基于多算法融合的抗遮擋目標跟蹤算法
2021-12-29 03:55:16林穎湯文兵
現代計算機 2021年31期
林穎,湯文兵
(安徽理工大學計算機科學與工程學院,安徽 232001)
0 引言
隨著計算機科技的進步,生活中不斷產生著大量的視頻圖像數據,如何對這些視頻圖像信息進行處理,使得計算機能夠將視頻圖像轉化成數字信息并進行邏輯計算分析,受到了研究人員的廣泛關注,這就是計算機視覺。對運動中的目標進行定位和追蹤[1]是計算機視覺領域的一個重要組成部分。目標跟蹤在軍事、醫療、體育、交通和工業中都有著廣泛應用,但是由于跟蹤過程中,目標形變、光照變化、目標遮擋、相似背景等多種復雜的跟蹤情況使得目標跟蹤成為一個富有挑戰性的課題。
單目標跟蹤是從二維的視頻序列中對物體進行分析和追蹤,由于深度信息的缺乏,容易產生目標自身遮擋或障礙物遮擋。當觀測物體被嚴重遮擋時,跟蹤器的置信度大幅度降低,目標的大部分特征的缺失容易導致跟蹤漂移或者失敗。遮擋問題嚴重影響了跟蹤的精度和效率,為了提高跟蹤算法的魯棒性,亟需提出一個抗遮擋的目標跟蹤算法來滿足實時性的跟蹤需求。
受現有的抗遮擋跟蹤算法的啟發,本文提出了一個基于多算法融合思想的抗遮擋目標跟蹤算法。在基于卡爾曼濾波的Mean Shift算法基礎上增加了一個SVM檢測器。當判斷目標被長時間嚴重遮擋或者目標丟失時,激活SVM輔助其他跟蹤器進行目標的檢測重定位。
1 基于卡爾曼濾波的Mean Shift算法
Mean Shift算法[4]采用的是顏色直方圖作為目標模型的特征,通過不斷迭代向量直到收斂于目標的實時位置。因為實時性好,抗形變、抗旋轉、抗遮擋等優勢而被廣泛應用在實時目標跟蹤中。但是在跟蹤時,如果目標運動速度過快,視頻序列相鄰的兩幀目標并不重疊,那么Mean Shift算法很難追蹤到目標,而且如果密度梯度不是目標形成的,那么收斂到的位置也不是目標所在的位置,此時跟蹤就會失敗。因為算法采用了加權核函數直方圖模型,增加目標中心像素權值并且減小邊緣像素權值,所以當局部被遮擋時,對算法的精確度干擾不大,但是當物體被嚴重遮擋時,目標信息嚴重缺失,此時通過單一的搜索密度極值區域不一定能準確判斷目標位置。
針對這些問題,有的學者將Mean Shift算法與卡爾曼濾波器相結合,用卡爾曼濾波器根據目標前一幀的信息預測目標當前狀態,得到目標可能存在的位置點,作為均值漂移算法的初始迭代位置。
卡爾曼濾波器有著計算簡單和魯棒性的優點,由于卡爾曼預測過程只需要由前一幀的目標運動信息等估計出下一幀目標的狀態信息,因此算法只需要保存目標的上一幀狀態信息,即只需要很小的存儲空間來存儲歷史信息,這使得卡爾曼濾波器具有存儲空間需求小、計算復雜度低且速度快的優勢。
采用卡爾曼濾波器預測到的目標位置比直接用前一幀計算得到的目標位置作為初始迭代點更加準確。這樣不僅能夠減少迭代次數,從而減少計算量,而且可以解決算法在目標高速運動時容易導致跟蹤丟失或者失敗的問題。此外,當目標被嚴重遮擋時,能夠用卡爾曼濾波器結合之前幀中的目標信息,對目標位置進行預測,可以有效地解決障礙物遮擋問題。
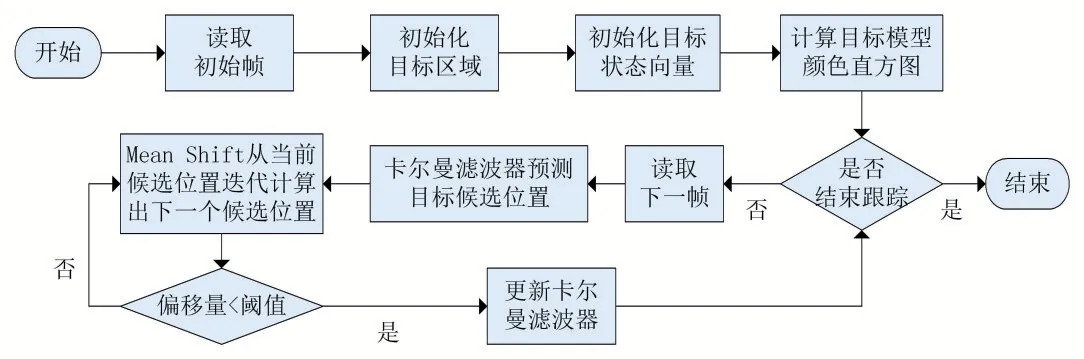
圖1 基于卡爾曼濾波器的Mean Shift算法流程
2 本文算法
2.1 SVM算法
SVM[5](support vector machine,支持向量機)是一種二分類的模型。支持向量機主要有線性和非線性兩大類,其中線性問題又可以分為線性可分和線性不可分。與貝葉斯分類器、決策樹分類器等常見分類器相比,具有更高的泛化性能,能夠更好地應對非線性的二分類問題,能夠很好地處理高位特征。其主要思想是找到空間中一個超平面,滿足將所有正負數據樣本劃分開,且所有樣本到這個超平面的總距離最短。
等妮兒她娘緩過來,瞿醫生劈頭蓋臉就罵了我一通,你不知道這個時候不能同房啊?你是想要她的命啊!我沒敢爭辯,怕當著外人說漏餡了,家丑啊。
也就是說支持向量機算法的最終目的就是尋找到一個超平面,將所有的正負樣本數據區分開,面對線性可分問題可以直接尋找超平面。在實際任務中,由于干擾因素或者樣本數據本身是線性不可分的可能會導致線性不可分問題,線性不可分的情況通常是絕大多數正負樣本是線性可分的,但是由于少數噪聲干擾等因素導致線性不可分的問題。針對這個問題,SVM模型放寬了自身標準,允許某些數據分類“出錯”,具體方法是將松弛變量引入分類約束條件公式中,并且找到盡可能小的松弛變量,同時引入放寬力度的常數作為“懲罰力度”。也就是說線性可分和線性不可分問題都可以變成線性問題。
但是在現實任務中,不是所有的問題都是線性問題,即不一定存在一個超平面能夠將所有的正負樣本數據。針對這個問題,SVM算法引入了核函數的概念,將原本線性不可分的樣本映射到更高一層的多維空間,使得在原來多維空間找不到的超平面可以被找到,也就是使得樣本數據線性可分。SVM常用的核函數有線性核函、徑向基核、Sigmoid核函數等。可以很好地處理非線性問題,是SVM的最大優勢。
2.2 SVM檢測重定位
目標檢測算法的目的是在圖像上預先找出目標可能出現的位置,通過各種特征進行模板匹配,從而檢測到目標所在位置。由于在遮擋過程中,目標的運動信息可能發生改變,導致目標可能出現的位置不確定,從而有大量的窗口需要匹配,再加上目標自身的形變,計算量更大。因此可以將檢測算法與目標跟蹤算法相結合,在有限的區域內預測目標的位置和尺度變化。
在SVM檢測算法中,首先對檢測器進行參數更新,在目標跟蹤過程中,首幀需要手動選擇跟蹤目標,此時首幀的訓練樣本不足,所以需要在跟蹤目標附近隨機選取大量樣本,根據目標占據采樣面積的比例來劃分正負樣本。
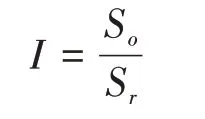
其中,I表示采樣框中目標區域的比例,S o表示目標區域的大小,S r表示采樣區域的大小。在本文算法中,為了防止SVM檢測器過擬合,把I值劃分為三個區間:當I值大于0.8,該采樣區域視為正樣本,當I值小于0.3,視為負樣本,當I值大于0.3小于0.8,該區域不采用。即分類標簽如下:

本文SVM檢測器首幀的訓練流程如下:
(1)根據首幀手動選擇目標的結果,在圖像上進行隨機采樣,根據目標面積占據采樣面積的比例來劃分正負樣本。
(2)對所有正負樣本進行歸一化操作,使得目標尺度歸一化為指定大小。
(3)提取所有正負樣本特征,根據提取樣本特征和該樣本的標簽進行SVM檢測器訓練,得到相應的參數。
SVM檢測器從初始幀開始訓練,進行正負樣本的采樣。為了保證檢測器模板的準確性,在后續的跟蹤過程中,每經過5幀高置信度跟蹤,更新一次SVM檢測器參數。當檢測到目標被長時間嚴重遮擋或者丟失時,激活SVM檢測器。
2.3 檢測遮擋機制
Mean Shift算法的基本流程是分別計算目標和候選目標模型的概率密度,并計算它們的相似度,找到使得相似度取最大值的位置,為目標在這一幀的位置。因此本文選擇基于顏色特征直方圖的遮擋因子來判斷被局部遮擋和完全遮擋。
目標模型的顏色特征直方圖概率密度表示為q={q u}u=1,…,m,公式計算如下:
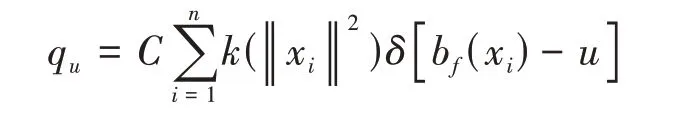
候選目標模型概率密度表示為:p={pu}u=1,…,m,公式計算如下:
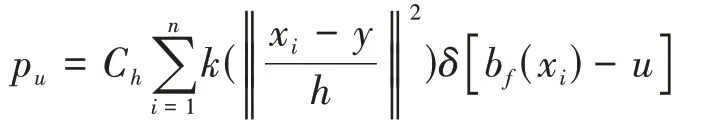
其中y表示當前幀候選目標區域像素位置的中心點,h為核剖面半徑,在Mean Shift算法中,核函數的帶寬通常是固定的,取窗寬的一半,C h為歸一化常數。
若y0為目標當前位置,令:

當t u>1時,判斷目標被部分遮擋,當t u=-1時,目標被全部遮擋。

其中,λ∈[ 1,∞),為遮擋程度參量,設遮擋因子occ為當occ>ζ(ζ∈(0,1)),則認為目標被遮擋。
3 實驗結果及分析
為了驗證本文算法對目標遮擋問題有更好的跟蹤效果,選取了OTB數據集中有代表性的幾組發生遮擋的視頻序列進行實驗分析,并與傳統的Mean Shift算法和基于卡爾曼濾波的Mean Shift算法進行對比,從實時性和魯棒性上對三種算法的性能進行對比分析。
3.1 部分遮擋狀態下的目標跟蹤結果對比
為了驗證本文算法的抗遮擋性能,選取OTB數據集中的Woman視頻序列進行仿真實驗。為了避免光照變化問題對算法的影響,選取了同一光線強度下視頻序列跟蹤效果的對比,是一個行人被汽車局部遮擋的到脫離遮擋的過程,分別取其中四幀做效果展示。如圖2所示,在目標被局部遮擋時,四種算法的跟蹤誤差明顯變大,但是由于Mean Shift算法有一定的抗遮擋性,所以在目標被遮擋時,仍然能夠成功跟蹤到目標,但是跟蹤效果較差。而卡爾曼濾波和本文的算法由于有位置預測的能力,在整個遮擋過程中表現良好。當目標脫離遮擋時,三種算法都找回了目標并繼續跟蹤,誤差逐漸減小。實驗表明三種算法對局部遮擋都具有一定的魯棒性。

圖2 Woman視頻序列跟蹤結果對比
為了進一步驗證本算法改進后的效果,對10次跟蹤平均誤差進行統計,具體方式是對視頻序列每幀手工選定目標實際位置中心點與算法跟蹤位置中心點計算歐式距離。圖3給出了傳統Mean Shift算法和本文算法在10次跟蹤后更細致的平均誤差對比,由此可以看出本文算法在復雜情況下具有更高的穩定性。
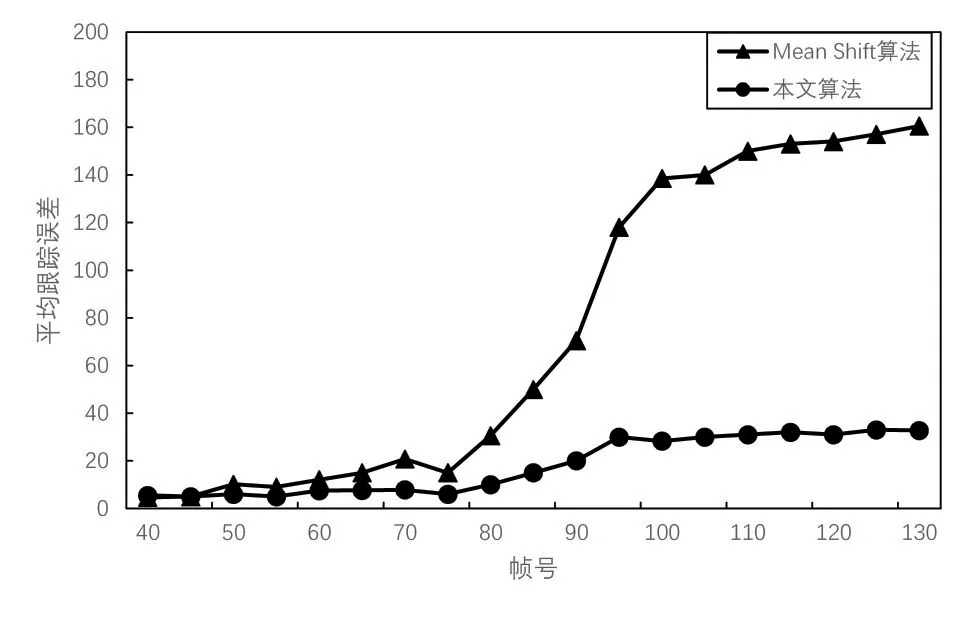
圖3 平均跟蹤誤差比較
3.2 嚴重遮擋狀態下目標跟蹤結果對比
為了進一步驗證本算法在遮擋情況下的跟蹤效果,選取OTB數據集[6]中一組嚴重遮擋情況下的視頻序列Coke,是一瓶可樂被葉子嚴重遮擋到完全遮擋最后脫離遮擋的過程,選取250,255,270,280幀展示效果。如圖4所示,Mean Shift算法由于目標模型被污染,跟蹤窗口漂移到了障礙物上,導致跟蹤失敗。而基于卡爾曼濾波的Mean Shift目標跟蹤算法和本文算法在目標被完全遮擋時可以預測目標位置進行追蹤,在結束遮擋后,仍然能夠繼續進行追蹤。但是通過兩個算法在270幀的對比可以發現,本文算法的誤差率減少6.2%。當目標脫離完全遮擋時,本文的算法能更加準確快速地捕捉目標,要優于基于卡爾曼濾波的Mean Shift目標跟蹤算法。

圖4 Coke視頻序列跟蹤結果對比
4 結語
本文針對跟蹤過程中的遮擋問題,基于多算法融合的遮擋算法思想,提出了一種將Mean Shift、卡爾曼濾波和SVM相結合的抗遮擋算法。通過實驗表明,本文提出的多算法融合的改進算法能夠在滿足實時性的情況下對局部遮擋和嚴重遮擋的目標進行跟蹤,很好地解決了目標跟蹤過程中的遮擋問題。
本文提出的算法在一定程度上相較于其他遮擋算法具有更好的跟蹤效果,較原算法提升了在遮擋情況下算法的精確度。但是依然存在一些不足和提升空間,有待于進一步的學習、研究和改進。
首先本文的研究方向是單目跟蹤問題,并沒有考慮到多目標跟蹤中更復雜的遮擋情況,還需要進一步提升;其次是并沒有對目標檢測方向進行深入研究,選擇了SVM檢測算法來作為檢測器,所以后續需要對主流的目標檢測算法進行深入研究,對目標檢測問題進一步完善;最后是本文更側重于在滿足實時性和實用性的情況下改進算法,所以沒有過度研究基于深度學習模型的跟蹤算法,因此,在后續的研究中可以更多的關注基于神經網絡方向的跟蹤模型。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
測控技術(2018年12期)2018-11-25 09:37:34
北京航空航天大學學報(2017年9期)2017-12-18 07:12:25
海峽科技與產業(2016年3期)2016-05-17 04:32:12
電源技術(2016年9期)2016-02-27 09:05:39
電源技術(2015年1期)2015-08-22 11:16:28
