基于RPCA和LatLRR分解的紅外與可見光的圖像融合
2022-01-25 07:53:06高清維盧一相
紅外技術 2022年1期
丁 健,高清維,盧一相,孫 冬
〈圖像處理與仿真〉
基于RPCA和LatLRR分解的紅外與可見光的圖像融合
丁 健,高清維,盧一相,孫 冬
(安徽大學 電氣工程與自動化學院,安徽 合肥 23061)
紅外光和可見光圖像的融合在視頻監控、目標跟蹤等方面發揮著越來越重要的作用。為了得到融合效果更好的圖像,提出了一種新的基于魯棒性低秩表示的圖像分解與深度學習結合的方法。首先,利用魯棒性主成分分析對訓練集圖像進行去噪處理,利用快速的潛在低秩表示學習提取突出特征的稀疏矩陣,并對源圖像進行分解,重構形成低頻圖像和高頻圖像。然后,低頻部分利用自適應加權策略進行融合,高頻部分利用深度學習的VGG-19網絡進行融合。最后,將新的低頻圖像與新的高頻圖像進行線性疊加,得到最后的結果。實驗驗證了本文提出的圖像融合算法在主觀評價與客觀評價上均具有一定的優勢。
圖像融合;深度學習;潛在低秩表示;稀疏矩陣
0 引言
紅外與可見光圖像融合是為了得到信息更加豐富的圖像。如今,紅外與可見光圖像的融合在很多方面發揮著作用。尤其對軍事應用和現實監控裝置有著重要的影響。紅外圖像通過熱輻射能夠捕捉潛在目標,但是分辨率低。相反,可見光圖像能夠提供大量的主要信息,但圖像質量容易受外界環境的影響。如今,對于紅外與可見光的圖像已經有大量研究,但是很難實現融合圖像噪聲小,沒有光暈同時包含豐富的細節信息。融合的目的就是為了讓融合圖像提供兩張圖像中的有用信息以提高圖像質量,這對于人類視覺的觀察以及目標的跟蹤都十分有利。
圖像融合的方法大多是基于像素級的融合。像素級的圖像融合可以劃分為變換域和空間域的圖像融合。在變換域中常用的融合方法包括平穩小波變換(stationary wavelet transform, SWT)[1]和離散小波變換(discrete wavelet transform, DWT)[2],以及之后出現的雙樹復雜小波變化(dual-tree complex wavelet transform, DTCWT)[3],非下采樣剪切波變換(non - sampling under shear wave transformation, NSST)[4]等。但是這些方法對于圖像細節信息的利用并不足夠。空間域的圖像融合方法包括全變分最小化(total variation minimization, TV)以及加權平均法[5]。但是往往效果不是很理想。基于稀疏域的圖像融合采用學習字典對圖像進行稀疏表示。最常用的方法是基于稀疏表示(sparse representation, SR)。Lin等人提出了一種新的基于SR的圖像融合方法[6]。此外,基于稀疏表示和其它算法相結合的算法也很多,如低秩表示(low rank representation, LRR)和稀疏表示聯合[7]、NSST聯合稀疏表示[8]以及SR和脈沖耦合神經網絡(pulse coupled neural network, PCNN)[9]。但基于SR的方法中,字典的學習通常十分耗費時間。此外,常用的方法也包括基于低秩表示的圖像融合方法。Li等人提出了一種基于潛在性低秩表示(latent low rank representation, LatLRR)的圖像融合方法[10],LatLRR是一種無監督的提取方法,能夠從數據中魯棒地提取出特征,為本文的算法提供了思路。
過去的幾年,深度學習不斷興起,并且融合效果得到證明。Yu、Liu等人提出了一種基于卷積稀疏表示(convolutional sparse representation, CSR)[11]以及基于卷積神經網絡(Convolutional neural network, CNN)的融合方法[12],但是,基于CNN的方法只適用于多視角圖像融合,基于CSR的方法存在較多的噪聲,且融合后的圖像突出特征并不明顯。Prabahakar等提出了基于CNN的簡單的圖像融合算法,可是該方法的深度特征沒有得到很好的利用[12]。為了解決這些缺點,Liu等提出了一種基于預訓練網絡的融合框架[13]。首先,經過圖像分解得出源圖像的高頻分量和低頻分量。采用平均策略對低頻分量進行融合,利用深度學習框架獲得融合的高頻分量。將融合后的低頻部分和融合后的高頻部分結合起來,重建之后得出融合圖像。但是該方法的圖像分解方法十分簡單,至于深度學習的優勢沒有更好地體現出來。
為了更好地融合可見光與紅外圖像,本文提出了一種基于RPCA(robust principal component analysis)和LatLRR分解與VGG網絡結合的融合方法。為了降低噪聲對融合效果產生影響,實現更好的圖像分解效果,本文利用RPCA對訓練數據進行去噪,之后利用無噪聲的LatLRR學習得到稀疏矩陣,對源圖像進行分解重建。為了保留更多的有用的圖像信息,分解后的高頻圖像利用預訓練的融合框架VGG-19提取深層次的特征進行融合,分解后的低頻圖像利用自適應加權融合,最后將融合后的高頻圖像與低頻圖像疊加,得到最終的融合圖像。實驗結果表明,該方法不僅很好地利用了可見光圖像的紋理信息,也充分利用了紅外光圖像的特征信息,從而取得了比較不錯的融合效果。
1 相關理論
目前,常用來進行特征提取的方法為深度學習和稀疏表示[14]。Liu等人提出了利用LatLRR進行子空間聚類以及特征提取,取得了很好的效果[15]。但研究發現LatLRR模型解決方法是不唯一的,使得選擇LatLRR模型的解決方法變得困難[18]。故本文提出利用RPCA和LatLRR結合的圖像分解方法。RPCA和LatLRR是無監督的特征提取方法,經驗證可以實現很好的圖像分解效果。
1.1 RPCA對訓練集圖像去噪
PCA在噪聲較小時,效果比較好;當噪聲較大時,即使只有少部分的數據被干擾,也會使PCA的性能大大降低。針對這種現象,Wright等人提出了魯棒主成分分析(RPCA),RPCA的作用是將矩陣分解成兩個部分,稀疏矩陣和低秩矩陣[17]。只要噪聲矩陣是足夠稀疏的,不管大小都可以恢復出低秩矩陣。其模型如(1)所示:
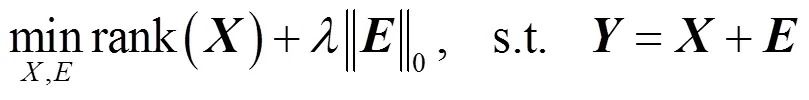
因為公式(1)是NP難的,故將式(1)松弛到如下凸優化問題(2):
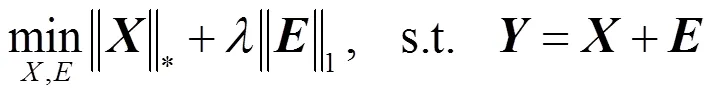
式中:為稀疏噪聲數據;為去除噪聲后的訓練數據。
1.2 無噪聲的LatLLR
在樣本數量足夠的情況下,LRR才可以很好地起作用。為了解決樣本數據不足,Liu等人提出了潛在低秩表示(LatLRR)[15]。如公式(3)所示:

式中:||||*代表核范數;代表無噪聲的數據;代表低秩矩陣;代表稀疏矩陣可以用來進行特征的提取。
2 基于RPCA和LatLRR分解的圖像融合
本文針對紅外與可見光圖像,首先,利用RPCA和LatLRR學習用于提取顯著特征的矩陣,將源圖像分解重構成低頻圖像和高頻圖像。之后,低頻部分利用自適應權重策略進行融合,高頻部分利用VGG-19網絡進行融合。最后,將新的低頻圖像與新的高頻圖像進行疊加,得到融合圖像。本文融合步驟如圖1所示。

圖1 圖像融合過程
對于輸入的源圖像I利用重疊的窗口滑動將源圖像分解成多個圖像塊。將每個圖像塊變成列向量重組成一個初始矩陣。通過公式(4)、(5)將初始矩陣分解得到高頻部分和低頻部分[10]:
=×(I) (4)
=I-() (5)
式中:代表圖像分解的次數;代表源圖像的序號;是稀疏矩陣;()代表前文提到的窗口滑動以及重組;()代表前文提到的圖像重建。
當一張源圖像經過次分解之后,得到高頻分量1:k和低頻分量。對1:k使用上文提到的窗口滑動以及重組方法進行重建,得到一張高頻圖像分量。
2.1 稀疏矩陣
本文利用RPCA和無噪聲的LatLRR訓練得到稀疏矩陣。1.2中利用RPCA得到無噪聲數據,再利用8×8滑動窗口將這些無噪聲數據分解成多個圖像塊,產生矩陣train。稀疏矩陣訓練過程如表1所示[16]。表1中的方法實驗操作簡潔,能夠實現更好的圖像分解效果。

表1 稀疏矩陣D的訓練過程
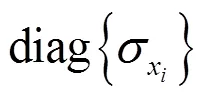
2.2 低頻分量融合
圖像的低頻部分代表圖像的主要部分,因此低頻分量的圖像融合的效果起著重要的作用[19]。雖然加權平均法和絕對值法可以達到低頻融合的目的,但效果較差。本文采用自適應加權法,利用RPCA和無噪聲的LatLRR對圖像進行分解,分解得到低頻分量1,2通過公式(6)、(7)、(8)、(9)得到低頻融合的權重1,2。
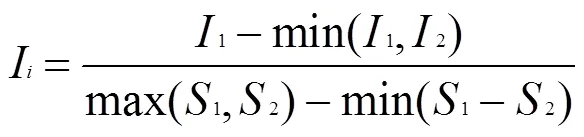



式中:S(,)=I(,)-,(,)表示圖像的像素點;表示圖像的平均像素點;={1,2}分別代表可見光和紅外圖像。I和I分別表示紅外與可見光低頻分量計算結果。
融合后的低頻圖像可以表示為(10):
I=1×1+2×2(10)
2.3 高頻分量融合
為了突出融合圖像的細節特征和邊緣部分,本文采用已經訓練好的VGG-19提取高頻圖像特征。VGG-19網絡結構中包含3個全連接層,5個池化層以及5個卷積層。通過公式(11)能夠得到VGG-19網絡的特征[20]:
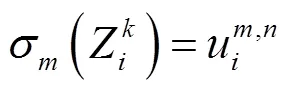
式中:(×)代表VGG-19網絡中的一層,={1,2,3,4,5},代表5個卷積組。通過如下步驟可以得到權重w。
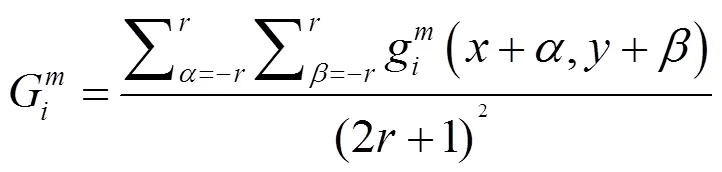

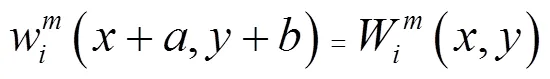
式中:,?{0,1,…,(2-1-1)},代表塊平均策略中塊的大小,本文中=1,與代表求和的窗口范圍。
本文中有5組權重矩陣w,每一組的高頻分量融合如公式(16)表示:
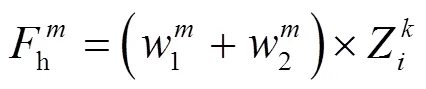
再由公式(17)選擇出融合效果最好的高頻分量融合圖。

3 實驗結果與分析
為了驗證本實驗方法的有效性和可行性,在WINDOWS 10和MATLAB 2018A的基礎上進行了4組實驗,如圖2所示。本文從TNO Image Fusion Dataset中選取6組經過配準的源圖像進行稀疏矩陣的訓練,另外選擇了4種具有代表性的圖像融合方法與本文的方法進行比較。

圖2 4組紅外與可見光源圖像
3.1 測評指標
本文選取了多層級圖像結構相似性,差分相關性之和,視覺信息保真度,特征相互信息,abf五種評價指標。
1)多層級圖像結構相似性(Multi scale structural similarity index,MS_SSIM)能更好地與人眼的視覺系統的視覺感知相一致[21]。并且在一定的尺度下,評價效果優于SSIM。公式如下:
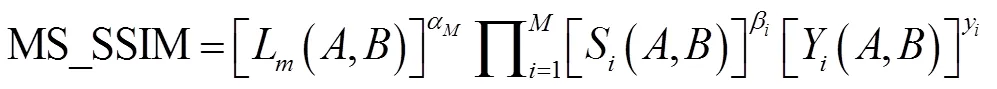
式中:(,),(,),(,)分別表示亮度比較,對比度比較和結構比較。與、分別代表該比較的重要程度。
2)差分相關性之和(difference and correlation, SCD)在圖像融合的應用中,要求融合圖像應包含盡可能多的來自輸入圖像的信息[22]。SCD反應圖像的反差大小,反差越大,則融合圖像效果越好,公式如下:
1=-2(19)
2=-1(20)
SCD=1,1)+2,2) (21)
式中:S表示源圖像;表示融合后的圖像;D表示融合圖像與源圖像之間的差異。(×)計算相關度,={1,2},分別代表紅外與可見光圖像。
3)視覺信息保真度(visual information fidelity, VIF)基于視覺信息保真度提出的衡量融合圖像質量的指標[23]。VIF越大,則圖像融合的效果就越好,可以表示為:

式中:代表圖像塊中的子帶;和分別代表參考圖像和融合圖像;(×)代表互信息量的計算。
4)特征相互信息(feature mutual information ,FMI)與質量相關的大多數信息都包含在細節信息里,并且與一些特征(如邊緣、紋理和對比度)相關[24]。FMI值越大,代表融合圖像細節信息越多,公式如下:

式中:FA與FB分別表示源圖像;A、B表示源圖像的熵值;F表示融合后圖像的熵值。
5)abf表示融合過程中人為添加到融合圖像上的噪聲比率。abf的值越小,圖像融合的效果就越好。
3.2 仿真結果及分析
本文分別選用基于離散小波(DWT)的圖像融合算法以及基于紅外特征提取和視覺信息度保存(Infrared feature extraction and visual information preservation , IFE_VIP)的圖像融合算法[27]、基于卷積稀疏表示的圖像融合(CSR)[25]以及基于交叉雙邊濾波器的圖像融合方法(Cross bilateral filter, CBF)[26]與本文提出的融合算法進行對比。DWT通過小波變換將圖像分解成高頻部分以及低頻部分,低頻部分采用均值,高頻部分采用區域能量最大值;IFE_VIP利用四叉樹分解以及貝塞爾插值提取紅外圖像背景圖,將其與可見光圖像線性疊加;CSR通過雙尺度圖像分解將圖像分解成高頻部分以及低頻部分,高頻部分利用基于稀疏表示的方法,低頻部分采用平均策略;CBF通過從源圖像中利用雙邊交叉濾波進行權值計算,直接用于源圖像的融合。從主觀角度來看,所有融合算法均達到圖像融合的目的,但融合效果卻不盡相同。
DWT的融合圖像的亮度低,細節信息損失嚴重,如圖3中的葉子。CBF融合圖像雖然亮度適中但是卻產生了黑色斑點,如圖4中圖像的邊緣以及主體部分。由于高頻分量融合步驟簡單,DWT和CBF均存在人工信息以及突出特征不明顯的問題。IFE_VIP很好地保存了背景細節和主體目標,但是人的部分存在過度增強,如圖3和圖4中人的部分。由于IFE_VIP的圖像分解能力有限,融合圖像的邊緣產生了光暈,如融合后圖5的邊緣部分。本文提出的融合算法因為使用RPCA和LatLRR分解所以融合圖像不會產生光暈,且不易受到噪聲的影響。CSR的融合圖像和CBF效果類似,產生了較大范圍的黑色斑塊或者斑點,例如圖6,CSR在融合后圖像的邊緣部分產生了黑色斑塊,CBF融合后的圖像在紋理信息處產生了很多明顯的黑色斑點。由于CSR在變換域需要融合系數,如果這些系數產生小的變化,空間域就會產生較大的變化。所以,易受到偽像的影響。本文提出的融合算法對比度適中,保留細節信息完整,沒有產生光暈,實現了更好的融合效果。

圖3 第1組仿真結果

圖4 第2組仿真結果

圖5 第3組仿真結果
但是主觀判斷誤差較大,并容易受外界影響。故本文選取了MS_SSIM,SCD,VIF,FMI,abf五種評價指標。
從圖7中可知本文提出的融合算法在FMI、SCD、MS_SSIM這3個指標上完全優于對比算法,表明本文算法得出的融合圖像與源圖像結構更相似,且包含的源圖像轉移的信息更多,細節信息也更多。在指標VIF上僅對于第3組源圖像的值略低于CBF算法,但其它組均高于對比算法。在abf指標上,遠遠低于對比算法,正是由于對于訓練集圖像進行了PRCA去噪,才會使得融合圖像的噪聲更小。

從表2中可以看出,本文提出的融合算法在FMI、SCD、MS_SSIM、VIF、abf這5種指標上,平均值均高于其他算法,說明本文算法融合后的圖像包含更多的有效信息,與理想結果更接近,得到的融合圖像更加清晰,且增加的人工噪聲更少。
表3列出了5種算法在TNO Image Fusion Dataset上運行時間的對比,雖然本文方法運行時間較長,但是融合后的圖像細節信息更加豐富、噪聲更小,融合效果更加出色。

表2 不同融合圖像的客觀評價結果

表3 不同融合方法的計算時間對比
4 結論
為了解決紅外與可見光圖像融合中細節紋理信息易丟失以及深度學習對于圖像融合方法中源圖像分解過于簡單、LatLRR的解決選擇困難等問題,本文提出了一種基于RPCA改進的LatLRR分解的紅外光與可見光的圖像融合方法。首先利用RPCA和LatLRR快速訓練得到稀疏矩陣,其次,利用稀疏矩陣與滑動窗口技術對源圖像進行分解重構,得到高頻圖像分量和低頻圖像分量。高頻圖像部分利用已經訓練好的VGG-19網絡進行特征提取,得到融合后的高頻圖像。低頻部分利用自適應加權策略,得到融合后的低頻圖像。最后,將融合后的高頻圖像與低頻圖像線性相加得到最后的融合圖像。實驗結果表明,在主觀和客觀兩方面,本文所提出的方法均具有更好的融合效果。下一步將著重于優化算法中的參數以適應多種類型圖像融合。
[1] DENG Y, LI C, ZHANG Z, et al. Image fusion method for infrared and visible light images based on SWT and regional gradient[C]//20173rd(), 2017: 976-979, doi: 10.1109/ITOEC.2017.8122499.
[2] BEN H A, Yun H, Hamid K, et al. A multiscale approach to pixel-level image fusion[J]., 2005, 12(2): 135-146.
[3] Goshtasby A A, Nikolov S. Image fusion: advances in the state of the art[J]., 2007, 8(2): 114-118.
[4] LUO X Q, LI X Y, WANG P F, et al. Infrared and visible image fusion based on NSCT and stacked sparse autoencoders[J]., 2018, 77(17): 22407-22431.
[5] MA J, MA Y, LI C. Infrared and visible image fusion methods and applications: a survey[J]., 2019, 45: 153-178.
[6] YANG J, Wright J, HUANG T S, et al. Image super-resolution via sparse representation[C]//, 2010, 19(11): 2861-2873, Doi: 10.1109/TIP.2010.2050625.
[7] 王文卿, 高鈺迪, 劉涵, 等. 基于低秩稀疏表示的紅外與可見光圖像序列融合方法[J]. 西安理工大學學報, 2019, 35(3): 8. WANG W Q, GAO Y D, LIU H, et al. Fusion method of infrared and visible image sequences based on low rank sparse representation[J]., 2019, 35(3): 8.
[8] 康家銀, 陸武, 張文娟. 融合NSST和稀疏表示的PET和MRI圖像融合[J]. 小型微型計算機系統, 2019(12): 2506-2511. KANG J Y, LU W, ZHANG W J. Pet and MRI image fusion based on NSST and sparse representation[J]., 2019(12): 2506-2511.
[9] 王建, 吳錫生. 基于改進的稀疏表示和PCNN的圖像融合算法研究[J]. 智能系統學報, 2019, 14(5): 7. WANG J, WU X S. Image fusion algorithm based on improved sparse representation and PCNN[J]., 2019, 14(5): 7.
[10] LI H, WU X, Kittler J. MD LatLRR: A Novel Decomposition Method for Infrared and Visible Image Fusion[C]//, 2020, 29: 4733-4746. Doi: 10. 1109/TIP. 2020. 2975984.
[11] YU L, XUN C, Ward R K, et al. Image fusion with convolutional sparse representation[J]., 2016(99): 1-1.
[12] Prabhakar K R, Srikar V S, Babu R V. Deep fuse: a deep unsupervised approach for exposure fusion with extreme exposure image pairs[C]//,, 2017: 4724-4732.
[13] LIU Y, CHEN X, CHENG J, et al. Infrared and visible image fusion with convolutional neural networks[J]., 2018, 16(3): S0219691318500182.
[14] WANG X Z, YIN J F, ZHANG K, et al. Infrared weak-small targets fusion based on latent low-rank representation and DWT[J]., 2019, 7: 112681-112692. Doi: 10.1109/ACCESS.2019.2934523.
[15] LIU G, YAN S. Latent Low-rank representation for subspace segmentation and feature extraction[C]//,2011: 1615-1622. Doi: 10.1109/ICCV.2011.6126422.
[16] WANG Y M, Morariu V I, Davis L S. Unsupervised feature extraction inspired by latent low-rank representation[C]//, 2015: 542-549. Doi: 10. 1109/WACV.2015.78.
[17] Wright J, MA Y, Mairal J, et al. Sparse representation for computer vision and pattern recognition[J]., 2010, 98(6): 1031-1044.
[18] ZHANG H, LIN Z, ZHANG C, et al. Robust latent low rank representation for subspace clustering[J]., 2014, 145(5): 369-373.
[19] 謝艷新. 基于LatLRR和PCNN的紅外與可見光融合算法[J]. 液晶與顯示, 2019, 34(4): 100-106. XIE Y X. Infrared and visible light fusion algorithm based on latLRR and PCNN[J]., 2019, 34(4): 100-106.
[20] LI H, WU X J, Kittler J. Infrared and visible image fusion using a deep learning framework[C]//24th(), 2018: 2705-2710. Doi: 10.1109/ICPR.2018. 8546006.
[21] WANG Z, Simoncelli E P, Bovik A C. Multiscale structural similarity for image quality[C]//, 2003, 2: 1398-140. Doi: 10.1109/ACSSC. 2003.1292216.
[22] Aslantas V L, Bendes E. A new image quality metric for image fusion: The sum of the correlations of differences[J]., 2015, 69(12):1890-1896.
[23] lantas V, Bendes E. A new image quality metric for image fusion: The sum of the correlations of differences[J]., 2015, 69(12): 1890-1896.
[24] Haghighat M, Razian M A. Fast-FMI: Non-reference image fusion metric[C]//, 2014: 1-3.
[25] LIU Y, CHEN X, Ward R, et al. Image fusion with convolutional sparse representation[J]., 2016, 23(12): 1882-1886. Doi: 10.1109/LSP.2016.2618776.
[26] Kumar B K S. Image fusion based on pixel significance using cross bilateral filter[J]., 2015, 9(5): 1193-1204.
[27] ZHANG Y, ZHANG L, BAI X, et al. Infrared and visual image fusion through infrared feature extraction and visual information preservation[J]., 2017, 83: 227-237.
Infrared and Visible Image Fusion Algorithm Based on the Decomposition of Robust Principal Component Analysis and Latent Low Rank Representation
DING Jian,GAO Qingwei,LU Yixiang,SUN Dong
(School of Electrical Engineering and Automation, Anhui University, Hefei 230601, China)
The fusion of infrared and visible images plays an important role in video surveillance, target tracking, etc. To obtain better fusion results for images, this study proposes a novel method combining deep learning and image decomposition based on a robust low-rank representation. First, robust principal component analysis is used to denoise the training set images. Next, rapid latent low rank representation is used to learn a sparse matrix to extract salient features and decompose the source images into low-frequency and high-frequency images. The low-frequency components are then fused using an adaptive weighting strategy, and the high-frequency components are fused by a VGG-19 network. Finally, the new low-frequency image is superimposed with the new high-frequency image to obtain a fused image. Experimental results demonstrate that this method has advantages in terms of both the subjective and objective evaluation of image fusion.
image fusion, deep learning, latent low rank representation, sparse matrix
TN391
A
1001-8891(2022)01-0001-08
2020-10-13;
2021-03-30.
丁健(1997-),男,安徽蕪湖人,碩士研究生,研究方向為圖像處理。E-mail: 1522523398@qq.com。
高清維(1965-),男,安徽合肥人,教授,博導,研究方向為數字圖像處理、信號處理、模式識別等。E-mail: qingweigao@ahu.edu.cn。
國家自然科學基金項目(61402004,61370110);安徽省高等學校自然科學基金項目(KJ2018A0012)。
猜你喜歡
中等數學(2022年2期)2022-06-05 07:10:50
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
小學生學習指導(低年級)(2020年6期)2020-07-25 02:31:36
現代出版(2020年3期)2020-06-20 07:10:34
小學生學習指導(低年級)(2018年9期)2018-09-26 05:59:44
瘋狂英語·新讀寫(2018年2期)2018-09-07 09:32:10
中華手工(2017年2期)2017-06-06 23:00:31
中外會展(2014年4期)2014-11-27 07:46:46
