復雜產品的關鍵質量特性識別
2022-02-21 12:20:52李秀
現代制造技術與裝備 2022年1期
李 秀
(鄭州大學 商學院,鄭州 450001)
隨著智能制造的迅猛發展和全球一體化的日益加深,產品質量成為了制造企業獲取競爭優勢的關鍵。作為制造業的核心,復雜產品的質量對我國經濟健康發展起著重要作用。由于復雜產品普遍采用單件小批的生產方式,質量數據呈現出小樣本、高維度的特點,易造成維度災難和過擬合問題,這在很大程度上降低了復雜產品質量預測的精度。在實際生產應用中,只有少數關鍵質量特性(Critical-To-Quality,CTQ)對最終產品質量有顯著影響,因此識別CTQ是構建質量預測模型的關鍵,對控制產品質量具有重要意義。
目前,CTQ識別方法主要集中在兩個方面:一是基于傳統線性回歸的關鍵質量特性識別,如TSUNG[1]利用狀態空間波動傳遞模型進行多階段制造過程的CTQ識別;二是將CTQ識別問題抽象為特征選擇的過程,通過數據挖掘構建產品質量特性與最終質量的關系模型,從而識別出對最終產品質量具有顯著影響的CTQ,如王化強等[2]針對復雜產品質量特性數據不相關和冗余特征問題,引入Lasso算法識別復雜產品CTQ。總的來看,現有研究多數僅考慮了復雜產品質量數據集的高維度、小樣本、數據不平衡特點中的一個或兩個,但實際生產過程中復雜產品質量數據集往往同時兼具上述3個特點。因此,針對復雜產品的加工質量特點,本文構建了基于B-K-Lasso模型的復雜產品關鍵質量特性識別方法,從而為復雜產品的質量控制提供有效參考。
1 B-K-Lasso質量特性識別模型
1.1 B-K-Lasso模型構建
Lasso是一種高維數據變量選擇算法,其基本思想是通過構造一個懲罰項來壓縮模型回歸系數,即通過調整變量的回歸系數使殘差平方和最小,從而將沒有影響或影響較小的自變量的回歸系數壓縮至0,實現高維數據的系數估計和變量選擇[3]。針對高維小樣本的數據,直接使用Lasso易導致計算量大、過擬合問題。馬嘯等[4]通過將特征隨機均勻地劃分為K份,并對每份特征子集用Lasso算法進行特征選擇,得到了K份選出的特征子集,然后將K份特征子集合并得到最優特征集。該方法通過特征分塊有效降低了數據維度,減少了計算量。然而,在實際生產過程中,K-split Lasso模型并不能完全有效識別出復雜產品的關鍵質量特性。其原因如下:第一,復雜產品的制造過程復雜,生產批量小,質量特征維度可能遠大于樣本量;第二,產品生產過程中面臨數據不平衡問題,即合格產品的數據遠高于不合格品的數據,模型傾向于將不合格品分為合格品,從而給企業帶來較大損失。
為解決上述不足,本文從兩個方面對K-split Lasso模型進行改進。一方面,采用合成少數類過采樣技術(Synthetic Minority Oversampling Technique,SMOTE)處理復雜產品質量特性數據集,從而得到平衡質量特性。SMOTE是一種過采樣技術,它可利用少數類樣本及其鄰近樣本隨機生成新的樣本,使得少數類樣本量增加,從而達到平衡樣本的目的[5]。另一方面,依托Bootstrap算法反復模擬原高維小樣本數據集,從而得到多個自助樣本,實現小樣本的擴充[6]。Bootstrap的基本思想是在原始樣本的基礎上通過多次重復有放回的隨機抽樣,得到多個與原有樣本同分布的樣本,從而構建大樣本數據集[7-9]。基于B-K-Lasso模型的CTQ識別如圖1所示。
1.2 復雜產品的關鍵質量特性識別步驟
第一,明確復雜產品的生產特點,在制造過程中采集質量特性數據,獲得原始質量特性數據集。第二,對原始數據進行預處理,并對預處理后的數據采用SMOTE技術,獲得平衡質量特性數據集X=(X1,X2,…,Xn),第j個樣本Xj是m維特征向量,j∈[1,n]。第三,用Bootstrap抽樣,即在原始數據集X上進行Q輪隨機有放回抽樣,得到Q個自助樣本X*=(X1*,X2*,…,XQ*),其中樣本的數量為n×Q。第四,對每個自助樣本Xi*構建K-split Lasso特征選擇模型,即把m個特征均分成K份得到M=(Mi1,Mi2,…,MiK),然后對每一份M用Lasso進行特征選擇,得到特征集合F=(Fi1,Fi2,…,FiK),其中i∈[1,Q]。第五,通過Lasso算法對合并后的特征集合F=(Fi1,Fi2,…,FiK)進行特征選擇,得到每個自助樣本的特征選擇結果Fi*。第六,集成Q個自助樣本特征選擇的結果。通過對對應特征系數平均加權實現集成,最終得到整個數據集的特征選擇結果F*即是復雜產品的關鍵質量特性集。
2 實驗結果及分析
2.1 數據說明及預處理
本文選用UCI數據庫中的SECOM數據集進行仿真實驗及結果分析。該數據集共包含1 570個樣本,每個樣本有590個質量特性。其中,合格品1 466個,不合格品104個。由于數據存在缺失問題,需要進行預處理,即將原始數據標準化,并將數據集中質量特性缺失大于20%的項刪除,其他缺失項用均值替換。實驗分別使用Lasso、K-split Lasso、Bootstrap-Lasso和B-K-Lasso進行CTQ識別。
2.2 評價指標
分類準確度(Accuracy,ACC)能反映整體分體精度,AUC值在二分類、不平衡數據集上具備更好的鑒別能力。因此,本文采用ACC、AUC指標進行綜合評價。
2.3 實驗過程及結果分析
首先,針對預處理后的數據,采用SMOTE技術生成不合格樣本,得到平衡質量數據集。其次,設置參數Q=50,K分別為3、4、5、8、10、15、20、25、30,然后使用B-K-Lasso進行CTQ識別,并輸出K取不同值時的關鍵質量特性集。最后,根據選取的不同關鍵質量特性數據集,測試分類結果。由于支持向量機(Support Vector Machine,SVM)在小樣本數據集上效果很好,且RF能夠通過集成具有不同特征的決策樹提高分類準確率,從而擁有更強的泛化能力,因此本文分別以RF和SVM作為分類器對模型進行性能測試。將每種算法運行20次,然后以運行結果取均值作為最終結果,具體結果如表1所示。
表1所示為各種算法所得降維水平和分類精度,由表1可以看出,B-K-Lasso集成算法下的RF和SVM算法總體上都能夠有效去除冗余特征,關鍵質量特性數在150個左右。B-K-Lasso RF和B-K-Lasso SVM算法都具有較高的分類準確率,最高值分別為93.42%和94.27%,分別在K=25和K=20時取得。但是,針對不合格產品的識別性能方面,B-K-Lasso SVM算法較差,AUC值較低,最大為62.55%;B-K-Lasso RF算法較為穩定,AUC值在75.81%左右波動,最大為79.52%。對于復雜產品生產企業來說,將不合格產品判定為合格產品要遠比將合格產品判定為不合格產品帶來的損失大。因此,綜合考慮ACC和AUC的值可知:本文算法可以有效識別復雜產品的CTQ,所識別的CTQ對產品也具有較好的預測能力。此外,RF集成分類算法對不合格產品的質量預測效果更好。
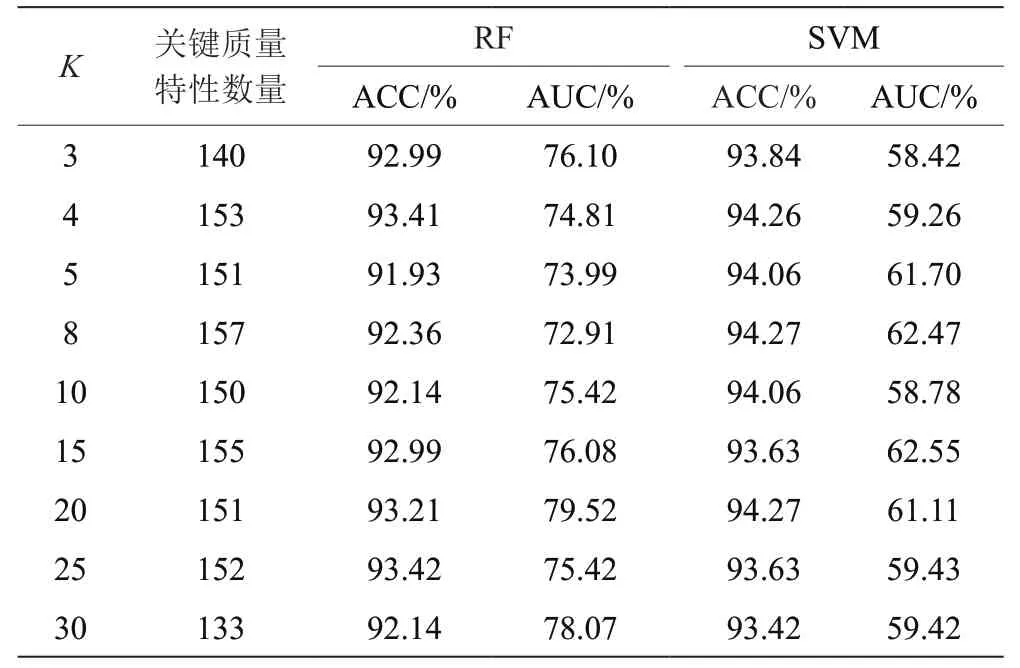
表1 B-K-Lasso RF和B-K-Lasso SVM獲得的關鍵質量特性測試結果對比
2.4 不同算法結果對比
由表1可知,針對不平衡數據,RF分類器的分類性能優于SVM,因此本文將B-K-Lasso、Lasso、K-split Lasso、Bootstrap Lasso這4種算法分別與RF進行結合,結果分別如圖2和圖3所示。
綜合圖2和圖3的結果,Lasso算法的ACC值為91.30%,AUC值為75.73%。與其他3種算法相比,Lasso的ACC值較低,AUC值較高,且不管K如何取值都保持不變。因此,Lasso對于不平衡數據中的少數類樣本較為友好,能有效識別復雜產品中不合格品的關鍵質量特性。B-K-Lasso算法的ACC和AUC的值基本都比其他算法大,對于復雜產品的整體識別度較高且對不合格品的識別度也較好。從圖中可以看到,將特征均分成K塊,即引入K-split Lasso算法后,不管K取何值,模型整體識別率均顯著提高,但AUC值比較小,即對不合格品的識別率較差。當引入Bootstrap進行樣本重構后,B-K-Lasso算法分類結果明顯比K-split Lasso波動小,模型結果更穩定。
綜上可知,在復雜產品的關鍵質量特性識別中,相比于K-split Lasso和Lasso算法,本文的B-K-Lasso集成特征選擇算法在提高不合格樣本準確率的同時,確保了總的識別率不會下降,特別是基于Bootstrap方法對樣本重構后,B-K-Lasso模型不僅穩定性顯著提高,而且可以有效去除冗余特征,從而識別復雜產品的關鍵質量特性,保證產品質量預測的效果。
3 結論
識別復雜產品的CTQ是當前制造企業普遍存在并亟待解決的問題。由于復雜產品質量特性數據高維度、小樣本、不平衡的特點,給復雜產品質量控制的成本和效率都帶來了極大的挑戰。本文通過采用Bootstrap重復抽樣,生成多個自助樣本,并在重構后的樣本上構建K-split Lasso模型進行特征選擇,從而解決了上述問題。仿真實驗結果表明:該方法具有一定的合理性和可行性,一方面能夠準確有效地識別復雜產品的關鍵質量特性,另一方面可以在提高不合格品識別準確率的同時確保總的準確率不會下降。
猜你喜歡
中學生數理化(高中版.高考理化)(2021年6期)2021-07-28 06:21:04
中國眼鏡科技雜志(2019年9期)2019-11-11 12:15:30
勞動保護(2019年7期)2019-08-27 00:41:04
質量技術監督研究(2018年1期)2018-03-26 08:04:36
新農業(2016年20期)2016-08-16 11:56:22
Coco薇(2015年1期)2015-08-13 02:23:50
NBA特刊(2014年7期)2014-04-29 00:44:03
中國商人(2013年1期)2013-12-04 08:52:52
玩具(2009年10期)2009-11-04 02:33:14
個人電腦(2009年9期)2009-09-14 03:18:46
