基于多粒度語義分析的二進制漏洞搜索方法*
2021-12-23 06:18:46馬慧芳閆彩瑞
計算機工程與科學 2021年12期
劉 豪,馬慧芳,龔 楠,閆彩瑞
(西北師范大學計算機科學與工程學院,甘肅 蘭州 730070)
1 引言
軟件開發項目組通常進行代碼復用以提高生產力和效率,目前最常用的方式是直接復制開源代碼以及引用第三方代碼庫。然而,在此過程中如果監管不善,就可能會導致沒有經過補丁修正的漏洞程序傳播至不同軟件程序,進而傳播至不同操作系統乃至平臺架構;其次,不同編譯器在編譯過程中可能會產生交叉優化二進制文件,而且源代碼可能會隨著時間推進發生演變(例如經過補丁優化),產生交叉版本二進制文件,這些潛在因素都可能導致二進制漏洞的產生。一旦這些漏洞被別有用心之人利用,將對公司資產和運營產生不利影響。例如,若信息管理系統因漏洞未及時修補而受到黑客攻擊或控制,將導致用戶私人信息泄露,并且受攻擊系統也可以作為黑客攻擊其他系統的跳板。
相關研究人員已經開展了很多基于代碼克隆的二進制文件相似度檢測和二進制漏洞搜索工作,這些工作主要基于二進制函數的控制流圖CFG(Control Flow Graph)來進行漏洞檢測。這些方法的性能在合理配置下均表現良好,但是可能會導致大規模二進制文件損失以及漏洞搜索的低準確率。例如,Genius[1]利用譜聚類算法生成代碼本,并基于二部圖匹配算法計算特定屬性控制流圖ACFG(Attribute Control Flow Graph)與代碼本中每個有代表性的屬性控制流圖(ACFG)之間的相似度,但此方法相當耗費時間,且準確率低;Gemini[2]提取出與Genius[1]相同的輕量級特征,并只依賴屬性控制流圖(ACFG)通過深度神經網絡DNN(Deep Neural Network)來生成二進制函數嵌入向量,但由于特征提取不夠合理,其搜索效率仍然較低;VulSeeker[3]優化了特征提取方式,以提取控制流圖(CFG)和數據流圖DFG(Data Flow Graph),組成標記語義流圖LSFG(Labeled Semantic Flow Graph),并通過深度神經網絡來獲取二進制函數的嵌入表示;CACompare[4]通過模擬函數執行過程來提取函數中的語義簽名,基于提取出的語義簽名進行相似度檢測,但是其模擬函數執行過程相當耗時,導致整體搜索效率低下;BinSeeker[5]則首先提取出函數的控制流圖(CFG)和數據流圖(DFG)組成標記語義流圖,并通過深度神經網絡(DNN)先篩選出一批漏洞函數,再進一步進行函數模擬來篩選出漏洞函數;Bingo[6]則利用選擇性代碼嵌入和長度可變部分追蹤來計算函數語義,這些語義用于構建函數模型,以進行相似度的比較以及漏洞搜索,但Bingo不支持跨平臺的漏洞搜索。α Diff[7]旨在應對交叉版本二進制文件相似度檢測挑戰,將二進制文件分為函數級和模塊級進行相似度檢測;趙鵬磊等[8]實現了基于標準化的無監督特征提取方法,并通過引入注意力機制來自動學習屬性控制流圖中不同節點的權重。這些方法在合理的實驗配置下有著不錯的搜索性能,然而,其分析二進制文件和漏洞文件的語義過于單一,進一步限制了其搜索性能及效率的提升。
本文提出了一種基于多粒度語義特征進行相似度比較的跨平臺二進制漏洞搜索方法Taurus,解決了跨平臺以及交叉優化所帶來的二進制文件代碼差異問題。給定待檢測二進制文件和數據庫中的二進制漏洞,Taurus分別對基本塊、函數和模塊3種不同粒度下的語義進行提取及分析,并計算3種粒度下的語義特征相似度。在獲取到3種粒度下語義特征的特征相似度后,Taurus將計算其總體相似度,然后對相似度得分進行降序排序,最終判定目標二進制文件中是否含有疑似漏洞。
目前本文已實現Taurus原型程序,并將其與各種配置下的最新漏洞搜索方法進行了比較,結果表明Taurus具有更好的搜索性能。本文貢獻如下所示:
(1)首次提出基于多粒度語義特征分析的二進制漏洞搜索方法,以提高漏洞搜索的準確性和效率。
(2)優化了原始的語義特征學習方法,通過標記語義流圖(LSFG),深度神經網絡(DNN)學習出的嵌入表示信息更加豐富。
2 Taurus方法
本節主要介紹Taurus方法及其實現原理。Taurus的任務是確定目標二進制文件中是否包含與已知漏洞相似的函數,其輸入是來自待檢測二進制文件和數據庫中的二進制漏洞。如圖1所示,Taurus共包含3個部分:多粒度語義特征提取、語義生成和相似度計算。給定待檢測二進制文件以及數據庫中的某個二進制漏洞,Taurus首先通過交匯式反匯編工具IDA Pro[8]提供的插件IDA Python提取2個文件中每個函數的控制流圖(CFG),同時通過LLVM RR[9]插件推斷2個基本塊之間是否具有數據指向邊緣,從而生成數據流圖(DFG),最后將控制流圖(CFG)和數據流圖(DFG)整合為標記語義流圖(LSFG),并通過特定的語義提取規則將其轉換為初始數值向量,通過深度神經網絡(DNN)計算出其在基本塊粒度下的相似度值;然后,Taurus提取出2個文件的函數調用圖,并獲取函數調用圖的入度和出度,通過歐氏距離計算出其在函數粒度下的相似度值;最后,Taurus提取出2個文件的導入函數集,通過集合交并關系獲得其數值向量,亦通過歐氏距離計算出其模塊粒度下的相似度值。在獲取到3種粒度下的相似度后,Taurus將整合這3種相似度并計算2個文件中函數的總體相似度得分。在計算出待檢測二進制文件與數據庫中每一個二進制漏洞的相似度后,Taurus將所有的相似度得分進行降序排序,輸出該二進制文件的漏洞檢測報告。
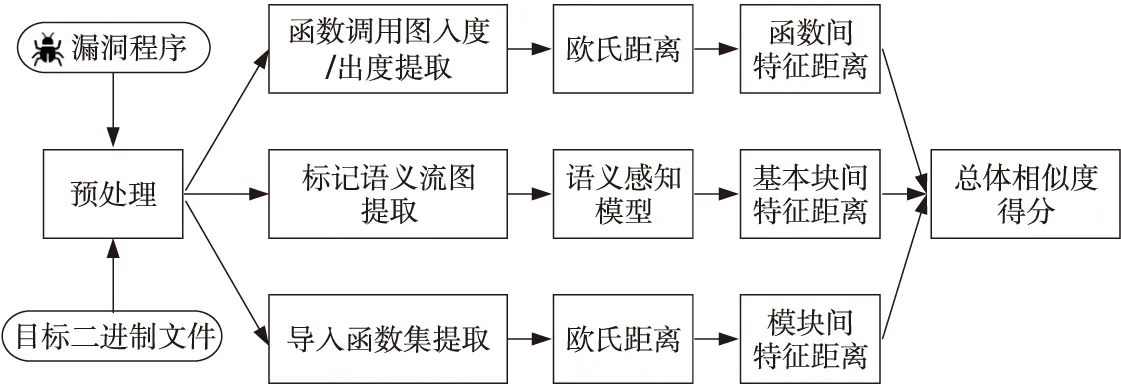
Figure 1 Framework of binary vulnerability search method based on multi-granularity semantic analysis圖1 基于多粒度語義分析的二進制漏洞搜索方法框架
2.1 基本塊間語義特征
2.1.1 標記語義流圖
標記語義流圖(LSFG)包含控制流圖(CFG)和數據流圖(DFG),它們的邊緣分別標記為0和1,其中0代表控制關系,1代表數據關系。使用標記語義流圖(LSFG),目的是提高模塊間語義生成的準確性,其同時考慮了函數中基本塊的控制關系和數據關系,這將有效地緩解不同平臺之間不同控制流圖(CFG)引入的結構干擾。本文使用IDA Pro提供的IDAPython為每個二進制函數的基本塊創建控制流圖(CFG),并利用IDA Pro的LLVM RR插件推斷2個基本塊之間是否有數據指向邊緣。對于來自2個不同的基本塊中滿足控制流圖(CFG)拓撲的2條指令i和j,如果指令i為一個寫存儲器操作,而指令j讀取相同的存儲器地址,則為這2個基本塊創建一條數據相關的邊。另外,僅保留不同塊之間的數據相關性,并且2個基本塊之間至多存在有一條數據相關性邊。Taurus將每個函數的控制邊和數據邊存儲在2個文件中。
2.1.2 基本塊間特征提取
通過參考已有工作[3]中使用的特征,并針對不同的特征集執行一系列代碼克隆實驗,本文最終確定使用表1所示的8種類型特征作為每個基本塊的初始語義表示。這些選定特征可以在各種體系結構和編譯優化配置下輕松提取和更改。利用IDA Python為每個基本塊提取特征,然后根據表1將基本塊中的8種特征指令按照特征數量編碼為數值向量,如圖2所示。對于每個二進制函數,函數中所有基本塊的數值向量都存儲在單獨的文件中。
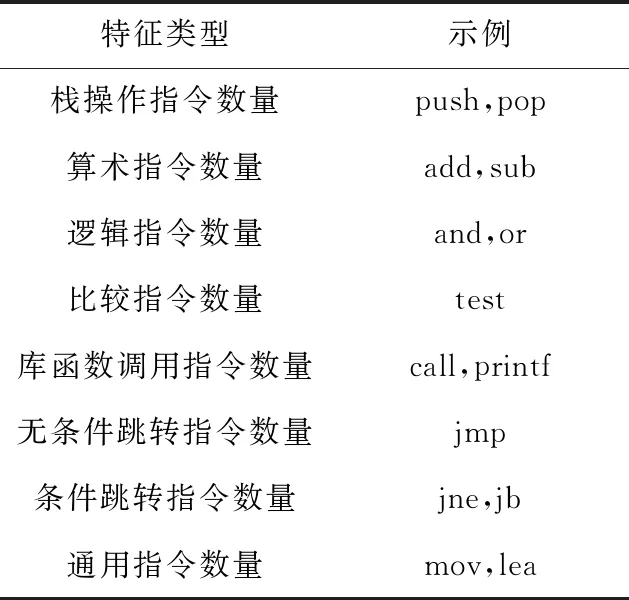
Table 1 Basic-block level features used by Taurus表1 Taurus使用的8種基本塊特征
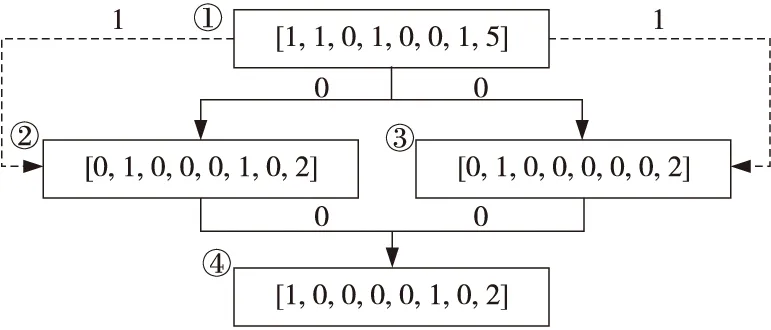
Figure 2 An example of the block feature extraction圖2 特征提取的一個例子
對于基本塊間的特征提取,本文通過語義感知深度神經網絡(DNN)模型來完成。在該模型中,輸入為函數中所有基本塊的d維初始特征向量,輸出則是表示函數語義的p維嵌入向量。為了精確捕捉函數語義,還要考慮到控制流圖中基本塊之間的數據以及控制關系。受VulSeeker[3]的啟發,并參照Structure2vec[10]神經網絡和Siamese[11]網絡結構,本文提出如圖3所示的語義感知深度神經網絡(DNN)模型。
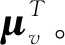
第t層嵌入的處理過程通過式(1)獲得:
(1)
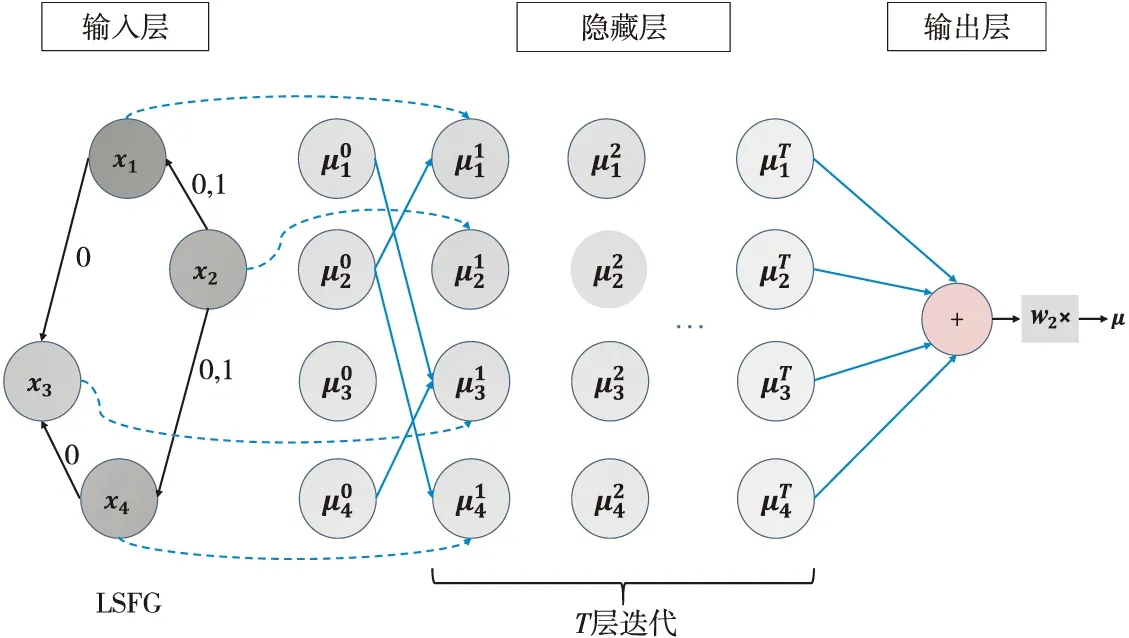
Figure 3 DNN model of Taurus圖3 Taurus的深度神經網絡模型
其中,w1是每層更新過程中的d×p維的待訓練參數矩陣,C和D為待表示節點的控制流鄰居節點集合和數據流鄰居節點集合,σc和σd是以ReLU作為激活函數的n層全連接神經網絡,如式(2)所示:
(2)
其中,n代表每個向量的嵌入深度,即全連接神經網絡的層數;Ti和Oi(1≤i≤n)為每層用到的p×p維的參數矩陣;lc和ld分別為式(1)中待表示節點v的控制流鄰居節點和數據流鄰居節點的向量和。
基本塊間語義特征提取過程如算法1所示。
算法1標記語義流圖嵌入生成
輸入:標記語義流圖G=〈V,Ec,Ed〉。
輸出:嵌入向量u。
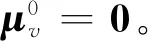
步驟2 fort=1toTdo
步驟3forv∈Vdo
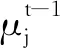
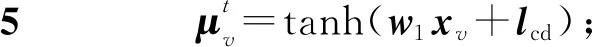
步驟6endfor
步驟7 endfor{將所有更新后的向量累加}
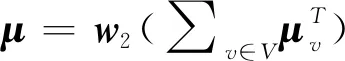
在得到待檢測二進制文件的嵌入Ea和待檢測二進制漏洞的嵌入Ev之后,通過式(3)計算其基本塊間語義特征距離:
(3)
2.2 函數間特征提取
首先要明確的是函數不能單獨運行,其需要在同一個二進制文件中調用其他函數或者被其他函數調用運行,這種特征稱為函數間語義特征,可以用函數間的調用圖來表示。值得注意的是,相似函數有相同調用圖,理想狀態下,需要考慮所有函數的調用圖。
本文只從函數調用圖中提取出1個節點的入度和出度來作為函數間語義特征,記為g(Ia)。具體來說,以目標函數Ia為例,令in(Ia)和out(Ia)表示函數Ia的函數調用圖的入度和出度,如式(4)所示:
g(Ia)=(in(Ia),out(Ia))
(4)
然后通過歐氏距離來獲取函數間語義特征距離,如式(5)所示:
D2(Ia,Iv)=‖g(Ia)-g(Iv)‖
(5)
2.3 模塊間語義特征提取
對于目標二進制函數,它需要調用一組導入函數,記為S(Ia)。值得注意的是,即使在版本更新過程中這些函數發生了變化,相似函數也會調用相似的導入函數,因為在模塊開發過程中未替換導入函數集,因此也可將導入函數集視為第3種語義,稱為模塊間語義。對于模塊間語義特征的提取,通過處理2個文件導入函數集的集合交并關系,將其轉換為數值向量,并通過計算歐氏距離來獲取二者在模塊粒度下的相似度。對于集合關系的獲取,通過式(6)將導入的函數集嵌入到超集的空間中:
h(A,B)=〈x1,x2,…,xs,…,xt〉
(6)
其中,集合B為集合A的超集,t為超集B的勢。若超集B中的第s個元素xs存在于集合A中,則記xs為1,否則為0。
對于目標函數Ia和漏洞函數Iv,記其二進制文件分別是Ba和Bv,則其導入函數集分別為imp(Ia)和imp(Iv),其二進制文件的導入函數集分別imp(Ba)和imp(Bv)。接下來,將超集定義為imp(Ba)∩imp(Bv),并利用式(6)分別將二進制文件和二進制漏洞在模塊粒度下的語義特征轉換為數值向量,然后利用式(7)計算其模塊粒度下的語義特征相似度:
D3(Ia,Iv)=‖h(imp(Ia),imp(Ba)∩imp(Bv))-
h(imp(Iv),imp(Ba)∩imp(Bv))‖2
(7)
2.4 總體相似度計算及漏洞相似度排名
給定2個函數Ia和Iv,根據前文所述,可以計算出它們的基本塊間特征距離(D1)、函數間特征距離(D2)和模塊間特征距離(D3)。
由于函數的導入函數集通常比較穩定,因此通常模塊粒度下的語義特征相似度D3數值位于0~1;其次,基本塊粒度下的語義特征相似度D1同樣也是位于0~1。由于交叉版本的二進制文件中的相似函數可以有不同的調用圖,特別是不同的入度和出度,因此函數粒度下可能會有相對較大的距離D2。為了解決這個問題,本文預定義了一個(0,1)內的超參數λ,以抑制D2數值過大的影響。因此,2個函數的總體相似度計算方法如式(8)所示:
D(Ia,Iv)=D1(Ia,Iv)+1-λD2(Ia,Iv)+D3(Ia,Iv)
(8)
對于任意待檢測二進制文件,可以計算出其與數據庫中每一個二進制漏洞總體相似度得分,然后依照相似度得分進行降序,從而獲取該二進制文件的漏洞檢測報告。
3 實驗
Taurus程序主要由3個模塊構成:函數內語義特征提取組件、函數間語義特征提取組件和基本塊間語義特征提取組件。Taurus使用的工具以及插件均基于IDA Pro 7.0。本節評估并測試Taurus在不同平臺以及版本優化下的漏洞搜索性能,旨在回答以下3個問題:
(1)在跨平臺二進制函數搜索中,Taurus是否比其他二進制漏洞搜索方法更準確?
(2)Taurus完成漏洞搜索任務所耗費的時間如何?
(3)Taurus是否可以在實際應用中進行漏洞搜索?
3.1 實驗配置
本文實驗平臺配置為:Intel i7-8750H CPU,6核12線程,3.90 GHz ,6 GB顯存 NVIDIA GTX 1060 GPU、內存為16 GB,且操作系統版本為64位Windows 10,版本號為2004。
3.1.1 數據集配置
為了公平地驗證Taurus的漏洞搜索性能,本文沿用了Genius[1]和Gemini[2]中構造的2個人工數據集來評估不同的搜索任務。其中,數據集I用來訓練Taurus,同時將Taurus與Genius、Gemini以及Taurus的2個變種Taurus-1和Taurus-2進行比較,Taurus-1是Taurus刪除了函數間語義特征提取模塊的版本,而Taurus-2是Taurus刪除了模塊間語義特征提取模塊的版本;數據集II用于測試Taurus的漏洞搜索效率,由于其他工具涉及跨平臺漏洞搜索,因此需要在不同平臺上進行漏洞搜索。
數據集I沿用Gemini中的人工數據集,從5個不同的開源程序中編譯了一組二進制文件:libjepg,Wget,OpenSSL,Coreutils和curl。通過具有4個優化配置(O0~O3)的2個編譯器(GCC和Clang)將這些開源程序分別編譯至3種體系結構(Windows X86/X64,MIPS32/MIPS64,ARM34/ARM64)。這個數據集中包含735 540個具有9 345×103個基本塊的二進制函數,具體信息如表2所示。
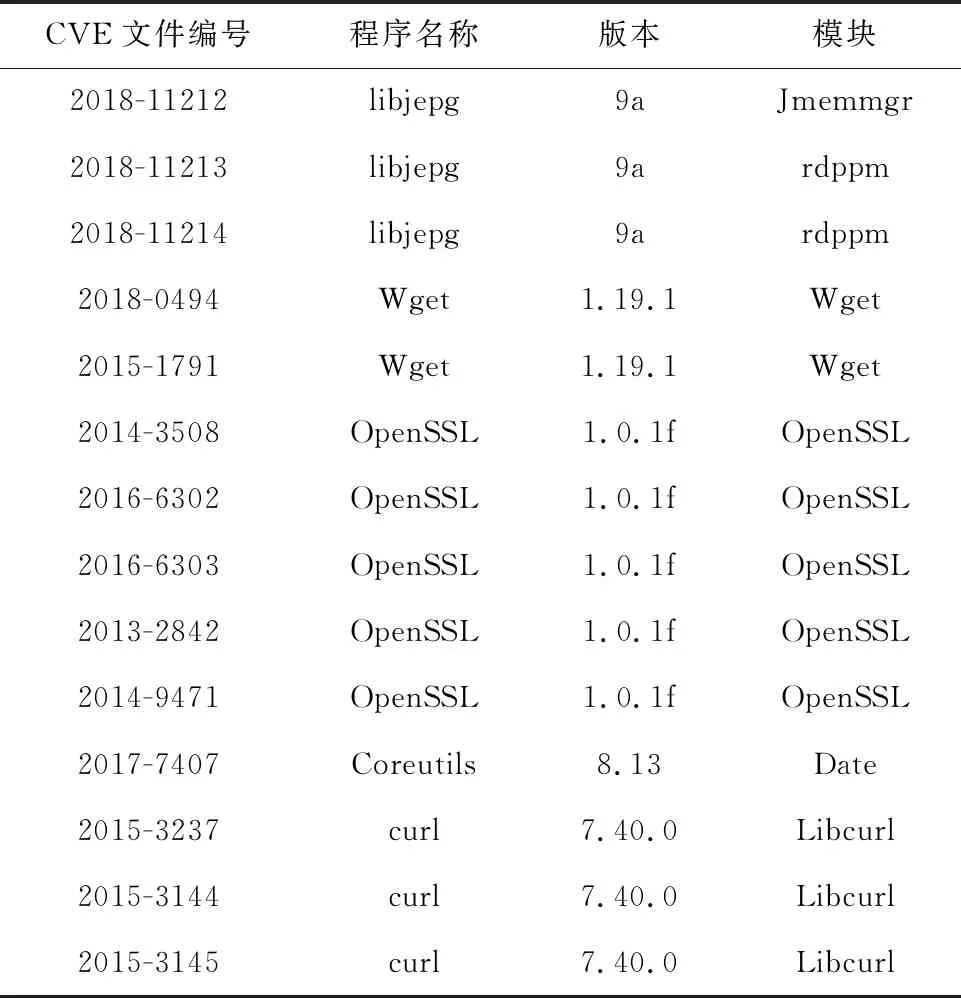
Table 2 Open-source programs表2 開源程序列表
數據集II由從各種不同的平臺選擇的4 649個物聯網固件鏡像組成,并且這些固件鏡像來自Genius[1]。
3.1.2 基線設置
Taurus需要一個帶有大量標記的相似和不相似二元函數對的數據集進行訓練,可以通過以下方法在數據集I中自動標記樣本:將代碼中的函數f編譯為一組二進制函數,記為set(f)={f1,f2,…,fn}。對于set(f)中的每一個函數fi,隨機選擇一個不同的函數fj(i≠j)組成一個相似的樣本對,記為Sam(fi,fj,+1)。同時隨機選擇set(f)中不存在的另一個二進制函數gk來模擬一個包含fi的不相似樣本,記為Dis(fi,gk,-1)。最后,總共構造了大約3 677×103個樣本對,且沒有完全相同的樣本對,只有相似和不相似的樣本對。
3.1.3 訓練方法
為了獲得更準確的實驗結果,本文通過10折交叉驗證對Taurus進行訓練和評估,即將樣本對分為10個子集,9個子集用來訓練模型,1個子集用來測試模型,重復此操作10次,每次選擇一個不同的子集進行測試。每次完成訓練后將隨機調整訓練集。訓練的目的是獲得模型Taurus中的參數:w1,T1,…,O1,…,On和w2,以優化式(9)所示的目標函數:
(9)
其中yi為待預測二進制文件的真實標簽。
為了獲得基本塊間特征提取模型的最合適參數,本文通過隨機梯度下降優化(即式(9)),直到模型可以達到最佳分類性能,終止訓練。經過上述訓練過程,Taurus中的基本塊粒度語義特征提取模型將有效地將標記語義流圖(LSFG)轉換為嵌入。
3.2 漏洞搜索準確性評估
本節主要探討問題(1),即本文方法是否可以更準確地進行跨平臺漏洞搜索。
Taurus的任務是準確識別存在漏洞函數的二進制文件,通過數據集I對Taurus,Taurus-1,Taurus-2和Gemini的漏洞搜索效率進行評估。分別從數據集I中隨機抽取2 100對二進制文件來比較Taurus與Gemini的漏洞搜索效率,其中3個不同平臺各700對,最終結果如圖4所示。
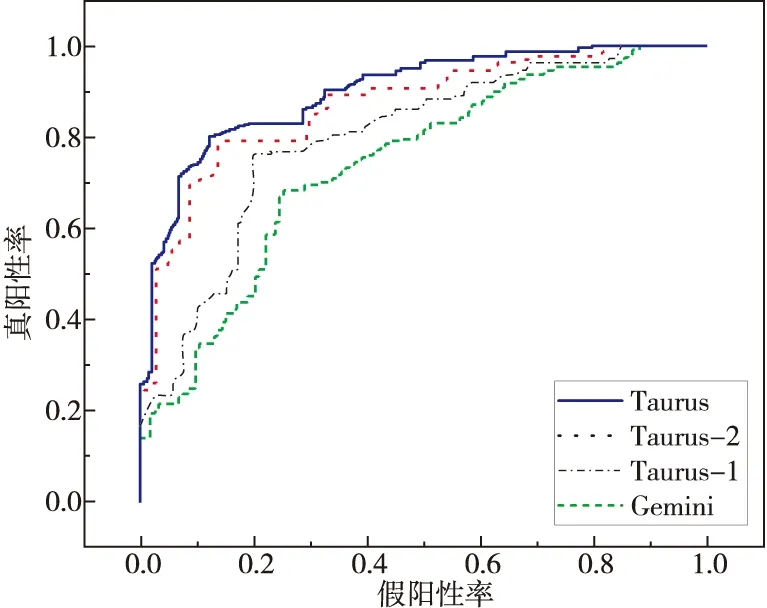
Figure 4 ROC curves of Taurus,Taurus-1,Taurus-2,and Gemini圖4 Taurus,Taurus-1,Taurus-2和Gemini的ROC曲線
從圖4可以觀察到,Taurus及其2個變種的ROC曲線都位于Gemini[2]之上,可以推斷出Taurus有較大的可能性先對漏洞函數進行分類。Taurus的AUC值為86.49%,比Gemini[2]的高13.19%,由此可以看出在漏洞搜索效率方面Taurus要優于Gemini[2],因為其可以獲取到更多的語義信息,有助于高效地識別漏洞函數。
另外,值得注意的是,當分別刪除函數間語義特征提取模塊和模塊間語義特征提取模塊時,Taurus-1和Taurus-2的漏洞搜索性能依然呈上升態,進一步表明了本文方法的有效性。控制語義粒度的目的是分別探究函數間語義特征和模塊間語義特征對漏洞的搜索效率的影響,實驗結果表明,在分別去除函數間語義特征提取模塊(Taurus-1)和模塊間語義特征提取模塊(Taurus-2)后,Taurus-1的AUC值比Taurus-2的小13.76%,這表明對于二進制文件相似性檢測而言,函數級語義要比模塊級語義重要得多。
3.3 漏洞搜索效率驗證
本節主要回答有關Taurus完成漏洞搜索任務的時間成本的問題(2)和有關現實生活中搜索性能的問題(3),在此分別討論了對數據集II進行漏洞搜索的時間和對數據集I進行訓練的時間。表3列出了Genius、Gemini和Taurus的程序搜索時間,第2列可以觀察到每個程序包含的函數數量,而第3~5列是每種方法執行漏洞搜索所耗費的時間。
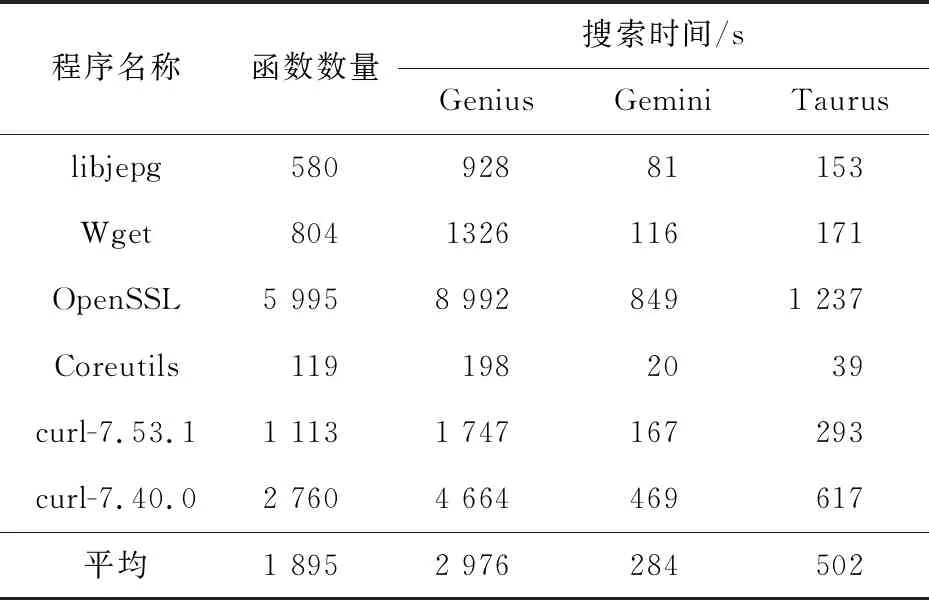
Table 3 Searching time of three methods表3 3種方法所耗費的搜索時間
表3中,所有程序平均包含1 895個函數。在搜索效率方面,Gemini和Taurus所需的時間較短,平均只需284 s和502 s即可完成漏洞搜索,這意味著Gemini和Taurus平均只需要0.15 s和0.26 s來計算目標函數和漏洞函數之間的相似度。但是,Genius需要2 976 s才能完成1 895個函數中的漏洞搜索。與Gemini和Taurus相比,Genius的時間成本要高得多,比前二者分別高10.48倍和5.93倍。結合圖4綜合來看,盡管Taurus比Gemini花費了更多的時間,但它卻以少量的時間為代價實現了更高的搜索準確性,因此Taurus更適用于大規模代碼的漏洞搜索任務。
對于本文配置的100 000對函數樣本,Genius通過譜聚類算法生成模型大約需要50天。而Gemini和Taurus受機器配置的限制,模型訓練的時間成本分別約為17天和23天。但是,訓練過程為一次性,之后幾乎不會影響漏洞搜索效率。這意味著一旦完成模型參數訓練,就可在任何情況下重用它,而無需再花費時間訓練。
3.4 參數研究
本節主要討論如何設置參數可以使得Taurus達到最佳性能,同時還評估了不同參數對漏洞搜索性能的影響。Taurus語義學習模塊的參數主要包括:嵌入尺寸、嵌入深度和迭代次數。
3.4.1 嵌入尺寸
嵌入尺寸是指用于表示函數語義的嵌入向量的維數p。與前文相同,本節還是通過ROC曲線來評估嵌入尺寸對漏洞搜索性能的影響。圖5是Taurus在不同嵌入尺寸下的ROC曲線,可以推斷,當嵌入尺寸為64時,Taurus的AUC值相當可觀。同時考慮到訓練和預測時間的成本,本文最終選擇64作為默認嵌入尺寸。
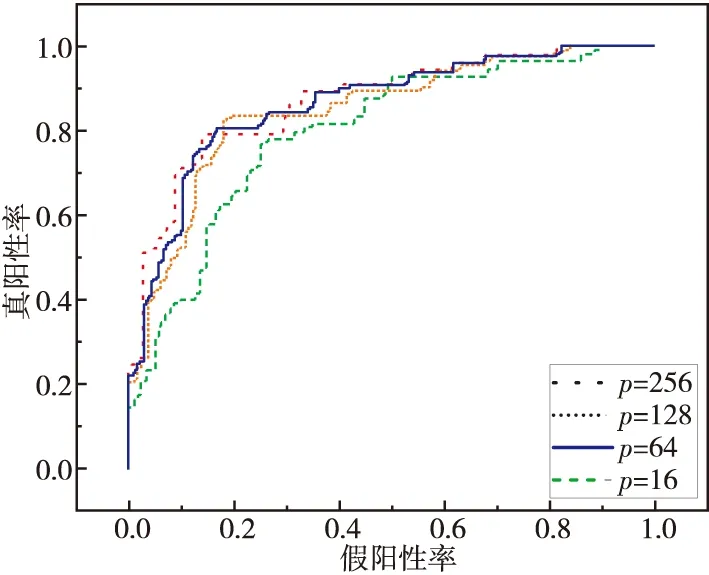
Figure 5 ROC curves of different embedding sizes圖5 不同嵌入尺寸下的ROC曲線
3.4.2 嵌入深度
嵌入深度是指Taurus中基本塊間語義特征提取模塊中全連接神經網絡的層數n。圖6為改變嵌入深度的效果。當嵌入深度為2時,可以獲得相對最佳的AUC值。結果表明,通過添加2層全連接神經網絡,生成的嵌入向量將具有更高的表示性能和更好的函數語義捕獲。但是,當嵌入深度大于2時,只會徒增時間成本和人工成本。
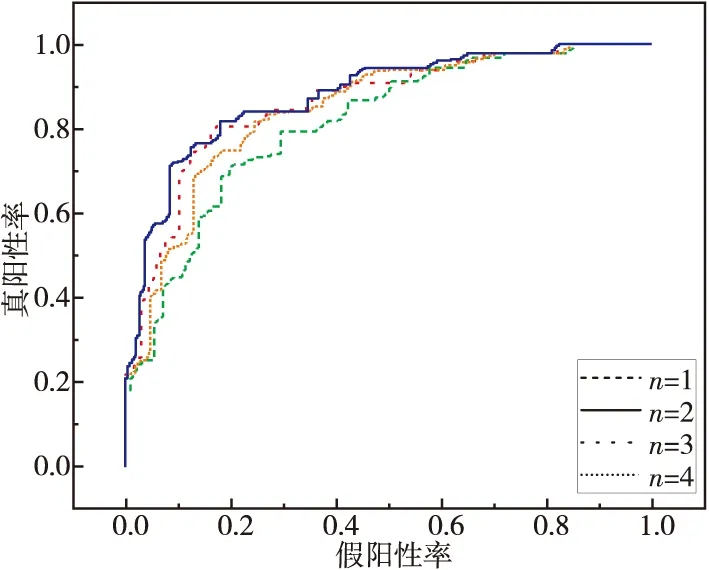
Figure 6 ROC curves of different embedding depths圖6 不同嵌入深度下的ROC曲線
3.4.3 迭代次數
如前文所述,迭代次數是指Taurus中基本塊間語義特征提取模塊的隱藏層層數T。圖7為Taurus在不同迭代次數下的ROC曲線。從圖7中可以推斷當迭代次數為6時,本文方法將獲得漏洞搜索的最佳性能,且在條件允許的情況下,迭代次數越多,結果越好。
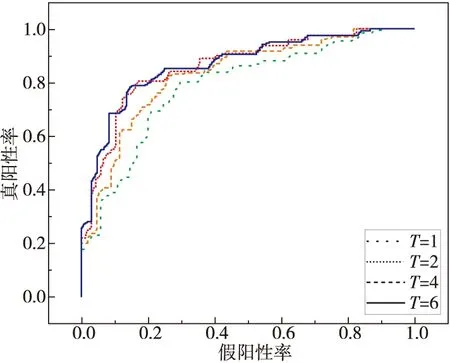
Figure 7 ROC curves of different iterations圖7 不同迭代次數下的ROC曲線
4 結束語
本文提出了一種基于3種語義特征的跨平臺二進制漏洞搜索方法Taurus,通過集合基本塊間語義特征、函數間語義特征和模塊間語義特征進一步提高了漏洞搜索的效率及準確性。實驗表明,Taurus在漏洞搜索準確性上比其他相關工作高,且在不同平臺上都略有提高,適用于現實生活中的跨平臺二進制漏洞搜索。
猜你喜歡
艦船科學技術(2022年15期)2022-09-14 09:21:50
開放教育研究(2020年2期)2020-03-31 01:54:14
電子制作(2019年15期)2019-08-27 01:12:00
電子制作(2018年19期)2018-11-14 02:37:08
自動化學報(2017年11期)2017-04-04 02:52:58
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
當代修辭學(2011年6期)2011-01-29 02:49:50
外語學刊(2011年1期)2011-01-22 03:38:33
