基于詞典分類器的細粒度機構(gòu)名識別
2022-02-15 07:14:48王路路吐爾根依布拉音姜麗婷艾山吾買爾
計算機工程與設計 2022年1期
李 磊,王路路,吐爾根·依布拉音,姜麗婷,艾山·吾買爾
(新疆大學 信息科學與工程學院,新疆 烏魯木齊 830046)
0 引 言
命名實體識別的主要方法有兩種:基于統(tǒng)計的方法和深度學習方法。統(tǒng)計學方法依賴于特征的選取,對于語料庫的依賴性較大,建立領域語料庫又是一大難點[1]。而深度學習方法不需要特征工程,適用性強,因此,目前大多數(shù)采用深度學習方法實現(xiàn)命名實體識別。
隨著深度學習的不斷發(fā)展,基于神經(jīng)網(wǎng)絡的命名實體識別已在新聞領域呈現(xiàn)了很好的性能。但現(xiàn)有的命名實體識別數(shù)據(jù)集大多數(shù)只有3種實體類型,為了更好理解數(shù)據(jù),研究者們提出了針對開放領域的細粒度命名實體識別。如盛劍等[2]采用LSTM-CNN-CRF完成中文細粒度命名實體識別,其F1值為0.8左右;Xu, Liang等[3]采用RoBERTa-wwm-large[4]模型對CLUENER20 20數(shù)據(jù)集實現(xiàn)細粒度命名實體識別,其F1值為0.8042。
在開放領域下人名、機構(gòu)名、地名的研究十分必要,其中機構(gòu)名所占比重較高,但由于機構(gòu)名結(jié)構(gòu)復雜、罕見詞多且存在別名、縮略詞(如“哈佛”與“哈佛大學”)、數(shù)據(jù)文本中存在英文實體等問題,因此識別精度不高,而且細粒度機構(gòu)名識別在關(guān)系抽取、機器翻譯等應用發(fā)揮重要作用。基于以上問題,本文提出了分階段細粒度機構(gòu)名識別的思想,首先采用Bert-BiLSTM-CRF模型對MSRA微軟亞洲研究院開源數(shù)據(jù)集[5]進行粗粒度機構(gòu)名識別;其次,建立機構(gòu)名細粒度實體詞典,采用最優(yōu)深度學習分類器Bert-CNN訓練機構(gòu)名分類器;最后使用機構(gòu)名分類器對識別出的粗粒度機構(gòu)名進行細粒度分類。實驗結(jié)果表明,細粒度命名實體識別的F1值達到0.8117,相較于詞典匹配方法,分階段實現(xiàn)細粒度命名實體識別是有效的。
1 相關(guān)研究
實體識別可以看作一種文本序列化標注問題,在標注語料上進行監(jiān)督學習。而深度神經(jīng)網(wǎng)絡能夠挖掘文本潛在的抽象信息,有助于提高實體識別的性能[6]。目前,中文命名實體識別的公開數(shù)據(jù)集有Boson數(shù)據(jù)集[7]、1998年人民日報標注數(shù)據(jù)集和MSRA微軟亞洲研究院開源數(shù)據(jù)集[5]。英文公開的細粒度命名實體識別的數(shù)據(jù)集有ACE、FIGER、HYENA、OntoNotes、TypeNet、UFET等,而公開的中文數(shù)據(jù)集僅有CLUENER[3]和CFET[8]。
早期的命名實體識別主要是基于規(guī)則的方法,主要依靠大量人工標注的規(guī)則,但是由于各種語言的結(jié)構(gòu)不同,難以制定一套統(tǒng)一的使用規(guī)則。針對不同的領域,專家要書寫不同的規(guī)則,存在代價很大,制定規(guī)則周期較長等問題[9]。傳統(tǒng)的命名實體識別主要是基于統(tǒng)計的方法[2],例如支持向量機(SVM)[10]、隱馬爾可夫模型(HMM)[11]、條件隨機場(CRF)[12]等。條件隨機場在分詞和命名實體識別任務上效果較優(yōu),其標注框架特征靈活,全局最優(yōu);缺點在于收斂時間和訓練時間較長[2];支持向量機的準確度較高,但是隱馬爾可夫的訓練速度更快。綜上所述,統(tǒng)計學方法依賴于特征的選取,而且對于語料庫的依賴性較大,但是建立領域語料庫又是一大難點[2]。而深度學習方法不需要規(guī)則且靈活度高,因此,現(xiàn)在研究者大多采用深度學習的方法,該類方法也是現(xiàn)在命名實體識別的主流方法,它以端到端的方法從原始輸入中自動獲取識別和分類實體所需的表示[9]。主要有CNN、RNN、Bert等神經(jīng)網(wǎng)絡模型。
目前,基于英文數(shù)據(jù)集的細粒度命名實體識別主要有以下幾個方法:①傳統(tǒng)方法,Xiao Ling提出細粒度命名實體識別[13],該文使用112個標簽和一個線性分類器進行多標簽分類。這是細粒度命名實體識別的開端。Yosef等[14]提出使用多個二分類SVM進行實體識別,共有505個標簽。②計算相關(guān)性方法,為了平衡細粒度標簽之間的關(guān)系,Yogatama等[15]提出將輸入的文本信息和標簽信息全部映射到低維空間,可以用標簽在低維空間的距離來衡量它們之間的關(guān)系,相關(guān)性越高,距離越近。③神經(jīng)網(wǎng)絡方法,Shimaoka等[16]提出了基于注意力機制的神經(jīng)網(wǎng)絡模型,該模型使用LSTM對實體上文編碼,然后對實體的上下文采用注意力機制,充分提取輸入句子的語義信息。Dogan等[17]提出用預訓練模型ELMo和知識庫Wikipedia實現(xiàn)實體識別。
在中文細粒度命名實體識別研究上,盛劍等[2]定義了12個領域下的46個細粒度標簽,采用LSTM-CRF-CNN實現(xiàn)命名實體識別,然后對數(shù)據(jù)進行細粒度分類,開啟了中文細粒度命名實體識別的研究,其中CNN有助于識別實體的邊界,該方法采用靜態(tài)的詞向量和單向的LSTM,有一定的改進空間。Liang等[3]公開了中文數(shù)據(jù)集CLUENER2020,其包含10類細粒度標簽,并采用RoBERTa-wwm-large預訓練模型實現(xiàn)中文命名實體識別。
2 細粒度機構(gòu)名識別研究
因傳統(tǒng)領域細粒度命名實體識別語料匱乏,本文提出基于實體詞典分類器的細粒度機構(gòu)名識別,該方法主要分為兩個模塊:粗粒度機構(gòu)名識別模塊、基于詞典的細粒度機構(gòu)名分類模塊。
2.1 任務定義
細粒度機構(gòu)名識別即給定文本,識別其中的機構(gòu)名并預測可能的細粒度標簽,見表1。

表1 細粒度機構(gòu)名識別示例
本文提出了分階段細粒度機構(gòu)名識別的方法。首先,基于中文百科構(gòu)建大規(guī)模的機構(gòu)名實體詞典,根據(jù)短文本分類的思想訓練機構(gòu)名分類器;對于待識別的文本,經(jīng)過粗粒度機構(gòu)名識別后,將識別的機構(gòu)名作為機構(gòu)名分類器的輸入,以預測機構(gòu)名的細粒度標簽。
2.2 詞典構(gòu)建
建立機構(gòu)名詞典,首先從百度百科中爬取大量的詞條,利用遠程監(jiān)督的方法篩選出詞條標簽中有標志性詞,如“組織機構(gòu)”、“俱樂部”、“協(xié)會”、“公司”的詞條。
將篩選出的詞條按照其語義特征,例如“某某公司”、“某某醫(yī)院”、“某某學校”等,或者詞條標簽的內(nèi)容,例如“公司”、“政黨”等分配細粒度標簽。
然而,在具體實現(xiàn)階段,發(fā)現(xiàn)標注數(shù)據(jù)有許多錯誤:①詞條標簽中存在誤導性標簽,例如“巢湖風景名勝區(qū)”、“中華侏羅紀公園”等詞條的標簽中都有組織機構(gòu),但是顯然這些實體不是機構(gòu)名;②存在語義歧義詞,如“5國集團”、“二十國集團”等顯然不是公司,而是國際組織;③存在許多英文實體,如“NBC”、“tvb”等無法使用語義信息,針對這些問題,根據(jù)詞條標簽、詞條摘要和語義對每個實體進行二次人工標注。
2.3 粗粒度機構(gòu)名識別
粗粒度機構(gòu)名識別通常被看作是序列標注問題,輸入句子X=(x1,x2,…xi,…,xn), 其中xi表示i個字符。輸出為標簽序列y=(y1,y2,…,yi,…,yn), 其中yi∈{B,I,O} 是xi的標簽, B,I,O分別表示機構(gòu)名的首字,機構(gòu)名的其它字和其它。本文提出利用Bert實現(xiàn)特征提取,結(jié)合BiLSTM和條件隨機場(CRF)混合的機構(gòu)名識別算法。模型如圖1所示。
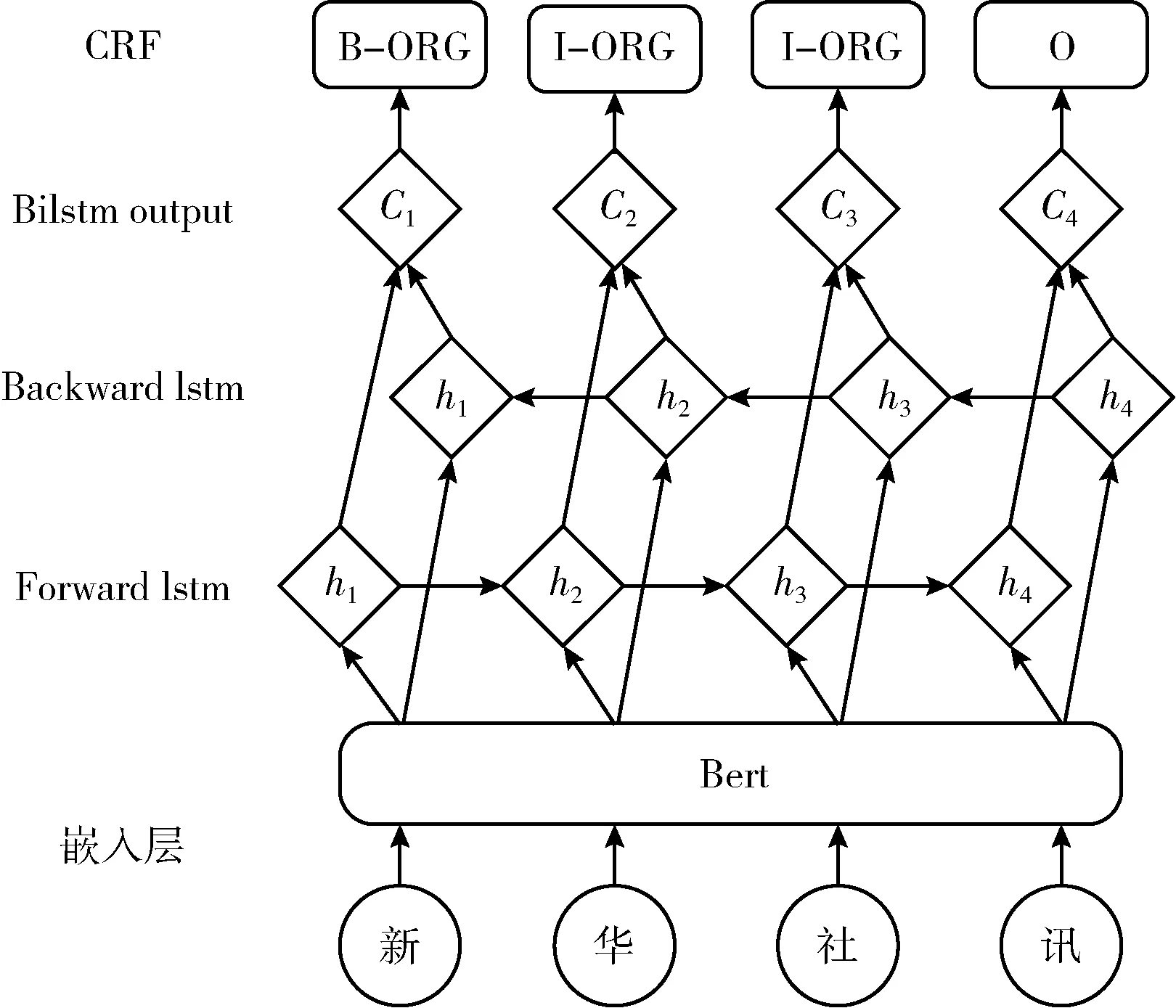
圖1 Bert-BiLSTM-CRF基本結(jié)構(gòu)
首先,將輸入轉(zhuǎn)換成向量形式,輸入到BiLSTM[18]中。詞向量的表示方式有one-hot、word2vec[19]等,但是one-hot將詞之間的關(guān)系視為獨立,導致向量稀疏問題。Word2vec雖然解決了這一問題,但是其窗口大小有限,且是靜態(tài),無法體現(xiàn)詞的復雜特性。Bert[20]采用雙向的Transformer結(jié)構(gòu),而Transformer模型的核心是注意力機制[21],可以學習輸入序列的上下文信息、提取字級、詞級和句子級特征,因此,本文考慮Bert提取詞向量。
然后,將Bert產(chǎn)生的向量通過雙向LSTM[18]層。由于LSTM非常適合時序數(shù)據(jù)建模,如文本數(shù)據(jù),可以更好捕捉雙向的較長距離的依賴關(guān)系。但其無法編碼反向信息,例如,“這件衣服臟的不行,需要清洗。”這里“不行”是“臟”的修飾詞。因此,采用雙向LSTM可以捕捉輸入文本的雙向語義依賴關(guān)系。
最后,將雙向LSTM拼接的編碼信息輸入CRF[11,12],學習相鄰實體標簽之間的轉(zhuǎn)移規(guī)則,約束輸出的標簽,調(diào)整不符合規(guī)范的標簽序列。
在機構(gòu)名識別的訓練語料中,假設輸入為
X=(x1,x2,…,xi,…,xn)
(1)
對應標簽為
y=(y1,y2,…,yi,…,yn)
(2)
經(jīng)過CRF層后預測的可能標簽為
(3)
定義Pi∈R3為xi在 {B,I,O} 上的得分,則有
Pi=Wshi+bs
(4)
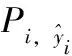
(5)
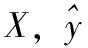
(6)
其中,Ys為輸入X所有可能的標簽序列集合。
(7)
2.4 基于詞典的機構(gòu)名分類器
已經(jīng)有實驗驗證Bert-CNN在文本分類方面取得很好的性能(https://github.com/649453932/Bert-Chinese-Text-Classification-Pytorch),本文將機構(gòu)名實體視為短文本,采用短文本分類的思想訓練機構(gòu)名分類器。首先利用Bert[20]充分提取輸入實體的字級、詞級和句級等特征,CNN[22]自動提取輸入的n-gram特征,實現(xiàn)最優(yōu)性能,而且由于實體分類屬于短文本分類范疇,本文的max_len僅為32,CNN在短文本分類上性能優(yōu)異,而LSTM[18]和DPCNN[23]主要在長文本上表現(xiàn)出優(yōu)異性能。因此,本文采用Bert-CNN,基本結(jié)構(gòu)如圖2所示。
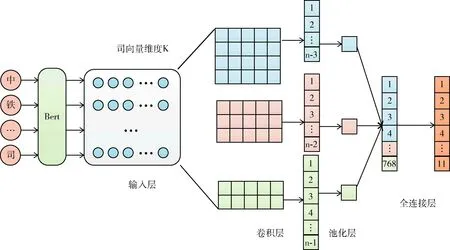
圖2 Bert-CNN的基本結(jié)構(gòu)
從圖2中可以看出,為了捕捉輸入真正意義的雙向關(guān)系,本文采用Bert將輸入的實體序列轉(zhuǎn)換成向量,并將其作為CNN的輸入。
CNN作為一個特征提取器,可以不斷提取輸入的特征,卷積操作和池化操作提取局部特征,全連接層可以提取整體特征。這樣使得較遠的輸入之間也可以建立語義上的聯(lián)系。使用大小分別為2×k, 3×k, 4×k的卷積核提取輸入的某個局部特征,目的是盡可能不遺漏有用信息。卷積后得到256×3個一維特征向量。
采用1-max-pooling將產(chǎn)生的一維特征向量轉(zhuǎn)化成一個值。對每個特征向量池化之后,將其結(jié)果拼接。拼接后的維度為768×1,將此特征向量通過激活函數(shù)為Linear的全連接層進行分類,最終輸出實體在11個細粒度類別標簽上的分數(shù)。為了防止過擬合,需要在池化層和全連接層之間加上dropout。
3 實 驗
上文詳細介紹了細粒度機構(gòu)名識別框架,主要分為兩個階段,分別是粗粒度機構(gòu)名識別和基于機構(gòu)名詞典的分類器。因此實驗首先對這兩個階段的效果分別進行評估,并對其性能進行討論分析,最后,驗證基于詞典分類器的細粒度機構(gòu)名識別的效果。
3.1 數(shù)據(jù)集
3.1.1 機構(gòu)名詞典
本文對傳統(tǒng)領域的機構(gòu)名進一步進行了細粒度劃分11種類別,分別是公司、教育科研機構(gòu)、政府組織、軍事組織、體育組織、社會團體、醫(yī)療機構(gòu)、國際組織、媒體機構(gòu)、政黨及其它。本文采用隨機將構(gòu)建的詞典分為訓練集、驗證集和測試集,實體數(shù)目見表2。

表2 細粒度實體詞典數(shù)目
3.1.2 粗粒度機構(gòu)名識別數(shù)據(jù)集
本文采用微軟的中文標注數(shù)據(jù)MSRA。其中,句子數(shù)目及所含機構(gòu)名實體數(shù)見表3。
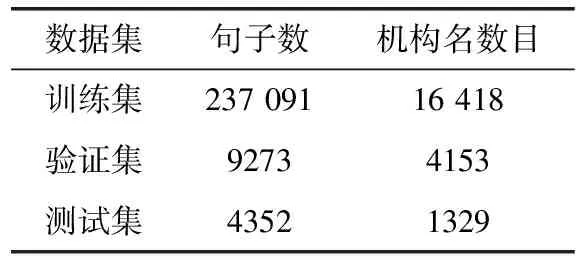
表3 數(shù)據(jù)集句子數(shù)目及組織實體數(shù)目
3.1.3 細粒度機構(gòu)名測試數(shù)據(jù)集
為了評估細粒度機構(gòu)名的識別效果,本文根據(jù)機構(gòu)名的細粒度標簽對MSRA微軟亞洲研究院開源數(shù)據(jù)集[5]的測試集進一步細粒度標注,以此作為整個方法的測試數(shù)據(jù)集。首先,利用詞典匹配的方法為現(xiàn)有的機構(gòu)名分配細粒度標簽,進一步人工校對,查看是否存在誤標、漏標現(xiàn)象,以確保數(shù)據(jù)集的可靠性。測試集中各細粒度機構(gòu)名的數(shù)目見表4。
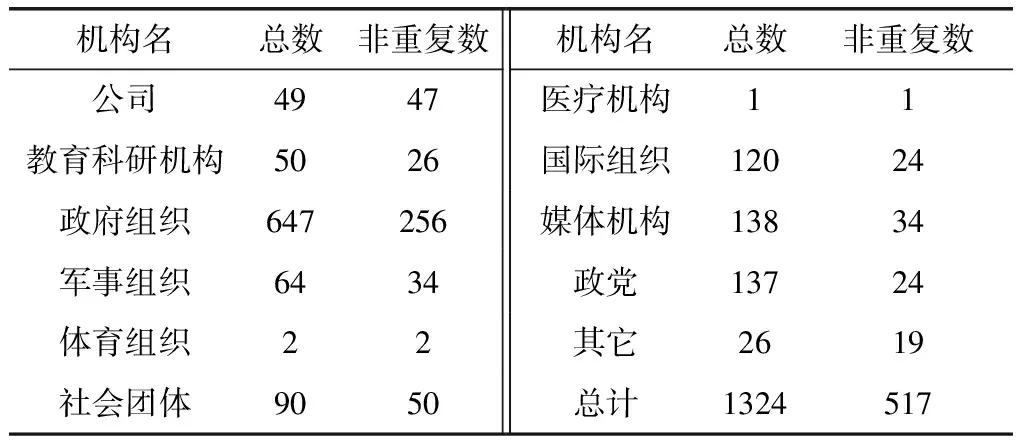
表4 測試集中各類別機構(gòu)名的數(shù)目
3.2 實驗結(jié)果
實驗的最終結(jié)果取決于分類器和粗粒度機構(gòu)名識別的效果,因此,需要對每個階段進行實驗。
3.2.1 粗粒度命名實體識別模型對比
為了驗證Bert-BiLSTM-CRF[25]在粗粒度機構(gòu)名識別的效果,選取若干模型與本文模型進行對比。
BiLSTM-CRF[12,18]:該模型是命名實體識別模塊經(jīng)典的方法之一。在輸入詞向量之后,BiLSTM獲取輸入序列的上下文表示,最后使用CRF層學習標簽之間的轉(zhuǎn)移規(guī)則。
Bert-CRF[12,20]:Bert具有廣泛的通用性且在文本數(shù)據(jù)上表現(xiàn)出優(yōu)異性能,因此,加入Bert驗證其在命名實體識別上的性能。
Bert-CNN-CRF[18,20,22]:CNN可以確定實體的邊界,因此,加入CNN以驗證其性能。
Bert-BiLSTM-CNN-CRF[22,25]:因CNN在句子建模方面效果突出,因此,將LSTM、CNN結(jié)合,驗證是否有更有效果。實驗結(jié)果見表5。

表5 命名實體識別模塊實驗結(jié)果
從表5中可知,Bert-BiLSTM-CRF在此數(shù)據(jù)集上的性能最好。總體來說,Bert和BiLSTM都會改進模型性能。但是若有Bert時,CNN的作用不大。
作為命名實體識別的經(jīng)典模型,BiLSTM-CRF在此數(shù)據(jù)集上的F1值為0.8451。引入預訓練Bert后,4種模型分別提高了0.0551、0.0555、0.0779、0.0651,這是因為Bert可以充分提取輸入各種維度的特征, 從而使提取的詞向量能夠更好地表征不同語境中的句法與語義信息,進而增強模型泛化能力,因此性能更加優(yōu)異。
與其它模型相比,Bert-BiLSTM-CRF的性能更好。Bert提取輸入的各維度特征,學習其語義相關(guān)性,提升了輸入的語義表示能力,BiLSTM對Bert產(chǎn)生的信息雙向編碼,通過記憶門、遺忘門,在一定程度上提升了有效信息的獲取。
CNN可以學習輸入的語義相關(guān)性,Bert也有這些作用。因為卷積核池化可能會丟失某些輸入的局部信息,因此,加入CNN效果不好。
本文模型可以正確識別以下類型的機構(gòu)名:①結(jié)構(gòu)復雜,如“美國中國商會”等;②縮略詞,如“聯(lián)大”等;③英文實體,如“abb”等。很大程度解決了機構(gòu)名識別存在的問題。
3.2.2 機構(gòu)名詞典模型對比
為了獲取CNN模型的最佳參數(shù),本文采用不同卷積核大小進行消融實驗,結(jié)果見表6。
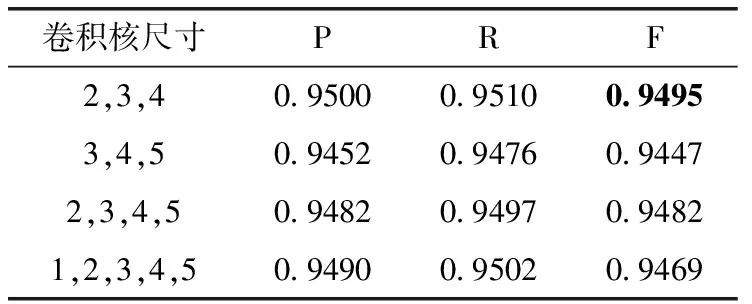
表6 模型的參數(shù)比較
從表6中可以看出,當卷積核大小為2、3、4時,模型效果最優(yōu)。因此,本文采用卷積核大小分別為2、3、4的卷積核對輸入進行特征提取。
為了驗證Bert-CNN[19,22]在基于機構(gòu)名詞典的分類器上的效果,本模塊分別用以下模型作為baseline進行比較。
CNN[22]:在文本分類任務上取得了很好的效果。以靜態(tài)的詞向量作為輸入,若干卷積核對輸入向量進行特征提取。
DPCNN[23]:與殘差網(wǎng)絡[24]相似,采用金字塔思想,以無監(jiān)督詞向量作為輸入,堆疊幾層卷積層和采樣層,形成尺度縮放的金字塔,達到維度縮放的目的。
Bert[20]:Bert在很多自然語言處理任務上表現(xiàn)出優(yōu)異的性能,包括文本分類任務。最終性能見表7。
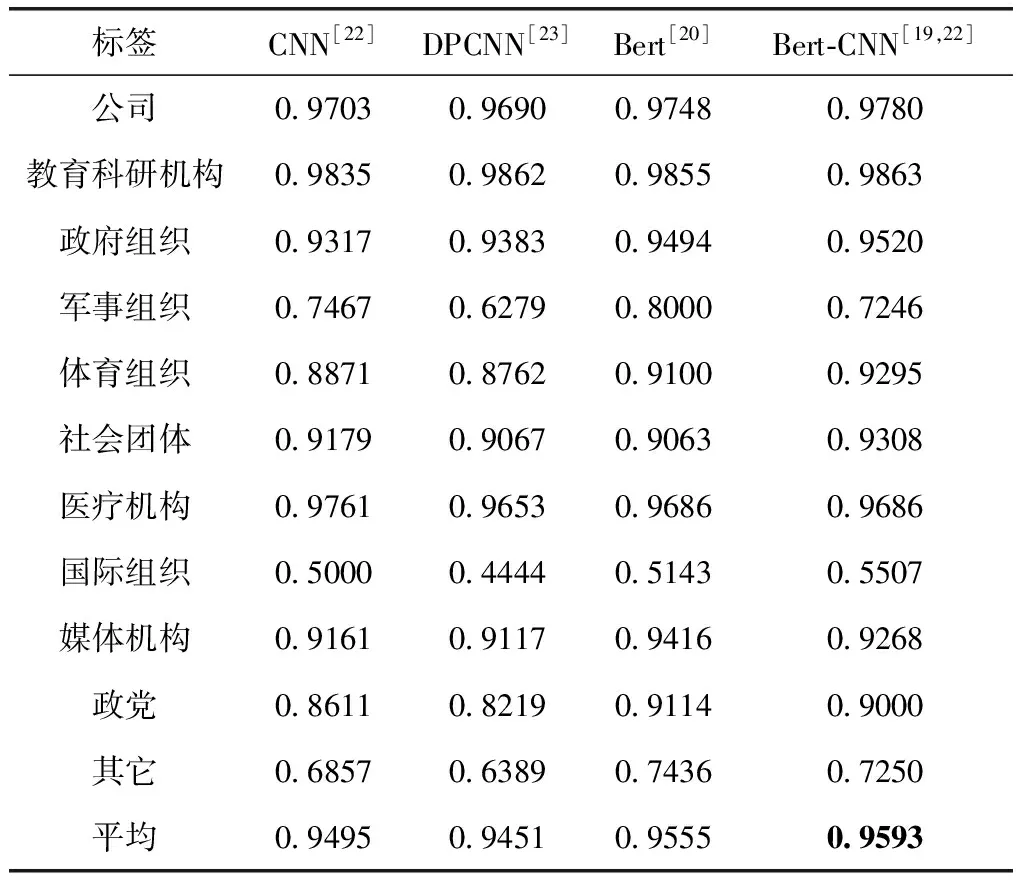
表7 分類器訓練模塊實驗結(jié)果(F1)
根據(jù)實驗結(jié)果,可以得出以下結(jié)論:
(1)模型的整體性能:DPCNN (2)分析每類機構(gòu)名的分類效果,軍事組織、國際組織和其它的效果均低于0.8,部分原因在于該類別的實體數(shù)目相對較少、實體名稱不規(guī)律(例如:國際組織“CABI”等,軍事組織“淮安獨立團”等),還出現(xiàn)英文實體如“Sun Microsystems”、“P.A.WORKS”等,難以學習語義并進行分析。 3.2.3 細粒度分類效果對比 為了評估細粒度機構(gòu)名識別的性能,本文提取測試集中粗粒度機構(gòu)名,通過詞典分類器為其分配對應的細粒度標簽。 為了對比,本文選用詞典匹配作為baseline。首先利用機構(gòu)名詞典對輸入文本實現(xiàn)雙向最大匹配,生成分詞文本。其次利用詞典對分詞文本生成預測標簽序列。細粒度機構(gòu)名識別的對比終結(jié)果見表8。 表8 細粒度分類模塊的實驗結(jié)果 實驗結(jié)果表明,相比于詞典匹配,分階段的機構(gòu)名識別效果更好,原因在于詞典匹配方法取決于詞典的覆蓋規(guī)模。相較于其它模型組合,當粗粒度命名實體識別模型為Bert-BiLSTM-CRF,分類器采用Bert-CNN訓練時,細粒度機構(gòu)名識別的性能最佳,F(xiàn)1值達到了0.8117,原因在于上游任務的準確率會影響下游任務,其次分類器也決定了細粒度標簽分類的性能。 相較于其它模型,Bert-BiLSTM-CRF中Bert采用雙向Transformer結(jié)構(gòu),Transformer的核心機制在于Multi-Head Attention,可以從不同于語義子空間捕獲文本語義特征、BiLSTM考慮文本的時序信息獲取文本的長距離依賴,CRF學習輸出標簽之間的規(guī)則并且約束BiLSTM輸出的語義信息。分類器最好的模型是Bert-CNN,相較于Word2vec模型,Bert可以生成動態(tài)的文本表示,能夠更加準確反映出詞匯在當前語義環(huán)境下的表示。CNN通過不同大小的卷積核可以有效學習Bert生成的語義表示,通過其最大池化層又規(guī)避了過擬合情況的發(fā)生,所以取得了最好的分類效果。 本文構(gòu)建了細粒度機構(gòu)名詞典,人工標注了不同領域的11類實體,共計38 575個,在此基礎上分階段完成細粒度機構(gòu)名的識別。本文解決了機構(gòu)名識別存在的問題,實驗對比了不同文本表示下各個命名實體識別和分類模型取得的實驗效果,為以后的進一步工作提供參考。在以后的工作中,我們將會把數(shù)據(jù)集擴展至人名、地名等傳統(tǒng)領域,并且考慮引入更先進的深度學習模型展開細粒度命名實體識別研究。
4 結(jié)束語
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
甘肅教育(2020年8期)2020-06-11 06:10:02
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
制造技術(shù)與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
光學精密工程(2016年6期)2016-11-07 09:07:19
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
核科學與工程(2015年4期)2015-09-26 11:59:03
