YOLOv3-tiny的硬件加速設計及FPGA實現*
2021-12-23 06:40:56陳浩敏姚森敬辛文成王龍海
計算機工程與科學 2021年12期
陳浩敏,姚森敬,席 禹,張 凡,辛文成,王龍海,任 超
(1.南方電網數字電網研究院有限公司,廣東 廣州 510623;2.天津大學電氣自動化與信息工程學院,天津 300072)
1 引言
隨著人工智能浪潮的不斷迭起,各種網絡模型層出不窮,在圖像分類領域有:AlexNet(Alex Network)[1]、VGGNet(Visual Geometry Group Network)[2]、GoogLeNet(Google LeNet)[3]和ResNet(Residual neural Network)[4]等,在目標檢測領域有:RCNN(Regions with CNN features)[5]、Fast RCNN(Fast Regions with CNN features)[6]、SSD(Single Shot multibox Detector)[7]和YOLO(You Only Look Once)[8]等。表1列舉了幾種典型的圖像分類網絡模型,從表1中可以看出,網絡模型的精度越來越高,但隨之而來的是網絡的結構越來越復雜,網絡的規模越來越大,因此網絡模型的訓練及前向推理過程也變得十分緩慢。表1中,GMACs表示每秒10億(=109)次的定點乘累加運算。

Table 1 Typical image classification network models表1 典型圖像分類網絡模型
網絡的性能越強其所需要的計算力也就越高,為了加速網絡的運算通常使用專用的硬件,如現場可編程門陣列FPGA(Field Programmable Gate Array)。FPGA是一種半定制、可重構的專用集成電路,具有功耗低、靈活性好、性能強的特點。Cloutier等人[9]使用FPGA進行手寫字母識別的相關加速工作,受制于當時芯片的制造工藝沒能取得較好的結果。Zhang等人[10]使用HLS(High Level Synthesis)的設計方法,提出了基于Roofline的模型分析方法,在XILINX Virtex7 FPGA上實現了AlexNet網絡的卷積層設計,消耗了較多硬件資源。Ghaffari等人[11]提出一種通用卷積神經網絡加速框架,使用LeNet5對設計架構進行測試,未能取得較高的計算力。Lu等人[12]使用快速 Winograd 算法進行卷積運算的加速,提出了一個能夠在FPGA上運行Winograd快速運算的算法架構,設計較為復雜。Li等人[13]提出一種基于FPGA的端到端卷積神經網絡加速器設計方法,以此提高加速器的吞吐率,然而靈活性較差。Venieris等人[14]提出一種基于FPGA的動態可重構卷積神經網絡加速框架,采用脈動陣列的方式設計硬件加速單元,動態可重構的設計需要在使用時對FPGA反復燒寫,模型部署較為復雜。FPGA進行硬件加速依然存在較多的挑戰,硬件加速的性能與FPGA的片上資源有直接關系,如何使用有限的硬件資源設計出高效的硬件加速架構是十分重要的研究問題。YOLOv3-tiny[15]具有優秀的目標檢測能力,但模型所需的計算力依然較大,難以實現面向嵌入式領域的應用。
本文設計一種YOLOv3-tiny的硬件加速方法,并在FPGA平臺上進行實現。從定點化、并行化和流水化3個角度對模型進行硬件加速設計,使用XILINX Vivado開發套件,在XILINX XC7Z020CLG400-1平臺上對上述研究內容進行設計驗證,分別設計了卷積、池化、上采樣和YOLO Detection硬件加速IP,在Vivado IDE上完成了基于Zynq7020的片上系統SOC(System On Chip)搭建,分別從計算速度、資源利用率和功耗效率等方面對設計進行了綜合性能分析。
2 基本理論
2.1 YOLOv3-tiny網絡結構
YOLOv3-tiny是YOLOv3網絡的精簡版,其與YOLOv3模型性能的對比如表2所示。表2中FLOPS(FLoating-point Operations Per Second)表示每秒浮點運算次數,Bn表示Billion。在未對網絡進行剪枝、壓縮等操作之前,YOLOv3-tiny所需的計算量和權重大小遠小于YOLOv3的,但模型識別精度低于YOLOv3的。主要是因為其主干網絡較淺,為了提升速度犧牲了一部分精度。

Table 2 Performance comparison between YOLOv3-tiny and YOLOv3 models表2 YOLOv3-tiny與YOLOv3網絡模型性能對比

Figure 1 YOLOv3-tiny network structure diagram圖1 YOLOv3-tiny網絡結構圖
YOLOv3-tiny的主干網絡由卷積層、BN層[16]和池化層等構成,預測分支網絡由卷積層、上采樣層和張量拼接層等組成,網絡結構如圖1所示。模型特征圖輸入尺寸為416×416×3,輸出13×13×255,26×26×255 2個尺度的預測結果,主干網絡由7層卷積層構成,卷積核尺寸均為3×3,步長均為1,每個卷積層之后緊跟著一個步長為2的最大池化層,池化單元尺寸為2×2,主干網絡是典型的直筒型卷積神經網絡結構,且卷積與池化計算統一,便于進行硬件加速實現。
多尺度的預測是YOLOv3網絡的一大特點,提高了網絡模型的泛化能力和檢測精度。不同尺度的網格單元相結合能夠增強網絡對目標的預測能力。對于YOLOv3-tiny網絡來說,需要設計的硬件加速單元有:卷積計算單元、池化計算單元、上采樣計算單元和YOLO Detection計算單元。需要強調的是,YOLO Detection為網絡輸出的最后一層,作用是輸出邊框預測及類別判斷信息,其輸出結果除tw、th(tw表示網絡預測邊框的寬,th表示網絡預測邊框的高)以外均需使用Sigmoid函數進行處理。
2.2 定點化原理
定點化的計算能夠顯著提高計算效率,一個定點數由符號位、整數位和小數位組成,其總位寬為W,整數部分位寬為I,量化因子為W-I-1,本文使用S_float(32)、int(W)、I_float(32)分別表示原始浮點型數據、定點量化后的數據和定點數反量化的數據,三者之間的關系可用式(1)表示:
int(W)=S_float(32)*2W-I-1
I_float(32)=int(W)/2W-I-1
(1)
當總位寬與整數部分位寬固定時,即可使用式(1)進行數據的量化與反量化,將W-I-1稱為量化因子,不同的量化因子具有不同的精度,量化因子越大相應的數據精度就越高。為了衡量定點化后數據損失的精度,通常將定點化之后的樣本數據進行反量化,并與原始樣本數據進行對比,總體的量化精度損失[17]可使用式(2)進行描述:
(2)
其中,N表示待量化的數據總個數。
定點化過程中數據整數部分位寬和量化因子的選擇十分重要,前者決定了定點數所能表示的數據范圍,后者決定了定點數據的精度。
2.3 并行化原理
文獻[18]對卷積神經網絡中的并行性做了詳細介紹,本文在此基礎上對并行性進行簡單分析。卷積運算是網絡計算中的主要計算單元,因此對并行性的分析主要針對卷積計算單元。
(1)卷積核間并行性:卷積核間并行是指每個卷積計算的卷積核是相互獨立的,所有的卷積核共享輸入特征圖。因此,卷積核間的計算不存在相互依賴的關系,可以同時進行。
(2)特征圖間并行性:特征圖間的并行性是指對于輸入特征圖來說,每一組卷積核都有與之對應的特征圖。當進行卷積計算時,每個卷積核與對應的輸入特征圖進行乘加計算。實際計算時可將每個特征圖與對應卷積核進行并行計算,然后將計算得到的結果相加即可。
(3)特征圖內并行性:一個特征圖共享一個卷積核,因此可以將特征圖上的卷積滑窗同時進行運算,在一個特征圖上的不同位置使用共享的卷積核進行并行運算,可減少循環的次數。
(4)卷積核內并行性:以3×3的卷積核為例,整個計算過程需要進行9次乘法與8次加法運算,如果使用串行計算共需要循環9次;如果將卷積核與特征圖滑窗展開為向量,可同時進行9次乘法運算,然后再進行1次加法運算即可完成整個計算。
2.4 流水化原理
流水化的設計思想被廣泛應用于硬件設計中。本文以3級流水線對流水化的設計思想進行簡單分析,從圖2可以看出,對于3個任務,串行設計需要耗時9個時鐘周期,并行設計需要耗時3個時鐘周期,流水化設計需要耗時5個時鐘周期。
橫向比較可知:并行化的計算速度最快,但并行化的過程需要將硬件資源加倍,圖2中所需的硬件資源為串行的3倍,流水化的設計無需將所有的硬件資源都加倍,但依然需要消耗額外的存儲單元和寄存器等。

Figure 2 Serial,parallel and pipeline structure 圖2 串行、并行和流水化結構
縱向比較可知:串行設計1次僅能計算1個子任務,并行化與流水化1次能夠計算3個子任務,區別在于并行化是對彼此獨立的任務1次執行多個相同的子任務,流水化是對彼此獨立的任務1次執行多個不同的子任務。
因此,并行化主要面向沒有數據依賴關系的任務間,流水化主要面向有相對數據依賴的任務內,流水與并行的同時應用能夠大幅提高任務的運行效率。本文將網絡模型的流水化抽象為2個層級,宏觀上的流水化可在網絡的各層級之間進行設計,微觀上的流水化可在具體的層內展開設計。
3 硬件加速設計
3.1 定點化設計
(1)數據范圍。
數據進行定點化之前需對數據范圍進行統計,以此確定定點數的位數,本文對YOLOv3-tiny定點化前后的各層權重和偏置數據分布進行統計,并對定點化前后的數據精度損失進行對比。YOLOv3-tiny共有13層卷積層,定點化前各層權重和偏置的總體分布如圖3和圖4所示,從圖中可知,各層權重與偏置數據主要集中分布在0附近。本文分別使用8位,16位以及32位定點數進行定點化設計,從精度損失和計算資源消耗2個方面對設計進行評估。

Figure 3 Overall distribution of weights圖3 權重總體分布圖

Figure 4 Overall distribution of bias圖4 偏置總體分布圖
為了衡量定點化后的數據精度損失,本文使用式(1)對定點化后的數據進行反量化,然后使用式(2)統計其精度損失,不同定點數定點化后各層的數據精度損失如表3所示。從表3可知,采用8位定點數(FP8)進行定點化數據精度損失較大,16位定點數(FP16)數據精度損失較小,32位定點數(FP32)幾乎可達無損量化。因此,從數據精度角度來說,使用16位定點數能夠滿足設計要求。雖然采用8~16位的定點數也有可能滿足權重精度的要求,但考慮到定點化的統一性以及定點數對中間層數據范圍的覆蓋能力,更少位數的定點數可能導致數據精度的下降。

Table 3 Weights and biases accuracy loss of each layer表3 各層權重和偏置定點化精度損失
通常網絡模型中原始的數據類型為float,其占用4個字節的內存空間,32位定點數所需的內存空間同樣為4個字節,因此不能節省存儲空間,16位定點數所需的內存空間為2個字節,能夠節省50%的存儲空間,而8位定點數則能節省75%的存儲空間。結合表3與圖5可知,采用16位定點數進行定點化設計能夠在數據的精度損失和資源消耗間取得平衡,因此本文使用16位定點數作為加速器整體的定點位數。
本文使用一個3×3的卷積運算對不同定點數的資源消耗進行仿真測試,結果如圖5所示。從圖5中可知,定點位數越高其所需的硬件資源也越多。

Figure 5 Resource consumption diagram圖5 資源消耗圖
(2)數據溢出處理。
對于YOLOv3-tiny網絡來說,數據溢出主要出現在卷積的計算過程以及計算結果的輸出中,各層的權重、偏置、輸入數據只參與計算過程,無需進行數據的更新(此處指本層輸入數據)。因此,權重、偏置、輸入數據的溢出處理直接使用舍去高位保留低位的方法。而卷積計算過程中的數據累加,則使用更大范圍的定點數據類型暫存計算結果,設計中本文使用32位定點數。對于卷積計算的最終輸出結果,本文使用16位定點數進行表示,當發生數據溢出時,直接使用定點數據的最大值代替該值,避免造成更大的精度損失。對于池化層、上采樣層和YOLO Detection層,其計算過程不存在數據累加、乘積等造成數據溢出的問題,因此直接使用16位定點數,當發生數據溢出時,直接使用定點數據的最大值代替該值。
3.2 計算單元并行化設計
(1)卷積計算單元。
卷積計算單元的結構如圖6所示。卷積計算單元的數據輸入共有2種AXI4-Stream數據流:一種用于權重和特征圖數據的傳輸,記為INA Stream;一種用于偏置和中間計算結果的傳輸,記為INB Stream。
①INA Stream。

Figure 6 Structure of convolution calculation unit圖6 卷積計算單元結構
輸入與輸出通道的循環分塊因子分別記為q和p,通過改變q和p的大小即可實現對并行度的控制。對于權重數據,本文僅將本次計算所需的權重傳輸至片上BRAM,因此片上BRAM的大小為:p×q×k×k,其中k為卷積核尺寸。對于特征圖的輸入,本文設計q個3行的緩存結構,記為“Line Buffer”,通過移動與插入即可實現輸入數據的緩存。對于卷積計算的滑窗,本文設計3×3的窗口,記為“Window”,將“Line Buffer”內的數據不斷移動到“Window”內即可實現卷積滑窗計算的功能。對于卷積計算的特征圖輸出,本文使用可編程邏輯PL(Programmable Logic)內部的AXI4-Stream協議設計FIFO結構,FIFO深度設置為2。
②INB Stream。
由于循環分塊因子的引入,本次卷積計算的結果需要和上次循環的計算結果累加,然后再作為本次計算的最終結果傳輸至片外存儲。因此,需要設計片上存儲結構,對本次循環所需要累加的數據進行存儲,緩存大小和輸出通道的循環分塊因子p相等;此外,當完成一個輸出通道的卷積計算時,需要將偏置與當前計算結果相加,然后再進行激活輸出,偏置的片上緩存大小也同輸出通道的循環分塊因子p相等。
③循環分塊因子。
本文使用“ARRAY_PARTITION”與“PIPLINE”指令對卷積計算單元進行優化。設置不同的循環分塊因子(AXI4-Stream位寬64,一次傳輸4個通道,因此循環分塊因子為4的倍數),進而得到不同循環分塊因子下的資源消耗,結果如圖7所示。從圖7中可知,隨著循環分塊因子的增加,硬件資源的消耗幾乎也成倍增加,考慮到實驗平臺Zynq7020的資源配置,本文最終將系統的循環分塊因子設置為32,即p=q=32。

Figure 7 Resource consumption of different cyclic blocking factors圖7 不同循環分塊因子資源消耗
(2)池化計算單元。
池化計算單元的設計相較于卷積計算單元要簡單,池化層中不存在權重與偏置,也無需設計復雜的片上存儲結構與計算流程,卷積計算單元中將循環分塊因子設置為32,為了保持系統設計的一致性,本文將池化層的循環分塊因子也設置為32。池化層中的輸入與輸出通道數相等,且各通道間的池化運算不存在數據依賴,池化計算單元的設計可用圖8描述。
池化計算單元的數據輸入與輸出均為AXI4-Srteam,由于YOLOv3-tiny中的池化步長固定為2,本文設計32個2行的緩存結構,通過移動與插入即可實現輸入數據的緩存;對于池化計算的滑窗,設計2×2的窗口,將“Line Buffer”內的數據不斷移動到“Window”內即可實現池化滑窗計算的功能,每完成一次池化計算即可將計算結果輸出,無需進行片上存儲。

Figure 8 Structure of pooled computing unit圖8 池化計算單元結構
池化計算單元的優化設計與卷積層相同,本文使用“PIPLINE”對輸入通道下的循環進行優化,使用“ARRAY_PARTITION”對行緩存數組進行分割。
(3)上采樣計算單元。
YOLOv3-tiny中僅有一層上采樣層,上采樣層的輸入輸出特征圖尺寸固定,分別為13×13,26×26,因此上采樣層的設計僅針對這一組參數即可。上采樣的計算過程與下采樣剛好相反,上采樣計算單元的設計與池化層十分類似,每完成一次上采樣計算即可將計算結果輸出,無需進行片上存儲,其優化方式也與池化層相同,這里不再進行贅述。
(4)YOLO Detection計算單元。
YOLO Detection為網絡輸出的最后一層,其作用是輸出邊框預測及類別判斷信息,圖9是其輸出向量示意圖,輸出結果除tw、th以外均需使用Sigmoid函數進行處理。圖9中,tx表示網絡預測邊框的橫向相對坐標,ty表示網絡預測邊框的縱向相對坐標。YOLO Detection計算單元的數據輸入無需使用行緩存,也無需設計片上存儲結構,數據以AXI4-Stream的形式輸入,計算單元直接對輸出數據進行處理,然后將結果輸出,由于未涉及到片上存儲,因此優化設計只需使用“PIPLINE”即可。該計算單元的設計不同之處在于Sigmoid函數的定點化硬件實現以及如何對tw、th進行特殊處理。Sigmoid函數可用式(3)表示:
(3)

Figure 9 YOLO Detection output vector圖9 YOLO Detection輸出向量
本文使用HLS中的“math.h”函數庫對Sigmoid函數進行實現。從前文可知,16位定點數的整數位為7,小數位為8,符號位為1,因此對于一個16位定點數,其所能表示的數據為[-128,128),最小數據精度為2-8,以最小數據精度為間隔,16位定點數所能表示的數據共有65 535個。因此,能夠得到等數量的Sigmoid計算輸出。本文將輸出結果與標準float型數據的運算結果進行對比并繪制輸出曲線圖,從圖10可知,除點p1(-128,1)與p2(-7.625,0.5625)外,定點化后的Sigmoid輸出曲線與原始曲線基本重合,將p1、p2 2個異常點剔除后,使其與標準輸出相等,得到修復后的輸出曲線,如圖11所示。

Figure 10 Output curve before repairing abnormal points圖10 異常點修復前輸出曲線

Figure 11 Output curve after repairing abnormal points圖11 異常點修復后輸出曲線
對于YOLO Detection計算單元,不需要片上存儲單元,因此本文僅使用“PIPLINE”對其進行優化。
3.3 層間流水化設計
層間流水化與層間數據的傳遞關系密不可分,對于ARM+FPGA架構的神經網絡加速器來說,網絡各層的數據傳遞可用圖12來描述。使用FPGA構成卷積、池化等計算單元的加速器,同時常用AXI4總線進行數據傳輸。圖12的結構中只有當卷積層或池化層的計算結束后才能開始下一層的計算,計算開始之前與計算完成之后均需要使用AXI4總線進行片外存儲的數據訪存,頻繁的數據傳輸將會限制加速器的計算性能。

Figure 12 Structure of network data transmission 圖12 網絡數據傳輸結構圖
由網絡各層的計算特性分析可知,標準卷積層的計算需要遍歷所有的輸入通道數據才能得到一個完整的特征輸出,因此卷積層的計算需要等上一層的計算完成之后才能進行。池化層的計算是對各個輸入通道數據的下采樣,通道間的計算沒有數據依賴。理論上可將卷積與池化合并為一個計算單元,但此時會失去各個計算單元獨立運算的靈活性。
如圖13所示,本文提出網絡各層間的流水化設計方法,依然設計不同的加速器計算單元,但在FPGA內部使用硬件控制器將不同的加速單元連接起來,可通過控制器選擇完成計算后的數據流向,對于卷積和池化來說,當完成部分卷積計算后,可對計算完成后的數據直接進行池化運算,然后再將數據傳輸至片外存儲,以此降低數據的傳輸次數,提高加速器的整體性能。

Figure 13 Pipeline structure of each network layer 圖13 網絡各層流水化設計結構
3.4 層內流水化設計
相對于層間來說,層內的流水化設計具有更大的設計空間,本文以卷積層的流水化設計為例進行詳細的分析。流水化的設計思想是將一個大的任務分割成幾個小的子任務,每個子任務對應著1級流水,任務執行時不同任務的子任務能夠被同時執行,從宏觀上來說一個時鐘周期能夠完成一個大任務的運算。如圖14所示,本文將卷積層的計算分為5個子任務,分別為:行緩存、卷積滑窗、卷積計算、數據累加和計算輸出,因此整個流水線為5級流水設計。

Figure 14 Pipeline structure of convolutional layer 圖14 卷積層流水化設計結構
流水線的工作流程如下:首先使用行緩存對輸入數據進行讀取;然后卷積滑窗從行緩存提取需要進行卷積運算的特征數據;接著卷積計算單元將提取出的特征數據與不同卷積核進行卷積運算,再將計算結果傳輸至數據累加單元,進行不同卷積核計算結果的累加,從而得到本次計算的輸出結果;最后將輸出結果送入計算輸出單元的FIFO單元進行臨時存儲,同時將上一次計算的結果輸出至片外存儲單元。
顯然,整個流水線中卷積計算單元的計算復雜度和時間復雜度均最高,該單元需要完成大量的乘加計算,因此是限制整個流水周期的關鍵路徑。本文給出的解決方法是在卷積計算單元內引入并行設計,使用更多的硬件資源進行計算,能夠大幅降低時間復雜度,同時使用定點數據降低計算復雜度。
4 系統實驗
加速器測試平臺使用Z-turn Board開發板,Z-turn Board是深圳市米爾科技有限公司推出的一款以XILINX Zynq作為主處理器的嵌入式開發板,核心芯片為Zynq7020,這里不作具體介紹。
4.1 實驗設計
本文使用Vivado軟件對各IP進行綜合設計,生成比特流文件,然后在軟件開發包SDK(Software Development Kit)環境下進行YOLOv3-tiny網絡的復現。實驗平臺的資源配置如表4所示。表4中PS(Processing System)表示處理系統。
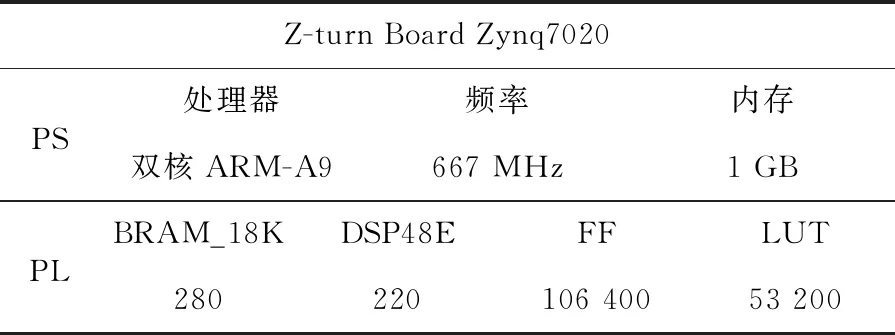
Table 4 Resource of experimental platform表4 實驗平臺資源
實驗設計分為:僅使用ARM、使用加速器但不引入層間流水化和使用加速器并引入層間流水化3部分。僅使用ARM進行實驗的設置比較簡單,不作詳細設計分析。

Figure 15 IP connection of accelerator without interlayer pipeline system 圖15 加速器無層間流水系統IP連接
使用加速器不引入層間流水的實驗設計中,系統各IP連接方式如圖15所示,AXI4 Stream數據流通過AXI Switch0選擇進入相應的計算單元內,待計算結束后再通過AXI Switch1將計算結果輸出,各IP并行排列,每進行1次加速計算僅能使用其中1個加速器,待該計算完成后再開始新的一輪加速運算。
使用加速器引入層間流水的實驗設計中,系統各IP連接方式如圖16所示,AXI4 Stream數據流通過AXI Switch0選擇進入卷積計算單元內,并通過AXI Switch1將卷積計算結果輸出到池化等計算單元內,最后通過AXI Switch2將計算結果輸出。每進行1次加速計算能使用其中2個加速器,無需進行數據的二次傳輸。

Figure 16 IP connection of the accelerator with interlayer pipeline system圖16 加速器有層間流水系統IP連接
4.2 實驗結果
實驗中FPGA端的時鐘頻率為100 MHz,ARM端的時鐘頻率為667 MHz,使用系統計時器記錄模型前向推理的時間段,用以評估計算延時。其中,不使用加速器的模型推理是基于Darknet框架在ARM-A9上進行實現的。使用加速器的2種模型,本文在SDK中分別設計了各自的代碼框架。從YOLO官方網站可以知道,YOLOv3-tiny所需的GOPS(Giga Operations Per Second)為5.56,本文將從資源消耗、計算延時、功耗和GOPS 4個角度對實驗結果進行分析。
對于GOPS,需要做相應的轉換,轉換公式如式(4)所示:
(4)
其中,Ts為前向推理時間。
相關實驗結果如表5所示,從表5中可知:對于資源消耗,引入層間流水前后并未造成較大幅度的資源消耗,兩者基本一致;對于計算延時,使用加速器能夠大幅提升網絡的推理速度,且引入層間流水的加速器設計的推理速度最快,是僅使用PS端進行模型推理的290.56倍,相較于未進行流水化設計的方法,層間流水能夠減少48 ms的推理時間。對于片上功率,相較于未加速的設計,使用加速器后的功率增加約1 W,且采用層間流水加速的設計其功耗相對更低,因此層間流水的設計在一定程度上既降低了功耗也提高了加速器的推理速度。對于GOPS,引入層間流水的加速器設計具有最大的GOPS,且能量效率最高。
總的來說,在Z-turn Board平臺上系統總體GOPS可達10.692,雖然并未達到實時推理的加速性能,但實現了高達290.56倍加速性能,對工程化實現具有一定的參考價值。此外,實驗所用平臺的硬件資源較為緊張,若在硬件資源更為豐富的平臺上進行設計,增加網絡的輸入輸出并行度,并提高PL端的時鐘頻率,相信能夠獲得更高的加速性能。

Table 5 Experimental results表5 實驗結果
下面對系統設計的綜合性能進行評估,將本文與前人的相關工作進行綜合對比分析。為了能夠全面地對系統設計性能進行說明,分別選取了采用不同設計思路的卷積神經網絡加速器設計方法的相關文獻,并從多個角度對性能指標進行對比,相關結果如表6所示。
文獻[10]給出了一種專用的卷積神經網絡加速器,針對AlexNet網絡的前5層卷積層進行加速,并對每一層使用設計空間搜索的方法得到每層的最優設計參數。與本文的工作相比,文獻[10]的加速器雖然取得了更高的GOPS,但使用了更多的計算資源,且從能量效率與GOPS/DSP來看,本文的設計要優于文獻[10]的。與本文的設計目標相同,文獻[11]設計了一種通用的卷積神經網絡加速器,并使用LeNet5對加速器的設計進行測試,在與本文相同的實驗平臺上僅獲得了1.62 GOPS的計算力,得益于更低的計算數據位,其單位BRAM的利用率要高于本文的。文獻[19]采用混合設計的思路,對YOLOv1-tiny的第1層卷積與最后1層卷積設計專用的計算單元,其他中間層采用通用計算單元,在與本文相同的實驗平臺上,雖然PL端時鐘頻率高于本文的,但加速器的整體性略低于本文的。針對YOLOv2-tiny,文獻[20]設計了一種專用的硬件加速系統,并采用低位數據對網絡進行量化與再訓練,其在與文獻[10]相同的平臺下取得了高達464.67 GOPS的計算性能,各方面設計性能均要優于本文的設計,但其可拓展性能較差且需要對網絡進行二次訓練,時間成本更高。

Table 6 Comprehensive comparison of system design performance表6 系統設計性能綜合對比
5 結束語
本文對YOLOv3-tiny網絡進行硬件加速設計,從定點化、并行化和流水化的角度分別完成了卷積、池化、上采樣和YOLO Detection硬件加速IP的設計。并在Z-turn Board平臺上對加速器的整體性能進行了測試,從資源消耗、計算延時、功耗和GOPS等方面對設計進行了綜合性能分析。最終,本文方法獲得了10.69 GOPS的有效算力,實現了1.89 fps的YOLOv3-tiny前向推理速度,系統功耗僅為2.533 W。此外,層間流水的設計方法,在未引入額外硬件資源的情況下減少了48 ms的推理時間。
猜你喜歡
云南畫報(2021年8期)2021-12-02 02:46:08
文苑(2020年10期)2020-11-07 03:15:26
現代裝飾(2020年7期)2020-07-27 01:27:42
流行色(2020年1期)2020-04-28 11:16:38
藝術啟蒙(2018年7期)2018-08-23 09:14:18
天津詩人(2017年2期)2017-11-29 01:24:12
海峽姐妹(2017年7期)2017-07-31 19:08:17
Coco薇(2017年5期)2017-06-05 08:53:16
視野(2015年6期)2015-10-13 00:43:11
海峽姐妹(2014年5期)2014-02-27 15:09:38
