基于集成策略的接觸網區域鳥窩智能識別方法
2022-03-03 07:47:56劉鵬
電氣化鐵道 2022年1期
劉 鵬
0 引言
接觸網是沿鐵路線路架設的向電力機車供電的輸電線路,主要由基礎與支柱、支持裝置、接觸懸掛裝置、定位裝置等部分組成[1]。因為接觸網的結構特點,每年3~5月,鳥類經常在接觸網隔離開關底座、硬橫梁、鋼柱等處修筑鳥巢,而鳥類筑巢的樹枝、金屬線等材料極易造成線路短路、電氣控制部件損壞、跳閘、機械補償裝置失靈等安全隱患,嚴重影響了行車安全[2]。目前,對接觸網區域鳥窩的檢測、識別主要依靠人工分析視頻監控圖像并判斷和標記,這種由人工進行的圖像甄別工作量大、效率低,而且可靠性和準確率也很難保證。 為了解決這一問題,文獻[3~6]提出通過分析接觸網沿線的車載視頻,再根據一定的先驗知識建立特征模型來完成接觸網區域巡檢中鳥窩的非接觸式識別檢測。近年來,基于深度卷積網絡的人工智能技術能夠在大量視頻圖像中快速確定含有特 定目標的圖像,然后對該圖像中目標區域進行定位、識別。文獻[7]利用SSD網絡及遷移學習技術完成對鳥窩的識別。文獻[8]運用Faster R-CNN模型對鳥窩進行自動識別。文獻[9]首先基于LSD直線段檢測算法獲取鳥巢可能出現的區域,然后運用YOLO v3網絡對可能區域進行鳥窩自動識別。雖然上述方法針對接觸網區域中的鳥窩識別取得了一定的效果,但針對成像條件復雜情況下的接觸網區域鳥窩識別的效果有限,難以同時兼顧正常成像、成像質量不佳、有霧天氣、圖像部分曝光、部分鳥窩被器件遮擋等不同成像狀態下的接觸網區域鳥窩智能識別任務。為了解決這一問題,本文提出一種基于YOLO-v5檢測模型與Inception v4識別模型多模型融合的接觸網區域鳥窩智能識別方法。
1 接觸網區域鳥窩樣本圖像集構建
構建接觸網區域鳥窩樣本圖像集是通過深度學習技術實現鳥窩智能識別的基礎。由于接觸網線路巡檢圖像中存在正常成像、成像質量不佳、有霧天氣、部分曝光、鳥窩被部分遮擋等多種不同成像情況,因此,在收集樣本構建接觸網區域鳥窩樣本圖像集時必須考慮上述因素。選取接觸網懸掛狀態監測系統不同場景下的鳥窩拍攝圖像構建鳥窩樣本圖像集。樣本集包含10000幅接觸網巡檢圖像,其中,包含鳥窩的圖像7000幅,不包含鳥窩的圖像3000幅,鳥窩樣本圖像集的像素均為2448×2050,其成像狀況分布如表1所示。

表1 鳥窩樣本圖像統計
對樣本集中的圖像進行標注時,首先由專業巡檢人員對接觸網區域中是否存在鳥窩進行判斷。若存在鳥窩,則利用標注工具在鳥窩出現處繪制矩形標記框,并標記nest類型。部分樣本圖像標注示例如圖1所示,包含了正常成像、有霧天氣、部分遮擋、部分曝光、成像不清晰等不同成像狀況。


圖1 典型樣本圖像及其標注示例
2 接觸網區域鳥窩智能識別方法
2.1 識別流程
本文所述接觸網區域鳥窩智能檢測識別流程如圖2所示。首先將前端采集的接觸網圖像經過預處理,縮放至長寬均為640像素,再分別由YOLO- v5的深層、淺層模型進行鳥窩初步檢測;然后將兩個模型檢測結果通過IOU指標進行融合;最后將融合結果經Inception v4模型進行精確識別,從而完成接觸網區域鳥窩的智能識別。

圖2 接觸網區域鳥窩智能識別流程
2.2 YOLO-v5深層模型與淺層模型
YOLO-v5[10]模型融合了CSP Darknet53[11]、PANET(路徑聚合網絡)[12]和SPP(空間金字塔池化)[13]等結構,不僅在對象檢測方面表現出色,而且YOLO-v5s的模型推理速度更是達到了140 F/s。目前,該系列有4個模型(YOLO-v5s、YOLO-v5m、YOLO-v51、YOLO-v5x),YOLO-v5s模型網絡在YOLO-v5系列中深度最小、特征圖寬度最小。針對真實數據,考慮到鳥窩的多樣性,選擇了網絡最小、速度最快的YOLO-v5s模型作為鳥窩初步檢測的淺層模型,模型結構如圖3所示,其中有4個由紅色框標記的結構區域,從左到右分別是Input、Backbone、Neck、Prediction區域。
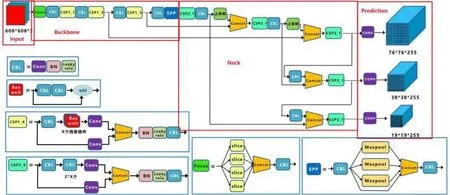
圖3 YOLO-v5s模型架構
模型輸入端包含Mosaic數據增強、自適應錨框計算兩部分。前者通過隨機縮放、裁剪、排布對圖像進行拼接,增加樣本庫中小目標樣本,提升檢測性能,自適應錨框計算。針對不同數據集,模型將設定一個初始長寬的錨框,在網絡訓練中,網絡在初始錨框的基礎上輸出預測框,進而與真實框Groundtruth進行比對,計算兩者差距,再反向更新,自適應計算不同訓練集中的最佳錨框值。Backbone包含Focus結構和CSP結構,Focus結構提供切片操作,CSP結構將梯度變化完整地集成到特征圖中,減少模型參數量和Flops數值,既保證推理速度、準確率,又減小了模型尺寸。Neck用于生成特征金字塔,增強了模型對于不同縮放尺度對象的檢測。Prediction用于最終檢測,在特征圖上應用錨定框,并生成帶有類概率、對象得分和包圍框的最終輸出向量。
深層模型選擇YOLO-v5l模型,其與YOLO- v5s最大的不同在于網絡結構中CSP1和CSP2 block深度的不同。
2.3 檢測模型集成策略
為提升接觸網區域鳥窩的檢出率,使兩個檢測模型實現檢測結果互補,本文采用IOU將兩種模型檢測的結果進行融合,IOU參數的計算式為

式中:Boxs表示淺層模型的檢測框,Boxl表示深層模型的檢測框。當IOU大于設定閾值(本文取0.5)時,將融合兩檢測框后再輸出,否則將兩個獨立檢測框均作為輸出。
2.4 融合結果精確識別
為得到更準確的識別結果,將融合后檢測框尺寸統一縮放為長、寬均為128像素的圖像塊(超過128則進行縮小,不足128則用灰度值為0的像素補齊),然后利用Inception v4模型[14]進行精確識別。
Inception v4模型架構如圖4所示。其中,Stem部分運用多次卷積和2次池化來防止瓶頸問題,之后共使用3種14個Inception模塊,3種Inception模塊間的Reduction模塊起到池化作用,同時使用了Inception v4模塊的并行結構來防止瓶頸問題的發生。

圖4 Inception v4模型架構
3 實驗及分析
3.1 實驗設置
采用本文表1所示樣本圖像數據集進行了相關實驗,并將數據樣本圖像統一縮放到640×640。
3.2 模型訓練
分別利用本文第1節構建的樣本圖像數據集進行YOLO-v5s和YOLO-v5l模型訓練與測試。首先將數據樣本按8∶2的比例隨機分成訓練集、測試集,并對訓練集進行水平鏡像。模型訓練時優化器選擇Adam,batch size設置為64,訓練輪數epochs設置為200,學習率設置為0.001。兩個檢測網絡均載入COCO數據集的預訓練權重,并保留在訓練集上獲得的最優模型。Inception v4模型[15]載入ImageNet數據集上的預訓練權重,然后進行鳥窩、非鳥窩二分類訓練,訓練集、測試集樣本均來自檢測模型融合結果中的真實鳥窩、非鳥窩檢測框,并按照8∶2比例劃分訓練集、測試集。對訓練集圖像進行水平鏡像,訓練時batch size設為32,訓練輪數epochs設置為100,學習率設為0.001。
3.3 實驗結果及分析
該實驗流程包括YOLO-v5s(淺層)網絡檢測、YOLO-v5l(深層)網絡檢測、深層與淺層網絡檢測結果融合、檢測結果融合后再通過Inception v4模型精確識別。實驗測試結果如表2所示,其中,準確率accuracy、召回率recall的定義分別為

表2 接觸網區域鳥窩智能識別性能對比
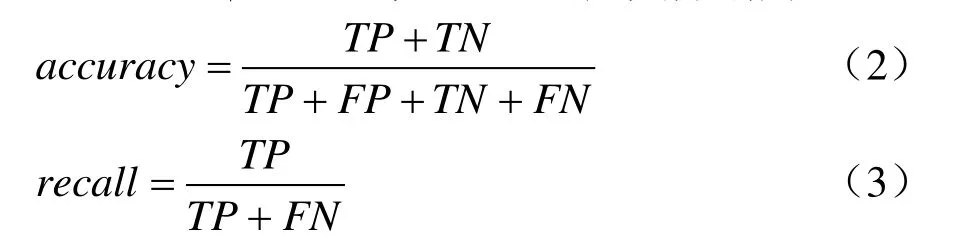
式中:TP為鳥窩圖像正確檢測的數量,TN為正常圖像中正確檢測的數量,FN為鳥窩圖像檢測錯誤的數量,FP為正常圖像被檢測錯誤的數量。
由表2可以發現,不同識別流程的召回率recall、準確率accuracy差別較大。其中,深層網絡(YOLO-v5l)針對鳥窩識別的召回率為94.57%優于淺層網絡(YOLO-v5s),但深層網絡(YOLO-v5l)的誤報FP較多,導致其準確率低于淺層網絡(YOLO-v5s)。進行模型融合(淺層&深層)后,召回率上升到98.71%,但隨之而來的誤報FP也大幅上升到364,導致該流程的準確率accuracy下降到79.15%。模型融合+Inception v4則表現出了最佳檢測性能,針對鳥窩檢測的召回率recall為98.71%,準確率為98.36%,均獲取了最佳性能。根據上述分析可知,將深層、淺層檢測模型的融合結果進一步由Inception v4模型進行精確識別,可以在保證較高召回率的情況下,大幅降低誤報(FP取值由364降低到23),從而大幅提升接觸網區域鳥窩智能識別方法的性能,能夠同時獲得最佳的召回率、準確率。表2所示最優檢測流程(將深層、淺層檢測模型檢測結果融合后再利用Inception v4進行精確識別)的部分典型識別結果如圖5所示。

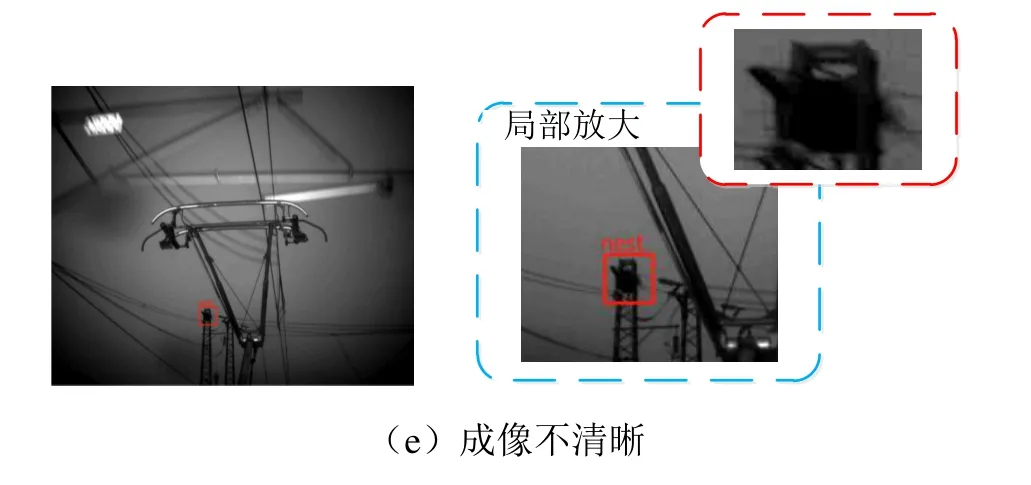
圖5 接觸網區域鳥窩智能識別結果的典型示例
4 結論
針對接觸網區域中鳥窩的智能識別問題,本文提出了將YOLO v5s淺層網絡與YOLO v5l深層網絡的檢測結果進行融合來實現接觸網區域鳥窩初步檢測,再使用Inception v4模型對初步檢測結果進行精確識別的方法。同時,為了滿足深度學習技術對樣本圖像數據量的要求,構建了接觸網區域鳥窩樣本圖像數據集,并由專業巡檢人員對鳥窩進行判讀、標注。實驗表明,所述方法能夠有效實現正常成像、有霧天氣、部分遮擋、部分曝光、成像不清晰等各種成像狀態下的接觸網區域鳥窩精確檢測、識別任務,對進一步研發接觸網區域鳥窩智能識別系統具有重要意義。
猜你喜歡
今日農業(2021年19期)2022-01-12 06:16:36
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
現代出版(2020年3期)2020-06-20 07:10:34
海峽科技與產業(2016年3期)2016-05-17 04:32:12
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
