半監(jiān)督卷積神經(jīng)網(wǎng)絡(luò)的詞義消歧
2022-02-11 08:41:48張春祥唐利波高雪瑤
西南交通大學(xué)學(xué)報 2022年1期
張春祥 ,唐利波 ,高雪瑤
(哈爾濱理工大學(xué)計算機科學(xué)與技術(shù)學(xué)院, 黑龍江 哈爾濱 150080)
詞義消歧 (word sense disambiguation,WSD)是自然語言處理領(lǐng)域的一個重要研究問題.Michael將歧義詞的上下文內(nèi)容分別與每個語義類在詞典中的定義進(jìn)行匹配,將匹配覆蓋率最高的語義類視為真實語義[1].因此,歧義詞上下文與歧義詞之間的相似性可以作為一種有效的判別條件,其中:楊安和Franco等[2-3]提出了一種基于特定領(lǐng)域關(guān)鍵詞信息的消歧方法,將上下文語境詞匯向量化,與不同領(lǐng)域關(guān)鍵詞向量作相似度判別,找到語境詞匯所屬領(lǐng)域,從而確定歧義詞匯所在的領(lǐng)域.唐共波等[4]利用知網(wǎng)(HowNet)對歧義詞及其上下文語境詞匯的義原信息進(jìn)行向量化,根據(jù)相似度計算結(jié)果來確定歧義詞匯的語義類別.Arab等[5]將歧義詞匯作為結(jié)點,根據(jù)詞典來獲取語義類和歧義詞之間的依賴關(guān)系并作為邊,計算邊的權(quán)重來找到最重要的結(jié)點,從而完成詞義消歧任務(wù).孟禹光等[6]計算上下文語境的詞匯向量與歧義詞向量之間的相似度,將相似度最高的語義類別作為歧義詞匯的語義類.鹿文鵬和Duque等[7-8]利用上下文語境詞匯和領(lǐng)域關(guān)鍵詞來構(gòu)建圖模型,使用歧義詞匯對圖模型進(jìn)行調(diào)整,選擇權(quán)重最大的領(lǐng)域關(guān)鍵詞作為歧義詞匯所屬的領(lǐng)域,從而實現(xiàn)詞義消歧.Tripodi等[9]提出了一種基于進(jìn)化博弈論的詞義消歧模型,利用分布信息來衡量每個單詞對其他單詞的影響,利用語義相似性來度量不同選擇之間的兼容性.由于有標(biāo)簽數(shù)據(jù)的獲取較為昂貴,而無標(biāo)簽數(shù)據(jù)獲取較為容易,所以利用無標(biāo)簽數(shù)據(jù)擴充有標(biāo)簽數(shù)據(jù)的半監(jiān)督方法便應(yīng)運而生,其中:Xu和楊陟卓等[10-11]提出了一種擴充訓(xùn)練語料的方法,利用詞典對有標(biāo)注歧義詞及其上下文語境進(jìn)行翻譯,并將其加入訓(xùn)練語料中,從而使詞義消歧的性能有所提高.Cardellino和Huang等[12-13]提出了一種擴充語料庫的詞義消歧方法,即利用少量有標(biāo)簽語料訓(xùn)練消歧模型計算相似度,找到高置信度的無標(biāo)簽語料并將其添加到訓(xùn)練語料中,提高詞義消歧效果.Mahmoodvand等[14]整合多個基礎(chǔ)消歧模型,結(jié)合協(xié)同學(xué)習(xí)思想從無標(biāo)簽語料中選取高置信度語料添加到訓(xùn)練語料中,從而實現(xiàn)高質(zhì)量的詞義消歧.隨著人工智能的發(fā)展,機器學(xué)習(xí)技術(shù)被廣泛地應(yīng)用到自然語言處理中[15-16].薛濤和 Pesaranghader等[17-18]提出了基于深度學(xué)習(xí)的詞義消歧模型,利用深度學(xué)習(xí)算法來提取語料中的關(guān)鍵特征,從而確定歧義詞匯的語義類別.Bordes等[19]以神經(jīng)網(wǎng)絡(luò)為基礎(chǔ),結(jié)合多關(guān)系圖來實施詞義消歧.Chen等[20]通過構(gòu)建情感詞匯網(wǎng)絡(luò),結(jié)合上下文來擴展訓(xùn)練語料,使得詞義消歧的質(zhì)量有所提高.
本文利用Word2Vec工具對歧義詞匯左右各2個詞匯單元的詞形、詞性和語義類進(jìn)行向量化處理,提取有標(biāo)簽語料中的聚類信息,結(jié)合卷積神經(jīng)網(wǎng)絡(luò) (convolutional neural networks, CNN)從無標(biāo)簽語料中選出高置信度的語料來擴充訓(xùn)練語料,使得CNN不斷優(yōu)化,最終獲得高質(zhì)量的詞義消歧模型.
1 構(gòu)建消歧特征向量
本文提取歧義詞左右各2個詞匯單元的詞形、詞性和語義類作為消歧特征.消歧特征提取過程如圖1所示.
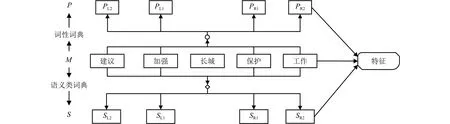
圖1 特征提取Fig.1 Feature extraction
圖1中:M代表詞形,P代表詞性,S代表語義類;PL1、PR1和PL2、PR2分別為歧義詞匯左、右側(cè)第 1個和第2個鄰接詞的詞性;SL1、SR1和SL2、SR2分別為歧義詞匯左、右側(cè)第1個和鄰接詞的語義類.
對包含歧義詞匯“長城”的句子,其消歧特征的提取過程如下所示:
漢語句子——文物保護(hù)組織的專家建議加強長城保護(hù)工作.
分詞結(jié)果——文物 保護(hù) 組織 的 專家 建議 加強 長城 保護(hù) 工作.
去停用詞和標(biāo)點符號——文物 保護(hù) 組織 專家建議 加強 長城 保護(hù) 工作.
詞性、語義類標(biāo)注——文物/n/Ba02 保護(hù)/v/Hi37組織/n/Di10 專家/n/Al02 建議/v/Hc14 加強/v/Ih10長城/n/Bn07 保護(hù)/v/Hi37 工作/n/Hi11.
使用Word2Vec進(jìn)行向量化處理:
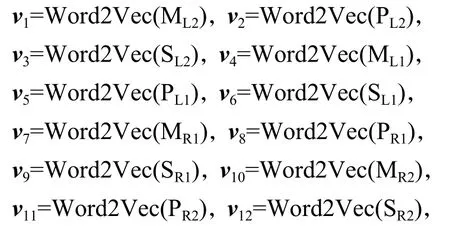
式中:Word2Vec(·)為向量化函數(shù);ML1、MR1和ML2、MR2分別為歧義詞匯左、右側(cè)第1個和第2個鄰接詞的詞形.
消歧特征矩陣為V=(v1,v2,v3,v4,v5,v6,v7,v8,v9,v10,v11,v12).
2 卷積神經(jīng)網(wǎng)絡(luò)詞義消歧模型
卷積神經(jīng)網(wǎng)絡(luò)詞義消歧模型是以前向傳播的消歧過程和反向傳播的優(yōu)化過程為基礎(chǔ)來構(gòu)建的.
2.1 前向傳播
通過輸入層、卷積層、池化層和輸出層的運算,最終獲得歧義詞在不同語義類下的概率.
2.1.1 輸入層
歧義詞c有l(wèi)個語義類S1,S2, ···,Sl.對于c共提取了12個消歧特征.利用Word2Vec工具將消歧特征向量化,每個特征向量作為行向量,可構(gòu)建一個大小為12 × 100的特征矩陣,輸入到CNN消歧模型.針對以上例子,歧義詞“長城”的特征矩陣構(gòu)建過程如圖2所示.
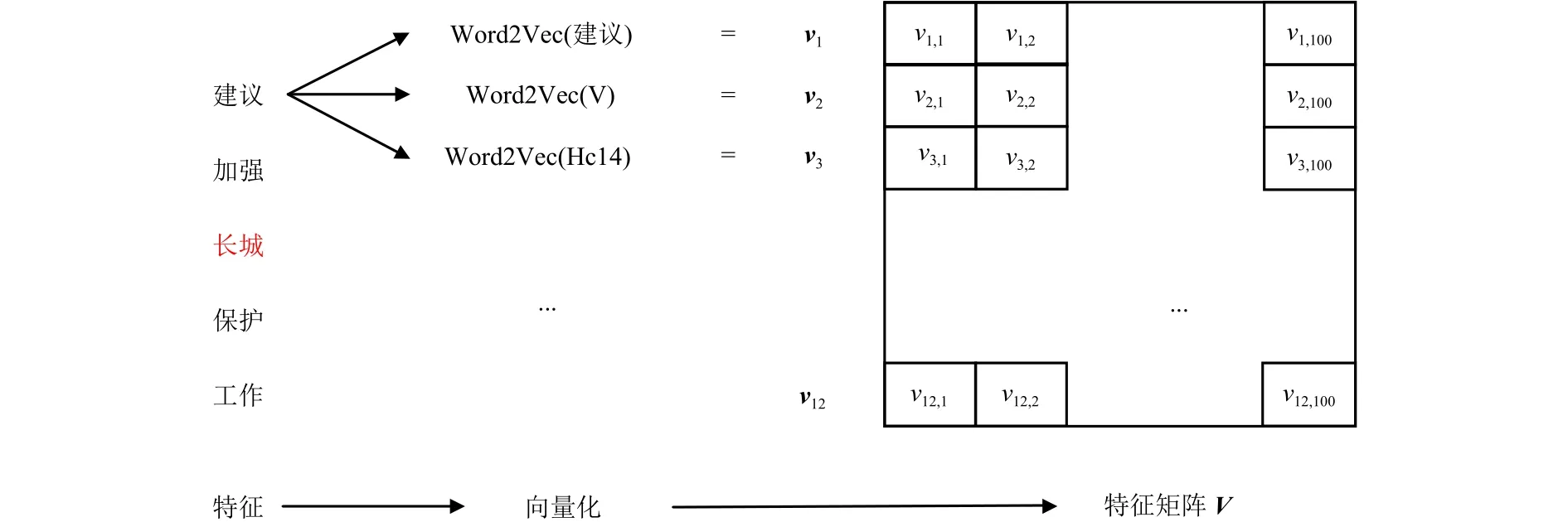
圖2 特征矩陣構(gòu)建過程Fig.2 Construction process of feature matrix
2.1.2 卷積層
對于歧義詞匯c,經(jīng)過輸入層可以得到消歧特征矩陣V=(vij)12×100.使用一個大小為h×k的卷積核w在V中由上至下進(jìn)行滑動,并與特征矩陣對應(yīng)位置進(jìn)行卷積操作.其中:h為每次卷積的特征向量的數(shù)量,1≤h≤12;k為每次卷積的特征向量的維度,1≤k≤100.卷積操作如式(1)所示.

式中:zi:j為第i個卷積核wi的第j次卷積獲得的特征;vj:j+h-1為第j個到第j + h -1 個特征向量;b為偏置量;f(·)為激活函數(shù),此處使用的是收斂效果較好的Relu函數(shù).
每次選取 2 個消歧特征向量vj和vj +1作為特征子矩陣進(jìn)行卷積,1≤j≤11.利用式(1)計算得到zi:j.zi=(zi:1,zi:2,··,zi:11),zi為第i個卷積核所提取的特征集合.通過設(shè)置不同的卷積核,可以提取不同屬性的特征.設(shè)卷積核的數(shù)量為n,可以得到n組不同屬性的特征,卷積層的輸出結(jié)果為z={z1, z2,··, zn}.
2.1.3 池化層
此處,采用最大池化(max-pooling)方法來提取最關(guān)鍵的特征,如式(2)所示.
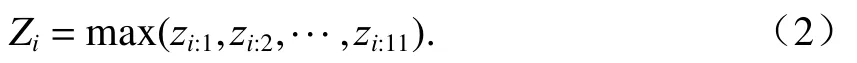
經(jīng)過輸入層和卷積層的操作,得到由n個卷積核提取的n組不同屬性的特征z={z1, z2,··, zn},利用式(2)計算不同屬性中的關(guān)鍵特征,則池化層最后的輸出為Z=(Z1, Z2, ··, Zn).
2.1.4 輸出層
在詞義消歧模型中,輸出層采用兩層結(jié)構(gòu).
第1層是全連接層,如式(3)所示.

式中:y為凈激活;W為全連接層的權(quán)重矩陣;B為全連接層的偏置量矩陣.
第2層為softmax層,輸出歧義詞c所屬不同語義類的概率值,如式(4)所示.

式中:yd為歧義詞c屬于語義類Sd的凈激活值;D為簇數(shù).
在輸出層中,經(jīng)過全連接層和softmax層,最終輸出歧義詞“長城”所屬不同語義類的概率,計算過程如圖3所示.
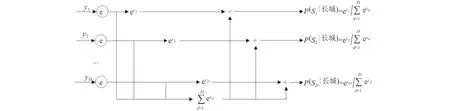
圖3 softmax 層Fig.3 softmax layer
選取最大概率值對應(yīng)的語義類作為歧義詞c的語義類,如式(5)所示.

2.2 反向傳播
反向傳播通過不斷調(diào)整權(quán)重和偏置量,逐步提高CNN消歧模型的泛化能力.
經(jīng)過前向傳播,CNN消歧模型輸出歧義詞c屬于不同語義類的概率P(Sd|c).計算輸出結(jié)果與真實結(jié)果的損失函數(shù),如式(6).
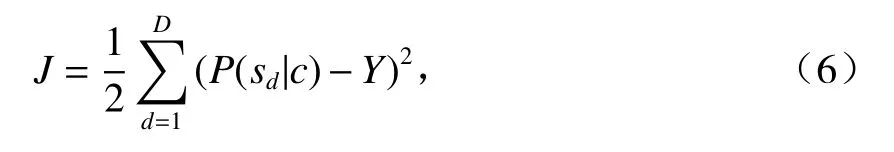
式中:Y為歧義詞c的真實語義類的One-hot表示.
根據(jù)損失函數(shù)J更新全連接層的權(quán)重W和偏置量B,然后更新卷積層的權(quán)重w和偏置量b.
3 半監(jiān)督卷積神經(jīng)網(wǎng)絡(luò)消歧模型
半監(jiān)督卷積神經(jīng)網(wǎng)絡(luò)消歧是利用聚類方法選取高置信度無標(biāo)簽語料來擴充訓(xùn)練語料,以優(yōu)化CNN詞義消歧模型.首先,對包含歧義詞c的有標(biāo)簽語料AL進(jìn)行聚類,抽取訓(xùn)練語料每個實例的特正量構(gòu)建D個簇C1,C2,···,CD.計算每個簇的中心點和簇內(nèi)各點到中心點的距離集合.根據(jù)簇內(nèi)點到中心點的距離集合來設(shè)定簇內(nèi)的閾值.然后,利用AL來優(yōu)化CNN消歧模型.從無標(biāo)簽語料AU中,取出任意實例.利用優(yōu)化后的CNN模型對該實例進(jìn)行語義類預(yù)測,其語義類別p.判斷該實例與Cd中心點的距離是否小于Cd的簇內(nèi)閾值.若滿足,則將該實例和其語義類別加入AL;否則,將該實例加入AU.重復(fù)上述步驟,直到有標(biāo)簽語料AL不發(fā)生擴充為止,循環(huán)結(jié)束.得到的CNN為優(yōu)化后的詞義消歧模型.訓(xùn)練過程如下所示.
輸入包含歧義詞匯c的有標(biāo)簽語料AL={(,其中:為有標(biāo)簽的特征量,qg為人工語義類標(biāo)注,g= 1,2,···,mL,mL為有標(biāo)簽語料數(shù);包含歧義詞匯c的無標(biāo)簽語料為無標(biāo)簽的特征量,e=1,2,···,mU,mU為無標(biāo)簽語料數(shù);閾值T∈{Tmax,Tmim,Tmed,Tavg},其中:Tmax、Tmim、Tmed和Tavg分別為特征量距離的最大值、最小值、中值和平均值.
輸出優(yōu)化后的CNN模型.
1)while (AL發(fā)生擴充){
for (inte=1;e<=mU;e+ + ){
① 根據(jù)語義類別將AL劃分為D個簇,獲得C1,C2, ··,CD.
② 計算簇Cd的中心點ud,如式(7)所示.

式中:xt為簇Cd內(nèi)第t點的特征量,t= 1, 2, ··· ,|Cd|.
③ 計算獲得簇Cd內(nèi)點到中心點ud的距離集合Ld,如式(8)所示.

式中:F(xt)為取二元序?qū)Φ牡?分量.
④ 獲得Ld={l1,l2,··,l|Cd|-1},對Ld由小至大進(jìn)行排序,計算每個簇內(nèi)的閾值:
當(dāng)閾值T = Tmax= max(Ld)時,有

當(dāng)閾值T = Tmin= min(Ld)時,有

當(dāng)閾值T = Tmed= med(Ld)時(med(·)為中值函數(shù)),有
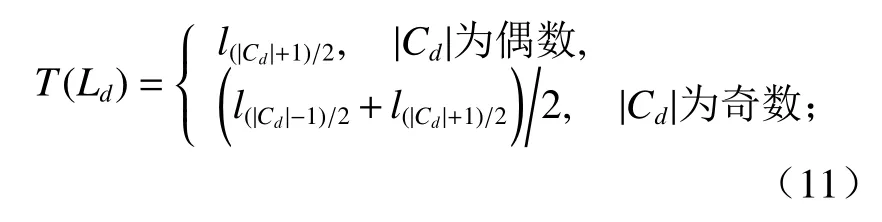
當(dāng)閾值T = Tavg= avg(Ld)時,有
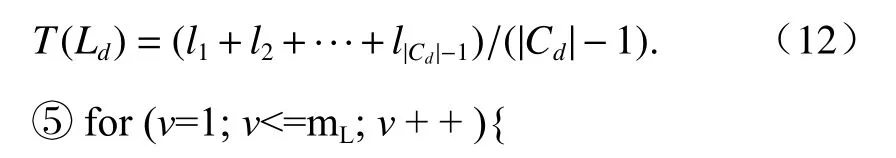
將有標(biāo)簽語料AL中的特征量輸入到CNN模型得到歧義詞匯c所屬不同語義類的概率,根據(jù)式(6)計算與真實語義類的損失函數(shù),通過不斷反向迭代優(yōu)化CNN模型的參數(shù),直到損失函數(shù)收斂為止.}
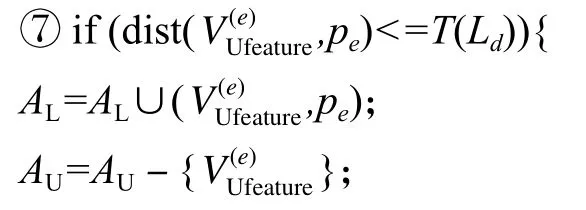
其中,dist(·)為歐式距離.
} } }
2)輸出優(yōu)化后的CNN模型.將包含歧義詞c的消歧特征向量輸入到優(yōu)化后的CNN模型計算c的預(yù)測語義類為Sd的概率P(Sd|c).從中選取最大概率值所對應(yīng)的語義類別為歧義詞c的語義類.
4 實驗分析
本文使用SemEval-2007: Task#5中的有標(biāo)簽語料作為訓(xùn)練語料和測試語料,使用哈爾濱工業(yè)大學(xué)無標(biāo)注語料作為無標(biāo)簽語料.選取了20個具有代表性的歧義詞匯進(jìn)行實驗.對比了深度信念網(wǎng)絡(luò)(deep belief network,DBN)模型、CNN 模型和本文提出方法的消歧效果,共進(jìn)行了3組實驗.
實驗 1分別設(shè)置閾值T為Tmax、Tmim、Tmed和Tavg,采用本文的半監(jiān)督卷積神經(jīng)網(wǎng)絡(luò)方法進(jìn)行詞義消歧,實驗結(jié)果如表1所示.從表1可以看出:當(dāng)T=Tavg時,本文所提出方法的性能最好.
對表1中的歧義詞根據(jù)類別數(shù)進(jìn)行歸類,計算在不同閾值下的平均消歧準(zhǔn)確率,如圖4所示.

表1 不同閾值的平均消歧準(zhǔn)確率Tab.1 Average disambiguation accuracy of different thresholds %
從圖4中可以看出:語義類別數(shù)為2的平均消歧準(zhǔn)確率要比語義類別數(shù)為3和4的要高,其原因是:隨著語義類別數(shù)的增加,預(yù)測結(jié)果具有更多的可能性,使得消歧模型更容易出錯.因此,當(dāng)語義類別數(shù)增加時,平均消歧準(zhǔn)確率有所下降.對于語義類別數(shù)為2和3的情況,當(dāng)閾值為Tavg時,平均消歧準(zhǔn)確率最高.對于語義類別數(shù)為4的情況,當(dāng)閾值為Tavg時,平均消歧準(zhǔn)確率低.但是,當(dāng)閾值為Tavg時,整體平均消歧準(zhǔn)確率最高.其原因是:當(dāng)閾值為Tmax時,有大量的無標(biāo)簽語料被誤分類,從而使訓(xùn)練語料所對應(yīng)的標(biāo)簽不準(zhǔn)確,導(dǎo)致訓(xùn)練過程出現(xiàn)分類錯誤;當(dāng)閾值為Tmin時,訓(xùn)練語料不能充分地擴充,從而導(dǎo)致訓(xùn)練語料不足;當(dāng)閾值為Tmed時,由于部分?jǐn)?shù)據(jù)分布較分散,從而使得中位數(shù)不具有代表性,導(dǎo)致訓(xùn)練過程不能達(dá)到最優(yōu);當(dāng)閾值為Tavg時,既考慮了數(shù)據(jù)分布的不平衡性,又考慮了最具代表性的數(shù)據(jù),因此訓(xùn)練效果最優(yōu).
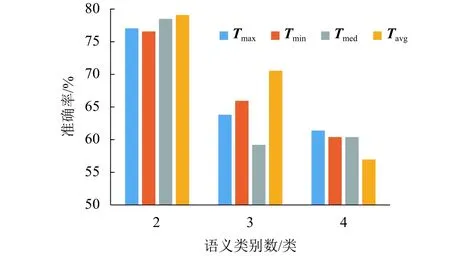
圖4 不同閾值和類別數(shù)下的平均消歧準(zhǔn)確率Fig.4 Average disambiguation accuracy at different thresholds and category numbers
實驗2利用實驗1獲得的最優(yōu)閾值,分別設(shè)置無標(biāo)簽語料與有標(biāo)簽語料的比率r.采用本文所提出的方法進(jìn)行詞義消歧,其消歧性能如表2所示.
從表2可以看出:隨著r值的增加,平均消歧準(zhǔn)確率呈現(xiàn)了一個先下降后上升的趨勢.其原因是:隨著無標(biāo)簽語料的引入,會增加很多噪聲,導(dǎo)致消歧性能下降.當(dāng)r= 100 時,平均消歧準(zhǔn)確率上升達(dá)到最大值.其原因是:無標(biāo)簽語料的引入增加了大量的消歧知識,它對消歧性能的貢獻(xiàn)已經(jīng)超過噪聲的影響.
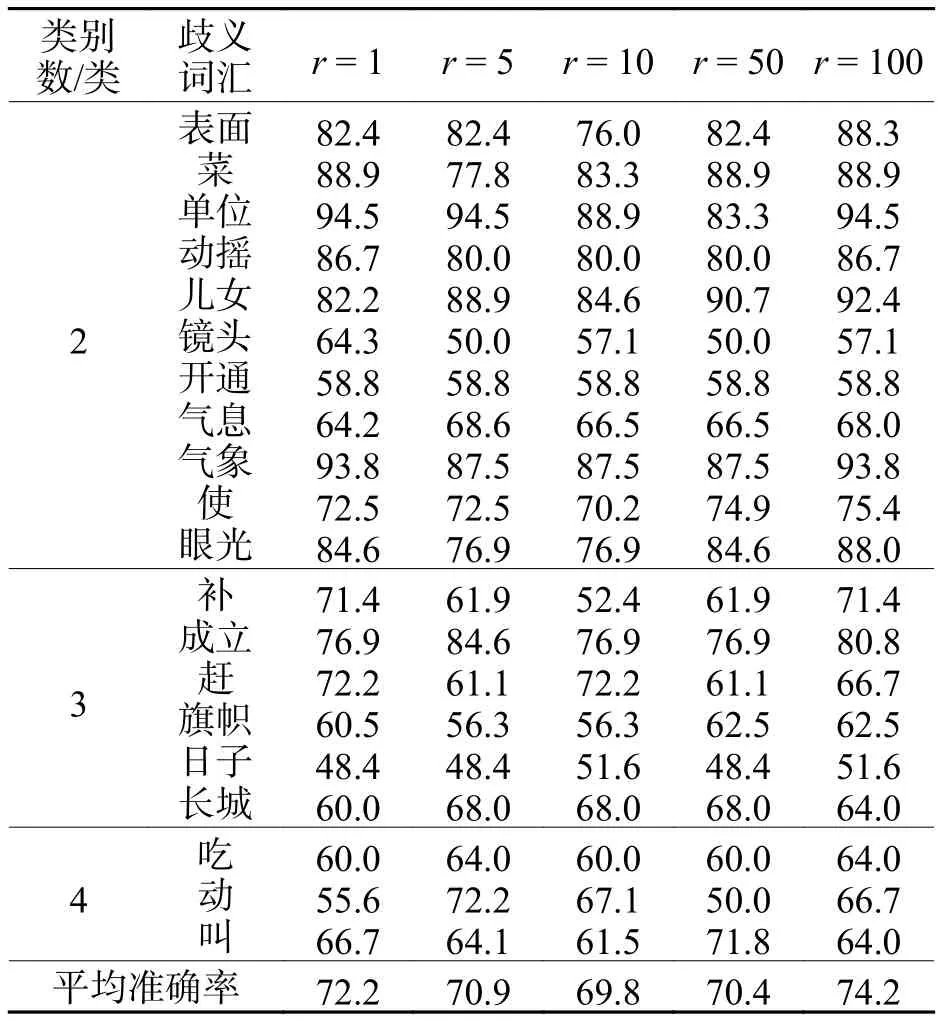
表2 不同比率下的平均消歧準(zhǔn)確率Tab.2 Average disambiguation accuracy of different rates %
對表2中的歧義詞根據(jù)類別數(shù)進(jìn)行歸類,計算每一類在不同比率下的平均消歧準(zhǔn)確率,如圖5所示.
從圖5中可以看出:語義類別數(shù)為2的平均消歧準(zhǔn)確率要比語義類別數(shù)為3和4的高,其原因是:隨著語義類別數(shù)的增加,預(yù)測結(jié)果具有更多的可能性,使得消歧模型更容易出錯.因此,當(dāng)語義類別數(shù)增加時,平均消歧準(zhǔn)確率有所下降.對于語義類別數(shù)為2和3的情況,當(dāng)比率為100時,平均消歧準(zhǔn)確率最高.對于語義類別數(shù)為4的情況,當(dāng)比率為100時,平均消歧準(zhǔn)確率排在第2位.但是,當(dāng)比率為100時,整體平均消歧準(zhǔn)確率最高.其原因是:添加無標(biāo)簽語料在引入消歧知識的同時,也會引入噪聲.但是,在添加大量無標(biāo)簽語料之后,消歧知識的影響已經(jīng)超過了噪聲的影響.
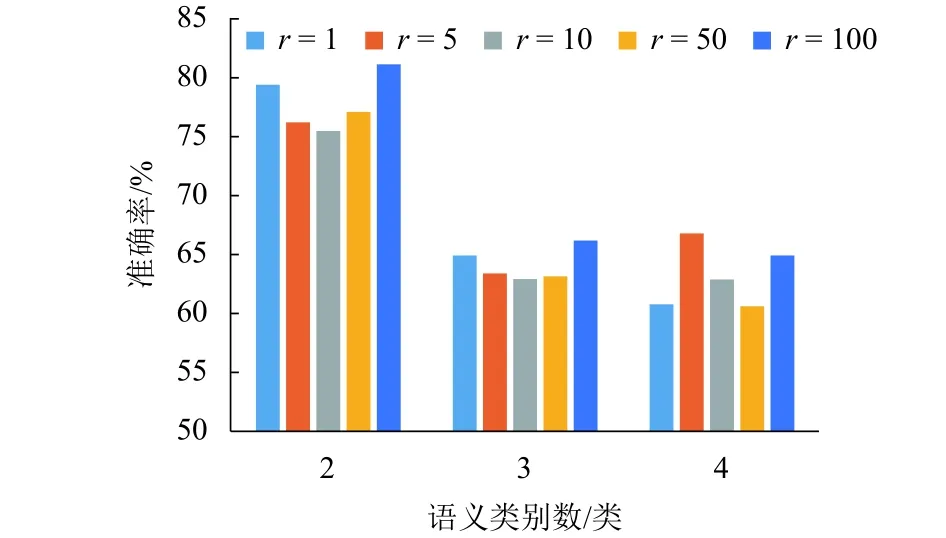
圖5 不同比例和類別數(shù)下的平均消歧準(zhǔn)確率Fig.5 Average disambiguation accuracy at different ratios and category numbers
實驗3對比了DBN模型、CNN模型和本文所提出方法的消歧效果.通過有標(biāo)簽語料來訓(xùn)練DBN模型和CNN模型,并利用優(yōu)化后的DBN模型和CNN模型對測試語料進(jìn)行消歧,與本文所提出方法進(jìn)行對比,消歧結(jié)果如表3所示.
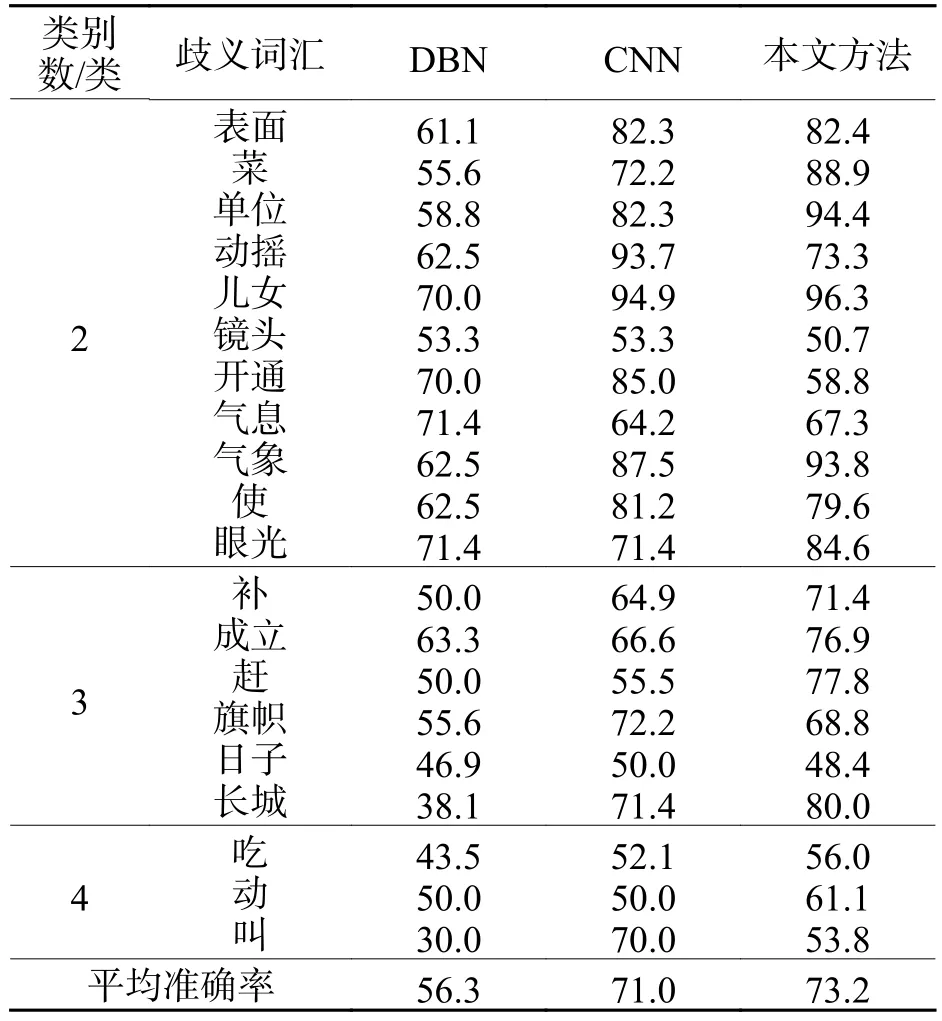
表3 3 組實驗的平均消歧準(zhǔn)確率Tab.3 Average disambiguation accuracy of three groups of experiments %
從表3可以看出:本文提出方法的平均消歧準(zhǔn)確率比DBN消歧模型和CNN消歧模型高,相對于CNN消歧模型而言,本文方法的消歧準(zhǔn)確率提高了3.1%.其主要原因是:在全監(jiān)督訓(xùn)練過程中,只能利用少量的有標(biāo)簽語料來優(yōu)化模型.在本文提出的方法中,利用聚類方法從無標(biāo)簽語料中選取高置信度語料來擴充訓(xùn)練語料,充分地利用了無標(biāo)簽語料中的語言學(xué)知識,使得消歧模型可以更好地被優(yōu)化.因此,本文所提出方法的消歧效果更好.
5 結(jié) 論
本文抽取詞形、詞性和語義類作為消歧特征,利用詞向量工具將消歧特征向量化.同時,引入半監(jiān)督學(xué)習(xí)思想,利用聚類方法從無標(biāo)簽語料中選取高置信度語料來擴充訓(xùn)練語料,優(yōu)化CNN消歧模型,從而有效地利用無標(biāo)簽語料中的語言學(xué)知識.實驗結(jié)果表明:相對于監(jiān)督DBN和CNN,本文所提出方法的消歧性能有所提升.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中華胰腺病雜志(2021年1期)2021-02-26 11:28:36
山東醫(yī)藥(2020年34期)2020-12-09 01:22:24
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
開放教育研究(2020年2期)2020-03-31 01:54:14
中華胰腺病雜志(2019年4期)2019-08-29 08:52:20
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
現(xiàn)代語文(2016年21期)2016-05-25 13:13:44
大連民族大學(xué)學(xué)報(2015年2期)2015-02-27 08:28:11
