基于知識關聯的多層本體立方體設計與實現
2022-01-07 07:01:10劉政昊
現代情報 2022年1期
劉政昊




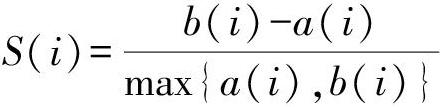





摘?要:[目的/意義]結合金融證券行業特征,借鑒層次式設計思路和數據立方體概念,提出多層領域本體立方體模型并完成構建。[方法/過程]復用FBIO本體進行知識建模;利用LDA主題建模與BIRCH層次聚類完成概念提取;基于依存句法和深度學習框架的知識抽取完成本體實例擴充;通過維度分類和基于概率的實體空間向量表示增強語義關聯性。[結果/結論]多層構建方式和立方體結構增加了知識內在關聯,為金融概念知識提供多層次、細粒度的知識組織方式;也為本體構建提供新的思路。
關鍵詞:多層領域本體;本體立方體;金融證券;知識關聯;層次聚類;知識抽取
DOI:10.3969/j.issn.1008-0821.2022.01.008
〔中圖分類號〕G254?〔文獻標識碼〕A?〔文章編號〕1008-0821(2022)01-0072-15
Abstract:[Purpose/Significance]Based on the characteristics of financial securities industry,a multilevel domain ontology cube model was proposed and constructed by referring to the concept of hierarchical design and data cube.[Method/Process]FBIO was used ontology for knowledge modeling;LDA topic modeling and Birch hierarchical clustering were used to complete concept extraction.Ontology instance expansion was completed by knowledge extraction based on dependency syntax and deep learning framework.Semantic relevance was enhanced through dimension classification and probabilistic entity space vector representation.[Result/Conclusion]The multi-level structure and the cube structure increased the internal correlation of knowledge,and provided a multi-level and fine-grained knowledge organization mode for financial concept knowledge.It also provides new ideas for ontology construction.
Key words:multilayer domain ontology;ontology cube;financial securities;knowledge association;hierarchical clustering;knowledge extraction
金融是現代經濟的核心。隨著經濟全球化進程的加速,各金融機構間的關聯日趨緊密,各細分行業產生的海量數據關聯也趨于多樣化,金融市場已成為開放、互聯的復雜巨系統[1]。金融科技概念的興起也引發了金融行業新一輪的技術革命,在國家大數據戰略背景下,金融大數據發揮了重要的價值[2-5]。然而,金融行業積累的豐富數據資源在給加速金融行業轉型升級帶來新的機遇的同時也引發了新的問題。在證券行業,由于業務、產品、客戶多模塊線條需要統一布局,存在著數據多源異構且稀疏性強、知識動態性和關聯性顯著等特點[6],加之證券投資領域知識體系本就紛繁復雜,這無疑增加了投研人員和投資者的認知和分析成本,從長遠來看,也不利于證券行業的數字化和智能化發展。因而,如何對金融知識進行有效組織與關聯以提高金融領域知識的利用效率,已成為學術界與業界共同關注的熱點問題。
本體(Ontology)作為一種能在語義和知識層次上描述多源異構知識的建模工具,被認為是大數據環境下解決“信息和知識孤島問題”的最佳方法[7-8]。領域本體(Domain Ontology)是對具體專業領域內知識的概括與集合,不僅定義領域內基本概念,還覆蓋各個概念之間的關系,提供該領域內的重要術語及理論、實例和相互關系領域活動等[9]。基于領域本體的知識表示與組織保證知識理解的唯一性,同時能夠適應涉及的知識領域多樣性以及語義關系復雜性的特點[10]。
領域本體的構建方法一直是當前本體研究熱點,傳統的人工構建方法需要領域專家的介入,成本較高且難以復用[11-12]。隨著人工智能的發展,越來越多基于深度學習的自動化構建方法受到了學者們廣泛關注[13-16]。本文以金融證券行業為例,提出了一種能夠多維度表征知識概念的本體立方體結構框架,首先對概念進行主題建模和層次聚類,構建概念間層級關系;然后基于信息抽取方法和技術,對大量的非結構化語料進行有效的實體和關系抽取,并依據概念間的語義相似性進行維度分類,從而構建起實例本體立方體結構,為實現金融知識的有效關聯與融合提供了理論模型支持,同時也為領域本體構建方法提供了新的實現思路。
1?相關研究
1.1?領域本體構建方法與技術
隨著人工智能第三次熱潮的到來,本體概念頻繁地被人工智能與知識工程領域所提及。目前,領域本體的構建方法與技術已經相對成熟。早在2003年,歐盟信息社會技術方案委員會就通過研究本體構建的36種方法,分析了以文本、字典、知識庫及半結構化圖表為數據源的領域本體構建技術、方法與工具[17]。同時期中國科學院則致力于研究形式化本體在領域知識的復用和共享中的作用以及領域知識復用的虛擬領域本體的構建方法與技術[18],并取得了一定成果。隨著對領域本體構建研究的深入,越來越多的學者試圖通過不同的技術和方法對不同領域進行本體建模。
在以統計學習為主的構建技術中,自然語言處理、信息檢索等技術被廣泛應用在領域本體構建的各個模塊,如國外學者Shih C W等[19]的基于詞匯共現與合并的水結晶模型(Crystallizing Model);Sanchez D等[20]的基于核心動詞挖掘技術;國內研究者鄭姝雅等[21]面向用戶生成內容的術語抽取技術;鄧詩琦等[22]面向智能應用的應用驅動循環技術等。這些技術的基本思想都是利用詞匯單元的共現信息識別它們的關系并應用在概念和關系抽取中,構建過程注重應用關聯規則挖掘等淺層語義,雖然一定程度上提高了構建效率,但準確率低下,難以擴展和復用。此外,Shamsfard M等[23]在調研中發現,領域本體的構建中多數研究仍主要關注層次關系(Hierarchical Relation),對于非層次關系的抽取與表示常常無能為力,因此僅采用統計學習為主的技術構建的本體維度略顯單一,只適合體系較為單一明確且知識關聯特征不明顯的領域。
與統計學習技術相對應的語言學構建技術則更加注重對深層語義的理解與分析,因此語義字典、語義模板等被應用在實際的領域本體構建中。國外學者Zouaq A等[24]提出了一種基于深度語義分析與圖論方法結合的領域本體構建方法;Lee C S等[25]在構建過程中利用語形學的概念構建了概念間的關系,同時結合領域專家對概念和關系進行了修正;國內學者劉萍等[26]基于語言學的方法對領域本體構建的概念抽取和關系識別進行了綜述分析,并認為深度語義和知識關聯特征需要多源異構數據融合和概念語義增強理解才能實現。基于語言學的方法可以在一定程度上解決術語多含義的問題并降低關系識別的誤差和丟失,從而獲得更高性能和更加權威的本體知識,但是由于領域知識的高度復雜性和動態性,僅靠語言學主導的領域本體構建在實際應用中依舊會受到較大的限制。
1.2?金融領域本體建模
本體作為一種能夠在語義和知識層次上描述信息系統的建模工具,被廣泛應用于各領域的知識表示與關聯中。在特定的金融領域中,好的本體模型作為金融知識表示的模式層可以很大程度上滿足金融行業對數據質量和語義關聯嚴謹性的需求[27],因此也受到該領域學界業界的廣泛關注。現有的金融本體中最為知名的是美國企業數據管理委員會(Enterprise Data Management Council,EDM Council)主導,通過眾包方式構建的FIBO(Financial Industry Business Ontology)。FIBO作為領域本體,定義了金融基本概念(FBC)、金融指標(IND)、金融實體(BE)、證券和股票(SEC)以及貸款(LOAN)等領域內的實體及其關系,并且在構建中也運用了層級化的思想。然而,FIBO尚處于本體開發周期的初級階段[28],主要對基本術語進行規范和共享,對金融知識的關聯表現一般。Browne O等[29]對FIBO進行了擴展,將以前未映射的股票和債券納入其中,并開發了數據管理框架,但這一改進只部分解決了數據交換的問題,多層次語義無法關聯的問題依舊存在。
此外,Ren R等[30]基于金融新聞庫構建了特定金融領域本體,該本體試圖存儲所有與金融新聞相關的重要信息,其語義表達能力較強,但由于缺乏規范性的構建流程,本體涉及的范圍邊界模糊、收集的概念顆粒度不適當,難以大規模運用;Yang B[31]提出物流金融風險本體論OntoLFR,并構建了物流金融風險本體論模型,以適應風險在預警和事前控制中的可變性、復雜性和關聯性,雖然該本體構建目的明確,但領域知識的揭示需要借助來自上層的知識體系及相關領域的大量概念,而該模型沒有提供規范化的標準,難以與相關領域集成;強韶華等[32]基于本體的規則推理技術和案例推理技術構建了金融事件本體,并建立基于本體的主題事件案例庫設計案例推理(CBR)表示、檢索與重用,其優點在于融合了金融輿情數據并考慮了本體推理,但其在金融領域屬性設計、基于本體的CBR+RBR關聯模型設計上均存在一定的缺陷,并且本體案例庫的設計規模較小,存在與實際應用脫節的問題。
綜合現有研究可以發現,雖然領域本體的構建方法和應用趨于多元化,但是由于知識系統的復雜性,在對領域異構知識的共享與重構時,未能很好地完成信息的廣泛組織和有效關聯。目前的領域本體構建思路偏重于專業性和針對性,但依舊存在本體難以服用和集成、概念體系不規范等問題,而且忽略了本體作為一種可共享的概念集合所應當具備的通用性與集成性。在金融領域,本體對于金融知識組織和表示具有很強的指導意義,但目前的構建過程并不十分規范;此外,現有的金融本體中影響力較大的FIBO本體不完全適用于中國的金融體系,且該本體包含范圍太廣,并沒有聚焦于特定的細分領域,因此不能很好地刻畫細粒度的概念和知識。綜上,本文以金融證券領域為例,基于現有研究的不足,重點解決的核心問題是:如何利用和改進多層本體框架,構建多層次、多維度的領域本體,提供一組具有正確類別、層級結構和關聯關系的金融證券領域概念語料庫,以便更好地管理金融領域知識、支持經濟決策。
2?多層本體立方體模型設計
2.1?概念定義
在數據庫領域中,數據立方體是數據倉庫和聯機分析處理研究領域的一種核心數據模型,它可以多維度表征數據特征,現有的很多研究借鑒了這一思路,如Li J等[33]通過構建語義—空間—時間數據立方體(Semantics-Space-Time Cube),探討了語義、空間和時間這3個異構信息方面的相互關系,并得出文本語義隨時間和空間的變化規律;Esteban P E等[34]使用基于RDF數據立方體詞匯表的多維模型方法,向開放鏈接數據添加值,完成了數據多維度特征的分析;師智斌[35]則借助FCA理論,以形式化的概念和概念層次為基礎進行了高性能數據立方體及其語義研究。由此可見,數據立方體的本質在于多維度、多刻面的特征表示。
本體作為知識庫的表現形式之一,融合多維度信息可以從不同側面展示本體知識的隱含特征,因此可以利用數據立方體的結構形式進一步豐富其語義表達的多維性和靈活性。本文依托數據立方體概念,將能夠多維表征關聯知識實例的本體模型定義為“本體立方體(Ontology Cube)”,具體定義如下:
定義1:本體立方體(Ontology Cube)是指由維度構建出來的多維知識表示和存儲空間,是一種為了滿足用戶從多角度多層次進行知識查詢和分析的需要而建立起來的基于事實和維的本體實例模型,其包含了所有要檢索分析的領域知識實例和關系,所有的關聯知識的操作都在立方體上進行。
表1對數據立方體和本體立方體涉及的基本概念、存儲對象、主要解決的問題和典型應用場景進行了詳細的對比介紹。
2.2?構建思想
框架布局和層次設計是在復雜性概念和具有結構特征的實例之間構建關系系統的前提。金融證券行業是對信息高度敏感的行業,也是信息源高度異構、知識體系最為龐雜的代表行業之一,因此需要建立一種能夠多層次且多維度刻畫領域知識的本體結構,以便能夠實現對復雜知識體系規范而明確的描述,從而增強概念間的語義關聯。對此提出以下構建思想:
1)借鑒由任守綱等提出的層次式領域本體模型[36],面向不同層次的知識體系并遵循自頂而下的本體構建原則,構建由基礎層、概念層和實例層構成的3層領域本體模型。其中,位于基礎層的頂層本體提供了領域特征的普遍聯系,揭示了領域知識在更高語義層次上的關系,為概念層本體提供了底層抽象;概念層的概念本體作為銜接抽象概念與應用實例的中間層次,能夠描述領域基本特征的明確化概念并針對領域核心知識類別進行規范化和明確化的表示;而應用本體作為實例層,可以實現領域內的具體實例集成表示。
2)根據Zhang L L等的劃分依據,將實例層的各金融實體劃分為行業、企業和內部環境3個維度[37],形成本體立方體結構。三者從不同的范圍和方向搭建了領域知識框架,其本身也作為類與類的關系(行業—企業關系、行業—內部環境關系、企業—內部環境關系)包含在本體之中。
行業(Industry):“行業”維度或稱為“市場”維度,從宏觀層面描述金融證券相關實體、屬性及其關系。金融證券行業/市場的主要屬性包括名稱、行業經營狀態、行業政策、行業能力(市場容量、輸出值和業內的公司數量),行業財務指標、行業的生命周期(初創期、成長期、成熟期和衰退期)及行業系統性風險等。
企業(Company):“企業”維度從中觀層面描述領域知識。其主要屬性包括公司或機構名稱和數量,公司或機構治理結構的股權結構、管理結構、貿易聯盟結構,企業/機構競爭合作,企業財務指標、公司的生命周期、企業外部風險等。其中企業財務指標是一個比較寬泛的概念,具有比較明顯的數值屬性。財務指標及其對應的財務實體通常用來反映財務實體的狀態、變化和關系,其屬性包括更新頻率、時間、數據源等。
內部環境(Inner Environment):“內部環境”維度則是從微觀層面進行知識表示。其主要屬性包括公司產品架構、公司人員組織結構、產品財務指標(包括增長階段、產能、銷售、價格等)、公司內部文化(公司價值觀、公司戰略、公司理念等)以及企業內部風險等。
具體的多層本體立方體模型如圖1所示。在該模型中,基礎層和概念層不具有維度傾向性,僅具有層次關系;實例層本體則被定義為由行業—企業—內部環境3個維度組成的立方體結構,其中由概念映射的實例集合可以構成特定的子立方體,每個子立方體內存儲著由概率值作為空間坐標的實體和關系。此外,所有概念和實體可跨層映射與關聯。
3?多層金融股權本體立方體構建
3.1?研究框架
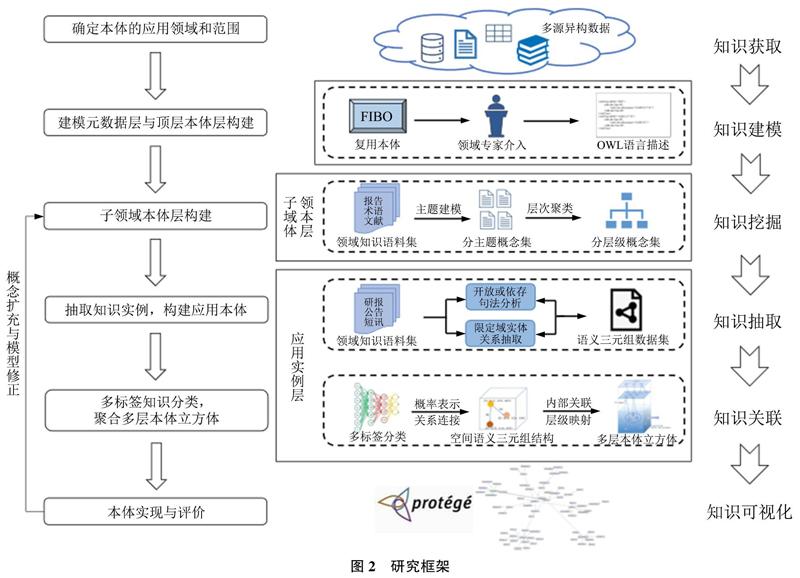
本文依托前述多層本體立方體的設計思路和本體規范化構建流程,分別從知識建模、知識挖掘、知識抽取和知識關聯的視角逐步完成多層、多維本體立方體的半自動化構建,并提出如圖2所示的研究框架,具體研究步驟如下:
1)數據獲取與預處理:獲取證券行業報告、企業研報及公告、財經新聞短訊、證券領域專業術語及相關學術文獻等多源異構數據,通過分詞、去停用詞等預處理形成初始語料庫。
2)知識建模與表示:結合領域專家知識完成對描述通用知識特征的上層本體構建,然后復用FIBO本體框架,并用OWL語言進行描述和建模。
3)知識組織與挖掘:利用LDA模型對概念主題建模,并對概念進一步進行BIRCH層次聚類,在繼承上層本體的基礎上實現層次概念及關系的組織。
4)知識抽取與擴展:首先基于依存句法實現知識實例的語義三元組抽取;而后針對特定的實體和關系利用FinBert深度學習預訓練模型實現實體和關系的進一步抽取和擴充。
5)知識關聯與融合:對概念和實例按構建維度分類,并利用相似度算法計算語義相似性,以確定其空間位置;最后將3層本體立方體結構聚合,完成證券本體立方體的構建。
3.2?知識建模:基礎層構建
上層本體可通過四元組O=(C,P,R,X)抽象化表示,其中C表示本體中概念集合,P表示概念屬性的集合,R表示概念間關系的集合,X則表示本體公理與規則集合。
以證券領域為例,上層本體的基本概念集合可表示為C={金融主體,金融合約,事件,機構,指標,時間,空間}。其中金融主體是指參與金融活動的個體,如股東、法人、債權人等;金融合約是金融活動得以實施的憑證,如合約文書、口頭合約;事件特指在金融活動中金融主體或機構參與的活動,如公司破產、對外投資等;機構主要指從事金融服務業有關的金融中介機構,同時也包含政府機構及合法存在的社會機構等。此外,概念與概念之間除了is-a、is-part-of、is-kind-of、is-instance-of、is-attribute-of等繼承與依賴關系,還可以人為定義不同實體概念的關系,實現概念間的初步關聯,如在企業—企業關系中,R企業={同業資金往來,控股,合作,競爭}。上層本體公理與規則X代表領域本體內存在的事實,可以對本體內類或者關系進行約束,如機構、事件等屬于金融概念的范圍。在實際構建與建模過程中,由于開發人員知識背景以及人力、時間的限制,將每一個相關的領域本體都進行構建是不現實的;考慮到國外已經構建了成熟的金融領域本體且不同語言描述的本體在基本概念定義上大體相同,為提高本體構建效率,研究復用了FIBO本體。FIBO本體雖然是領域本體,但主要關注金融全領域的普遍聯系[38],并涵蓋了證券子領域的通用概念、屬性與關系,可以指導上層本體的構建。
構建上層本體的核心是完成對通用知識的表示,研究采用OWL語言完成通用概念的建模。基本元素在知識表示過程中首先需要對信息資源和知識資源進行面向對象的抽象,以提取概念及其關系;其次需要按照OWL的語法要求構建相應的類(包括概念、屬性、關系等)并將類存儲在OWL類型聲明文檔中。
在基礎層,OWL強大的表達能力還得到了許多概念構造函數和公理的支持,除了可以通過“subClassOf”和“subPropertyOf”形成概念的層級結構,通過“domain”“range”“equivalentProperty”“hasValue”等描述概念間的約束關系外;還可以通過“equivalentClass”“sameAs”“inverseOf”形成語義關聯關系;通過“intersectionOf”“unionOf”等形成概念的邏輯組合;通過“uniqueProperty”“transitiveProperty”等實現概念及其關系的公理定義[39]。上述定義還為概念層和實例層的構建提供了規范的表示框架,便于相關概念和實體的規范表示與擴充,從而從更高的語義層面指導概念層和實例層的設計與實現。
3.3?知識挖掘:概念層構建
3.3.1?概念主題建模
目前在金融領域,現有的結構化語料尚未達到能夠構建共享概念模型的程度,因此,利用主題建模的方式挖掘非結構化文本信息有助于領域概念的識別。本文采用LDA主題模型構建特征詞項,經過聚類得到的特征詞可以為概念主題劃分和層級聚類奠定基礎。
為保證文本來源的多樣性,并能夠從行業、企業和內部環境的角度分別進行主題建模,本文爬取百度百科金融證券領域相關詞條325個,調用Tushare接口獲得上市公司簡介及主營業務4 270條,獲取公司研報及證券行業短訊共1 000條,此外還人工收集了350條專業術語解釋,共同作為主題建模的語料庫。
在模型參數設置方面,采用專家咨詢法集合困惑度判斷法設定主題數K=5,learning_decay=0.7,learning_offset設為50,訓練結果如表2所示。
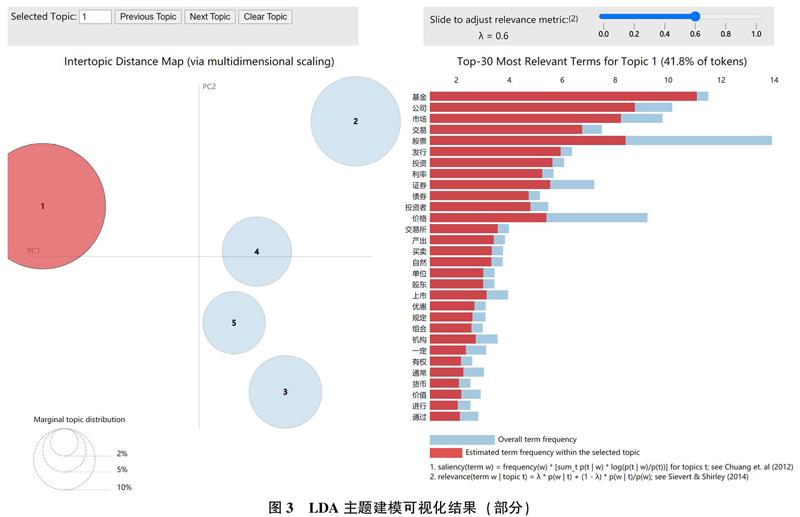
進一步地,利用pyLDAvis實現主題建模可視化,如圖3所示。圖中左側氣泡分布表示不同主題,圓圈大小代表每個主題的出現頻率,而主題間的位置遠近表達了主題接近性。距離越大,說明主題之間的差異性越高,困惑度也就越小。圖3右側則顯示了Topic1前30個特征詞。其中淺藍色表示該詞在整個文檔的權重,紅色表示該詞在當前主題中所占的權重。此外,超參數λ可以調節特征詞的顯示,λ越接近1表示該主題下更頻繁出現的詞與主題更相關;λ越接近0則表示該主題下更特殊、更獨有的詞與主題更相關。
3.3.2?概念層次聚類
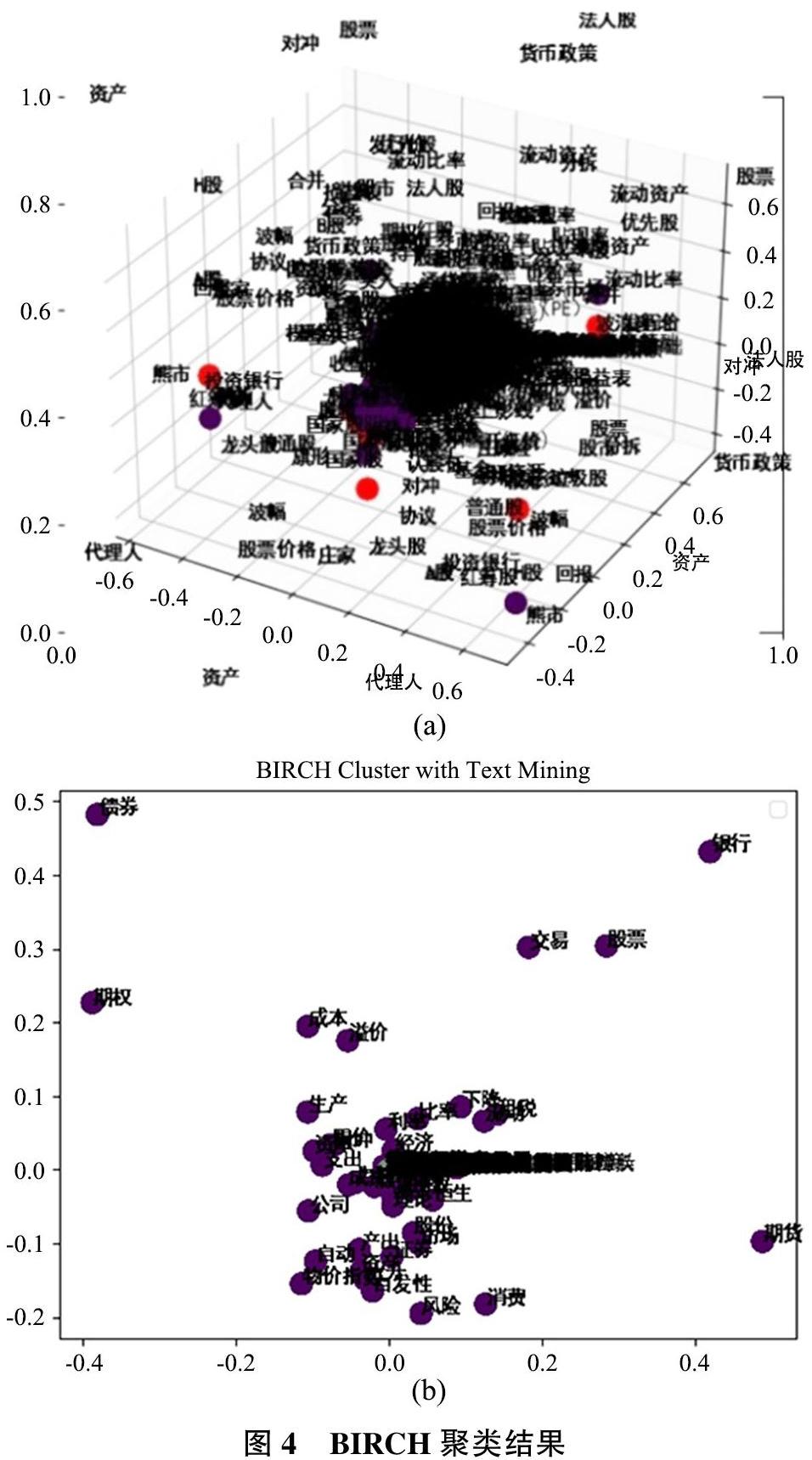
基于概念主題建模得到了大量的實體標志詞,然而各概念間的層次關系較為混亂,無法構建出結構清晰的概念本體模型。基于此,在上層本體的框架基礎上利用LDA主題模型和語義特征構建自定義特征詞典獲取具有代表性的特征詞,然后通過BIRCH聚類算法劃分領域內概念的層次關系。BIRCH算法是一種增量的聚類方法,首先用自底向上的層次算法,然后用迭代的重定位來改進結果,且聚類效率很高。實驗的具體步驟如下:
1)層次聚類。BIRCH聚類算法無需提前設定聚類數目,初始聚類結果設定為與前述主題相等的5個簇,如圖4(a)所示,可以看到此時概念間的父類子類關系并不明顯。為了能夠將主題建模得到的詞向量達到較好的層次聚類效果,將得到的聚類數目最多的簇再次聚類,以此類推共迭代10次,圖4(b)展示了最后一次迭代的聚類結果。
2)聚類評價。研究采用輪廓系數(Silhouette Coefficient)對聚類結果進行評價。如式(1)所示,輪廓系數S(i)結合內聚度a(i)和分離度b(i)兩種因素,當S(i)趨近于1時,說明樣本i聚類越合理。最后一次迭代時的輪廓系數為0.4577,表明聚類結果已較為理想。
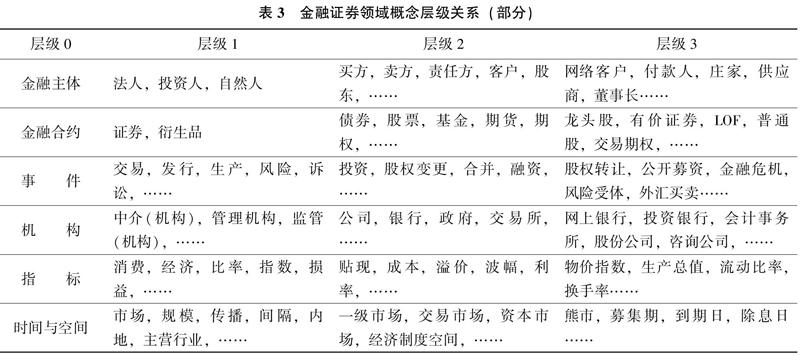
3)層級與類別劃分。將詞向量對應到具體的詞語,從最后一次的迭代結果開始向上追溯,根據每次的聚簇形狀,結合詞語所表達的概念范疇可大致劃分成3層概念集合(其中第0層繼承自上層本體,不包含在內),具體的層級關系如表3所示。
從表3可以發現,基于上層本體框架的層級聚類能夠在一定程度上表征領域的層級關系,但由于金融領域的特殊性,各術語概念間的層級關系并不十分明顯,且概念間存在多種潛在的關聯關系如時空關聯、事件關聯等,導致BIRCH聚類效果并不突出;也正因如此,構建多維度的本體立方體模型顯得十分必要。
3.4?知識抽取:實例層構建
實例層的應用本體引用和繼承上層本體集成的模塊,并通過對概念本體的映射,實現領域內的實例集成表示與本體擴充。然而,要構建應用本體需要對大量的證券領域實體和非層級關系進行抽取,傳統的語言學模板方法需要構建大量的規則,雖然準確率較高,但不適應數據量較大的情況;因此后來又陸續提出了基于句法分析的關系抽取和基于深度學習的監督/半監督關系抽取方法。本文先基于依存句法規則進行開放域三元組抽取,而后根據提取結果,借助深度學習框架完成限定域實體的輔助抽取,從而實現了應用本體的進一步擴充。
3.4.1?基于依存句法的開放域實體關系抽取
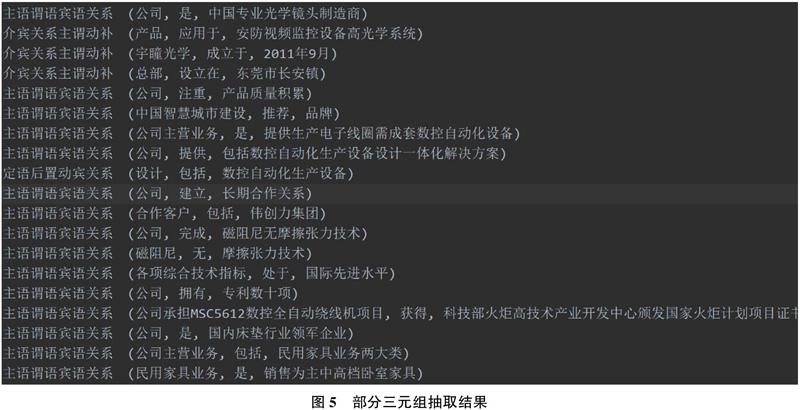
依存句法分析(Dependency Parsing)能夠根據詞性及詞間的位置關系判斷句中各成分的語法依存關系,因此,基于依存句法的實體關系抽取主要依賴于句中的謂詞,當以謂詞為代表的關系中含有論元時,能夠提取出語義三元組。本文采用LTP自然語言處理工具實現多源文本數據的三元組有效提取,通過設置抽取規則,如表4所示,為擴充本體實例及其關系提供技術支持。
對于抽取的結果,將表義模糊的實體和非表意關系進行人工剔除,最終得到32 627個實體及其關聯的1 928種語義關系,部分抽取結果如圖5所示。
3.4.2?基于深度學習的限定域實體抽取
開放域的抽取固然可以有效地擴充實體和關系,然而一方面由于獲取的頭尾實體及關系類型過多導致難以有效組織應用本體結構;另一方面基于句法分析得到的實體雖然表義明確但過于冗長,且一些證券領域的專有名詞和公司名未能被很好地識別出來。對此特別對公司股票、組織機構、人名地名、主營產品和風險事件進行了實體識別。
本文將實體識別環節視為一個序列標注問題,通過BIO標注法對隨機抽取的2 000條文本進行人工標注,然后使用FinBERT+Bi-LSTM+CRF實體標注深度學習框架進行訓練。具體來說,首先利用FinBERT預訓練模型對詞向量進行訓練,而后將生成詞向量通過與定義的實體標簽信息進行合并編碼作為輸入到Bi-LSTM模型加強詞性分析,捕捉前后文的雙向語義信息,最后通過CRF解碼完成命名實體識別任務。
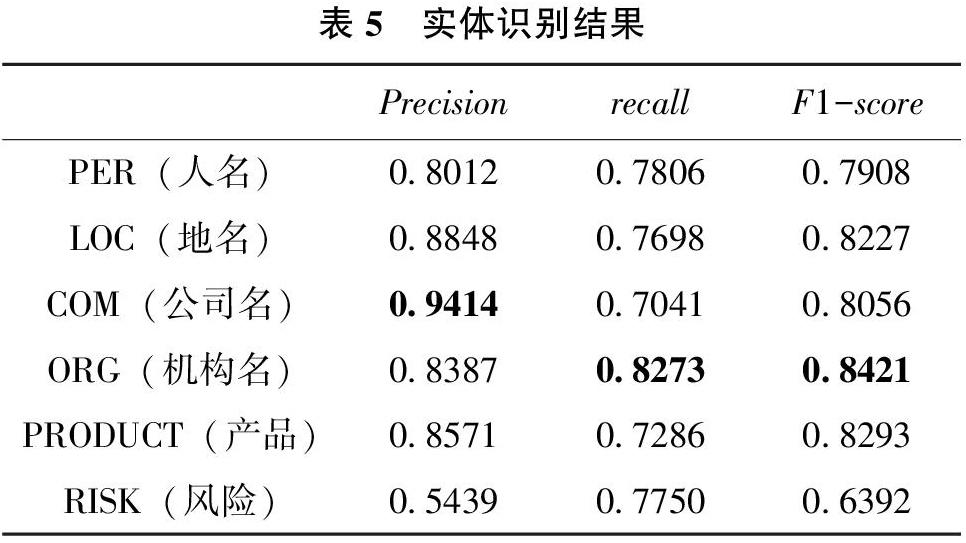
本文將實驗數據按照7∶1∶2分為訓練集、開發集和測試集,設置learning rate=0.001,banch_size=32,epochs=20。最終的實驗結果如表5所示。
上述結果可以看出,機構名和公司名的識別效果較好,而風險識別結果較差,這與標注樣本的規范性和實體在文本中所占比例有關。研究對語料中未標注文本進行了實體抽取,人工去重和剔除錯誤結果后,共抽取出23 245個實體,完成了對領域實體的擴充。
3.5?知識關聯:多層本體立方體聚合
3.5.1?文本分類與空間向量表示
多層本體的聚合完成了多層次、細粒度的金融領域知識表示,但是對于證券領域內大量跨層級實體和非層級關系的表征依舊顯得無能為力。比如“信用風險”在不同的語境下的風險對象可能是企業或個人,甚至可能是整個產業鏈;再如“合作”關系的主體可能涉及到不同層次下的金融主體與金融機構。由此可見,概念本身的多義性決定了其能夠在不同維度表征不同含義,而并非只能劃歸到單一的維度或類別中。本體立方體可以將實體表示為基于概率的三維向量,從而加強語義關聯的能力。
基于依存句法的三元組較好地保留了語境和語義信息,可以作為分類的原始語料。因此,研究將提取的語義三元組視為一個整體進行分類,并用概率表示頭實體和尾實體的分類結果;對于相同的實體,則取平均值作為最終的空間向量值。得到的結果將其進一步劃分在不同的子立方體內,完成實體的最終定位。
在實驗中,依照2.2節的維度劃分情況將隨機抽取的8 000個三元組分為行業(市場)、企業和內部環境3類,然后將數據按8∶2分為訓練集和測試集。實驗采用Keras+Finbert深度學習框架完成分類任務,設定banch size=16,epochs=5,采用Adam優化器,實驗結果如表6所示。
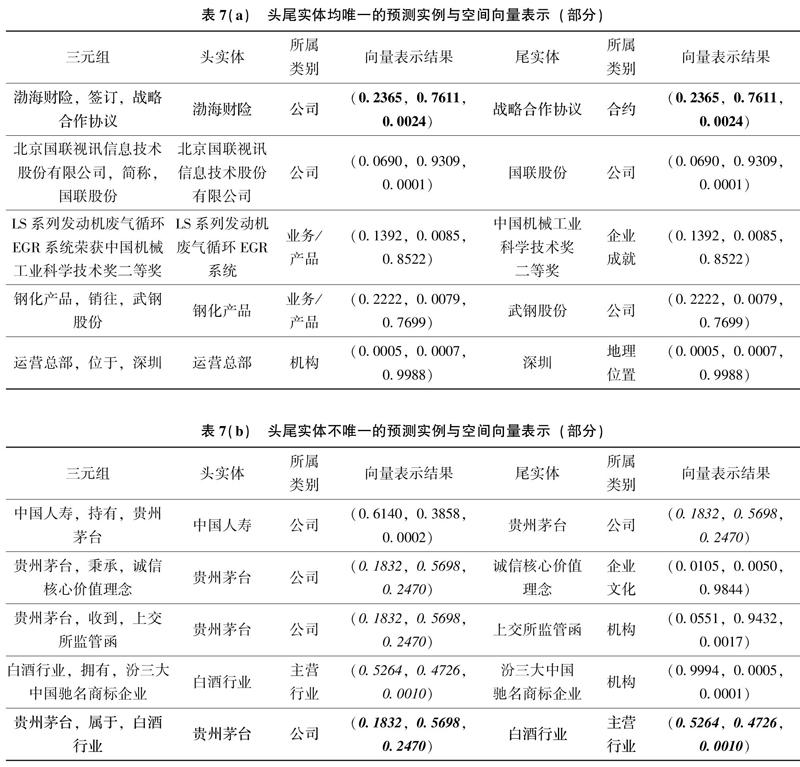
實驗結果表明,對于三元組的維度分類總體效果是符合預期的。在最后的預測任務中,直接用Softmax激活函數所表達的分類概率作為每個三元組的頭實體和尾實體的坐標值。例如三元組(渤海財險,簽訂,戰略合作協議)被分為“行業/企業/內部環境”的概率分別為0.2365/0.7611/0.0024,那么頭實體“渤海財險”和尾實體“戰略合作協議”的相對坐標均為(0.2365,0.7611,0.0024),只是由于二者分屬不同的概念類別,因此被存儲在不同的子立方體中;再如(貴州茅臺,屬于,白酒行業)這一三元組整體的輸出概率為0.0533/0.9446/0.0021,但由于頭尾實體在語料庫中均出現多次,所以二者最終的相對坐標以平均值的形式被表征出來。表7分別呈現了在語料庫中頭尾實體唯一(a)和不唯一(b)兩種情況下部分預測實例和基于概率的空間向量表示結果。
3.5.2?多維本體關聯與融合
三層本體通過語義數據映射模型將所有的概念和實體逐一映射、完全關聯。在構建過程中,從上而下的構建模式將知識元素映射到底層的實體、關系及屬性,大大增強了本體結構的穩定性與可擴展性;而在應用過程中,自下而上的歸納與融合能夠逐步提煉出缺失的金融證券知識概念與關系模式,并能夠進一步利用語義數據映射補充至上層本體。此外,連接不同層級和不同子立方體之間的關系對于完整、多維的概念知識描述尤其重要。基于表7的實例及空間向量表示,圖6直觀展示了多層本體立方體的映射、關聯與融合結果。
為了便于本體的存儲與可視化,研究選用本體構建工具Protégé5.5.0版本對證券領域本體進行編輯,通過OWL語言對本體進行描述,部分概念及關系如圖7所示。
在概念層到應用層的實例化過程中,研究采用D2RQ技術實現關系數據向RDF格式的轉換,并將實例化數據結果存儲在RDF數據庫graphDB中。在數據映射技術的基礎上,對本體中術語和數據源抽取知識中詞匯的映射關系等加以構建處理,從而促使不同的數據源的數據能夠綜合在一起,不同源的實體也會指向現實的同一個客體[40],最后融合而成的實例知識庫提供了一種存儲和管理的新方式。
3.6?多層本體立方體評價
本體的評價是領域本體構建非常重要的環節,能夠幫助判斷本體是否符合領域需求以不斷迭代改進。目前尚未由通用而規范的本體評價方法,本文借鑒了黃奇等[41]對本體映射系統的評價體系,將評價的維度分為內容多樣性、結構深入性、語義關聯性和本體實用性4個方面,每個層面采取定性或定量的細化評價方法。
3.6.1?內容多樣性
在內容多樣性的評價層面,研究借鑒了Onto QA本體評價方法。該方法是Tartir S等[42]在2005年提出的一種評價本體通用性的方法,評價指標包括類的豐富性(CR)、關系豐富性(RR)、屬性豐富性(AR)等,如表8所示。
從表8的評價結果可以看出對證券領域本體定義的類和概念相對豐富,并能夠較為充分地體現出關系多樣性,但是概念的屬性相對較少,證實了金融證券領域概念分散、關系復雜且基礎屬性較少的特點。
3.6.2?結構深入性
結構深入性體現了本體在結構關系層面是否充分挖掘,并直接影響了語義層面的關聯性。本文通過設定“多層”本體的概念豐富了本體的結構表現形式,同時各層本體具有完整的映射關系,如層級關系映射、類和實例映射。此外,實例層的立方體結構直觀地刻畫了各實例的維度傾向性和距離關系,為本體結構提供了新的設計思路。
3.6.3?語義關聯性
語義關聯性是對概念實體豐富性和結構深入性的擴展,也是本文的核心內容。語義關聯性可以由層次聚類、關系抽取和維度分類的效果直接體現。層次聚類結果表明,證券領域概念層級關系在文本信息中較難發現,仍需依賴人工梳理;關系抽取結果反映出領域關系的多樣性,基于句法分析的抽取雖然使得部分實體過于冗長,但最大程度地保留了語義信息;維度分類和實體的空間映射作為本文的創新之一,對于豐富各實例的語義表達起到了一定的增強作用。
3.6.4?本體實用性
實用性是從使用者的角度出發對構建的本體進行全面的評價,它是對內容、結構和語義的綜合評判。在實用性層面,借鑒黃奇的評價指標,如表9所示,結合實際情況進行合理的解釋說明,并通過公式φ=∑4i=1αiβi加以量化。
對指標的量化打分需要領域專家的介入,本文構建的本體實用性評分為0.8104,說明具備一定的理論研究和應用價值。然而上述關于實用性的量化指標依舊過于主觀,未來針對特定領域的本體評價體系仍需進一步完善。
4?結論與展望
金融大數據的價值源于其蘊涵的廣泛存在的知識關聯,而傳統的金融大數據的扁平化組織忽略了數據內在的聯系,也沒有考慮多源異構數據的有效組織與融合。本文依托于本體及其構建理論,針對傳統單層領域本體知識表示模型無法進行規范而明確描述的弱點,構建了包含基礎層、概念層和實例層在內的多層領域本體,同時結合證券領域特殊性,考慮“行業—企業—內部環境”三級維度概念對領域知識的影響,借鑒數據立方體概念,提出并構建了“多層金融領域本體立方體”知識表示模型,豐富和擴展了本體構建的理論與方法論體系。在具體的構建過程中,按照知識獲取、挖掘、抽取、關聯及存儲的知識管理周期思路,并依靠主題建模、層次聚類、關系抽取和維度分類等自然語言處理技術實現了證券領域本體架構的半自動化構建,具有一定的應用價值。
當然,任何領域的知識幾乎都是無窮盡的,領域之間也總是存在交叉性,而且領域內的知識也是動態發展變化的,因此本文構建的本體存在一定的局限性。在數據獲取方面,雖然語料來源豐富,但對文本內容的真實性和有效性未作處理,各來源比例也未進行規范;在數據處理方面,由于處理的數據規模有限,加之證券領域概念復雜分散,因此無法全部覆蓋,需要人工干預。未來將會對語料來源進行進一步的規范說明,并繼續探索領域本體自動構建的相關算法;此外,隨著知識圖譜的不斷發展,在后續研究中可以考慮將構建的本體與知識圖譜直接映射,從而更好地應用在領域知識的表示、分析、關聯與融合中。
參考文獻
[1]錢學森,于景元,戴汝為.一個科學新領域——開放的復雜巨系統及其方法論[C]//中國系統工程學會第六次年會,1990:526-532.
[2]Hasan M M,Popp J,Oláh J.Current Landscape and Influence of Big Data on Finance[J].Journal of Big Data,2020,7(1):1-17.
[3]Zhang P,Yu K,Yu J,et al.QuantCloud:Big Data Infrastructure for Quantitative Finance on the Cloud[J].IEEE Transactions on Big Data,2018,4(3):368-380.
[4]丁曉蔚,蘇新寧.基于區塊鏈可信大數據人工智能的金融安全情報分析[J].情報學報,2019,38(12):1297-1309.
[5]陳云.金融大數據[M].上海:上海科學技術出版社,2015.
[6]林天華,張倩倩,祁旭陽,等.證券大數據分析研究[J].計算機技術與發展,2020,30(10):179-186.
[7]李善平,尹奇韡,胡玉杰,等.本體論研究綜述[J].計算機研究與發展,2004,(7):1041-1052.
[8]劉仁寧,李禹生.領域本體構建方法[J].武漢工業學院學報,2008,27(1):46-49,53.
[9]El-Diraby T E.Domain Ontology for Construction Knowledge[J].Journal of Construction Engineering and Management,2013,139(7):768-784.
[10]張文秀,朱慶華.領域本體的構建方法研究[J].圖書與情報,2011,(1):16-19,40.
[11]付苓.大數據環境下領域本體構建框架研究[J].圖書館,2017,(11):66-71.
[12]丁晟春,李岳盟,甘利人.基于頂層本體的領域本體綜合構建方法研究[J].情報理論與實踐,2007,(2):236-240.
[13]Singh A,Anand P.Automatic Domain Ontology Construction Mechanism[C]//Intelligent Computational Systems.IEEE,2013:304-309.
[14]Yan Y,Jiang Z,Liu X,et al.An Intelligent Approach for Construction Domain Ontology[C]//IEEE International Conference on Automation & Logistics.IEEE,2009:1283-1288.
[15]王思麗,楊恒,祝忠明,等.基于BERT的領域本體分類關系自動識別研究[J].情報科學,2021,39(7):75-82.
[16]肖奎,譚小虎,吳天吉.一種面向領域的本體自動構建方法[J].小型微型計算機系統,2013,34(7):1514-1517.
[17]Gomez-Perez A,Manzano-Macho D.A Survey of Ontology Learning Techniques and Applications[J].Technical Report of the OntoWeb Project:Deliverable 1.5,2003.
[18]陳剛,陸汝鈐,金芝.基于領域知識重用的虛擬領域本體構造[J].軟件學報,2003,(3):350-355.
[19]Shih C W,Chen M Y,Chu H C,et al.The Enhancement of Domain Ontology Construction Using a Crystallizing Approach[J].The Experts Systems with Applications,2011,38(6):7544-7557.
[20]Sanchez D,Moreno A.Learning Non-taxonomic Relationships from Web Documents for Domain Ontology Construction[J].Data & Knowledge Engineering,2008,64(3):600-623.
[21]鄭姝雅,黃奇,張戈,等.面向用戶生成內容的本體構建方法[J].情報科學,2019,37(11):43-47.
[22]鄧詩琦,洪亮.面向智能應用的領域本體構建研究——以反電話詐騙領域為例[J].數據分析與知識發現,2019,3(7):73-84.
[23]Shamsfard M,Barforoush A A.The State of the Art in Ontology Learning:A Framework for Comparison[J].Knowledge Engineering Review,2003,18(4):293-316.
[24]Zouaq A,Gasevic D,Hatala M.Towards Open Ontology Learning and Filtering[J].Information Systems,2011,36(7):1064-1081.
[25]Lee C S,Kao Y F,Kuo Y H,et al.Automated Ontology Construction for Unstructured Text Documents[J].Data & Knowledge Engineering,2007,60(3):547-566.
[26]劉萍,胡月紅.領域本體學習方法和技術研究綜述[J].現代圖書情報技術,2012,(1):19-26.
[27]Ruan T,Xue L J,Wang H F,et al.Building and Exploring an Enterprise Knowledge Graph for Investment Analysis[C]//Proceedings of the International Semantic Web Conference.Heidelberg:Springer,2016:418-436.
[28]Kayed A,Hirzallah N,Shalabi L A A,et al.Building Ontological Relationships:A New Approach[J].Journal of the American Society for Information Science and Technology,2008,59(11):1801-1809.
[29]Browne O,OReilly P,Hutchinson M,et al.Distributed Data and Ontologies:An Integrated Semantic Web Architecture Enabling More Efficient Data Management[J].Journal of the Association for Information Science and Technology,2019,70(6):575-586.
[30]Ren R,Zhang L L,Cui L M,et al.Personalized Financial News Recommendation Algorithm Based on Ontology[J].Elsevier B.V.,2015,55:843-851.
[31]Yang B.Construction of Logistics Financial Security Risk Ontology Model Based on Risk Association and Machine Learning[J].Safety Science,2020,123(C).
[32]強韶華,羅云鹿,李玉鵬,等.基于RBR和CBR的金融事件本體推理研究[J].數據分析與知識發現,2019,3(8):94-104.
[33]Li J,Chen S M,Chen W,et al.Semantics-Space-Time Cube:A Conceptual Framework for Systematic Analysis of Texts in Space and Time[J].IEEE Transactions on Visualization and Computer Graphics,2020,26(4):1789-1806.
[34]Esteban P E,Candela G,Trujillo J,et al.Adding Value to Linked Open Data Using a Multidimensional Model Approach Based on the RDF Data Cube Vocabulary[J].Computer Standards & Interfaces,2020,68(1):1-15.
[35]師智斌.高性能數據立方體及其語義研究[D].北京:北京交通大學,2009.
[36]任守綱,徐煥良,劉小軍,等.層次式本體模型的領域分析與設計方法的研究[J].計算機與應用化學,2009,26(11):1385-1388.
[37]Zhang L L,Zhao M H,Feng Z L.Research on Knowledge Discovery and Stock Forecasting of Financial News Based on Domain Ontology[J].International Journal of Information Technology & Decision Making,2019,18(3):953-979.
[38]Petrova G G,Tuzovsky A F,Aksenova N V.Application of the Financial Industry Business Ontology(FIBO)for Development of a Financial Organization Ontology[J].2017,803(1):012116.
[39]Gruber T R.Towards Principles for the Design of Ontologies Used for Knowledge Sharing[J].International Journal of Human-Computer Studies,1995,43(5-6):907-928.
[40]曹敏,鄒京希,唐立軍,等.基于知識圖譜技術的海量非結構化配網數據集成方法[P].云南:CN107330125A,2017-11-07.
[41]黃奇,范佳林,陸佳瑩,等.本體映射系統的評價體系研究[J].情報學報,2017,36(8):781-789.
[42]Tartir S,Arpinar I B,Moore M,et al.OntoQA:Metric-Based Ontology Quality Analysis[C]//IEEE ICDM 2005 Workshop on Knowledge Acquisition from Distributed,Autonomous,Semantically Heterogeneous Data and Knowledge Sources.IEEE,2005.
(責任編輯:孫國雷)
