基于圖像深度學習的牛個體的識別與統計
2022-01-22 07:21:44何欽李根嚴永煜于文靜王嶸
電子測試 2021年21期
何欽,李根,嚴永煜,于文靜,王嶸
(華東理工大學信息科學與工程學院,上海,200237)
0 引言
在傳統的養牛行業,常見的識別方法包括基于耳標的系統識別,基于圖案的標記技術,嵌入式微芯片生物標記技術[1]以及基于RFID的射頻識別系統。傳統的識別系統用于防止動物的盜竊、數量的統計、個體識別、疾病監測等一系列管理,然而這些傳統的識別方法無法阻止對動物體內嵌入標簽的復制和篡改,進而發生欺詐行為。隨著現代化養牛業的發展,通過圖像識別實現群體中個體識別及數量的統計從而實現精細化管理成為目前智能化養殖的一個新興熱點。本項目利用TensorFlow object Detection API及Intel OpenVINOTM工具套件在目標識別的快速性、便利性及高遷移性,并利用牛的特征信息改善其精確度,建立自己的數據集進行訓練,實現圖像中目標牛數量的統計及多目標的標定,目前未見相關技術應用于牛類養殖業。
1 牛類養殖行業現狀
牛養殖行業的規模在現代科技的輔助下不斷擴大,然而其監管方法卻存在著很多瑕疵。傳統方法之一的生物耳紋身及機械烙印方法不僅標記過程極為耗時而且容易丟失、損壞、可二次復制;再者,像RFID等電子標簽技術的缺陷在于電子標簽可能會遭到修改、復制,極易造成欺詐行為,降低可監管的程度。現提出的前沿技術主要有三種:視網膜血管形態、DNA測序檢測、基于生物虹膜特征的動物識別[2],由于高昂的檢測費用及虹膜數據獲取效率低下的原因,不被廣泛采用。隨著圖像處理技術的普及和發展,利用圖像識別算法輔助牛類畜牧業監管為相關企業提供了一定的借鑒作用。
2 牛個體識別與統計關鍵技術
2.1 TensorFlow
TensorFlow是目前非常流行的開源機器學習平臺。它擁有極其豐富的而全面的社區資源,且包含大量工具及不同應用方向的機器學習庫。在本項目中主要應用到了TensorFlow Object Detection技術,其發源于Google公司物體識別系統。2017年Google宣布將TensorFlow Object Detection API進行開源,幫助機器學習和計算機視覺社區進一步發展。其次,TensorFlow還提供了預訓練模型。TensorFlow預訓練模型提供了在多個數據集上完成了訓練的模型。使用該技術可以迅速的對目標對象進行標定,同時模型的訓練基于TensorFlow預訓練模型可以輕松實現目標對象的訓練。
2.2 SSD目標檢測算法
2.2.1 原理
Single Shot MultiBox Detector(SSD)目標檢測算法屬于one-stage方法,相較于two-stage方法有很大的不同:two-stage方法是先進行粗略的分劃,再對分劃后的對象進行判斷。而one-stage方法首先在圖片的不同位置進行均勻密集地抽樣,抽樣時可以采用不同尺度和長寬比,然后利用CNN提取特征后直接進行分類與回歸,整個過程只需要一步,所以其優勢是速度快,但是均勻密集采樣的一個重要缺點是訓練比較困難,這主要是因為目標與背景極其不均衡,導致模型準確度稍低。
2.2.2 設計
SSD最核心的設計理念分為三點:采用多尺度特征圖用于檢測、采用卷積進行檢測、設置先驗框。
多尺度特征圖,可以用來檢測不同大小的目標。一般最開始的特征圖尺度較大,可以用來檢測較小的目標,然后對特征圖進行處理,改變特征圖的尺度,而小的特征圖檢測大目標。其次,SSD直接采用卷積對不同的特征圖來進行提取檢測結果。對于任意大小的特征圖,采用一個卷積核進行處理,得到檢測值,然后對目標結果進行判斷。最后,SSD借鑒了Faster R-CNN中的anchor的理念,每個單元格設置了不同尺度的先驗框,預測框是以這些先驗框為基礎的,可以在一定的程度上減少訓練難度。一般情況下,針對不同的對象,有不同形狀的先驗框。
在SSD中對于每個單元的先驗框都輸出一套獨立的檢測值,對應一個邊界框。檢測值分成兩個部分,第一個部分是各個類別的置信度,特別的是,SSD將背景也看做一個特殊的類別,如果檢測目標共有n個類別,SSD需要對每個先驗框預測n+1個置信度,其中第一個置信度代表的是先驗框內容為背景的評分。第二部分是邊框的位置,邊框包含四個元素(cx,cy,w,h),分別代表了邊框的中心坐標、寬和高。先驗框用表示,其對應邊界框那么,邊界框的預測值l是b相對于d的轉換值:

一般我們將其稱為編碼,當得到了預測值的時候需要反向這個過程,稱為解碼,即從預測值和先驗值推出邊框的真實位置:
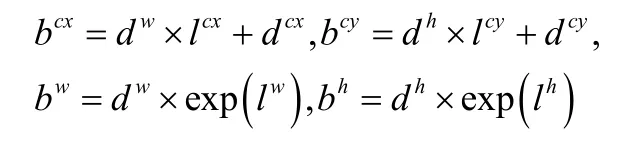
2.3 OpenVINOTM工具套件
OpenVINOTM工具套件是英特爾于2018年發布的主要用于計算機視覺實現神經網絡模型優化和推理計算加速的軟件工具套件。該工具套件基于最新一代的人工神經網絡,可擴展跨英特爾?硬件的計算機視覺和非視覺工作負載。OpenVINOTM主要包括用于優化神經網絡模型的工具Model Optimizer和用于加速推理計算的軟件包Inference Engine。如圖1所示。

圖1 OpenVINO?工具套件
當模型訓練完畢,導出TensorFlow凍結圖模型文件(*.pb文件),接著使用工具套件中的Model Optimizer工具優化凍結圖模型。Model Optimizer工具是一個跨平臺命令行工具,可將經過訓練的神經網絡模型執行多項優化。優化完畢后會將模型從源框架轉換為與nGraph兼容的中間表示(IR文件)。IR文件包含兩個文件,一個是描述神經網絡拓撲結構的*.xml文件,另一個是儲存模型權重參數的*.bin文件。優化過后的模型在不影響精度的情況下,在英特爾的多平臺硬件上可以更快的執行。
獲得IR文件后,就可以使用Inference Engine來完成推理計算。Inference Engine其本質為一組C++/Python API函數,依靠該函數組,可以實現初始化AI推理計算硬件,同步或者異步加載經過優化后的神經網絡模型及執行推理計算并返回推理計算的結果。
3 牛個體的識別與統計
3.1 環境
本文所有工作在以下環境中完成:
Windows 10(64 bit),Ubuntu 20.04,labelImg Windows_v1.8.0,TensorFlow Obeject Detection API r1.13.0,OpenVINO 2021.2,Cmake V3.4,CPU為 intel i7-10875H;GPU為Nvidia RTX 2070s
3.2 數據集的收集及標注
原始圖片一部分來源于Kaggle數據集,一部分來源于現場拍攝。圖片清晰,噪點較少,且包含牛個體不同角度的照片,部分圖片中牛的數量多于1頭,在后期的時候都需要進行標注。在標注前需要進行準備工作,將圖片按照順序標號同時轉換為標準RGB通道格式。原始數據如圖2所示:

圖2 原始圖片數據集
其次進行標注工作,本項目使用LabelImg軟件進行標定。提前預設標簽,在圖片數據集中將目標進行人工標記,如圖3所示。在完成所有圖片的標記之后每張圖片會自動生成xml文件,其中包括目標檢測對象在圖片中的位置和標簽信息。
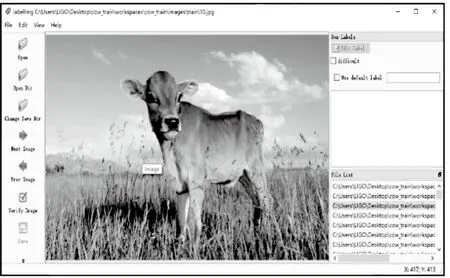
圖3 圖片標記過程

圖4 圖片標記典型流程

圖5 xml文件標記信息
數據集中用來訓練的圖片和用來作驗證的圖片比例為8:2,本項目訓練數據集為812張,測試數據集為208張。
3.3 使用TensorFlow訓練模型
3.3.1 數據集的轉換
TensorFlow推薦使用TFRecord格式文件向TensorFlow模型輸入訓練數據,該數據結構下訓練速度最快、效率最高。TensorFlow內核很多的數據處理機制都是基于TFRecord文件做的優化。TFRecord格式文件是TensorFlow定義的二進制文件,基于Google Protocol Buffers這個跨平臺跨語言序列化結構數據的協議標準。其擴展名為*.tfrecord。因此為了提高訓練效率,需要將xml文件轉換為csv文件進行過渡,然后將csv文件轉換為tfrecord文件。
csv主要是將xml中的信息進行整合,其內容包括:圖片文件名Filename;圖片寬度Width;圖片高度Height;標注Class;坐標的起始位置和終止位置Xmin、Ymin、Xmax、Ymax。如圖6所示。

圖6 csv文件提取xml文件內容
在得到csv文件后,將其轉換為tfrecord文件即可作為標準輸入文件,輸入目標檢測網絡進行訓練。
3.3.2 基于預訓練模型進行模型訓練
本項目使用的預訓練模型網絡為ssd_inception_v2_coco,結合SSD目標檢測方法[3]和inception特征提取網絡對原始數據集進行訓練。在訓練之前需要設置訓練參數,為了更有效率的完成訓練,本項目采取TensorFlow-gpu進行基于GPU的訓練。
本次實驗參數的設置為:Batch_size為6,訓練步數為5000步。在訓練過程中可以使用TensorFlow的可視化工具tensorboard對相關參數進行監控和調整。主要關注的參數為Loss虧損函數,主要用于描述訓練的模型參數同真實值之間的差異,在訓練過程中會隨著訓練步數的增加而減小,其值越接近于0說明其訓練效果越好。
在訓練完成之后得到model.ckpt.data-00000-of-00001、model.ckpt.index和model.ckpt.meta文件。這三個文件一起構成TensorFlow和Checkpoint文件,是訓練過程中保存的模型變量、模型權重等重要參數。當模型訓練完畢后需要執行Frozen操作,將所有變量的值提取出來變成常量,同模型權重一起合并為一個*.pb文件作為后期推理計算的模型文件。
3.3.3 Loss函數
Loss函數作為模型訓練中的一個重要參數,可以通過其數值大小來反映訓練效果。SSD算法中的損失函數定義為位置誤差(localization loss,loc)與置信度誤差(confidence loss, conf)的加權和[4]:

其中,N為符合先驗框的樣本數量,c為類別置信度預測值,l為邊界框的預測值,α為權重系數,設置為1,g為真實框的位置參數。
同時SSD采用Smooth L1 loss方法計算位置誤差:
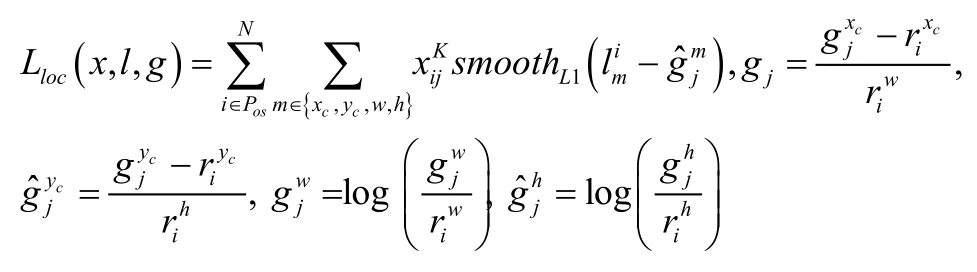
采用softmax loss表示:

其中,Neg代表負樣本集。
通過TensorFlow自帶的tensorboard可以將該過程可視化,隨時監控訓練的過程,如圖所示。在經過10000步迭代后loss值約為1.37。

圖7 classification_loss變化趨勢

圖8 locallization_loss變化趨勢

圖9 TotalLoss變化趨勢

圖10 clone_loss變化趨勢
3.4 使用OpenVINOTM進行模型優化
當模型訓練完畢,可以導出TensorFlow凍結圖模型文件(*.pb文件),接著使用OpenVINOTM中的Model Optimizer工具優化TensorFlow凍結圖模型,獲得模型的中間表示(IR)。IR模型包含兩個文件,一個是描述神經網絡拓撲結構的*.xml文件,另一個是儲存模型權重參數的*.bin文件。經過該工序優化過后的模型,在不影響精度的情況下,在英特爾的多平臺硬件上可以更快的執行,為之后的硬件實現提供基礎。
3.5 可視化測試結果
在模型優化完畢后,可在基于Intel的平臺之間通用。從測試結果可以看出模型還是具有相當好的泛化效果。經過完整的測試,本次訓練的模型識別精度較低,并不是特別理想。由于識別過程對背景、圖片的清晰度有一定的要求,且牛群相互遮擋時的識別效果不佳,總體的識別率還是有待提高,后期的改進措施應提高訓練步數至150k乃至300k步迭代,其次通過圖片的變換豐富原始數據集,得到更好的訓練模型。

圖11 牛個體檢測示意圖1

圖12 牛個體檢測示意圖2
3.6 基于Nvidia Jetson nano 和Intel NCS 2的硬件實現
Nvidia Jetson nano是Nvidia推出的GPU運算平臺,可以做為嵌入式設備實現推理。Intel Neural Compute Stick 2 (NCS2) 是Intel公司推出的邊緣側推理加速設備。本項目引入Nvidia Jetson nano和Intel NCS 2,將上述部分的所有環境移植到Ubuntu 20.02系統中實現了基于視頻流的牛個體識別與檢測,為相關企業提供了基于圖像處理的監管方案。
4 總結
本文從圖像處理角度為牛養殖業提出了新的監管手段,基于TensorFlow框架和OpenVINOTM實現了牛個體的識別與統計,為大規模畜牧業養殖的監管提出了新的解決思路。在該構想的實現過程中也有很大的改善空間,如牛群遮擋狀況下的識別,以及超大規模的牛群識別等。John Hopkins大學提出了使用殘差網絡估計大密度人群[5],下一步研究的方向集中于如何利用殘差提取網絡對超大規模的牛群實現識別,進一步提高技術的效果與可用度。綜上,為了更好的將圖像識別技術應用于畜牧業養殖過程中,需要軟硬件協同工作,綜合利用各種方法的優缺點,最終達到最佳的識別效果。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
房地產導刊(2022年5期)2022-06-01 06:20:14
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
