結(jié)合學(xué)科情感分析與依存關(guān)系的相似度評(píng)分
2022-03-16 03:36:36付鵬斌楊惠榮
計(jì)算機(jī)技術(shù)與發(fā)展 2022年2期
付鵬斌,劉 曼,楊惠榮
(北京工業(yè)大學(xué) 信息學(xué)部,北京 100124)
0 引 言
目前,國內(nèi)外基于深度學(xué)習(xí)、機(jī)器學(xué)習(xí)的主觀題自動(dòng)評(píng)分方法在技術(shù)理論上取得了一些成果。Riordan等基于深度學(xué)習(xí)模型,結(jié)合CNN與LSTM構(gòu)建神經(jīng)網(wǎng)絡(luò),預(yù)測(cè)考生得分。Yang等提出了一種基于深度自動(dòng)編碼器的短答案評(píng)分算法,可以在不明確定義目標(biāo)答案的情況下構(gòu)建評(píng)分模型。雖然這些方法評(píng)分效果較好,但需要依靠大量訓(xùn)練數(shù)據(jù),在高考等大型考試中,考題為新題,訓(xùn)練集中無該題對(duì)應(yīng)的教師評(píng)分?jǐn)?shù)據(jù),難以進(jìn)行自動(dòng)評(píng)分,具有一定局限性。
丁振國等人利用《知網(wǎng)》中計(jì)算義原相似度方法提出詞與詞之間的相似度計(jì)算方法,并進(jìn)一步提出了計(jì)算參考答案和考生答案文本相似度的算法。但因?yàn)槠鋵?duì)文本的處理僅采用分詞技術(shù),不能對(duì)詞性以及句法依存做進(jìn)一步分析,復(fù)雜度高且準(zhǔn)確度不理想。翟社平等提出了一種多特征融合的句子相似度計(jì)算方法,分別對(duì)詞性、詞序以及句長(zhǎng)等特征進(jìn)行提取并融合,以計(jì)算句子的相似度,但該方法對(duì)于本體庫中未涉及的內(nèi)容,計(jì)算精確度不高,且對(duì)于主觀性強(qiáng)的文本語義分析不準(zhǔn)確。
Joshi和Penstein-Rose把依存廣泛關(guān)系和相關(guān)衍生特征應(yīng)用到分類過程中。通過依存句法分析得到三元組,得到如RELATION_HEAD_MODIFIER形式的特征,這個(gè)特征針對(duì)性太強(qiáng),只能用在固定領(lǐng)域。Yessenalina等使用基于情感詞典的自動(dòng)方法來標(biāo)注情感信息。他們用基于結(jié)構(gòu)化SVM(Yu and Joachims)的兩級(jí)聯(lián)合分類模型,其對(duì)于由較少情感詞匯組成的句子來說,情感傾向分析并不準(zhǔn)確。以上方法對(duì)于語文古詩文閱讀類字?jǐn)?shù)較多且具有較強(qiáng)主觀性的答案來說,評(píng)分效果并不理想。
該文通過構(gòu)建語文古詩文語料庫、古詩文情感詞庫及學(xué)科情感分析模型,使情感傾向分析更加符合學(xué)科特點(diǎn),并使用依存句法分析,明確了詞語在句子中的所屬依存關(guān)系,以此實(shí)現(xiàn)了結(jié)合學(xué)科情感分析與依存關(guān)系的相似度評(píng)分算法,使主觀題的評(píng)分更加合理有效,經(jīng)實(shí)驗(yàn)驗(yàn)證,和教師的實(shí)際評(píng)分趨勢(shì)基本一致。
1 構(gòu)建學(xué)科情感分析模型
學(xué)科情感分析模型的構(gòu)建,分為語料庫、情感詞庫、情感分析模型的建立,以及古詩文的情感預(yù)測(cè)。
1.1 古詩文語料庫
目前,并沒有構(gòu)建好的古詩文相關(guān)語料庫可以使用,因此該文收集整理了包含初中、高中課本內(nèi)全部古詩詞和文言文,其中包括:先秦時(shí)期《詩經(jīng)》、《論語》、《孟子》等;兩漢《史記》等全部原文、譯文;唐宋詩人李白、杜甫、蘇軾等所有原文、譯文、注釋和賞析等,并經(jīng)學(xué)科專家審核,生成了古詩文語料,共計(jì)81 927條,并將其與中文維基百科語料進(jìn)行融合,后通過Jieba工具包對(duì)語料進(jìn)行分詞及詞性標(biāo)注,將預(yù)處理后的文本通過古詩文過濾詞表進(jìn)行過濾標(biāo)點(diǎn)、停用詞等處理,經(jīng)過檢查、去重后,將其存入古詩文基礎(chǔ)語料,預(yù)處理后的古詩文部分語料如圖1所示。

圖1 古詩文部分語料
將古詩文基礎(chǔ)語料,通過文本向量化算法Word2vec中的CBOW(continuous bag-of-word)模型來進(jìn)行詞向量的訓(xùn)練,構(gòu)建了古詩文語料庫,其中詞語對(duì)應(yīng)的向量維度為192維。相比中文維基百科語料庫,其在詞語向量的表達(dá)上更加符合學(xué)科背景,“郭綸”是宋代詩人蘇軾的詩作,屬于古詩文閱讀題中的專有詞匯,該詞在古詩文語料庫中的向量表達(dá)及其相似詞的排序都是符合學(xué)科特點(diǎn),而維基百科語料庫中缺乏“郭綸”一詞,因此將古詩文語料庫作為整個(gè)評(píng)分算法中的底層數(shù)據(jù)支持是可靠的。
1.2 古詩文情感詞庫的建立
Word2vec訓(xùn)練的詞向量模型,只是提供兩個(gè)詞語之間空間位置上的相關(guān)性,對(duì)于語義相似度的計(jì)算并不準(zhǔn)確,例如“喜歡”,通過模型的wv.most_similar方法找出與其相似度最高的十個(gè)詞,其中相似度最高的詞語是“討厭”,顯然這兩個(gè)詞語義相反。在古詩文閱讀題的評(píng)分過程中,語義相反的詞語是不能進(jìn)行得分操作的,所以僅僅通過詞向量模型進(jìn)行相似度計(jì)算是不準(zhǔn)確的,因此該文將古詩文語料中帶有情感傾向的詞語進(jìn)行收集和整理,并結(jié)合《哈工大同義詞詞林?jǐn)U展版》進(jìn)行情感詞庫的構(gòu)建。
為了使古詩文情感詞庫的構(gòu)建更加合理,方便后續(xù)詞庫的擴(kuò)充與維護(hù),該文在構(gòu)建情感詞庫時(shí)制定了入庫規(guī)則,詞庫按照樹狀的層次結(jié)構(gòu)將所有詞語組織起來,將其進(jìn)行了四個(gè)層次的劃分。情感詞入庫如下:
規(guī)則1:第一層代表學(xué)科類型,為最大類,用兩個(gè)英文字母表示,該文以語文古詩文閱讀題為研究對(duì)象,最大類命名為“Sg”(詩歌拼音首字母縮寫);
規(guī)則2:第二層代表是否為學(xué)科專有名詞,用兩位數(shù)字表示,如“喜愛”為通用情感詞匯,其第一層用“Sg”表示,第二層用“01”表示,“愛國熱情”為學(xué)科專有名詞,將其第一層用“Sg”表示,第二層用“02”表示,以此類推;
規(guī)則3:第三層用來劃分詞性,用一個(gè)大寫字母表示,因表達(dá)情感的詞匯不是只有動(dòng)詞,還有名詞、形容詞等,如:“郁悶”為形容詞,其具有消極的情感表達(dá)。將評(píng)分中出現(xiàn)的情感詞匯進(jìn)行整理,并將其詞性代表的英文字母按順序往后順延,并不斷擴(kuò)充;
規(guī)則4:第四層作為最底層,是用來劃分詞語的情感傾向,以兩位數(shù)字表示,用奇數(shù)表示積極詞匯,用偶數(shù)表示消極詞匯。
情感詞庫構(gòu)建的具體步驟如下:
(1)預(yù)處理后的古詩文語料按照詞性進(jìn)行分類,詞性為動(dòng)詞的詞語歸為一類,去掉重復(fù)詞語,剩下詞語存入情感詞庫中,每個(gè)詞占一行。
(2)將情感詞庫中所有詞語進(jìn)行情感傾向分析,數(shù)值大于等于0.6的認(rèn)定該詞為積極詞語,相反為消極詞語,并將其基于上文介紹的情感詞入庫規(guī)則,進(jìn)行重新定義和排序。
(3)根據(jù)《哈工大同義詞詞林?jǐn)U展版》的層次結(jié)構(gòu),將詞林中每一行所有同義詞存入同義詞列表中,并在列表中查找與詞庫中相同的詞,將其相同詞語的全部同義詞存入情感詞庫中相對(duì)應(yīng)詞語的后面,詞語之間以空格分開。
(4)將詞林中每一行的所有反義詞語存入反義詞列表中,并在列表中查找與詞庫中相同的詞,對(duì)情感詞庫進(jìn)行檢驗(yàn)和補(bǔ)充。
(5)通過人工檢驗(yàn),對(duì)情感詞庫中有歧義的詞語,不斷補(bǔ)充和調(diào)整,逐步完善情感詞庫。
1.3 構(gòu)建學(xué)科情感分析模型
通過對(duì)古詩文主觀題及教師評(píng)分方法的研究發(fā)現(xiàn),盡管教師評(píng)分的主要標(biāo)準(zhǔn)是考生答案中對(duì)應(yīng)的得分點(diǎn),但語句的通順性、情感表達(dá)的一致性也是重要的評(píng)判依據(jù)。因此,對(duì)答案中包含的情感傾向進(jìn)行分析是不可或缺的。
SnowNlp情感分析模型常用于購物類評(píng)價(jià),其語料庫中相關(guān)學(xué)科詞條較少,如“這首詩表達(dá)了詩人報(bào)國無門的憤恨”,表達(dá)的是消極情感,但SnowNlp情感分析模型得出該句表達(dá)的情感是積極的。因此,將其用于古詩文閱讀題的情感分析是不恰當(dāng)?shù)摹T撐囊許nowNlp的情感分析模型為基礎(chǔ),設(shè)計(jì)并構(gòu)建了學(xué)科情感分析模型,用于對(duì)古詩文閱讀題答案的情感分析與評(píng)價(jià),模型結(jié)構(gòu)如圖2所示。
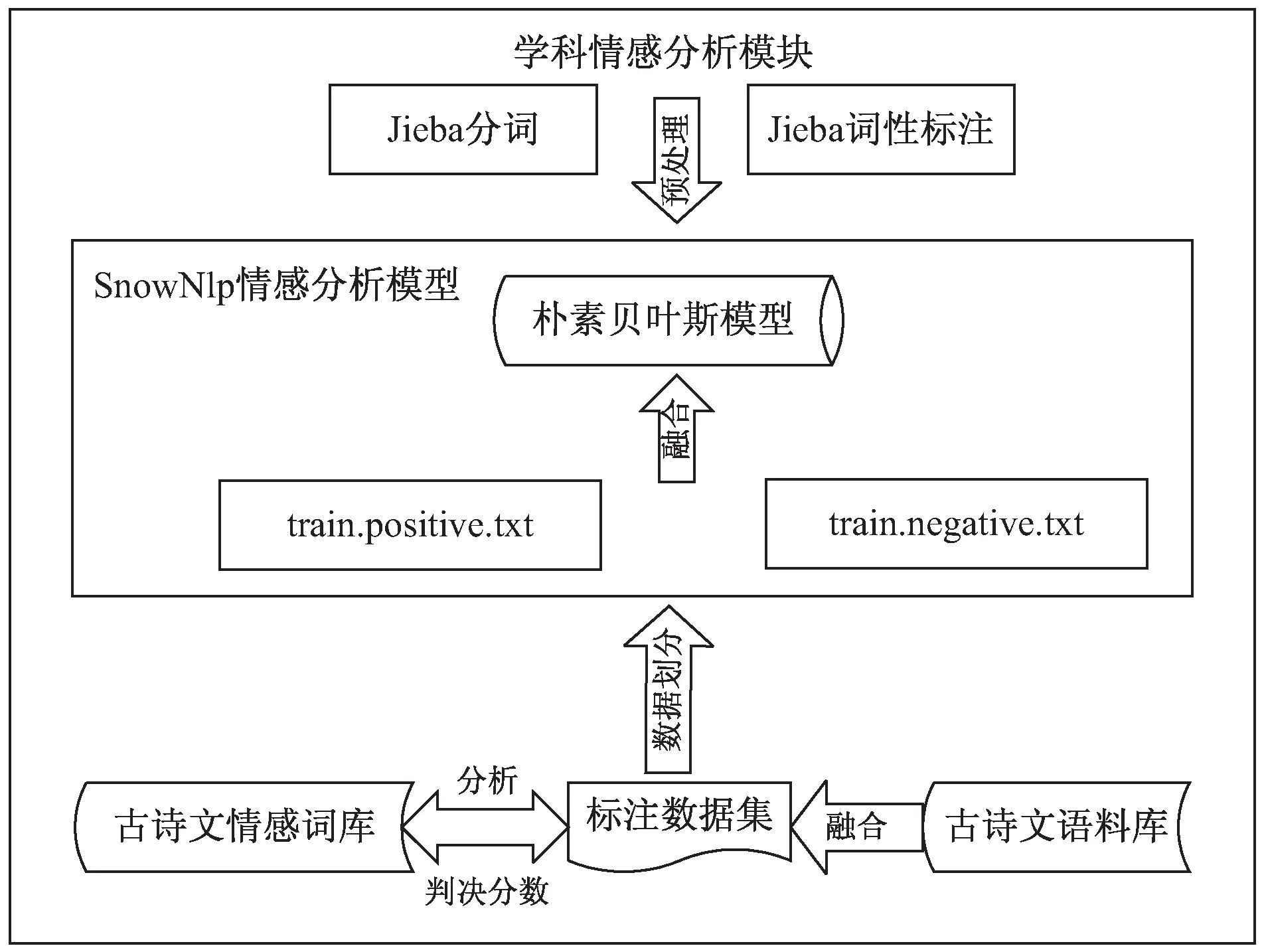
圖2 情感分析模型
從圖2可以看出,整個(gè)構(gòu)建過程主要分為三個(gè)模塊,分別為:數(shù)據(jù)模塊、預(yù)處理模塊和訓(xùn)練模塊。
數(shù)據(jù)模塊:該文收集了陜西省某重點(diǎn)高中近五年全部考試中的古詩文類閱讀題,整理了學(xué)生答案與教師評(píng)分,將其融入古詩文語料,生成帶標(biāo)注的基礎(chǔ)數(shù)據(jù)。根據(jù)學(xué)生分?jǐn)?shù)分布規(guī)律,基于分?jǐn)?shù)來判定情感分類。判定時(shí)以標(biāo)準(zhǔn)答案中的情感詞語為基準(zhǔn),高分代表情感更趨向于標(biāo)準(zhǔn)答案情感,低分代表情感與其差別較大,以此確定判決分?jǐn)?shù),將標(biāo)注數(shù)據(jù)集中的學(xué)生答案按照判決分?jǐn)?shù)分別存為積極數(shù)據(jù)集train.positive.txt和消極數(shù)據(jù)集train.negative.txt,并將其作為模型訓(xùn)練的初始語料。
預(yù)處理模塊:構(gòu)建模型初期,使用SnowNlp中的分詞和詞性標(biāo)注模塊,經(jīng)過實(shí)驗(yàn)對(duì)比,發(fā)現(xiàn)通過Jieba工具包對(duì)古詩文學(xué)生答案進(jìn)行分詞和詞性標(biāo)注更加合適,因此在SnowNlp模型中引入Jieba工具包,將其分詞和詞性標(biāo)注方式進(jìn)行更改。
訓(xùn)練模塊:將SnowNlp情感分析模型的積極數(shù)據(jù)集與消極數(shù)據(jù)集分別替換為train.positive.txt和train.negative.txt,作為其模塊中的樸素貝葉斯算法的訓(xùn)練數(shù)據(jù)。訓(xùn)練過程中,運(yùn)用網(wǎng)格搜索法,用于搜索滿足最高準(zhǔn)確率時(shí)對(duì)應(yīng)參數(shù)值的大小,進(jìn)行超參數(shù)的調(diào)整,將以SnowNlp進(jìn)行分詞和詞性標(biāo)注的訓(xùn)練模型保存為GswSen.marshal,以Jieba進(jìn)行預(yù)處理的訓(xùn)練模型保存為GswJieSen.marshal。修改sentiment中的模型路徑,將新模型進(jìn)行替換,模型構(gòu)建完成。
不同模型的情感分析數(shù)值對(duì)比如表1所示。可以看出學(xué)科情感分析模型對(duì)學(xué)生答案的情感分析是更準(zhǔn)確的(數(shù)值在0~1之間,數(shù)值越高表示越積極,數(shù)值越低表示越消極)。
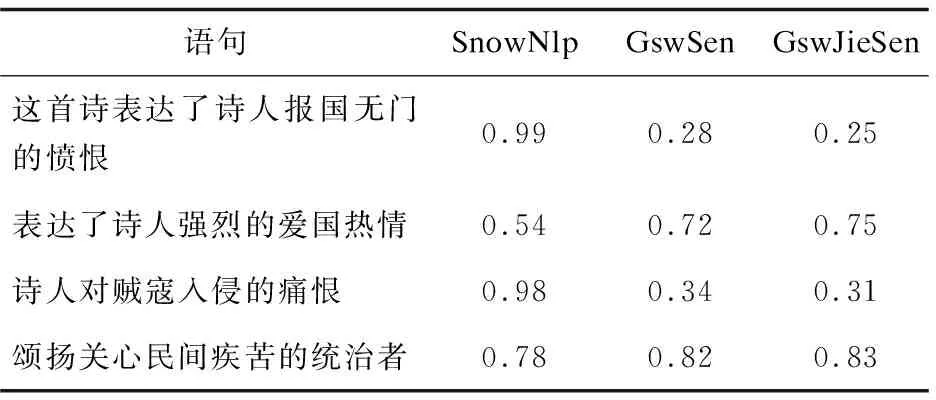
表1 不同模型的情感分析數(shù)值對(duì)比
2 結(jié)合學(xué)科情感分析與依存關(guān)系的相似度評(píng)分算法
情感與依存關(guān)系在古詩文主觀題的評(píng)分中至關(guān)重要,而學(xué)生答案與標(biāo)準(zhǔn)答案中的關(guān)鍵詞相似度也對(duì)評(píng)分結(jié)果影響較大,因此,該文基于多個(gè)維度對(duì)古詩文主觀題進(jìn)行相似度綜合評(píng)分。
2.1 基于詞性的關(guān)鍵詞相似度計(jì)算
在古詩文主觀題評(píng)分過程中,如何在考生答案中獲取得分點(diǎn)十分重要,得分點(diǎn)其實(shí)就意味著答案中的得分關(guān)鍵詞,且考生答案中的關(guān)鍵詞與標(biāo)準(zhǔn)答案中的關(guān)鍵詞是否完全一樣,相似度是多少,也是教師評(píng)分過程中一個(gè)重要的評(píng)判標(biāo)準(zhǔn)。因此,該文提出了基于關(guān)鍵詞提取的詞向量相似度計(jì)算方法。
2.1.1 關(guān)鍵詞提取
傳統(tǒng)意義上的關(guān)鍵詞提取方法主要有TF-IDF、TextRank、LDA等。通常是通過詞頻或是提取文檔中的主題來進(jìn)行,但是學(xué)生答案屬于短文本,且用詞比較單一和平均,用已有關(guān)鍵詞提取算法顯然是不能滿足需求的。因此該文根據(jù)學(xué)科特征,將學(xué)生答案和標(biāo)準(zhǔn)答案進(jìn)行拆分,拆分后的詞語,如“表達(dá)”、“體現(xiàn)”等不是得分點(diǎn),且會(huì)對(duì)評(píng)分造成影響的詞語,將其通過古詩文過濾詞表進(jìn)行過濾,并按照詞性進(jìn)行關(guān)鍵詞的提取。具體算法(WordClass)如下:
算法1:WordClass算法。
輸入:學(xué)生答案文本A和標(biāo)準(zhǔn)答案文本A
輸出:序列Nord和Nord
Step1 初始化:古詩文過濾詞表gswfil,古詩文語料庫gswmodel;
Step2 基于Jieba將A和A進(jìn)行分詞和詞性標(biāo)注,得到序列Ord(w
,f
)={(w
,f
), (w
,f
),…,(w
1,f
1)}和Ord(w
,f
)={(w
,f
),(w
,f
),…,(w
2,f
2)},其中Ord和Ord分別表示A和A預(yù)處理后的序列,w
表示詞語,f
表示詞語w
對(duì)應(yīng)的詞性;Step3 遍歷Ord和Ord,分別在gswfil中進(jìn)行查找,若有相同詞語,則將該詞語及其詞性在對(duì)應(yīng)序列中刪除,直到遍歷結(jié)束;
Step4 將Ord和Ord中詞性為“v”(動(dòng)詞),“n”(名詞),“a”(形容詞)和“i”(成語)開頭的詞語通過正則表達(dá)式查找,并將其提取出來,得到新序列Nord={w
,w
,…,w
1}, Nord={w
,w
,…,w
2}。2.1.2 關(guān)鍵詞詞向量的相似度計(jì)算
該文基于古詩文語料庫將提取的關(guān)鍵詞表示為詞向量,其每一維的值代表一個(gè)具有一定的語義和語法上解釋的特征,并將其通過相加求和再平均得出句向量,利用Tanimoto系數(shù)得出兩個(gè)句向量之間的相似度,具體算法(VecMate)如下:
算法2:VecMate算法。
輸入:學(xué)生答案文本A和標(biāo)準(zhǔn)答案文本A
輸出:句子相似度Sim(A,A)
Step1 初始化:古詩文語料庫gswmodel;
Step2 將A和A通過WordClass算法,得到序列Nord={w
,w
,…,w
1}和Nord={w
,w
,…,w
2};Step3 將Nord和Nord進(jìn)行遍歷,查詢?cè)~語是否在gswmodel中,若不存在,則將該詞語在對(duì)應(yīng)序列中刪除,將對(duì)應(yīng)序列的長(zhǎng)度減1,得到處理后的Nord及其長(zhǎng)度L
和處理后的Nord及其長(zhǎng)度L
,若L
、L
其中一個(gè)為零或兩個(gè)都為零,則相似度Sim=0,輸出Sim,否則到Step4;Step4 通過gswmodel將Nord和Nord中的詞語表示為詞向量,通過式1分別計(jì)算,其中(192維)表示序列中第i
個(gè)詞語的詞向量,得出句向量和;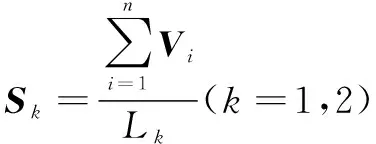
(1)
Step5 根據(jù)Tanimoto系數(shù)算法,通過式2計(jì)算和的相似度Sim(,)。Sim(,)=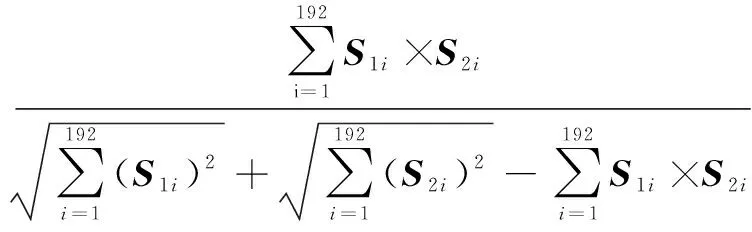
(2)
2.2 基于學(xué)科情感分析模型的相似度計(jì)算
計(jì)算機(jī)語言學(xué)中,情感分析指判定文本所持有情感(或觀點(diǎn)、態(tài)度)的極性和強(qiáng)度的過程。該文通過對(duì)學(xué)生答案和標(biāo)準(zhǔn)答案的情感傾向分析,結(jié)合古詩文情感詞庫與學(xué)科情感分析模型分別計(jì)算兩個(gè)文本對(duì)應(yīng)的積極情感數(shù)值,實(shí)現(xiàn)相似度評(píng)分計(jì)算,具體算法(ActSen)如下:
算法3:ActSen算法。
輸入:學(xué)生答案文本A和標(biāo)準(zhǔn)答案文本A
輸出:句子情感相似度Sensim(A,A)
Step1 初始化:古詩文情感詞庫gswsen,學(xué)科情感分析模型GswJieSen;
Step2 通過WordClass算法,得到序列Nord和Nord;
Step3 對(duì)Nord和Nord進(jìn)行遍歷,分別查詢?cè)~語是否在gswsen中,若存在,將gswsen中含有該詞的序列作為列表Yseq中的元素提取出來;若不存在,則將該詞語分別存入Nseq和Nseq;得到對(duì)應(yīng)序列長(zhǎng)度Lg和Lg,若Yseq的長(zhǎng)度大于零,轉(zhuǎn)Step4,否則,轉(zhuǎn)Step5;
Step4 遍歷Yseq,獲取Yseq中每個(gè)序列中下標(biāo)1對(duì)應(yīng)的元素Num,若Num對(duì)2取余不等于零,則將其對(duì)應(yīng)的數(shù)量Jsum(初始值為零)加1;
Step5 遍歷Nseq和Nseq中的所有詞語,查詢GswJieSen中是否存在該詞語,若存在,則將其通過GswJieSen進(jìn)行情感分析,若其情感數(shù)值大于并等于0.6,則將Jsum加一,若不存在,則將其情感分析數(shù)值記為0.5(默認(rèn)中性詞匯),Xsum(初始值為零)加1;
Step6 通過式3計(jì)算兩個(gè)句子的積極情感分析數(shù)值(情感相似度)Sensim(Nord,Nord);
Sensim(Nord,Nord)=
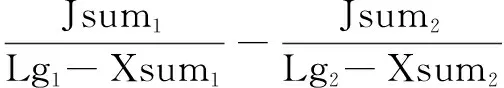
(3)
2.3 基于依存關(guān)系的相似度計(jì)算
在學(xué)生作答過程中,有時(shí)會(huì)出現(xiàn)對(duì)應(yīng)于相同的賓語,謂語動(dòng)詞的情感完全相反的情況,若不考慮詞語的順序,很有可能會(huì)造成誤判。如“詩人熱愛國家,對(duì)賊寇的痛恨”為得分答案,學(xué)生作答為“詩人痛恨國家,對(duì)賊寇的熱愛”,若不考慮詞語在句子中的結(jié)構(gòu)信息,兩個(gè)句子會(huì)得到相同的分?jǐn)?shù),顯然不合理,因此,需要對(duì)重點(diǎn)詞語進(jìn)行所屬關(guān)系定位。依存句法分析的主要任務(wù)是識(shí)別出句子所包含的句法成分以及這些成分之間的關(guān)系。該文采用StanfordCoreNLP的依存句法分析進(jìn)行相似度的計(jì)算,先將句子的主謂、動(dòng)賓關(guān)系找到,并將其通過主語和賓語進(jìn)行定位,以此來確定謂語詞的情感傾向,實(shí)現(xiàn)相似度計(jì)算,具體算法(WordLoc)如下:
算法4:WordLoc算法。
輸入:學(xué)生答案文本A和標(biāo)準(zhǔn)答案文本A
輸出:基于依存關(guān)系的句子相似度Depsim(A,A)。
Step1 初始化:古詩文語料庫gswmodel,學(xué)科情感分析模型GswJieSen,StanfordCoreNLP依存句法分析模型Sparse;
Step2 將答案文本基于正則表達(dá)式進(jìn)行分句,得到序列Sord={ss,ss,…,ss}和Sord={cs,cs,…,cs},其中ss表示學(xué)生答案中拆分的句子,cs表示標(biāo)準(zhǔn)答案中拆分的句子;
Step3 遍歷Sord和Sord,將ss和cs分別通過Sparse進(jìn)行依存句法分析,將其對(duì)應(yīng)的句子結(jié)構(gòu)表示Mord(s,v,o)={(s,v,o),(s,v,o),…,(s1,v1,o1)}和Mord(s,v,o)={(s,v,o),(s,v,o),…,(s,v, o)},其中s,v,o分別表示句子的主語、謂語和賓語,若句子結(jié)構(gòu)不完整,則將該詞語用占位符x代替;
Step4 遍歷Mord(s,v,o),查找Mord(s,v,o)中與o1相同的詞語,并將其對(duì)應(yīng)的謂語進(jìn)行提取,若Mord中無相同詞語,則將o1和o2通過gswmodel進(jìn)行相似度對(duì)比,若相似度大于0.8則將o1和o2對(duì)應(yīng)的謂語進(jìn)行提取,若不滿足條件,則視為學(xué)生未作答該得分點(diǎn);
Step5 得到序列Vord(v)={(vi,vi),(vi,vi),…,(v1,v2)},其中vi表示所提取的謂語;
Step6 遍歷Vord(v),得到其長(zhǎng)度Lv,通過模型GswJieSen將vi1和vi2進(jìn)行情感分析,兩個(gè)詞語數(shù)值相減的絕對(duì)值小于等于0.15,則認(rèn)為其情感表達(dá)一致,將Vsum(初始值為零)加1;
Step7 通過式4計(jì)算兩個(gè)句子的相似度Depsim(AA);

(4)
2.4 結(jié)合學(xué)科情感分析與依存關(guān)系的相似度評(píng)分算法
該文通過關(guān)鍵詞詞向量相似度、學(xué)科情感分析模型的相似度以及依存句法分析的相似度,多個(gè)維度計(jì)算學(xué)生答案與標(biāo)準(zhǔn)答案文本之間的加權(quán)語義相似度。并將構(gòu)建的古詩文語料庫、古詩文情感詞庫和學(xué)科情感分析模型,用于相似度綜合評(píng)分算法,符合語文學(xué)科背景,具體算法如下:
算法5:結(jié)合學(xué)科情感模型與依存關(guān)系相似度評(píng)分算法。
輸入:學(xué)生答案文本A和標(biāo)準(zhǔn)答案文本A
輸出:學(xué)生得分Stugrade
Step1 初始化:古詩文語料庫gswmodel,古詩文情感詞庫gswsen,學(xué)科情感分析模型gswsenmod,依存句法分析模型Sparse;
Step2 將A和A通過WordClass算法,得到序列Nord(w
,f
)={(w
,f
), (w
,f
),…,(w
1,f
1)和Nord(w
,f
)={(w
,f
),(w
,f
),…,(w
2,f
2)} ,通過VecMate算法得到Vecsim(A,A);Step3 將序列Nord和Nord中詞性以“n”和“v”開頭的詞語通過正則表達(dá)式提取出來,分別存入Nseq(n)={n1,n2,…,n}和Vseq(v)={v,v,…,v},(其中i
取值為1,2,i
=1代表學(xué)生答案序列,i
=2代表標(biāo)準(zhǔn)答案序列),Nseq(n)為名詞序列,Vseq(v)為動(dòng)詞序列;Step4 通過ActSen算法,將Nseq(n)進(jìn)行情感分析模型的相似度計(jì)算,得到Nsensim(A,A),將Vseq(v)進(jìn)行情感分析模型的相似度計(jì)算,得到Vsensim(A,A);
Step5 將答案文本A和A代入,通過WordLoc算法,得到相似度Depsim(A,A);
Step6 通過式5進(jìn)行加權(quán)得到考生答案相似度Stusim(A,A)
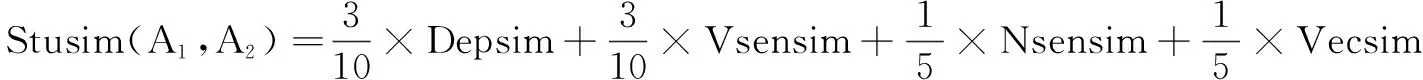
(5)
Step7 通過式6得到考生答案分?jǐn)?shù)Stugrade(A,A),其中total表示該題總分?jǐn)?shù)。
Stugrade(A,A)=total×Stusim(A,A)
(6)
3 實(shí)驗(yàn)對(duì)比與分析
由于目前國內(nèi)沒有用于主觀題自動(dòng)評(píng)分的數(shù)據(jù)集,因此,該文采集了陜西省某高中1 348名考生的真實(shí)考試數(shù)據(jù),其中包括2019屆高三年級(jí)第二學(xué)期語文期末考試和高二年級(jí)第二學(xué)期的語文期末考試中的詩歌鑒賞題和古文翻譯題,其考試形式與高考相同,需要考生將答案寫在答題卡上,由教師通過網(wǎng)上閱卷進(jìn)行評(píng)分。基于以上考試共采集學(xué)生答案和教師得分,共1 348條作為實(shí)驗(yàn)數(shù)據(jù),并進(jìn)行人工整理,構(gòu)建實(shí)驗(yàn)測(cè)試數(shù)據(jù)集,驗(yàn)證基于學(xué)科情感分析與依存關(guān)系的相似度評(píng)分算法的可靠性。
第一組實(shí)驗(yàn):將Word2vec相似度算法、BERT相似度算法、基于BERT與GswJieSen的評(píng)分算法與該評(píng)分算法進(jìn)行實(shí)驗(yàn)對(duì)比,如圖3所示。
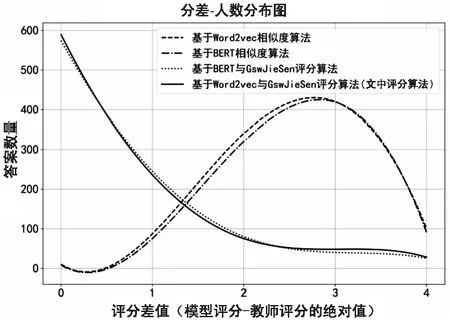
圖3 不同相似度評(píng)分算法之間的實(shí)驗(yàn)對(duì)比
其中,BERT是Google于2018年發(fā)布的基于雙向Transformer結(jié)構(gòu)的語言預(yù)訓(xùn)練模型。從圖3可以看出,基于BERT與GswJieSen的評(píng)分算法與該評(píng)分算法趨勢(shì)相同,評(píng)分差值為零所對(duì)應(yīng)的答案數(shù)量是最多的。在不加入情感模型的相似度算法中,Word2vec相似度算法、BERT相似度算法在相似度評(píng)分中與教師分差主要集中在2~3分?jǐn)?shù)段內(nèi),評(píng)分效果較差。對(duì)應(yīng)于不同的文本向量化算法,結(jié)合學(xué)科情感分析模型都對(duì)評(píng)分準(zhǔn)確率有很大的提升。因此,在古詩文主觀題評(píng)分算法中引入學(xué)科情感分析模型是合理且高效的。
第二組實(shí)驗(yàn):該文將SnowNlp情感分析模型、HanLp自然語言處理情感分析模型與該文構(gòu)建的學(xué)科情感分析模型GswJieSen進(jìn)行評(píng)分相似度算法實(shí)現(xiàn),比較它們?cè)谠u(píng)分上的效果。
從表2可以看出,SnowNlp評(píng)分算法的準(zhǔn)確率相對(duì)較低;HanLp的評(píng)分準(zhǔn)確率與其相差不大;該評(píng)分算法在三個(gè)模型中三項(xiàng)指標(biāo)均為最高,將分差在3分即以上的評(píng)分結(jié)果看作評(píng)分失誤,不予比較。
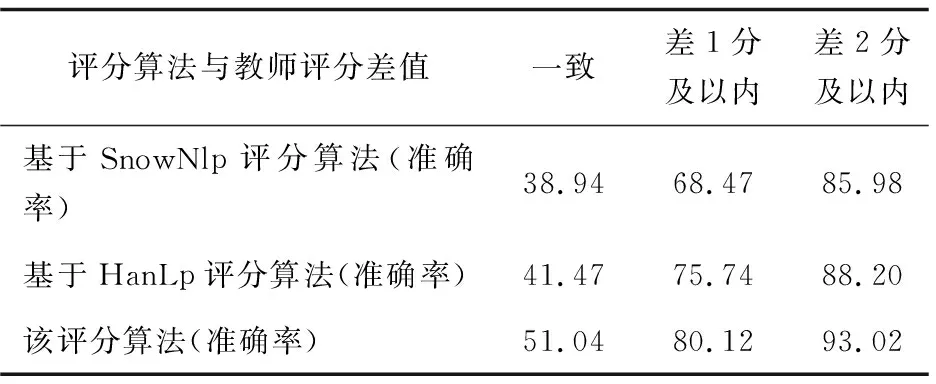
表2 不同評(píng)分模型的準(zhǔn)確率對(duì)比 %
從圖4可以形象地看出,每個(gè)模型對(duì)應(yīng)的差值與個(gè)數(shù)大體上呈現(xiàn)正態(tài)分布。該評(píng)分算法對(duì)應(yīng)的分差為0的個(gè)數(shù)最多,趨勢(shì)較其他模型更為陡峭,±1,±2,…答案數(shù)量依次遞減,評(píng)分差距在2分及以內(nèi)的準(zhǔn)確率為93.02%,可以看到該評(píng)分算法更接近教師的評(píng)分。
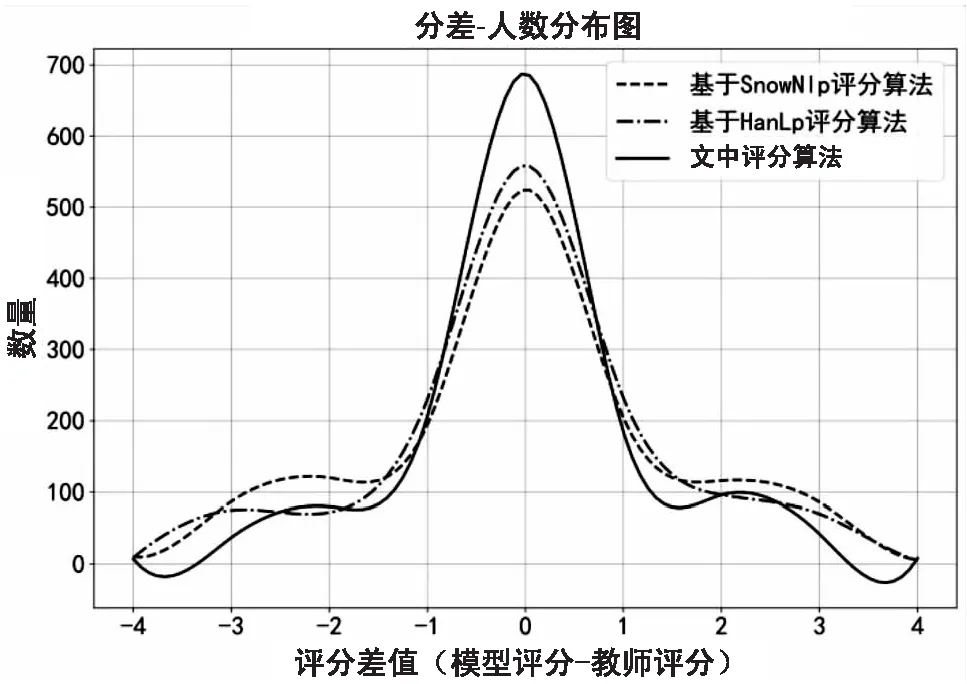
圖4 不同評(píng)分模型之間的分差-人數(shù)分布圖
在1 348條測(cè)試數(shù)據(jù)集中隨機(jī)抽取330個(gè)學(xué)生答案,從圖5可以看出,大部分分?jǐn)?shù)集中在3~5這個(gè)分?jǐn)?shù)段內(nèi),該算法的評(píng)分與教師評(píng)分高低趨勢(shì)相同,且分差不大。從圖6可以更為清晰地看出,該評(píng)分算法與教師評(píng)分準(zhǔn)確率大體分布在85%,結(jié)合表2可以看出評(píng)分一致的準(zhǔn)確率達(dá)到51.03%,差一分的準(zhǔn)確率達(dá)到80.10%,差兩分的準(zhǔn)確率達(dá)到93.02%等。通過式7計(jì)算平均評(píng)分準(zhǔn)確率。
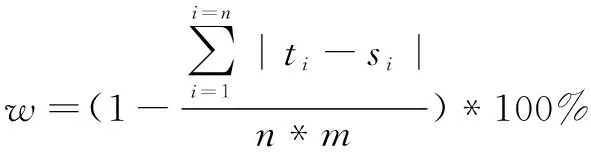
(7)
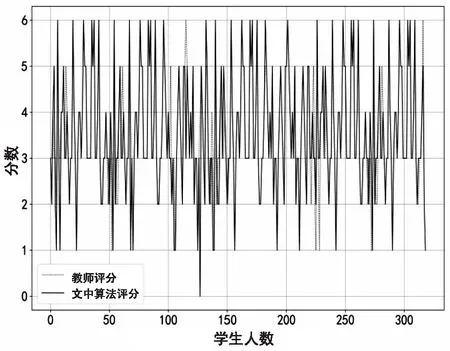
圖5 教師評(píng)分與該相似度評(píng)分算法評(píng)分對(duì)比
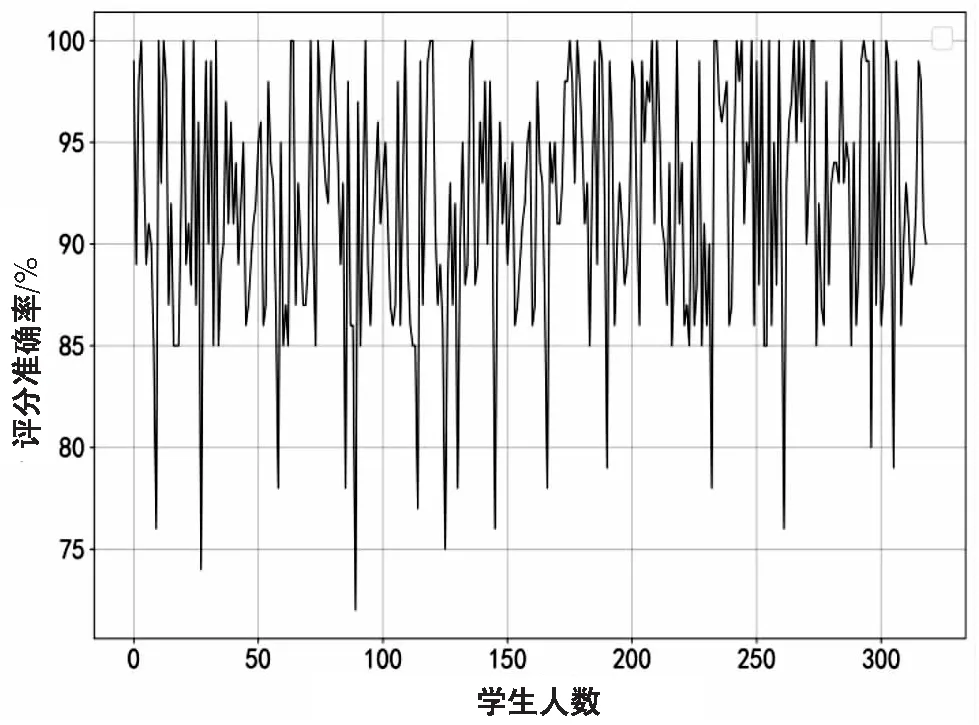
圖6 教師評(píng)分與該相似度算法評(píng)分準(zhǔn)確率
其中,w
表示評(píng)分準(zhǔn)確率,n
表示實(shí)驗(yàn)數(shù)據(jù)集中的數(shù)據(jù)總量,m
表示試題滿分,t
表示教師評(píng)分,s
表示該算法的評(píng)分。可以得出該算法在當(dāng)前實(shí)驗(yàn)測(cè)試集中的平均準(zhǔn)確率為89.42%,實(shí)驗(yàn)證明,基于學(xué)科情感分析模型與依存關(guān)系的相似度評(píng)分算法是有效且準(zhǔn)確的。4 結(jié)束語
根據(jù)語文古詩文閱讀題的特征,實(shí)現(xiàn)了一種基于學(xué)科情感分析模型與依存關(guān)系的相似度評(píng)分算法,將其通過考生考試中真實(shí)的答題數(shù)據(jù)進(jìn)行實(shí)驗(yàn)驗(yàn)證,實(shí)驗(yàn)結(jié)果表明,該算法與教師評(píng)分趨勢(shì)基本一致,準(zhǔn)確率較高。但是,學(xué)科之間存在一定的差異性,同一學(xué)科的不同題型也存在差異性,提出的算法在不同學(xué)科題型的評(píng)分準(zhǔn)確率上并不高,因此,還需根據(jù)不同的學(xué)科題型特征對(duì)算法進(jìn)行調(diào)整,以此實(shí)現(xiàn)適用于不同學(xué)科題型的相似度評(píng)分算法。
猜你喜歡
浙江樹人大學(xué)學(xué)報(bào)(人文社會(huì)科學(xué)版)(2022年4期)2022-08-15 10:58:48
寧波大學(xué)學(xué)報(bào)(理工版)(2022年4期)2022-07-08 05:12:02
寧波大學(xué)學(xué)報(bào)(理工版)(2022年2期)2022-03-15 12:10:56
華北理工大學(xué)學(xué)報(bào)(自然科學(xué)版)(2021年3期)2021-07-03 09:06:34
中國生殖健康(2020年5期)2021-01-18 02:59:48
家庭醫(yī)學(xué)(下半月)(2020年4期)2020-05-30 12:42:50
北極光(2019年12期)2020-01-18 06:22:10
小太陽畫報(bào)(2019年10期)2019-11-04 02:57:59
中國生殖健康(2018年5期)2018-11-06 07:15:40
軍事文摘·科學(xué)少年(2017年4期)2017-06-20 23:29:09
