基于深度學習的魯棒地震數據去噪
2022-02-18 02:42:16李新月王洪濤董宏麗
石油地球物理勘探 2022年1期
關鍵詞:模型
張 巖 李新月 王 斌 李 杰 王洪濤 董宏麗
(①東北石油大學計算機與信息技術學院,黑龍江大慶 163318; ②黑龍江省大慶市信息技術研究中心,黑龍江大慶 163318; ③東北石油大學人工智能能源研究院,黑龍江大慶 163318)
0 引言
隨機噪聲嚴重影響地震資料的處理工作[1-2],如何高效地從含噪數據中提取有效信息,是地震資料處理領域的一個重要研究方向。為了解決這一問題,學者們提出了多種隨機噪聲壓制方法。按照是否假設具體的先驗模型,這些方法可劃分為兩類:基于先驗模型的傳統去噪方法和基于深度學習的去噪方法。
基于先驗模型的傳統去噪方法是從數據的分布先驗出發,建立并求解數學模型。該方法又可以進一步劃分為傳統時域去噪、傳統頻域去噪、多尺度幾何分析和稀疏表示去噪等。其中,傳統時域去噪方法是利用地震數據時域分布的特點構建濾波函數去除噪聲,主要包括中值濾波[3-5]、非局部均值濾波[6-7]等。傳統頻域去噪方法是將地震數據變換到頻域,在頻域內分析有效信號與噪聲分布的特點,預測并去除噪聲,然后返回時域以實現噪聲壓制,主要包括Fourier變換[8]、Radon變換[9]等。多尺度幾何分析的原理與傳統頻域去噪的原理類似,區別在于多尺度幾何變換較傳統的頻域變換具有多尺度和多方向特性,更適用于地震數據的同向軸紋理特征表示,主要包括Wavelet變換[10-11]、Curvelet變換[12]等。稀疏表示去噪方法是通過字典學習等方式得到基函數以表示地震數據的主要特征,去除噪聲特征以達到去噪的目的,主要包括K-奇異值分解(K-Singular Value Decomposition,K-SVD)[13-16]、三維塊匹配(Block-Matching and 3D Filtering,BM3D)[17]等。
以上地震數據去噪方法對于不同噪聲條件下的去噪具有一定的效果,但地震數據的噪聲產生因素多,噪聲分布復雜。根據數據先驗知識,人工建立的模型只能提取淺層特征,表達能力較弱,無法描述復雜的噪聲分布,影響了模型假設和參數設置的準確性[18]。更重要的是,野外數據的噪聲分布是未知的,缺乏足夠的先驗信息,因此去噪效果不太理想[19-20]。
近年來,深度學習技術以強大的深層特征提取與非線性逼近能力而倍受關注,基于深度學習的地震數據處理方法[21-23]的研究也逐漸展開。它與傳統去噪方法的主要差異在于不再假設具體的先驗模型,而是從數據本身出發,通過多層卷積的方式提取數據主要特征,利用大量的訓練樣本學習得到一個復雜的去噪模型。該技術主要包括基于降噪自編碼的噪聲壓制[24-26]、基于殘差學習的卷積去噪網絡[27-28]和基于生成對抗網絡的噪聲壓制[29]等。其中,基于降噪自編碼的網絡由編碼和解碼兩部分組成,編碼過程中通過多層卷積和池化等操作提取數據中主要的紋理特征,解碼過程中使用反卷積和上采樣等操作輸出去噪后數據。
Zhang等[24]和Chen等[25]利用U-Net的網絡結構對地震數據進行隨機噪聲壓制,自適應地從噪聲中學習地震信號,實現了無監督的地震數據隨機噪聲壓制。羅仁澤等[26]改進了U-Net網絡,在訓練過程中進行深度加權,進一步提取深層信息; Zhang等[27]結合卷積神經網絡、殘差網絡和批量歸一化,提出基于殘差學習的卷積去噪網絡(Residual Learning of Deep CNN for Image Denoising,Dn-CNN),在圖像處理領域得到廣泛應用。同時,Zhang等[27]還提出了DnCNN的變體DnCNN-B以處理不同分布的未知噪聲,該方法通過對訓練集添加不同分布的隨機噪聲,使訓練集的噪聲分布覆蓋測試集,以此達到盲去噪的目的。但模型的泛化能力較低,在高噪聲分布下會導致圖像過平滑的現象和細節信息的丟失。韓衛雪等[30]借鑒DnCNN網絡結構提出的地震數據去噪方法,效果優于傳統地震數據去噪方法。由于DnCNN出色的去噪性能,很多學者將其應用于地震數據的隨機噪聲壓制任務。Wang等[31]將DnCNN模型應用于地震數據噪聲壓制,取得了較好的效果。Yu等[32]和Zhao等[33]系統介紹了DnCNN算法用于地震數據噪聲壓制的過程并討論了CNN的超參數設置問題。Dong等[34]采用自適應的DnCNN算法對沙漠地震資料進行去噪處理,有效提高了信噪比。Yang等[35]擴展了原有的DnCNN模型,將激活函數替換為指數線性單元(Exponential Linear Units,ELU),增強了網絡的魯棒性。
基于生成對抗網絡的噪聲壓制方法包含一個生成網絡和一個判別網絡,采用博弈論的思想,用判別網絡指導生成網絡學習樣本的分布,在圖像處理領域得到了成功應用[36]。Radford等[37]在Yang等[35]基礎上加入卷積神經網絡,提出了深度卷積生成對抗網絡(Deep Convolutional Generative Adversarial Networks,DCGAN)。俞若水等[38]將DCGAN應用于工程勘探領域的瑞雷波勘探,實現了基于深度卷積生成對抗網絡的瑞雷波信號隨機噪聲去除,取得了較好的效果。
當前基于深度學習的噪聲壓制方法是通過多層卷積提取地震數據的主要特征,自適應地構建去噪模型,解決了傳統去噪方法中受有限的先驗知識影響而導致模型不準確、參數設置不確定性的問題。基于深度學習的網絡模型在測試集噪聲分布接近其訓練噪聲分布的情況下,能達到較好的去噪效果。但在樣本覆蓋不充分的情況下,往往缺少魯棒能力。受采集環境、地質條件等影響,地震數據之間存在的差異很大,樣本充分覆蓋在實際應用中存在很大的困難,導致去噪效率大幅降低。
在地震數據處理領域,魯棒的深度學習去噪研究比較鮮見。在圖像處理領域,盲噪聲壓制的方法有兩種思路:一種是不需要對噪聲進行估計,例如Mohan等[39]提出的無偏置卷積神經網絡(Bias-Free Convolutional Neural Networks,BF-CNN),通過刪除所有的加性常數(Additive Constants)提高網絡的泛化能力; 另一種是采用噪聲估計與噪聲去除相結合的思想,以提高模型的魯棒性。例如Zhang等[40]提出了一種快速靈活的去噪卷積神經網絡(Fast and Flexible Denoising Convolutional Neural Network,FFDNet)處理不同分布的噪聲,網絡的輸入包括兩部分:含噪圖像和一個可調的噪聲分布估計圖,提供了一種靈活的方式處理不同的噪聲分布,在噪聲分布估計圖近似真實噪聲時可以得到很好的去噪效果。然而,噪聲分布的估計值同樣受到先驗知識的限制,致使FFDNet在各種噪聲條件下也存在與DnCNN相似的問題。Guo等[41]借鑒了FFDNet網絡的優點,提出了卷積盲去噪網絡(Convolutional Blind Denoising Network,CBDNet),該方法設置了兩部分網絡:在第一部分對圖像噪聲分布進行估計,自適應地學習噪聲分布估計圖,避免了先驗知識對去噪效果的影響; 在第二部分采用U-Net網絡對含噪圖像進行去噪。該網絡有更好的魯棒性,但網絡模型較復雜,訓練效率較低。
本文借鑒CBDNet的思想,提出一種魯棒的深度學習地震數據去噪網絡,包含噪聲分布估計子網(Estimate Subnet,ES)和去噪子網(Denoising Subnet,DS)兩部分,分別實現地震數據中隨機噪聲分布的估計與去噪; 噪聲分布估計子網利用多層卷積神經網絡估計噪聲分布; 去噪子網中引入特征融合方法,將淺層與深層的地震數據特征信息融合,進一步增加地震數據特征提取的準確性,并且引入殘差學習策略,避免網絡結構較深導致梯度消失的現象; 整體網絡模型采用L1范數作為損失函數以提高魯棒性。
1 方法原理
1.1 噪聲壓制模型
深度學習訓練數據中的噪聲分布與測試地震數據中的噪聲分布越接近,訓練得到的模型在測試地震數據上的表現就越好。假設地震數據中噪聲為高斯隨機噪聲,含噪聲地震數據y可表示為
y=x+v
(1)
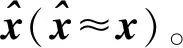
1.2 網絡結構設計
本文算法的網絡模型結構如圖1所示,包含兩部分子網,分別為噪聲分布估計子網和去噪子網。其中,噪聲分布估計子網分5層,每層由卷積(Convolution,Conv)和修正線性單元(Rectified Linear Unit,ReLU)組成,用來學習地震數據中隨機噪聲的分布。卷積操作用于提取噪聲分布特征,前4層和第5層卷積處理后分別得到64和1個特征映射。采用ReLU激活函數可以更好地逼近真實噪聲估計圖的分布。

圖1 網絡模型結構圖
去噪子網由兩個階段組成。其中,第一階段包括5層網絡,前4層分別由Conv和ReLU組成,每層卷積處理后得到64個特征映射。第5層僅由Conv組成,卷積操作后得到1個特征映射,即為深層的地震數據特征。然后,將第一階段輸出的深層特征與含噪地震數據特征融合后再傳入第二階段。特征融合采用向量拼接的方式,即將淺層與深層的地震數據特征進行拼接融合,增加地震數據特征提取的準確性。第二階段包括12層網絡,對應去噪子網的第6層至第17層。其中,第6層至第16層由Conv和ReLU組成,卷積處理后得到64個特征映射; 第17層由Conv組成,卷積操作后得到1個特征映射,即去噪后的地震數據。最后,將得到的去噪后地震數據與含噪地震數據相減,即可得到殘差學習的噪聲。
以上所有卷積操作前,均對待處理數據用0擴充邊界以確保輸入、輸出尺寸一致,且卷積核尺寸均為3×3。整個網絡模型中所有卷積操作步長均為1,并且未使用批量標準化(Batch Normalization,BN)層。
綜上所述,本文算法的去噪原理可以描述如下。
首先,輸入含噪地震數據y,經過噪聲分布估計子網后,輸出預測噪聲估計
(2)
式中:FES為噪聲估計子網的函數;θES為噪聲分布估計子網中參數的集合;wi為噪聲分布估計子網中第i層的權重參數;youti為i層的輸出;bi為i層的偏置參數;R為ReLU激活函數。
(3)
式中:FDS為去噪子網的函數;θDS為去噪子網中參數的集合;C為向量拼接操作;i=1,2,…, 15且i≠4。
本文網絡模型的主要特點概括如下。
(1)網絡模型由兩部分子網組成。通過噪聲分布估計子網學習噪聲估計,最大程度地避免了先驗知識的影響,進而通過去噪子網實現地震數據的去噪任務。
(2)聯合L1損失函數。為盡可能地增加網絡模型的魯棒性,本文算法采用了L1范數作為兩部分子網的損失函數,總的損失為兩部分子網聯合誤差。這有助于網絡模型整體的優化,減少網絡訓練時間,提高網絡的泛化能力,防止網絡模型過擬合。
(3)特征融合。隨著神經網絡層數的加深,深層的全局信息被提取,但是淺層局部信息較弱。本文模型在去噪子網中引入特征融合的思想,將深層的特征信息與淺層的特征信息融合,綜合考慮地震數據的高頻與低頻信息以提高地震數據去噪的魯棒性。
(4)殘差學習策略。由于本文算法的網絡結構較深,為了避免訓練過程中出現梯度消失的現象,引入殘差學習策略學習噪聲的特征。
2 去噪影響因素分析
采用理論分析和實驗驗證相結合的方法解析本文網絡模型去噪的原理。采用Marmousi模型數據進行去噪實驗,分析兩部分子網的網絡結構、聯合L1損失函數、特征融合以及殘差學習的作用。選用的數據為經過裁剪得到的10000個尺寸為300個采樣點、207道的原始不含噪數據x,將數據集按照80%、10%、10%的比例分別劃分為訓練集、驗證集和測試集。添加0均值正分布的高斯隨機噪聲仿真,噪聲標準差定義為
(4)
式中:M為切片時間采樣總數;N為切片地震道采樣總數;t為時間采樣序號;s為地震道記錄序號;u為地震數據的均值;l為噪聲強度的比例因子,訓練過程中l設置范圍為0.01~0.03。
去噪效果的衡量指標采用峰值信噪比(Peak Signal to Noise Ratio,PSNR)和信噪比(Signal Noise Ratio,SNR),以單個樣本為例,對應表達式為
(5)
(6)
2.1 子網結構的分析與驗證

另外,本文模型未采用BN層處理,原因是在標準化的過程中首先要計算一批(Batch)內所有數據的均值和方差,但地震數據包含不同分布的隨機噪聲,一個Batch內數據有明顯差別,訓練集中噪聲強度較高的地震數據將影響整個Batch內的均值和方差,從而影響后續的歸一化處理。不采用BN層的結構,可以在提高網絡的魯棒性的同時降低網絡模型復雜度。
為了充分證明兩部分子網的網絡結果對盲去噪任務的有效性,將本文模型中的噪聲分布估計子網除去,修改后的模型記為G1,并與本文模型對比實驗。
訓練過程分別迭代100次,PSNR的變化曲線如圖2所示。由圖可見,不含噪聲估計子網的PSNR曲線有多處波動,本文模型的PSNR曲線收斂相對更穩定。
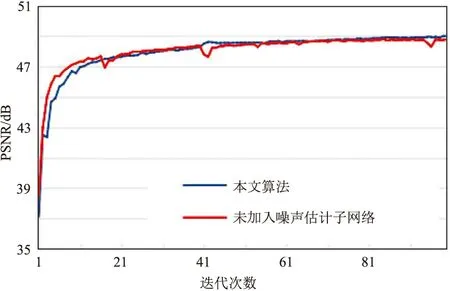
圖2 模型有無噪聲分布估計子網的PSNR對比
在測試集中,任意選取一個原始地震數據樣本(圖3a),加入l=0.08的高斯隨機噪聲后的地震數據如圖3b所示,由于噪聲較強,部分同相軸信息被覆蓋。圖3c是噪聲剖面,作為標準用來對比、評價不同模型的去噪效果。
圖3d為G1去噪結果,部分同相軸由于特征不明顯而被當作噪聲去除。圖3e有明顯的同相軸信息。圖3f為本文模型去噪結果,同相軸信息損失較少,原因在于訓練集的噪聲范圍沒有覆蓋到所有測試樣本,導致G1去噪魯棒性不理想。相比之下,本文算法首先利用噪聲估計子網估計出噪聲分布,然后再通過去噪子網進行噪聲壓制,將噪聲信息引入到網絡中,增強了網絡的泛化能力。圖3g進一步證明了本文算法可以在提高噪聲壓制效果的同時很好地保留了同相軸信息。
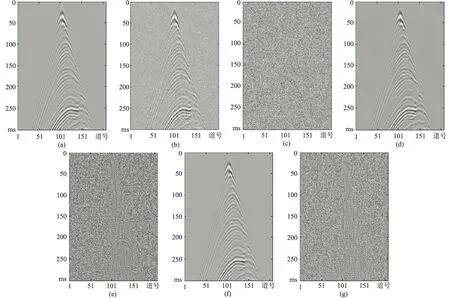
圖3 模型有無噪聲分布估計子網的去噪結果對比(a)原始地震數據; (b)加入l=0.08的高斯隨機噪聲的地震數據; (c)含噪地震數據的殘差剖面; (d)模型無噪聲估計子網的去噪結果; (e)模型無噪聲估計子網去噪后的殘差剖面; (f)本文模型的去噪結果; (g)本文模型去噪后的殘差剖面
2.2 聯合L1損失函數的分析與驗證
目前基于深度學習的去噪處理中,最常用的損失函數有最小均方誤差(Mean Squared Error,MSE)、L1范數、L2范數等。其中MSE是回歸損失函數中最常用的誤差,即
(7)
式中:obsi和predi分別為目標值和估計值;n為數據點數。L2范數又稱最小平方誤差,即
(8)
這兩個損失函數的優勢在于連續可微分且具有較為穩定的解。但當函數的輸出值與最小值之間差距較大時,使用梯度下降法求解會導致梯度爆炸; 另外,由于是平方運算,較大的誤差就會被過度放大,即對于較大的誤差給予過大的懲罰,使模型對離群點更加敏感,降低模型的魯棒性。
L1范數又稱平均絕對值誤差,是對目標值與預測值之差的絕對值求和再取均值,表示預測值的平均誤差幅度,其表達式為
(9)
L1有著穩定的梯度,不會導致梯度爆炸的問題; 另外,因為L1計算的誤差是目標值與預測值之差的絕對值,所以對于任意大小的差值,其懲罰相對穩定,對離群點不敏感,具有很好的魯棒性。因此本文模型選擇更具有魯棒性的L1范數作為本文算法的損失函數。
另外,本文算法采用聯合誤差的思想,將損失函數分為兩部分,噪聲分布估計子網的損失函數為
(10)

(11)
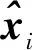
E=λ1EES+λ2EDS
(12)
式中λ1和λ2分別為噪聲估計子網損失和去噪子網損失的權衡超參數。
為證明L1損失函數更適用于地震數據去噪,將網絡模型中的損失函數替換為MSE,修改后的網絡模型記為G2,并與本文模型相對比。訓練過程中分別迭代100次,PSNR的變化曲線如圖4所示。由圖可見,訓練過程中G2模型的PSNR曲線出現劇烈波動且收斂時的值比本文算法小。測試樣本(圖3a和圖3b)G2去噪結果如圖5a所示,出現大面積的紋理模糊且部分同相軸消失。圖5b為圖5a與圖3a的殘差剖面,可以看到圖5a中消失的同相軸信息。
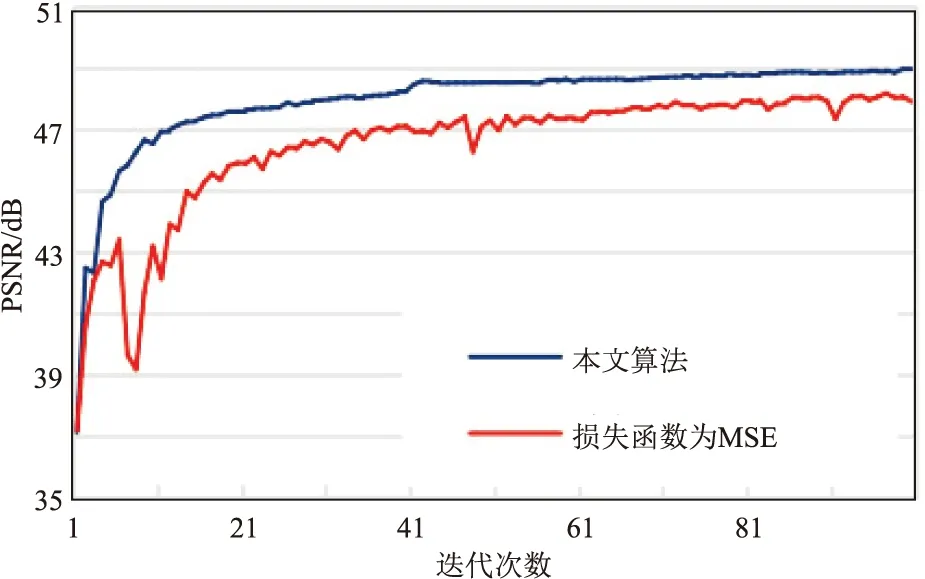
圖4 使用不同損失函數的PSNR對比

圖5 使用MSE為損失函數的去噪結果(a)和殘差剖面(b)
2.3 特征融合的作用
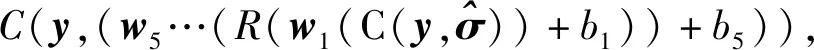
為證明特征融合在去噪中的作用,將本文模型中的特征融合階段除去,修改后的模型記為G3。迭代100次的PSNR變化曲線如圖6所示,G3的PSNR曲線出現兩次驟降、回升,原因在于網絡層數較深,在前向傳遞過程中極容易導致網絡的輸出與目標值之間的誤差增大,因此PSNR下降; 誤差的增大會觸發Adam算法自適應地調節學習率以更好地擬合目標值,隨著誤差的反向傳遞、學習率以及權重的更新,網絡的下一次前向傳遞后得到的輸出與目標值之間的誤差減小,因此PSNR出現回升。顯然無特征融合的的算法不容易收斂。G3去噪結果如圖7a所示,同相軸紋理也出現了消失或模糊的現象。圖7b為圖7a與圖3a的殘差剖面,依然存在被錯誤去除的同相軸信息。與圖3g對比,可以證明模型中引入特征融合對于地震數據盲去噪具有更好的噪聲壓制效果。

圖6 模型有、無特征融合的PSNR對比

圖7 模型無特征融合的去噪結果(a)和殘差剖面(b)
2.4 殘差學習的作用
為避免訓練過程中梯度消失,網絡中引入殘差學習策略,前向傳遞過程為
(13)
式中:yK為第K層的輸入,yk為第K-1層的輸出;F(yi,wi)表示殘差塊的輸出。反向傳播過程為
(14)
通過求偏導可以看出,即使網絡層數較深,也不會出現梯度消失的現象。
為了證明殘差學習對地震數據去噪的有效性,將本文模型中的殘差學習除去,修改后的模型記為G4。迭代100次的PSNR變化曲線如圖8所示,G4的PSNR曲線呈鋸齒形波動,不易收斂。G4去噪結果如圖9a所示,同相軸不連續且部分消失。圖9b為圖9a與圖3a的殘差剖面,可以看到少量的同相軸信息。與圖3g對比,可以證明模型中引入殘差學習對地震數據盲去噪的有效性。

圖9 模型無殘差學習的去噪結果(a)和殘差剖面(b)
3 Marmousi模型數據實驗
本文實驗用的Marmousi模型數據為經過裁剪得到的10000個切片數據,每個切片數據包含207道,每道包含300個采樣點。將數據集按照80%、10%、10%的比例分別劃分為訓練集、驗證集和測試集。訓練過程中l設置為0.02~0.05,即對于每個Epoch中的每一批數據,分別加入l為0.02~0.05的噪聲來訓練,學習率初始設定為0.001,使用Adam優化算法,Epoch設置為100次,批大小為20,網絡的輸入、輸出尺寸均為300×207。實驗硬件平臺采用Intel I7 8核CPU,內存為32G,GPU為GeForce RTX2080 Super。操作系統為 64位Ubuntu 18.04 LTS,軟件平臺采用Python 3.6環境,深度學習框架使用Pytorch1.2搭建,該環境下訓練時長約42h。為驗證本文模型的去噪效果,將本文算法與BM3D、DnCNN-B和BF-CNN等進行對比實驗。
3.1 相同強度隨機噪聲下不同去噪算法對比
任選一個測試集地震數據樣本如圖10a所示,圖10b為加入l=0.1的高斯隨機噪聲后的地震數據,其中紅色矩形區域中的地震數據信息被噪聲淹沒。圖10c為含噪地震數據的殘差剖面,將其作為各種算法去噪后殘差剖面的評判依據。

圖10 測試數據樣本(a)原始地震數據; (b)加入l=0.1的高斯隨機噪聲后的地震數據; (c)含噪地震數據的殘差剖面
圖11a為BM3D去噪的結果和殘差剖面,該方法聯合空域與變換域算法,可以看出,矩形區域中大部分噪聲得到壓制,但噪聲被壓制的同時,同相軸信息也被去除,存在同相軸信息丟失的現象。圖11b為DnCNN-B去噪的結果和殘差剖面,該方法通過訓練集噪聲覆蓋測試集噪聲進行盲去噪,但由于本實驗中訓練集噪聲的l設置為0.02~0.05,而測試集中噪聲的l設置為0.06,導致去噪效果下降,矩形區域中的同相軸信息丟失。圖11c為BF-CNN去噪的結果和殘差剖面,該方法不改變網絡結構,在DnCNN的基礎上通過刪除卷積層和BN層的加性常數提高噪聲壓制的魯棒性。可以看出,矩形區域去噪效果得到明顯改善,但由于未引入噪聲估計子網、損失函數,仍采用MSE以及沒有特征融合策略等,導致部分同相軸信息被去除,殘差剖面中仍然存在著被錯誤去除的同相軸信息。圖11d為本文算法去噪的結果和殘差剖面,本文算法先估計出噪聲的強度,進而自適應地對噪聲進行壓制。可以看出,與其他方法相比,矩形區域的地震數據細節保護得更好,同相軸紋理也更加清晰。殘差剖面中含有很少的有效信號,更逼近隨機噪聲。上述方法去噪后的PSNR和SNR的對比結果(表1)進一步證明了本文算法去噪效果的優勢。

圖11 不同算法對圖10a的去噪結果(左)和殘差剖面(右)對比(a)BM3D; (b)DnCNN-B; (c)BF-CNN; (d)本文算法
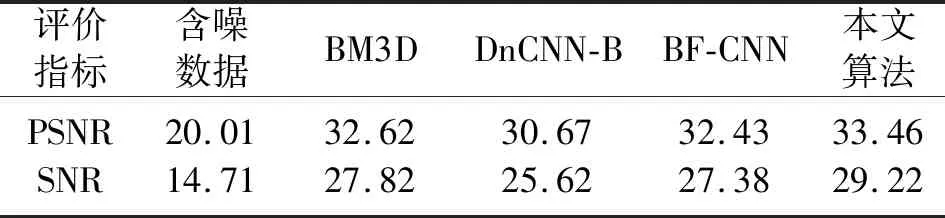
表1 不同算法去噪后PSNR、SNR對比 dB
3.2 不同強度隨機噪聲下不同去噪算法對比
對于不同強度的隨機噪聲(l為0.01~0.90),不同算法去噪后的SNR如表2所示。可以看出,噪聲強度較小時(l為0.01~0.07),各種去噪算法都表現出了良好的去噪性能。隨著噪聲強度的增加,本文算法表現出了更高的PSNR值。噪聲強度較大時(l為0.10~0.90),本文算法仍然具有很好的去噪效果。當l大于0.05時, DnCNN-B方法效果最差,原因在于DnCNN-B的訓練集噪聲強度沒有覆蓋較強的噪聲范圍,并且模型的設計未考慮魯棒性。相比之下,本文算法的去噪效果明顯優于其他算法,原因在于通過噪聲分布估計與噪聲壓制兩部分子網,提高了模型的魯棒性,對不同強度噪聲具有較好的泛化能力,即使在有限的噪聲分布樣本內訓練,也可以在未覆蓋的測試樣本范圍獲得較好的去噪效果。

表2 不同算法對含有不同強度高斯隨機噪聲地震數據的去噪前、后SNR對比 dB
4 實際地震數據實驗
實際地震數據的噪聲較合成數據更復雜。為驗證本文模型的去噪效果,利用兩組數據進行實驗。第一組為經過噪聲壓制預處理作為標簽的實際數據,用來訓練網絡模型; 第二組為無標簽的含噪實際數據,用來測試本文算法對實際地震數據的魯棒性和去噪效果。
第一組為經過噪聲壓制預處理的14000個實際數據樣本,每個樣本包含300道,每道包含200個采樣點,其中訓練集包括11200個樣本,驗證集包含2800個樣本。因為實際數據中噪聲復雜且分布未知,所以訓練樣本不再加入高斯噪聲進行仿真,而是采用現有的去噪算法預處理后得到的噪聲殘差作為訓練樣本的噪聲。具體的實現流程如圖12所示。訓練過程中學習率初始設定為0.001,采用Adam算法優化學習目標,Epoch設置為100次,批量大小設置為20,訓練時長約66h。

圖12 訓練樣本流程
任選第100次迭代中的一個訓練樣本,如圖13所示。由圖可以看出,噪聲基本得到壓制。圖13e為第100次迭代訓練去噪后的殘差剖面,視覺上與經過噪聲壓制預處理后的殘差剖面(圖13c)基本一致,因此本文模型對復雜的未知分布的實際噪聲也有很好的壓制效果。
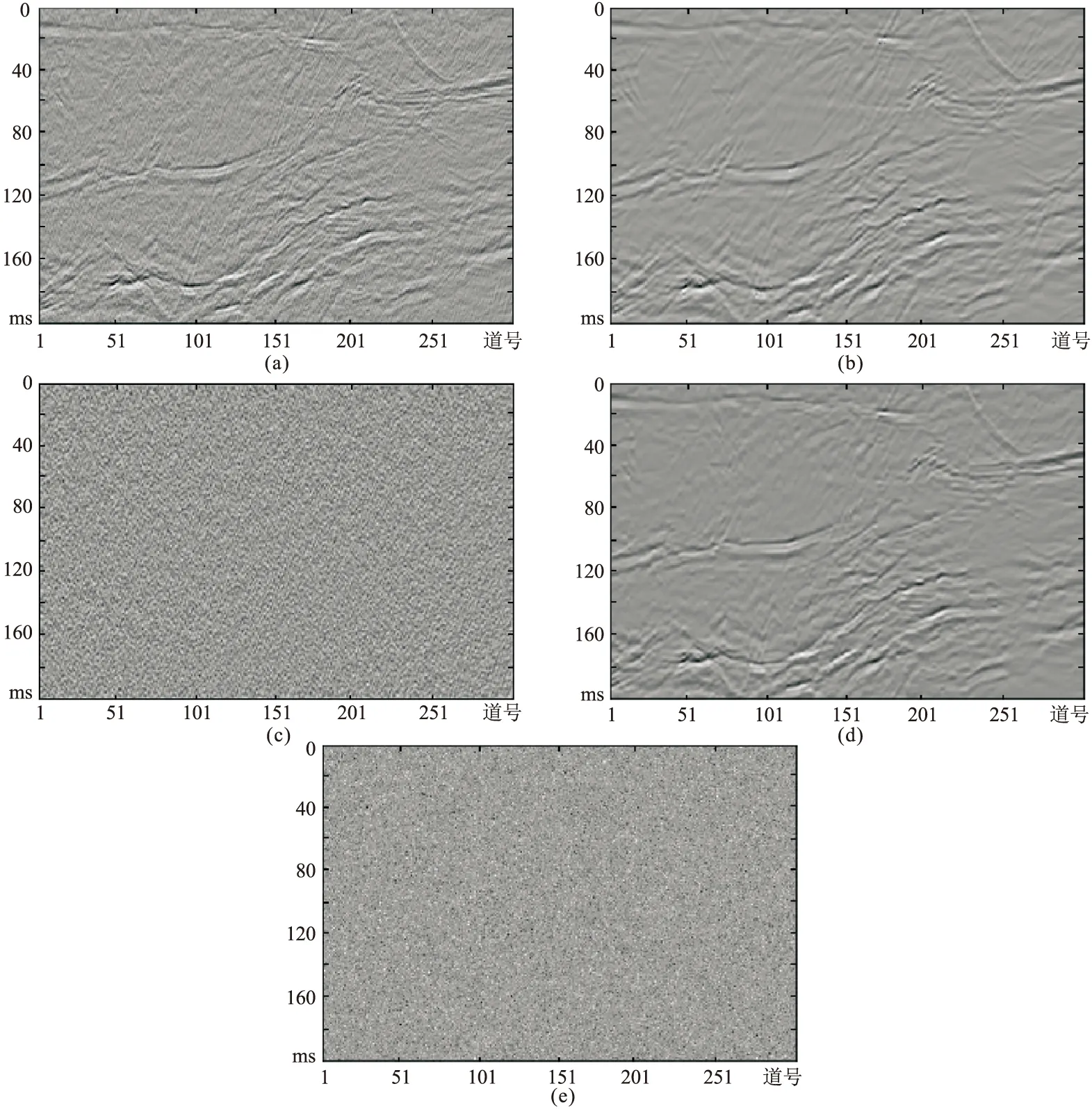
圖13 任意樣本第100次迭代訓練的效果(a)原始含噪地震數據; (b)經過噪聲壓制預處理后的地震數據; (c)噪聲壓制預處理后的殘差剖面;(d)第100次迭代訓練的去噪結果; (e)第100次迭代訓練去噪后的殘差剖面
第二組為1400個原始實際數據樣本,每個樣本包含300道,每道包含200個采樣點。任取其中一個樣本如圖14a所示,其中,紅色矩形Ⅰ、Ⅱ區域中的同相軸不清晰且連續性較差,紅色矩形Ⅲ區域中的地震信號受噪聲干擾嚴重,特征不明顯,很難辨識出有效信息。圖14b為經過BM3D去噪后的結果和殘差剖面,可見Ⅰ區域中同相軸信息得到了較好地恢復且噪聲基本被壓制,但Ⅱ、Ⅲ區域中紋理過于平滑,殘差剖面中有丟失的細節信息。圖14c為DnCNN-B模型去噪后的結果和殘差剖面,由于實際含噪數據噪聲復雜,DnCNN-B模型泛化能力較低,噪聲不能被有效去除。其中,Ⅰ區域中噪聲壓制不充分、對應殘差剖面中提取的噪聲信息較弱,Ⅱ、Ⅲ區域中噪聲基本被壓制,但出現紋理特征過平滑的現象。圖14d為BF-CNN模型去噪后的結果和殘差剖面,可見模型泛化能力較DnCNN-B有所提高,但Ⅰ、Ⅲ區域中同相軸過平滑,仍存在少量噪聲未被壓制。Ⅱ、Ⅲ區域中部分細節信息丟失,殘差剖面中仍存在著部分橫向的同相軸信息。14e為本文模型去噪后的結果和殘差剖面,可見Ⅰ區域中噪聲得到了很好地抑制,保留了清晰且連續的同相軸信息,Ⅱ、Ⅲ區域中將噪聲壓制的同時很好地保留了地震數據細節信息,殘差剖面中的有效信息較弱。與以上同類算法相比,本文方法在視覺方面最好。

圖14 原始實際數據不同方法噪聲壓制(左)及殘差(右)剖面對比(a)原始疊后地震數據; (b)BM3D; (c)DnCNN-B; (d)BF-CNN; (e)本文算法
第二組數據的不同算法去噪的運行時間(每個樣本的平均去噪時間)如表3所示,可以說明不同算法的去噪效率。BM3D算法包括基礎估計和最終估計,且每種估計又包括相似塊分組、協同濾波和聚合,所以耗時相對較長。基于深度學習的去噪方法,在測試過程中不需要迭代學習,因此耗時更短。本文模型采用噪聲估計與去噪相結合的思想,引入特征融合策略等方法,使模型的設計更為復雜,去噪時間較DnCNN-和BF-CNN多約0.03s。因此,本文算法可以在不增加過多計算量的同時,改進了噪聲壓制的效果,具有較高的去噪效率。

表3 不同算法去噪的運行時間對比
5 結束語
本文提出了一種魯棒的基于深度學習的地震數據去噪模型,為避免先驗知識的影響,采用噪聲分布估計與噪聲壓制相結合的思想將模型分成兩部分,噪聲分布估計子網利用多層卷積神經網絡估計噪聲分布; 去噪子網將噪聲分布與含噪地震數據一同作為輸入進行去噪處理,提高了地震數據噪聲特征的提取能力; 引入特征融合策略,將淺層與深層的地震數據特征信息融合,改善噪聲去除的效果; 為避免梯度消失,模型引入殘差學習策略提取噪聲特征; 網絡模型整體利用更具有魯棒性的L1范數作為兩部分子網的損失函數,增加了網絡模型的泛化能力。與同類算法相比,本文去噪模型可獲得更高的信噪比,且網絡模型的魯棒性更強。因此,該模型可有效地對地震數據進行去噪處理,同時也為其他方面的地震數據處理提供了參考。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
