基于改進的ResNet34網絡模型的蘋果葉病害識別
2022-02-24 02:22:36喬印虎
安徽工程大學學報 2022年6期
彭 勇,喬印虎,姚 杰
(1.安徽工程大學 機械工程學院,安徽 蕪湖 241000;2.安徽科技學院 機械工程學院,安徽 鳳陽 233100)
蘋果富含多種營養成分,包括多種維生素和人體必需微量元素,還含有多種植物活性成分,如植物甾醇、β-胡蘿卜素和酚類物質[1]。為了加強蘋果產業的競爭力,降低病蟲害對蘋果產業造成的損失,使其能夠生產出品質更加優良的蘋果,目前,機器視覺技術的應用已滲透到農業生產的各個領域,對其的研究也取得了很大進展[2]。機器視覺技術是運用光學設備獲取真實圖像,通過圖像處理技術進行圖像分析獲取所需信息或控制機械執行裝置完成預設操作的一種非接觸式測量技術[3]。
崔艷麗等[4]以色調H作為顏色特征參數的研究域,以色調直方圖統計特征參數的計算和百分率直方圖區間值特征作為區分病變葉片與正常葉片的重要依據。通過色調區間來對正常葉片和病害葉片進行識別,需要提取較多的參數。溫芝元等[5]通過分水嶺算法提取蟲害邊界,通過邊界提取、閾值分割,得到二值圖像,再將其導入到小波神經網絡中,進而識別碰柑樹病蟲害,平均識別準確率為87%。分水嶺算法雖然對簡單的特征分割效果較好,但是對植物病害特征等較為復雜的場景進行分割時,會由于對圖像中的噪聲極其敏感而導致分割效果不佳。
由此可知,基于傳統機器視覺的模型對植物病蟲害識別的準確率不高,在圖像特征處理階段具有一定的主觀性。深度學習的逐漸興起為植物病蟲害識別帶來了新的方法。郭小清等[6]在AlexNet的基礎上,通過修改網絡結構,使模型對番茄葉部病害及每種病害早中晚期的平均識別準確率達到 92.7%;蒲秀夫等[7]通過將VGG16用改進后的符號函數對權重和激活值二值化,以符號函數和尺度因子α代替浮點型權值參數,以提高模型的計算速度;宋程勇等[8]在GoogleNet的基礎上進行改進,通過減少Inception模塊數量,增加卷積層和池化層,用改進后的模型對蘋果病蟲害數據集進行識別。
本研究基于ResNet34進行改進[9-13],用蘋果葉病害數據集對模型進行訓練,并通過消融實驗評價模型的性能。
1 實驗數據集
蘋果葉病害數據集[14]主要在晴天光線良好的條件下獲取,部分圖像在陰雨天進行采集,不同的采集條件進一步增強了數據集的多樣性。 數據集包括斑點落葉病、褐斑病、花葉病、灰斑病以及銹病5種常見的蘋果葉面病害圖像數據,然后經過翻轉、對比度調整等數據增強,對數據集進行擴充,其中蘋果葉病害數據集病害圖片示例如圖1所示,表1給出了每個病害類別的圖片數量。

圖1 蘋果葉病害數據集示例圖
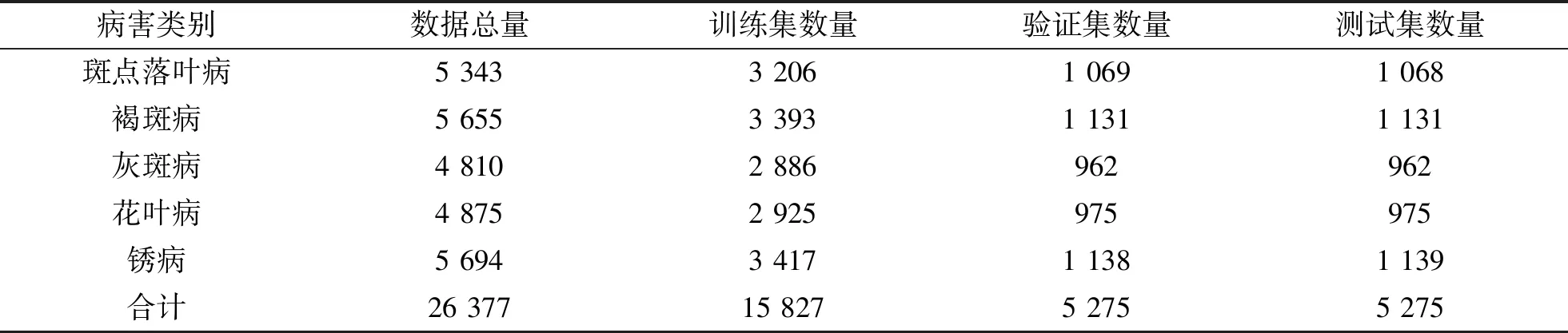
表1 蘋果葉病害數據集統計表
2 蘋果葉病害識別模型
2.1 ResNet34模型
目前,卷積神經網絡在圖像分類[15-18]、目標檢測[19-21]、圖像分割[22]等領域獨樹一幟。ResNet網絡由何凱明等[9]提出,它極大地提高了模型的識別能力,同時很好地解決了卷積神經網絡層數加深后出現的梯度消失、梯度爆炸和網絡退化問題。其核心之處在于提出了殘差結構,具體如圖2所示。
首先輸入通道數為3,大小為224×224的圖像,經過第一層卷積層之后,通道數變為64,大小變為112×112;然后經過最大池化層,通道數不變,大小減少為一半;然后進入到殘差部分,殘差部分有4個殘差網絡,依次對應著3、4、6、3個殘差結構,第一個殘差網絡里面的殘差結構都為實線,后面3個殘差網絡里的第一個殘差結構為虛線,其余的為實線殘差結構;最后將第4個殘差網絡與平均池化層和全連接層連接。ResNet34模型如圖3所示。
2.2 ResNet34模型的改進
(1)卷積核的替換。從圖3可以看到,ResNet34第一層卷積層的卷積核大小為7×7,雖然大尺寸卷積核能夠提取更多和更復雜的特征信息,但會存在較多的參數,導致計算速度緩慢。卷積核參數量的計算如式(1)所示:
Params=N×(w×h×F)×c,
(1)
式中,Params表示卷積核的參數總數;N表示卷積核的個數;w、h、c分別表示卷積核的寬、高和通道數;F表示輸入的特征圖的大小。由式(1)可知,1個7×7卷積核的參數量為49 cF,改為3個3×3卷積核后,參數量為27 cF,減少了大約45%,模型改動如圖4所示。

圖2 殘差結構

圖3 ResNet34模型
卷積神經網絡各輸出特征圖中的每個像素點,在原始輸入圖片的映射區域的大小,稱為感受野(Receptive Field),其計算如式(2)所示:
(2)

(2)殘差結構的優化。原始ResNet34中,殘差網絡中的殘差結構是兩個卷積核大小為3×3的卷積層(見圖2)。為減少ResNet34網絡模型參數,故對殘差結構進行優化,將其改為1×1、3×3和1×1串聯的瓶頸結構,其中,由3×3卷積層實現下采樣,后面的1×1實現上采樣,具體結構如圖5所示。

圖4 卷積核替換 圖5 殘差結構優化
(3)shortcut結構的優化。由圖2b可知,主分支的輸出與shortcut輸出特征矩陣的形狀不相同時,捷徑分支必須要經過一個卷積核大小為1×1,步長為2的卷積層,即經過圖2b所示虛線殘差結構,從而可以進行相加的操作。我們對這個虛線殘差結構進行改進,添加一個平均池化層來取代之前的卷積核大小為1×1的卷積層的下采樣功能。添加平均池化層不僅可以去除冗余信息,對特征進行壓縮,降低網絡復雜度,而且可以防止過擬合或者欠擬合,提高網絡模型的識別能力。
(4)殘差網絡block數的改變。由ResNet34、ResNet101、ResNet152模型結構可知,各層殘差網絡block數分別為[3,4,6,3]、[3,4,23,3]和[3,8,36,3],第一層殘差網絡中的block數與最后一層相同,第3層最多。在本文中,將會把ResNet34中的各層殘差網絡的block數改為[1,2,12,1],將主要的特征提取任務集中在第3個殘差網絡上,從而可以達到降低模型參數量,提高計算速度的作用。
3 實驗
3.1 實驗環境
本研究實驗訓練環境在Windows 11家庭中文版操作系統下,基于處理器11th Gen Intel(R) Core(TM) i7-11800H @ 2.30 GHz,16 GB運行內存,使用的顯卡為NVIDIA GeForce RTX 3060 Laptop GPU,采用深度框架tensorflow 2.6.0,配合Cuda 11.6進行訓練,模型訓練過程設置學習率為0.001,批數量設置為16,訓練epoch數設置為50,采用Adam優化器更新模型參數。
3.2 實驗評價指標
本文使用混淆矩陣中的識別準確率(Accuracy)、平均精確率(Ave-Precision)、平均召回率(Ave-Recall)和平均綜合評價指標(Ave-F-Measure)這4個指標來評價網絡的性能。其中,識別準確率、平均精確率、平均召回率、平均綜合評價指標如式(3)~(6)所示:
(3)
(4)
(5)
(6)
式中,M為蘋果葉病害分類個數;P表示正樣本;N表示負樣本;T為預測正確;F為預測錯誤;TP表示模型將正樣本預測為正樣本的個數;TN表示模型將負樣本預測為負樣本的個數;FP表示模型將負樣本預測為正樣本的個數;FN表示模型將正樣本預測為負樣本的個數。有如下關系:P=TP+FN,N=TN+FP。Precision和Recall為單個類別對應的精確率和召回率。當式(6)中的α=1時,為平均F1分數。
3.3 實驗設計
本研究將采用3∶1∶1的比例,將其劃分為訓練集、驗證集和測試集。為了證明ResNet34網絡的優越性能,選取了AlexNet、VGG16、GoogLeNet、ResNet18,通過相同數據集進行對比實驗,結果如表2所示。由表2可知,ResNet34網絡模型的識別準確率最好,達到了96.2%,具有更強的識別能力,故選用ResNet34作為本研究識別蘋果葉病害的基礎模型,并對其結構進行優化改進,得到性能更加優良的殘差網絡模型。

表2 不同基礎模型識別結果對比
3.4 實驗結果與分析
為確定本研究改進的ResNet34模型中小卷積核替換大卷積核、殘差結構優化、shortcut結構優化、殘差網絡block數的改變對于模型的優化能力,其中小卷積核替換大卷積核已經由理論公式證明,下面將通過消融實驗證明其他改進方法的實際效果。
(1)殘差結構優化的消融實驗。為驗證ResNet34模型在殘差結構優化后的實際效果,故進行殘差結構優化的消融實驗。將殘差結構中的兩個3×3卷積層變為1×1、3×3和1×1卷積層得到的網絡模型A-ResNet34與ResNet34模型在本文相同的實驗環境中進行訓練后對比,實驗結果如表3所示。由表3可知,雖然殘差結構優化導致了A-ResNet34的識別準確率比ResNet34下降了0.2%,但是模型參數量卻減少了7 410 944,降低了大約34.8%,實驗結果表明,本研究的殘差結構優化雖然小幅降低了網絡模型的識別準確率,但是大大減少了模型參數量,降低了計算損耗。

表3 殘差結構優化結果對比
(2)shortcut結構優化的消融實驗。為驗證ResNet34模型在shortcut結構優化后的實際效果,故進行shortcut結構優化的消融實驗。將shortcut連接中的1×1卷積層的前面加上一個平均池化層,并取消1×1卷積層的下采樣功能,由平均池化層執行下采樣操作,得到網絡模型B-ResNet34,與ResNet34模型在本研究相同的實驗環境中進行訓練后對比,實驗結果如表4所示。從表4可知,B-ResNet34的識別準確率比ResNet34上升了0.3%,平均召回率和平均F1分數增加了0.1%,平均精確率相同,B-ResNet34模型與ResNet34模型相比,對蘋果葉病害的識別能力具有一定的提升。

表4 shortcut結構優化結果對比
(3)殘差網絡block數改變的消融實驗。為驗證ResNet34模型在殘差網絡block數改變后的實際效果,故進行殘差網絡block數改變的消融實驗。將之前ResNet34模型中殘差網絡的block數由[3,4,6,3]變為[1,2,12,1],得到網絡模型C-ResNet34,與ResNet34模型在本研究相同的實驗環境下進行訓練后對比,實驗結果如表5所示。從表5可知,隨著殘差網絡block數的改變,C-ResNet34模型識別準確率比ResNet34下降了0.6%,但模型參數卻減少了14.5%,在犧牲小幅度的識別準確率的前提下,減少了模型參數量,提高了計算速度。

表5 殘差網絡block數改變結果對比
(4)改進的ResNet34模型實驗結果。本研究對ResNet34進行改進,將大卷積核改為小卷積核、殘差結構優化、shortcut結構優化、殘差網絡block數改變,得到了改進模型,訓練后在訓練集和驗證集的識別準確率和損失函數值如圖6、7所示。 從圖6、7可知,改進模型識別準確率不斷提高,損失函數值不斷減少,并最終在25個epoch趨于收斂。保留模型損失函數值最低時對應的權重參數,將測試集輸入到訓練好的改進模型中,得到混淆矩陣[23]如圖8所示。
由圖8可知,X軸對應的為真實標簽,Y軸對應的為預測標簽,標簽分別對應Alternaria_Boltch(斑點落葉病)、Brown_Spot(褐斑病)、Grey_Spot(灰斑病)、Mosaic(花葉病)和Rust(銹病)。在混淆矩陣中,主對角線對應的數字為改進模型預測正確的部分,而其他位置為預測錯誤的部分,數字總和為測試集圖片數量。改進模型和ResNet34實驗結果如表6所示。由表6可知,改進的ResNet34模型相較于ResNet34基礎模型,識別準確率、平均精確率、平均召回率和平均F1分數分別增加了0.5%、0.5%、0.6%和0.6%,模型參數量降低了大約43.3%。識別能力得到了小幅度提升,同時減少了模型參數量,降低了計算損耗,更加容易應用到移動端和嵌入式設備中。

圖6 訓練集和驗證集識別準確率迭代過程 圖7 訓練集和驗證集損失函數迭代過程
4 結論
本文針對蘋果葉病害識別的研究,基于ResNet34模型提出了一種改進的ResNet34模型。模型的特點主要包括:①將原始模型ResNet34中的第一層卷積層中的7×7卷積核替換為3個3×3的小卷積核,初步減少模型參數量;②將殘差結構中的兩個大小為3×3卷積層替換成大小為1×1、3×3和1×1串聯的卷積層,使模型參數量減少了34.8%;③在虛線殘差結構處,取消1×1卷積層的下采樣功能,添加了一個平均池化層來進行下采樣操作,使模型的識別能力得到了小幅的提升;④將ResNet34模型殘差網絡的block數由[3,4,6,3]改為[1,2,12,1],使模型參數量減少了14.5%。改進的ResNet34模型在實現識別能力小幅度提升的同時,減少了43.3%的模型參數量,較為顯著地降低了模型的計算開銷,為其應用到移動端和嵌入式設備提供了一定的思路。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
房地產導刊(2022年5期)2022-06-01 06:20:14
哲學評論(2021年2期)2021-08-22 01:53:34
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中華詩詞(2019年7期)2019-11-25 01:43:04
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
影視與戲劇評論(2016年0期)2016-11-23 05:26:01
發明與創新(2016年38期)2016-08-22 03:02:52
