多維關聯規則在圖書館借閱數據中應用分析
2021-12-19 18:56:16李華群
電腦知識與技術 2021年32期




摘要:該文旨在分析出不同屬性的讀者與借閱的圖書類別之間多維關聯規則,將讀者所在學院和年級屬性進行細分,與借閱圖書類別三級類目屬性生成多維屬性事務表,利用維間編碼自連接的方式將多維屬性整合成單維屬性的模式,對不同學院不同年級2020年下半年借閱數據進行多維維間和混合維關聯規則分析,根據讀者細分程度,得出不同讀者的個性化需求特征,為圖書館優質的服務提供有力的理論依據。
關鍵詞:多維關聯規則;圖書館;數據挖掘;關聯規則;借閱數據
中圖分類號:TP311 ? ? ? ?文獻標識碼:A
文章編號:1009-3044(2021)32-0018-04
圖書館隨著智能現代化技術發展,服務器里存儲了大量的讀者借閱行為歷史數據,這些寶貴的數據不應僅備份起來保持“有”,還應該“活用”起來,使這些數據能夠“說話”。發揮他最大的作用。數據挖掘技術是可以讓數據活用起來的技術,是可以從大量的、不完全的、有噪聲的、模糊的數據中提取隱含在其中的人們事先不知道的、但又是潛在有用的信息和知識。數據挖掘技術常用的有關聯規則、貝葉斯分類算法、決策樹算法、神經網絡算法、支持向量機、聚類分析、模糊集方法等。其中關聯規則技術常被用于圖書館借閱數據挖掘中,尋找出其中的借閱規律,為圖書館資源建設和提供個性化服務提供理論依據[1]。
但目前的研究大多僅在圖書類別之間尋找讀者借閱書籍的關聯規則。侯賀[2]將關聯規則應用到圖書館流通數據挖掘中,是通過館藏量依照中圖法分類分成T類和其他類進行圖書類別間的關聯分析;聶飛霞[3]是運用Apriori算法在圖書館典藏規劃中的應用,通過建模運算得出圖書各類別之間的關聯規則;陳淑英[4]也將關聯規則應用到高校圖書館圖書推薦服務中,通過一次抽取不同專業不同年級的記錄進行多維屬性的關聯規則分析,但僅研究的是讀者屬性與書籍類別之間維間關聯規則,如關聯規則{法學類專業,大一}==> H31,表示該讀者是法學類專業一年級的學生,同時借閱了圖書H31,是維間關聯規則,缺少混合維規則的挖掘。王蕾[5]的借閱行為大數據應用于高校圖書館服務創新的路徑分析文中使用weka將年級、專業和圖書分類三個字段進行關聯分析,分析出的也是維間規則。本文將讀者的屬性所在學院、年級信息和圖書類別三級目錄屬性多維屬性通過編碼自連接的方式整合成單維屬性,運用weka3.8.0數據挖掘工具Apriori算法不僅挖掘出維間規則,同時挖掘出混合維關聯規則,分析出更多潛在的信息,為圖書館更好地發展提供豐富的理論依據。
1關聯規則
1.1 關聯規則基本概念
關聯規則就是發現描述數據庫中數據項之間潛在的關聯,找出大量數據之間未知的、有用的依賴關系。一個關聯規則是[X?Y]的形式,即[A1?A2?…?Am?B1?B2?…?Bn]規則樣式,其中[Ai和Bj均為屬性值],[X?Y]表明滿足X中條件的數據庫元組多半也滿足Y中的條件,X為規則的前項,Y稱為結果的后項。
定義1:數據項和事務
設[I=i1,i2,...,im]是m個不同項目的一個集合,每個[ikk=1,2,...,m]稱為數據項(Item),數據項的集合I稱為數據項集。
事務T(Transaction)是數據項集I上的一個子集,即[T?I]。每個事務均有一個唯一的標識符TID與之相聯,不同事務的全體構成了全體事務集D(即事務數據庫)[6]。
定義2:支持度和置信度
關聯規則的支持度就是事務集中同時包含X和Y出現的概率,即:
[SupportX?Y=P(X?Y)]
關聯規則的置信度就是在數據集X出現的前提下Y出現的概率,即:
[ConfidenceX?Y=P(Y|X)]
定義3:提升度
由于支持度和置信度不足以過濾掉一些無用的關聯規則,再引入提升度作為度量參數,提升度是含有X的條件下同時含有Y的概率與Y總體發生的概率之比,即:
[LiftX?Y=PY|X/P(Y)]
用來描述X對Y的影響力大小,若值小于1,意味著一個出現可能導致另一個不出現,只有值大于1時的關聯規則才有意義[7]。
1.2多維關聯規則
關聯規則依照數據的維數可分為單維關聯規則和多維關聯規則。如規則[BookTP3?BookH2],其中TP3和H2是讀者借閱書籍的分類號,是屬于同一個屬性范圍,只有一個謂詞,這是單維關聯規則。涉及兩個屬性或兩個以上謂詞的關聯規則就是多維關聯規則。比如[Dept(X,計算機專業)?Grade(X,"2")]
[?Book(X,"TP312")],這里就有三個謂詞(Dept、Grade和Book)。規則中的謂詞只出現一次稱為無重復謂詞,這樣的關聯規則稱為維間關聯規則(不允許維重復出現),另外一種允許維在規則的左右同時出現的,稱為混合維關聯規則,比如[Dept(X,計算機專業")?Book(X,"TP311")?Book(X,"I247")],規則前后項都出現了Book謂詞[8]。
2多維關聯規則在圖書館中數據挖掘
2.1數據采集
考慮2020年疫情原因,上半年沒有可用的借閱數據,僅拉取2020年下半年的借閱流通數據作為數據源。因本次數據挖掘需要考慮讀者所在學院和年級,還選取了讀者庫和館藏清單用來提取讀者對應的學院和年級屬性、所借閱書籍分類號。在智慧借閱系統里選擇2020年9月份~2021年1月份的2017級~2020級大學四個年級4685名本科生36485筆借閱數據和對應的讀者庫和2000年以來的館藏清單數據。
2.2 數據的預處理
數據預處理是在分析之前對原始數據進行必要的清理、集成、轉換、歸約等一系列處理工作,本文重點在于對多維數據的處理,將多維數據形式通過編碼自連接的方式轉換為單維數據形式。
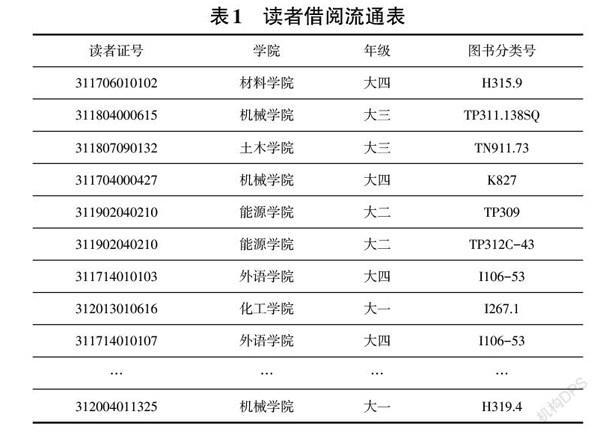
先對借閱流通數據做簡單清洗,刪除空白項、缺失項、無效項等數據行,再刪除其他無用的屬性列,包括圖書財產號列、借書還書時間列、操作人員列。通過讀者庫和館藏清單,將讀者的學院、年級和圖書分類號信息對應到讀者ID上,經處理得到3660名本科生23326筆有效的借閱數據。構成一個新的讀者借閱流通表,如表1所示。
因直接對圖書分類號進行關聯分析,得到的數據是稀疏的,分析不出實際意義,需要對圖書分類號依照中圖法進行三級分類數據合并,對學院和年級進行簡化編碼,學院名稱統一簡化為首字母縮寫,年級統一用1、2、3、4來表示,如機械學院大四學生簡化為jx4。再通過屬性間邏輯與自連接的方式將讀者屬性與所借閱圖書分類號進行融合,將多維屬性轉換為單維屬性的形式,最終處理如表2所示。
根據Weka可以識別的數據形式,將此表建立事務數據庫,每個讀者借閱數據為一個事務項目,把每個讀者-圖書值列為一個數據項屬性,并保存為.csv格式。
2.3模型建立與分析
2.3.1模型建立
依照中圖法的22大類,將借閱圖書分類號的第一級大類分解出來,進行統計分析,借閱范圍大致分布如圖1。
從圖1可知,文學I類借閱量占整體的46%,借閱量比較大,將所借圖書類別一起進行關聯分析,其結果會出現關聯關系集中在文學類書籍上,不能深入挖掘出其他類別書籍關聯結果,為此我們把讀者借閱的模式分為2種類型:一種是借閱了I文學類書籍的讀者;另一種是借閱了非文學類書籍的讀者。
2.3.2 文學類讀者與圖書類別間關聯分析
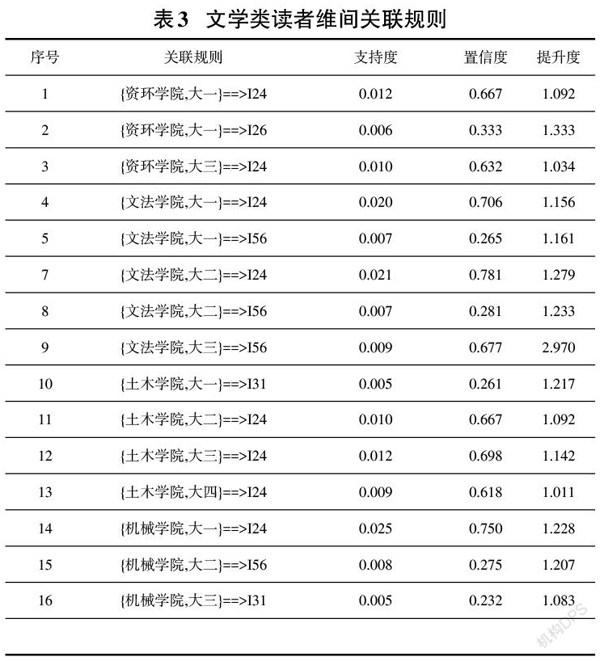
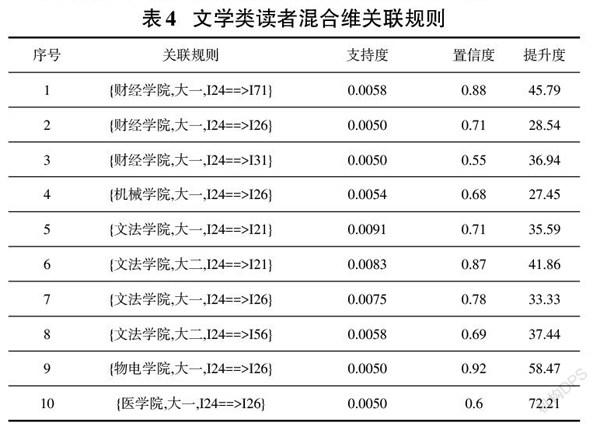
應用Weka3.8.0數據挖掘工具[9],使用preprocess模塊打開需要分析的csv文件,選擇Associate關聯規則模塊,運用Apriori算法對參數進行設置,經多次試驗選用lowerBoundMinSupport為0.5%,MetricType為Confidence,MinMetric為0.1,運行結果如表3和表4。
從表3關聯結果可以看出:
(1)文學類書籍屬于通識類書籍,大一、大二年級學生主要課程以基礎課為主,極少涉及到專業類課程,他們大多借閱書籍以文學類為主,各學院大一、大二年級的讀者有2%以上都借閱了文學類書籍,而大三、大四年級的讀者相對較少,不到1%,說明隨著專業課的開展和學習,讀者的偏好有所轉移,涉獵了更廣泛類別的書籍。
(2)其中文學類書籍最受歡迎的是I24中國文學小說和I56外國文學小說,70%以上讀者借閱了I24類書籍,25%以上讀者借閱了I56類書籍,而且各學院各年級都有借閱比例,尤其借閱比例高的是文法學院和機械學院讀者,且I56外國文學類書籍集中借閱在文法學院各年級。
(3)這些規則提升度都大于1,說明規則前項和后項是正相關關系,前項的出現都會有后項同時出現,如{文法學院,大三}==>I56,提升度是2.97,意味著文法學院大一年級的讀者借閱I56類書籍是所有讀者隨機借閱I56類書籍的2.97倍。
從表4混合維關聯規則可知:
(1)財經學院、機械學院、文法學院、物電學院大一新生借閱了I24中國小說類書籍的讀者有60%以上都同時借閱了I26中國散文集書籍,文法學院和財經學院文科類學院學生涉及的類別相對較多些,財經學院大一新生有88%讀者還同時借閱了I71外國文學類書籍,文法學院大一、大二學生有71%都借閱了I21中國作品集。
(2)這些規則提升度都在27.45以上,表明前項后項關聯性很強,如規則1,讀者是財經學院大一新生借閱了I24類書籍,同時也借閱了I71類書籍的概率是讀者隨機借閱I71類書籍的45.79倍。
2.3.3 非文學類讀者與圖書類別間關聯分析
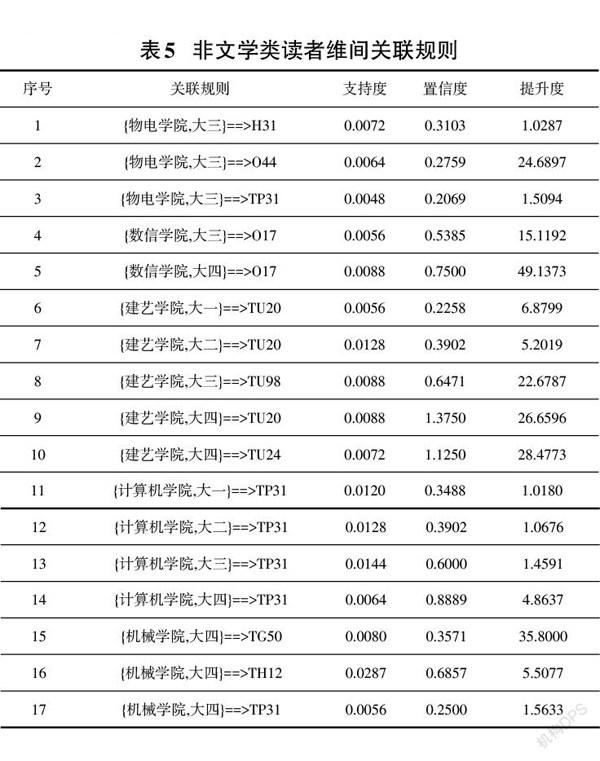
運用Weka3.8.0挖掘工具,選擇非文學類讀者借閱數據表進行分析,使用associate關聯規則模塊,對Apriori算法的參數進行設置,設置參數lowerBoundMinSupport為0.5%,MetricType為Confidence,MinMetric為0.1,挖掘結果如下表5和表6。
從表5關聯規則結果可知:
(1)非文學類書籍大多是偏專業性強的書籍,大多借閱集中在大三大四年級,借閱比例較高的有物電學院大三學生借閱了H31英語類書籍,數信學院大四學生借閱了O17數學分析類書籍,建藝學院大三學生借閱了TU98區域規劃類書籍,計算機學院大三學生借閱了TP31計算機軟件類書籍,機械學院大四學生借閱了TH12機械設計類書籍,但也有建藝學院和計算機學院大一大二學生也開始閱讀TU20建筑學一般性問題類書籍和TP31計算機軟件類書籍。
(2)因專業內容范圍的不同,有的學院學生借閱書籍類別比較單一,有些則涉及類別比較多樣,如數信學院大二、大三、大四學生有30%以上都借閱了O17數學分析類書籍,計算機學院大一、大二、大三、大四學生有34%以上都借閱了TP31類書籍,而且隨著年級提高借閱比例也提高,計算機學院大四學生有88%比例都借閱了TP31類書籍。物電學院大三學生都分別有31%借閱了H31英語類書籍,27%借閱了O44電磁學類書籍,20%借閱了TP31計算機類書籍,機械學院大四學生都分別有35%借閱了TG50機床加工類書籍,68%借閱了TH12機械設計類書籍,25%借閱了TP31計算機軟件類書籍。
(3)從提升度來看,有相當一部分關聯規則的提升度很高,表明因前項出現導致后項出現概率比后項隨機出現概率高許多,前后項有很強的關聯性,比如關聯規則{數信學院,大四}==>O17的提升度為49.13,數信學院,大四的學生借閱O17類書籍是任意學生借閱O17書籍的49.13倍。
從表6生成的關聯規則可知:
(1)因專業類知識學習也是逐漸遞增的過程,從基礎類專業到某方向類專業,大多學生借閱了某類別的書籍后同時也會借閱同類別其他書籍,如機械學院大四學生借閱了TG50機床一般性問題,有60%借閱了TH12機械設計類和80%借閱了TH16機械制造工藝類書籍,計算機學院大三學生借閱了TP30計算機一般性問題,有100%借閱了TP3-0計算機理論類書籍和50%借閱了TP31計算機軟件類書籍,建藝學院大四學生借閱了TU-0建筑理論類書籍,有67%借閱了TU20建筑設計一般性問題和67%借閱了TU98區域規劃類書籍。
(2)有的學院專業知識比較集中,借閱書籍類別相對較少,如化工學院大四學生借閱了O65分析化學類書籍100%都會借閱O62有機化學類書籍,數信學院大四學生借閱了O15代數類書籍78%會借閱O17數學分析類書籍。
(3)因有的專業界限清晰,不會涉及跨專業類學科,分析出的關聯規則提升度超過100,如化工學院借閱的書籍是有關化學方面的,建藝學院借閱的書籍都是建筑設計類書籍,與其他學院專業知識基本無交叉,意味著只有化工學院的學生才會借閱O62、O65類書籍,只有建藝學院學生才會借閱TU建筑設計類書籍,這些關聯規則極強。
3 多維關聯規則在圖書館的應用分析
3.1 優化館藏資源建設
通過對2020年下半年本科四個年級的圖書借閱數據分析,可以看出大概有近一半的學生都偏愛文學類書籍,尤其是低年級的大一和大二學生,本校目前只有一個文學庫,借此圖書館擴建時機,可以考慮增加書籍館藏量并增設文學庫,來滿足讀者對文學類書籍的需求。
依照讀者借閱書籍的關聯關系,還可以適當調整館藏布局,將借閱關聯度大的書籍就近放置,方便讀者尋找和閱讀。如I24、I56中外文小說類書籍深受讀者喜愛,可以適當優化館藏布局,為讀者快速找到自己偏愛的書籍提供便利。
3.2 提供個性化服務
通過讀者大量的歷史借閱數據,不僅分析出讀者與圖書的維間關聯性,還分析出讀者不同學院不同年級借閱圖書的混合維關聯關系,細化了讀者屬性,明確了讀者需求分布特征,可以更加精準地指導圖書館進行個性化推薦服務、個性化檢索和推送服務。如讀者是大一學生,都可以給讀者推薦I24、I56文學類書籍;計算機學院的學生,可以給讀者推薦TP31計算機軟件類書籍;機械學院大四的學生,都可以推薦TH12機械設計類書籍和TP31計算機類書籍,如果讀者借閱過TG50機床類書籍,且是機械學院大四的學生,可以給讀者推薦TH12機械設計類書籍。建立圖書推薦系統,將被動服務變為主動服務,主動根據數據分析結果預測讀者可能喜愛的書籍,不僅可以縮短讀者借閱圖書的時間,還可以快速找到讀者偏愛的書籍,節約了讀者的時間,同時也提高了書籍流通率和借閱率,將圖書館的價值充分發揮出來。
3.3 學科服務
通過讀者不同學院不同年級對借閱書籍的關聯規則,可以找出不同讀者對借閱的圖書類別的分布特征,可以與所在學院和年級進行合作,開展一些文獻信息咨詢服務和文獻資源分布指南培訓等活動,并嵌入到學院、教學第一線的信息素養教育中,使讀者更深入地了解圖書館資源信息分布,使資源被充分利用起來。也從中挖掘出學科間隱藏的關聯,可以引導讀者拓寬閱讀范圍,為跨學科建設指明方向。
4 結論
本文以讀者屬性所在學院、年級、所借閱圖書來建立挖掘的體系架構,不僅細化了讀者屬性,也將圖書的類別依照中圖法劃分成三級類目,將多維屬性通過編碼自連接的方式轉換成單維屬性,運用Weka3.8.0數據挖掘工具進行多維關聯規則數據挖掘,分析出維間規則和混合維規則豐富的潛在信息,其結果不僅可以指導圖書館優化館藏資源建設,還可以為讀者提供更精準的個性化服務和學科服務。但本文僅使用了關聯規則一種數據挖掘技術,在以后的研究中應加入更多的數據挖掘技術如聚類分析、分類分析、神經網絡、隨機森林等算法,挖掘出更多潛在和可用的信息,以此來進一步指導高校圖書館發揮更大的服務職能。
參考文獻:
[1] 馮磊.大數據挖掘在高校圖書館個性化服務中應用研究[J].圖書館學刊,2019,41(1):109-112.
[2] 侯賀.基于關聯規則的圖書館流通數據挖掘——以深圳大學城圖書館為例[J].圖書館學刊,2017,39(2):107-111.
[3] 聶飛霞,陳長明.Apriori算法在圖書館典藏規劃中的應用[J].情報探索,2018(7):30-35.
[4] 陳淑英, 徐劍英.關聯規則應用下的高校圖書館圖書推薦服務[J].圖書館論壇,2018 (2):97-102.
[5] 王蕾, 高翔.借閱行為大數據應用于高校圖書館服務創新的路徑分析[J].大學圖書館情報學刊, 2020(11):107-120.
[6] 鄭繼剛. 數據挖掘及其應用研究[M].昆明:云南大學出版社,2014.
[7] 李珺, 劉鶴. 基于改進的K-means算法的關聯規則數據挖掘研究[J].小型微型計算機系統,2021(1):15-19.
[8] 溫海波.多維關聯規則在圖書館中的應用研究[D].合肥:合肥工業大學,2013: 9-11.
[9] 周捷, 章增安.基于大數據的高校圖書館個性化推薦書目生成研究[J].晉圖學刊,2017(5):29-33.
【通聯編輯:王力】
收稿日期:2021-04-10
基金項目:河南理工大學人文社科基金資助,年度項目“改進Apriori算法在圖書館信息知識發現中應用分析”(項目編號:722618/172)
作者簡介:李華群(1985—),女,河南省焦作市人,河南理工大學圖書館助理館員,碩士研究生,主要研究方向:圖書情報、數據挖掘。
猜你喜歡
大眾投資指南(2021年35期)2021-02-16 01:06:26
文苑(2019年20期)2019-11-16 08:52:12
文苑(2018年17期)2018-11-09 01:29:40
小太陽畫報(2018年1期)2018-05-14 17:19:25
電力與能源(2017年6期)2017-05-14 06:19:37
中國中醫藥信息雜志(2016年7期)2016-12-01 06:07:55
少年博覽·小學低年級(2016年10期)2016-11-24 06:48:23
信息通信技術(2015年6期)2015-12-26 01:16:46
小天使·一年級語數英綜合(2014年8期)2014-06-26 14:42:04
河南科技(2014年23期)2014-02-27 14:18:43
