基于機器學習的火山巖巖性智能識別及預測
2022-03-10 07:20:08鄒正銀王志章蔣慶平常天全王偉方
特種油氣藏 2022年1期
關鍵詞:模型
劉 凱,鄒正銀,王志章,蔣慶平,常天全,王偉方,楊 笑,3
(1.中國石油新疆油田分公司,新疆 克拉瑪依 834000;2.中國石油大學(北京)油氣資源與探測國家重點實驗室,北京 102249;3.中國石油長慶油田分公司,陜西 西安 710018)
0 引 言
1957年,中國火山巖油氣藏在準噶爾盆地首次被成功發現,截至目前,已在11個含油氣盆地中發現火山巖油氣藏[1]。準確識別火山巖巖性特征是研究火山巖油藏的重要基礎,但火山巖巖性復雜,礦物成分多變,測井響應特征不明顯,巖性識別難度極大。SANYAL等[2]利用聲波時差、中子測井曲線的響應特征識別巖性;譚伏霖等[3-4]鑒于取心樣本有限,采取樣本擴充法識別火山巖巖性;由于單一測井曲線很難準確識別巖性,羅德江[5]根據逐步分析法和fisher判別方法進行識別;程國建等[6]將粒子群優化算法(PSO)與最小二乘支持向量機相結合進行識別;鞠武等[7]利用有序聚類分析方法識別;范存輝等[8]利用深度神經網絡結合測井資料進行識別;牟丹、Li等[9-10]基于最小二乘支持向量機識別。該文綜合利用準噶爾盆地金龍2井區的取心、薄片、成像資料解釋的巖性樣本標定測井資料,通過交會圖開展巖性特征分析,判斷巖性與電性相關關系,形成測井和巖性標簽的樣本庫,并隨機將樣本庫分為訓練集(占70%)和測試集(占30%)2個部分。結合機器學習中的決策樹、隨機森林、梯度提升樹和貝葉斯算法,利用同一訓練集建立4種火山巖巖性識別模型,并利用同一測試集評價這4種模型的穩定性,優選算法模型,實現利用常規測井曲線識別火山巖巖性。
1 原理方法
1.1 決策樹算法
決策樹是對實例進行分類描述的樹形結構,由結點和有向邊組成,也是屬性與值之間的一種映射關系。根據特征選擇不同算法,主要包括ID3算法、C4.5算法和CATR算法[11]。ID3算法是在原始決策樹算法的基礎上實現的,其特點是在結點上選擇特征時采用信息增益。C4.5算法是對ID3算法的改進,其利用信息增益率來進行特征屬性的選擇,避免了偏向多值的特征屬性。CATR算法使用基尼系數代替信息增益,基尼系數代表了模型的不純度,基尼系數越小,不純度越低。
1.2 隨機森林算法
隨機森林算法屬于集成學習的一種。隨機森林算法分配給每棵樹的樣本從數據集中隨機抽取,抽取完后放回數據集中[12]。每抽取一次數據,就建立一個決策樹模型,最后所有的決策樹就形成了一片森林,通過投票決策的方式,確定最終的預測結果。該算法在決策樹算法的基礎上,引入2個不同的隨機條件,第1次隨機條件是從數據集中隨機地抽取訓練數據集,每抽取一次形成一棵決策樹;第2次隨機條件是從抽取的訓練集中的數據特征屬性集合n中隨機選取S(S≤n)個特征屬性集合。這2個隨機條件使得該算法相比決策樹具有更好的效果[13]。
1.3 梯度提升樹算法
梯度提升樹算法是一種迭代的回歸決策樹算法,由多棵決策樹組成,將所有決策樹的結論累加起來就是最終的結論[14]。該算法主要用于分類和回歸2個方面。在各結點分支時,選擇最小化均方差來判斷結點分支[15]。
1.4 貝葉斯算法
貝葉斯算法根據已知的數據學習計算出先驗概率,再根據條件獨立性假設計算條件概率,最后計算后驗概率,對未知數據集進行預測。缺點是建立在樣本屬性獨立性假設的基礎上,如果樣本屬性有關聯,其效果較差[16]。
2 研究區實際應用
2.1 火山巖巖性常規測井響應特征
不同類型的火山巖由于其化學成分、礦物成分、物性特征等存在差異,導致其測井響應特征存在一些變化[17-23]。研究區火山碎屑巖類主要有火山角礫巖、熔結角礫巖;熔巖類主要有玄武巖、安山巖、英安巖、流紋巖(圖1)。火山巖越致密電阻率越高,熔巖類的電阻率高于火山碎屑巖類,熔巖中英安巖裂縫發育較少,電阻率很高,安山巖、流紋巖和玄武巖等由于裂縫和氣孔的影響導致電阻率偏低。從基性到酸性火山巖,放射性增加,基性玄武巖自然伽馬小于26 API,中性安山巖在45 API左右,酸性英安巖和流紋巖大于65 API。火山角礫巖和熔結角礫巖存在較大的原生孔隙,中子值約為20%左右,是該區主要儲層;安山巖由于裂縫發育,中子值約為17%;玄武巖由于發育杏仁構造,中子值高達25%,流紋巖和英安巖致密,中子值約為10%。從基性到酸性火山巖,密度逐漸變小,玄武巖為2.70 g/cm3左右,安山巖為2.54 g/cm3左右,流紋巖密度最低,火山碎屑巖的密度低于熔巖。火山碎屑巖的聲波時差略高于熔巖,火山角礫巖和熔結角礫巖聲波時差在65 μs/m左右,英安巖聲波時差約為57 μs/m,玄武巖、流紋巖和安山巖聲波時差約為60 μs/m。利用成像測井靜態圖并結合周圍巖石電阻率變化可區分沉積巖和火成巖[24-25];利用FMI動態圖可以識別火山碎屑巖和具有流紋構造的流紋巖;利用動態圖和常規測井曲線可以識別英安巖、安山巖和不具流紋構造的流紋巖。
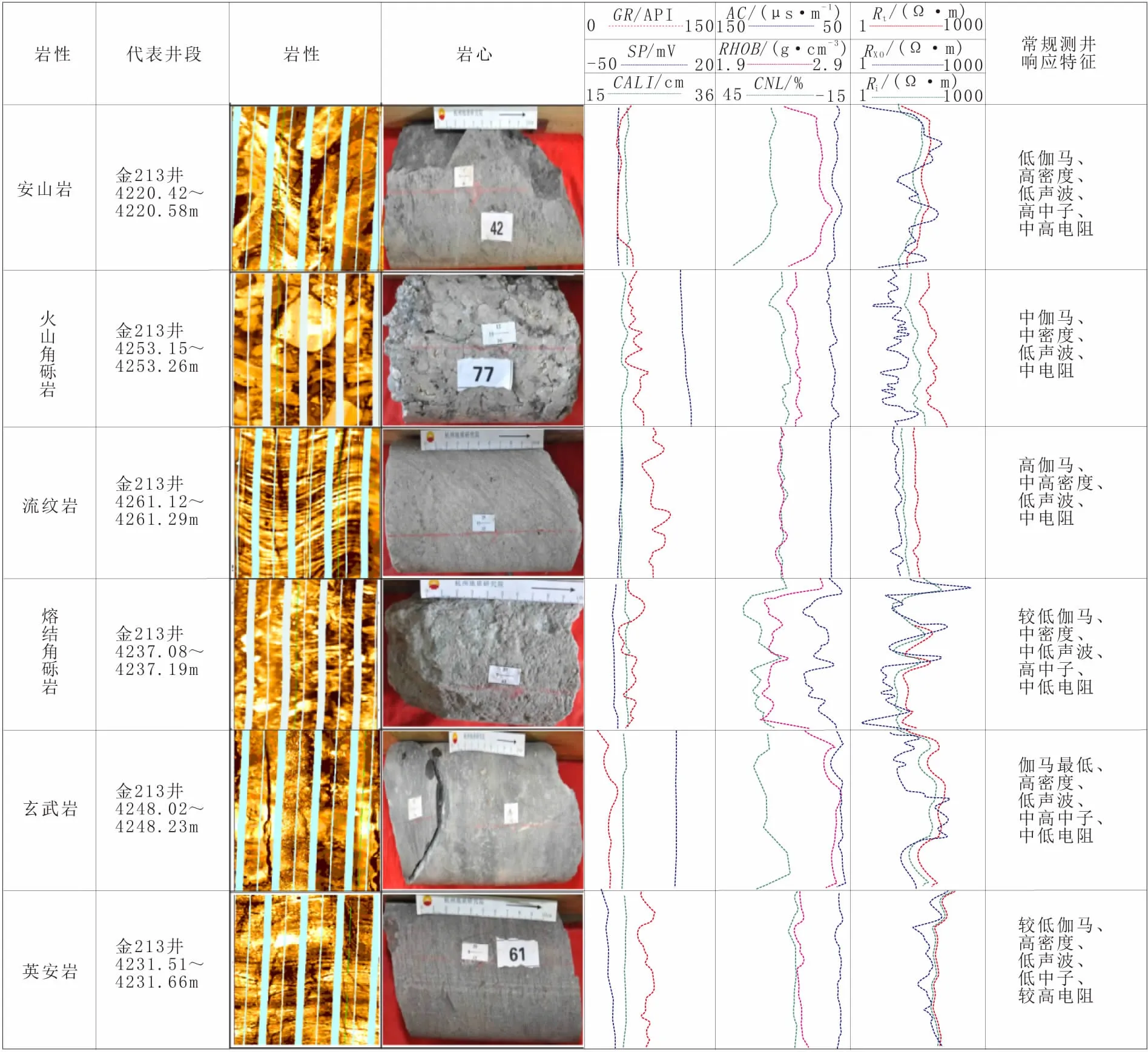
圖1 火山巖測井響應特征
2.2 M-N交會圖
以往的研究中,常采用密度與自然伽馬等交會圖分析不同巖性特征,提取敏感特征[26-32]。分析表明,此方法很難將各類巖性區分開。因此,應用中子、密度和聲波3種孔隙度測井曲線,通過求解M、N值,進行交會圖分析,旨在消除裂縫造成的孔隙度影響,更準確識別巖性(圖2)。
(1)
(2)
式中:M為聲波與密度交會圖中流體點與骨架點連線的斜率,(μs·cm3)/(m·g);N為中子與密度交會圖中流體點和骨架點連線的斜率,cm3/g;Δtf為聲波時差測井的液體時差值,μs/m;Δt為聲波時差測井值,μs/m;ρb為測井密度值,g/cm3;ρf為液體密度值,g/cm3;φNf為中子測井的液體值,%;φN為中子測井值,%。
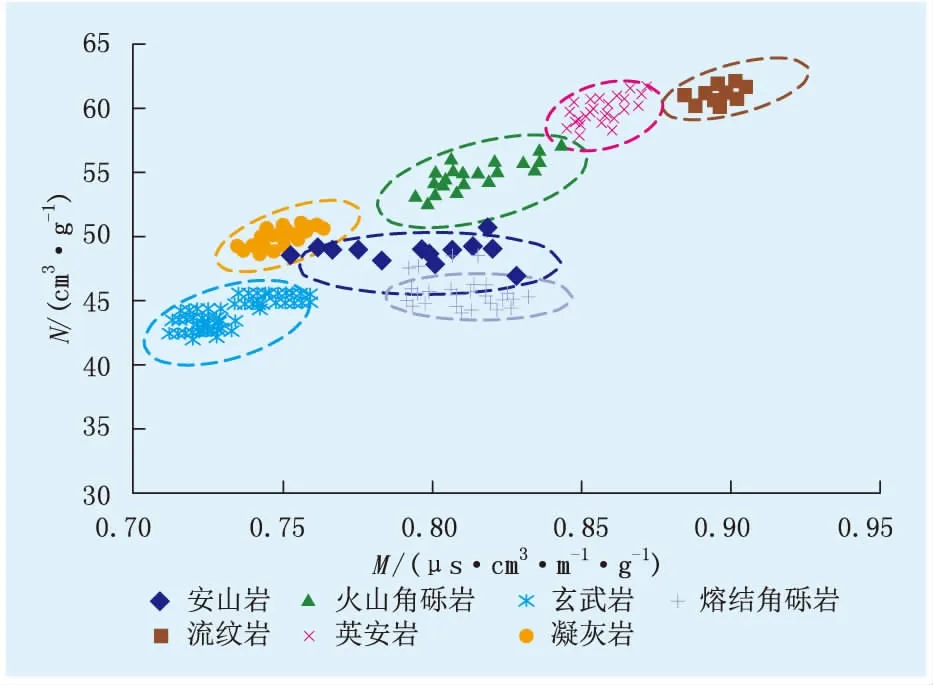
圖2 M-N交會圖
2.3 機器學習巖性識別
利用機器學習建立巖性分類及預測模型,具體包括:樣本庫的建立、特征參數選擇、測井特征數據的歸一化、訓練模型、評價模型以及巖性預測。
2.3.1 樣本庫建立
依據研究區5口井取心資料、測井數據和成像測井數據,分析測井數據與不同火山巖巖性的對應關系,生成樣本空間。
2.3.2 特征參數選擇
前文具體分析了不同火山巖巖性的測井響應特征,優選出巖性敏感的測井曲線,同時,根據2個新的特征值,即M和N,最終確定巖性敏感特征參數為:GR、N、Ri、M、CNL、DT、Rt、DEN,其占用的權重比依次為0.22、0.18、0.16、0.13、0.11、0.08、0.07、0.05。
2.3.3 測井數據歸一化
由于巖性數據測量儀器不同,數值上會存在一定的系統偏差,因此,對測井數據需進行歸一化處理。數據歸一化處理可以消除量綱影響,降低不同測井儀器測量絕對值誤差導致的影響,利于后期建立的模型對全區井段都能有很好的預測效果。因此,將選取的8種特征全部歸一化到[0,1]中。對于GR、DT、DEN、CNL、M、N采用線性變量歸一化處理,即:
(3)
式中:Y為測井曲線歸一化結果;X為某一深度的某測井曲線值;Xmin為同一測井曲線的最小值;Xmax為同一測井曲線的最大值。
對于電阻Rt、Ri,采用先取對數,再歸一化,即:
(4)
為準確獲得特征參數最大值和最小值,避免一些極端值參與運算,干擾主體數據的歸一化,采用累積概率曲線一次求導(斜率)的方法來獲取特征的最大和最小值。
2.3.4 訓練模型
在機器學習模型的訓練過程中,為了使模型具有更好地泛化能力,需將數據集分割為訓練集與測試集。根據準噶爾盆地金龍2區塊的巖心數據,建立各類巖性樣本庫。各類巖性樣本點總數為4 744個,將樣本數據隨機切分為訓練集和測試集,其中,訓練集占70%,數量為3 320個巖性樣本點,測試集占30%,數量為1 424個巖性樣本點。訓練集用于訓練模型,測試集用于檢驗模型的泛化能力。4種機器學習算法的主要參數為:①min-sample-split,為分裂一個內部節點(非葉節點)所需的最小樣本數;②min-samples-leaf,為每個葉節點所包含的最小樣本數;③learning-rate為每個學習器的學習率,即權重的縮減系數或步長,取值范圍為[0,1];④n-estimators為弱學習器的最大迭代次數,或者是最大的弱學習器的個數,一般選擇在[0.5,0.8]。
2.3.5 模型評價
為了更好地確定火山巖巖性識別模型的預測精度和泛化能力,利用精確率、召回率、ROC曲線確定分類模型的準確性和泛化能力。
精確率是被判定為正類樣本數中實際為正類的比例:
(5)
召回率是覆蓋面的度量,類似于靈敏度,度量有多少個正類樣本數被判定為正類:
(6)
式中:P為精確率,%;recall為召回率,%;TP為正類判定為正類的樣本數,個;FP為負類判定為正類的樣本數,個;FN為正類判定為負類的樣本數,個。
通過對各類算法在訓練集與測試集的精確率與召回率的比較可知,隨機森林算法具有更好的泛化能力。
ROC曲線是反應模型敏感性與特異性連續變量的綜合指標。其橫坐標FPR為預測為正但實際為負的樣本占所有負例樣本的比例;縱坐標TPR為預測為正且實際為正的樣本占所有正例樣本的比例。(0,0)代表所有樣本全部被判定為負類,(1,1)代表所有樣本被判定為正類,(0,1)代表最完美分類。圖3為不同算法的ROC曲線,隨機森林算法和梯度提升樹算法的性能較好,能很好地向(0,1)點靠近,其次是決策樹算法,而貝葉斯算法較差。AUC值為ROC曲線下與坐標軸圍城的面積,是衡量算法優劣的一種性能指標,AUC越接近1,則算法真實性越高。隨機森林算法和梯度提升樹算法效果較好,每種巖性的AUC值都接近于1。
3 預測效果分析
根據前文建立的模型對未知井段進行預測,為驗證預測的準確性,采用未參與建模的取心井進行預測驗證。選取JIN204、JIN214井為盲井進行驗證。其中,JIN204有3段取心,如圖4a所示,自上而下分別為安山巖、流紋巖、凝灰巖與火山角礫巖互層。在第2段流紋巖處,4種算法都取得了準確的預測效果;第1段安山巖處,除梯度提升樹算法外都進行了準確的預測;第3段凝灰巖與火山角礫巖的互層,只有隨機森林算法取得了很好的效果。JIN214井是全區取心厚度較大的井,主要為火山角礫巖與安山巖巖心,如圖4b所示,4種算法都能取得很好的預測結果。但在4 100~4 120 m處,安山巖與火山角礫巖疊置發育的部位,隨機森林算法預測效果更好。通過對4種算法的模型評價與優選表明,隨機森林算法較好。
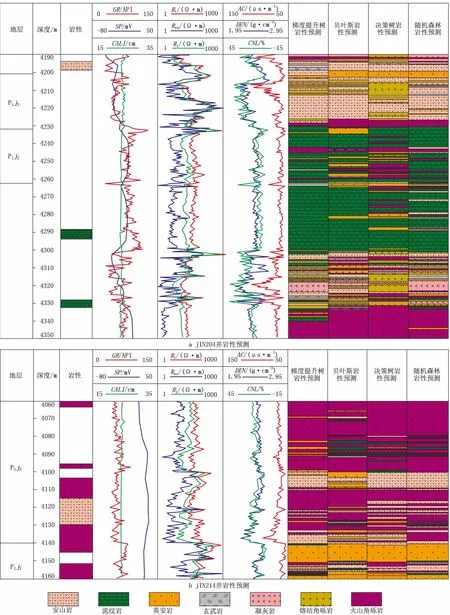
圖4 典型井巖性預測結果
4 結 論
(1) 結合取心、薄片、成像、實驗分析數據確定巖性,并根據測井響應特征分析標定測井曲線對應的巖性,形成測井曲線和巖性對應樣本庫,為后續機器學習訓練預測奠定基礎。
(2) 根據建立的樣本庫數據,對數據進行歸一化處理,利用機器學習中的決策樹、隨機森林、梯度提升樹和貝葉斯算法,采用交叉驗證和網格搜索優選每個模型的最優參數,建立4種機器學習模型,并對這4種不同模型評價優選,選出最優的隨機森林算法模型。
(3) 利用優選出的隨機森林模型,對該研究區45口井巖性智能解釋,通過對取心井段的統計驗證,結果與井段取心的符合率高。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
