基于神經網絡的中文語音識別技術
2022-01-19 11:50:54代偉,劉洪
四川師范大學學報(自然科學版) 2022年1期
代 偉,劉 洪
(1.內江師范學院 人工智能學院,四川 內江 641112;2.四川大學 計算機學院,四川 成都 610065)
語音識別技術(Automatic voice recognition)是一種將語音信號轉換為計算機可讀文本的技術,是一個包含了聲學、語音學、語言學、數字信號處理理論、信息論、計算機科學等眾多學科交叉的領域.由于語音信號的多樣性和復雜性,其信號質量易受環境、設備干擾和眾多采集參數的影響.因此,當前語音識別系統基本上只能在一定的限制條件環境添加下獲得滿意的性能,或者說只能應用于某些特定的場合.同時,作為提升產品智能化程度的一個標志,語音識別技術大量用于生活當中,包括語音搜索、智能家居等.
語音識別首先可分為孤立詞和連續詞語音識別,1952 年在美國貝爾實驗室、1962 年在IBM實驗室都開發實現了基于孤立詞(特定的數字及個別英文單詞)的語音識別系統[1].連續詞識別因為不同人在不同的場景下會有不同的語氣和停頓,很難確定詞邊界,切分的幀數也未必相同,給連續語音識別造成了不小的挑戰[2].
直到20 世紀80 年代,研究人員通過引入隱馬爾科夫模型(Hidden markov model,HMM)在語音識別領域取得了里程碑式的突破[3].每個音素用一個包含6 個狀態的HMM 建模,每個狀態用高斯混合模型(Gaussian mixture model,GMM)擬合對應的觀測幀[4],觀測幀依據時間順序將數據組合成觀測序列.每個模型可以生成任意長度的觀測序列,訓練時將樣本按音素劃分到具體的模型,在訓練數據的基礎上通過算法學習每個模型中HMM 的轉移矩陣、GMM的權重以及均值方差等參數.
其后,由于神經網絡應用的不斷興起,研究人員將神經網絡引入到語音識別領域,神經網絡的引入主要是代替GMM 擬合觀測幀數據.由于神經網絡的在函數逼近上的強大能力[5],語音識別效果亦有較大提高.上述方法雖然在語音識別中取得了較好的效果,但基于音素的HMM 模型是依賴于專家知識人為設計和創建的識別模型,未必反映了語音聲學的本質;其次,模型設計較為復雜且不易理解,不利于研究人員入門和改進.因此,研究人員一直在實驗其他相關語音識別方法,端到端(End-toend)在此時應運而生.
End-to-end的語音識別方法是典型的深度學習模型方法,依賴于神經網絡在特征自提取和表示方面的強大能力,不再人為預設對應的模型,直接從輸入的語音頻譜圖映射到對應的文本標簽,同時End-to-end的方法不再依賴基于上下文(Context dependent)的狀態轉移和對齊(Alignment)處理.
本研究在借鑒和改進已有的英文端到端識別方法基礎上進行中文語音識別.首先,將語音信號分幀并轉換為頻譜圖;隨后,卷積神經網絡(Convolutional neural network,CNN)在時間維將頻譜圖進行特征提取和壓縮,壓縮之后的特征以時間維輸入到多層遞歸神經網絡(Recurrent Neural Network,RNN)進行時序相關性建模;然后,使用CTC(Connectionist temporal classification)作為損失函數進行誤差反向傳遞,神經網絡輸出單個漢字.
本文采用的網絡結構如圖1 所示,實驗數據采用清華大學信息技術研究院語音和語言技術中心王東等[6]發布的開放語音數據集THCHS30,最終以CCER(Chinese character error rate)作為識別結果評判標準.

圖1 多層神經網絡結構Fig.1 The structure of the multi-layer neural network
1 頻譜圖MFCC
MFCC 是Mel-frequency cepstral coefficients 的縮寫,其特征提取包含2 個關鍵步驟:首先將信號轉化到梅爾頻率,然后進行倒譜分析[7].
1.1 梅爾頻率梅爾刻度是一種常用的語音信號分析方法,基于人耳對等距的音高(Pitch)變化的感官判斷而定的非線性頻率刻度.梅爾刻度的濾波器組在低頻部分的分辨率高,跟人耳的聽覺特性是相符的,這也是梅爾刻度的物理意義所在.梅爾頻譜m和頻率f的關系如下:
在頻譜圖生成過程中,首先,對時域信號進行傅里葉變換轉換到頻域;然后,再利用梅爾頻率刻度的濾波器組對頻域信號進行切分;最后,每個頻率段對應一個數值.
1.2 倒譜分析倒譜分析是在對時域信號做傅里葉變換取對數之后,再進行反傅里葉變換,可以分為復倒譜、實倒譜和功率倒譜,通常語音信號處理采用功率倒譜[8].
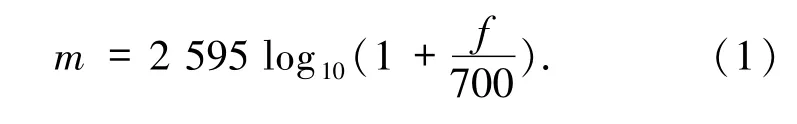
1.3 MFCC特征處理步驟1)預加重:高通濾波器處理,補償語音信號受到發音系統所壓抑的高頻部分;
2)窗函數處理:使用漢明窗平滑信號,會減弱傅里葉變換以后旁瓣大小以及頻譜泄露;
3)梅爾濾波器處理:將語音信號從時域轉換到頻域,并精簡信號在頻域的幅度值,然后進行對數處理,本文采用的濾波器組為39 個;
4)倒譜分析:反傅里葉變換(實際中常用離散余弦變換),然后通過低通濾波器獲得最后的低頻信號;
5)差分處理:由于語音信號是時域連續的,分幀提取的特征信息只反應了本幀語音的特性,為了使特征更能體現時域連續性,因此,在特征維度增加前后幀信息的維度,常用的是一階差分和二階差分.
2 模型結構
本研究采用的網絡層類型包含CNN 和RNN.CNN用在時間維上對數據進行特征自提取和維度壓縮,同時考慮到RNN 在模型訓練時對時序數據記憶困難問題,采用改進的GRU(Gated Recurrent Unit)結構進行數據時序建模[9].
CNN是一種廣泛用于計算機視覺領域[10]中的神經網絡單元,其核心思想是模擬人類視覺特征,認為視覺不只是聚焦在感興趣的像素上,還對其周圍領域的像素產生響應,解決了圖像空間相關性問題[11-12].同時,在局部采用共享權值,以降低模型訓練難度,卷積操作具有位移、縮放及其他形式扭曲不變性,極大地降低了CNN 對目標在圖像中的角度、縮放和扭曲的依賴性和敏感度,池化操作對局部區域提取顯著性特征,壓縮圖像特征數據,降低數據維度,提取有用深層數據特征,基本操作如(2)式所示:

RNN是一種廣泛用于時序數據建模的神經元結構[13],其核心思想為網絡會對前面的信息進行記憶并應用于當前輸出的計算中,即隱藏層之間的節點不再無連接而是有連接的,并且隱藏層的輸入不僅包括輸入層的輸出,還包括上一時刻隱藏層的輸出[14].理論上,RNNs 能夠對任何長度的序列數據進行處理.但是在實踐中,為了降低復雜性,往往假設當前的狀態只與前面的幾個狀態相關,基本操作如(3)式所示:

對于每一個隱狀態s,其輸入包含該時刻的輸入x(s)以及上一時刻的隱狀態h(s-1),輸出y(s)依賴于h(s),w 表示不同輸入輸出之間的權重值,b 為權重偏置值.
本文采用1 個CNN層用于時間維特征提取和數據壓縮,多個RNN 層用于時序時間建模[15],通過全連接層映射到語音識別詞典表,全連接層采用softmax作為激活函數,輸出為對應標簽的概率值.
3 CTC
在傳統的語音識別模型中,對語音模型進行訓練之前,往往都要將文本與語音進行嚴格的對齊操作[16].這樣不僅要花費人力、時間,同時預測出的標簽只是局部分類的結果,無法給出整個序列的輸出結果,往往要對預測出的標簽做一些后處理才可以得到最終想要的結果.
2016 年,Graves 等[17]提出CTC(Connectionist temporal classification)算法用于解決時序數據的對齊問題,其核心思想是在標注符號集中不斷加入空白符號blank,然后利用RNN 進行標注,最后把blank 符號和預測出的重復符號消除.例如標簽“_a_bb”和“a_bbbb”最終均被處理為“ab”標簽,上述表述中“_”代表blank,是發音之間的間隔.
對于給定長度為T的時間序列
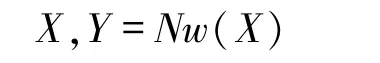
為網絡的輸出序列,y(k,t)表示輸出單元k 在t 時刻被觸發,即在t時刻標簽為k 的概率.那么,輸入觀測值在輸出集合(L′)上的時序數據概率分布可表示為(4)式,最終的標簽輸出概率為所有可能的路徑之和,如(5)式所示:
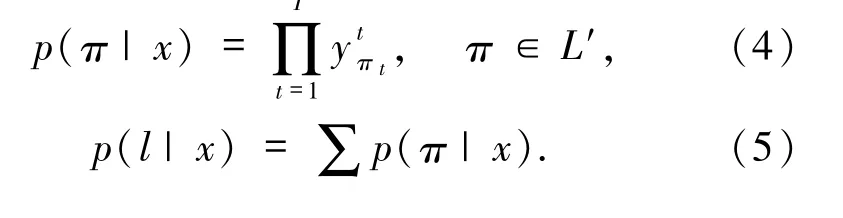
4 實驗
本文的實驗數據為THCHS30,實驗環境操作系統為Ubuntu16.04,處理器為Intel(R)Core(TM)i7-6800K@ 3.4 GHz,內存64 GB,顯卡為2*NVIDIA GTX1080(2*8 GB顯存).
深度學習神經網絡相關實現基于Keras1.1.2和Theano 0.8.2 開源框架,程序開發語言為Python.實驗設計包含以下部分:
1)通過實驗驗證不同的GRU 層數和神經元數量對識別效果的影響;
2)與傳統語音識別方法(HMM/GMM 和HMM/DNN)的識別結果比較;
本文采用的識別結果評斷因子為CCER,為了使識別出來的詞序列和詞序列真實值(truth)之間保持一致,需要進行替換(S),刪除(D),或者插入(I)某些詞,這些插入、替換、刪除的詞的總個數,除以標準的詞序列中詞的個數的百分比,定義如(6)式所示:
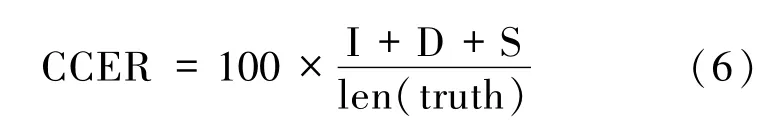
根據上述實驗設定,本文進行了相關的仿真實驗,實驗1 的結果如表1 所示.
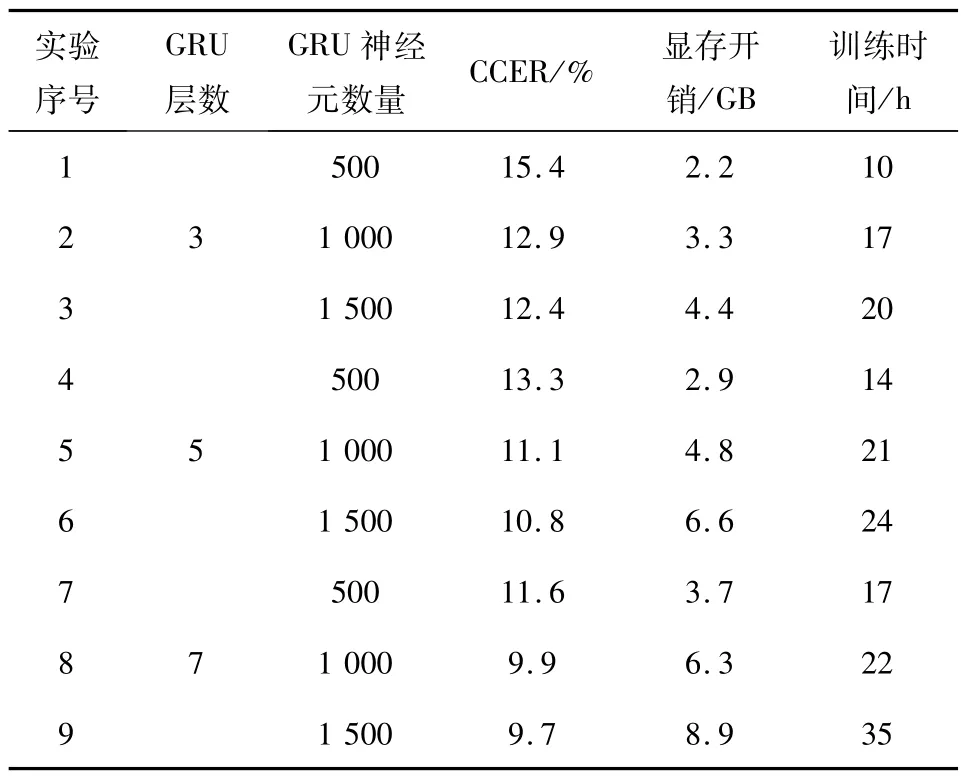
表1 神經網絡結構驗證實驗結果Tab.1 Verification of the experimental results based on the neural network structure
針對已有訓練數據集,在仿真實驗過程中,本文做了9 組對比實驗,包含3、5、7 層的GRU 網絡結構和與之對應的500、1 000、1 500 個GRU 神經元.表1 中對應的CCER為多次實驗所得的最好識別結果,顯存開銷和訓練時間是為了對比增加GRU網絡層數和神經元數量對整個模型造成的附加影響,其值均為大概值.
由表1 的結果可知,增加GRU 網絡層數和神經元數量可在一定范圍內提升最終的語音識別效果,由3*500 的15.4%提升到7*1 500的9.7%.在GRU 神經元數量從500 增加至1 000,在各個GRU層數量的情況下,最終的CCER 均能提升2%~3%,但是神經元數量從1 000 增加至1 500之后,CCER提升并不如之前的改進大,約為0.3%,這個現象說明1 000 為本文網絡結構神經元的合適選擇值.在增加GRU 網絡層數和神經元數量的同時,模型訓練的顯存和時間開銷明顯增大,大約為3.5 倍.
在完成上述實驗之后,再基于同一訓練數據集進行一組對比實驗,對比本文的端到端語音識別方法與傳統的HMM/GMM算法和HMM/DNN算法的識別效果和訓練時間,結果如表2 所示.
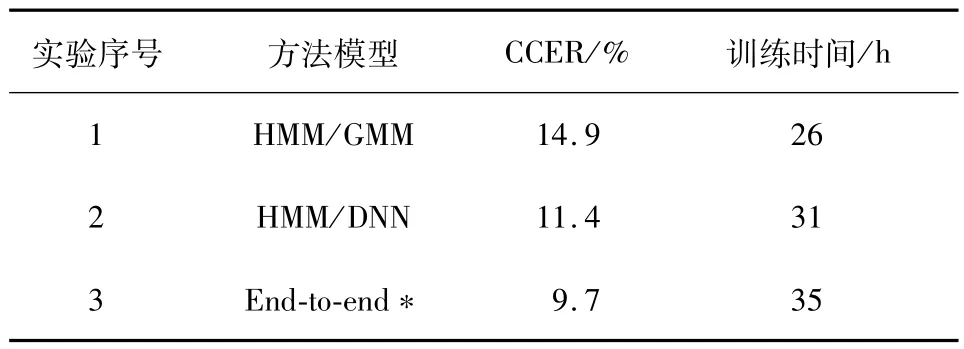
表2 語音識別對比實驗結果Tab.2 Comparison of the experimental results based on the different algorithms
從表2 可知,本文所采用的方法在識別效果上均優于傳統的HMM/GMM 算法和HMM/DNN 算法,但是訓練時間上稍遜,但如果采用實驗1 中第8個實驗的結果,那么本文的方法在識別結果和訓練時間消耗上均優于傳統的語音識別算法.深究訓練時間開銷的原因可知,傳統的HMM/GMM 算法和HMM/DNN算法在使用維特比算法解碼時消耗了大量的訓練時間,約占50%.在識別效果和時間上的優勢也是當前端到端語音識別算法成為主流的根本原因.
5 結論
本文在傳統語音識別算法人為設計模型較為復雜,且消耗訓練時間較長的情況下,借鑒并改進端到端語音識別算法在英文識別中的結果,設計和實現了適合本文數據集的中文語音識別算法.通過與其他傳統方法的識別結果比較,本文所采用的算法在能保證更好的識別效果的同時,降低模型訓練消耗的時間;同時極大地降低了語音識別技術對專家知識的依賴性,利用神經網絡強大的特征自學習和建模能力對數據分布進行擬合,端到端語音識別技術必將成為未來語音識別的主流技術.
以后,將從增加訓練樣本數據量、調整模型訓練時的超參數等方面入手,進一步改進本文的模型識別結果.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
鴨綠江(2021年35期)2021-04-19 12:24:18
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
數學物理學報(2020年2期)2020-06-02 11:29:24
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
電子制作(2018年11期)2018-08-04 03:25:42
光學精密工程(2016年6期)2016-11-07 09:07:19
發明與創新(2016年38期)2016-08-22 03:02:52
