基于數據挖掘技術的電網時序數據質量維護研究
2022-02-18 01:34:04謝瀚陽彭澤武唐重陽肖嘯魏理豪
電測與儀表 2022年2期
謝瀚陽,彭澤武,唐重陽,肖嘯,魏理豪
(1.廣東電網有限責任公司信息中心, 廣州 510062; 2.深圳市康拓普信息技術有限公司,廣東 深圳 518034)
0 引 言
隨著科學技術的不斷進步,電網的智能化水平也越來越高,也因此在電網運行和設備監測的過程中產生了大量的數據[1-2],例如系統運行數據、設備狀態數據、用戶需求數據等等。另外,物聯網技術和云計算的蓬勃發展,也進一步增強了電網數據的體量和復雜度。如此龐大的數據體系難免會帶來一些數據質量問題,如數據缺失、數據冗余、數據異常等。數據質量的好壞不僅關乎電網應用分析的可靠性與正確性,還會對電力系統的穩定運行產生影響[3-4]。所以,進行高效可靠的數據質量管理對電力系統具有重要意義。
數據質量維護是數據質量管理的重要組成部分[5],可以有效檢測出問題數據并進行篩除,是改善數據質量的重要組成部分。不少學者在數據質量維護方面作出了相關的貢獻。
文獻[6]以CIM/E文本為載體,改進多源數據篩選較優質量數據的手段,由借助主站狀態估計對現場數據進行反饋,提高了電網調度系統的整體數據質量;文獻[7]從多源多時空角度出發,基于配網SCADA數據提出一種用于綜合檢測與修正電壓數據質量的策略,并通過算例證明了所提方法能有效檢測出不滿足精度要求的電壓數據;文獻[8]設計一種考慮多維度電網調度數據質量的綜合分析與評價系統,為電網調度人員提供更為直觀的綜合數據考核與評價手段。
近年來,數據挖掘技術在電網數據管理中的應用也越來越廣泛[9-10]。文獻[11]針對電能質量檢測問題,應用數據挖掘技術,提出了一種的電能質量數據分析處理體系,并應以某城市電網為例,獲得了良好的效果;文獻[12]建立基于數據挖掘的營銷分析方法模型,成功用于分析給定市場環境中各種因素之間價格變化的層次關系。文獻[13]對模糊角力分析進行改進,并用于電網不良數據的檢測與辨識,獲得良好成效。
關于電力數據質量檢測已有不少研究,但仍存在以下問題:
(1)大多檢測方法對全部樣本進行統一分析,但隨著數據量的不斷增長,逐漸出現檢測效率低下的問題;
(2)對數據的質量好壞評價已有較多研究,但對于數據的問題定位研究相對較少。
基于數據挖掘技術,針對不同系統的數據結構特點有所不同的特點,結合使用決策樹算法與數據離群檢測兩種方法,提高數據檢測的效率的同時,快速定位數據的問題類型,便于開展數據修復與改進。
1 智能電網時序數據質量分析
1.1 電力數據傳輸過程分析
科學技術的不斷發展使電網的智能化和信息化水平大大提高,對電網數據的需求量也逐漸增大。智能電網系統可以通過數據采集與監控系統、能量管理系統等,實時獲取相關生產和運行數據。智能電網將獲取的源頭數據存儲進入數據庫,并進行相關管理。與此同時,用戶則可通過用戶訪問接口、手機APP等訪問所需數據[14]。該數據邏輯結構如圖1所示。
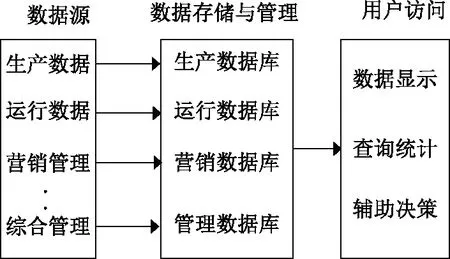
圖1 電力數據傳輸邏輯結構圖Fig.1 Logical structure diagram of power data transmission
1.2 電力統計數據問題
隨著電網體系規模的不斷擴大,其運行過程中產生的數據量也越來越豐富,這其中蘊含著大量的信息,是可以影響發電、輸配電、用戶用電管理的決策指標的基礎。但由于設備故障、認為原因等,電力數據可能會存在一些誤差甚至是錯誤,這不僅不能為電力系統提供可靠的數據分析基礎,而且可能因此帶來決策錯誤,影響整個系統的良好運行。圖2指出電力數據傳輸過程中可能會遇到的問題。

圖2 電力數據主要問題Fig.2 Main problems of power data
(1)格式錯誤。所獲取的數據格式應是統一的,不滿足格式的數據組應視為不合格。另外在數據傳送過程中,可能會出現亂碼等錯誤,這也是格式檢查的重要方向;
(2)精度錯誤。在數據獲取和傳輸過程中,所有數據的精度都應保持一致,精度與規定不一致的數據應為不合格;
(3)數據越限。每個數據都有自身約束范圍,數據應在規定范圍內;
(4)數據冗余。數據傳輸過程中可能存在重復記錄的問題,因此會產生數據冗余;
(5)數據缺失。在數據獲取和用戶訪問端,所獲取的數據量應一致,不能存在缺失記錄或缺失字段;
(6)合理性問題。所獲取數據都應滿足電力系統運行要求,各數據之間互相約束,數據段不滿足運行條件的為不合格數據段。
2 時序數據質量維護體系構建
為了快速準確地篩選質量差的數據,結合使用數據挖掘技術中的決策樹法和離群檢測法,充分利用決策樹的快速分類和離群檢測法在數據相關性檢測的優勢,可操作性和準確度更高。
2.1 決策樹算法
決策樹算法是分類算法的一種。它首先要預處理原始數據,然后通過對原始數據的初步分析建立分類規則,分類規則一般以樹的形式出現,通過建立的樹對樣本訓練集進行實質的分析[15-16]。
采用最經典的ID3算法建立相關決策樹。在該算法中,各類別的不確定性是判斷分類效果的標準。這里用信息增益值描述該標準,其中信息增益值越高,不確定性越低。具體的步驟如下:
設S是包含m個數據樣本的集合,分類特性共n個,記為Bi(1,2...n),其中Bi所包含的樣本數為mi,則對于S的總信息熵為:
(1)
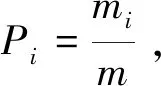
令Sj是集合S中特性Bi類別中有j個數據點的子集,則屬性Bi的信息熵為:
(2)
式中I(Sj)是Sj分至各個屬性的信息熵。
屬性Bi在集合S的信息增益G(S,Bi)為:
G(S,Bi)=I(D)-I(D,Bi)
(3)
G(S,Bi)越大,說明屬性Bi對分類起到的作用越大。所以,決策樹的分支節點應是信息增益最大的特性。
構建時序數據質量檢測順序決策樹時,決策樹算法需要使用歷史數據訓練集。選取某地區的典型歷史數據,并形成數據訓練集,具體如表1所示。
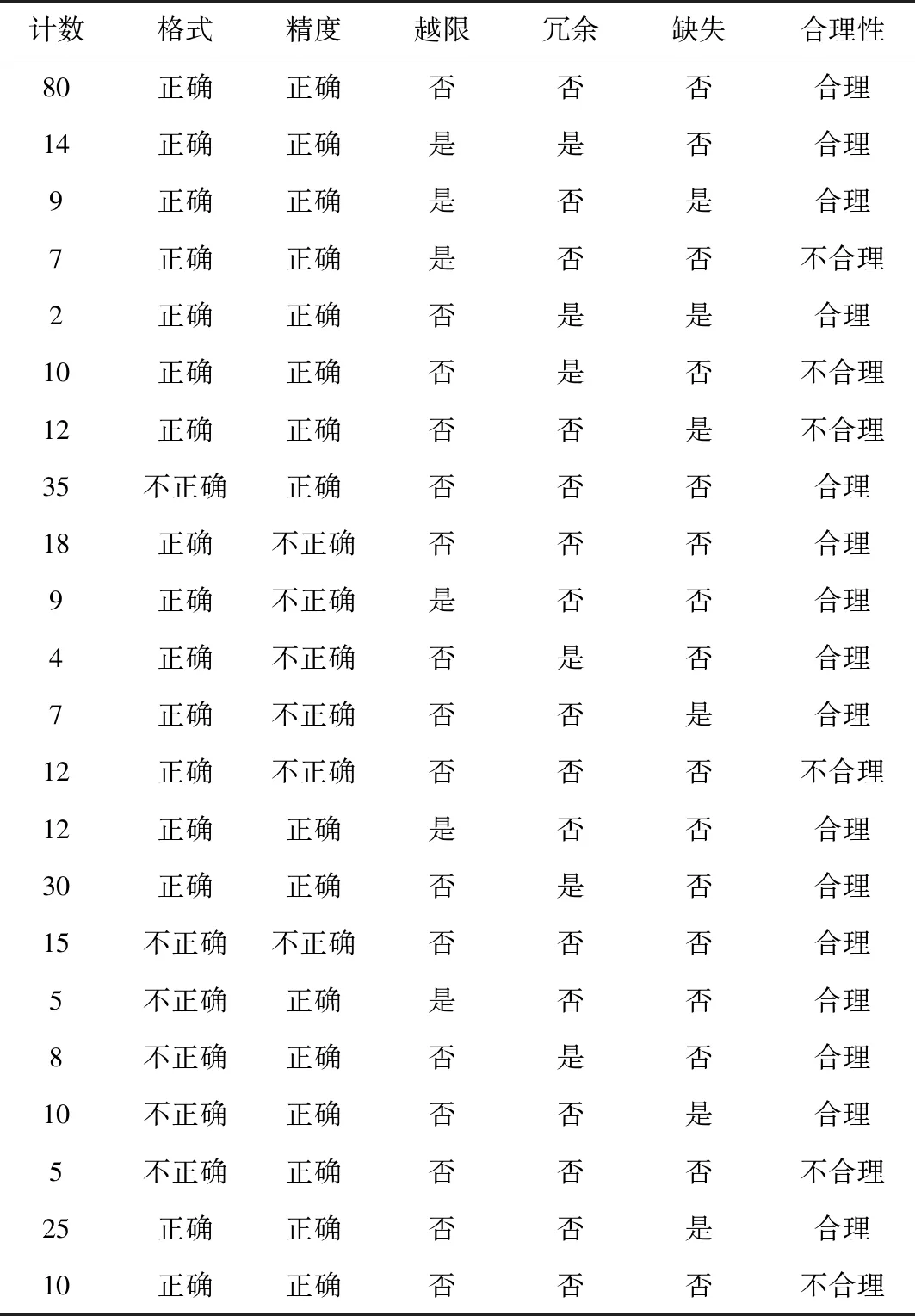
表1 電網數據訓練集Tab.1 Power grid data training set
輸入訓練集經過決策樹算法可形成初始決策流程,指標檢測順序如圖3所示。

圖3 指標決策順序Fig.3 Order of indicator decision
由上述分析可知,電力數據的格式錯誤、精度錯誤、數據越限、數據冗余、數據缺失等問題的檢測方式相對簡單,可對該數據點獨立進行檢測。但數據的合理性問題需要綜合考慮整體運行情況,檢測相對更為復雜,引入離群檢測法對數據合理性進行分析。
2.2 離群檢測法
離群點檢測用于檢測數據樣本中明顯偏離于其他數據的樣本,該類樣本不能滿足數據的普遍特征或行為,是數據挖掘技術的重要研究方向[17-18]。離群點檢測方法按照數據挖掘技術的不同可分為基于統計的離群檢測、基于深度的離群檢測、基于聚類的離群檢測等。本文采用基于距離的利離群檢測對數據合理性問題進行分析,篩選出不合格的數據。
聚類的思想主要是利用數據樣本和各類別間的相互關系[19-20],通過把樣本劃分為不同的類,使得同一分類內的數據點相似性最大,而不同分類之間的差異性最高。所采用的離群檢測方法主要分為兩個階段:首先采用K-means將數據進行聚類;然后針對每個數據樣本,計算其到距其最近類中心的距離,將該距離記為離群度量值。如果該數據樣本的離群度量值偏大,則為離群數據;反之,就是正常數據。
假設數據樣本X={x1,x2, …,xi, …,xn},設定分類數目為M,形成M個簇T={tm,m=1, 2, …,M}
步驟1:首先隨機選擇M個數據序列作為初始聚類中心c1,c2,…cM;
步驟2:計算每個數據序列和每個聚類中心的距離,把數據序列分配給距它距離最小的聚類中心,直到全部數據序列都被分配。計算各類聚類中心cm到所有屬于tm簇的元素xi的距離平方和為:
(4)
步驟3:計算各類數據序列距其所在類別中心cm的距離平方和L(T)。
(5)
式中rmi表示類別判定系數,當xi∈tm,rmi=1;反之,rmi=0。聚類中心更新為各類別中全部數據序列的平均值;
步驟4:返回步驟2,直至各聚類中心都不發生改變且L(T)小于設定參考值,聚類結束。
引入BMP指標來確定數據樣本的最佳分類數和評估聚類結果[21-22]。BWP是描述某樣本分類和它相鄰類別關系的指標,數學表達式如下:
(6)
式中Dw為聚類距離,表示最小類間距離和類內距離之和;Dn為聚類離差距離,表示最小類間距離和類內距離之差。
BWP基于樣本幾何結構對數據進行分析,BWP數值越大,說明數據樣本的聚類效果越準確。
2.3 數據質量維護總流程
數據質量維護流程圖如圖4所示。

圖4 數據質量維護流程圖Fig.4 Flow chart of data quality maintenance process
2.4 數據質量異常原因
在電網運行過程中,以下幾種情況可能會導致異常數據的產生:
(1)量測數據在傳輸過程中出現偶然性誤差,可能導致數據冗余、格式不正確、數據缺失、精度不足等問題;
(2)量測或傳輸系統故障、受到干擾引起的異常,可能導致數據冗余、數據越限等問題;
(3)電力系統各個量測點非同時測量,可能會引起數據合理性不足等問題[23]。
3 算例分析
以某地區配電網某檢測點為研究對象,結合本文提出的時序數據質量維護體系,對該地區某時段內電力數據進行分析。該點相關數據參數取值范圍為:電壓U∈[198,235.4],電流I∈[0,288.68],有功功率P∈[0,200],無功功率Q∈[0,120]。為了便于對比分析,本文僅列出部分樣本數據,如表2所示。
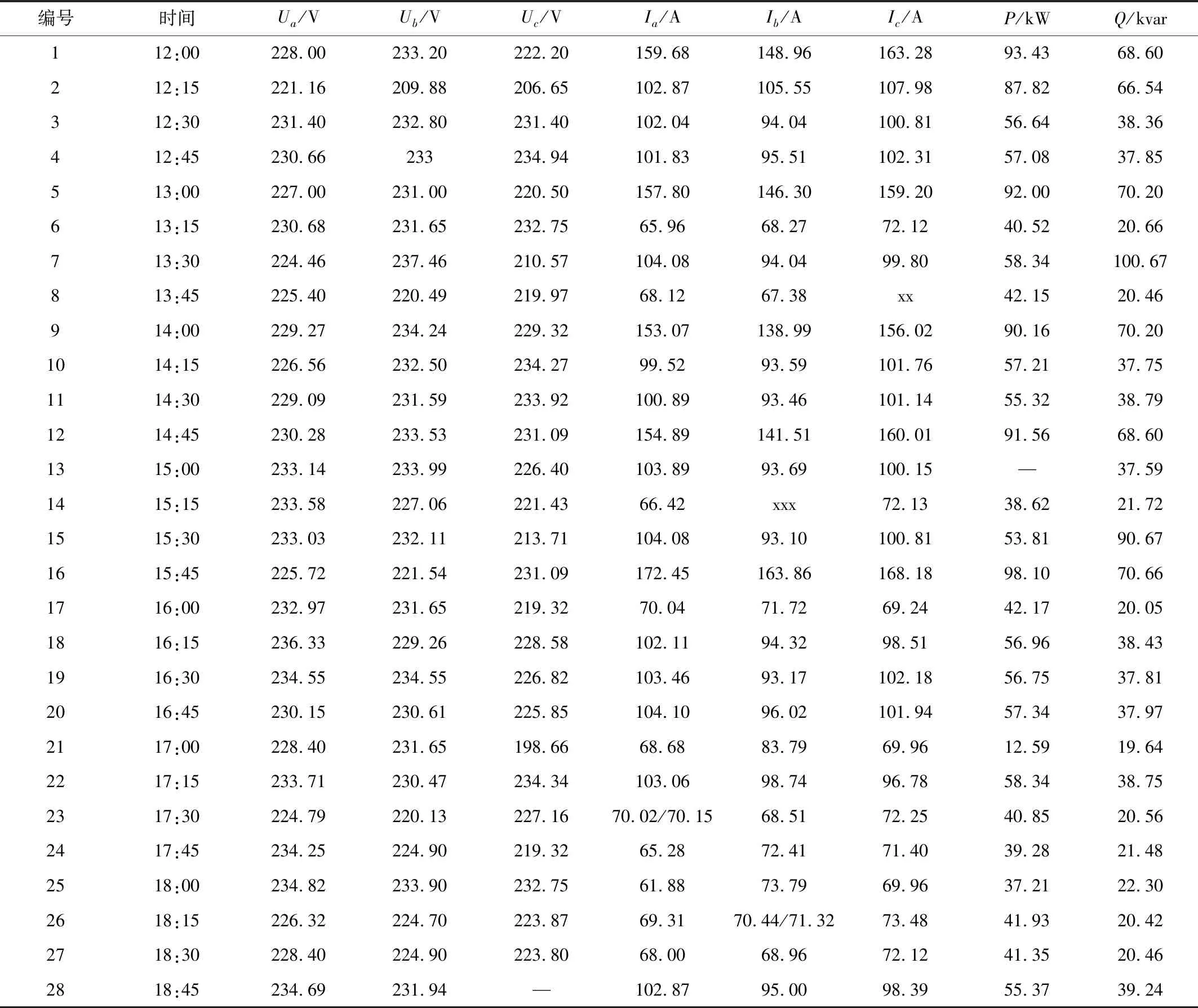
表2 部分樣本數據Tab.2 Partial sample data
通過文中的時序數據質量維護體系可以分析出數據是否有格式錯誤、精度錯誤、數據越限、數據冗余、數據缺失等問題,得到如表3所示結果。
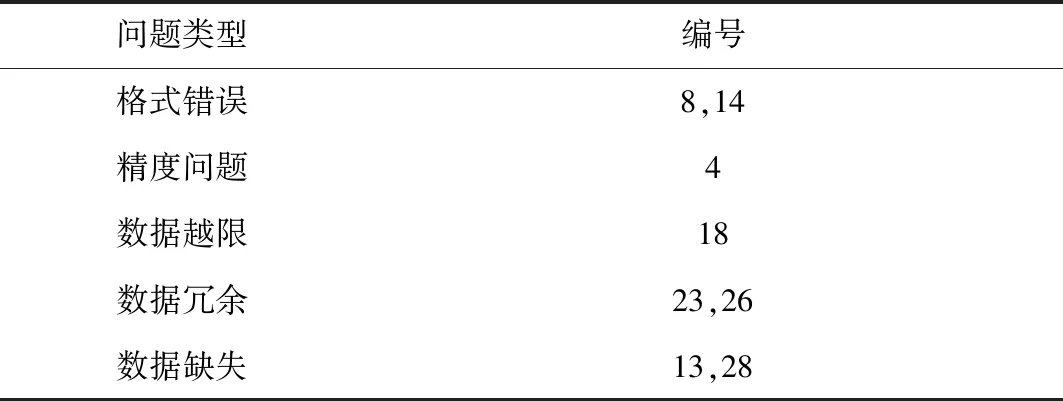
表3 電網數據訓練集Tab.3 Power grid data training set
在樣本中,有的數據點沒有上述問題,但是否存在合理性問題仍需通過離群檢測法進行判斷。有上述分析可知,共20個樣本數據需進行離群檢測。采用基于聚類的離群檢測法,樣本集分類個數依據BWP指標確定。不同分類數的BWP指標變化如圖5所示。
由圖5可知,最佳分組數為六組。當分組數為6時,結果如圖6所示。
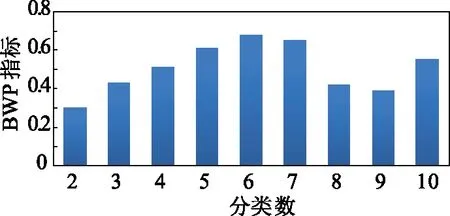
圖5 不同分類數的BWP指標Fig.5 BWP indices of different classification numbers
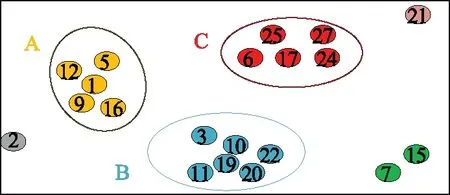
圖6 離群檢測結果示意圖Fig.6 Schematic diagram of outlier detection results
可以看出,數據點2、7、15、21明顯偏離其余大類,為不合理數據。為了驗證結果的準確性,對上述四個數據點的各項數據進行深入分析,各數據點存在問題如下:
(1)數據點2的B、C兩相電壓和三相電流值相比于其他合理數據都明顯偏低,因此作為孤立點是合理的;
(2)數據點7和數據點15相接近,但相比于B集群它們的無功功率值都偏大不少,因此作為孤立點是合理的;
(3)數據點21的C相電壓和有功功率值相比于C集群的其他數據明顯偏低很多,因此數據點21作為孤立點也是合理的。
為了確保未標識數據均為正確數據,根據所有樣本數據間的物理關聯關系進行狀態估計,監測結果如圖7所示,圖中1表示數據異常,0表示數據正常。
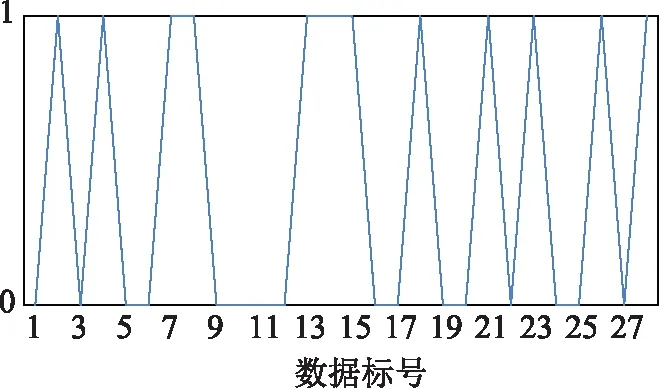
圖7 狀態估計檢測結果示意圖Fig.7 Schematic diagram of state estimation detection results
由圖7可知所提方法與狀態估計法檢測結果一致。經上述分析可知,通過文中的時序數據質量維護可有效快速發現各數據點存在的問題,定位問題數據,并確定數據的問題類型,為運行維護人員確定數據問題原因,提高數據可靠性奠定基礎。
4 結束語
基于數據挖掘技術提出一種時序數據質量維護體系,通過該檢測體系,可有效發現問題數據點,并進行篩除,主要結論如下:
(1)不同地區的數據特點不同,為了提高檢測速度,本身首先利用決策樹法對歷史數據進行分析,得出適應于該地區的數據問題檢測順序,可在一定程度上提高計算效率;
(2)與其他數據問題不同,數據的合理性問題檢測較為復雜。引入基于聚類的離群檢測法對所獲取的數據進行分析,可有效篩選出問題數據;
(3)提出一種時序數據質量維護體系,不僅可以定位問題數據,還可以確定數據出現的問題,保證用于電網分析與規劃的數據的可靠性,同時也利于及時發現問題數據,快速定位問題點,便于快速修復與改進。
猜你喜歡
中學生數理化·八年級物理人教版(2021年12期)2021-12-31 03:23:08
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
大眾投資指南(2021年35期)2021-02-16 01:06:26
中學生數理化·中考版(2020年10期)2020-11-27 01:59:48
中國生殖健康(2019年2期)2019-08-23 08:12:08
電力與能源(2017年6期)2017-05-14 06:19:37
海峽科技與產業(2016年3期)2016-05-17 04:32:12
汽車觀察(2016年3期)2016-02-28 13:16:26
