聯合知識圖譜與改進高斯混合模型的電力用戶聚類方法
2022-02-08 01:03:20朱韻攸王迥源
重慶理工大學學報(自然科學) 2022年12期
吉 濤,何 軼,朱韻攸,王迥源,申 強,廖 勇
(1.國網重慶市電力公司信息通信分公司, 重慶 401120;2.國網重慶市電力公司, 重慶 400014;3.重慶大學 微電子與通信工程學院, 重慶 400044)
0 引言
目前,為了適應科學環保的經濟發展模式,智能電網成為了目前電力工業關注的熱點。然而,與傳統電網相比,智能電網的終端用戶信息以及各種電氣設備數據急劇增加,因此對用戶側進行數據的采集、傳輸和存儲并進行行為分析和管理是目前電力系統面臨的一大難點,同時這決定了智能電網的可靠運行[1]。
傳統的用戶劃分方式只考慮了用戶的單一特征屬性,忽略了目前用戶數據的多樣性,同時傳統的數據處理方法也無法很好地挖掘數據之前的相關性。因此,如何對電力用戶側的行為進行精準分析是當前重要的研究課題[2]。
聚類方法是處理隨機數據的一類代表性方法,如基于原型聚類、層次聚類、密度聚類等都可以對未知特征的數據進行挖掘。其中高斯混合模型(gaussian mixture model,GMM)聚類作為原型聚類的代表方法,由于其良好的聚類性能而被廣泛研究。蔡秋娜等[3]利用用戶的負荷數據使用GMM方法進行聚類,提取其典型日負荷曲線,并采用支持向量機方法,根據用戶類別與其典型日負荷曲線之間的關系,在訓練集上建立分類模型,并據此對新的用戶進行行業分類。李婉婉等[4]采用GMM聚類方法對車站微機監測系統中采集的功率數據進行分類,根據結果建立概率神經網絡的訓練集和測試集,結果表明基于 GMM 聚類和概率神經網絡的方法可以改善不收斂、誤差大等問題。薛琳[5]首先提取電力用戶的行為特征,借助GMM方法得到不同質量的電力用戶,以條件互信息為標準進行更優用戶的篩選,最后借助長短期記憶網絡(long short-term memory,LSTM)進行負荷預測。上述3種方法雖然都借助GMM方法進行聚類分析,但只有文獻[3]和文獻[5]提及了電力用戶的聚類分析,并且文獻[3]使用GMM方法對電力用戶進行聚類分析,但是沒有對其行為特征進行進一步挖掘,而文獻[5]的方法存在輸入特征增加而難以建模的問題。所以基于GMM的電力用戶數據分析還需進一步的研究。
另一方面,知識圖譜(knowledge graph,KG)也被稱作知識域映射地圖或知識域可視化,KG目前在智能電網領域的應用主要面向用戶服務、設備運維、知識管理等方面。徐蕙等[6]針對電網企業的數據資源無法被智能分析與管理等問題,提出基于KG的語義搜索方法,相比于傳統的關鍵詞搜索,該方法的性能得到有效提升。周帆等[7]針對模型管理等相關業務的問題解答,利用電力調度模型構建了KG,并實現了智能問答系統的構建。由此可得,KG在智能電網中的應用還有很大的發展空間。李金星等[8]通過使用BiLSTM-CRF模型對電網故障分析和電網調度領域進行分析,利用KG技術,獲取到各電網間的拓撲關系以及電網故障信息,提高了電網維修的效率。上述方法均表征了基于KG的電網管理方案要比傳統的方法高效,因此KG技術在智能電網中的應用還有很大的發展空間。
為進一步提升對電力系統用戶的管理,本文提出聯合KG和期望最大化[9](expectation maximization,EM)的GMM聚類方法,簡稱KGEG方法。該方法主要包括2個步驟:① 利用KG,將復雜的文本轉換為GMM方法所需要的輸入;② 利用EM方法對上一步驟中獲得的數據進行GMM聚類,實現對數據隱藏的相關性進行聚類分析。最后將所提方法應用在電力公司的用戶數據分析中,得到電力公司用戶分群,并通過評價指標將該方法與其他方法進行對比,以驗證所提方法的可行性和有效性。
1 KGEG方法
1.1 KG預處理
KG采用四元組表示知識,知識元可以表示為:kej={cj,pj,rj,aj},其中cj,pj,rj,aj分別代表概念、實體、關系和屬性,由ɡ個知識元組成的知識域記為kud={ke1,ke2,…,keg}。知識域、知識元的關系如圖1所示:
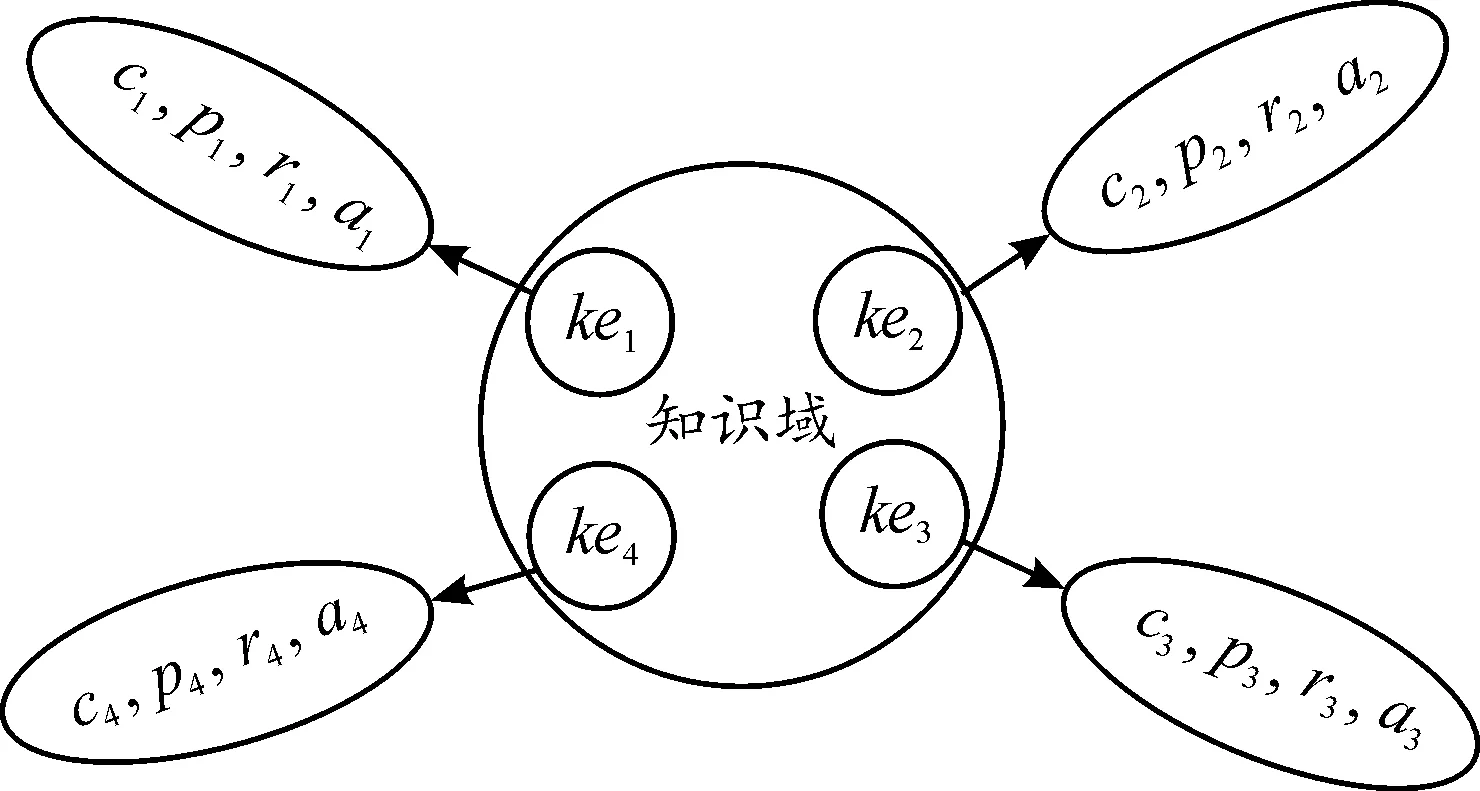
圖1 知識域與知識元示意圖
對于復雜文本,KG可以有效分析文本的核心概念以及關鍵內容,對于聚類方法,需要規范的輸入數據x=[x1,x2,…,xn]T,通過KG得到文本的知識元節點后再進行聚類,避免手動處理聚類所需要的數據,其原理如圖2所示。
圖2(a)為KG預處理過程的抽象描述,圖2(b)為具體過程。記文本數據輸入為s,通過KG預處理文本數據后,得到聚類方法輸入x=fKG(s),下一小節將描述基于GMM的聚類方法。
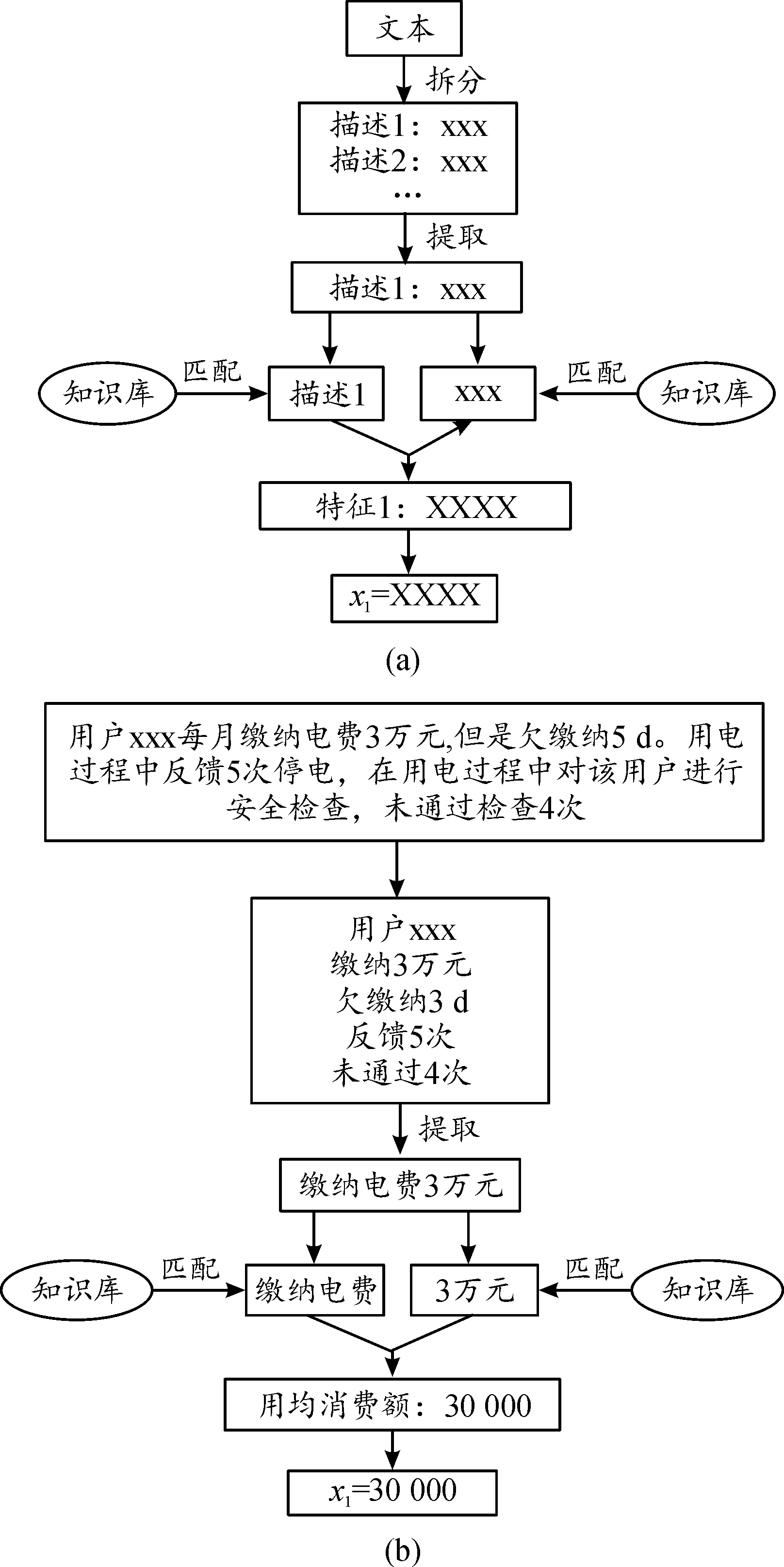
圖2 KG預處理過程框圖
1.2 高斯混合聚類
對于所有的輸入樣本集合D={x1,x2,…,xm},假設這些數據分為k類,對于其中的一個輸入x,其服從于高斯混合分布,因此概率密度函數為:
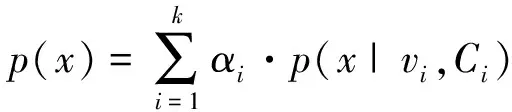
(1)
式中,p(x|vi,Ci)表示其中的一個成分,服從均值為vi、方差為Ci的高斯分布:
(2)
式中:vi和Ci分別為均值、協方差,(·)T為轉置運算。對于式(2),其參數為vi和Ci。記隱變量p(yj=i)=γji為樣本xi是來自第j個高斯分布成分的概率,通過下式,能夠判定xj第i個高斯成分:
maxγji,j=1,2,…,k
(3)
為了求解以上參數,構建以下對數似然函數:
(4)
對于均值vi,其偏導數為:
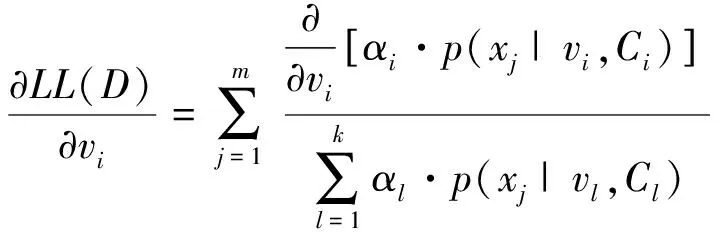
(5)
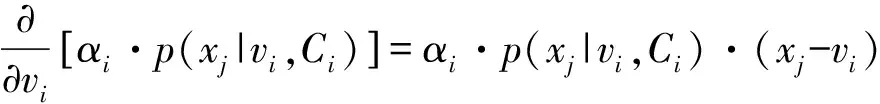
(6)
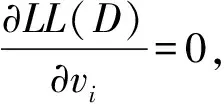
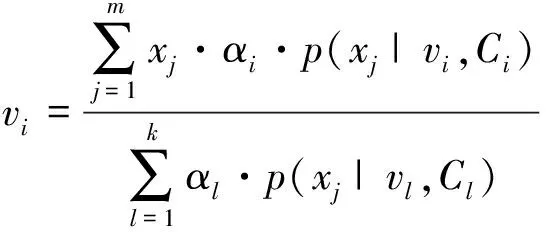
(7)
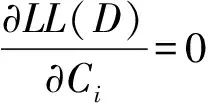
(8)
最后,對于參數αi,注意到δi存在約束,引入拉格朗日乘子法:
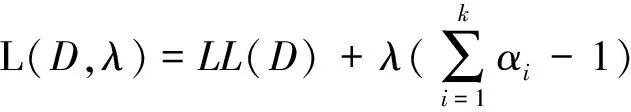
(9)
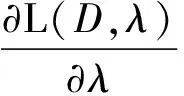
(10)
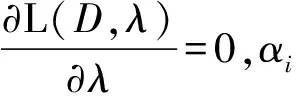
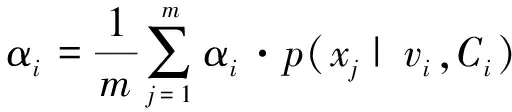
(11)
vi、Ci以及δi這3個參數均需要分模型p(xj|vi,Ci)的概率,根據式(12),結合貝葉斯公式,可以得到p(yj=i|xj)為:
(12)
由于第i個分模型需要參數vi和Ci,因此式(12)又需要參數vi、Ci和αi,參數和模型交替迭代,達到最大似然估計的目的,該方法即為EM方法的原理。在初始化模型參數(αi,vi,Ci)后,反復更新均值、協方差、分模型概率3個參數,直到這些參數在下次迭代時收斂為止。方法1描述了基于KG預處理的GMM聚類方法的過程:
方法1:KGEG方法
輸入:復雜文本s
輸出:聚類簇劃分θ={θ1,θ2,…,θk}
過程:
1.復雜文本查詢轉換為聚類輸入x=fKG(s)
2.隨機從x中選取k個數據xinit={x1′,x2′,…,xk′}作為初始聚類的中心點
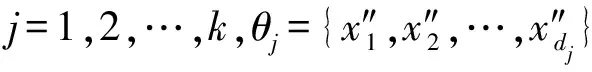
4.令αj=dj/n;令vj=xj′,j=1,2,…,k;令Cj=COV(θj)
5.Δαi=∞,Δvi=∞,ΔCi=∞
6.while
7.forj=1,2,…,n
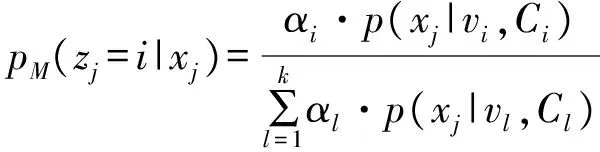
9.(i=1,2,…,k)
10.end for
11.fori=1,2,…,k
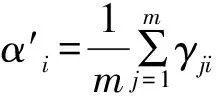
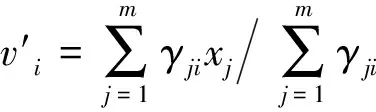
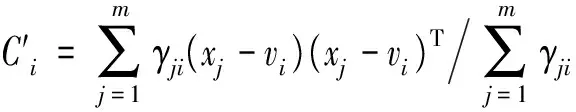
15.end for
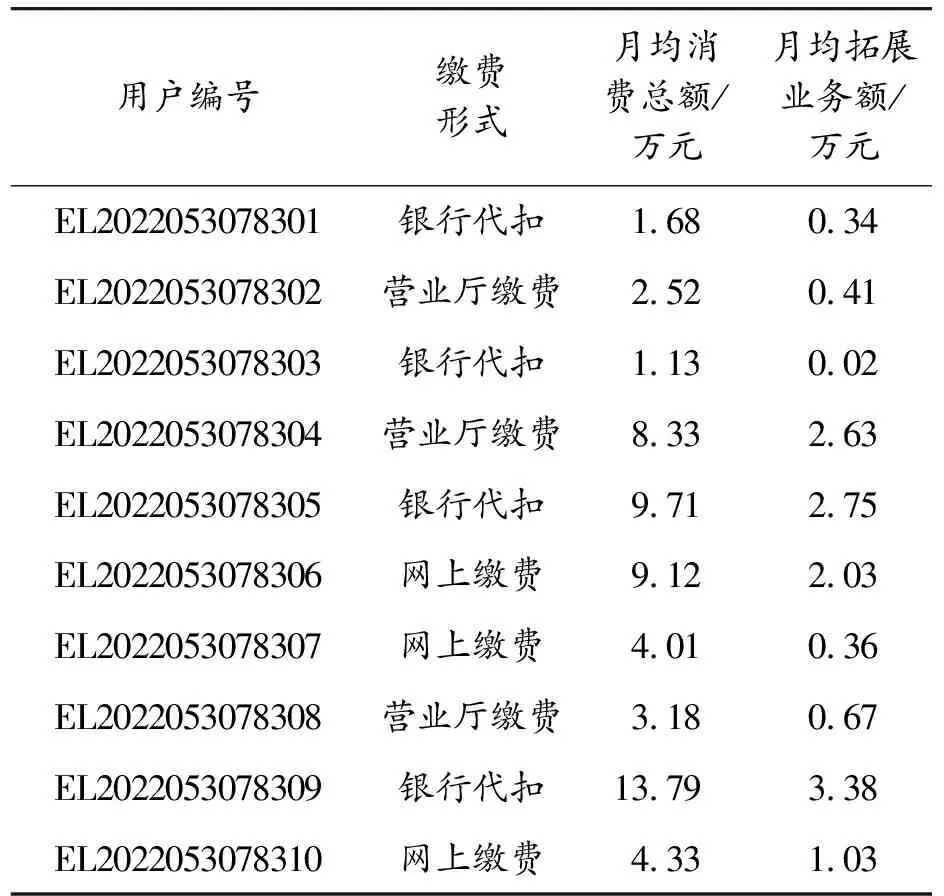
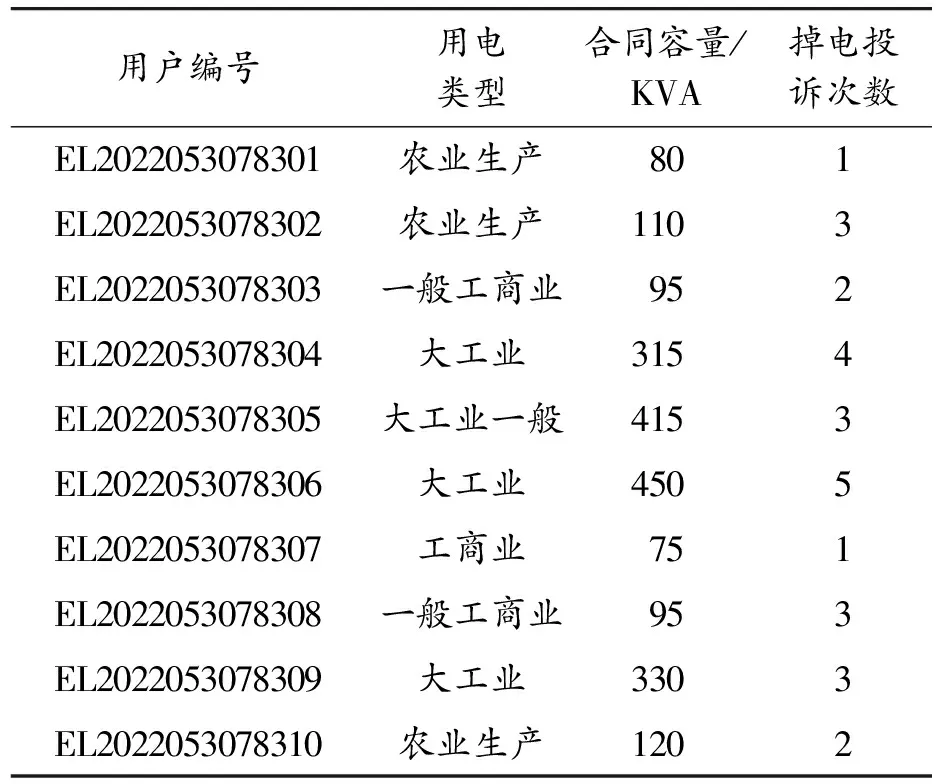
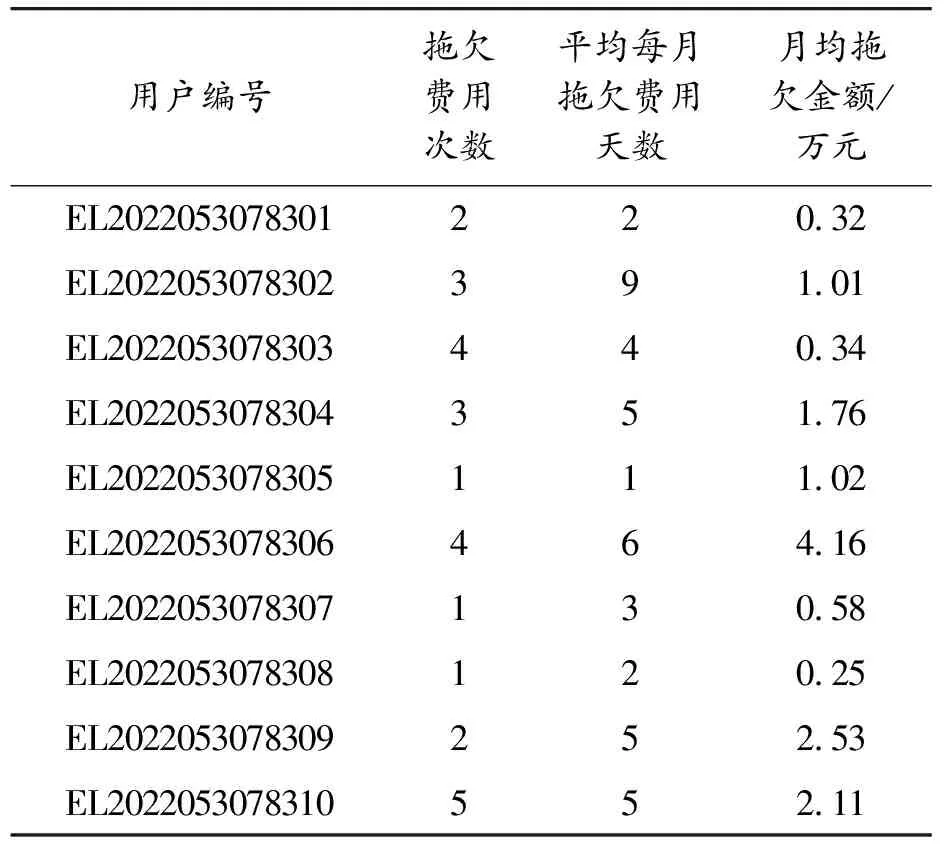
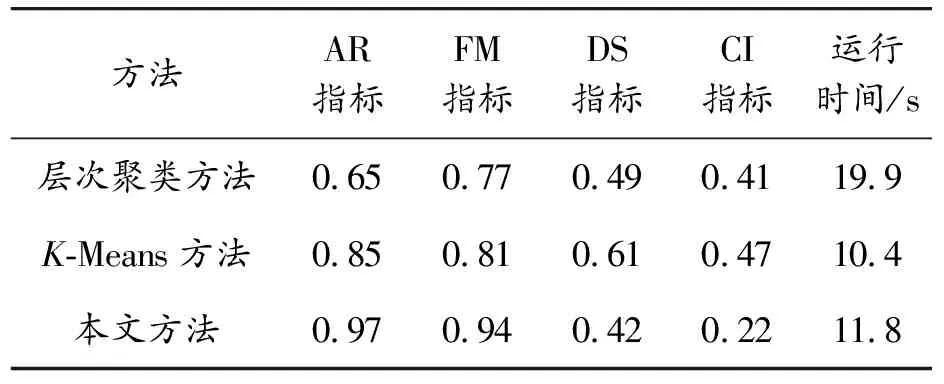
16.until Δaiand Δviand ΔCi 17.fori=1,2,…,n 18.根據式計算每個xi的簇類別ξj,劃分到簇θξj 19.end for 判斷聚類標準的指標有很多,本文從內部、外部以及整體3個方面選擇評價指標,包括緊湊度CI[10]、FM[11-12]、Adjusted-Rand(AR)[13]以及分離度(degree of separation,DS),其中CI為內部評價指標,FM和AR為外部評價指標,DS為選取的整體評價指標。 CI指標:從數據簇的內部來判斷聚類的效果,用于體現一個簇的數據集的聚集程度,若一個簇內的數據越相似,則CI指標越高,也說明了聚類效果優秀[14]。 計算簇內CI的方法如式(13),其中n為總樣本數,每個樣本由p個向量組成:X={x1,x2,…,xn},X?Rp,c為最后聚類分簇數,U是一個維度為c*n矩陣,uij為數據j對第i類的支持度,若該支持度越大,說明其包含的信息越多;V是一個維度為c*p的矩陣,表示聚類原型;并且采用的計算距離方式為歐氏距離。 (13) 使用外部評價指標的過程一般是將聚類方法用于現有的標準測試數據集中,再利用相應的指標進行評判方法劃分的準確程度[15],經典的外部聚類評價指標如FM指標和AR指標等。 1) FM 如下式所示,計算FM指標 的過程為: (14) FM指標為精度和召回的幾何平均數,取值范圍為0~1,一般該值越大,則說明該聚類方法劃分的簇與標準結果越接近,只有當聚類結果完全正確時,IFM=1。 2) AR 首先,如下設置對應的參數的式子: (15) (16) (17) (18) (19) AR是蘭德系數的改進版本,為去掉隨機標簽對評估結果的影響,取值范圍在0~1,該值越大,也代表了聚類效果很好。 DS表示了劃分后各個簇的分離界是否清晰,之間的界線越清晰,即DS越高,則聚類效果更好。 簇間DS公式如式(20)和式(21)所示: Fij=(uij-α)2 (20) (21) 如下式為整體分離度,通過將所有子簇的DS相加獲得: (22) 式中:α表示懲罰系數,其默認取值為0.5;Fij表示模糊偏差,主要用于加強隸屬度矩陣特征。模糊集合的DS為簇之間的模糊偏差做積運算。 在進行聚類之前,需要對數據先進行預處理,以保證數據具備規范的格式,也保證聚類的質量。 3.1.1數據準備 首先盡量選取能對聚類產生較大影響的數據特征作為聚類的特征對象,這是后續聚類分析的基礎。 1) 特征屬性的選取 參考電力通信中已有的對用戶分析的研究,確定出能有效體現用戶行為的特征,通過這些特征來細分,并建立對應的指標體系,能大大加強管理者對其中業務組織的管理并改善服務質量。如表1所示,本文的聚類特征屬性分成了四大類,分別為用戶消費能力、掉電容納水平、用戶欠費評估以及用戶安全等級。通過這些方面的指標特征,能整體地分析電力用戶所屬的大致群體。 表1 用戶分群評估信息 2) 數據采集 本文選用了10 000位電力信通用戶的數據,通過上文選取的評估特征進行提取,表2為其中的一些用戶的消費能力數據信息。 用戶掉電容納水平選取的部分數據如表3所示,包括了用電類型、合同容量等類別。 表4為部分用戶的欠費評估數據信息,這些數據能較為全面地體現用戶繳費的一個積極度與誠信度。 表2 用戶消費能力信息 表3 用戶掉電容納水平 表4 用戶欠費評估信息 用戶的設備風險的信息如表5所示,通過安全檢查不合格次數等類別屬性可以判斷用戶對用電安全的整體素質,包含的用電量和合同量的匹配度通過式(30)得到: (23) 式中:γ為用電匹配度;β為實際用電量;α為合同中包含用電量。 表5 用戶安全等級信息 3.1.2數據標準化 為保證聚類時的數據規范統一并且完整,還需要對數據進行標準化處理。 1) 空缺處理 由于選用的隨機用戶數據在收集時不完整,存在空缺信息,需要對這種情況進行處理。譬如部分用戶存在掉電后投訴次數的數據為空,為了保證聚類的過程的正常運行以及結果的準確,采用平均值填空的方法進行補充數據,具體來說,通過找到該類特征數據的眾數值進行補充,而對于缺失屬性量大于2的數據直接進行刪除。 2) 噪聲數據處理 在選用的數據中還存在數據噪聲,若其中的數據遠遠不在該類屬性數據的范圍之內,那么可以確定該數據為噪聲數據,需要進行處理,本文采用了箱型圖自動識別噪聲數據,即通過2個閾值U、L,其中U為所有數據中該類屬性的大小的前1/4數據的閾值,而L為所有數據中該類屬性的后1/4數據的閾值,取2個閾值的差為Q,則上界設定為U+1.5Q,下界設定為L-1.5Q,超過上界以及低于下界的數據都為噪聲數據,將該條數據刪除處理。 3) 不一致數據處理 在選取的數據中也存在少量數據混亂的情況,如不同類別的數據位置相反,如將用電合同容量填寫到了繳費形式處,或者將安全檢查不合格次數寫到了用電匹配量處,這樣存在的數據較少,對于這樣的數據,通過中值法來進行處理,具體為:通過統計該類屬性的中位數來替代該類數據。 將這些數據標準化處理后,就得到了本文聚類時的最終數據。 本小節將本文所提方法與傳統方法中的層次聚類方法以及K-Means方法進行了仿真對比,使用的數據是由電力公司提供的用戶數據,通過對比不同測試結果指標綜合分析評價本文所提方法的性能。 1) 聚類結果 為了使聚類結果更具代表性,本文只選擇對聚類結果有影響的特征變量進行操作。首先從電力公司提供的用戶信息中選取10 000名用戶信息,并對這些數據信息進行數據轉換和數據清洗,然后使用本文所提KGEG方法對數據進行分析,聚類結果以及每一類用戶群的特征均值分布情況如圖3、圖4所示。 圖3 KGEG聚類結果 圖4 3種用戶群特征 表6展示了聚類結果的詳細信息,即電力公司用戶數據經所提KGEG方法處理后的結果。從表中可以得出所分三類用戶的各項參數的平均值,對這些聚類數據結果進行分析能夠使電力公司為用戶提供更加具有科學依據的服務方案。 表6 用戶聚類結果 2) 結果分析 將聚類后的數據進行分析整理,其結果如表7所示。從表7可以看出,電力用戶被分成了三類群體,下面對這三類用戶群體分別進行分析。 表7 用戶聚類結果提取 用戶群1:該類用戶在總用戶群中占有一定的比率,具體為40%,同時該類用戶的消費水平較高,平均月消費水平為14.76萬元;該類用戶的拖欠金額平均為3.15萬元,說明這些用戶拖欠電費比較多;該群體主要是大工業用戶群,他們的合同容量高達400 KVA,用電需求非常高;并且該類用戶群的安全意識比較高,用電匹配度高達96%。總的來說,用戶群1對電力公司而言是優質的客戶群。 用戶群2:該用戶群具有最多的數量,占總用戶數的50%。這些用戶的每月平均消費額為2.53萬元,消費水平相對是最低的;該類用戶的拖欠金額平均為0.21萬元,該類用戶的誠信水平較高,拖欠金額較少;該群體主要是工商業用戶群,他們的合同容量僅為70 KVA,用電需求不高;這些用戶的用電安全意識薄弱,因為其用電匹配度為0.88。因此,用戶群2對電力公司而言是中等的客戶群。 用戶群3:該用戶群的數量是最小的,即只占總用戶10%的數量。該類用戶的每月平均消費額為5.15萬元,消費處于中等水平;該類用戶的拖欠金額平均為2.87萬元,該類用戶的誠信水平一般,拖欠金額中等;該群體主要是農業生產用戶群,他們的合同容量為160 KVA,用電需求較高;該類用戶群的整體安全用電意識是最差的,因為用電匹配度僅為0.79。總的來說,用戶群3對電力公司而言是一般的客戶群。 根據上述方法得到最后的聚類結果,電力公司可以針對不同的用戶群制定不同的銷售方案,能夠滿足不同用戶群的需求,提高電力公司的銷售量,同時獲取更大的用戶滿意度,以此來提高整體電力公司客服效率、提高客服滿意度并減少客服開銷。 3) 聚類質量評價 為了對本文所提KGEG方法的聚類效果進行評價,本節將所提KGEG方法、層次聚類方法以及K-Means方法對電力公司信通用戶數據的仿真結果評價指標進行了對比,為了防止出現偶然誤差,本文對數據集進行了100次重復實驗,最后計算采樣數據的平均值作為最后的評價標準。通過五項指標來測試評價所提方法與其他兩類方法的聚類效果,分別為AR指標、FM指標、DS指標、CI指標以及運行時間。具體聚類指標如表8所示。 表8 用戶聚類指標 從表8可以看出,在用戶樣本數為10 000的情況下,本文所提KGEG方法的各項評價指標均要優于K-Means方法和層次聚類方法。并且,從表中還可以得出所提KGEG方法的AR指標和FM指標均要接近于1,說明所提KGEG方法能夠取得非常好的聚類效果,因為得到的聚類簇與數據原始簇非常接近。對比這幾種方法的DS指標,可以看出所提KGEG方法的結果均要低于層次聚類方法和K-Means方法,雖然與層次聚類方法的結果有些接近,但是所提方法在這3個方法中的結果值是最低的,說明所提KGEG方法的聚類后的簇的分離度要比層次聚類方法和K-Means方法聚類后簇的分離度更大,聚類效果更好。在CI指標上,所提KGEG方法明顯要優于層次聚類方法和K-Means聚類方法,說明所提KGEG方法聚類后的簇具有很好的緊湊度。但是所提KGEG方法的運行時間要高于K-Means方法,運行時間是第二長的,運行時間最長的為層次聚類方法。雖然所提KGEG方法的運行時間略長于K-Means方法,但是其余的各項指標性能都要遠遠高于K-Means方法,并且KGEG方法的運行時間只比K-Means方法高1.4 s,方法復雜度的提升是完全可以接受的。總的來說,所提KGEG方法能夠取得比其他2種方法更好的聚類效果,只是運行時間稍長。 針對電力用戶聚類問題,提出了一種聯合KG和EM的GMM方法,簡稱KGEG方法。該方法首先采用KG對復雜電力用戶文本數據進行預處理,得到聚類方法的輸入,接著采用基于EM方法的GMM聚類方法,能夠有效提高聚類的全局尋優能力。通過對給定的電力用戶數據進行仿真驗證,以標準聚類質量評價指標進行對比,結果表明所提KGEG方法相比于傳統聚類方法能夠得到更好的聚類結果、分類效果和全局尋優性能,驗證了所提方法的可行性和有效性。 由于本文在驗證時采用的數據集較小,方法的泛化能力體現不夠,所以下一階段的研究重點將使用更大數據集對所提方法進行進一步地測試驗證,另外還考慮將所提方法應用于電力公司數據分析的其他領域。2 聚類有效性評價
2.1 內部評價
2.2 外部評價
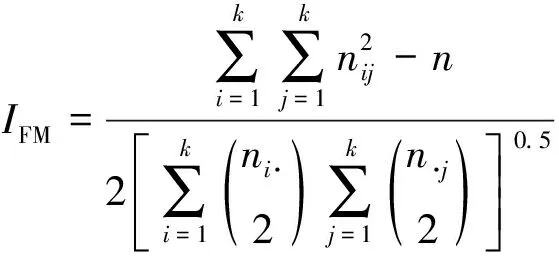

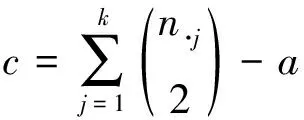
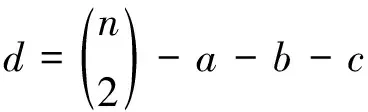
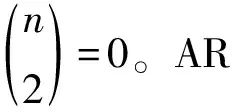
2.3 全局評價
3 應用案例分析
3.1 數據處理

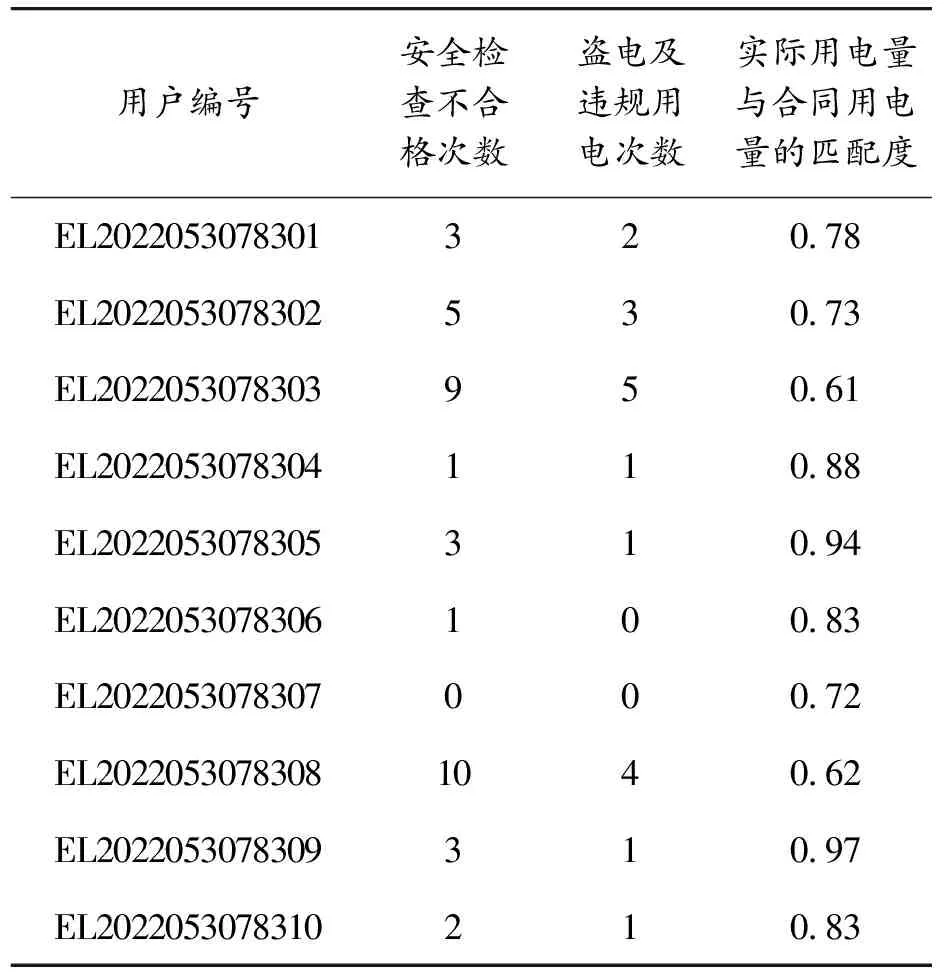
3.2 結果評價
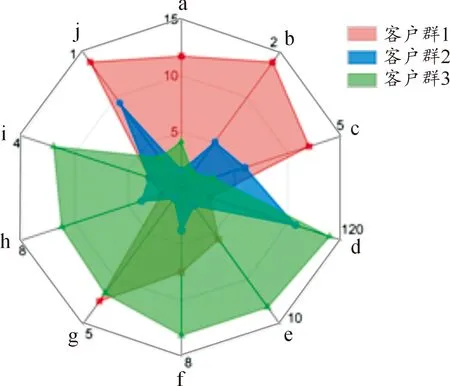

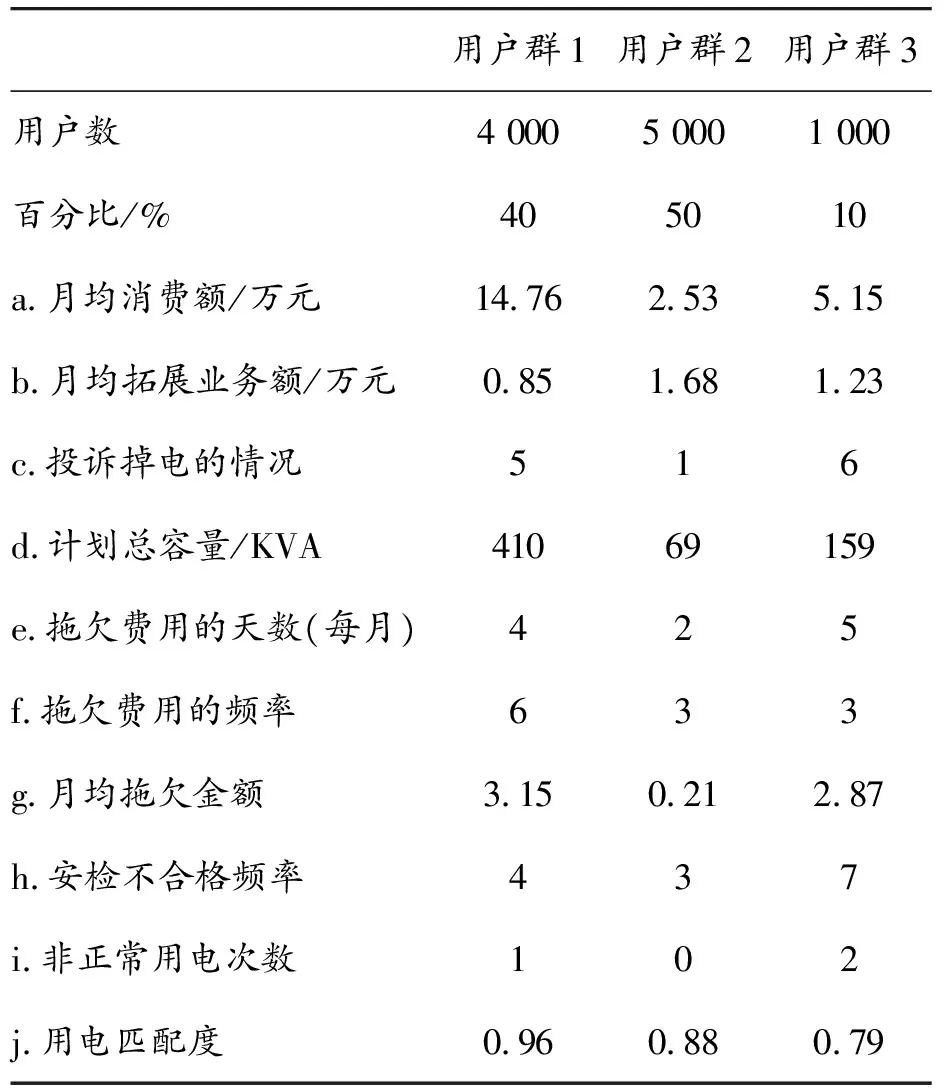
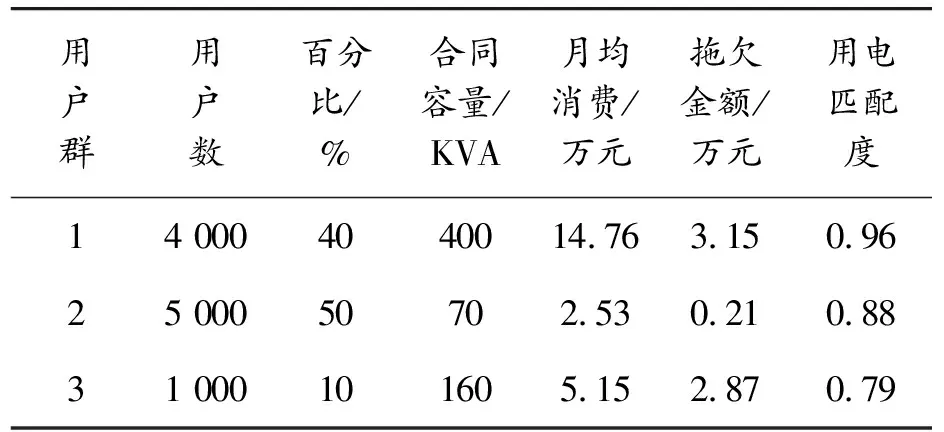
4 結論
猜你喜歡
石油瀝青(2021年4期)2021-10-14 08:50:44
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
中國教育技術裝備(2015年19期)2015-03-01 02:43:07
創業家(2015年5期)2015-02-27 07:53:25
俄羅斯問題研究(2012年1期)2012-03-25 09:54:51
