流數據聚類方法
2022-03-02 06:15:14張寶杰陳斯羽
現代計算機 2022年23期
張寶杰,余 濤,王 玉,陳斯羽
(西安石油大學計算機學院,西安 710065)
0 引言
物聯網(IoT)技術,智能手機和社交媒體服務的廣泛使用產生了大量的高速數據流,比如,實時監控系統產生的數據,相機的圖像序列(視頻)數據,或社交媒體流的文本輸入,等等[1]。在面對以上應用場景時,如何快速對這些數據流進行分析和處理成為首要任務。聚類通常被用于對數據進行快速探索性數據分析。然而傳統的聚類方法在處理流數據時會面臨兩個問題:①提取有效信息效率低;②要占用大量設備內存。如何使用聚類方法從流數據中提取有用的信息成為研究熱點。
流數據聚類方法解決了傳統的聚類方法在處理流數據上出現的問題。常見流數據聚類的具體實現過程如下:
(1)面對流數據M={m1,m2,…,mn},使用窗口模型對數據進行分割,獲得K組數據塊;
(2)對第一組數據塊使用聚類方法進行聚類,獲取聚類信息;
(3)提取當前的聚類信息;
(4)結合(3)中獲取的聚類信息以及第i(1<i<K)塊數據,重新進行聚類,獲得聚類結果;
(5)重復(3)、(4)步驟,直到i=K,輸出聚類結果。
本文首先介紹流數據聚類中的基本概念,其次對流數據聚類算法進行分類,依據分類分別介紹了當前存在的流數據聚類算法,在第三節主要介紹流數據聚類實驗中常用的應用及衡量標準,最后對流數據聚類進行總結和展望。
1 基本概念
1.1 聚類
聚類是一種典型的無監督學習方式,能夠將具有相似性的數據劃分為一組。通常被用于進行快速探索性數據分析。假設有N個對象的集合M={m1,m2,…,mn},那么將這N個對象依據某種特征劃分為k∈{2,3,…,N-1}個子集,其中每個m由一個p維特征向量定義,xi∈Rp在X={x1,x2,…,xn}∈Rp集合中。這樣的過程被稱為聚類。
1.2 窗口模型
流數據在理論上是一組大量、連續沒有邊界的數據序列[2]。當前流數據聚類檢測主要面臨兩個問題:①存儲挑戰。由于數據點不斷到達,序列理論上是無窮無盡的,因此從一開始就將整個流存儲在內存中是不可行的。②效率問題。在實際應用中需要立刻對當前的數據進行分析并得出聚類結果[3]。研究表明,在流數據中使用窗口模型將整個數據切割,只處理最新到達的數據對象比處理全部數據更有效,而且該方法對內存需求量少,能夠加快分析效率。當前有四種主要的窗口模型(如圖1所示),分別是阻尼窗口模型(damped window model)、地標窗口模型(landmark window model)、滑動窗口模型(sliding window model)和傾斜窗口模型(tilted window model)。
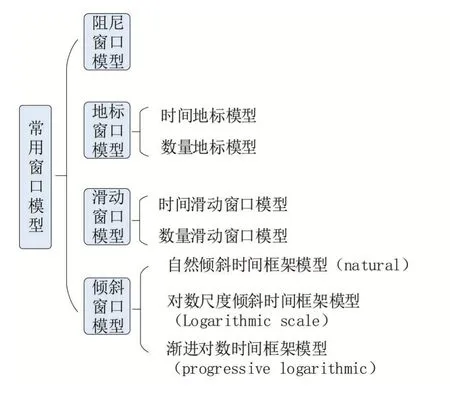
圖1 常用流數據窗口模型
阻尼窗口模型:該模型為每一個對象分配權重,通過設置衰減函數或衰減因子,使最新到達的對象獲得盡可能大的權重,隨著時間變化,該權重會逐漸下降。地標窗口模型:該模型主要通過在流數據中設置聚類的起始點,從起始點開始進行聚類。滑動窗口模型:滑動窗口模型主要通過設置一個固定長度的窗口m,從t1時間開始,只有最近的m個數據對象被拿來進行聚類。傾斜窗口模型:該模型能夠在整個窗口期保存主要的信息[4-6]。
2 方法概述
依據傳統(批處理)聚類算法的分類對流數據聚類進行分類,主要可以分為五個類別:層次聚類、分區聚類、密度聚類、網格聚類和模型聚類[7]。依據流數據方法實現可主要分為三大類:數據匯總聚類[8-10]、在線(實時)聚類、時間序列聚類[11-12]。其分類結果如圖2所示。在本文中,主要依據傳統分類方法對當前提出的流數據方法進行介紹。

圖2 數據流聚類算法的分類
2.1 基于層次的流數據聚類方法
流數據層次聚類方法核心和層次聚類方法類似,主要基于二叉樹的數據結構。基于層次的流數據聚類方法的優點是不需要提前預估計數據中存在的簇,可以根據自己的需要直接切割從而獲得聚類結果,同時基于層次聚類能夠輸出當前流數據塊的樹狀結構圖。然而基于層次的流數據聚類方法時間復雜度比較高,此外還容易受到異常值的影響。
ODAC方法是Rodrigues等[12]提出的時間流數據的層次聚類方法,該方法使用樹結構來更新流數據中簇的變化。通過對聚類的質量進行測量,將同一簇對象之間的最大不相似度定義為簇的直徑。但是由于層次聚類自身在添加或刪除葉子節點時需要對樹結構進行調整,所以會導致時間復雜度變高。Udommanetanakit等[13]在2007年提出E-Stream方法,該方法用一種新的聚類表示方法和距離函數來改進流聚類算法,它是基于進化的流聚類方法,支持出現、消失、自進化、合并和分裂等不同類型的聚類結構演化。對于一組數據M={m1,m2,…,mn},最初時將每次輸入的一個mi看作是一個對象,當第min個對象到達時,如果A={mi1,mi2,…}的密度足夠大,那么A就是一個簇。因此,該方法根據相似度評分將新到達的對象分配給一個簇,否則可以將數據歸類為孤立的數據。Meesuksabai等[14]在2011年提出HUE-Stream方法,該方法解決了E-Stream方法在異構數據上出現的不確定性問題,并且能夠針對不同類型的聚類結構進行演化。
2.2 基于分區的流數據聚類方法
在批處理聚類中,常見的分區聚類方法典型代表就是K-means方法。假設有限數據集M={m1,m2,…,mn}中有K個簇,設置初始的聚類簇中心K={K1,K2,…,KK},DiK是每個對象到Ki的距離,i={1,2,…,K};據此將每個對象分配給具有min{DiK}的簇,找出該組數據劃分為MK1={mi1,mi2,…,mib},…,MKK={mic,mic+1,…,mn},更新簇中心。基于分區的流數據聚類方法大部分是在基于分區的批處理方法上面進行擴展,它的優點是易于實現,易于理解,但是基于分區的流數據聚類方法需要預估計當前數據對象中存在簇的個數,如果預估計的簇少于實際存在的簇的個數,這將會導致出現無效聚類。
基于分區的相關流數據聚類算法有SWClustering[15],Streamkm++[16],Adaptive Stream Kmeans[17],FEAC-Stream[18]等。SWClustering方法通過使用滑動窗口和聚類特征指數直方圖(exponential histogram of cluster feature,EHCF)來維護流數據中簇的特性,因此該方法能夠獲得最近窗口中簇的分布及其演化過程,能夠根據選擇的樣本集合計算出聚類結果[19]。Streamkm++是K-means++[20]算法對數據流聚類的擴展,是K-means算法的擴展,該方法能夠在流數據上取得很好的聚類結果。Puschmann等[17]提出Adaptive Stream K-means方法,該方法是一種基于在線分區的流數據聚類算法,Puschmann指出該方法克服了基于分區的流聚類方法需要預先確定K以及難適應輸入數據中概念漂移的問題。該方法的一個局限性是需要對當前數據中存在的簇進行估計,預估計的簇數量會直接影響到聚類結果。de Andrade Silva等[18]提出基于kmeans算法的FEAC-Stream聚類方法,該方法通過使用進化方法來自動估計K值。FEACStream是完全在線的方法,使用Page-Hinkley(PH)[21]評價當前算法聚類結果的質量,通過Page-Hinkley(PH)評價方法能夠協助FEACStream聚類方法自行調整到最優策略,能夠直接維護最終的聚類結果。Clustream方法提出了在線-離線框架,使用傾斜窗口模型,在線通過微簇結構來獲取并維護流數據的樣本信息,在離線階段,基于在線階段總結的樣本信息產生聚類結果[22]。Clustream方法能夠應用于各種復雜的情況并產生較好的聚類結果。然而該方法并沒有區分出過期數據與近期數據的差異性權重,因此在高維數據上聚類性能會變差。
2.3 基于密度的流數據聚類方法
基于密度的流數據聚類方法具有任意形狀簇的噪聲魯棒性,它通過計算數據之間的密度,從密度低的區域進行切割,將密度高的區域劃分為一個簇[23]。然而該方法在面對具有多種密度的簇的情況下,大部分基于密度的流數據聚類方法難以獲得滿意的聚類結果。
Cao等[10]提出DenStream算法,該方法采用了在線-離線原理。在線階段主要通過使用一種“密集”簇(core-micro-cluster)的方法對當前流數據中的簇進行歸納,并維護和區分潛在的簇和異常點。在離線階段通過利用在線階段獲得的結論進行聚類,從而獲得聚類結果。MuDi-Stream[23]方法解決了當流數據中簇具有多密度情況時,基于密度的流數據聚類表現效果急劇下降的問題。使用基于在線-離線框架的流數據聚類方法,在線階段通過采用基于網格的方法,獲得以核心小集群的形式保存的多密度流數據的匯總樣本,在離線階段通過DBSCAN的擴展方法計算聚類結果。然而該方法沒有解決歷史數據樣本與當前數據之間關系的問題。Chenaghlou等[3]提出了一種考慮觀測時間接近性和空間接近性,以實時識別異常的算法(online clustering anomaly detection,OnCAD)。該方法不能直觀展示當前數據中的簇結構,因此在亂序數據集上表現較差。Fahy等[24]提出了一種基于生物的在線聚類動態數據流的方法——蟻群流聚類(ACSC)算法,該方法極大提高了算法的聚類效率。Tareq等[25]提出了基于自適應切比切夫距離(CEC)的進化數據流聚類,該方法是一種基于密度的在線聚類算法,它解決了聚類質量受距離函數(distance)影響這一問題,當使用距離函數時,會導致聚類結果降低。DFPSclustering(the dynamic FPS-clustering algorithm)該算法引入基于密度的目標函數,采用適應度比例共享策略對聚類中心進行更有效的搜索,該方法能夠應用于社交媒體分析、股票市場預測和網絡入侵檢測等領域,其缺點是計算成本略高[26]。
2.4 基于網格的流數據聚類
基于網格的流數據聚類方法基于網格聚類模型。首先使用網格對數據空間進行分割,將數據對象映射到網格單元[27]。獲取網格單元之間的密度,從密度低的區域進行切割,獲得一組密度大于周圍網格單元的連接網格單元,這樣獲得的簇被稱為網格簇。單元格的密度被定義為當前單元格中點的密度,在流數據中單元格能夠保存流數據的歷史信息,同時在流數據聚類中需要在線對單元格信息進行更新。然而在網格單元上進行聚類需要耗費大量的時間。
潘登等[28]提出一種能夠并行處理數據和便于增量計算的智能聚類方法,該方法主要結合徑向基函數(radial basis function,RBF)和網格劃分,實現了流數據聚類。張東月等[29]依據在線-離線模式提出了一種基于網格耦合的流數據聚類方法。在線階段主要實現對數據映射,以及對網格進行更新、添加和刪除的操作。在離線階段進行聚類操作獲得流數據的聚類結果。
2.5 基于模型的流數據聚類方法
基于模型的流數據聚類方法主要是通過找到最適合輸入數據的數據分布模型,從而利用該模型進行聚類來獲得聚類結果,該方法具有噪聲穩定性。其中SWEM方法就是一種基于模型的流數據聚類方法[30-31]。
此外,AutoCloud聚類方法是一種基于典型和偏心數據分析的在線數據流聚類進化方法[32],它基于最近引入的典型性和偏心數據分析的概念,主要用于異常檢測任務。evoStream[33]算法能夠利用流中的空閑時間來增量地提高聚類結果。
3 評價指標及應用
3.1 評價指標
當前流數據聚類方法大多分為在線-離線方案,通過離線實現聚類并輸出聚類結果。因此在大部分論文中,依舊采用和批處理聚類一樣的評價指標。在批處理聚類方法上,其評價指標可以分為兩類:內部評價指標和外部評價指標。內部指標是無監督的,主要是通過計算對象與簇中心的距離來衡量聚類結果的好壞。其中常用的內部指標有戴維森堡丁指數(Daviesbouldin index,DBI)、鄧恩指數(Dunn validity index,DVI)、輪廓系數(silhouette coefficient)[34]。常用的外部指標有標準化互信息(normalized mutual information,NMI)、調整互信息(adjusted mutual information,AMI)、局部精度(partation accuracy,PA)等。
調整互信息的計算如下:
其中,E{M I(U,V)}為互信息M I(U,V)的期望,其計算方法如下:
其中k=(ai+bj-N)+為max(1,ai+bj-N);ai和bj分別為列聯表M的第i行和第j列和,具體為:
3.2 實際應用
表1舉例了四種流數據聚類方法及其應用。
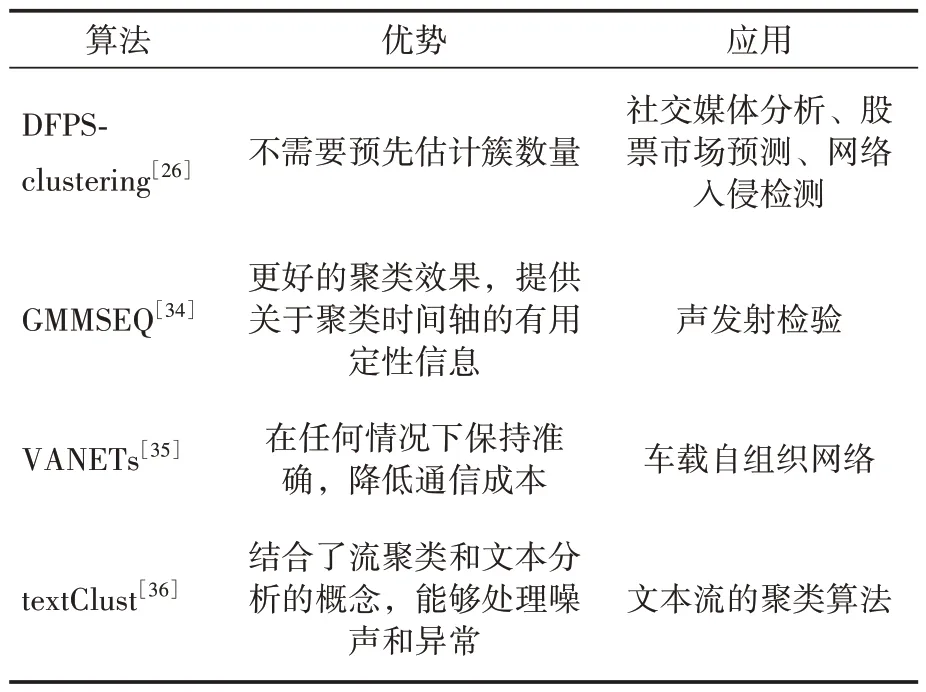
表1 流數據方法及應用
Peixoto等[35]提出一個應用于車載自組織網絡(vehicular ad-hoc networks,VANETs)的流數據聚類框架,該框架定義了兩種減少交通數據流的方法:其中之一為普通的交通擁塞檢測方法——基線方法,并通過實驗表明該方法能夠有效降低通信成本,為VANETs的發展帶來顯著成果。textClust[36]實現了文本流的聚類算法,該方法通過使用兩階段聚類方法來識別和跟蹤文本流中的主題。GMMSEQ[34]是一種能夠用于管理附加在聲發射信號上的連續時間戳的聚類算法。在聚類過程中利用時間戳,使人們能夠獲得對聲發射數據流的信息。Hassan等[37]對進化聚類算法(ECA*)進行改進,稱為iECA*。該方法能夠用于COVID-19和醫療疾病數據集的實際應用。
4 結語
本文主要對流數據聚類方法進行分類和總結,從層次聚類、分區聚類、密度聚類、網格聚類和模型聚類五個方面分別介紹了幾種流數據聚類方法,并對這五個大類的流數據聚類方法普遍存在的優缺點進行分析,介紹了近幾年提出的流數據聚類方法;對當前常用的流數據聚類指標做了簡要的介紹,并介紹了一些實際應用場景。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
兒童故事畫報(2019年5期)2019-05-26 14:26:14
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
核科學與工程(2015年4期)2015-09-26 11:59:03
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
