機器視覺技術(shù)在圖書館書籍書號識別問題中的研究
2021-12-06 10:13:48馮麗娟鄭中旭袁玉霞
魅力中國 2021年49期
馮麗娟 鄭中旭 袁玉霞
(鄭州科技學(xué)院電子與電氣工程學(xué)院,河南 鄭州 450064)
一、引言
光學(xué)字符識別(OCR)是圖像處理和模式識別中最熱門的問題之一,它需要對圖像中的符號進行識別。這個問題已經(jīng)存在了很長時間,然而,即使是眾所周知的OCR系統(tǒng),在OCR的特殊情況下也不能很好地工作,以美國國會圖書館(LC)書號識別為例。本文的目標是定義這一特定的問題,并評估現(xiàn)有的OCR 系統(tǒng),分析哪種方法可以有效解決識別難的問題[1-3]。
已經(jīng)有人嘗試使用新技術(shù),如RFID 或條形碼[4,5]來識別書籍。然而,這將需要重新標簽每一本書,購買RFID 或條形碼閱讀器,天線和軟件許可證,這將導(dǎo)致非常高的初始和維護成本。此外,在讀取設(shè)備或系統(tǒng)出現(xiàn)故障的情況下,RFID 標簽和條形碼無法被人類或用戶讀取。因此,有低成本自動化系統(tǒng)的需求,可以檢測書籍的移動,如在[6]中提出的。在這類系統(tǒng)中,關(guān)鍵問題之一是識別每個圖書館書籍上的標簽中的書號。
OCR 已經(jīng)研究了很長一段時間并取得了顯著的成功,但在本文中,通過大量的實驗,結(jié)果表明,目前的OCR 系統(tǒng)在這個特定的情況下并沒有產(chǎn)生令人滿意的結(jié)果。因為存在下劃線的問題,導(dǎo)致了識別較差的結(jié)果,如許多圖書館標簽褪色或磨損,特別是當標簽的背景是白色的,在上面的符號非常薄。另一個面臨的問題是圖書館周圍的書架不均勻的照明,這經(jīng)常造成不均勻的亮度,在某些情況下,它不夠明亮,不足以閱讀什么是舊標簽。這些問題表明,在研究新的更有效的算法來解決這個特殊的圖書書號識別問題之前,需要更徹底地研究這個問題,更仔細地分析可用的OCR系統(tǒng)的性能。在本文中,進行了一些實驗,在不同的情況下,OCR 算法的性能將被測試和分析[7]。
二、圖書館書籍書號識別問題分析
(一)問題描述
給定圖書館書架上書籍的圖像,每本書的書面上應(yīng)該有一個圖書館標簽或貼紙,如圖1 所示,它通常在白色的背景上包含書的編號。需要一個OCR 軟件來提取給定圖像中所有圖書的每個標簽中的圖書書號或圖書ID。問題是需要清晰的識別圖像中的文本和符號。首先,它看起來很簡單,而且也有很多令人滿意的OCR 識別應(yīng)用程序。但是,正如后面的實驗結(jié)果所顯示,這仍然是一個具有挑戰(zhàn)性的問題。
(二)參數(shù)
在光學(xué)字符識別問題中,輸入圖像質(zhì)量對識別結(jié)果的成功起著很大的作用。對于這個特殊的OCR 問題,我們需要檢查各種情況和環(huán)境,在什么時候和什么地方獲得書本的圖像。換句話說,需要確定在解決給定的圖書書號問題時,哪些參數(shù)可能會影響識別成功率。
書面背景:書面的顏色在識別通常為白色背景,對圖書標簽上的文字和書號符號識別時會產(chǎn)生很大的影響。
1.標簽質(zhì)量:書號印在書面上的標簽上。標簽的背景色通常是白色,而編號(由字母和數(shù)字混合而成,中間有點)印得很薄,看起來是灰色而不是黑色。這些標簽是在書籍被添加到圖書館目錄時第一次制作的。經(jīng)過多年,許多標簽可能會磨損掉,因為它們是部分剝落,墨水褪色。不幸的是,這些標簽不會立即被新的替換,因為檢測、打印和替換標簽需要很長時間。因此,在圖書館看到的圖書標簽可能會從非常清晰的黑色墨水標簽到模糊的標簽,其中圖書編號的符號是模糊的,不再清晰。
2.相機高度(燈光):眾所周知,燈光對OCR 的性能有很大的影響。光強的差異可能很難被人的眼睛檢測到,但對于OCR 軟件來說,這可能會導(dǎo)致識別成功率的巨大差異。在圖書館里,光線的主要來源通常來自天花板。因此,相機的位置越高,圖像就越亮,越清晰,反之,相機的位置越低,圖像就越暗。獲得不同光線強度的圖像最簡單的方法是將相機從高到低放置在圖書館書架的不同書架上。可以在書架的頂層得到光線更多的圖像,或者是書架底層光線較少的圖片,如圖1 所示。

圖1 左:更多光下的頂部擱板;右:較少光下的底部擱板
由于相機位置的高度可以很容易地通過書柜的外表來量化。最低的光強度值是當相機是在水平的低端時拍的。同樣的,最高光強值也會出現(xiàn)在相機在頂部的水平上。
三、本文的識別測試系統(tǒng)
為了測試OCR 軟件的性能,可以用于圖書館書號識別問題,設(shè)計了一個測試系統(tǒng),它集成了幾種OCR 的技術(shù)。用相同的一組輸入數(shù)據(jù)運行,如圖2 所示。
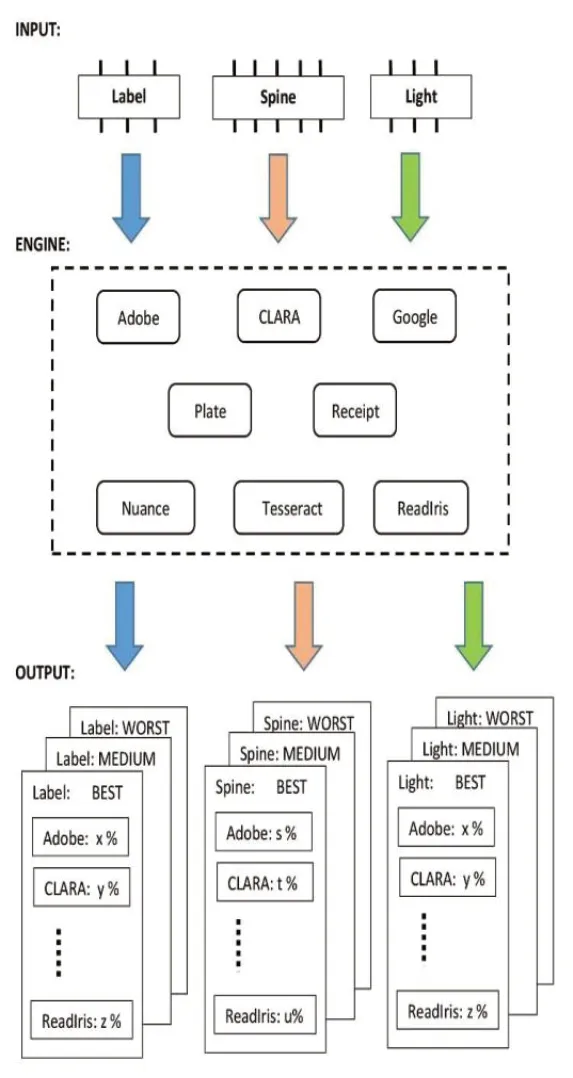
圖2 識別書號測試系統(tǒng)
在測試系統(tǒng)的引擎中包含以下內(nèi)容:Adobe Acrobat、CLARA、Google Cloud Vision、License Plate ALPR、Nuance OmniPage、Readlris、Tagun Receipt、Tesseract 等。引擎中的所有OCR 使用相同的輸入。在不同環(huán)境中,可能會遇到識別復(fù)雜圖書書號的問題。輸入數(shù)據(jù)可以分為三組:書面背景、標簽質(zhì)量、照明(或相機高度)。
用圖書館標簽處理每一幅書面的圖片,圖像的輸出是文本文件中的圖書書號列表。然后,通過比較文本文件中的結(jié)果和相應(yīng)圖片中的圖書編號,對每個OCR 系統(tǒng)的每個參數(shù)的性能進行評分。
四、實驗及結(jié)果分析
使用兩種不同分辨率的相機:(i) 1.3 萬像素的基本的網(wǎng)絡(luò)攝像頭和(ii) 12 萬像素的高端智能手機攝像頭。由于給定的問題需要解決在大型圖書館中的設(shè)備可能太昂貴,因此可能無法得到。因此,了解相機質(zhì)量對每個OCR 軟件性能的影響是很有用的。利用上述測試系統(tǒng),進行了實驗。
使用在第2 節(jié)中描述的參數(shù)范圍內(nèi)的不同輸入圖像集來測量所有OCR 系統(tǒng)的成功率。成功率由從1 到10 的分數(shù)來定義,其中10 是最好的,或者識別100%的標簽是正確的,而1 是最差的性能,即OCR 不能識別超過10%的書號。結(jié)果如表1、2、3所示。本實驗中使用的圖像均為手機相機拍攝。
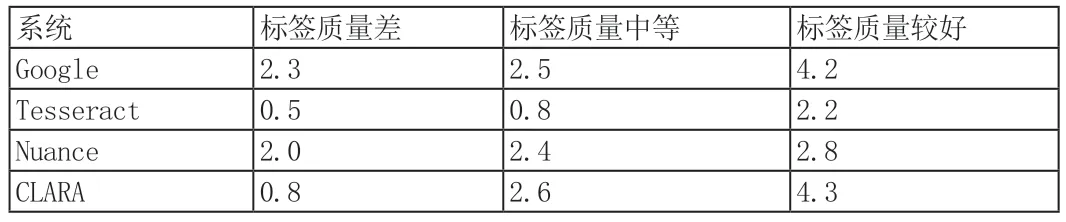
表1 標簽質(zhì)量對測試結(jié)果的影響
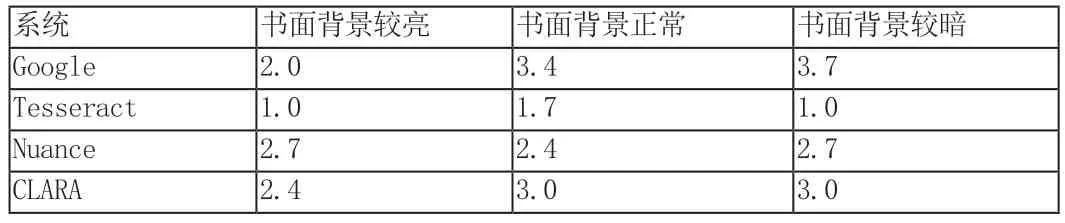
表2 書面背景對測試結(jié)果的影響

表3 相機高度對測試結(jié)果的影響
五、結(jié)論
在圖書館圖書圖像中識別圖書書號是一個非常具有挑戰(zhàn)性的OCR 問題。即使使用目前先進的OCR 系統(tǒng)和頂尖IT 公司的技術(shù),識別書面上標簽圖片上的書號成功率也只有40%或更低。考慮到一個很好的解決方案對于這個OCR 的問題會形成一個非常低成本自動化的大圖書館的書位置跟蹤系統(tǒng),無需添加任何新標簽的書或需要任何額外的人類勞動,這將對圖書館建設(shè)是非常重要的。在未來,根據(jù)機器學(xué)習(xí)機制,如神經(jīng)網(wǎng)絡(luò)和模糊邏輯可以加入到目前的解決方案中,以取得更好的結(jié)果。更多地研究其他可能影響這個特定OCR 問題結(jié)果的因素,也有助于為這個非常具有挑戰(zhàn)性的問題制定更有效的解決方案。
猜你喜歡
工業(yè)設(shè)計(2022年8期)2022-09-09 07:43:20
軍民兩用技術(shù)與產(chǎn)品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
裝備制造技術(shù)(2019年12期)2019-12-25 03:06:46
文苑(2019年20期)2019-11-16 08:52:12
中國洗滌用品工業(yè)(2019年4期)2019-05-11 09:27:34
文苑(2018年17期)2018-11-09 01:29:40
小太陽畫報(2018年1期)2018-05-14 17:19:25
家庭影院技術(shù)(2017年9期)2017-09-26 03:41:45
少年博覽·小學(xué)低年級(2016年10期)2016-11-24 06:48:23
