基于網絡爬蟲的青花瓷文物圖像數據集設計與構建
2021-11-27 10:38:06郭麗胡志恒趙恒謙張瑞彬吳瑞翔高振肖珂珂
科技資訊 2021年22期
郭麗 胡志恒 趙恒謙 張瑞彬 吳瑞翔 高振 肖珂珂


DOI:10.16661/j.cnki.1672-3791.2108-5042-3116
摘? 要:深度學習模型結構復雜,利用其進行圖像分類需要龐大的數據量,圖像數據集的規模和質量直接影響模型的效果,同時人工獲取文物圖像時,存在諸多不便。該文利用網絡爬蟲技術在故宮博物院官網批量獲取不同年代的青花瓷文物圖像,大大提高工作效率,然后對獲取的文物圖像進行全方位的分析和處理,為用戶之后進行不同年代的青花瓷圖像分類提供數據源。
關鍵詞:網絡爬蟲? ?青花瓷文物? ?數據裁剪? ?數據增強? ?數據集構建
中圖分類號:TP391.41? ? ? ? ? ? ? ? ? ? ?文獻標識碼:A文章編號:1672-3791(2021)08(a)-0015-04
Design and Construction of Blue-and-White Porcelain Image Dataset Based on Web Crawler
GUO Li? ?HU Zhiheng? ?ZHAO Hengqian*? ?ZHANG Ruibin? ?WU Ruixiang? ?GAO Zhen? XIAO Keke
(College of Geoscience and Surveying Engineering, China University of Mining & Technology(Beijing), Beijing, 100083 China)
Abstract: The structure of deep learning model is complex.Using it for image classification requires a huge amount of data. The scale and quality of image data set directly affect the effect of the model. At the same time, there are many inconveniences when manually obtaining cultural relic images. Through web crawler, we obtained images of blue-and-white porcelain from various dynasties in batch from Palace Museum official website, which greatly improves efficiency. We conduct an all-around analysis and processing of these images, thereby provide a data source for any users when classifying blue-and-white porcelain images from different dynasties.
Key Words: Web crawler; Blue-and-white porcelain; Data clipping; Data augmentation; Dataset construction
我國歷史源遠流長,文物遺存豐富,其中古陶瓷類文物種類繁多,工藝精湛,文化內涵豐富,具有極高的科技研究價值。成熟的青花瓷出現在元代景德鎮,明清時期是青花瓷發展的主流,對青花瓷器文物的研究不僅可以反映出當時的社會文化,更是對傳統文化的一種傳承與保護。采集青花瓷文物圖像并對其進行預處理,是便于后續對不同年代的青花瓷文物進行分類。
對不同年代的青花瓷文物的分類離不開深度學習,同時深度學習模型結構復雜,利用其進行圖像分類需要龐大的數據量,圖像數據集的規模和質量直接影響模型的效果,利用網絡爬蟲技術批量下載博物館官方提供的青花瓷文物圖像可以大大提高數據獲取的效率。圖像的預處理工作也是非常重要的環節,預處理的主要目的是篩選特征圖像,突出待識別圖像的特征,才能有效擴充數據集[1]。該文重點討論圖像的獲取和處理工作,為下一步研究做好充分準備。
1? 圖像獲取
為了保證數據來源真實可靠,經過調研最終確定選擇故宮博物院提供的陶瓷藏品,同時為了快速批量獲取各個年代的青花瓷圖像,筆者使用網絡爬蟲技術從故宮博物院官網批量獲取各個年代的青花瓷圖像。爬蟲使用的編程語言是Python和JavaScript,依賴庫主要是lxml、js、py_mini_racer、ScrapyPillow、OpenCV等。其中lxml是一個使用C語言編寫的第三方庫,它結合了速度以及簡單方法提取結構化XML的優點,對于在網頁中提取數據很方便[2]。
利用網絡爬蟲技術獲取圖像具有快速、方便的特點,但同時也存在一些困難。當下的前端技術發展很快,幾乎所有的網站都加入了反爬機制,如果簡單的暴力提取,不僅不會提取到大量數據,還會被封掉IP,甚至會封掉賬號,所以選擇使用大量代理IP和攔截請求,修改js代碼的逆向爬蟲技術。這樣不僅可以不必分析結構化的HTML文件,還大大提高了獲取速度,但缺點是接口分析難度相比于HTML分析至少是提高了一個數量級[3]。對于信息量不大且反爬比較嚴重的網站就會使用lxml直接提取信息[4]。而對于信息量很大,但是接口容易分析而且逆向破解可以實現的話,主要使用逆向爬蟲的方法。如果實在是難以實現,我們最終選擇使用Selenium獲取數據,這是一個網站自動化測試包,在網站前端復雜而信息量不大的情況之下使用它進行數據獲取是一個很好的選擇[5]。
在圖像獲取的過程中,會有一些不是青花瓷的圖像被意外下載,對待這個問題,我們使用的是TensorFlow Hub的目標探測模型,對于不是瓷器的圖像選擇放棄下載,很大程度上減輕了人工去錯的壓力。由于網絡請求耗時太長,我們需要充分利用多線程提高效率,同時考慮Python多線程不能充分利用多核,加入了多線程也是提高效率的方法[6]。
最終,使用網絡爬蟲技術獲取到明清時期24個年代的青花瓷圖像,為了之后使用深度學習模型進行青花瓷文物圖像分類,選擇數據量較為豐富且具有代表性的10個年代青花瓷文物圖像進行后續研究。其中,10個年代分別為:明成化、明嘉靖、明隆慶、明萬歷、明宣德、明永樂、明正德、清康熙、清乾隆、清雍正。
2? 圖像裁剪
基于Python的圖像裁剪主要用到的是OpenCV庫和PIL(Python Imaging Library)庫。OpenCV是一個基于BSD許可(開源)發行的跨平臺計算機視覺和機器學習軟件庫,可以運行在Linux、Windows、Android和Mac OS操作系統上。它輕量級而且高效——由一系列C函數和少量C++類構成,同時提供Python、Ruby、MATLAB等語言的接口,實現了圖像處理和計算機視覺方面的很多通用算法。主要用于圖像分割、機器視覺、人機互動等相關研究。
PIL是Python一個強大方便的圖像處理庫。PIL庫可以完成圖像歸檔和圖像處理兩方面功能的需求。
(1)圖像歸檔:對圖像進行批處理、生成圖像預覽、圖像格式轉換等。
(2)圖像處理:圖像基本處理、像素處理、顏色處理等。
2.1 整體裁剪
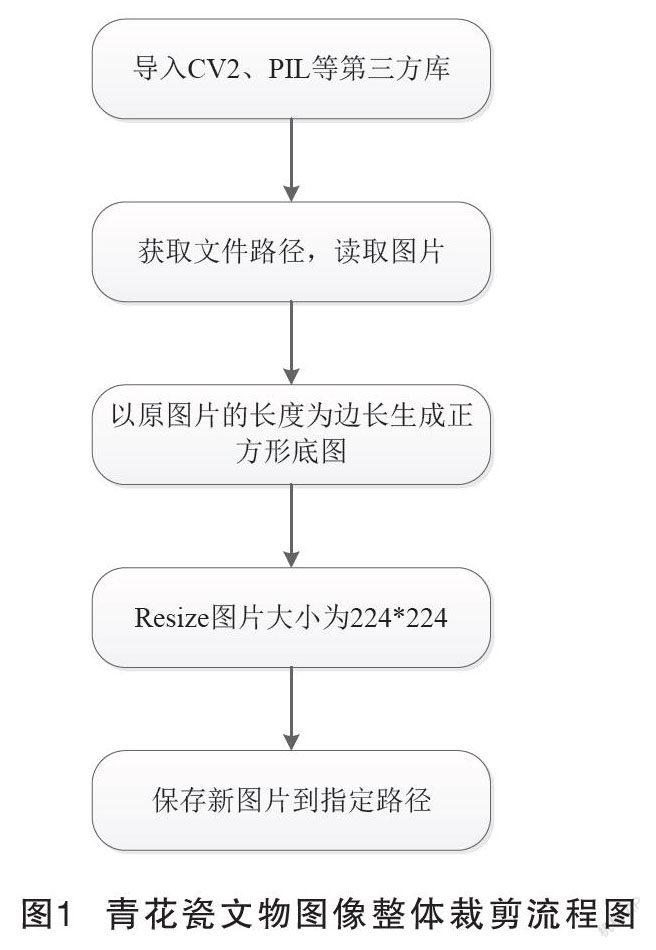
由于獲取的圖像大小不一,為了便于后續研究工作的順利開展,先對圖像數據進行裁剪處理,統一裁剪成像素大小為224×224。為了避免裁剪后出現變形等失真情況,裁剪之前先將圖像補成以原圖像的長邊為邊長的正方形,再批量對其進行裁剪。
裁剪流程圖如圖1所示,為了獲得原圖像的長和寬,先用Image.fromarray函數實現從數組到圖像的轉換,再通過函數image.size獲取原圖像的長和寬,將原圖像的長度作為正方形的邊長生成正方形的底圖,底圖的R、G、B賦值都為127,因此生成的是灰色的底圖。在此基礎上,將圖像裁剪成224×224大小,使用到的是image.resize函數。
將圖像進行整體裁剪,實際上類似圖像縮放,并沒有真地裁剪掉圖像的有效信息。圖2是青花瓷文物圖像整體裁剪的結果。
2.2 局部裁剪
為了更細致地描述青花瓷器的特征,同時達到數據集擴充的目的,我們進行了圖像的局部裁剪,獲得每張圖像的一些局部區域來作為輸入進行青花瓷器的分類。如果從圖像左上角或右下角等處進行裁剪,會得到大量圖像的背景信息,為了保證每張裁剪后的圖像信息有效,分別以每張圖像長和寬的1/1.5處、1/2處、1/2.5處和1/3處為中心進行局部裁剪,裁剪的圖像大小為100×100。裁剪用到的函數是image.crop,最后將裁剪后不包含青花瓷器特征的圖像或只包含少量特征的圖像刪除。
3? 數據增強
從故宮博物院官網爬蟲獲取的數據經篩選后,每個朝代只有幾十張圖像,數據量遠遠不夠,而數據增強可以有效增加訓練樣本、減少網絡的過擬合現象,通過對訓練圖像進行變換可以得到泛化能力更強的網絡,更好的適應應用場景。因此采用數據增強來擴充數據集,使擴充后的數據集滿足輸入到深度學習模型的需要。具體方法有添加椒鹽噪聲、高斯噪聲、旋轉、調整圖像亮度等。
首先,由于imread不能直接讀取中文路徑的圖像,所以讀取中文路徑的圖像用cv2.imdecode(np.fromfile(file_path,dtype=np.uint8),-1)來解決——先用np.fromfile()讀取為np.uint8格式,再使用cv2.imdecode()解碼。然后對每張圖像進行以下處理:分別添加30%的椒鹽噪聲和高斯噪聲、以圖像中心為旋轉中心旋轉15°、調整圖像的亮度為原來的90%和150%,使其更暗或更亮,這樣最終得到的圖像數量是原來的5倍。圖3是部分青花瓷文物圖像數據增強的結果。
4? 結語
該文使用網絡爬蟲技術,同時結合多個第三方庫,從故宮博物院獲取了多個年代的青花瓷文物圖像,經過對其進行分析和裁剪、數據增強等處理,最終選擇數據量較為豐富且具有代表性的10個年代的青花瓷文物圖像構建數據集。該數據集不僅滿足了日后使用深度學習模型進行圖像分類工作的要求,還為其他類別圖像數據集的構建提供了思路。
參考文獻
[1] 曾銘杰.基于深度學習的陶瓷類目識別[J].電腦知識與技術,2021,17(13):174-175.
[2] 張楠.Python語言及其應用領域研究[J].科技創新導報,2019,16(17):128-129.
[3] 吳道君.大數據背景Python在網絡爬蟲框架中的應用[J].科學技術創新,2021(21):97-99.
[4] 陶衛衛.Python爬蟲的Cookie反爬應對策略研究[J].信息與電腦:理論版,2021,33(8):189-192.
[5] 趙涵原.基于Python爬蟲的書籍數據可視化分析[J].電子技術與軟件工程,2021(14):178-179.
[6] SHANG S T,WU H G,MA J T.An Improved Focused Web Crawler based on Hybrid Similarity[J].International Journal of Performability Engineeri-ng,2019,15(10):2645-2656.
