面向SSL VPN加密流量的識別方法
2022-01-22 07:46:26王宇航姜文剛翟江濤史正爽
計算機工程與應用 2022年1期
王宇航,姜文剛,翟江濤,史正爽
1.江蘇科技大學電子信息學院,江蘇 鎮江 212003
2.南京信息工程大學智能網絡與信息系統研究院,南京 210000
3.愛丁堡大學信息學研究院,愛丁堡 EH8 9YL
互聯網技術的高速發展,在為人們生活帶來便利的同時,也會被一些犯罪分子用于不法傳輸,這對網絡空間的穩定性及安全性產生了極大的影響,使得網絡安全問題越來越受到人們的關注,因此,全球加密網絡流量不斷飆升。雖然流量經過加密后再傳輸,使得傳輸數據的安全性得到保障,但也為流量的審計增加了難度。
常用的VPN 技術有MPLS VPN、IPSEC VPN、SSL VPN三種。MPLS VPN主要應用在路由器和交換機等設備上,IPSEC VPN 是IPSec 協議在VPN 上的一種應用,SSL VPN 屬于應用層VPN 技術。相比于前兩種在使用上更加便捷,這使得SSL VPN 在安全傳輸中得到了廣泛使用,但這也使得一些惡意流量有了可乘之機。一些非法應用利用SSL VPN來繞過防火墻等安全設施的檢測。因此,對SSL VPN 加密流量的有效識別對網絡信息安全具有重要意義。
Shen等人[1]通過增加Markov鏈的狀態多樣性,來建立二階Markov 鏈模型從而對HTTPS 應用進行識別。程光等人[2]采用相對熵區和蒙特卡洛仿真方法結合實現加密流量和非加密流量的識別,取得了不錯的識別效果。Lotfollahi 等人[3]采用卷積神經網絡模型對流量進行分類。趙博等人[4]利用加密數據的隨機性特點,對網絡報文逐一實施累積和檢驗,最終,實現了對加密流量的普適識別。目前,對加密流量分類的相關文獻取得不錯的成果。
針對SSL 流量的識別常采用機器學習的方法和指紋識別的方法,文獻[5]對SSH 流量的識別問題展開研究,提出了一種SSH 流量識別方法。該方法基于SSH協議建立連接階段的特征,對使用SSL 協議的流量進行識別。文獻[6]采用簽名和統計相結合的方法,選擇了13 個特征字段和14 個流屬性,通過C4.5,Naive Bayesian 和SVM 等多種機器學習算法,對SSL 協議流進行識別。
流量識別研究大多圍繞對某種協議流量的識別展開,針對VPN 流量識別的研究尚不足。西佛羅里達大學[7]的研究人員對文獻[8]發布的數據集開展深一步的研究,比較了Logistic回歸、樸素貝葉斯、SVM、KNN、RF和GBT 方法的識別效果,并對算法參數進行了相應的優化,最終VPN 流量達到了90%以上識別率。王琳等人[9]提出一種將指紋識別與機器學習方法相結合識別SSL VPN流量,雖然取得了91%以上的識別率,但是該方法需要手工提取流的特征。
本文在現有研究基礎上,提出一種基于Bit 級DPI和深度學習的檢測方法,分兩步實現SSL VPN 流量的識別。先使用本文提出的一種新的基于Bit級DPI的指紋生成技術——位編碼,通過將流的少量初始位與生成的位指紋匹配,來判斷當前數據包是否使用SSL 協議、當前數據流是否為SSL 流。對于第二階段的SSL VPN 流量識別,本文提出了一種基于注意力機制的改進的CNN網絡流量識別模型,并與一般的CNN模型進行比較。實驗結果表明,本文提出的方法不僅有效解決了SSL 加密流量指紋識別方法存在的漏識別率較高的問題,同時改進后的深度學習模型,能提取網絡流量中具有非常顯著性的細粒度的特征,從而更加有效地捕捉網絡流量中存在的依賴性,識別模型具有良好的實驗效果。
1 相關工作
1.1 DPI識別技術
深度包檢測技術(deep packet inspection,DPI)采用匹配特征字段對網絡流量進行識別[10]。許多基于DPI的檢測方法使用有效負載內容生成特定于應用程序的指紋。DPI可快速準確地識別指紋庫存在的流量,但也存在著致命的缺陷,DPI 識別依賴于應用協議特征字段,無法識別協議交互階段加密數據和私有協議[11]。但本文提出了一種基于Bit 級DPI 的指紋生成技術,用于快速篩選識別SSL協議流量,發揮了DPI識別速度快的優點,對識別模型預處理過程有很大的作用。
1.2 SSL協議
SSL(安全套接字協議)在傳輸層與應用層之間對網絡連接進行加密,是一種為主機間通信提供安全的協議。SSL 協議由握手協議、記錄協議、更改密文協議和警報協議組成,如圖1所示。
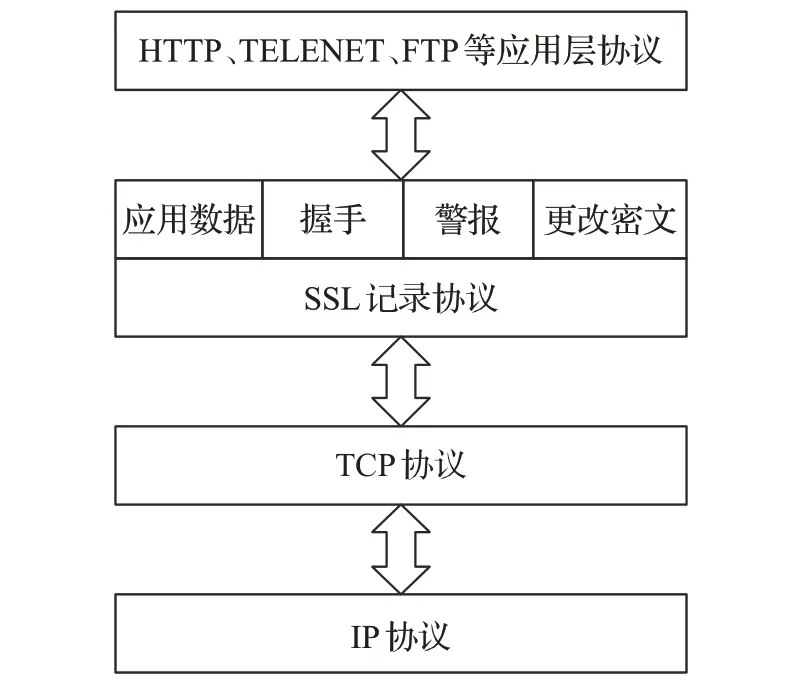
圖1 SSL協議位置與組成Fig.1 SSL protocol location and composition
握手協議是SSL協議中十分重要的協議,是在應用程序的數據傳輸之前使用的。該協議允許服務器和客戶機通過握手相互驗證,在這一過程中雙方需要確認密鑰和算法,同時還要協商信息摘要算法、數據壓縮算法等。在握手協議結束后,雙方開始加密數據的傳輸。握手協議的通信流程如圖2所示。
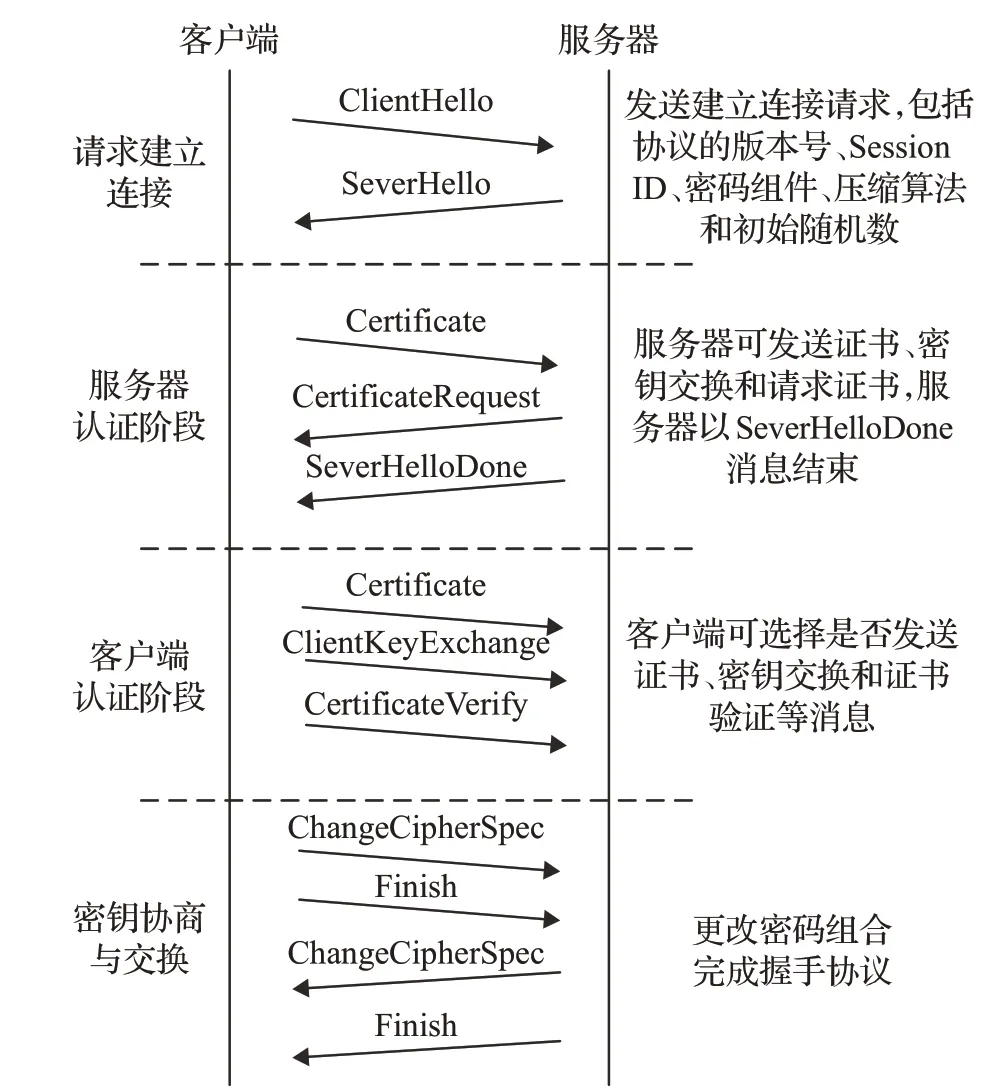
圖2 握手協議的通信流程Fig2 Flow of handshake protocol communication
1.3 卷積神經網絡
卷積神經網絡(convolutional neural network,CNN),是深度學習的代表算法之一,提供了一種端到端的學習模型。這一深度學習網絡模型相較于傳統的其他模型存在以下優點:
網絡中的神經元采用稀疏連接的方式,而非像一般神經網絡的神經元采取全連接的方式。達到了降低參數的數量的目的,方便網絡結構模型的擴展和模型的訓練。
采用參數共享,其過程就是針對每個神經元與前面層次的所有連接都貢獻權重值,這樣也能夠進一步的減少訓練的參數數量[12]。
利用池化操作獲取更具代表性的特征值,同時降低了參數的數據量信息。有利于后面模型的訓練卷積神經網絡能自動從學習樣本中很好的學習原始數據中的特征,并完成對數據特征的提取與分類,無需像機器學習那樣人工設計特征。
1.4 注意力機制
注意力模型最近幾年在圖像處理、語音識別、自然語言處理等領域得到廣泛應用,其核心目標是從眾多信息中選擇出對當前任務目標更關鍵的信息,增加感興趣區域,抑制無用信息。因此,本文將注意力機制引入到CNN 模型當中,用來提取序列中非常顯著性的細粒度的特征,實現短期的有效提取。從而優化輸入信息,達到提升模型分類能力的目的。
注意力機制可分為,硬注意力(hard attention)及軟注意力(soft attention)。硬注意力核心的原理在于直接限制深度學習模型當中輸入內容的這種處理方法,但是在時序預測的相關領域相對來說并不是完全適合[13]。同時硬注意力是一個隨機的預測過程,更強調動態變化。其訓練過程往往是通過增強學習來完成的,且后期模型訓練難度較大,導致模型的通用性比較差。與硬注意力機制不同,軟注意力是確定性的注意力。學習完成后,可以通過神經網絡得到注意力的權重,直接加權全局上的信息作為輸入特征。軟注意力機制更關注區域或者通道,最關鍵的地方是軟注意力是可微的,可以很好地與一種端到端的學習方式相結合。
基于以上分析,本文將軟注意力機制引入到一維卷積神經網絡當中。采取對輸入特征逐個加權的方式,達到關注特定空間和通道目的。最終,對時間序列上細粒度的顯著性特征進行提取,從而完成對網絡流量中存在的依賴性的有效捕捉。
2 基于Bit級DPI的SSL加密流量識別
SSL握手協議采用明文傳輸的形式,因此可以利用解析PCAP文件得到的數據包的頭部信息,判斷出當前數據包為何種SSL 握手協議的消息類型。一個完整的握手協議,其通信過程一定包含ClientHello、SeverHello、SeverHelloDone、ClientKeyExchange、ChangeCipherSpec類型的消息。基于傳統的DPI 檢測技術若某數據流中未能全部包含以上5 種類型的消息,則判斷為非SSL流。當數據流中只檢測到部分類型信息時,可能是自身握手協議建立不成功,或者是抓取數據包時存在漏包的情況。然而在實際抓取數據包時,設置確定截斷時間,會存在一個流雖然是SSL 流,但并不是從開始截取的,而是從其他傳輸階段截取的。這時,基于傳統的DPI檢測技術會因為沒有檢測到SSL握手協議的消息,將其判定為非SSL 流,因此,會產生漏識別的情況。為了解決這一問題,本文提出一種基于Bit 級DPI 的SSL 加密流量識別。
SSL 加密的數據包根據其消息類型的不同,有不同的消息格式,但其前5 個字節的格式是固定的,分別表示通信的階段(握手(Handshake)、開始加密傳輸(ChangeCipherSpec)還是正常通信(Application)等),SSL 協議版本號和剩余包長度[2],如表1 所示。基于位級DPI的SSL加密流量識別方法,僅使用來自TCP數據段的少量初始位,并將不變位標識為位指紋。隨后,對這些指紋進行編碼,將其轉換為狀態轉換機,用來識別SSL流量。這種方法擴大了SSL流識別的范圍,不僅能夠識別SSL握手階段的流,同時也能識別數據傳輸階段的SSL流。

表1 協議前5個字節格式Table 1 First five bytes of protocol format
整個識別過程分為以下幾個部分:
(1)重構流
網絡流由兩個主機之間交換的一系列數據包組成。這兩個主機由兩個唯一的IP 地址標識。共享相同5 元組的所有包都是流的一部分,依據相同的5元組信息對流進行重構,從而將所有數據包(流內)的有效載荷數據都被獲取并連接起來,用作后續指紋生成階段的輸入。
(2)位指紋生成
位編碼使用前一階段選擇的有效載荷的不變位集生成應用程序特定的位指紋。假設訓練集中存在L(L∈I)個SSL流,它從SSL的L個流中各收集前n位,并為SSL流生成n位位指紋。第h個流(1 ≤h≤L)的前n位為f1h,f2h,…,fnh。L個流都被提取都用于生成如下位指紋。每個流提取的第k位[1,n]位置用來決定SSL流的第k個指紋位。指紋創建過程如下所示,其中每個Si是一個指紋位:

如果每個流的第k位(1 ≤k≤L)的值都為0,k指紋位設置為0,如果每個流的第k位(1 ≤k≤L)的值為1,k指紋位設置為1。如果這些位的位置中有0位和1位,則第k個指紋位設置為“^”。圖3 顯示了SSL 流的位指紋生成過程,在這個示例中,有3 個流,每個流有15 位,用于指紋生成。

圖3 生成位指紋Fig.3 Generate bit signature
(3)運行長度編碼
指紋位由1 位、0 位和^位組成,每個指紋為n位。為了有效地表示、存儲和比較,對這n位進行了運行長度編碼(RLE)。RLE 是一種用于無損數據壓縮的技術。RLE 通過指定重復次數來減少重復字符串的大小。在RLE中,數據的運行是指在許多連續數據元素中具有相同數據值的序列存儲為單個值,并存儲該數據值重復的次數計數。例如,它的位值是1111111000000^^^^111,在使用RLE編碼之后,它被轉換為7O6Z4^3O顯示狀態。
(4)狀態轉換機器創建
經過第(3)步驟之后生成一個編碼指紋,將經過編碼的位指紋轉換成狀態轉換機。然后與需要的網絡流量流進行比較,以識別應用程序。狀態轉換機的定義如下:

用20 位指紋(11111111000000^^^111,編碼指紋為8O6Z3^3O)生成的示例狀態轉換機如圖4 所示。在狀態轉換機中有5種狀態,從q0到q4,q0是開始狀態,q4是結束狀態。每個狀態都有一個計數器(C0到C4),每次轉換訪問該狀態時,該計數器都會被初始化為一個新值。機器在q0狀態下啟動,將q0的計數器設置為0,從測試流中讀取比特,并進行允許的轉換以達到最終狀態。狀態轉換機的轉換有一個輸入符號(位值)和一個對計數器值的約束,計數器值充當保護,只有當約束被滿足(評估為true)時,才允許轉換。
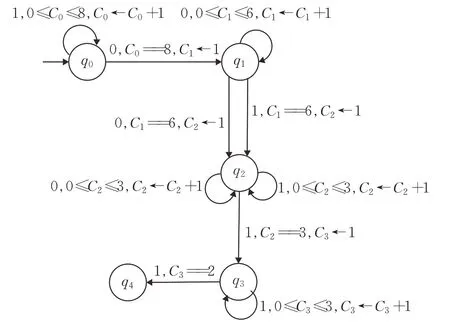
圖4 生成狀態轉換機Fig.4 Transition machine of generating state
在圖4中,狀態q0在輸入1上定義了一個到自身的轉換。這個轉換對C0的計數器值有一個約束,它在0到8之間。這個約束映射了在開始時在流中讀取8個連續的1 要求。從q0到q1的轉換是在輸入0 上,只有當C0處的計數器值為8時才有效(已經讀取了8個連續的1),并將q1處的計數器C1設置為1(在8 個連續的1 之后讀取0)才有效。無論何時在指紋中有^,它將有兩個轉換,一個是輸入0,另一個是輸入1,這兩個轉換都將增加計數器值。
(5)識別SSL流
與狀態轉換機匹配的簽名過程如圖5 所示。與簽名生成過程類似,在這個階段也存在重構該流,數據流的前n位被提取出來作為輸入(從第一個位到最后一個位,每次一個位),來自測試流的n位將提供給SSL狀態轉換機。SSL狀態轉換機進行了允許的轉換,如果數據流能達到SSL 狀態轉換機最終狀態,則流被標記SSL流;如果沒有達到最終狀態,則標記為非SSL流。
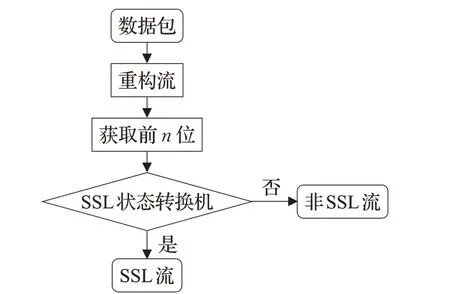
圖5 匹配狀態轉換機Fig.5 Transition machine of matching state
以位序列11111111000000101111 和001111110000 00101111。第一個序列作為輸入提供11111111000000 101111 給圖4 狀態轉換機,很容易看到它到達最終狀態,因為它以8個1開始,接下來是6個0,隨后三位0或1都行,最后三位數是1。然而,第二個序列不被狀態轉換機接受,因為它從0開始,并且當計數器C0在狀態q0下為0時,不存在與輸入0的轉換。
3 基于注意力機制的改進CNN 網絡流量分類識別模型
3.1 基于注意力機制的CNN結構
在本文中注意力機制模塊引入到一維CNN 中,包含特征的聚合和尺度恢復兩個部分。特征聚合主要是采用多層次的卷積和池化層次的堆疊,從跨尺度的子序列中提取出細粒度的顯著性的特征,最后一層上則用來挖掘其中的線性關系。尺度恢復指是將關鍵性的特征直接恢復到與網絡模型中的CNN模塊的輸出保持一致。為將數值直接保持在0~1 之間,采用Sigmoid 函數。最后將獲得的上下文特征,作為實際的基礎性的顯著性特征。
令xi∈Rk,也就是用k維向量表示數據流中的第i個流量字節,一個長度為n的數據流的定義如下:

xi:j為流量字節的連接結果,卷積操作由一個過濾器或卷積核構成,w∈Rhk,過濾器的窗口寬度為h,過濾器對一組流量字節操作一次,就輸出一個新的特征CI。具體操作如下:
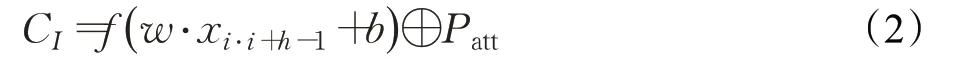
其中,Patt為注意力機制的權重,b為偏置項,f是ReLU的非線性函數。過濾器將在每個可能的流量字節窗口進行操作,產生一個特征映射。時序最大池化操作,在特征映射上找到最大值,最終輸出對應輸入在每一類輸出上的概率分布。
基于注意力機制的CNN 結構,由于將原本的CNN的輸入替換為注意力模塊支路輸入,并采用堆疊深層卷積和池化層的方式,所以擴大了特征對應的輸入感受野。這樣有利于捕捉網絡流量中存在的依賴性,從而學習當前局部序列特征的重要程度。通過引入注意力模塊,能夠提高重要時序特征的影響權重,抑制非重要特征時序的干擾,因而有效解決了模型無法區分時間序列數據重要程度的差異性的問題。
3.2 基于注意力機制的改進CNN 網絡流量分類識別模型
本文提出的基于注意力機制的改進CNN網絡流量分類識別模型如圖6所示。模型包含數據預處理、模型訓練和模型測試3個階段。
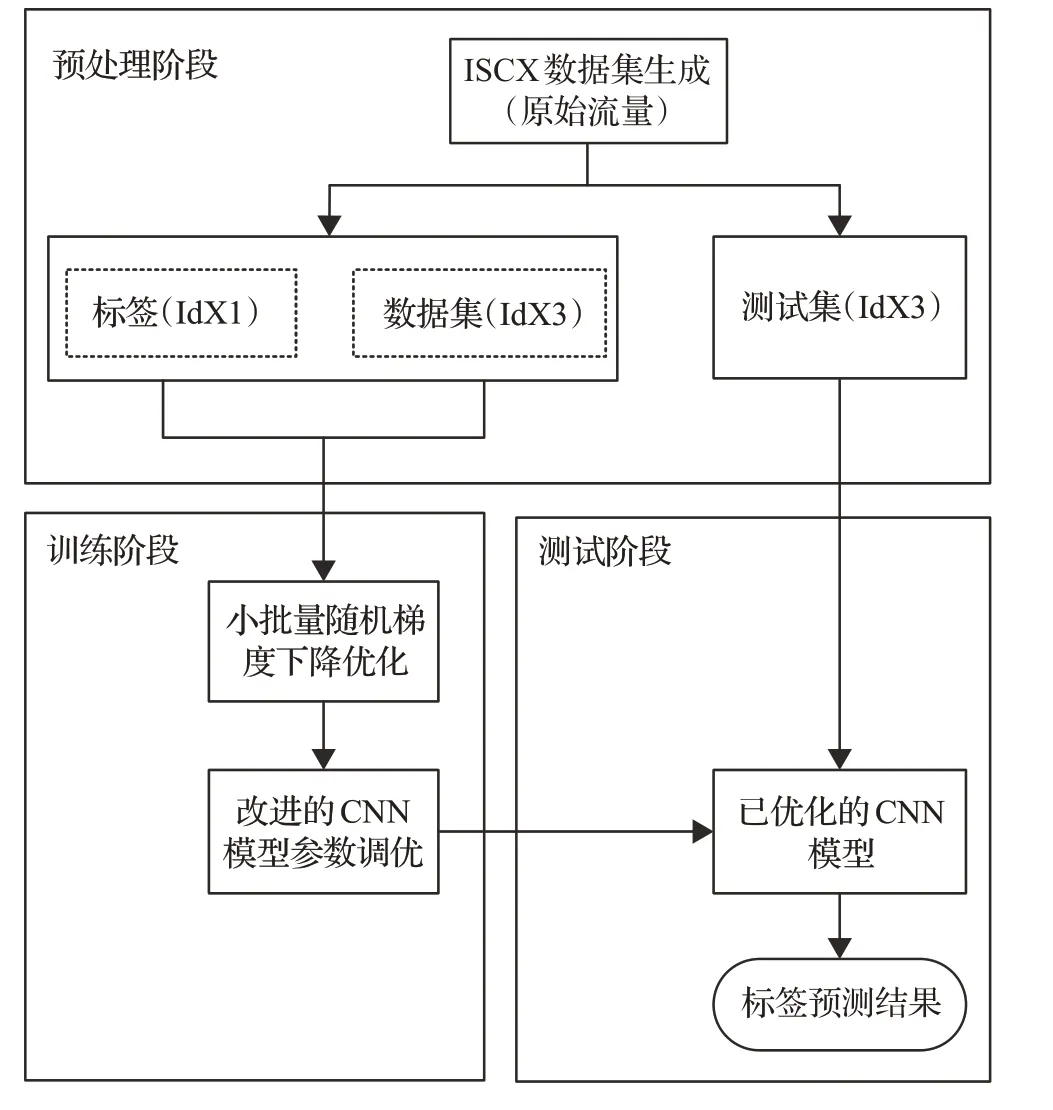
圖6 改進的CNN網絡流量分類識別模型Fig.6 Improved traffic classification and recognition model of CNN network
數據預處理階段:將數據集中的原始流量進行預處理,得到CNN 模型輸入所需的數據格式文件。這里使用的王偉博士開發的USTC-TK2016,包括流量切分、流量清理、圖片生成、IDX轉換4個步驟[13]。流程全過程如圖7所示。
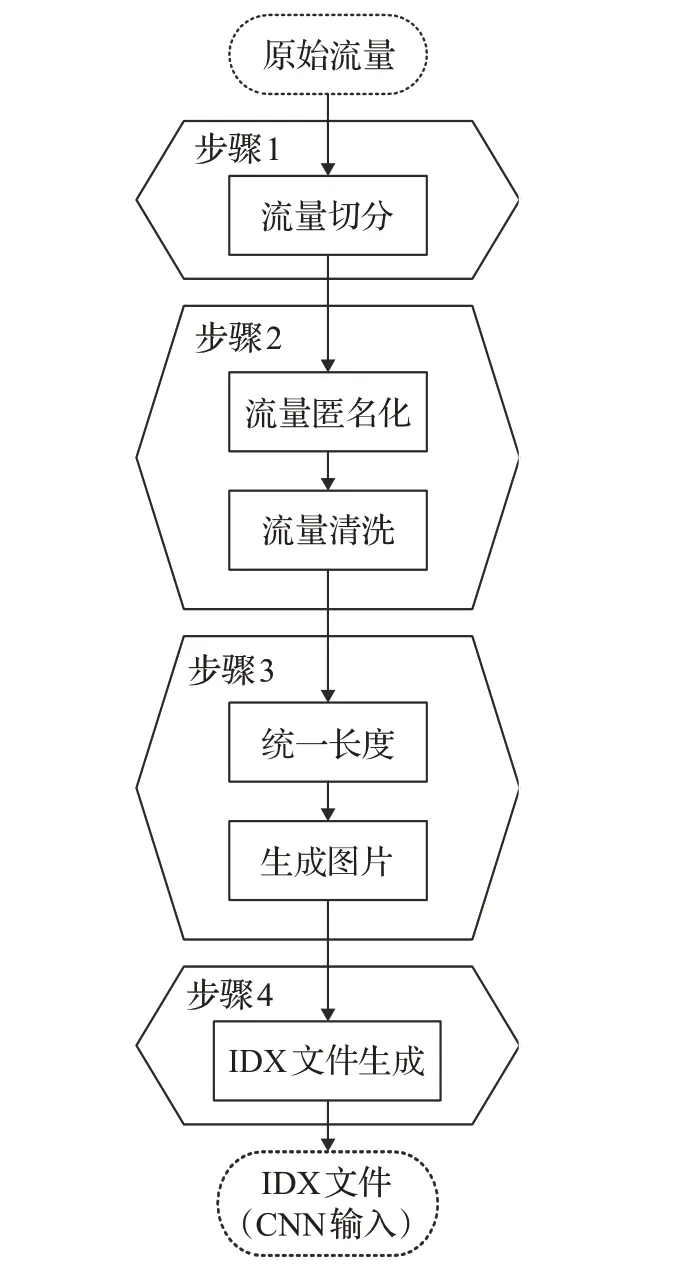
圖7 網絡流量數據預處理流程圖Fig.7 Flow chart of network traffic data preprocessing
訓練階段:使用上一階段處理得到的流量數據(IDX3 格式)和標簽數據(IDX1 格式)訓練改進的CNN模型,訓練方法是最小批隨機梯度下降技術。為使模型具有良好的泛化能力,訓練采用10 折交叉驗證技術。最終,得到的改進CNN 模型作為測試階段使用的模型。
測試階段:使用訓練階段得到改進的CNN模型數,對數據預處理階段輸出的IDX3格式的測試數據進行類別預測,得出最終分類結果。
其中,在數據預處理階段的圖片生成步驟,每個流量結果樣本可以表示成28×28 像素的灰度圖,結果如圖8 所示。從流量可視化的結果看,大部分圖片之間還是很容易區分的。SSL VPN 流量的黑色部分主要集中在底下部分,而非SSL VPN 流量的黑色部分主要集中在底部1/4 處。因此二者之間的區分度較為明顯,可以推測,使用CNN 模型對其進行分類應該能夠取得良好效果。

圖8 可視化結果Fig8 Visualization results
4 實驗結果及分析
4.1 實驗數據集
本文采用的數據集是Lashkai等人[14]在2016年發布的VPN-nonVPN數據集,共包含28 GB數據。該實驗室的官網對數據集進行了詳細介紹,并提供下載,不同類別的流量生成方式如表2所示。

表2 實驗數據集Table 2 Experimental data set
4.2 SSL流識別結果
SSL加密的數據包雖然有不同的消息格式,但其前5個字節的格式是固定的。分別表示通信的階段(握手(Handshake)、開始加密傳輸(ChangeCipherSpec)還是正常通信(Application)等)、SSL 協議版本號和剩余包長度[9]。因此,本文選定SSL流數據包的前40位生成指紋將壓縮后,生成狀態轉換機,用以識別SSL 流。由于傳統的SSL 加密流量指紋識別方法在沒有檢測到完整的SSL 握手協議的消息,就會將其判定為非SSL 流。本文在此基礎上提出了基于Bit級DPI的SSL加密流量識別技術,有效地解決了傳統SSL 加密流量指紋識別方法存在的漏識別率較高的問題。除Vimeo 等少數流量識別率未到97%外,其余應用的SSL 流識別率均達到99%以上,與傳統SSL 識別方法的實驗結果對比如圖9所示。
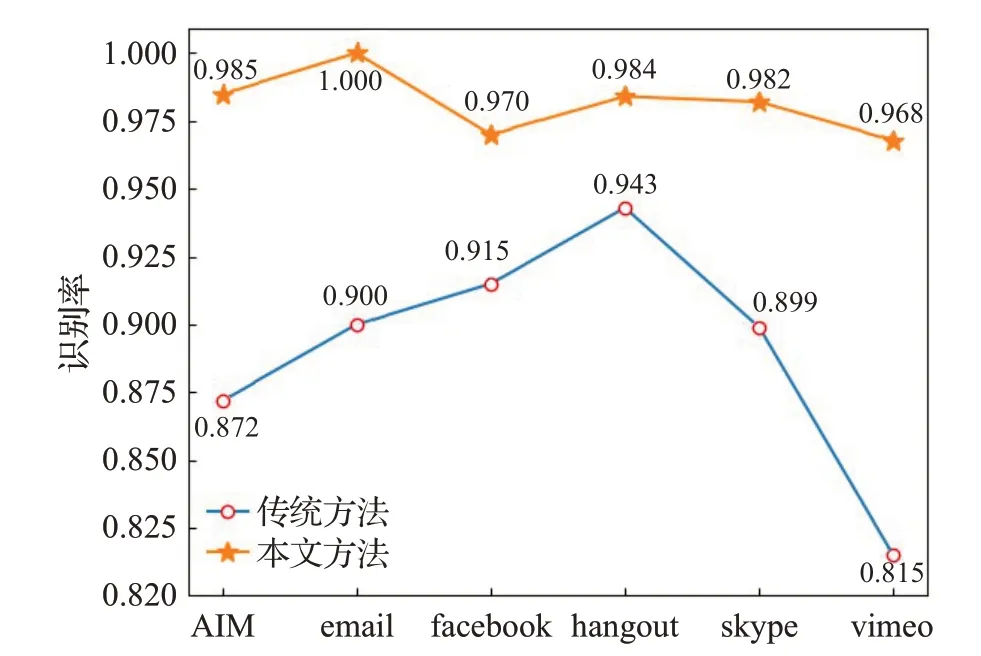
圖9 SSL流識別結果對比Fig.9 Comparison of SSL stream identification results
4.3 改進CNN模型識別VPN流量實驗結果
本文選擇精準率P、召回率R和F1這3 項評分來評估基于注意力機制的改進CNN模型。其計算公式為:

式中,Tp真正表示加密流量的樣本被正確識別的個數,Fp假正表示真實是加密流量但被錯誤的標識的個數,FN假負表示未加密流量的樣本被正確識別的個數。
為了驗證本文提出的算法模型的有效性及優越性,本文選擇了KNN(K近鄰)、PGA-RF(基于參數優化的改進RF 算法)和CGA-RF(基于子分類器優化的改進RF算法)進行比較。為驗證一維CNN 模型相比于二維CNN 模型更適合于流量分類,本文還設計了二維CNN模型與之對比,結果如表3所示。
從表3 可以看出,相比較于傳統的機器學習算法,本文提出的模型具有很好的識別效果,網絡流量的服務識別性能都有了大幅度的提升。本文方法的準確率為97.6%,相比于文獻[7]中KNN 的83.7%提升了13.9個百分點。與文獻[9]中改進的方法PGA-RF 的91.6%相比,CGA-RF 的92.2%提升了0.6 個百分點。在精確率對比實驗中,本文方法的精確率為98%,相比于文獻[7]中KNN 的83.9%提升了14.1 個百分點,而參考文獻[9]中PGA-RF、CGA-RF 的精確度分別為92.1%、92.6%,本文方法精確率明顯高于參考文獻[9]。同時本實驗還對召回率進行了對比,召回率優于文獻[7]中KNN的82.5%與文獻[9]中91.1%和91.9%。最后,本文方法與各方法的F1-score 進行對比,本文方法的F1-score 為97.8%,文獻[7]中KNN 為83%,參考文獻[9]的F1-score 分別為92.3%、92.1%,本文方法F1-score 上也是高于參考文獻[9],提升了5.7 個百分點。綜合4 項指標對比實驗可以看出,本文模型優于文獻[7]中使用的KNN 與文獻[9]中改進傳統機器學習方法PGA-RF 與CGA-RF。
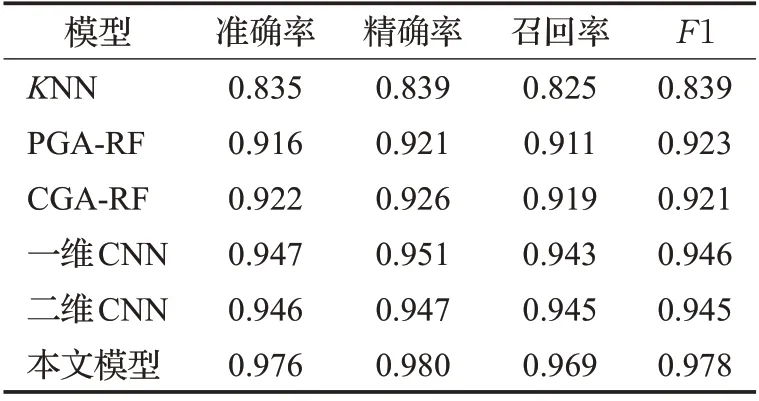
表3 SSL VPN 流量識別結果對比Table 3 Comparison of SSL VPN traffic identification results
通過四項指標對比實驗可以看出,一維CNN 模型在準確率、精確率、和F1-score 上均優于二維CNN 模型。這是由于網絡流量本質上是一種時序數據,是按照字節、幀、會話、整個流量層次化結構組織起來的一維字節流,因此選擇一維CNN 網絡模型識別加密流量更符合數據流的特征。
此外,相比于其他普通的深度神經網絡模型,本文所提模型在準確率上提升了2.9 個百分點,精確率提升了2.9 個百分點,召回率提升了2.7 個百分點,F1-score則提升了3.2個百分點。這是由于注意力機制的引入能夠對網絡流量中存在的依賴性的進行有效捕捉,從而提高重要時序特征的影響,抑制非重要特征時序的干擾,因而有效解決了模型無法區分時間序列數據重要程度的差異性的問題。
因此,本文還將改進前后的一維CNN 網絡模型進行了對比,分別選擇前5 輪訓練的準確率結果進行比較,如圖10。可以看出引入注意力機制的改進CNN 模型比普通的CNN 模型收斂速度快,且平均準確率提升了0.3 個百分點以上。如圖11 展示了基于注意力機制的改進的CNN識別模型在實際訓練過程中準確率的變化趨勢;圖12 展示了是基于注意力機制的改進CNN 識別模型訓練過程中的損失率變化的情況。
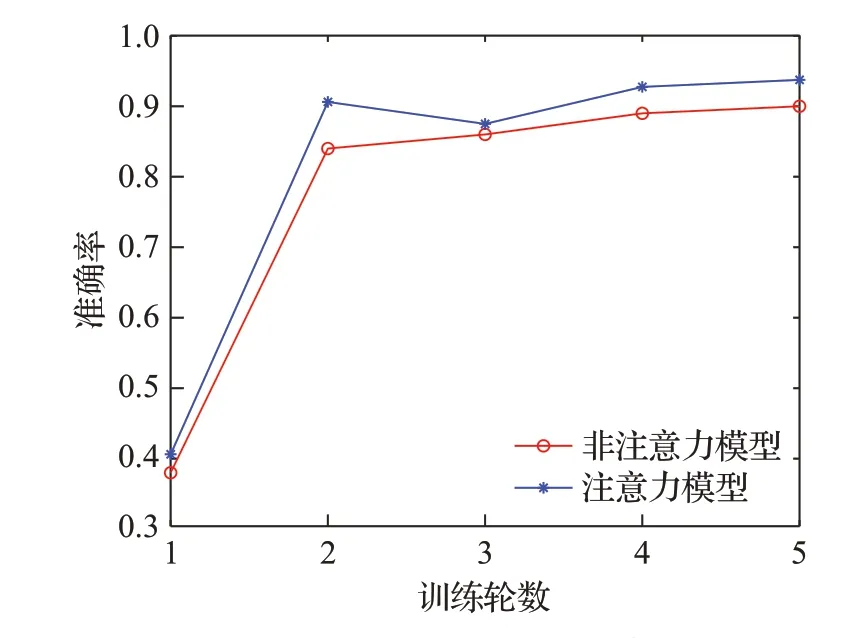
圖10 改進前后的一維CNN網絡實驗對比圖Fig.10 One-dimensional CNN network experimental comparison diagram of before and after improvement
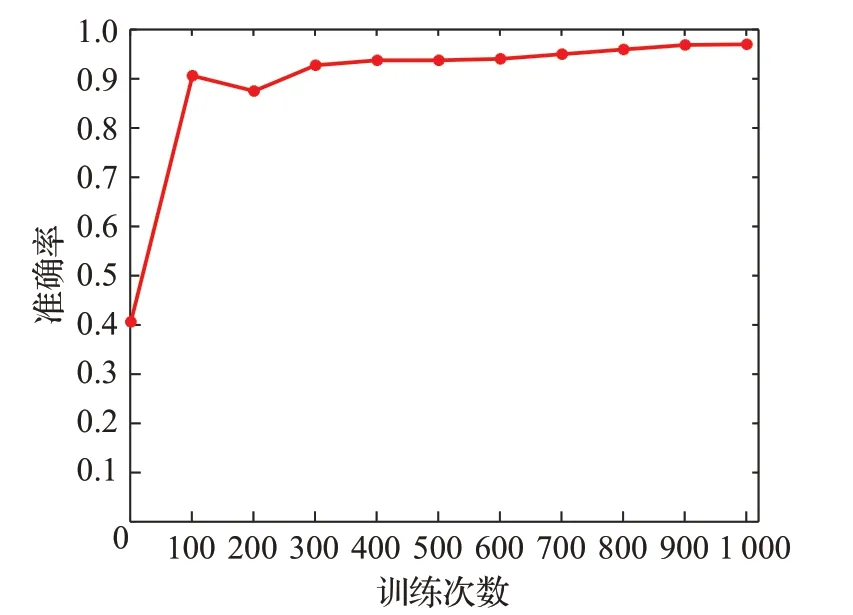
圖11 模型訓練過程中準確率的變化Fig.11 Change of accuracy during model training
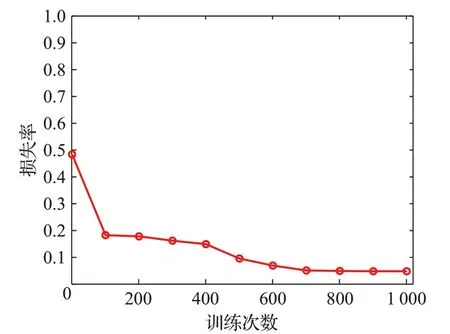
圖12 模型訓練過程中損失率的變化Fig.12 Change of loss during model training
5 結語
本文提出了一種基于混合方法的SSL VPN 加密流量識別方法。本文的Bit 級DPI 技術識別SSL 流具有快速、準確的優點,極大地改善了流的漏識別問題,最大程度上發揮了DPI 的優勢。所提基于注意力機制的改進CNN 網絡流量識別模型對SSL VPN 流量識別,其平均的精準率、召回率和F1-score 分別達到了98.0%、96.9%和97.8%,與傳統的流量識別模型相比具有優良的識別性能,實現了SSL VPN 加密流量的有效識別。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
