩碼矩陣。但并不是直接進入生成器中開展運算的,需要經(jīng)過一個填充過程,將其缺失部分元素用隨機噪聲進行填充,即:=⊙+⊙(1-)(7)
其中,為規(guī)模和一致的隨機生成的噪聲。圖2中,“G_”表示模型參數(shù),在本模型中共設(shè)置了三個卷積層,“G_w2”,“G_w3”,“G_w4”分別為相對應的三個卷積核,卷積核大小分別為 “7×7”,“5×5”和 “3×3”。“G_b1”,“G_b2”,“G_b3”,“G_b4”分別表示各層的偏置。將最后一個卷積層輸出的結(jié)果矩陣命名為,為保證原有數(shù)據(jù)不被更改,以免引入新的誤差,在最后的輸出層將原始數(shù)據(jù)重新賦回,即: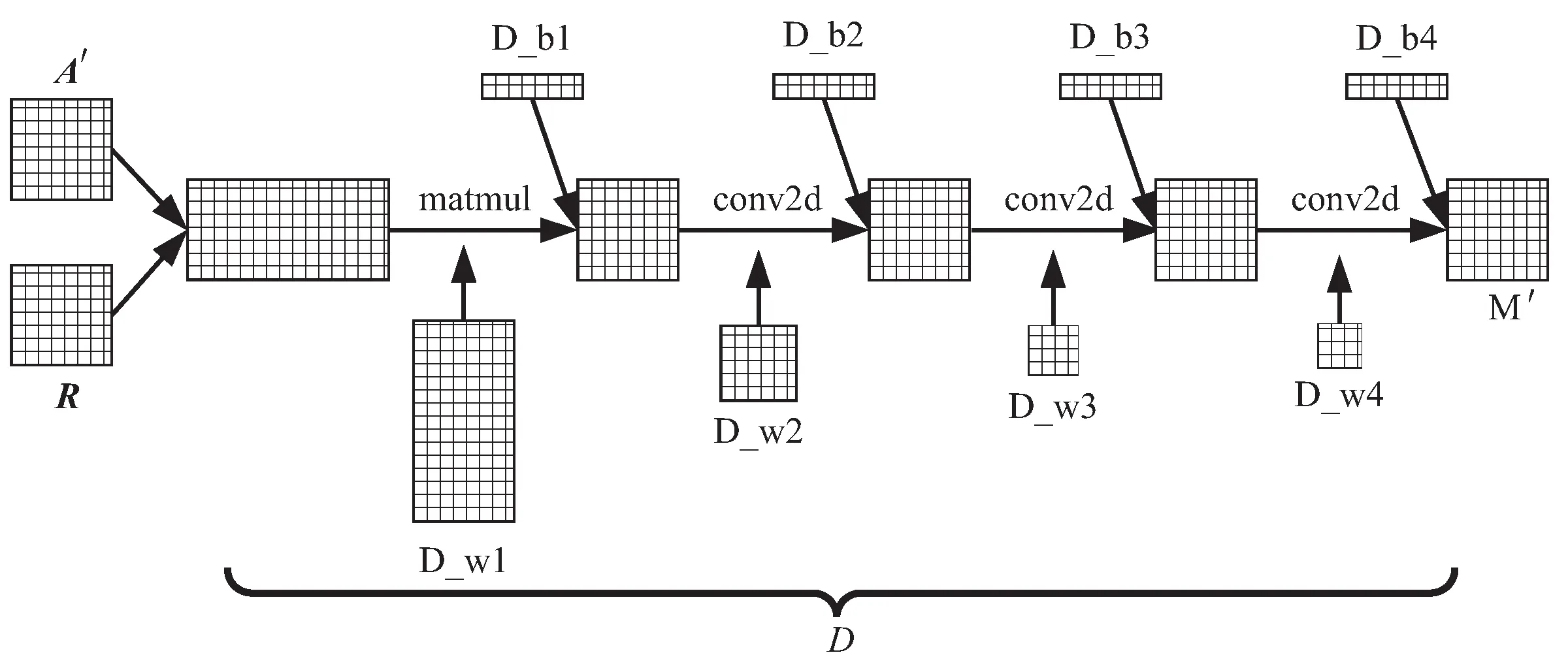
圖2 生成器(G)結(jié)構(gòu)
=⊙+⊙(1-)(8)
最終輸出的就是對原數(shù)據(jù)的一個推斷結(jié)果。2.2 判別器
判別器的作用是利用輸入數(shù)據(jù)(,)所提供的信息,判斷矩陣中哪些元素是矩陣中原本就有的真實數(shù)據(jù),哪些是由生成器生成的,判斷的結(jié)果用一個掩碼矩陣M
來表示,因此也可以認為是對掩碼矩陣中位置部分的推斷。圖3中,“D_”表示模型參數(shù),在本模型中共設(shè)置了三個卷積層,“D _w2”,“D _w3”,“D _w4”分別為相對應的三個卷積核,卷積核大小分別為 “7×7”,“5×5”和 “3×3”。“D _b1”,“D _b2”,“D _b3”,“D _b4”分別表示各層的偏置。將最后一個卷積層輸出的結(jié)果矩陣命名為M
,即判別器的輸出。
圖3 判別器(D)結(jié)構(gòu)
2.3 模型訓練
在信息論中,香農(nóng)(Shannon)提出使用交叉熵(cross entropy)來度量兩個分布之間的差異程度,給出x
,y
間的交叉熵公式:F
(x
,y
)=∑[x
logy
+(1-x
)log(1-y
)](9)
該文使用交叉熵函數(shù)來計算損失函數(shù),結(jié)合公式(5)和公式(6),可以得到判別器的損失函數(shù):
D
=E
[F
(,)](10)
考慮生成器的損失函數(shù)時,急需要使生成器最后一次卷積得到的結(jié)果中原數(shù)據(jù)保留位置的元素盡可能保持不變,又要使生成器生成的部分不被判別器判別出來。
對于原有數(shù)據(jù)而言,在圖2中,經(jīng)過生成器G
處理之后輸出的應該盡可能使原始數(shù)據(jù)保持不變,和之間的差異帶來的損失可以用均方差來體現(xiàn),這個損失同時也是衡量整個模型準確率的關(guān)鍵指標:
(11)
從博弈的角度出發(fā),G
要盡量使D
不能判別出來哪些數(shù)據(jù)是由G
生成的,因此這部分的損失可以由圖3中和的交叉熵來表示:G
2=∑(1-)log(1-)(12)
將關(guān)于G
的兩個誤差加權(quán)和作為生成器的損失函數(shù):G
=∑(1-)log(1-)+
(13)
其中,λ
是一個正常數(shù),用于平衡生成器損失函數(shù)所考慮的兩個方面損失相互之間的重要性。3 實驗與分析
實驗所使用的數(shù)據(jù)集來源于美國Abilene骨干網(wǎng)絡上的真實數(shù)據(jù),為了便于計算分析,實驗中所使用的數(shù)據(jù)均已做歸一化處理。在Abilene骨干網(wǎng)絡中,共有12個IP網(wǎng)絡節(jié)點,因此對應的流量矩陣規(guī)模為“12×12”(即m
=12)。為了正確測試模型的泛化性能,從數(shù)據(jù)集中隨機抽取10%作為驗證集,剩余90%作為訓練集。為驗證模型在流量矩陣推斷上的表現(xiàn),在實驗中對模型參數(shù)配置如下:將數(shù)據(jù)缺失率設(shè)為20%;每輪訓練128個樣本,即mini_batch = 128,每訓練完10個mini_batch計算一次誤差和損失函數(shù);訓練過程中學習率設(shè)為3×10;計算G_loss1所用的權(quán)值λ
=10;掩碼矩陣對提示矩陣的提示率為0.9。圖4顯示了在2 000輪次訓練過程中本模型進行流量矩陣推斷的誤差,即公式(11)計算的G
_loss1。圖4表明,在整個訓練過程中,G
_loss1在訓練開始階段下降明顯,在500輪訓練后逐漸趨于平穩(wěn),約1 000輪次的訓練后G
_loss1達到約0.10,隨后開始圍繞均衡點震蕩。由此可見,模型在無完整數(shù)據(jù)的條件下,對于缺失流量矩陣的推斷仍然能夠保證較高的準確率。
圖4 訓練過程中模型對流量矩陣推斷誤差曲線
圖5顯示了整個訓練階段中判別器和生成器的損失函數(shù)變化情況。根據(jù)圖5可以看到,在訓練開始階段(0~250輪),判別器和生成器的損失都在不斷減小,

圖5 訓練過程中判別器(D)/生成器(G)損失曲線
這表明兩者的能力都在不斷增強。而后判別器的損失繼續(xù)下降,但生成器的損失開始上升,這是由于生成器在計算損失時同時考慮了流量矩陣和掩碼矩陣兩個方面的損失所產(chǎn)生的,到模型最后階段,兩個損失函數(shù)都趨于穩(wěn)定,模型訓練完成。
圖6顯示了在其他參數(shù)保持不變的情況下,在1 000輪次的訓練過程中,當缺失率取不同的值時的模型誤差曲線(G_loss1)。根據(jù)圖6可以得出結(jié)論,測量得到的流量矩陣數(shù)據(jù)信息越多,模型的誤差就越小,反之則誤差越大,這與主觀經(jīng)驗是完全一致的。如圖6所示,當缺失率低于30%時,模型都能夠以較高的準確率(G
_loss1≈0.
10)得到推斷結(jié)果。當缺失率高于50%時,模型的推斷結(jié)果開始逐漸變差,當缺失率達到90%時,模型的推斷功能將徹底失效,無法再起到任何作用。
圖6 不同缺失率下的推斷誤差
根據(jù)實驗驗證可以得出結(jié)論,本模型具備在缺少完整數(shù)據(jù)的情況下,僅僅利用缺失的流量矩陣數(shù)據(jù)就能以較低的誤差水平推斷得到完整的流量矩陣。并且本模型在缺失率低于50%的條件下都能有較好的表現(xiàn),在缺失率低于90%的條件下也能起到一定的效果,但無法保證較低的誤差水平。
4 結(jié)束語
該文研究了如何在缺少完整流量矩陣數(shù)據(jù)集的條件下,解決流量矩陣推斷問題,并結(jié)合Goodfellow教授提出的生成對抗網(wǎng)絡技術(shù),給出了一種新的推斷方法,建立了基于掩碼矩陣評估的卷積生成對抗網(wǎng)絡(BM-DCGAN)模型。通過利用深度卷積神經(jīng)網(wǎng)絡強大的建模功能,實現(xiàn)了在不使用完整流量矩陣數(shù)據(jù)的前提下,僅利用測量獲取的部分流量矩陣數(shù)據(jù),在模型的輔助下將位置部分的流量矩陣數(shù)據(jù)推斷出來。該模型可以實現(xiàn)在容忍低于30%數(shù)據(jù)缺失的情況下,以0.10左右的誤差將缺失的流量矩陣還原。
與以前的方法相比,該方法具有以下優(yōu)勢:
(1)無需大量的完整數(shù)據(jù)用于訓練,減少了測量耗費,降低了網(wǎng)絡測量成本,從而降低了問題解決的代價,使模型更具有實際意義;
(2)使用卷積神經(jīng)網(wǎng)絡,利用卷積特性,有效捕捉了流量矩陣的空間特征;
(3)模型收斂速度快,推斷誤差小,實現(xiàn)了高效使用的目的。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網(wǎng)絡安全與數(shù)據(jù)管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數(shù)理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數(shù)學備考)(2021年9期)2021-11-24 01:14:36
成都醫(yī)學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數(shù)學備考)(2020年9期)2021-01-04 00:25:14
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
