基于MLP 神經網絡的鋁電解槽出鋁量預測
2021-12-01 05:26:40倪小峰
智能計算機與應用 2021年8期
倪小峰,曹 斌
(1 貴州大學 大數據與信息工程學院,貴陽 550025;2 中鋁智能科技發展有限公司,杭州 310000)
0 引言
隨著現代信息化水平和大數據相關技術的發展,“數化世界,萬物互聯”已成為時代發展的必然趨勢[1]。在鋁電解工藝中,電解流程中產生的各種參數并不都是能夠實時監控的。因此,從已知的參數中發現數據之間的關聯關系及規律,進行動態分析及預測成為極其重要和亟待解決的問題。
鋁電解槽由槽體、陽極以及陰極構成。熔鹽電解槽在高溫、強腐蝕的環境中工作,在炭素體陽極發生氧化反應,陰極發生還原反應產出鋁液[2],積存于電解底部,車間操作人員定期出鋁,鑄造成鋁產品。鋁電解生產是一個多變量耦合、大延遲以及非線性工藝生產過程。維持電解過程的兩大平衡(能量和物料平衡),是保障其生產高效穩定運行的關鍵因素。然而,鋁電解的兩大平衡受多種因素、指標的共同影響,耦合關系復雜,對氧化鋁添加量和出鋁量的正確決策是維持兩大平衡,保證經濟效益最直接、有效地途徑[3-4]。本文將鋁電解工藝生產過程中所產生的各種參數進行分析,利用歷史生產數據,將特征選擇得到的強特征作為MLP 神經網絡的輸入,出鋁量作為輸出對網絡進行訓練,通過訓練、測試和驗證,最后得出一個預測模型,為一線工作人員提供槽作業的指導作用。
1 數據預處理
數據預處理是實驗的前提,包括了數據的缺失值處理、規一化處理、特征選擇等內容。對于鋁電解工業,影響其生產過程的參數眾多,而且各個槽控系統參數之間存在著極其復雜的關聯關系。如:電解槽工作電壓、氧化鋁下料量、氟化鋁下料量、電解質水平、鋁水平、分子比等多達十幾項指標,若其中任何一個發生變化,都可能導致其它參數隨之發生相應的變化。所以為了使實驗結果具有可靠性,數據特征處理至關重要,需根據步驟依次進行。
1.1 數據采集與分析
本次實驗數據來源于中鋁集團貴州某鋁廠槽控機系統監控的實時數據和人工采集的每日真實鋁電解槽生產數據。每個電解槽的相關參數包括鐵含量、硅含量、電解質水平以及鋁水平等,總計10 維2 000多條特征數據。通過所采集的數據進行觀察,分子比和氧化鋁濃度數據缺失過多,因此后續實驗和分析不考慮這兩個參數。之后,再利用XGBoost[5]機器學習算法將剩余參數進行重要性排序。
1.2 數據Z-score 標準化
實驗數據集有10 個參數,并且各個參數指標的數據量級有著非常明顯的差異。如:每天出鋁量的平均值達到了2 850 kg,而鐵含量、硅含量、噪聲和氟化鋁下料量等數據的量級則比較小。考慮到實驗數據在數量上存在著比較大的偏差,必須對實驗數據進行標準化處理。本文采用的是Z-score 標準化。
利用Python 中自帶的“.describe()”函數,可以從原始數據組中提取標準差和均值。將數據處理為符合正態分布的數據集,其平均值為0,標準差為1。這樣做有利于減小因數據差異太大而導致的結果誤差。轉化函數為:
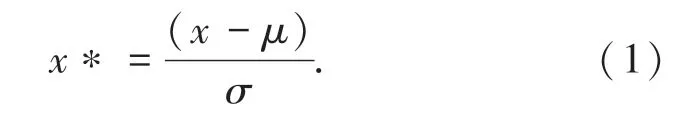
其中,μ表示各個參數的均值,σ代表相關參數標準差。
1.3 數據相關性分析
Pearson 相關系數用于衡量兩個變量之間的變化趨勢的方向及程度[6],計算表達式如下:
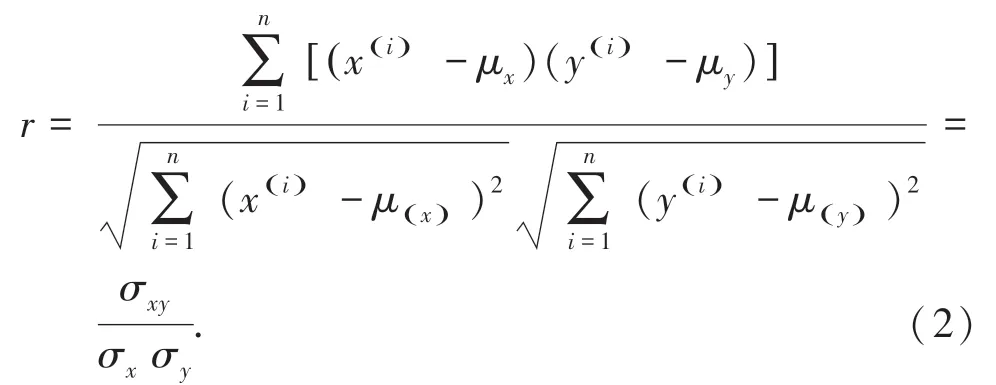
式中,μ為實驗數據集的均值;σxy為參數x與y之間的協方差;r∈[-1,1]。通過r值的大小可以判斷相關參數之間的相關性強弱。若任意兩個參數之間的相關系數大于0,說明兩個參數是正相關關系,當兩個參數的相關系數小于0 時,說明兩個參數呈負相關狀態。總的來說,r的絕對值越大,表示兩個參數之間的相關性越強。
Pearson 相關系數熱力圖如圖1 所示,Fe含量與Si含量呈正相關,鋁水平與電解質水平呈正相關,氧化鋁下料量與出鋁量呈正相關。在鋁電解過程中需要保證鋁水平和電解質水平保持在一定范圍內,才能保證電解槽處于穩定狀態,以達到最佳的電解反應,獲得最優的實際出鋁量。
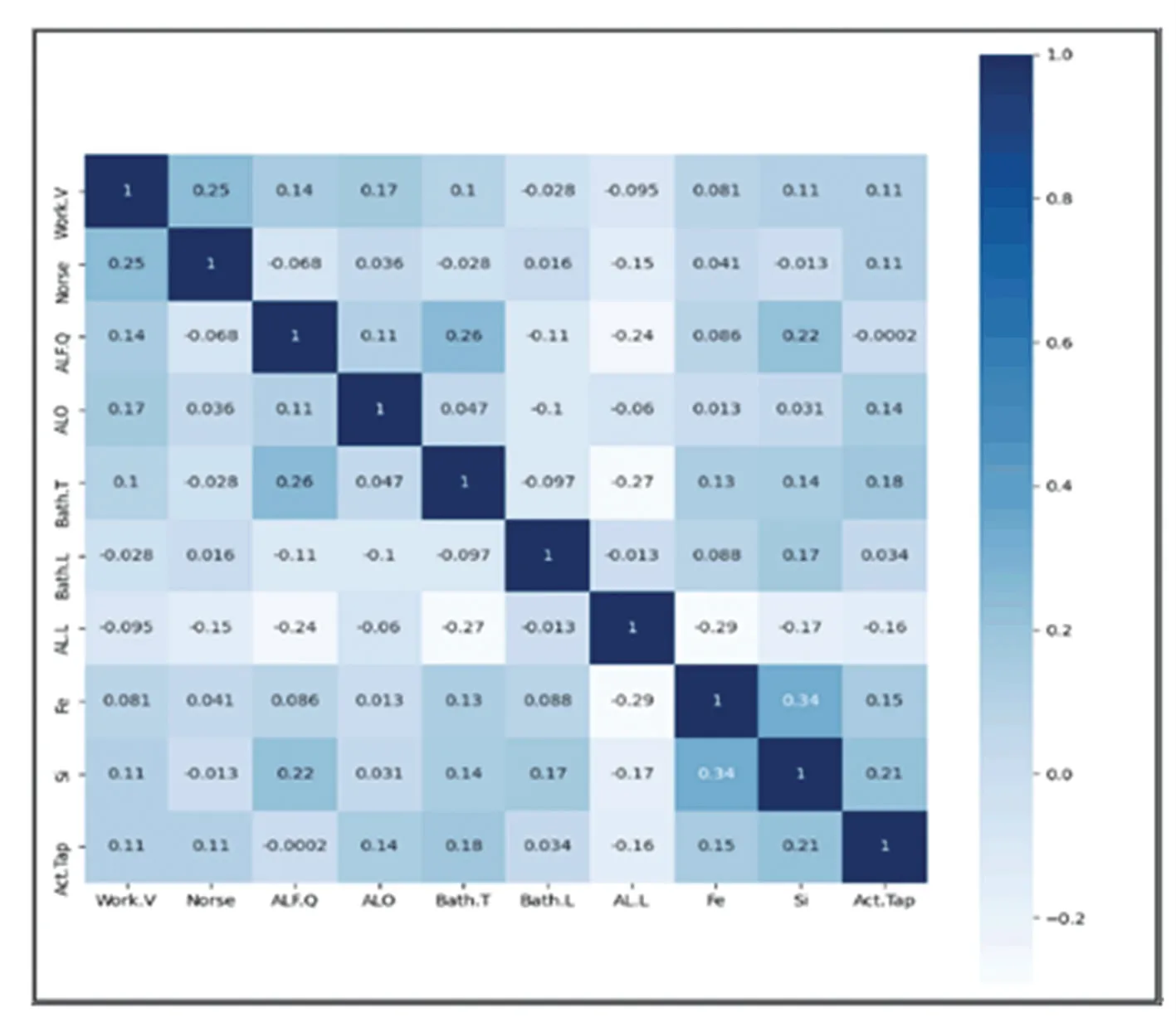
圖1 相關系數熱力圖Fig.1 Heat map of correlation coefficient
2 MLP 神經網絡
2.1 MLP 原理
MLP 神經網絡的基本運算單元是神經元[7],如圖2 所示,x1、x2、…、xn為神經元的輸入,y為神經元的輸出。顯然,不同的輸入對神經元的作用是不同的,因此用權值w1、w2、…、wn來表示影響程度的不同。神經元內部由兩部分組成;第一步是把所有的參數進行求和,第二步負責對第一步的結果求和,最后“激活”求和結果,得到最終該神經網絡的輸出結果。
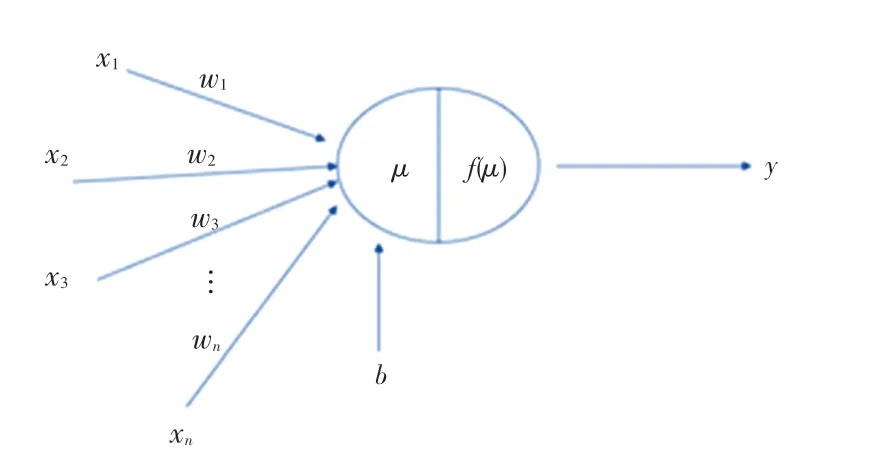
圖2 神經元模型Fig.2 Neuron model
加權求和公式如下:
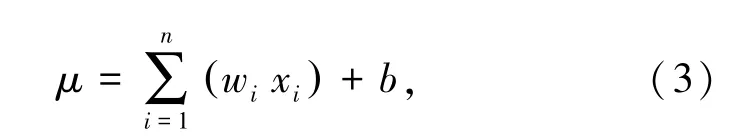
式中,b為偏移量,該偏移量也可以定義為輸入恒為1 的權值w0,即權值也包括偏移量,因此上式可以改寫為:
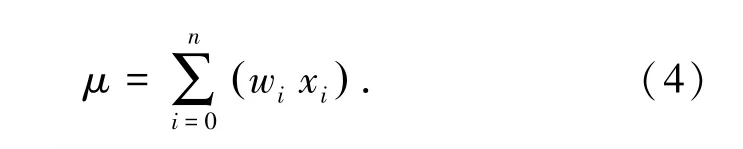
且x0≡1,激活公式為:y =f(μ),f(.)稱為激活函數。
多層感知器模型(Multi-Layer Perceptron,MLP)是人工神經網絡模型中的一種,由一個輸入層、一個或多個隱含層、一個輸出層組成,能夠描述一組輸入變量到輸出變量之間復雜的映射[8]。本文設計的模型中,影響出鋁量的參數信息通過神經網絡的輸入節點進入,輸入的數據參數信息及一系列復雜處理、加工通過輸出層和隱含層,借助權值w完成。同時對數據進行反向傳播自動更新權值和閾值,然后尋找整個過程的最優解,最終出鋁預測值量由搭建模型的輸出節點得到,實現從歷史經驗數據來預測出鋁量的模型。
2.2 輸入參數的選取
通過觀察操控系統各個相關參數的工藝曲線變化情況,輸入參數的選取必須是對出鋁量有著重要影響的。通過實地考察、查閱鋁電解的相關資料以及查看歷史生產相關參數,分析得到電解質水平是鋁電解槽的重要技術參數。電解質水平應該保持一定的高度,太高和太低都不利于電解的進行,電解質太高容易發生陰極的使用率,減低和降低電流效率,電解質太低導致電解槽發熱,穩定性差,最終會對出鋁量產生重大影響。鋁水平過高或者過低都會引起電解槽溫度不穩定,從而影響電解過程導致出鋁不能達到最優。另外,氧化鋁下料量也直接影響著氧化鋁的濃度,氧化鋁的濃度過高或過低都會導致電流工作效率不穩定;Fe含量和Si含量也會影響電流的工作效率;工作電壓波動會引起電解槽的穩定,工作電壓如果出現急速上升或者下降會導致電解槽的溫度不穩定和電解過程的不穩定,最終影響出鋁量。
綜合工藝專家經驗、數據的相關性分析結果以及電解車間里技術人員經驗分析,最后選擇電解槽噪聲(Norse)、工作電壓(Work.V)、電解質水平(Bath.L)、鋁水平(AL.L)、氧化鋁下料量(ALO)、氟化鋁下料量(ALF.Q)、電解質溫度(Bath.T)、鐵含量(Fe)和硅含量(Si)作為神經網絡的輸入參數,選擇實際出鋁量(Act.Tap)作為輸出結果。
2.3 隱含層的確定
在搭建神經網絡時最重要的一點是神經元個數和網絡參數的選擇,兩者之間有著密切的聯系。神經網絡如果能夠確保隱含層有著足夠多的神經元,所搭建的神經網絡模型就可以實現復雜度較大的映射。在實際工業生產中,隱含神經元個數一般是通過試錯法來進行調整的。MLP 網絡的搭建包括一個或多個隱含層,而神經元個數需要根據公式(5)來確定,然后不斷進行試錯調整,直到最終找到最優參數為止。

式中,b為神經元個數,a為輸入節點數。
經過反復實驗及對結果的分析,出鋁量預測模型輸入參數是通過Python 中自帶的相關分析函數“DataFrame.corr()”而得。其計算出參數之間的相關度,并且把相關度從高低排序后,選取相關度高的參數作為模型的輸入參數。最終確定神經網絡模型的輸入層為9 個輸入變量、隱含層有17 個神經元,輸出層為電解槽實際的出鋁量;激活函數為Sigmoid,表達式如下;
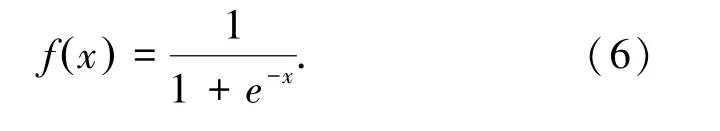
3 實驗過程與結果分析
3.1 MLP 神經網絡實驗
本次實驗在Tensorflow[9]的環境下使用Python語言編寫程序[9],并在CPU2.50 GHz、內存4 Gb、Windows10 操作系統的計算機上進行電解槽出鋁量預測實驗。該實驗采用貴州某鋁廠350KA 系列電解槽的歷史數據,表1 中展示了部分數據集;工作電壓(Work.V)、噪聲(Norse)、氟化鋁下料量(ALF.Q)、氧化鋁下料量(ALO)、電解質溫度(Bath.T)、電解質水平(Bath.L)、鋁水平(AL.L)、鐵含量(Fe)和硅含量(Si)作為神經網絡的輸入參數,實際出鋁量(Act.Tap)為預測結果。MLP 神經網絡的實驗步驟如下:
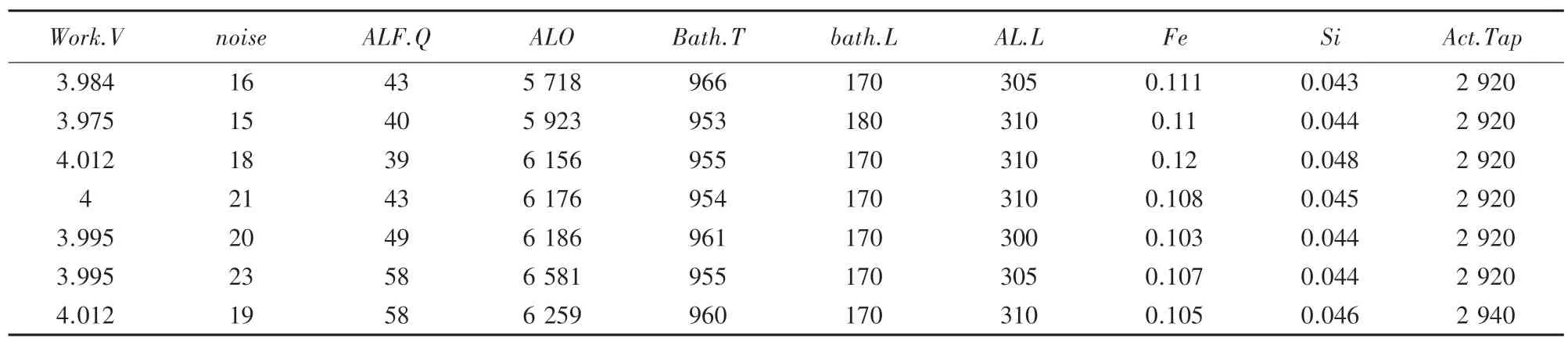
表1 數據集部分樣本Tab.1 Data set partial sample
Step 1輸入和輸出的數據集Z-score 標準化處理。
Step 2數據集進行隨機劃分,將20%的數據作為測試集,80%的數據集作為訓練模型的訓練集。最后再選取60 天的數據對MLP 模型預測效果進行驗證。
Step 3使用搭建好的神經網絡模型對訓練集的輸入和輸出參數進行訓練。
Step 4使用MLP 出鋁量預測模型對測試集的輸入參數進行預測。
Step 5將預測值與真實值進行反歸一化處理,得出MAE(平均絕對誤差),最后再畫出預測值和實際值之間曲線對比圖進行分析。MAE計算公式如下:
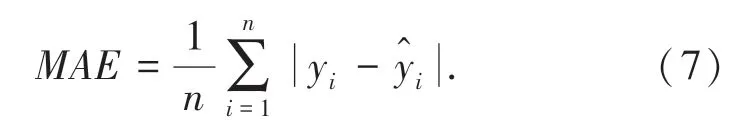
式中:n、yi、分別代表測試集數據數量、第i行真實值和第i行預測值。
3.2 訓練與預測結果分析
損失函數衰減過程如圖3 所示。訓練集數據在迭代25 次之后,測試集的損失函數穩定在5.0~7.5左右。
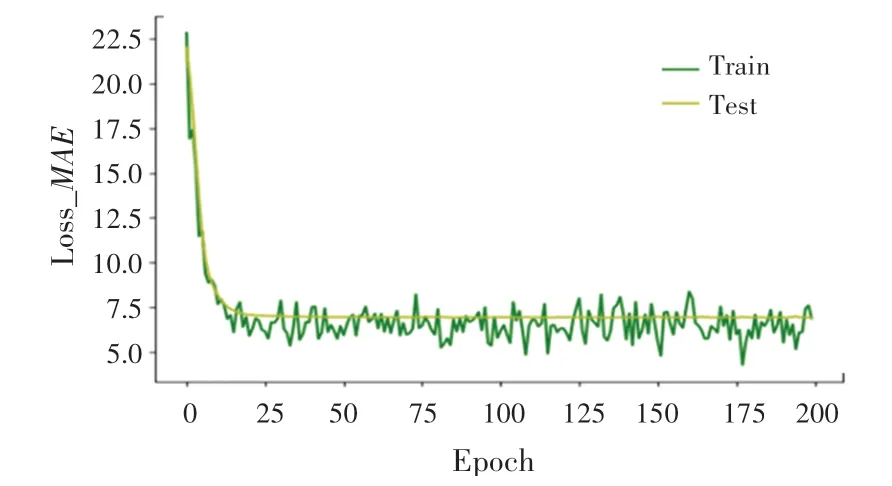
圖3 損失函數衰減圖Fig.3 Attenuation diagram of loss function
使用測試集數據進行出鋁量預測時,將測試數據集各相關參數通過神經網絡模型得到預測值曲線,然后再與每日出鋁量實際值曲線進行比較擬合,如圖4 所示。通過比對兩條曲線的變化趨勢,出鋁量的平均絕對誤差MAE =35.8,該誤差均在鋁電解工業誤差允許范圍之內,MLP 神經網絡對鋁電解生產過程中所產生的歷史數據進行擬合回歸后,該模型利用經驗數據中所含有的規律完成對數據的學習訓練,然后在一定誤差范圍內作出出鋁量的預測。
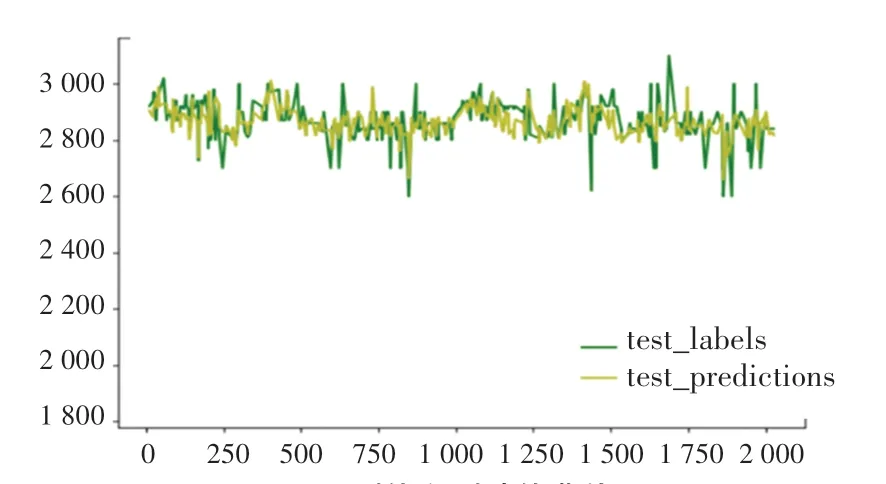
圖4 預測值和測試值曲線圖Fig.4 Predicted and tested value curves
4 結束語
本文利用tensorflow 機器學習框架,結合Python編程語言搭建了鋁電解槽的出鋁預測模型。針對貴州某鋁廠350KA 一產區某電解槽的生產歷史數據進行數據預處理,從鋁電解工藝生產過程中產生的一系列參數中,篩選出9 個主要參數,用搭建的神經網絡對電解槽的出鋁量進行預測。通過多次輸入不同時期的數據得到神經網絡預測的值和實際的出鋁量對比驗證了該模型的可行性。在實際生產過程中,將該模型應用到鋁電解的生產分析中,不僅對操作人員進行槽作業時有一定的指導作用,而且減少了電解原料的損失。實驗證明,該模型在鋁電解工業上有一定的參考價值,算法具有一定的實用性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
光學精密工程(2016年6期)2016-11-07 09:07:19
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
核科學與工程(2015年4期)2015-09-26 11:59:03
