基于Transformer的中文糾錯系統設計與實現
2022-01-06 11:13:38北方工業大學信息學院李丹丹
數字技術與應用 2021年12期
北方工業大學信息學院 李丹丹
實現中文文本糾錯的目的是提高語言的正確性,同時減少人工校驗成本。序列到序列的深度模型可以避免人工提取特征,減少人工工作量,對文本任務擬合能力強,特別是Transformer模型,近幾年在自然語言處理領域大火大熱。Transformer模型摒棄了傳統序列到序列模型中CNN或RNN的方法和模塊,開創性地將自注意力機制作為編解碼器的核心,不僅訓練速度快,而且解決了RNN處理長距離文本可能導致語義丟失的問題。本論文設計了一個基于Transformer的中文糾錯系統,經過NLPCC 2018官方基準測試集的測試,本論文設計的模型精確率達到27.19,召回率達到12.27,證明本系統有效。
0 引言
當前,全球格局加速演變,經濟全球化、文化多樣化已經深入各國的發展。中國的國際地位正在逐步提高,學習中文的人越來越多,而中文經過幾千年的演變和發展,已形成了一套復雜的文法和句法規則。這些語法和句法規則復雜多變,比如一些字或詞存在多音、多義等現象。當語言使用者對語言掌握不足或粗心大意時,就很容易犯用詞不當、張冠李戴等錯誤。另外爆炸式增長的網絡數據中也存在著大量的錯誤信息,諸如錯別字、錯誤語法等,這極大降低了電子文本的可讀性和規范性。
本文期望設計并實現一款基于中文文本的糾錯系統,旨在實現自動識別并糾正文本錯誤的功能,比如糾正文本中包含的用詞錯誤、語法錯誤。中文糾錯系統不僅可以適用于中文的初學者,幫助外國人學習中文,弘揚中國文化,還可以應用于出版業等需要文本校對的機構。這不僅可以大大降低人力成本,還可以提高文本質量,增加人們對電子文本的信賴度。
1 系統相關技術分析
1.1 Seq2Seq網絡
在文本糾錯任務中,輸入句子的長度與輸出句子的長度不一定相等,輸出句子的長度往往是不確定的。Seq2Seq(Seqence2Sequence)就是用來處理這種輸出長度不確定時采用的方法。如圖1所示,最基礎的Seq2Seq模型包含了三個部分:編碼器、解碼器和連接兩者的中間狀態向量C,編碼器通過學習輸入,將其編碼成一個固定大小的狀態向量C。繼而傳給解碼器,解碼器再通過對狀態向量C的學習來進行輸出。

圖1 Seq2Seq基礎結構Fig.1 Seq2seq infrastructure
1.2 注意力機制
在自然語言處理(NLP)中,輸入向量中包含大量信息,但是輸入的某些部分可能會比其他部分對決策更有幫助,于是在處理當前單詞的時候,希望模型多關注與該單詞相關的信息,并忽略一些不相關的信息。這就是注意力機制所做的事,從大量信息中篩選出少量重要信息,并聚焦到這些重要信息上,忽略大多不重要的信息。在注意力機制中,如圖2所示,權重越大越聚焦于其對應的值向量(Value)上,即權重代表了信息的重要性,而值向量是其對應的信息。
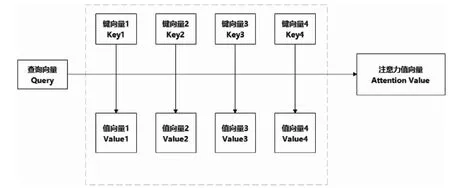
圖2 映射向量Fig.2 Mapping vector
自注意力機制是注意力機制的變體,它減少了對外部信息的依賴,更擅長捕捉數據或特征的內部相關性。這個機制作為本論文所實現模型的核心部分,主要是通過計算詞之間的相關性,來解決長距離依賴的問題。
在這里我們選用的計算公式為公式1:
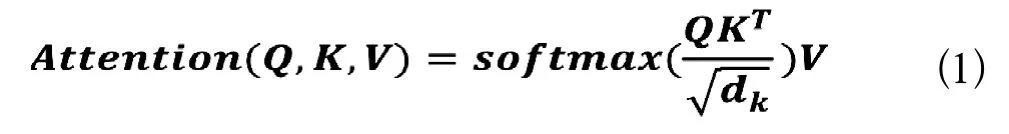
句子中所有詞的鍵向量(K)與編碼詞的查詢向量(Q)點積,然后除以鍵向量的維度的平方根,也就是8,再通過softmax()這個函數歸一化,最后將歸一化后的值乘以值向量。最后一步,我們將這些分數求和得到自注意力的輸出。
1.3 Transformer模型
Transformer的結構如圖3所示,我們可以看出該模型由很多個小部件構成。我們將這些小部件分成四個部分:輸入部分、編碼器部分、解碼器部分、輸出部分。
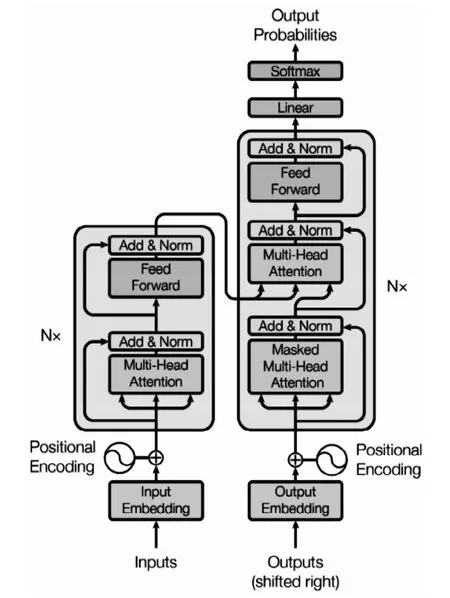
圖3 Transformer結構圖Fig.3 Transformer structure
輸入部分拿到整個模型的源文本(Inputs),然后將源文本中的詞匯通過詞嵌入算法(Input Embedding)轉換為詞向量。在代碼中,詞向量的維度為512維。接著給這些詞向量加上位置編碼(Positional Encoding),將它們放在一個列表中傳給下一個部分——編碼器部分。位置編碼的必要性是由于該模型不包含循環網絡,也沒有卷積網絡,而模型需要利用序列中每一個數據的位置信息。在詞向量中加入關于序列中字符的相對或絕對位置的一些信息,將“位置編碼”添加到編碼器和解碼器堆棧底部的輸入嵌入中。
編碼器部分由N個編碼器(Encoder)構成。這N個編碼器結構相同,互相獨立,不共享參數。詞嵌入只發生在底層的編碼器,也就是說只有最底層編碼器接收的輸入是由輸入部分傳來的詞向量列表,其他編碼器的輸入都是上一層編碼器的輸出。
編碼器可分為兩層:多頭注意力層和前饋網絡層。多頭注意力層里包含了多頭注意力(Multi-Head Attention)和求和與歸一化(Add&Norm);前饋神經網絡層包含了前饋神經網絡(Feed Forward)和求和與歸一化(Add&Norm)。其中求和與歸一化中的求和,其實就是殘差連接。殘差連接的概念已經在上面被介紹過了。在本模型中,它的好處體現在兩個方面:一是解決梯度消失的問題,二是解決權重矩陣的退化問題。
解碼器部分有N個解碼器堆疊而成,這里的N與解碼器部分的N保持一致。解碼器中的網絡層與編碼器中的編碼層大致相同,只有多頭自注意力層的操作方式與編碼器中的多頭自注意力層的操作方式不太相同。在解碼器中,自注意力層只能處理輸出序列中更靠前的位置,這是因為在softmax步驟前會加入掩碼,把后面的位置隱去。之所以加入掩碼是因為在一些生成的自注意力張量中,張量的值可能是由指導未來信息計算得到。未來信息被看到是因為訓練時會把整個輸出結果都一次性進行嵌入,但是理論上解碼器的輸出不是一次就能產生最終結果,而是一次次通過上一次結果綜合得出。
2 系統設計及數據集
2.1 軟硬件環境
本系統的實現是基于一臺Win10的64位操作系統,運行內存為8.00GB,顯卡為GTX 1060,顯存為6.00GB。本系統的編譯在Visual Studio Code完成,系統的實現基于PyTorch庫。它是一個基于Python的可續計算包,提供兩個高級功能:(1)具有強大的GPU加速的張量計算(如NumPy);(2)包含自動求導系統的深度神經網絡。
2.2 系統框架
本系統結構為系統接收用戶輸入的語句,通過加載語言模型來完成問句查錯和錯誤字符串糾正功能,然后系統輸出正確性語句建議。
2.3 數據集
NLPCC 2018 GEC訓練集來自NLPCC2018GEC共享任務測評[1]。
官方地址:http://tcci.ccf.org.cn/conference/2018/taskdata.php
“HSK動態作文語料庫”( http://202.112.195.192:8060/hsk/login.asp )是母語非漢語的外國人參加高等漢語水平考試(HSK高等)作文考試的答卷語料庫,其中收集了1992-2005年的部分外國考生的作文答卷[2]。
3 系統實現
3.1 模型效果
系統所實現的語言模型在上述數據集上進行測試。采用的評價指標為精確率、召回率和F0.5分數,在設計實現的工作中,本文設置了一組實驗,用以證明Transformer模型應用于針對中文的文本糾錯有效。實驗結果如表1所示。

表1 實驗結果Tab.1 Experimental results
3.2 系統界面
系統界面的頭部是系統的中英簡介:中文糾錯系統,Welcome to Chinese Text Correction System,用以說明系統的功能。從上往下的第一個輸入框用于給用戶輸入需要校正的語句,并在輸入框中設置了提示語句“請在此輸入待校正的語句”,提高系統的交互性。在輸入框下方設置一個校正按鈕,用戶點擊該按鈕后,系統會從下方輸入框返回建議的正確語句。下方的這個輸入框對用戶來說是不可編輯的,僅用于系統返回校正結果,避免用戶在輸入框中輸入了數據,造成界面顯示的返回結果不純。
例如,我們在上方輸入框輸入一個錯誤語句“我覺的作業得了滿分。”,點擊校正按鈕后,系統在下方輸入框返回校正后的語句“我交的作業得了滿分。”
4 結語
本系統使用Transformer模型來實現中文糾錯系統,效果客觀,但還有進一步提升的空間,本人認為可以在以下幾個方面改善模型效果:可以將Bert模型應用到該任務當中,以Bert模型為首的各種預訓練方法在各大任務中大放異彩,可以將預訓練模型的隱藏層狀態作為詞向量,以包含更多的語義信息;可以進一步改進Transformer模型,繼Transformer模型大火之后,各種變體的模型相繼誕生,如Transformer-XL、Adaptive Attention Span、Reformer等。
引用
[1] 鄧永康.基于神經機器翻譯的中文文本糾錯研究[D].武漢:武漢大學,2019.
[2] 高印權.基于深度學習的文本語法自動糾錯模型研究與實現[D].成都:電子科技大學,2020.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
中華手工(2017年2期)2017-06-06 23:00:31
光學精密工程(2016年6期)2016-11-07 09:07:19
小學教學參考(2015年20期)2016-01-15 08:44:38
中外會展(2014年4期)2014-11-27 07:46:46
語文知識(2014年1期)2014-02-28 21:59:13
