基于BPNN端到端時延預測的多路傳輸調度
2022-02-15 07:00:28蘇旭東衷璐潔
計算機工程與設計 2022年1期
蘇旭東,衷璐潔
(首都師范大學 信息工程學院,北京 100048)
0 引 言
MPTCP(MultiPath TCP)是一種基于多接口的傳輸控制協議,允許在多條鏈路同時傳輸數據,旨在提高吞吐量的同時更充分地利用網絡資源。在移動網絡環境下,帶寬、延遲、丟包率等網絡參數動態變化,終端的移動性會引發網絡鏈路間的頻繁切換,造成數據包不能按序到達接收端,引起數據包亂序問題。亂序數據包在接收端緩沖區滯留等待,嚴重時會導致接收端緩存阻塞,造成網絡延遲,降低網絡吞吐量。在該問題背景下,如何針對移動異構網絡特點,減少數據包亂序發生可能,實現高效移動多路傳輸調度具有重要意義。對此,本文提出一種基于BP神經網絡(back propagation neural network,BPNN)端到端(傳輸)時延預測的移動多路傳輸調度方法,綜合考慮鏈路丟包率、RTT、吞吐量等性能參數,通過BP神經網絡的訓練與學習,提取輸入性能參數與端到端時延間的有效規則,在更準確預測端到端時延的基礎上,對路徑擁塞狀況進行計算評估,并基于路徑綜合評估結果實施數據包調度,以使數據包盡可能按序到達接收端,進而有效避免緩沖區阻塞,實現負載均衡,提高多路傳輸網絡吞吐量。
1 相關工作
MPTCP數據調度:Ke等[1]利用自定義的排序算法對路徑狀態信息進行排序,之后基于排序結果實現數據包的傳輸。黃輝等[2]提出一種將RTT與丟包率相結合,運用綜合效用函數作為評估指標的數據調度機制。Luo等[3]提出一種基于強化學習DQN的數據調度算法,通過強化模型完成路徑的選擇判斷,并借助路徑獎懲值計算實現路徑選擇的更新。
基于端到端時延的調度:Xue等[4]通過計算在接收端不發生亂序的前提下應為每條路徑分配的數據包個數,為各路徑分配DSN連續的數據包。王振朝等[5]利用路徑帶寬、往返時延和擁塞窗口預測數據包到達時間,并以此為基礎完成數據包的分發。Dong等[6]根據子流是否丟包對端到端時延采用不同的計算方法進行估算。Froemmgen等[7]通過主動探測未使用的子流并根據傳統TCP時間戳選項得到的端到端時延來調度數據包。
數據包亂序減少:Han等[8]通過預測數據包到達時間,將數據包調度到最早到達時間的子流上,以保證數據包到達的順序。Shi等[9]選擇慢路徑發送序列號較大的數據包。Kim等[10]通過估算無序數據包數量及傳輸所需的緩沖區大小來減少數據包亂序的發生可能。Ling等[11]對路徑阻塞時延進行評估,選擇不易造成阻塞的子流集進行數據傳輸。
2 基于BP神經網絡端到端時延預測的多路傳輸調度
基于BP神經網絡端到端時延預測的多路傳輸調度(multipath scheduling based on BP neural network EET prediction,MSBPEET)通過綜合考慮丟包率、吞吐量、RTT等路徑性能參數,構建BP神經網絡對數據包在各路徑上的端到端時延實施預測,隨后選擇時延小且擁塞狀況良好的路徑進行傳輸,以使數據包在盡可能短的時間內按順序到達接收端。方法總體框架如圖1所示,包括:(Ⅰ)RTT預測;(Ⅱ)基于BP神經網絡的端到端時延預測;(Ⅲ)子流擁塞狀況評估;(Ⅳ)網絡狀態綜合評估及有效路徑集排序調度4個部分。其中:RTT預測部分將RTT及RTT高頻變化分別建模為常量信號和噪聲,然后結合卡爾曼濾波,對當前RTT測量值進行評估和糾正;基于BP神經網絡的端到端時延預測部分主要通過BP神經網絡的構建、訓練和學習完成對端到端時延的更準確預測;子流擁塞狀況評估部分主要完成對各個子流的擁塞狀況評估;網絡狀態綜合評估及有效路徑集排序調度部分主要負責在對路徑完成綜合評估后,選擇最優路徑進行數據包調度。
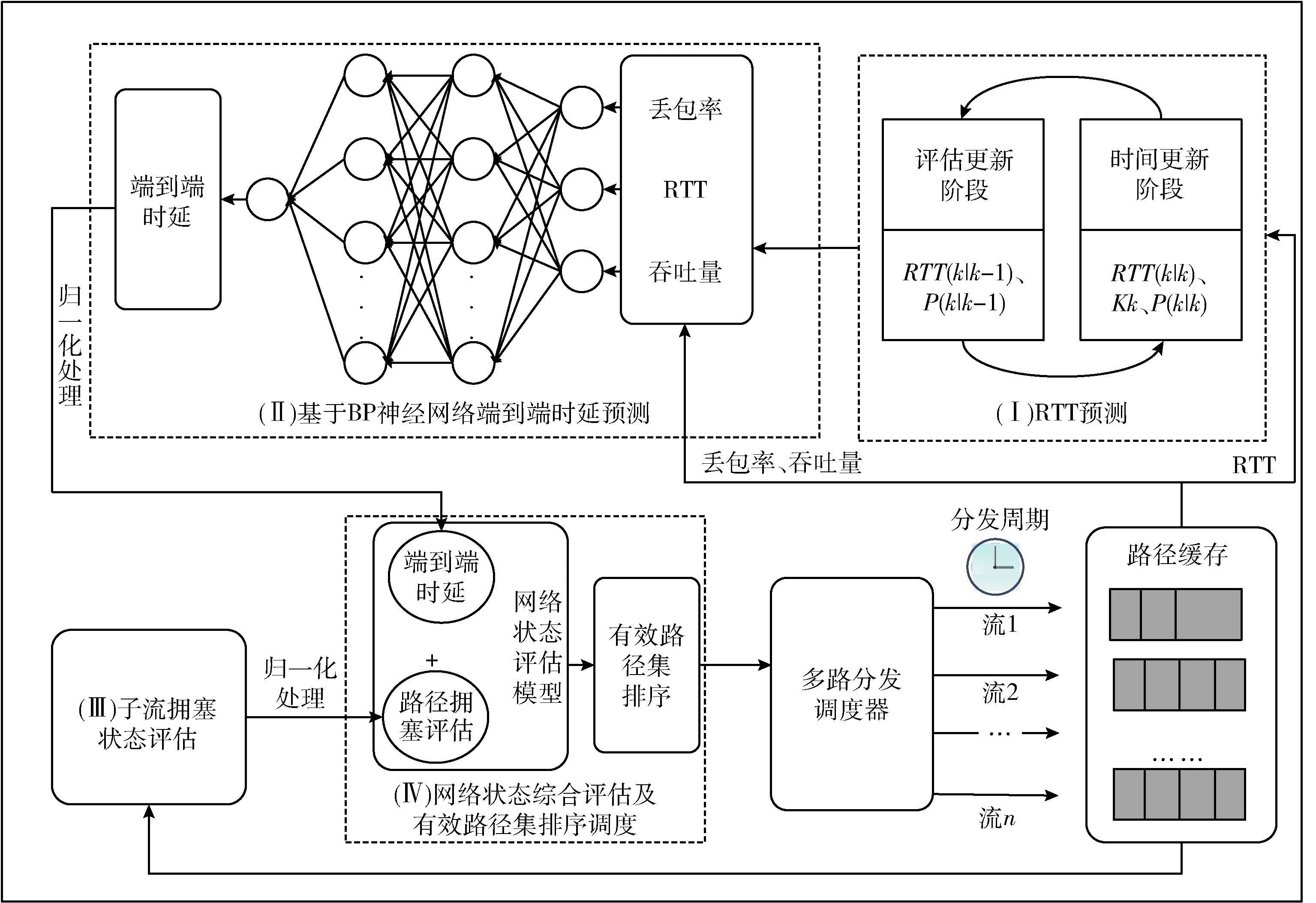
圖1 基于BP神經網絡端到端時延預測的多路傳輸調度
2.1 RTT預測
RTT是路徑質量評估的重要參數。在本文中,RTT作為BP神經網絡的輸入,其預測準確性將直接影響端到端時延預測的準確性。在路徑參數高度動態變化的移動無線網絡環境下,為進一步提高RTT預測的準確性,本文采用卡爾曼濾波方法,利用前一時刻的RTT與當前時刻RTT的測量值來更新對RTT的預測估計,進而獲得當前時刻RTT更準確的估計值。
首先將RTT及RTT高頻變化分別建模為常量信號及噪聲,如式(1)和式(2)所示
RTTk=RTTk-1+wk
(1)
RTT′k=RTTk+vk
(2)
其中,RTTk和RTTk-1分別表示當前時刻k和上一時刻k-1的RTT;wk表示過程噪聲,服從高斯分布;RTT′k表示當前時刻RTT的測量值;vk是測量噪聲,服從高斯分布。RTT卡爾曼濾波預測過程如下:
(1)初始化測量噪聲R、 過程噪聲Q和誤差協方差P;
(2)對任一MPTCP子流j,若子流j收到ACK或發生超時,獲取子流j當前時刻RTT測量值RTTk及上一時刻最優RTT估計值RTT(k-1|k-1)。 初次預測時,將子流j上一時刻的RTT測量值RTTk-1視作上一時刻的最優RTT估計值,然后轉步驟(3)~步驟(7)。
時間更新階段:
(3)計算當前時刻RTT的預測值,記作RTT(k|k-1), 如式(3)所示
RTT(k|k-1)=RTT(k-1|k-1)
(3)
(4)計算當前時刻誤差協方差的預測值,記作P(k|k-1), 如式(4)所示
P(k|k-1)=P(k-1|k-1)+Q
(4)
其中,P(k-1|k-1) 為上一時刻誤差估計協方差;Q為過程噪聲,服從高斯分布。
評估更新階段:
(5)根據當前時刻誤差估計協方差更新卡爾曼增益Kk, 如式(5)所示
Kk=P(k|k-1)(P(k|k-1)+R)-1
(5)
其中,R為測量噪聲,服從高斯分布。
(6)根據卡爾曼增益Kk和當前時刻RTT預測值RTT(k|k-1) 及當前時刻RTT測量值RTTk計算當前時刻最優RTT估計值,如式(6)所示
RTT(k|k)=RTT(k|k-1)+Kk(RTTk-RTT(k|k-1)
(6)
(7)根據當前時刻誤差估計協方差P(k|k-1) 和卡爾曼增益Kk更新誤差估計協方差P(k|k), 如式(7)所示
P(k|k)=(1-Kk)P(k|k-1)
(7)
(8)最終輸出經卡爾曼濾波處理后的RTT(k|k), 即為子流j當前時刻的最優RTT估計值,將其作為端到端時延預測BP神經網絡的輸入之一。
2.2 基于BP神經網絡的端到端時延預測
端到端時延預測的準確性對減少數據包亂序發生具有重要的指導意義。影響鏈路端到端時延的主要因素包括鏈路丟包率、吞吐量、RTT等,為實現端到端時延的更準確預測,本文提出構建服務于端到端時延預測的BP神經網絡模型,以RTT、丟包率、吞吐量等端到端時延特征參數為輸入,端到端時延為期望輸出,對設計的多層BP神經網絡實施訓練,使其通過訓練和學習,提高端到端時延預測的準確性。
基于BP神經網絡的端到端時延預測主要分為BP神經網絡端到端時延預測模型構建和端到端時延預測兩部分。其中模型構建部分主要負責構建基于BP神經網絡的端到端時延預測模型,通過實驗收集的數據樣本集對設計的多層BP神經網絡模型進行訓練,并實施優化,提高端到端時延預測的準確性。
模型構建部分主要由樣本數據獲取、BP神經網絡構建與訓練和訓練優化3個部分組成。圖2給出了這3個部分的組成示意。當應用層有數據傳輸需求時,端到端時延預測部分將在BP神經網絡端到端時延預測模型的基礎上,以鏈路丟包率、吞吐量、RTT等參數為輸入,獲得鏈路端到端時延的預測輸出。
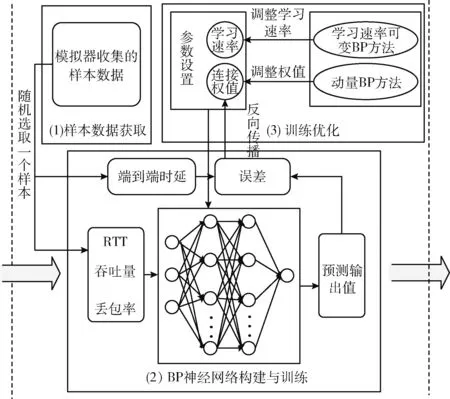
圖2 基于BP神經網絡的端到端時延預測模型
2.2.1 樣本數據獲取
(1)計算、獲取丟包率Loss、 吞吐量Th及RTT。 其中RTT由RTT預測部分獲取,丟包率Loss、 吞吐量Th的計算方法如式(8)和式(9)所示
(8)
(9)
其中,Cwndpre表示擁塞窗口收縮之前的值,Cwnd表示當前時刻的擁塞窗口值。
(2)計算端到端傳輸時延EET, 計算方法如式(10)所示[12]
EET=Tr-Ts-Te
(10)
在式(10)中,Tr表示接收端發送SACK的時間;Ts表示發送端發送數據包的時間;Te表示接收端從接收到數據包到發送SACK的間隔時間。
(3)對訓練數據和測試數據進行劃分。為避免過擬合問題,將經由(1)獲取到的樣本集劃分為訓練集和測試集,并設置訓練集占比85%,驗證集占比15%。考慮到不同維度間的樣本數據差距及同維度樣本數據間的相差范圍,在訓練前采用Min-max方法[13]對數據進行歸一化處理,將數據映射至區間[-1,1],以減少數據波動對神經網絡訓練時間及收斂效果的影響。
2.2.2 BP神經網絡構建與訓練
(1)設置權重、閾值、學習速率、訓練最大迭次數等相關參數。初始化權重和閾值在[-1,1]之間。對于學習速率,從較大學習速率開始訓練,然后逐漸減小速率,直至損失值不再發散。訓練最大迭代次數設置為50 000。在多次試算的基礎上,兼顧網絡穩定性及訓練時長考慮,具體參數設置見表1。

表1 參數設置
(2)輸入、輸出層神經元個數選擇。輸入層神經元分別為Th、RTT、Loss,輸出層神經元為EET。相應地,輸入層神經元個數I設為3,輸出層神經元個數J設為1。
(3)隱含層層數和節點數設置。通過獲取的樣本集,對設置不同隱含層數和節點數的BP神經網絡進行訓練測試,根據不同神經元個數訓練的均方誤差來確定隱含層層數和節點數。隱含層節點個數K參考式(11)及測試結果綜合選定
(11)
在式(11)中,J為輸出層節點個數,I為輸入層節點個數,a為1~10間的常數。
(4)隨機選取第m個輸入樣本及其對應的期望輸出,將輸入樣本作為正向傳播輸入,其中第m個輸入樣本如式(12)所示,其對應的期望輸出如式(13)所示
xi(m)=(Th(m),Loss(m),RTT(m))
(12)
H(m)=EET(m)
(13)
(5)判斷訓練樣本是否用盡,若否,轉步驟(6)~步驟(7);否則轉步驟(8)。
(6)前向計算各p隱含層及輸出層神經元的輸入和輸出。
1)輸入層神經元Th、RTT、Loss計算隱含層輸出值Dk(m), 計算方法如式(14)~式(16)所示,其中k表示隱含層節點;i表示輸入層節點;I為輸入層節點數;xi(m) 表示輸入層輸入;oi(m) 表示輸入層輸出;wik表示輸入層到隱含層的神經元權值;dk(m) 表示隱含層輸入;Bk表示輸入層到隱含層的閾值;f為輸入層和隱含層激活函數,為正切S形函數(tansig)
oi(m)=f(xi(m))
(14)
(15)
Dk(m)=f(dk(m))
(16)
2)將隱含層神經元的輸出值傳遞給輸出層
(17)
Y(m)=g(y(m))
(18)
在式(17)和式(18)中,k表示隱含層節點;K為隱含層節點數;wk表示隱含層到輸出層的神經元權值;B表示隱含層到輸出層的閾值;y(m) 為輸出層輸入;Y(m) 為輸出層輸出。g為輸出層激活函數,為線性函數。
(7)誤差反向傳播,調整連接權值和閾值。計算神經網絡輸出Y(m) 與期望值H(m) 之間的誤差,如式(19)所示
(19)
之后運用梯度下降法,通過反向傳播不斷調整各層神經元的權值和閾值,使誤差函數沿著負梯度方向下降,輸出值不斷接近實際值。
(8)計算網絡全局誤差,如式(20)所示
(20)
其中,M代表樣本數,H(m),Y(m) 分別代表第m個樣本的神經網絡輸出與期望值。
(9)判斷網絡全局誤差是否滿足要求,若滿足,預測過程結束;否則查看是否達到設定的迭代次數上限,若已達到,預測過程結束,否則轉步驟(4)~步驟(7)。
2.2.3 訓練優化
針對權值在學習過程中發生震蕩、收斂速度慢等問題,使用動量BP和學習速率可變的BP方法,不斷調整各層神經元的權值和閾值,以減小誤差,提高BP神經網絡的收斂速度。
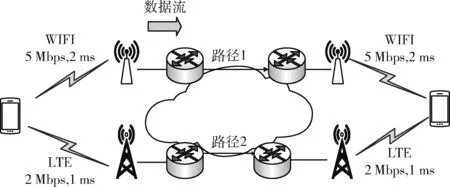
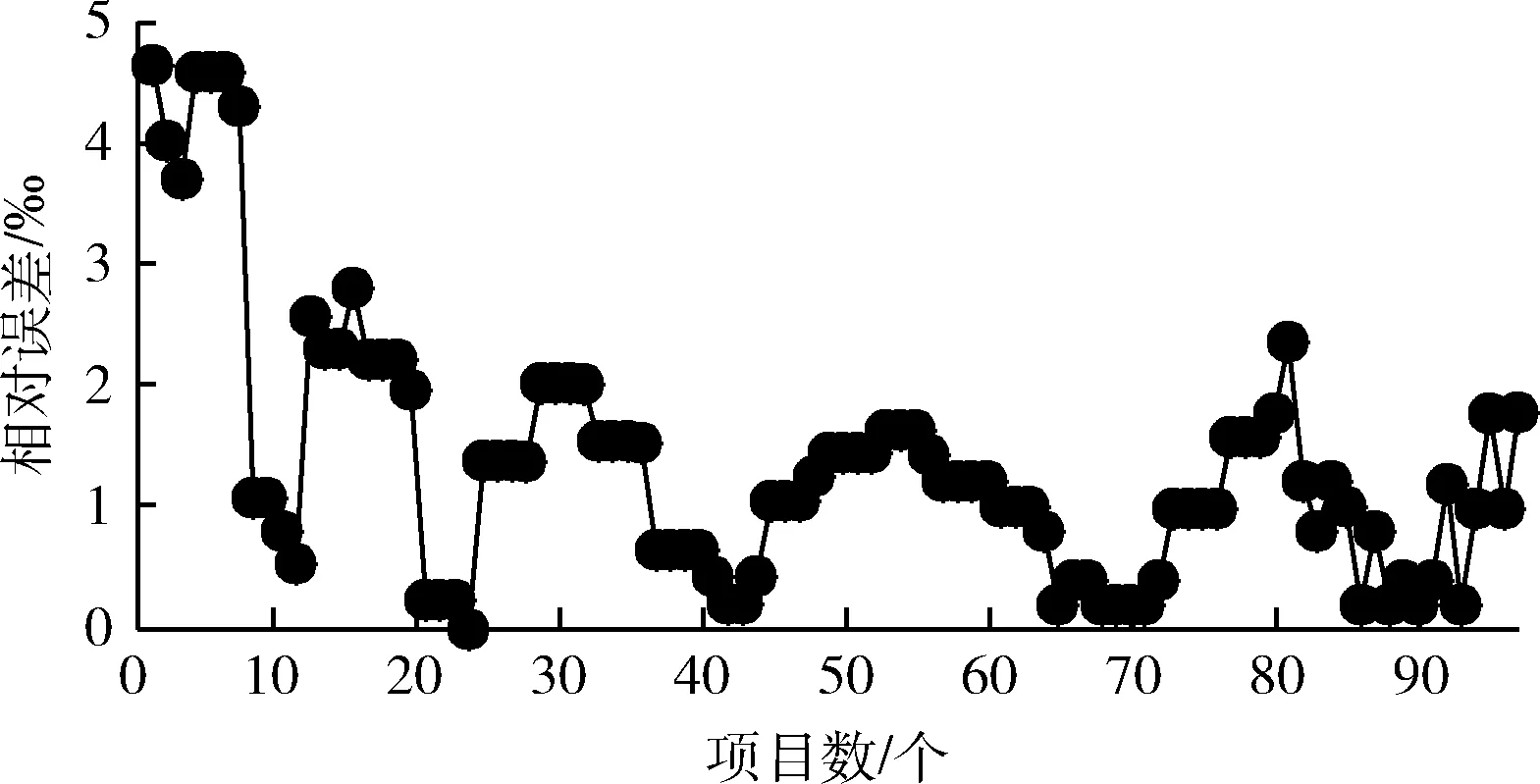
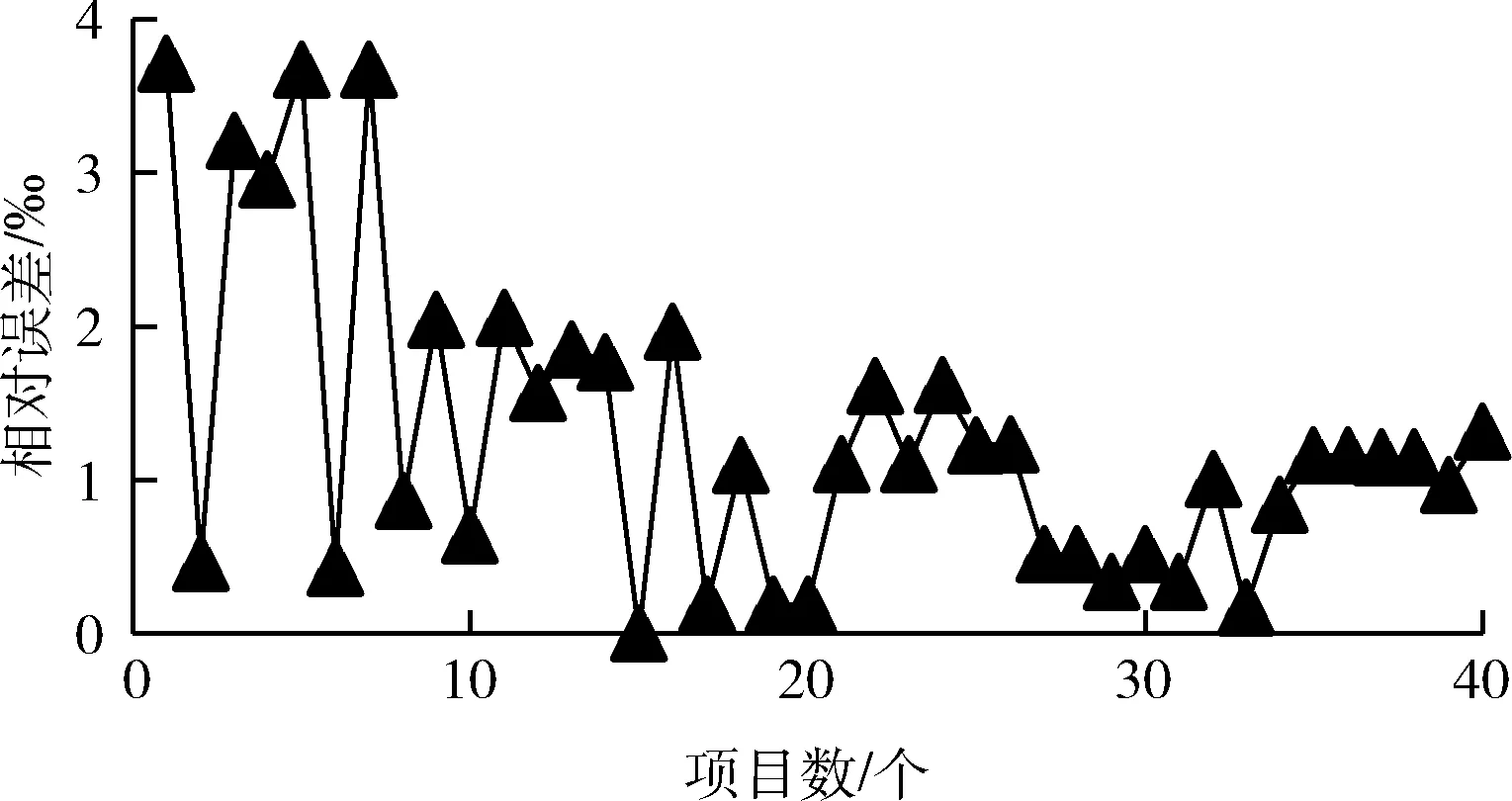
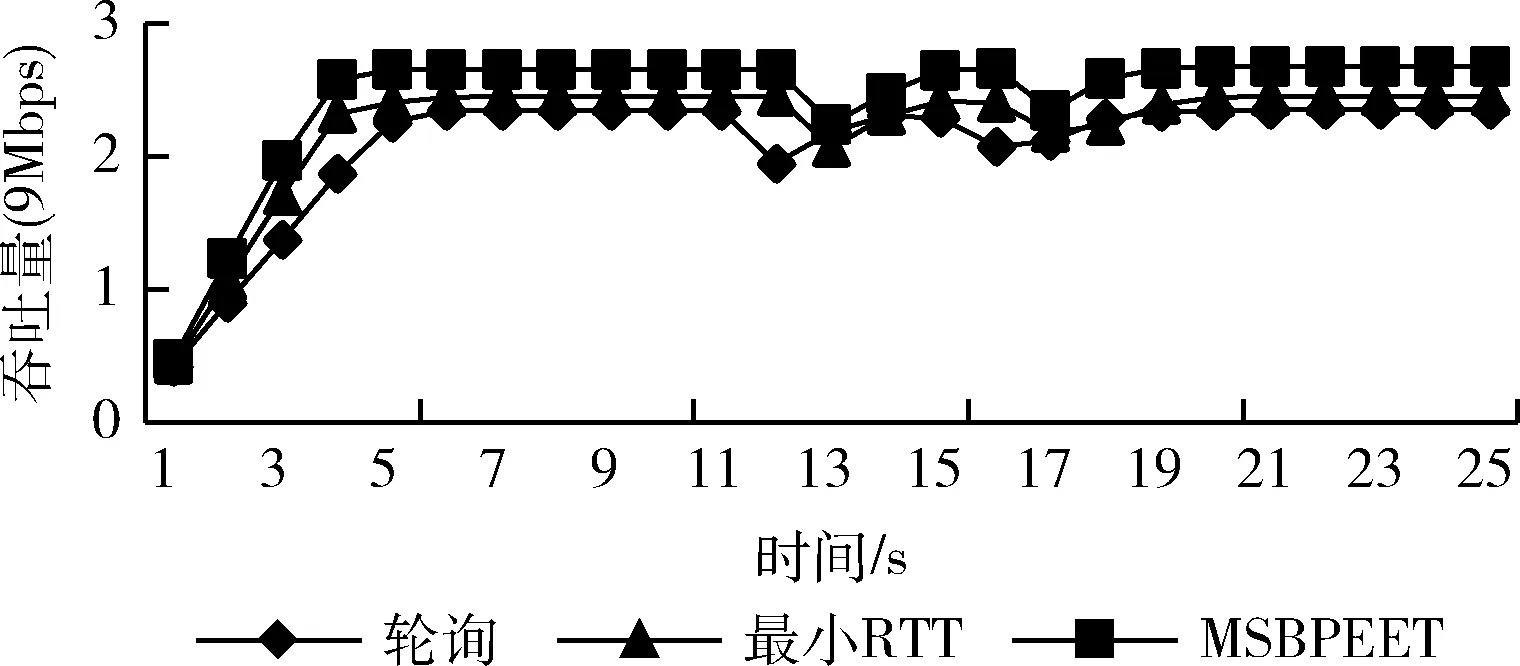
(1)在權值更新時,引入動量因子a(0 w(t)=w(t-1)+Δw(t)+a[w(t-1)-w(t-2)] (21) 在式(21)中,w(t) 代表當前時刻t的權值;w(t-1) 代表上一時刻權值; Δw(t) 代表t時刻權值更新量;w(t-1)-w(t-2) 為上一時刻權值更新量。 (2)根據誤差的增減情況對學習速率進行調整:當誤差減小時,增加學習速率;當誤差增大時,減小學習速率,并撤銷上一步修正過程,調整方法如式(22)所示 (22) 其中,η(t) 表示當前時刻t的學習速率;η(t-1) 表示上一時刻的學習速率;e(t) 為當前時刻誤差;e(t-1) 為上一時刻誤差;rateup和ratedown分別代表學習上升速率和下降速率。 2.2.4 端到端時延預測 利用已訓練好的BP神經網絡對端到端時延進行離線預測。當存在數據包發送需求時,輸入各鏈路丟包率、吞吐量、RTT,獲取端到端時延預測輸出結果。算法1給出了該部分工作的算法描述。 算法1: EET_Prediction 輸入: 丟包率Loss、 吞吐量Th、RTT 輸出: 各子流歸一化后的端到端時延EET′j (1) for 任一連接子流jdo (2) if 子流j收到ACK或發生超時 then (3)EETj←BP_EET_Presult(Lossj,THj,RTTj); (4) end if (5)EETmax←Findmax(); (6)EETmin←Findmin(); (7) end for (8) for 任一連接的子流jdo (9)EET′j←(EETj-EETmin)/(EETmax-EETmin); (10) end for 在算法1中,行(1)~行(4)通過BP神經網絡預測各子流的端到端時延,其中BP_EET_PResult用于實現在BP神經網絡中對子流j的端到端時延預測,其算法描述如算法2所示;之后將預測結果存入EETj中;行(5)~行(6)分別調用Findmax和Findmin求取各子流端到端時延的最大值和最小值;行(8)~行(10)完成對各子流的端到端時延值歸一化。 算法2: BP_EET_Presult 輸入: 子流j的丟包率Lossj、 吞吐量Thj、RTTj 輸出: 子流j的端到端時延EETj (1) for任一連接子流jdo (2)xi=(Lossj,Thj,RTTj); (4)Dk←f(dk); (6)Y←f(y); (7)EETj←Y; (8) end for 在算法2中,行(2)獲取輸入數據,即子流j的丟包率Lossj、 吞吐量Thj和RTTj; 行(3)~行(4)完成隱含層輸入輸出的計算;行(5)~行(6)負責將隱含層神經元的輸出值傳遞給輸出層,并計算獲得輸出層的輸出,即子流j的端到端時延EETj。 為更有效避免擁塞,減少亂序的發生,在前述工作的基礎上,我們進一步提出對子流擁塞狀況進行評估。定義子流路徑的擁塞程度評估值δj, 用于刻畫第j條子流路徑的擁塞情況,其計算方法如式(23)所示 (23) 在式(23)中,Unackj表示第j條子流路徑已發送但尚未確認的數據包數量;Cwndj為當前子流路徑的擁塞窗口大小。 定義鏈路j的網絡狀態評估值σj如式(24)所示 σj=αEET′j+βδ′j (24) 其中,EET′j、δ′j分別表示歸一化處理后的端到端時延及子流擁塞程度評估值;α、β為參數權重,其選取和調整視實際網絡狀態而定,α+β=1。 鏈路的σj值越小代表網絡狀態越好。 在實施數據調度時,選擇有發送窗口的路徑形成有效路徑集,P={P1,P2,…Pn}, 計算該路徑集中各路徑Pj的網絡狀態評估值,當上層應用有數據發送需求時,選擇優先級最高,即網絡狀態評估值最小的路徑進行傳輸,直至該路徑的擁塞窗口被填滿。若仍有數據需發送,則重新獲取路徑參數對有效路徑集進行更新后再實施上述過程。 算法3給出了網絡狀態評估及有效路徑集排序的算法描述。在該算法中,行(1)~行(3)中的Path_Collecting負責收集有效路徑,形成有效路徑集Spath; 行(4)~行(6) 對Spath中的各路徑計算網絡狀態評估值;行(7)通過PathSortingandSelect完成根據所求得的各路徑網絡狀態評估值進行排序后,挑選出優先級最高也即網絡狀態評估值最小的路徑pselect, 并將其用于后續的數據包調度。 算法3: OptimalPath_Select 輸入:EET′,δ′,α,β 輸出:pselect (1)for 任一子流jdo (2)Path_Collecting(Spath); (3)end for (4)for eachpjinSpathdo (5)σj←αEET′j+βδ′j; (6)end for (7)pselect←PathSortingandSelect(); 實驗機器配置為Intel(R) Core(TM) i7-4790 CPU,主頻3.6 GHz,內存8 GB,操作系統Ubuntu16.04,實驗平臺為NS-3。實驗網絡拓撲如圖3所示,使用雙接口手機終端,Wi-Fi和LTE雙路徑并行傳輸。 圖3 實驗網絡拓撲 具體網絡參數設置見表2。 表2 實驗參數設置 隱含層神經元個數對BP神經網絡的訓練誤差存在較大影響,增加隱含層神經元個數可有效降低BP神經網絡的訓練誤差,但同時也會增加計算量。在實驗過程中,設定的隱含層神經元個數超過16時,訓練結果趨于穩定;而當隱含層神經元個數超過18時,訓練誤差增大。因此,綜合考慮訓練效果及計算效率,最終隱含層神經元個數設置為16。 該部分實驗所使用的樣本數據來自仿真模擬器,樣本數據中的85%用作訓練集實施BP神經網絡訓練,其余部分用作測試集完成對神經網絡的測試。 (1)訓練誤差數據 圖4給出了訓練階段的輸出誤差情況,總體而言訓練集樣本的相對誤差絕對值小于等于5‰,僅有6個樣本的相對誤差絕對值在4‰~5‰,一個樣本在3‰~4‰之間,其余樣本均在3‰以下。這表明神經網絡的預測輸出值與實際值較為接近,所構建的BP神經網絡具有較好的端到端時延預測學習能力。 圖4 訓練相對誤差 圖5 測試相對誤差 (2)測試誤差數據 測試集樣本經由神經網絡學習的相對誤差數據如圖5所示。所有測試集樣本的相對誤差絕對值不超過4‰,該相對誤差絕對值相較訓練相對誤差絕對值更低,其中4個樣本的相對誤差絕對值在3‰~4‰之間,3個樣本在2‰~3‰之間,剩余樣本都在2‰以下。表明該神經網絡可有效完成端到端時延預測的相關學習。 本文以輪詢調度和最小RTT調度為比較對象,進行多路傳輸調度性能分析與比較。 (1)吞吐量 圖6給出了輪詢調度、最小RTT調度及本文MSBPEET方法的吞吐量數據。其中,MSBPEET在整個傳輸期間都表現出了相較于另兩種調度方法更高的吞吐量,這主要是因為MSBPEET對路徑的端到端時延和擁塞狀況進行了綜合考慮,在調度決策時可更準確地選擇合適路徑完成數據包發送,使數據包能盡可能按序到達接收端,減少了接收端重排序時間,提升了吞吐量。表3進一步給出了MSBPEET相較于另兩種調度方法的吞吐量提升比數據。其中,MSBPEET相比輪詢調度吞吐量提升16%,相比最小RTT調度提升了10%。 圖6 吞吐量 (2)失序數據包數量 圖7給出了輪詢調度、最小RTT及MSBPEET這3種方法失序包數隨時間變化的數據。在仿真時間段內,輪詢調 表3 吞吐量提升比 圖7 失序包數 度接收端的失序包數量最多,最小RTT調度次之,這主要是因為輪詢調度將所有可用路徑同等對待,輪流在各路徑上發送數據,從而導致序列號靠前的數據包在路徑質量較差的路徑上發送而引發失序。而最小RTT調度總是選擇RTT最小的子流路徑進行數據傳輸,這樣極易出現數據集中涌向低時延路徑而導致網絡擁塞現象加劇,進而引發丟包和數據包亂序等問題。本文MSBPEET方法,由于實施了更準確的端到端時延預測和路徑質量的綜合評估,極大地減少了數據包失序的發生。 本文針對移動異構網絡環境網絡高度動態變化、鏈路屬性差異較大,多路傳輸極易發生數據包亂序等問題,提出一種基于BP神經網絡端到端時延預測的多路傳輸調度方法,通過構建和訓練BP神經網絡,對端到端傳輸時延實施更準確預測,然后優先選擇擁塞程度評估值低、優先級高的子流路徑進行數據傳輸,令數據包極可能按序到達接收端,減少數據包亂序發生的可能,在有效避免下一時刻擁塞的同時提高吞吐量。
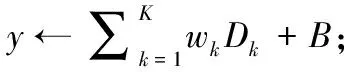
2.3 子流擁塞狀況評估
2.4 網絡狀態綜合評估及有效路徑集排序調度
3 實驗結果與分析
3.1 仿真環境及參數設定

3.2 BP神經網絡訓練與學習情況
3.3 多路傳輸調度性能


4 結束語
