自適應短文本關鍵詞生成模型
2022-03-08 12:24:52王永劍孫亞茹楊瑩
北京航空航天大學學報 2022年2期
王永劍,孫亞茹,楊瑩
(公安部第三研究所,上海 201204)
關鍵詞是文檔內容的緊湊表示,由一個或多個字組成[1-2]。對短文本進行關鍵詞匹配可以有效表達文本主題,關鍵詞識別的準確度對文本分類、文本推薦及文本搜索存在著較大的影響,是文本挖掘和文本分析領域中一項重要的基礎工作[3]。正確提取文本的關鍵詞,有助于對文本的主題進行全面的研究和分析,亦可以對文本做出很好的決策。但因短文本在內容結構上表達靈活和主題風格各異等特點,使得從短文本中提取關鍵詞成為了一項具有挑戰性的任務。
分析社交平臺發文數據最重要的任務之一是關鍵字提取。由于社交平臺發文文本較短,字數限制140個字符,內容多樣性、非正式性、語法錯誤、流行語、俚語及實時內容的生成速度等問題,需要一種有效的技術來提取有用的關鍵詞[4]。傳統的關鍵詞提取方法主要是基于機器學習[5-7]或圖模型[1,8-9]。機器學習方法通常采用特征值量化的方式從預處理后構建的候選集中得到關鍵詞,如基于頻率特征的TF-IDF模型、挖掘詞句隱藏信息的LAD和HMM模型。詞劃分的準確度會對這些模型造成較大的擾動,并且存在語義缺失等問題。圖模型對文本構建網絡圖,詞為節點,邊為詞間的關系。在對圖進行分析的過程中,通過評估節點重要性來選出關鍵詞,這增強了節點間的語義關聯,如基于拓撲結構的TextRank和在TextRank的基礎上改進的NE-Rank[10]。NE-Rank是一種節點-邊的加權方法,通過構造主題關鍵詞特征來有效改進關鍵詞提取。盡管基于機器學習和圖模型的方法取得了良好的效果,但是會受特征選擇和人工定義規則的影響。近年來,隨著深度學習技術的出現,利用深度學習算法自動學習特征可以提高許多任務的性能。采用卷積神經網絡在文本字符級上建模,學習文本和單詞間的分布矢量表示,以捕獲有關單詞的形態信息,有效緩解了未知單詞的問題[11]。然而卷積神經網絡無法捕獲長距離依賴,獲取到的是文本局部特征。楊丹浩等[12]采用序列標注模型從字粒度和詞粒度角度結合注意力機制[13-14]提取文本特征,有效改進中文文本的關鍵詞提取。序列標注模型在文本處理領域取得了較好的進展,基于深度Bi-LSTM的ELMo[15]可以學習到詞在上下文中復雜的用法,但是序列模型當前步的計算依賴前一步的計算,無法考慮另一個方向的數據。圖神經網絡(graph neural network,GNN)的出現緩解了深度學習模型處理文本數據結構的一系列問題。圖神經網絡將詞、句子或詞句搭配表示成圖中的節點,節點的表征依賴與其相鄰的節點,邊表示節點間不同類型的關系,在圖結構上應用神經網絡可以直接獲取節點依賴信息。但是基于有監督學習的模型依賴標簽數據,存在模型移植性能差、不能有效發現新詞等問題。綜上,如何使模型可以正確劃分詞并能夠識別出可以表達文本主題的關鍵詞或詞組是任務的關鍵。
針對上述所提問題,本文提出了一種以圖神經網絡為框架結合注意力機制的關鍵詞生成模型—— ADGCN,有效捕獲關鍵詞與文本主題間的關聯密度,擺脫數據領域的偏向,以提高無監督學習方法的性能。基于圖到序列的學習模型,在文本數據結構上應用圖神經網絡的同時結合注意力機制捕獲數據中豐富的語義信息,自適應地將局部特征與全局依賴性相結合,使模型有效學習節點間的關聯強度,更有效地利用圖結構中的信息。
本文的主要貢獻如下:
1)構建文本內容與主題標簽間的圖鏈接,通過圖構建層來表征文本的內部結構和主題間的關系。在圖構建層的基礎上采用注意力機制來學習節點特征空間的相關性,關注不同子空間的信息,引導節點間的關聯密度。
2)提出了一種新的線性解碼模型,采用圖神經網絡編碼圖信息,捕獲節點間的遠依賴信息,解決未登錄詞的問題。
3)收集并公布了一個社交平臺的標簽數據集。
1 相關工作
1.1 圖神經網絡
圖神經網絡模型在圖形結構數據建模方面的應用越來越受到人們的關注,包括關系結構明確的社會網絡預測系統[16]、推薦系統[17-18]、知識圖譜[19]等,也包括關系結構不明確的非結構化場景,如圖 像 分 類[20-21]、文 本 處 理[22-27]等。本 文 利用圖神經網絡對非結構化的文本數據進行建模。
近期研究致力于將圖神經網絡應用于文本分類任務中,涉及到將文本建模為圖。文獻[23]提出將文檔轉換為單詞共現圖,再將其用作圖卷積層的輸入,利用圖表示的優勢,有效捕獲非連續和長距離語義的優勢。文獻[24]以概念圖的形式表示文本,通過圖卷積神經網絡(graph convolution neural network,GCN)匯總匹配信號,比較包含相同概念頂點的句子來匹配一對文本。文獻[25]構造了一個文本圖張量,從文本的語義、句法和上下文信息3個角度來學習圖內傳播和圖間傳播,用于協調和集成圖之間的異構信息。本文從以上工作得到啟發,但是這些工作是為分類任務設計的,分類任務和生成任務是存在差別的。
一些研究是基于GCN 做生成任務的。文獻[26-27]提出了一種基于圖序列的Graph2Seq神經網絡模型,結合注意力機制并遵循傳統的編碼器方法,構建了一個圖形編碼器和一個序列編碼器,基于圖神經網絡學習節點間屬性在SQL-totext任務中對SQL查詢進行編碼。文獻[28]提出了基于圖神經網絡解決AMR-to-Text的問題。盡管這些工作將圖神經網絡做為編碼器,但都是利用已經存在的圖形式的信息,如SQL查詢、抽象語義(abstract meaning representation,AMR)圖和依存圖,并且輸入的文本相對社交平臺發文較長,而筆者對短文本處理的工作更具挑戰性。
1.2 關鍵詞提取
關鍵詞提取有利于信息檢索、自動索引、自動分類、自動聚類、自動過濾等應用。文本中的主題不唯一,若只集中在文本語料庫上,可能會導致知識獲取的瓶頸和誤解。目前的方法主要集中在怎樣提取表達文本主題的關鍵詞或詞組。
文獻[29]提出了一個利用主題模型從大眾分類提取主題關鍵概念的方法。根據標簽相對于某個主題的重要性進行排序,將排名靠前的標簽作為提取主題關鍵的概念。文獻[30]提出了一種以圖表示文檔、以節點表示文檔單詞、以邊表示文檔單詞之間關系的關鍵字提取算法,用度和臨近度中心測量主題關鍵詞。文獻[31]提出了一種利用3個主要因素不同于其他關鍵詞提取方法,這3個主要因素是前面話題的時間、話題關聯和參與者。當前發表言論的人應該被認為比其他參與者的言論更重要。本文從以上工作中得到啟發,將文本主題與圖表示序列模型聯合生成短文本關鍵詞。
2 ADGCN模型
2.1 模型概述
模型的目標是對句子進行信息壓縮,輸出短文本關鍵詞信息。如圖1所示,模型主要包括文本嵌入層、圖構建層、注意力層、主題交互層和密集連接層,對應關鍵詞生成的3個步驟:文本嵌入、特征編碼和特征解碼。

圖1 ADGCN模型原理結構Fig.1 Schematic diagram of ADGCN model
文本嵌入部分的輸入是預處理好的社交平臺發文文本。對文本采用命名實體識別,并利用TextRank提取文本中的M關鍵詞,對分好的詞采用glove訓練生成詞嵌入向量。特征編碼部分的目的是將文本嵌入層的輸出進一步編碼成一組隱藏向量,以獲取文本節點關聯信息和關鍵詞隱藏信息。圖構建層對文本節點進行編碼,用于組織文本句子間的關系。圖構建后由N個相同的編碼模塊連接,每個塊包含2個層:注意力層和主題交互層。注意力層對圖加強邊的權重,用于引導節點間的聯系密度,這里采用多頭注意力機制,挖掘隱含的節點關系,生成的是全連接的邊權圖。主題交互層對圖結構進一步編碼,編碼框架采用GCN,初始的輸入是節點向量和節點的鄰接矩陣,每一層包含上一層和初始時的輸入。本文由M個主題交互層組成,對應著M 頭注意力。輸出的隱藏向量由特征解碼部分的密集連接層處理生成關鍵詞。密集連接層對編碼信息進行解碼,在解碼過程中采用注意力機制計算上下文向量對主題交互層的輸出,并用一種復制機制來計算關鍵詞的復制概率。
2.2 圖構建層
圖構建的目的是將短文本組織成圖結構,便于模型理解文本的內部結構和主題之間的聯系。相比較序列標注模型對文本的處理方式,圖結構可以直接獲取節點依賴關系,編碼較廣范圍的語義信息,做到減少噪聲語句對關鍵語句的影響,降低高維度特征的復雜度,緩解非主題數據對關鍵節點的擾動。
如圖2所示,對含有n條句子的短文本S={s1,s2,…,sn}構建圖,節點分為關鍵節點vk、空閑節點vempty和主題節點vtitle。關鍵節點是由關鍵詞K={k1,k2,…,km}和包含關鍵詞的句子組成。空閑節點vempty是由剩余未包含關鍵詞的句子組成。主題節點vtitle是由TextRank計算一個文本主題title,同時融合HashTag向量表征。若節點間包含相同的句子,則添加邊,相同句子的個數作為邊的權重。依據圖構建算法生成圖節點和邊,并將圖轉化為鄰接矩陣,作為下一層的輸入。圖構建方法如算法1所示。

圖2 圖構建過程Fig.2 Graph construction process

?算法1 圖的構建方法。輸入:關鍵詞k={k1,k2,…,km},句子s={s1,s2,…,sn},文本主題title。輸出:關鍵節點{v1,v2,…,vm},空閑節點v empty,主題節點v title,節點vi 和節點vj邊的權重wij。1:對文本主題提取,并對文本分詞。2:做命名實體識別,并提取文本中的m個關鍵詞k={k1,k2,…,km}。3: for s={s1,s2,…,sn}do:4: if句子si包含關鍵詞ki then:5: 將si分配給節點vi 6: else:7: 將si分配給節點v emp ty 8: end for 9: for節點vi和節點vj do:10: wij為vi和vj間包含相同句子的個數

11: end for
文本中詞的初始輸入是其在句子中的位置特征pi∈Rd×d及詞特征xi∈Rd×d表征,如下:

2.3 注意力層
注意力層用于引導節點間的關聯密度。如圖3所示,對圖構建層輸出的鄰接矩陣做多頭注意力來關注不同子空間的信息,生成全連接的注意力矩陣,對應鄰接矩陣的邊權連通圖,矩陣中每個元素對應相應節點之間邊的權重,從而捕捉到領域節點間的關系密度。

圖3 注意力層Fig.3 Attention layer
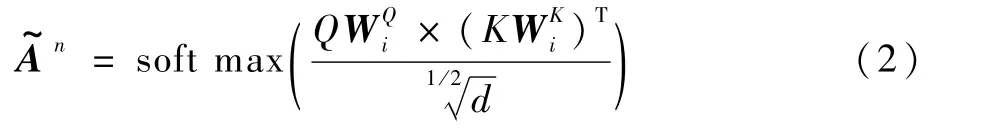
式中:Q和K為模型第l-1層的表征;WQ∈Rd×d和WK∈Rd×d為可學習參數矩陣。
2.4 主題交互層
主題交互層是對圖信息進行編碼,編碼器采用GCN[32]。圖神經網絡既可以對節點內容編碼,又可以利用圖結構中豐富的信息。其核心思想是:通過學習一個映射函數映射圖中的節點vi,vi可以聚合自己的特征與其鄰居特征來生成節點vi新的表示。通過多個GCN層可以挖掘到更深層次的節點信息,節點的最終表征包含了更遠的鄰居節點信息。


隨著GCN網絡層數和迭代次數的增加,節點的隱層表征會趨向于收斂至空間中的同一個位置,即過度平滑問題。為了避免GCN過度平滑的問題,在每一層輸入時考慮之前層的輸出:

2.5 密集連接層
密集連接層完成對文本解碼的工作,參考機器翻譯模型[33]采用循環神經網絡(recurrent neural network,RNN)模型作為解碼器。GCN層的輸出Gout作為密集連接層的初始輸入,以生成一個注釋標記序列y ={y1,y2,…,ym}。考慮短文本主題是一個重要的信息,將圖編碼器處理后的主題隱藏特征作為解碼器RNN的初始輸入t0,RNN每一步的解碼特征ti。在解碼過程中,采用注意力機制αj計算上下文向量ci來關注GCN的輸出:

式中:δ為函數,計算當前解碼器狀態與原文各單詞的相關度。
考慮初始抽取關鍵詞本身的重要性,采用復制機制[34],將預測的詞標記的概率分布與注意力分布相結合,利用解碼器的隱藏狀態ti和上下文信息向量ci動態計算關鍵詞的復制概率pcopy:

式中:U、M、Wcopy和b為可學習的模型參數。
3 實驗與分析
3.1 實驗數據
本文從某個社交平臺上收集數據,由于在不同主題下數據量差別很大,從生活、藝術、時尚、世界、科技、商業、微博、體育、健康、教育、旅行等主題中選擇3個比較流行的主題:生活、教育和健康。對原文本處理成社交平臺發文文本和話題標簽的格式,稱之為標簽數據集(TH)。TH數據集詳情如表1所示,可通過https://github.com/MiniiEcho/keywords-generation.git訪問該數據集,可以用來做提取標簽或是文本分類等任務,這些數據是可以免費獲取的。在數據集中存在一個話題共用多個主題的情況,如#HappyTeachersDay屬于生活也屬于教育。教育和健康2個主題的樣本數相對生活的少一些,健康主題的樣本數不足教育主題的樣本數的一半,但是總樣本數為30 093條,足以支撐模型訓練的。

表1 不同話題中的TH樣本和標簽數量Table 1 Num ber of TH sam p les and tags in different topics
在收集的小型數據集上評估時,體現為:具有較好的可移植性和在大規模數據集中同樣可以取得較好的結果,選擇在一個公開數據集即KP20k[35]上進行測試和評估。該數據集是Meng等[35]從ACM、SicenceDirect和Web of Science圖書館中收集的有關計算機領域的高質量數據,許多模型[35-37]在該數據集上驗證其模型性能的有效性。KP20k數據集總樣本數超過50萬,是TH數據集的18倍,可以作為大規模數據集去驗證模型性能。KP20k詳情如表2所示。

表2 KP20k數據集描述Tab le 2 KP20k dataset descrip tion
3.2 實驗設置
通過在驗證集上的測試發現,從N={1,2,3}中選擇編碼部分的塊數,從M ={1,2,3,4}選擇多頭注意力的頭數,從L={2,3,4,5}中選擇主題交互層的層數。通過對驗證集的初步實驗,發現(N=2,M =2,L=1,d=300)的組合設置在TH數據集上取得了最好的效果,在頂點數相對較小的情況下,降低L數值,會緩解模型過度平滑問題。(N=2,M=3,L=2,d=300)的組合設置在KP20k數據集上取得了最好的效果。該模型是在NVIDIA GeForce GTX 1650下采用CUDA9.0訓練。訓練周期為100,每10個周期用時約270 s。詞典大小為60 000。句子大小為100,生成關鍵詞的長度最大值為4。對于解碼器,采用雙向LSTM,128隱藏節點,2層。dropout率設置為0.1,并采用Adam優化器訓練參數。初始化的學習率為0.01,epoch為10,每epoch一次學習率減少至原來的一半。
3.3 評估度量標準
本文采用3種度量方法評估收集的數據集上生成的關鍵詞的質量,分別為相關性、信息量和連貫性。對所有的度量方法,讓評分者按3種方式打分,分值范圍為0~10。在KP20k數據集上采用精準率P、召回率R和F1值作為評估模型性能的評估指標。
1)相關性。用于評估結果是否與文本主題一致,即關鍵詞是否符合社交平臺發文文本內容,屬于或是不屬于社交平臺發文文本。
2)信息量。用于評估結果包含了多少具體信息。衡量的是輸出結果是否涉及到某個人物或事件的特定方面,或者是對某個人物或事件的概括描述,或者是一般關鍵詞。
3)連貫性。用于評估輸出的詞是否流暢,是否是正確的、有意義的詞。
本文邀請3位評分員去評估不同模型生成的關鍵詞。由于評估過程復雜,選取3個話題的各100條發文的結果進行評估。評分員會得到原發文、發文主題和關鍵詞,這與用戶在線閱讀發文的方式相同。使用Spearman等級相關分數來衡量評分者之間的相關性,p-values都低于1×10-50,這表明評分員之間的評分有較好的相關性。在這些指標中,連貫性的差異更大。這和預期的一致,因為該指標更靈活,不同的人會有不同的評估標準。
3.4 Baseline
本文從無監督和有監督模型進行對比,選取的Baseline是Tf-id f、TextTank、Maui[36]、RNN[35]、CopyRNN[35]、CovRNN[37]。Tf-id f、TextTank屬 于無監督模型,Maui、RNN、CopyRNN、CovRNN是有監督模型。Tf-idf、TextTank是基于統計的方法,其針對候選關鍵詞的次數來作為對文本的重要性,無法體現文本內容包含的語義信息,更無法生成未出現的關鍵短語。Maui、RNN、CopyRNN和CovRNN是生成方法,可以捕捉文本上下文信息。
3.5 實驗結果
表3~表5展示了在生活、教育和健康3個不同主題下的不同Baseline模型與本文模型在不同度量下的結果。從結果中可以看出,本文提出的ADGCN模型在相關性和信息性方面都優于所有的Baseline。

表3 生活主題下Baseline模型和本文模型的3個度量評估比較Tab le 3 Com parison of three m easurem ent evaluation of Baseline m odel and p roposed m odel under life topic
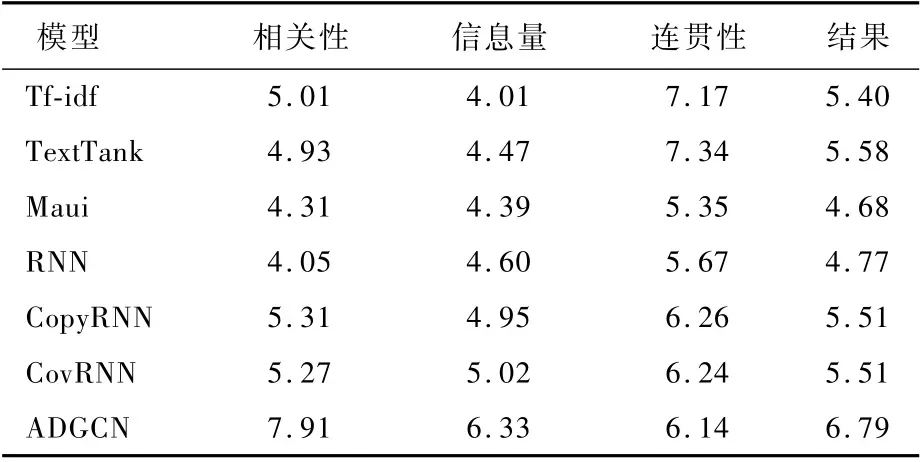
表4 教育主題下Baseline模型和本文模型的3個度量評估比較Table 4 Com parison of three m easurem ent evaluation of Baselinemodel and proposed model under education topic

表5 健康主題下Baseline模型和本文所提模型的3個度量評估比較Table 5 Com parison of three m easurem ent evaluation of Baseline m odel and p roposed m odel under health topic
1)相關性。與所有其他Baseline模型相比,本文模型在相關性方面獲得了較高的分數。這說明本文所提出的基于圖到序列的學習模型可以更有效地獲取和生成與文本主題相關的關鍵詞。在遇到低頻率話題時,如#HappeningNow下的某個句子“The protesters in Rochester NY are‘shutting down restaurants’,tables are broken,peop le running off sc…”。句子與話題的相關性不明顯,這誤導關鍵詞的生成,這種現象嚴重影響了關鍵詞相關性的分值。在Baseline模型中Tf-idf取得了較高的結果,這說明對與話題相關性不明顯的句子提取關鍵詞時,在樣本數量足夠的情況下,基于統計的方法可以提取出與文本主題相關的詞。而在樣本數量較少的情況下,如表5所示,統計的方法便不如生成模型的結果了。生成模型可以輸出文本中不存在的詞組,來更好地表達主題。
2)信息量。從結果中可以看出,隨著樣本數的減少,關鍵詞包含的信息量隨之增大。與所有其他Baseline模型相比,本文模型在信息量方面獲得了更高的分數。信息量和相關性是有一定關系的,相關性較高的模型,其信息量越豐富。但是當樣本較少時也會出現不穩定的情況,像在健康主題下,RNN模型信息量與相關性沒有呈現正比的關系。原因是:在健康主題下,樣本中低頻率話題較多,文本主題和話題不匹配會對模型造成一定的擾動。從結果中可以看出,基于圖的模型可以利用文本結構,捕獲文本情節,有穩定的健壯性。
3)連貫性。基于統計的方法是從原文中直接復制詞,連貫性只受到分詞的影響。因此,結果中也顯示基于統計的模型的連貫性分值要遠高于生成模型。在檢查了部分生成的關鍵詞后,總結了以下幾條影響流暢度的原因:①機器對人名不能較準確地識別,如趙立、堅定,而趙立堅是一個人名。②存在連續生成相同詞的問題,嚴重影響了連貫性分值,本文猜測這和復制機制有關,這也是下一步待解決的問題。③模型生成的關鍵詞是有悖知識邏輯的,如Railway Speak Up(鐵路大聲的說)。這一問題也是比較難解決的問題之一。
表6展示了Baseline模型與本文模型在KP20k數據集上的P、R和F1值的對比結果。發現各模型的召回率都比較低,這表明模型將很多正樣本賦值了錯誤的標簽,這和數據集樣本的質量有關。另外,數據集中主題不明確的句子會對模型造成較大的擾動。KP20k數據集中的標簽大部分是文本中不存在的,因此,這對統計模型直接提取造成了重創。對生成模型來說,所生成的標簽存在重復、次序混亂等現象而導致錯誤結果。但是本文模型ADGCN仍取得了較好的結果。

表6 KP20k數據集上Baseline模型和本文模型的精確率、召回率和F1 值評估比較Tab le 6 Com parison of p recision,recall and F1 evaluation of Baselinem odel and proposed m odel on KP20k dataset
3.6 實驗分析
3.6.1 消融分析
對模型的各模塊進行消融研究,評估結果如表7所示。從結果中發現,編碼模塊的注意力層和主題交互層對模型的貢獻最大。去除注意力層,模型F1值降低至0.413,減少了0.04。這說明注意力層有效發揮了捕捉領域節點間關系密度的作用。去除主題交互層,模型F1值降低至0.406,減少了0.047。這說明編碼遠距離的鄰居節點信息可以提升模型準確率。若兩者都去除,F1值則會降低0.06,這對模型性能的影響是最大的。而圖構建層和密集連接層對模型的影響相對較小。可見,注意力與圖神經網絡相結合有助于ADGCN學習短文本內的信息聚合,以生成更好的節點信息特征。
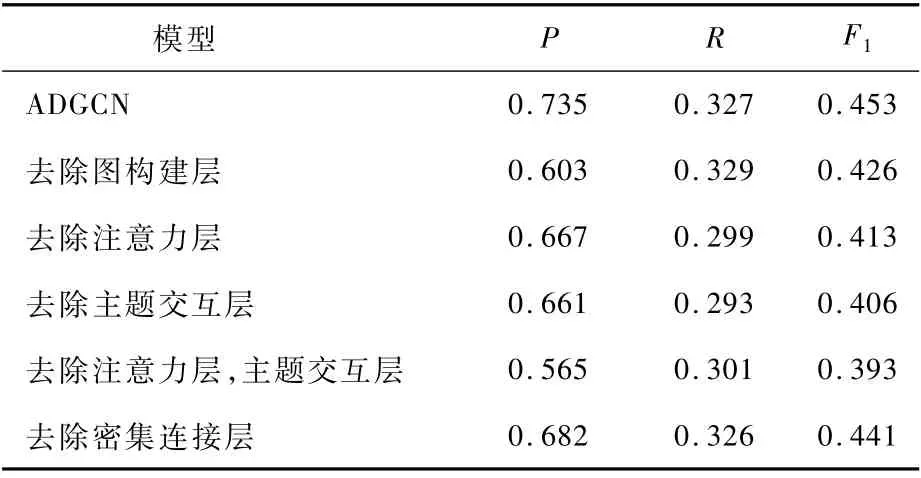
表7 ADGCN模型的消融Tab le 7 Ab lation of ADGCN m odel
3.6.2 數據集規模對模型性能的影響
對KP20k數據集進行統一劃分,設置5種規模訓練數據:20%、40%、60%、80%和100%的訓練數據。對ADGCN和Baseline模型在不同訓練設置上進行評估。如圖4所示,在數據規模不大時,CovRNN取得了較好的效果,這說明CovRNN可以從樣本較少的數據中捕獲有利的信息,但是與其他生成模型的差距并不明顯。隨著數據集規模的擴增,發現生成模型與統計模型的性能差距越明顯,在數據集規模達到40%時,生成模型遠超于統計模型。在數據集規模達到60%時,本文所提出的ADGCN的F1值達到了其他Baseline模型的最優值。這說明ADGCN可以更有效地利用訓練數據集,在數據規模一定的情況下,基于圖到序列的模型可以有效學習短文本中主題信息。
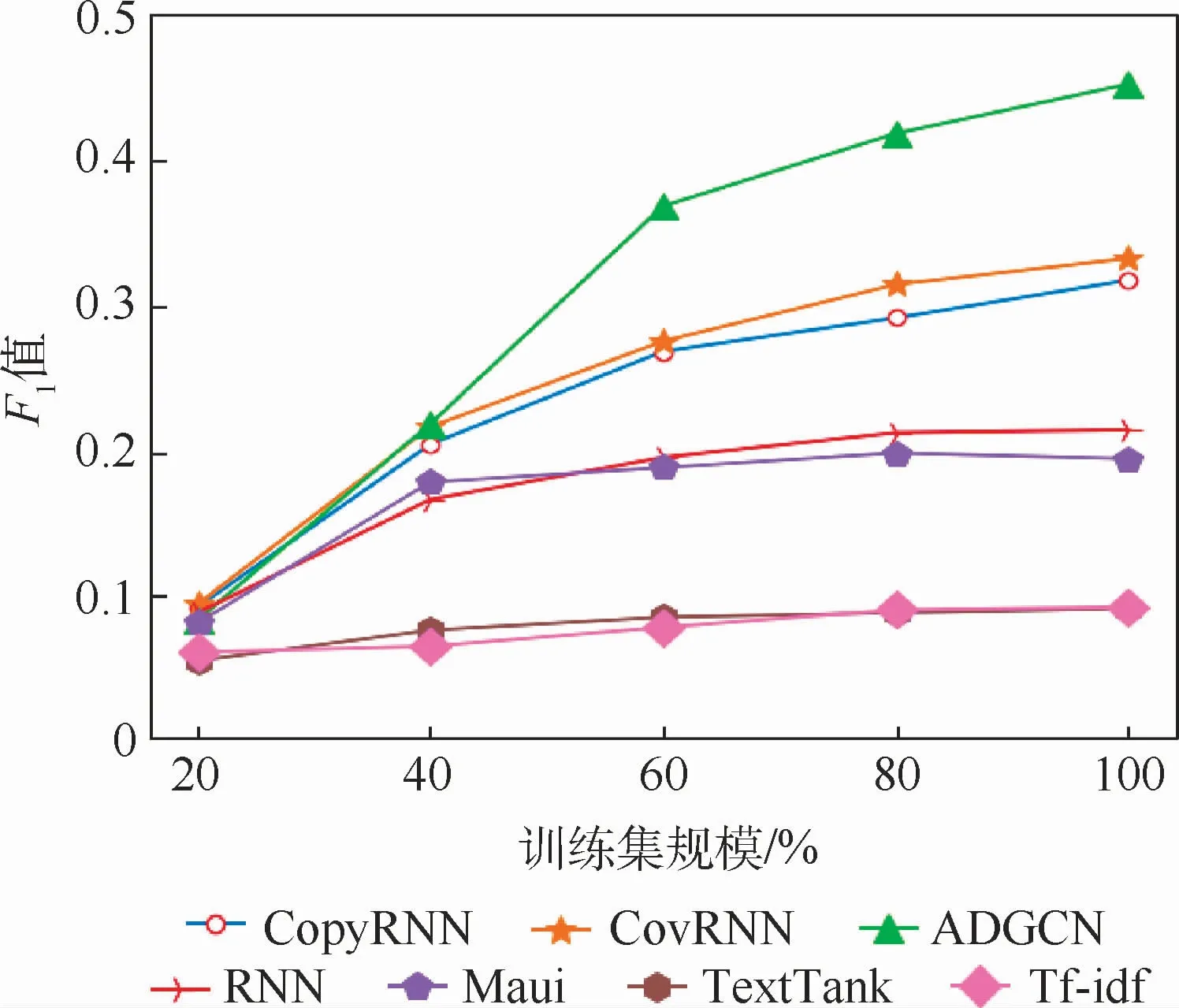
圖4 不同數據規模下各模型的F1 值比較Fig.4 Comparison of F1 values of differentmodels under different data scales
3.6.3 話題種類對模型性能的影響
評估TH數據集中話題種類對模型性能的影響。設置包含不同話題種類個數1、2、3、4和≥5的句子,對ADGCN和與ADGCN較相近的Copy-RNN、CovRNN模型在不同數量的話題句子上進行關鍵詞質量評估,分別從關鍵詞的相關性、信息量、連貫性3個方面進行統計評估。統計包含不同個數的話題標簽的發文比例,如圖5所示。話題種類個數為1的只占據了60%,而話題種類個數在5之上的占據了5%,這些數據增加了文本主題的噪聲,對短文本主題表征會有一定的影響。如圖6所示,發現各模型在話題種類個數≤2時生成的關鍵詞質量是最好的。而隨著話題種類個數的增加都有減少的趨勢,這說明話題種類的數量越多對模型的擾動性越大。
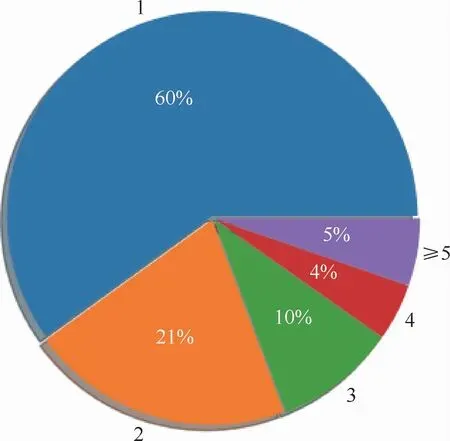
圖5 話題標簽個數比例Fig.5 Ratio of the number of topic tag

圖6 不同話題標簽個數下度量值的評估Fig.6 Evaluation ofmeasurement value under different numbers of topic tag
在對相關性評估分析時發現,ADGCN的相關性分值雖然也會收到數據擾動的影響,但是相對CovRNN和CopyRNN兩個模型較緩慢。CovRNN和CopyRNN在話題標簽個數大于2時急速下降,在[2~4]區間存在不明顯的差距。而在對信息量評估時,2個模型的差距明顯化,這說明Cov-RNN相對CopyRNN是穩定的。當話題種類個數為1或是超過5時,無論是相關性還是信息量CopyRNN的表現要比CovRNN模型弱一些,猜測可能和數據不平衡有關。而ADGCN可以有效緩解數據不平衡的影響,因此表現是最優的。
在對連貫性評估分析時發現,CovRNN 和CopyRNN在話題種類個數為1時的表現比ADGCN好,但是當話題標簽個數增加時,2個模型下降明顯,而ADGCN下降緩慢,并在數值較大時有緩升的趨勢。這說明在文本組織結構明顯的情況下,序列標注模型對文本信息的組織可能要優于圖結構模型。對結構化不明顯的文本,圖結構模型表現出了優勢。
造成數據擾動的原因可能有以下2點:①因發文有字符字數限制,話題種類數量越多,文本的組織結構會越差。這對序列標注模型RNN的影響是較大的。相比較,利用圖表示模型的結果會好一點。②隨著話題種類的增加,主題節點表征的信息特征越不明顯,這大大降低了文本主題的表達,模型信息獲取的性能會隨之下降。而本文所提出的ADGCN在不同設置上的性能完全優于其他生成模型。
4 結束語
本文提出了一種新的圖到序列的關鍵詞生成,一是通過圖構建層來表征文本內容與主題標簽間的圖鏈接;二是結合注意力機制來學習節點特征空間的相關性,關注不同子空間的信息,引導節點間的關聯密度。該方法有效緩解了短文本主題依賴和文本組織結構差對模型造成擾動的影響。ADGCN模型不僅具有良好的相關性、信息量及連貫性,在大規模數據集KP20k上也取得了較好的性能。
接下來會對模型的不足進行改進和優化,如復制機制的影響、知識邏輯的推理等。緩解多話題標簽對文本主題的影響也是未來待解決的問題之一。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
甘肅教育(2020年8期)2020-06-11 06:10:02
數學物理學報(2020年2期)2020-06-02 11:29:24
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
光學精密工程(2016年6期)2016-11-07 09:07:19
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
核科學與工程(2015年4期)2015-09-26 11:59:03
