基于DeepLab v3+的多任務圖像拼接篡改檢測算法
2022-01-14 03:02:34朱昊昱陳祺東
計算機工程 2022年1期
朱昊昱,孫 俊,陳祺東
(江南大學人工智能與計算機學院,江蘇無錫 214122)
0 概述
隨著數字圖像處理軟件的開發與普及,用戶可以輕易地對圖像數據形式及內容進行修改,但這也給違法分子可乘之機,使其在未經授權的情況下也能對圖像數據與內容進行非法操作[1],例如篡改證照、偽造新聞圖片、人臉篡改[2]等,對社會的和諧穩定造成負面影響。在圖像取證領域中,圖像拼接是一種最為常見的篡改方式,即把某圖像的一部分復制粘貼到另一幅圖像中。傳統的圖像拼接篡改檢測算法主要利用圖像的頻域特性或統計特征,例如局部噪聲估計[3]、色彩濾鏡矩陣(Color Filter Array,CFA)模式分析[4]、離散余弦(Discrete Cosine Transform,DCT)系數[5]等。但在現實生活中,圖像的篡改方法比較復雜。例如,為了掩蓋圖像的篡改痕跡,偽造者還會對圖像的篡改邊界進行高斯平滑或中值濾波等模糊操作[6],使篡改區域得以更好地融入到整幅圖像中。但傳統方法只能針對特定的篡改方法進行檢測,難以檢測復雜的篡改方法。
近年來,卷積神經網絡(Convolutional Neural Network,CNN)在計算機視覺領域取得了重大的突破,研究人員把CNN 應用到圖像拼接篡改檢測中,但大部分基于深度學習的方法[7-9]只是利用CNN 分類篡改圖像,不能定位圖像的篡改區域。ZHANG 等[10]對篡改區域的定位進行了初步嘗試,但只能得到一些粗糙的正方形區域。BAPPY 等[11]提出CNN-LSTM 模型預測圖像的篡改區域,使用LSTM 捕捉圖像塊的重壓縮特征,但無法完全識別位于篡改區域內的圖像塊。SALLOUM 等[12]提出多任務全卷積網絡(Multitask Fully Convolutional Network,MFCN),使用了分類網絡VGG-16[13]來提取圖像特征,然后分別預測圖像的篡改區域和篡改邊界,有效提升了篡改區域的分割精度。CUN 等[14]在CNN-LSTM 模型的基礎上進行改進,增加一個預測圖像塊篡改可能性的分類網絡,并使用條件隨機場(Conditional Random Fields,CRF)改善了預測結果,但算法的分割精度依然不高。ZHOU 等[15]提出一個基于Faster-RCNN[16]的雙流網絡,在模型中融合了通過SRM[17]濾波器提取的圖像噪聲特征,但該方法無法對篡改區域進行分割。此外,還有一些基于圖像相似性[18]和語義分割[19]的篡改檢測方法,類似于語義分割,圖像篡改區域分割的難點也在于尋找區域邊界,以上提到的算法使用傳統的分類網絡來提取圖像特征,多次下采樣后丟失了圖像的語義信息和篡改痕跡,導致最終的檢測效果較差。
本文提出一種基于DeepLab v3+的圖像拼接篡改檢測算法,在語義分割網絡DeepLab v3+[20]中增加分支網絡,利用圖像的淺層特征預測篡改區域邊界,使模型對圖像的篡改邊界更加敏感。同時,將卷積塊注意模塊(Convolutional BlockAttention Module,CBAM)[21]注意力機制融入到DeepLabv3+中的空洞空間金字塔池化(Atrous SpatialPyramidPooling,ASPP)模塊中,并對空間和語義信息進行壓縮和建模,從而加強模型對多尺度篡改區域的適應性。
1 DeepLab v3+網絡
本節將對DeepLab v3+進行簡要介紹,包括空洞卷積核、ASPP 模塊及其網絡架構。DeepLab 系列是一種經典的語義分割網絡,使用空洞卷積核替換了普通卷積,可以在不縮小特征圖的前提下增加感受野,從而更好地分割出圖像中的目標區域。
1.1 空洞卷積
在經典的分類網絡如VGG-16、ResNet[22]等圖像的內容信息容易被丟失,導致使用經典分類網絡進行語義分割的效果有待提高。對此,CHEN 等[23]提出DeepLab v1網絡,把空洞卷積應用到語義分割網絡中,替換原有網絡中的普通卷積層。空洞卷積的計算形式如下:
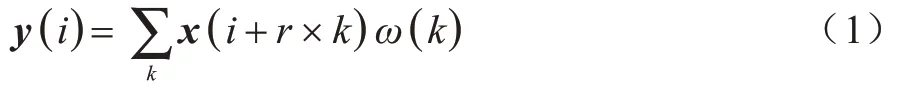
其中:x為一維的特征向量;y為卷積后輸出的特征向量;i為y中的每一個位置;ω為空洞卷積核;k為卷積核中的參數;r為空洞卷積的采樣率。
空洞卷積在保持特征圖尺寸大小不變的情況下增加其感受野,其結構如圖1 所示。其中:kernel 為卷積核大小;stride 為卷積步長;pad 為填充寬度;rate代表空洞卷積的采樣率(標準卷積核采樣率為1)。當rate=pad 時,輸入和輸出特征圖的大小相同,但相比于普通卷積感受野更大。
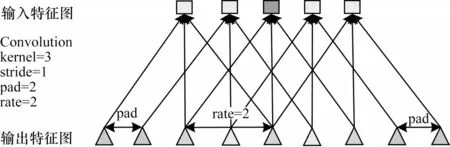
圖1 空洞卷積結構Fig.1 Structure of arous convolution
1.2 ASPP 模塊
如果使用相同采樣率的空洞卷積來處理特征圖,那么模型就無法很好地檢測圖像中的多尺度物體。對此,CHEN 等[24]設計了一個ASPP 模塊,使用不同采樣率的空洞卷積來學習多尺度信息,每個尺度為一個獨立的分支。ASPP 的結構如圖2 所示,ASPP 模塊由4 個空洞卷積組成,采樣率(rate)分別為1、6、12、18,其中Conv 代表卷積核。
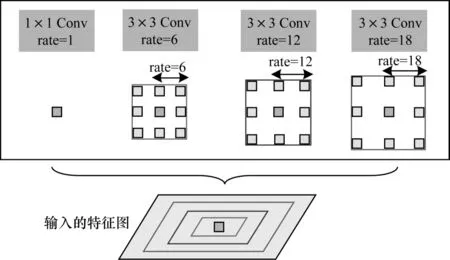
圖2 ASPP 模塊的網絡結構Fig.2 Network structure of ASPP module
1.3 DeepLab v3+網絡
DeepLab v3+是經典的語義分割網絡之一,采用了Encoder-Decoder結構,在編碼過程中把特征提取網絡中的普通卷積替換為采樣率為2 的空洞卷積,可以在特征圖大小保持不變的情況下增加感受野,此外,還使用了ASPP 模塊來對多尺度的上下文信息進行編碼。在解碼過程中通過上采樣以及融合淺層特征的方式恢復了特征圖的空間信息,從而捕獲更清晰的對象邊界。DeepLab v3+采用的是全卷積神經網絡,接受多尺度的圖像輸入,較好地保留了圖像的語義信息和維度特征,在語義分割領域中取得了較好的預測結果。本文將其網絡架構進行了改進,并應用到圖像篡改檢測領域中。
2 圖片篡改檢測模型
本文提出的網絡架構如圖3 所示,模型由編碼器、解碼器1、解碼器2 這3 部分組成,輸入的圖像大小為512×512,在編碼器中使用ResNet101 以及融合了CBAM 注意力機制后的ASPP 模塊來提取圖像的深層特征,在解碼器1 中融合了深層特征和淺層特征來預測圖像的篡改區域,在解碼器2 中使用了淺層特征來預測圖像的篡改區域邊界。下面將對編碼器、解碼器1、解碼器2 這3 個模塊進行詳細介紹。
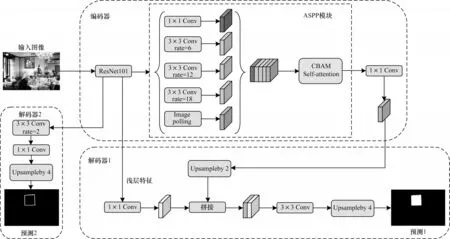
圖3 基于DeepLab v3+的多任務圖像拼接篡改檢測架構Fig.3 Multi-task framework for image splicing forgery detection based on DeepLab v3+
2.1 編碼器
將使用ResNet101 提取的圖像特征送入ASPP模塊中,并通過采樣率分別為1、6、12、18 的空洞卷積和全局平均池化層得到不同尺寸的感受野特征圖,其中1×1 Conv 和3×3 Conv 分別代表kernel 大小為1 或3 的卷積核。特征圖在拼接后通過CBAM 注意力機制對語義信息進行建模,CBAM 注意力模塊結構如圖4 所示。

圖4 CBAM 注意力模塊結構Fig.4 Structure of CBAM attention module
由圖4可知,輸入的圖像特征F先通過通道注意力模塊得到加權結果MC(F)后,再經過一個空間注意力模塊加權后輸出最終結果MS(F)。MC(F)的計算過程如下:
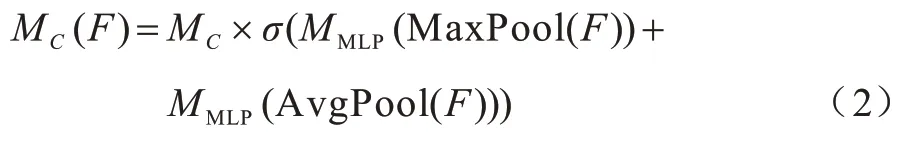
其中:F為輸入的特征圖;MaxPool和AvgPool分別為全局最大池化層和全局平均池化層;MLP(Multi-Layer Perceptron)為多層感知機;σ為sigmoid激活函數。
通道注意力模型的結構如圖5 所示,首先將輸入的特征圖分別經過空間維度上的MaxPool 和AvgPool,然后經過兩層MLP 并基于Element-wise 將輸出的特征圖相加,最后經過sigmoid 激活函數后得到通道特征圖MC。得到的通道特征圖MC和輸入的特征圖F基于Element-wise 相乘,生成空間注意力模塊需要的輸入特征圖MC(F)。

圖5 通道注意力模塊結構Fig.5 Structure of channel attention module
本文所提模型使用ASPP 模塊得到不同感受野大小的特征圖,通道注意力可以將特征圖在空間維度上進行建模,使模型關注響應最大的通道特征,而忽略響應小的通道特征。MS(F)的計算過程為:
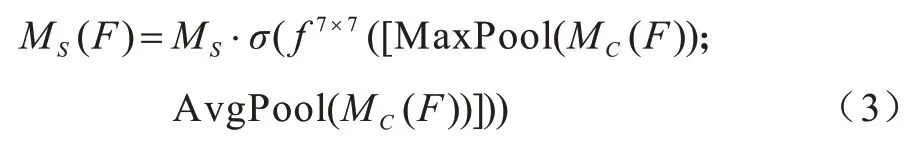
其中:MC(F)為輸入的特征圖;f7×7為7×7 大小的卷積核;σ為sigmoid 激活函數。空間注意力模塊的結構如圖6 所示,首先將輸入的特征圖分別經過通道維度上的MaxPool 和AvgPool,然后將其輸出基于通道維度進行拼接,最后經過卷積操作和sigmoid 激活函數后得到空間特征圖MS。將得到的空間特征圖MS和輸入的特征圖MC(F)基于Element-wise 相乘,生成通道注意力加強后的結果MS(F)。空間注意力機制可以看作是對特征圖的通道進行建模,通過所有位置的特征加權總和選擇性地聚集每個位置的特征,使模型能更好地關注響應較大的空間特征,并忽略那些響應小的空間特征。最后得到的深層特征經過1×1 的卷積核進行降維。
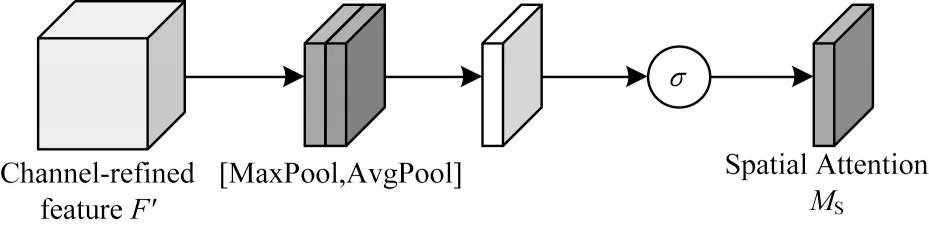
圖6 空間注意力模塊結構Fig.6 Structure of spatial attention module
2.2 解碼器1
分支網絡解碼器1 負責預測圖像的篡改區域,如圖3 所示,其中1×1 Conv 和3×3 Conv 分別代表kernel大小為1 或3 的卷積核,Up sample by 2 和Up sample by 4 分別代表2 倍或4 倍的上采樣操作,上采樣的方式為雙線性插值法。該模塊接受的輸入為通過ResNet101提取到的淺層特征以及編碼器1 輸出的深層特征。通過1×1 卷積操作降維后的淺層特征與經過兩倍上采樣操作后的深層特征相拼接,拼接的方式為通道維度上的張量拼接,拼接后的特征經過3×3 的卷積層以及4 倍的上采樣操作后輸出最終的預測結果。解碼器1 作為模型的主干網絡,通過融合多尺度的圖像特征來預測圖像的篡改區域,最后輸出的預測結果顯示其尺寸大小和輸入圖像相同。
2.3 解碼器2
模型中另一個預測圖像篡改區域邊界的分支網絡為解碼器2,如圖3所示,其中1×1 Conv 和3×3 Conv 分別代表kernel 大小為1 或3 的卷積核,含Rate的為空洞卷積,Up sample by 4 代表4 倍的上采樣操作,上采樣的方式為雙線性插值法。該模塊接受的輸入為通過ResNet101 提取到的淺層特征,經過3×3的采樣率為2 的空洞卷積和1×1 的普通卷積以及4 倍的上采樣操作后輸出圖像篡改邊界的預測結果。因為淺層特征學習到的是圖像中的邊緣線條、物體形狀等特征,而深層特征則是學習物體類別等復雜信息,通過在模型中加入一個預測篡改邊界的分支,篡改區域的痕跡能更容易被模型捕捉到。消融實驗結果表明,多任務訓練后模型的分割精度得到了有效提升。
3 實驗結果與分析
本節對數據集與數據擴充、實驗環境與訓練細節、評價標準、對比實驗結果以及消融實驗結果等模塊進行詳細介紹。其中,訓練好的模型分別在2 個數據集上進行測試,以驗證其有效性。
3.1 數據集與數據擴充
本文提出的模型使用CASIA v2.0[25]數據集作為訓練集,該數據集中包含7 491 張原始圖像和5 123 張篡改圖像,是目前圖像取證領域中最大的一個數據集。但該數據集的制作者沒有提供圖像的篡改區域Mask,只是把篡改區域的來源圖片編碼在了圖像的文件名中,本文通過灰度差值的方法得到圖像的篡改區域Mask,計算方式如下:

其中:ID為篡改圖片和原始圖片各像素點灰度值的絕對差,本文設置了閾值s=8,如果相應位置的灰度值絕對差大于8 則判定為篡改像素點(標記為1),小于8 則認為是真實像素點(標記為0)。
此外,由于CASIA v2.0 數據集中圖像數量較少,因此為擴充模型的訓練集,本文還使用了VOC2012數據集[26],利用其語義分割的Ground Truth 生成篡改圖像,共得到了27 088 張拼接而成的篡改圖像。訓練好的模型在CASIA v1.0[25]、Columbia[27]數據集上進行測試,訓練集和測試集的介紹如表1 所示。從表1 可知,測試集中的CASIA v1.0 數據集有921 張篡改圖像,篡改的方式為圖像拼接和復制粘貼;Columbia 數據集中有180 張拼接篡改的圖像,圖像格式是TIF。模型使用的訓練集為VOC2012 生成的27 088 張圖像和CASIA v2.0 中的1 851 張拼接篡改圖像。
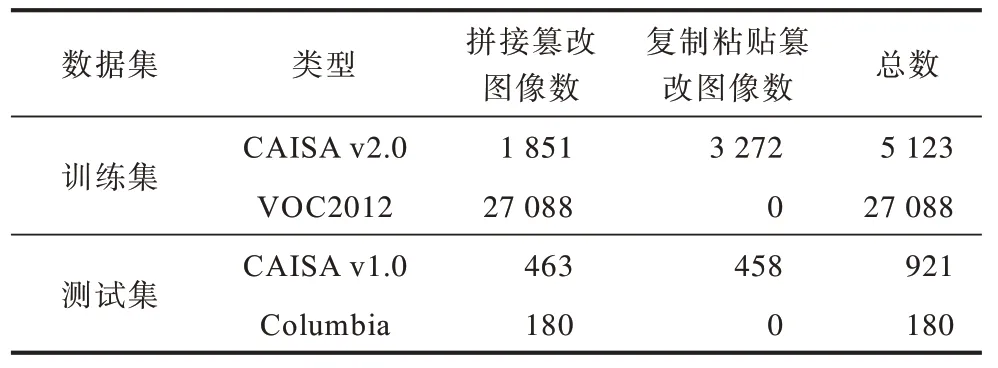
表1 訓練集和測試集圖像數Table 1 Number of images of training set and testing set
3.2 實驗環境與訓練過程
本文的實驗環境配置:CPU 型號為I7-5930k,內存為32 GB,顯卡型號為GeForce 1080Ti,顯存為11 GB。模型基于Pytorch 深度學習框架搭建網絡架構,訓練方法為隨機梯度下降法(SGD),初始學習率設為0.007,動量設置為0.9,權重衰減為0.000 5。每次接受的輸入為4 張512×512 大小的圖像,總共進行50 輪的訓練。數據增強的方式為水平翻轉和隨機高斯模糊,首先對訓練集的圖像均進行水平翻轉,然后進行隨機高斯模糊,高斯模糊的平滑半徑設為0~1的隨機值,最后得到的訓練集圖像數量擴增為原來的4 倍。在訓練過程中,首先凍結主網絡(圖3 中的解碼器1)卷積核參數,訓練預測圖像篡改區域邊界的分支網絡(圖3 中的解碼器2),然后凍結分支網絡的卷積核參數,并訓練主網絡,最后進行聯合訓練。模型訓練的損失函數為帶權重的交叉熵LMask,計算方式為:
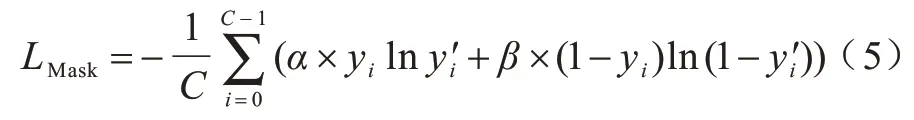
其中:yi和分別為圖像區域中每個目標點的真實值和模型的預測值;C為每次接受圖像的像素點總數;α和β的值分別為10.0 與1.0。
3.3 評價標準
本文使用F1-Score 和MCC-Score 作為模型的評估指標,其均可用來評價篡改區域的檢測精度。F1-Score是查全率與查準率的加權調和平均,MCC-Score 則為較均衡的指標,在兩類別的樣本含量差別很大的情況下可以更好地對模型進行評價,比較適用于篡改檢測領域。F1-Score 的計算公式為:
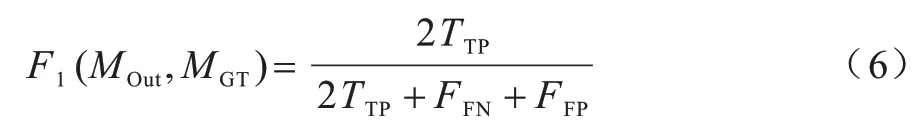
其中:MOut和MGT分別代表模型的預測結果和圖像的篡改區域Mask;TTP代表被正確分類的篡改像素數量;TTN表示被正確分類的真實像素數量;FFP代表被錯誤分類的篡改像素數量;FFN代表被錯誤分類的真實像素數量。MCC-Score 的計算方式為:
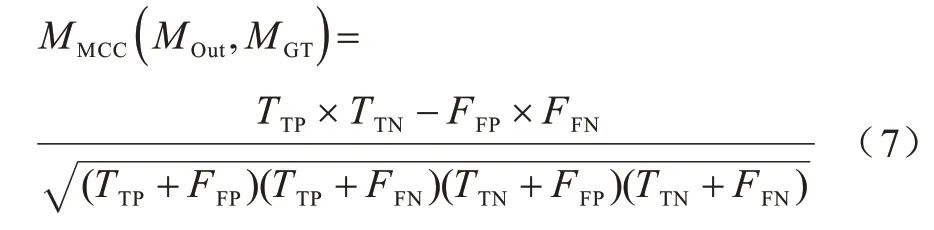
3.4 實驗結果分析
本文所提算法和其他圖像拼接篡改檢測算法的檢測精度如表2 所示,其中DCT 為傳統的圖像篡改檢測算法,其余為基于深度學習的圖像篡改檢測算法。表中加粗數字表示該組數據最大值。

表2 不同算法的檢測結果對比Table 2 Comparison of detection results of different algorithms
由表2 可知,本文所提算法在CASIA v1.0 和Columbia 這2 個數據集中均有較好的檢測結果,且優于其他算法。各算法在CASIA v1.0 數據集中的部分檢測結果如圖7 所示。由圖7 可知,本文所提算法能有效地識別出圖像中的篡改區域,且分割精度優于其他對比算法。其中,CASIA v1.0 數據集中的圖片類型與CASIA v2.0 相似,均為拼接篡改后的圖像,且圖像質量也較為接近,所以模型在CASIA v1.0 數據集中的魯棒性較好。Columbia 數據集中圖像的人為篡改痕跡較為明顯,且篡改區域較大,但模型訓練集中包含通過VOC2012 數據集進行數據擴充后生成的篡改圖像,所以算法仍有較好的檢測結果。
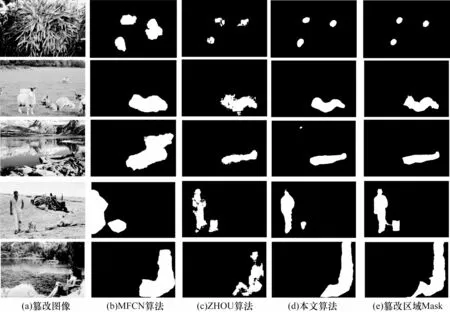
圖7 各算法在CASIA v1.0 數據集上的檢測結果對比Fig.7 Comparison of detection results of each algorithm on CASIA v1.0 data set
對文中提出的改進點進行消融實驗,應用不同方法訓練得到的模型在CASIA v1.0 數據集中的檢測精度如表3 所示。其中:Base model 代表使用未改進的ASPP模塊和圖3中的解碼器1模塊直接預測圖像的篡改區域;Self-attention 代表使用CBAM 注意力機制改進后的ASPP 模塊;Multi-task 代表使用了圖3 中解碼器1 和解碼器2 模塊進行多任務訓練;F1-Score 和MCC-Score 為模型檢測結果的評價指標。由表3 可知,相比于Base model,CBAM 注意力機制的融入能有效提升模型的檢測精度,MCC-Score 提升了約3 個百分點,使用多任務訓練方法后模型的檢測精度也有較大提升,MCC-Score提升了約4個百分點。
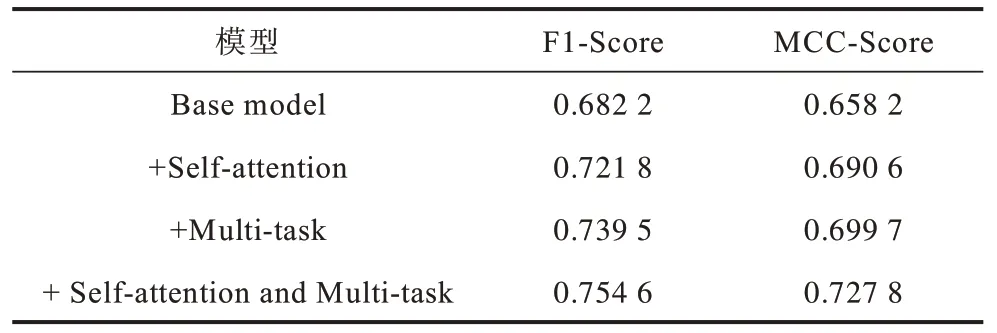
表3 各模型檢測結果對比Table 3 Comparison of detection results of each model
各模型的部分圖像篡改檢測結果如圖8 所示,其中Self-attention 代表使用CBAM 注意力機制后的檢測結果,Multi-task 為多任務訓練后的檢測結果。
由圖8 可知,加入CBAM 自注意力機制后模型的檢測效果有了較大提升,而使用多任務訓練后,模型對于篡改邊界的定位更準確。最終,模型在CASIA v1.0 數據集上的分割精度(MCC-Score)達到了0.727 8。
4 結束語
針對在圖像篡改檢測任務中篡改區域邊界難以被識別、篡改區域尺度差異大等問題,提出一種基于DeepLab v3+的多任務圖像篡改檢測算法。通過分階段訓練網絡提升模型對預測圖像篡改邊界和區域的敏感度,并在DeepLab v3+的ASPP 模塊中融合CBAM 注意力機制,從而提高模型對多尺度篡改區域的適應性。實驗結果表明,本文算法在CASIA v1.0 和Columbia 數據集中的分割精度分別為0.754 6 和0.727 8,與DCT、BAPPY 等算法相比有較大性能提升。但本文算法仍存在無法識別部分圖像篡改區域的問題,下一步將提取更復雜的篡改特征以提高算法的檢測精度和魯棒性。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
海峽科技與產業(2016年3期)2016-05-17 04:32:12
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
電測與儀表(2015年5期)2015-04-09 11:30:52
